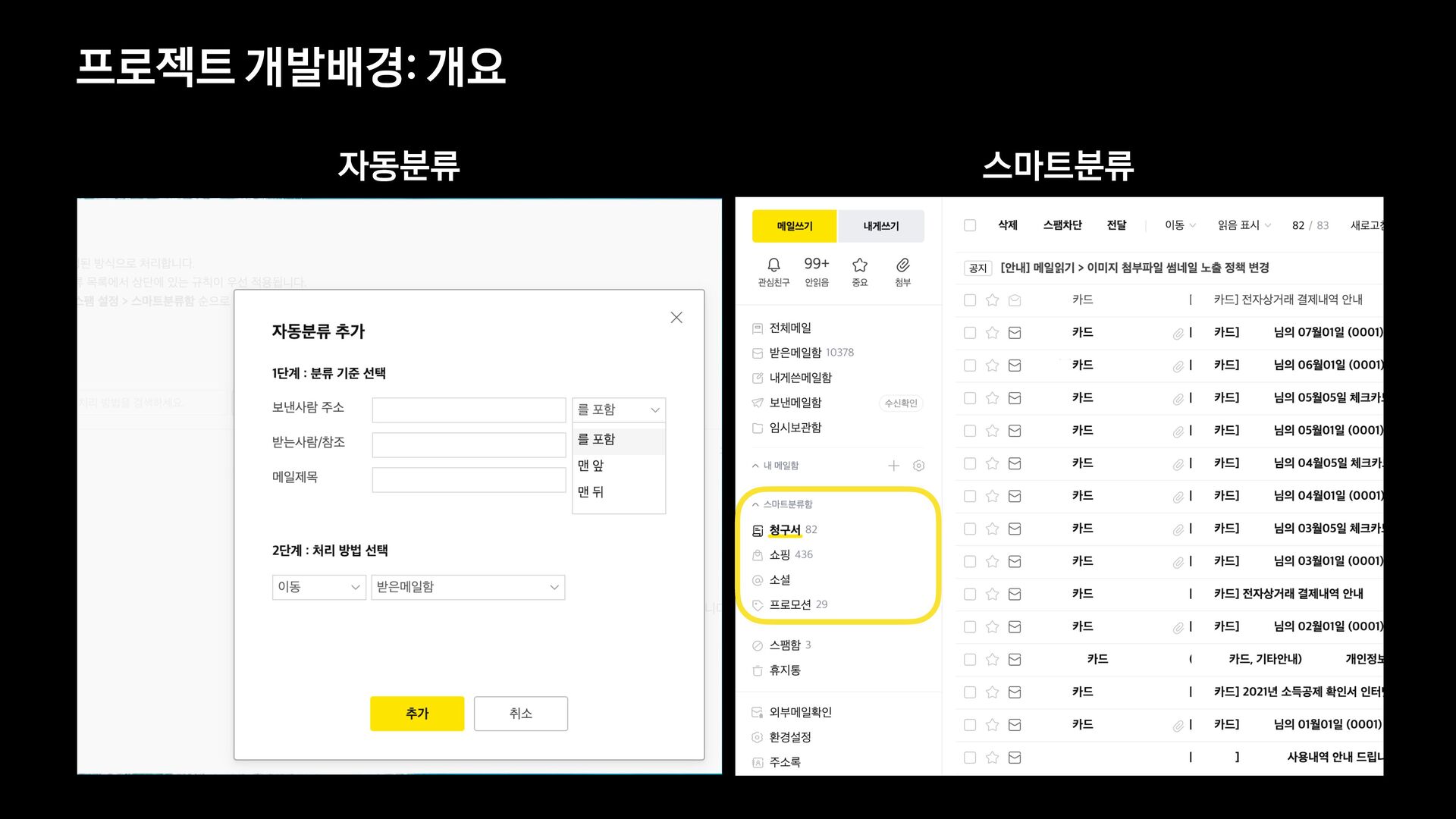
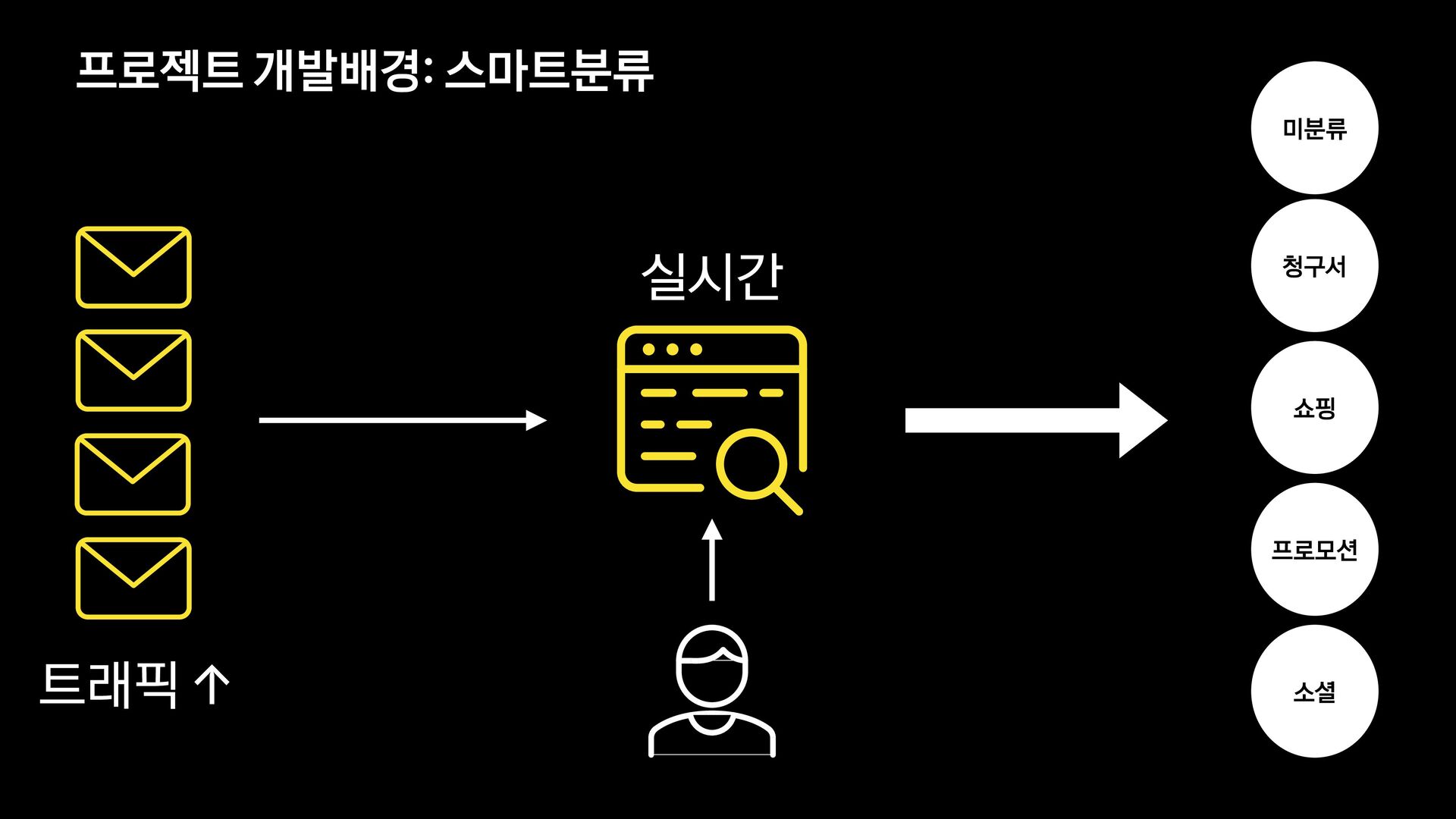
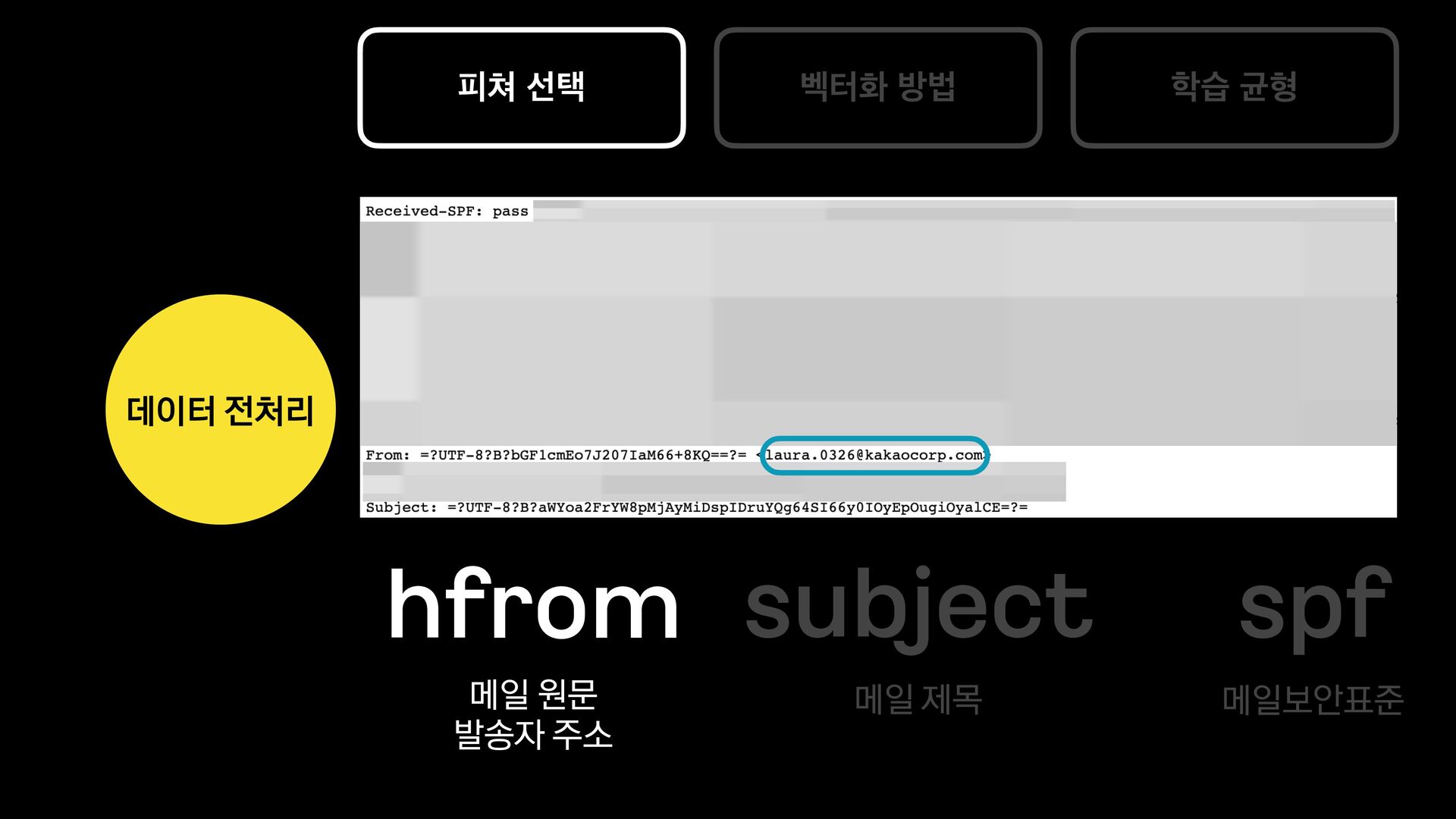
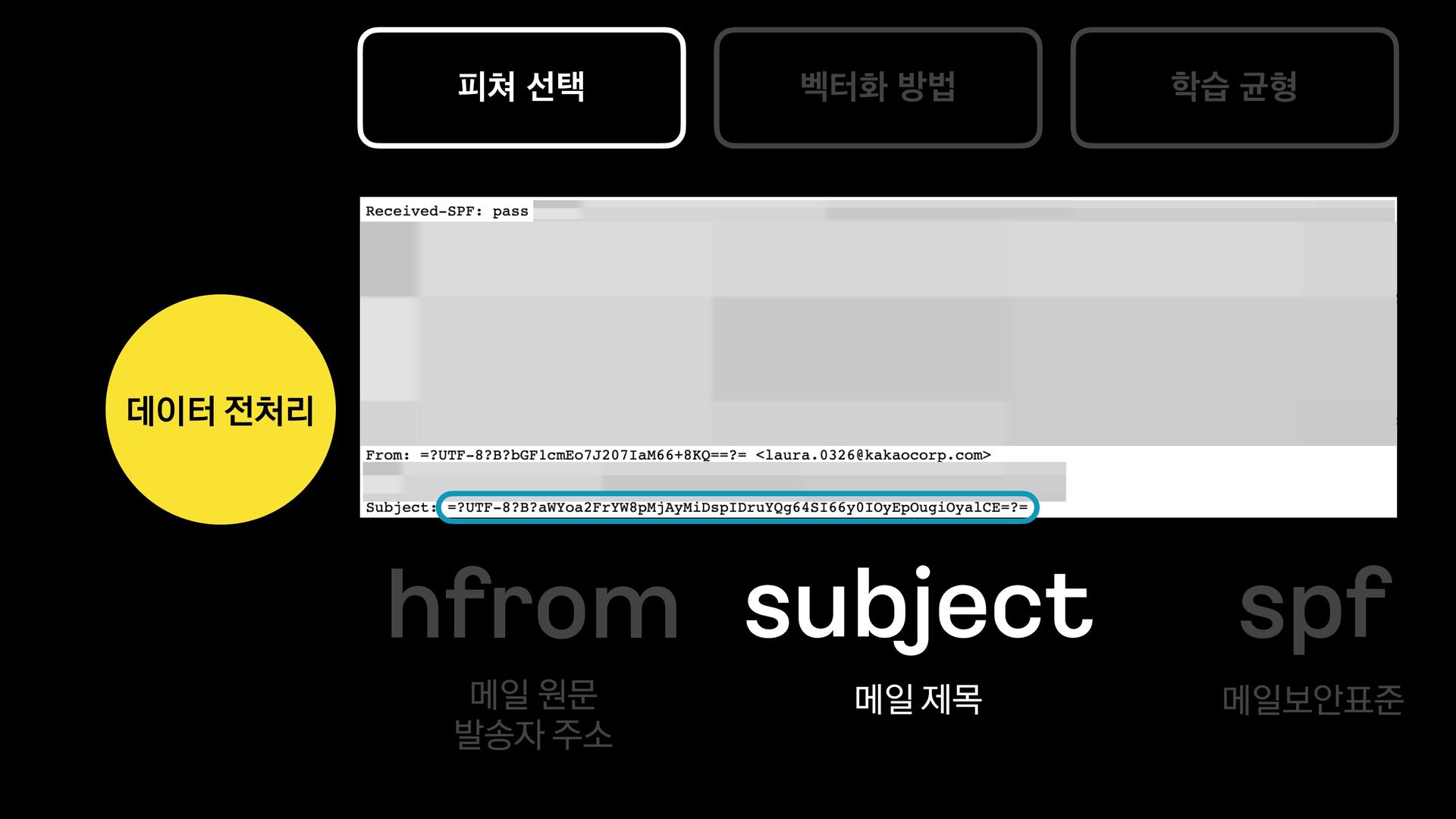
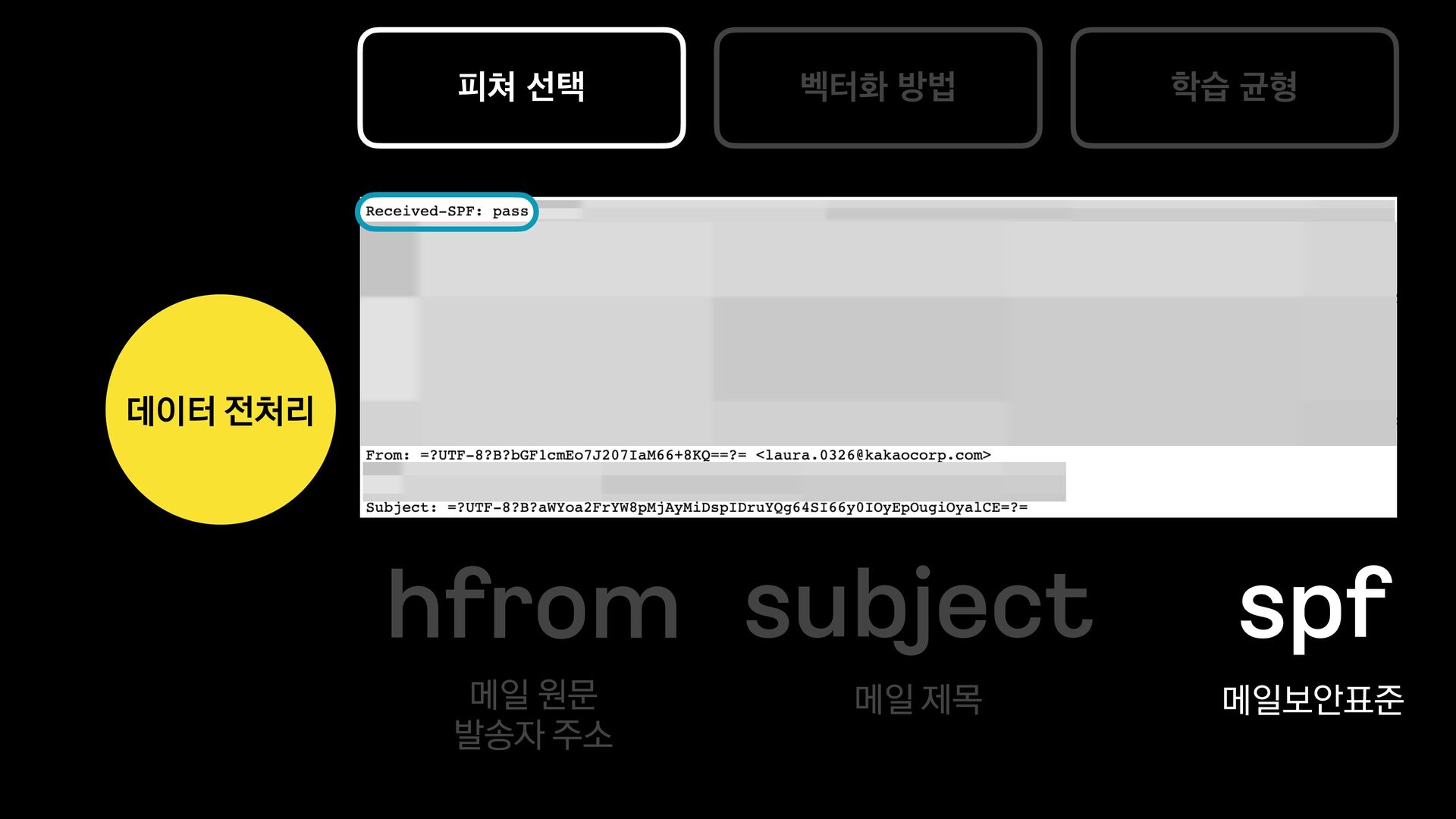
카카오에서는 다음 메일과 카카오 메일을 서비스 하고 있습니다.
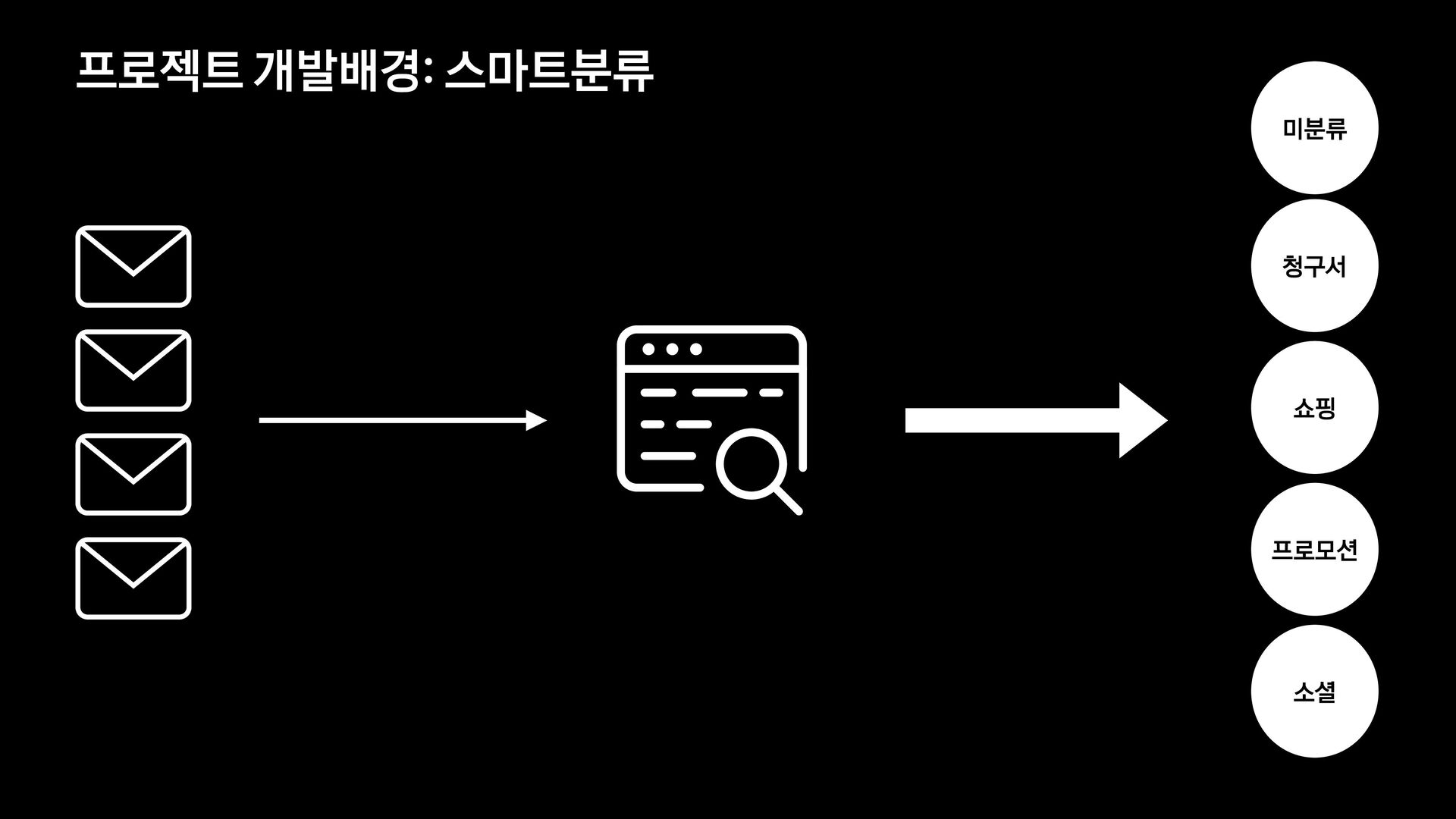
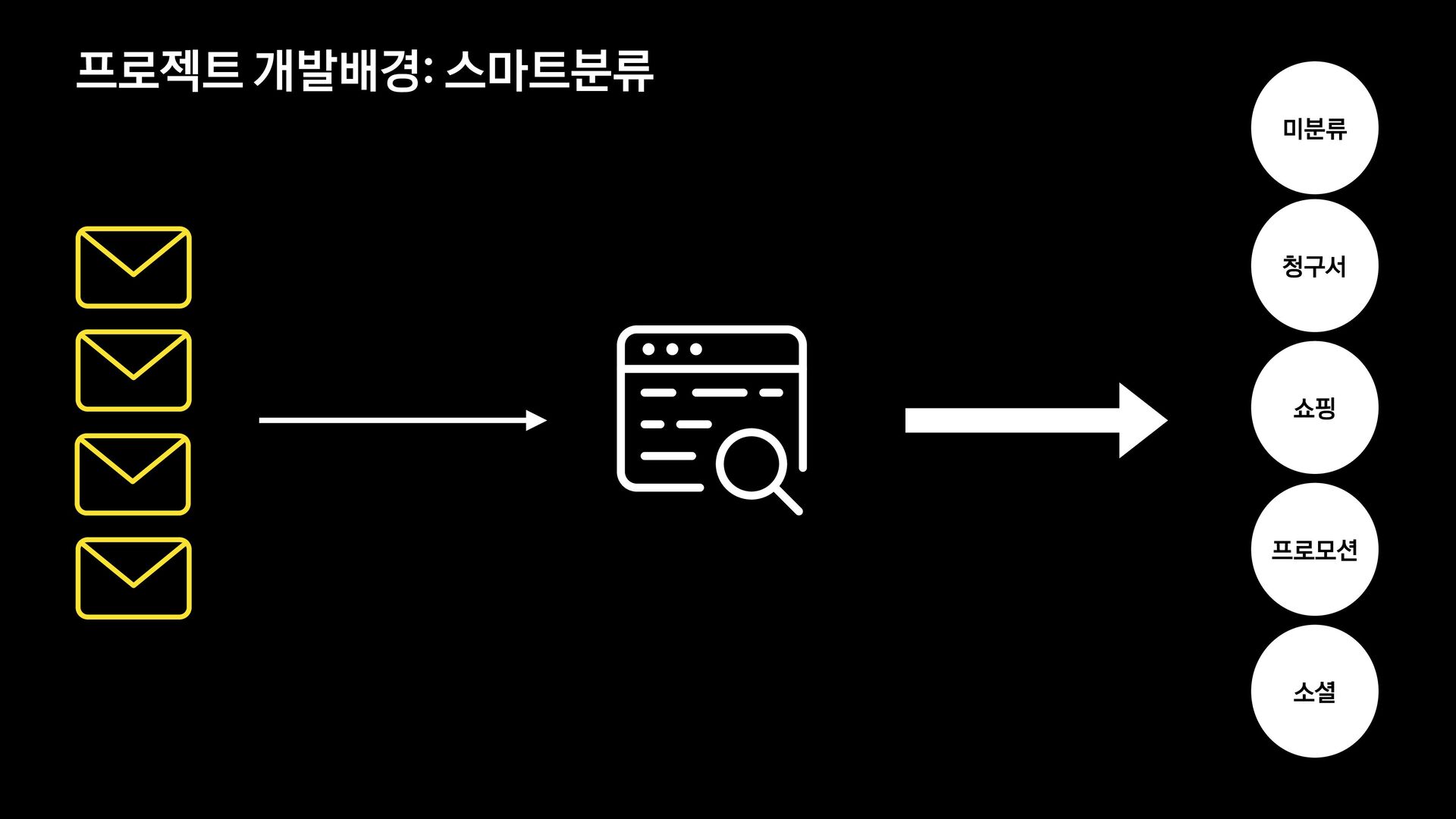
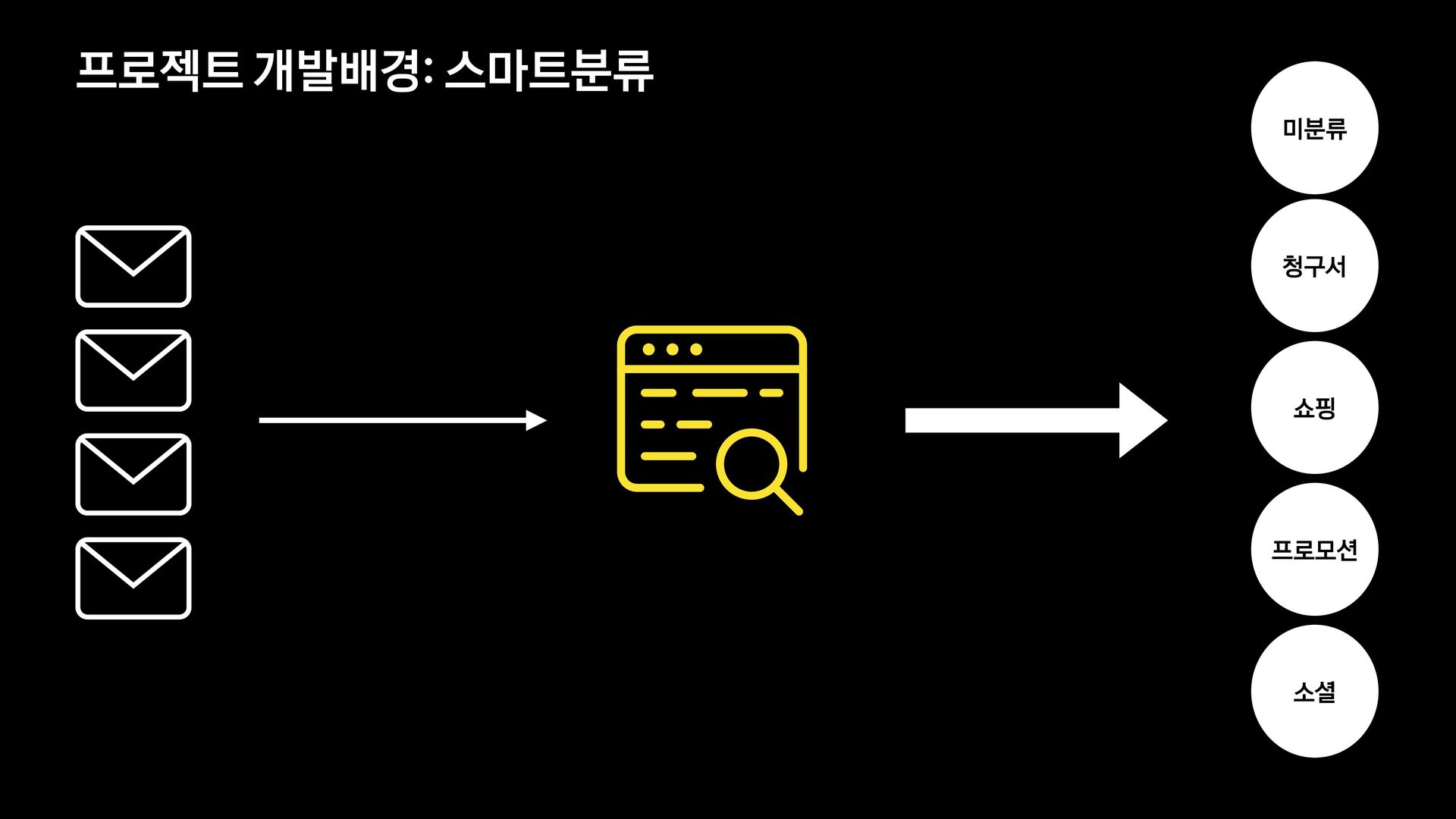
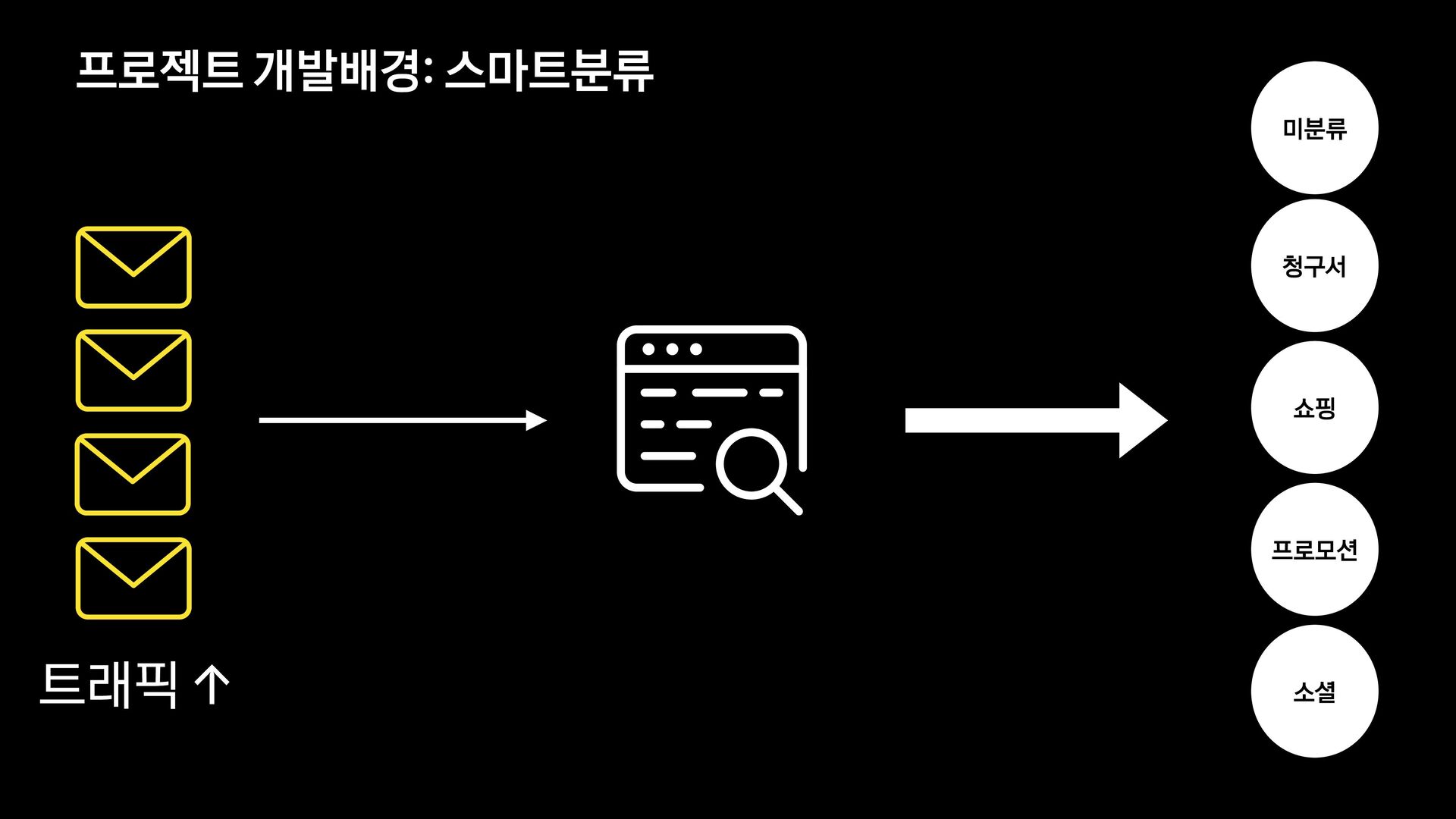
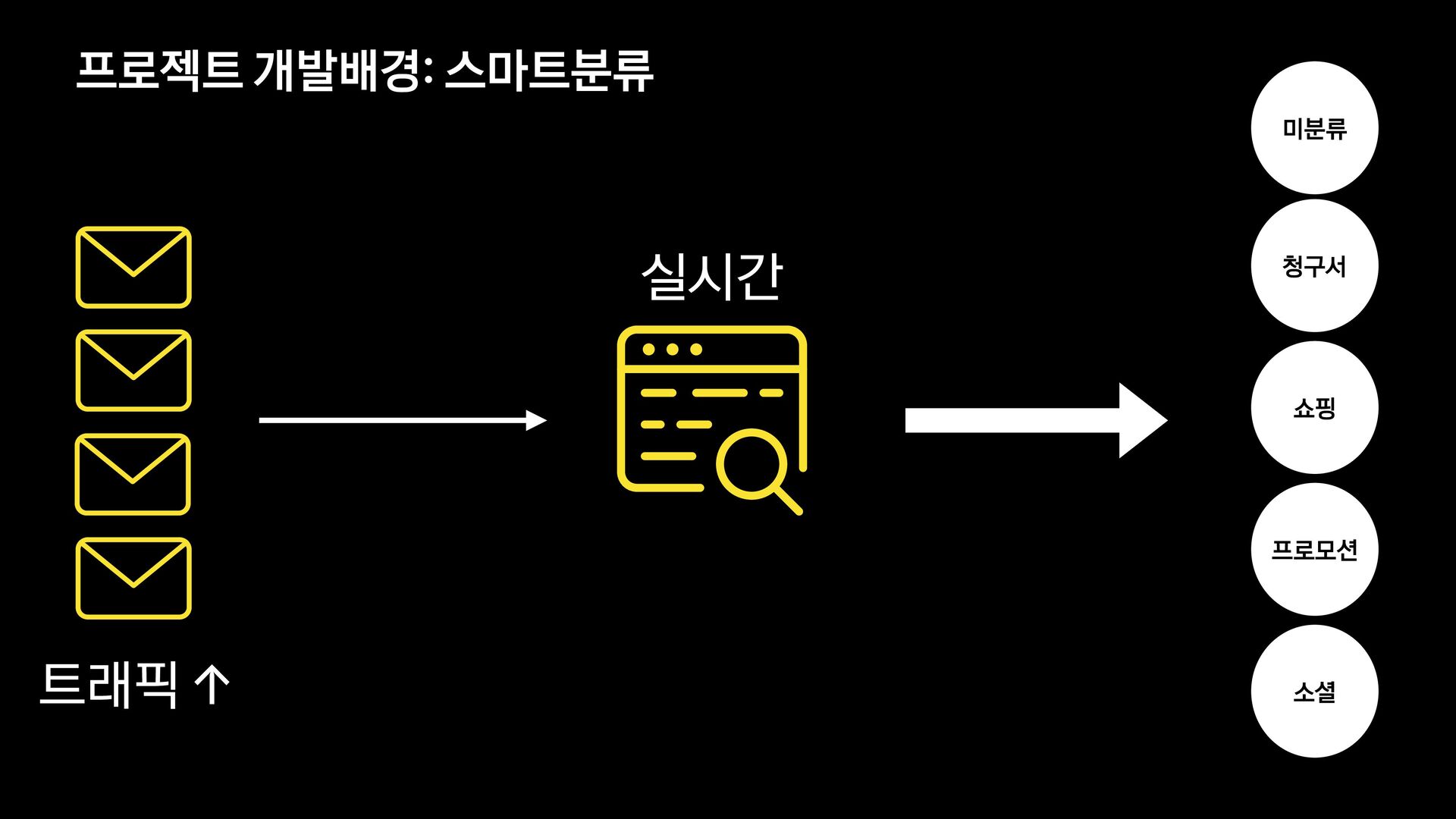
각 서비스에서는 메일의 유형을 분류하는 모델을 신규로 개발 중에 있습니다.
이 세션에서는 머신러닝에 대해 생소한 백엔드 개발자가 어떻게 분류 모델을 개발하였는지, 그 과정과 진행하며 깨달은 사항들에 대해 공유합니다.
발표자 : laura.0326
카카오에서 다음/카카오 메일 서비스를 개발하고 있는 로라입니다.
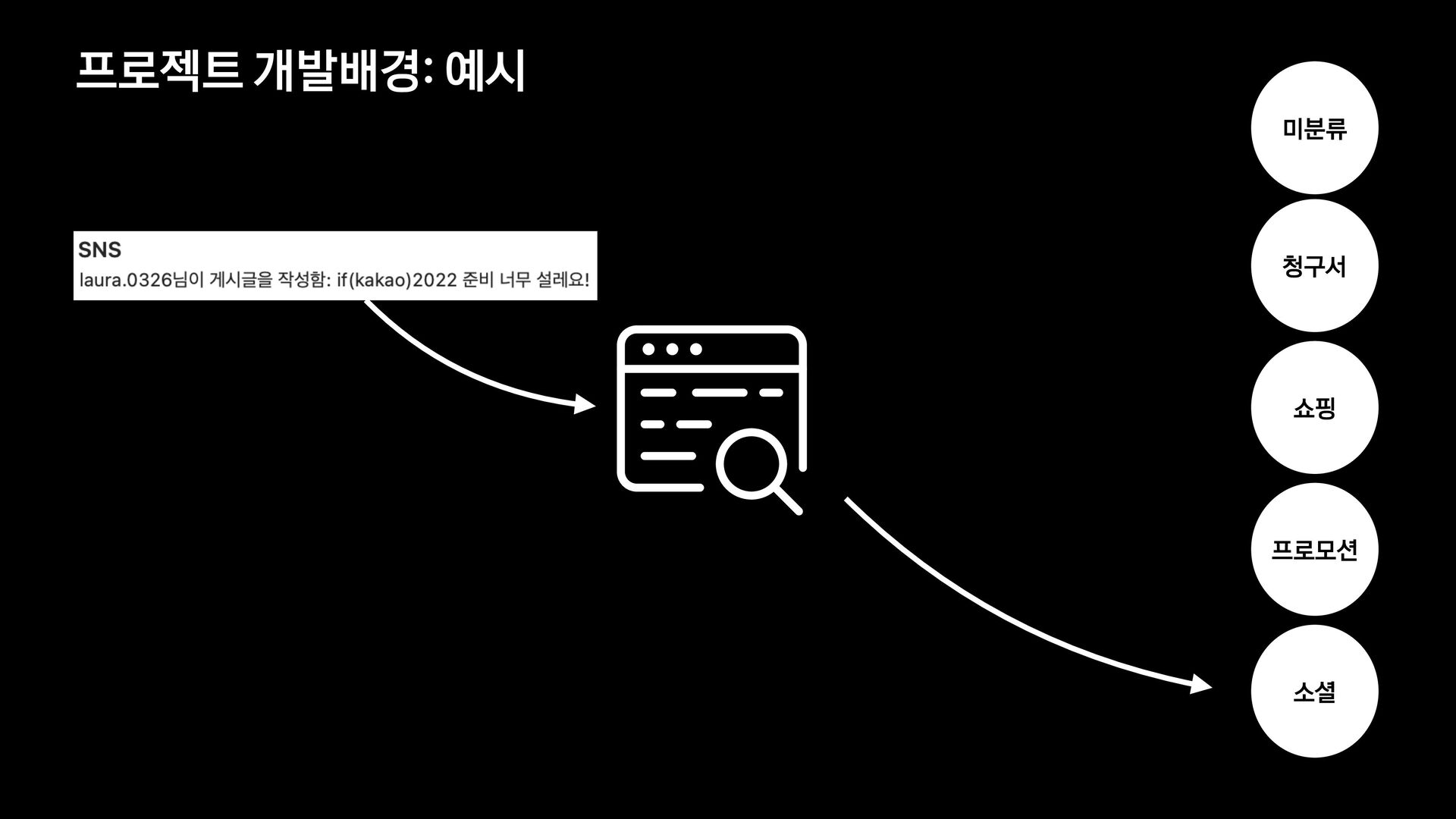
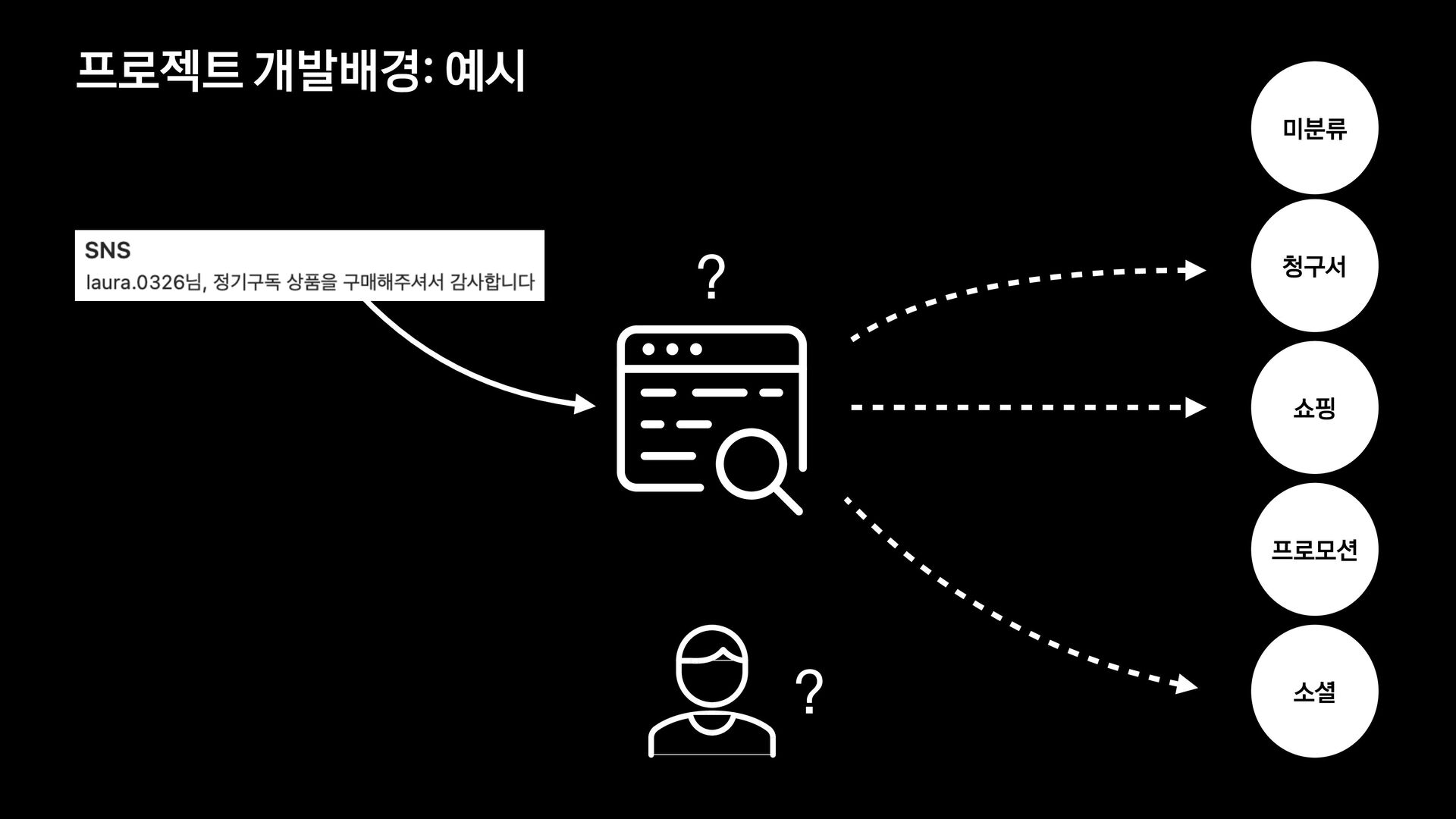
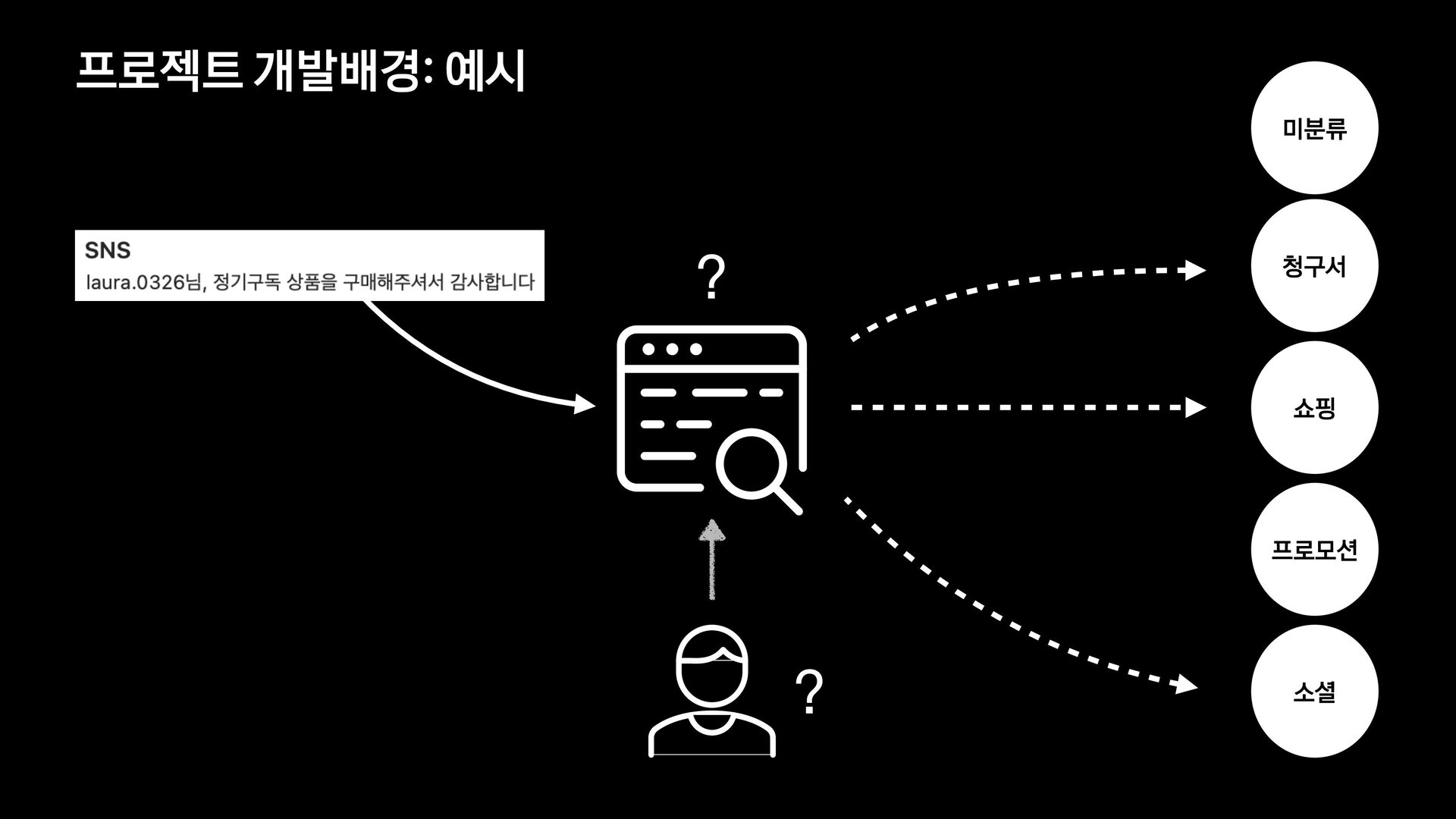
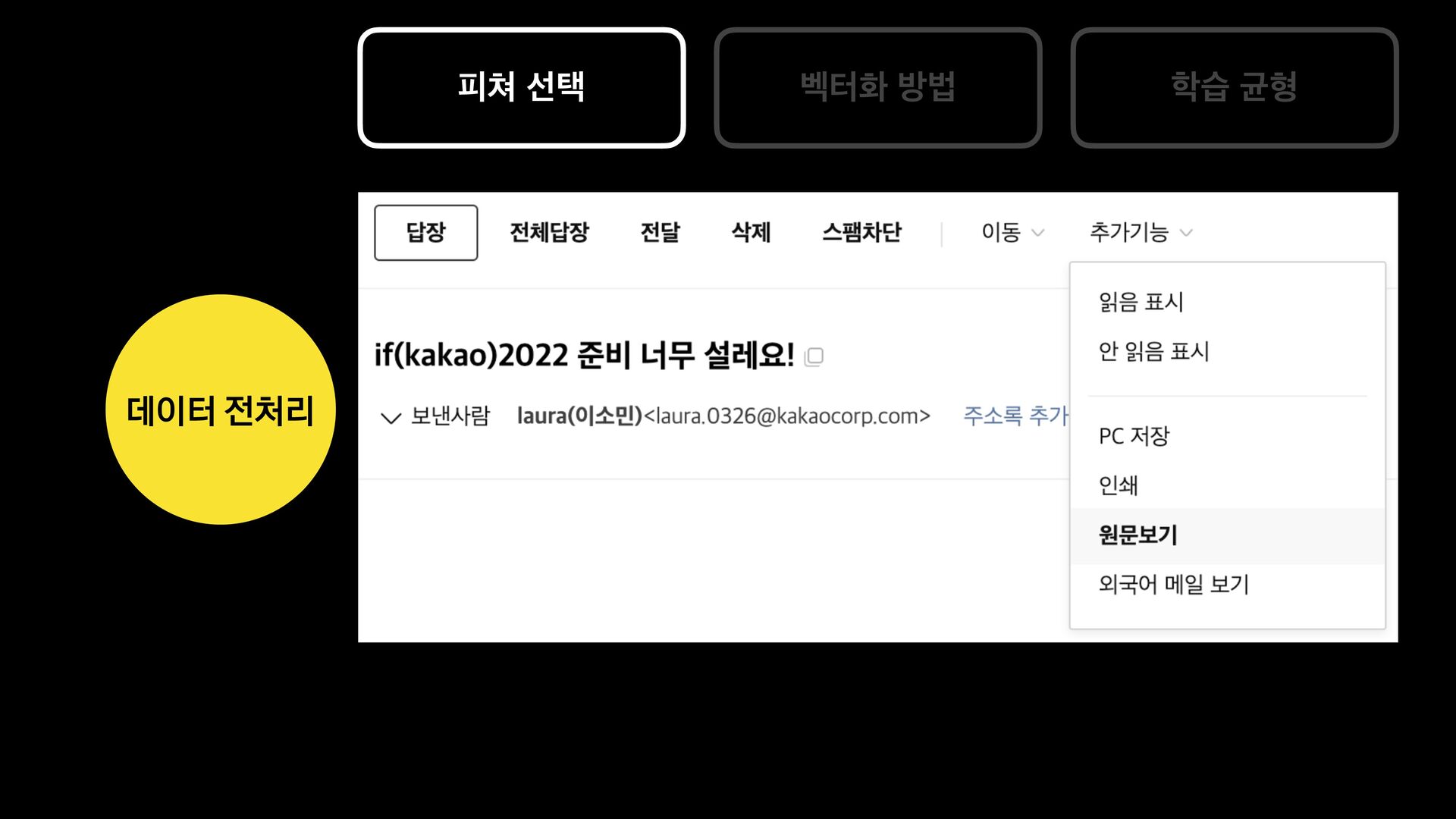
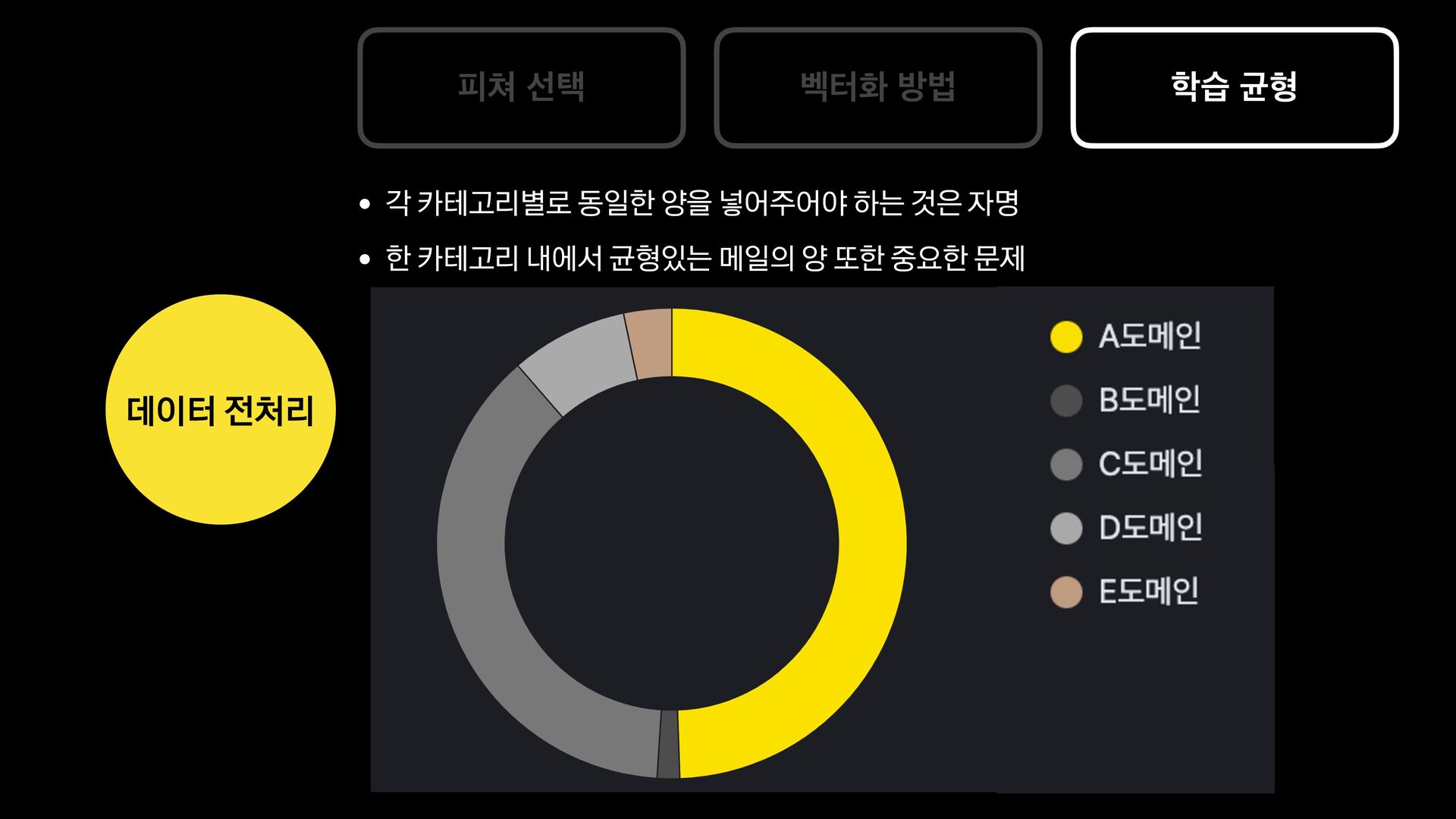
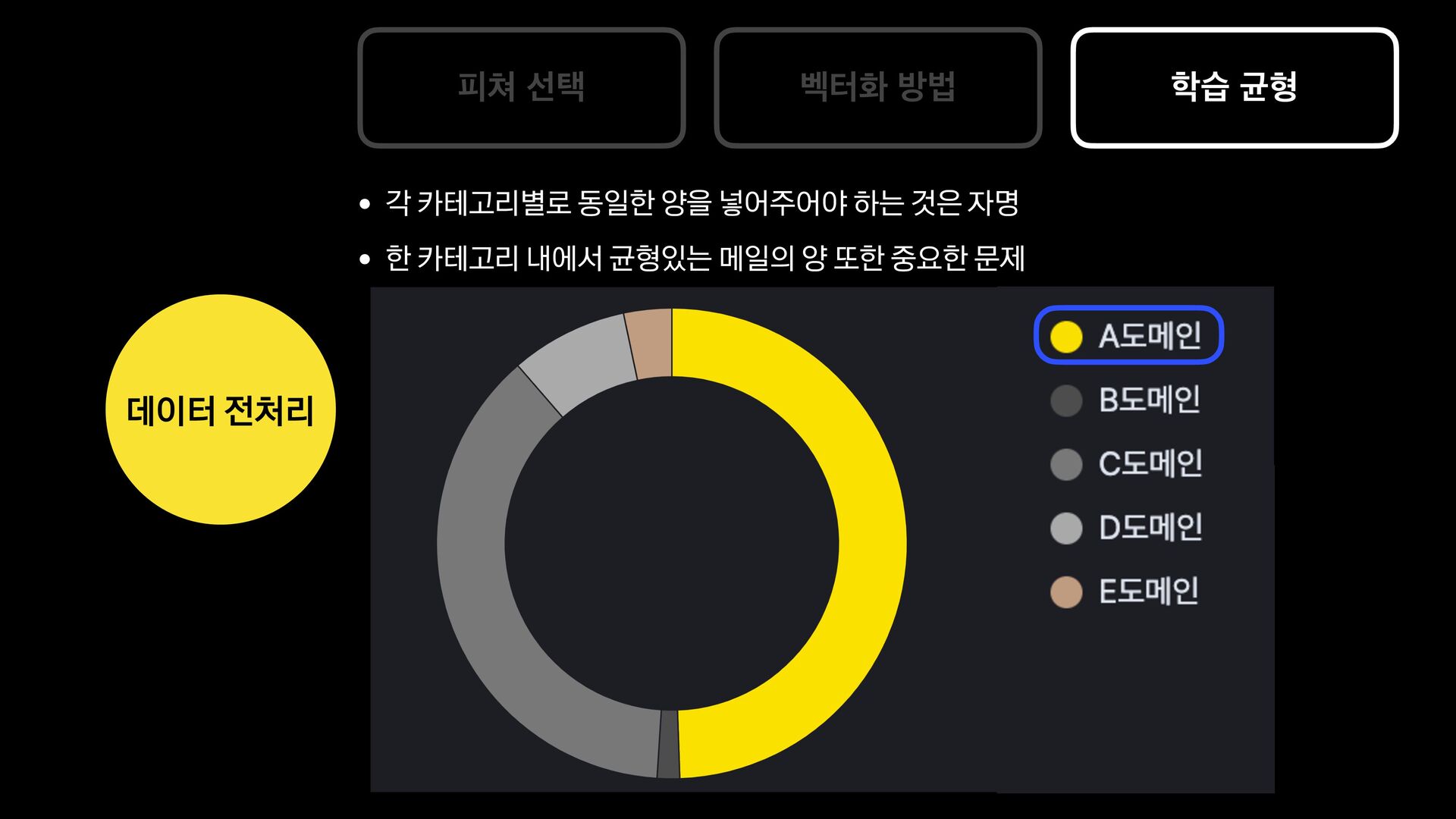
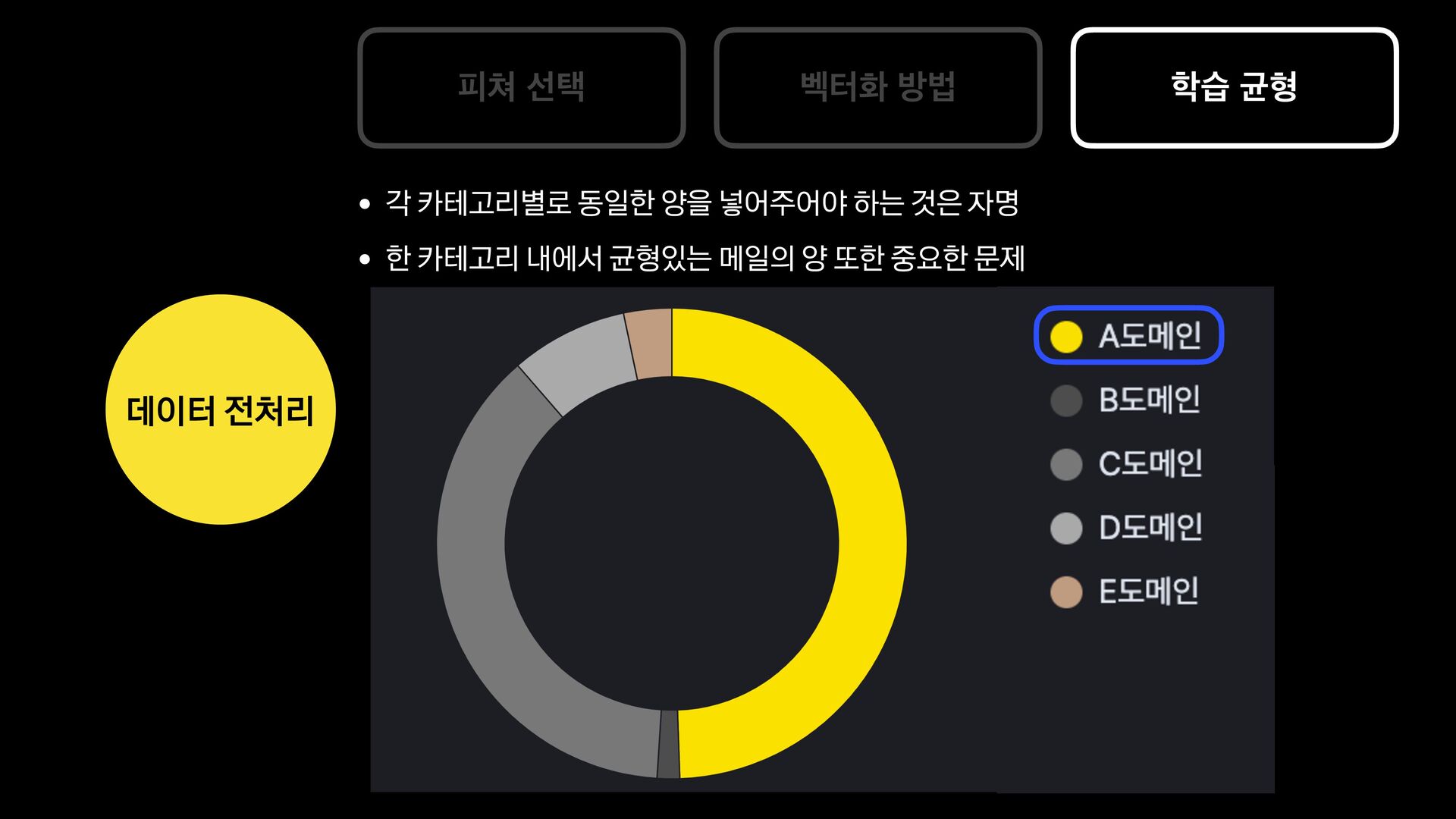
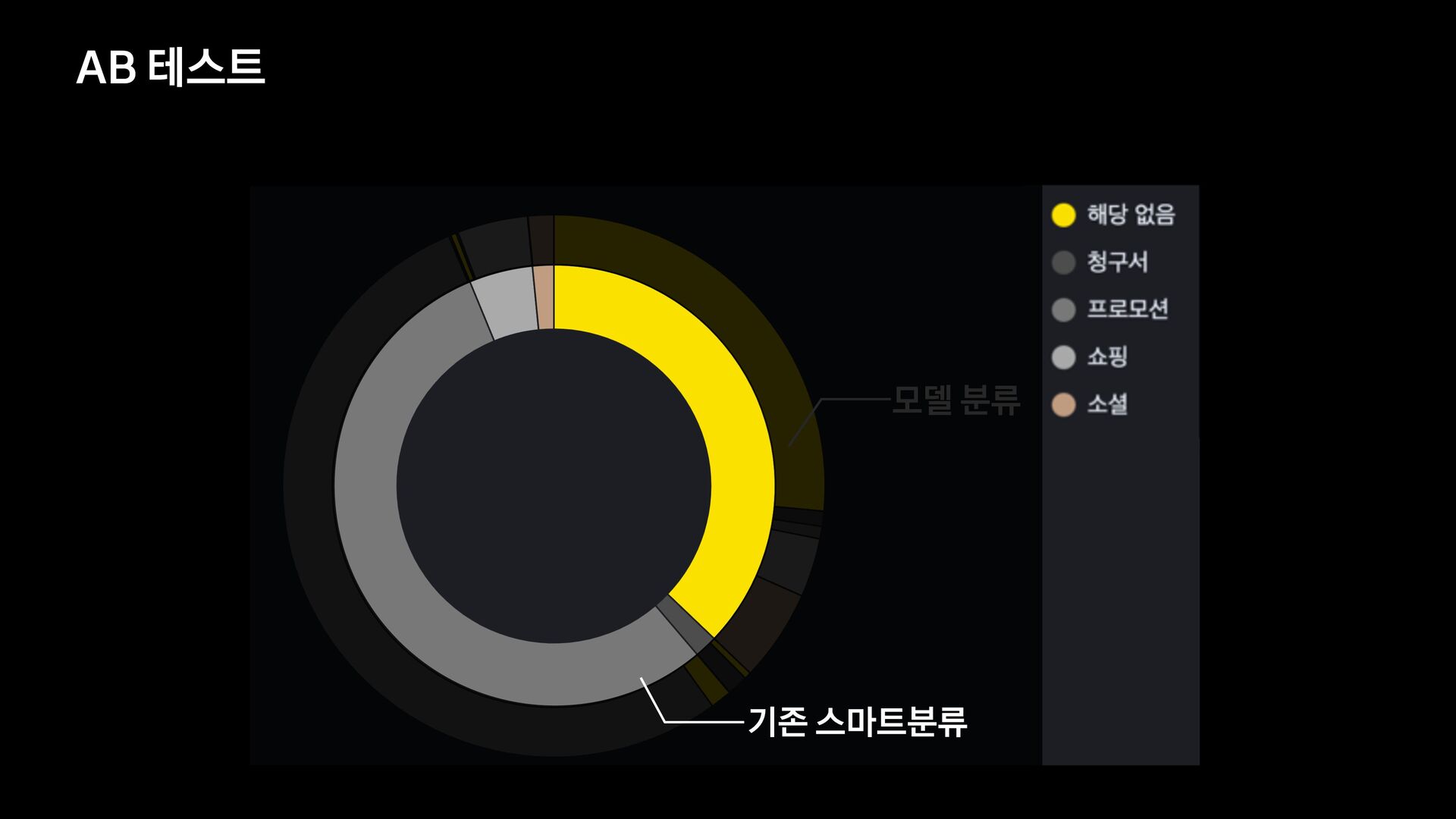
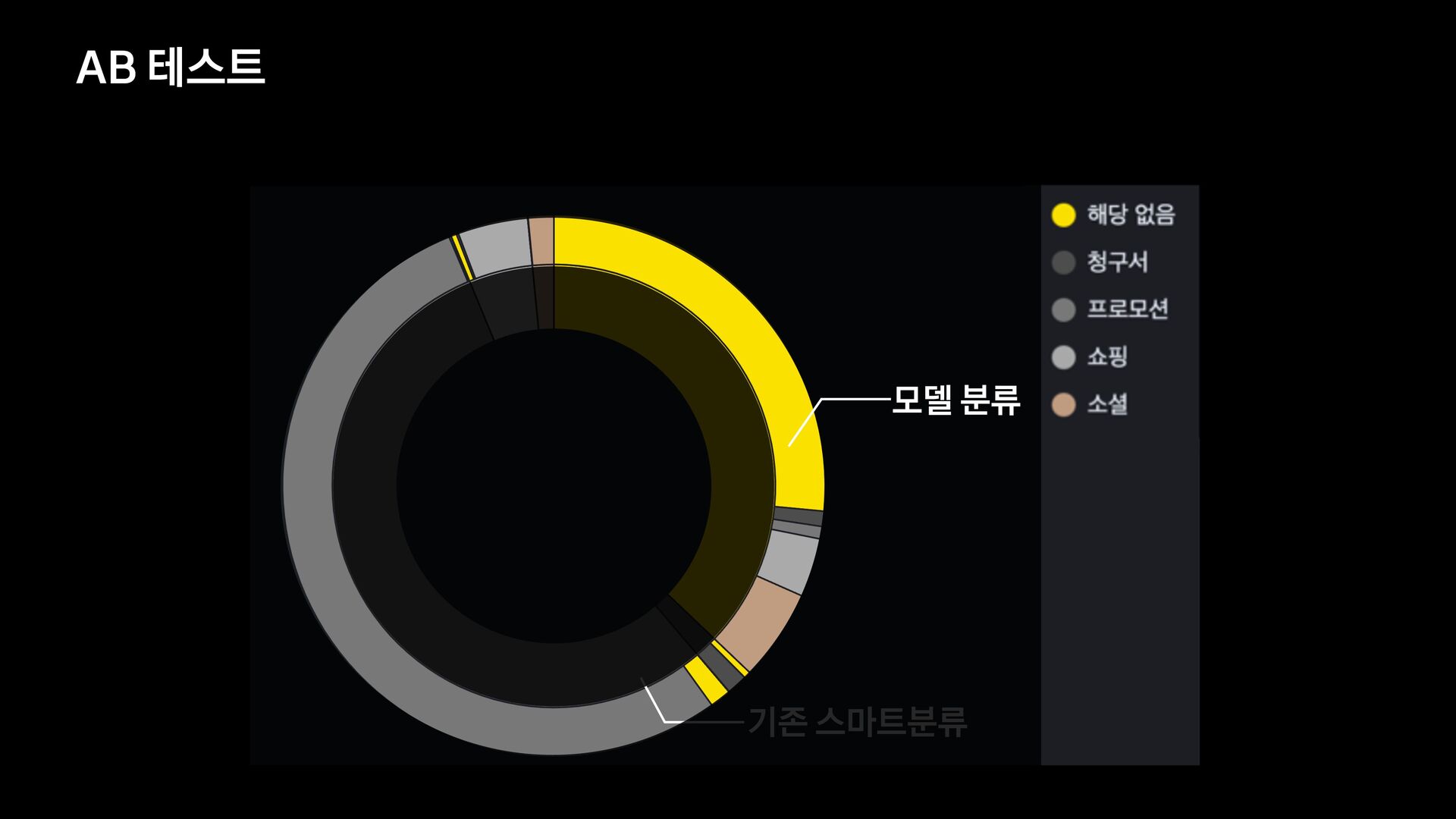
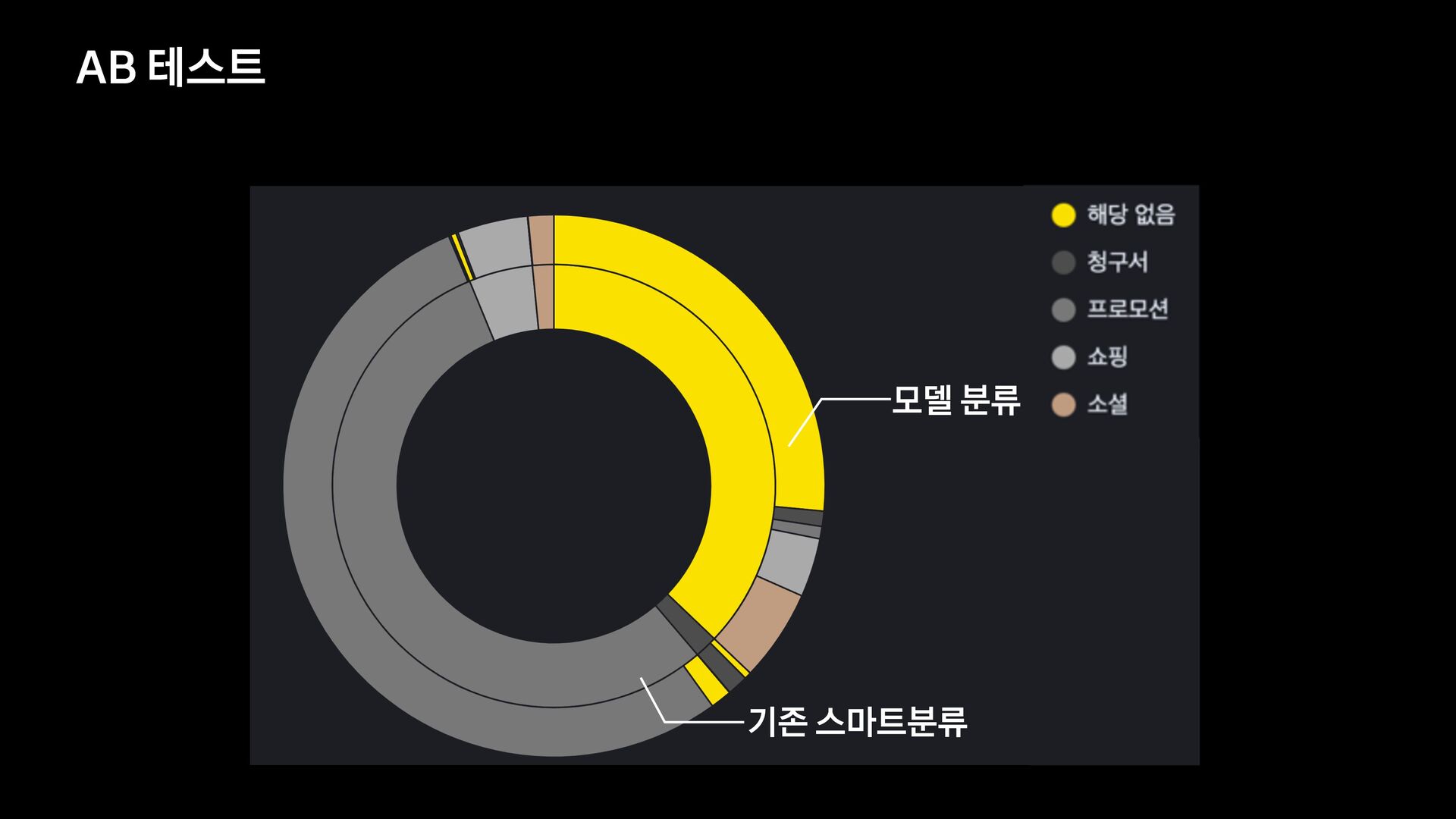
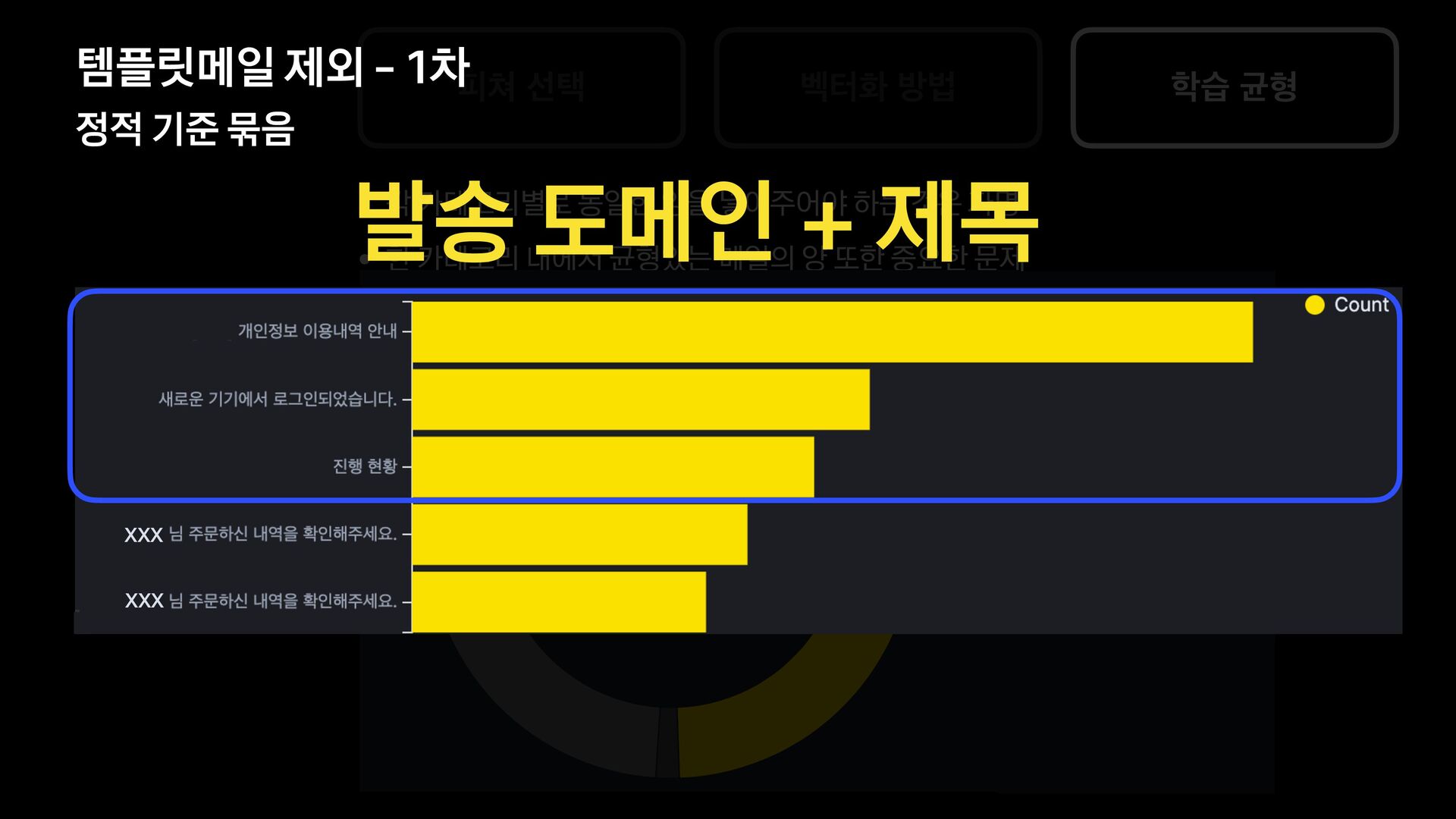
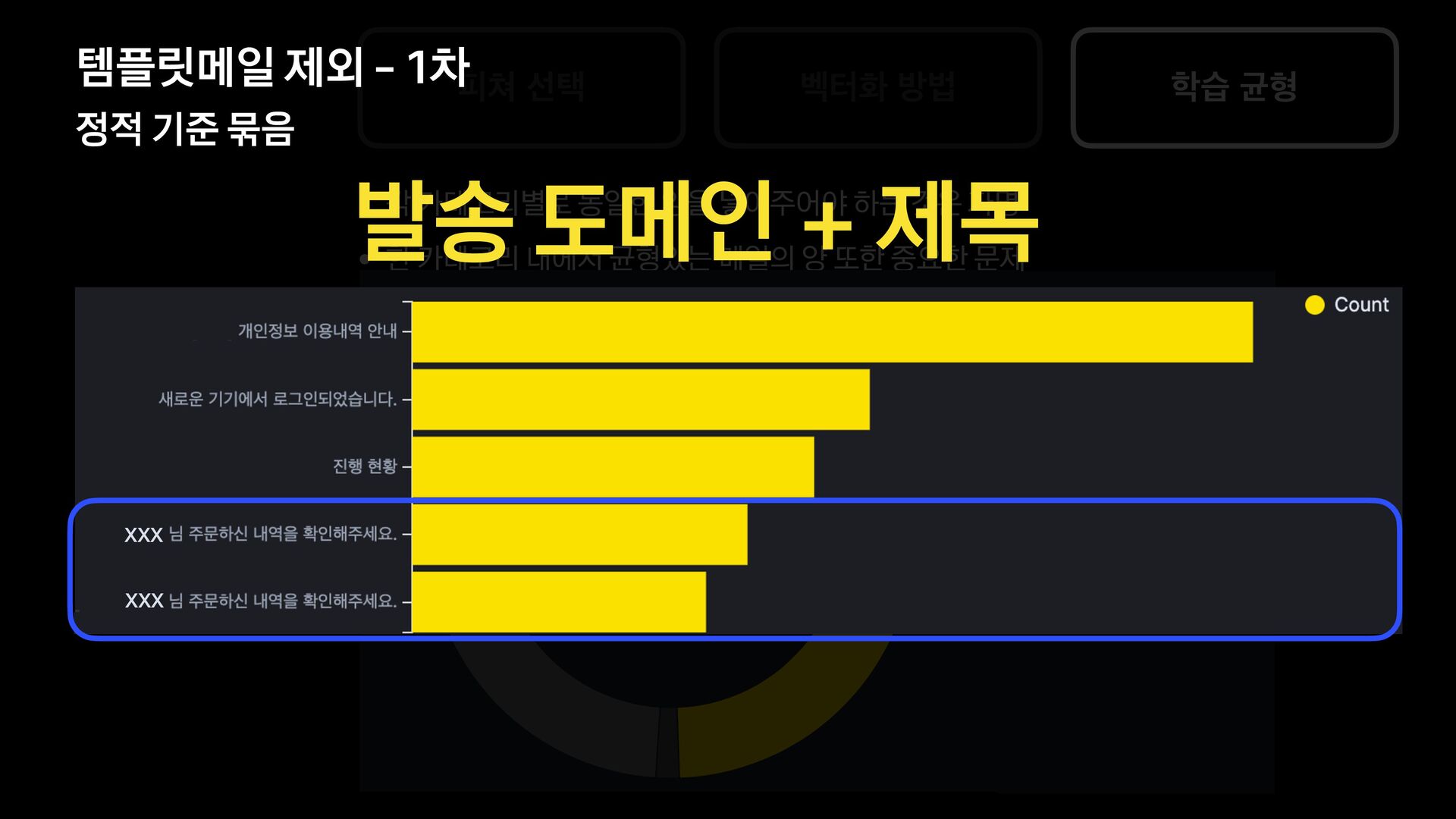
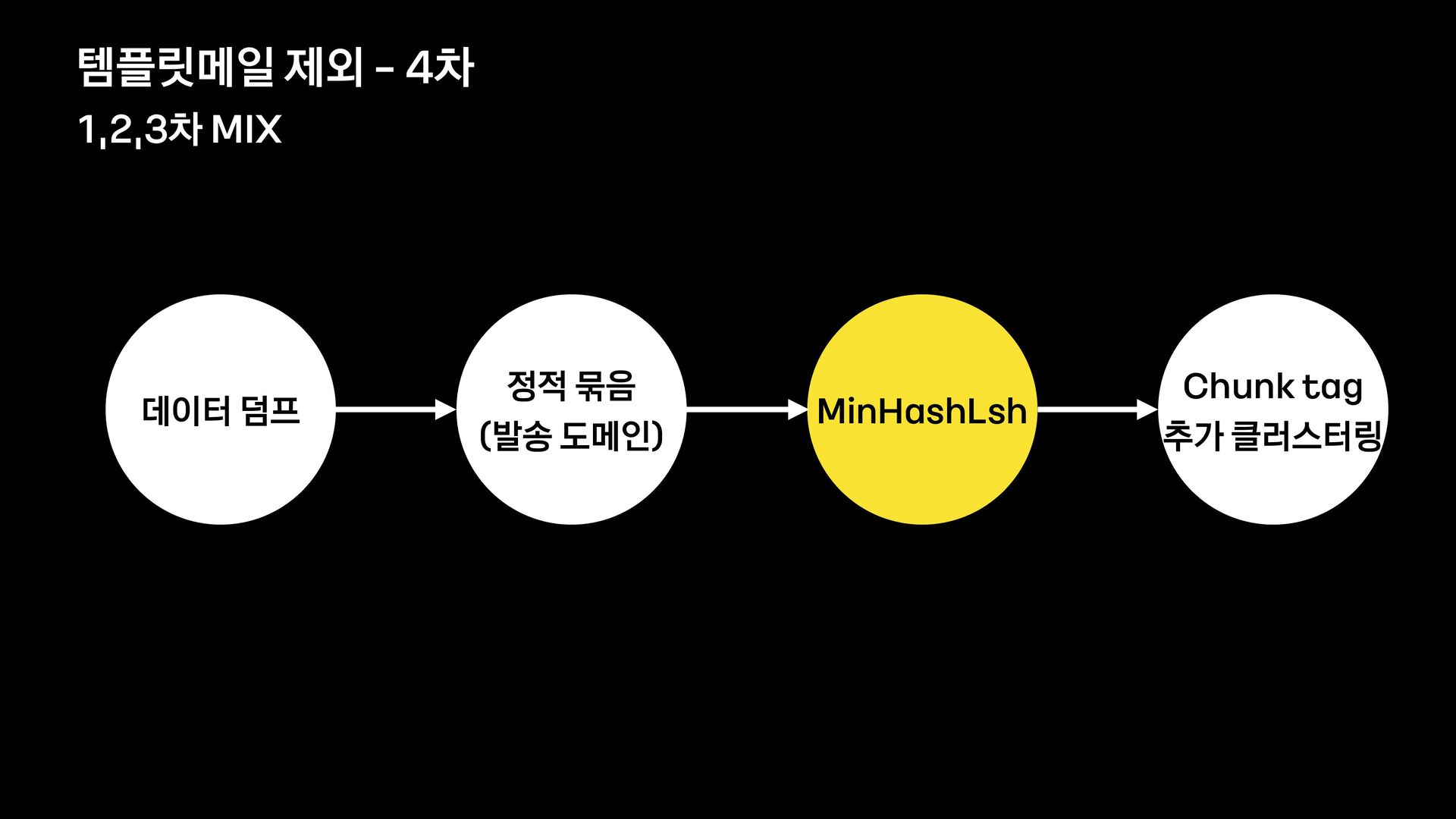
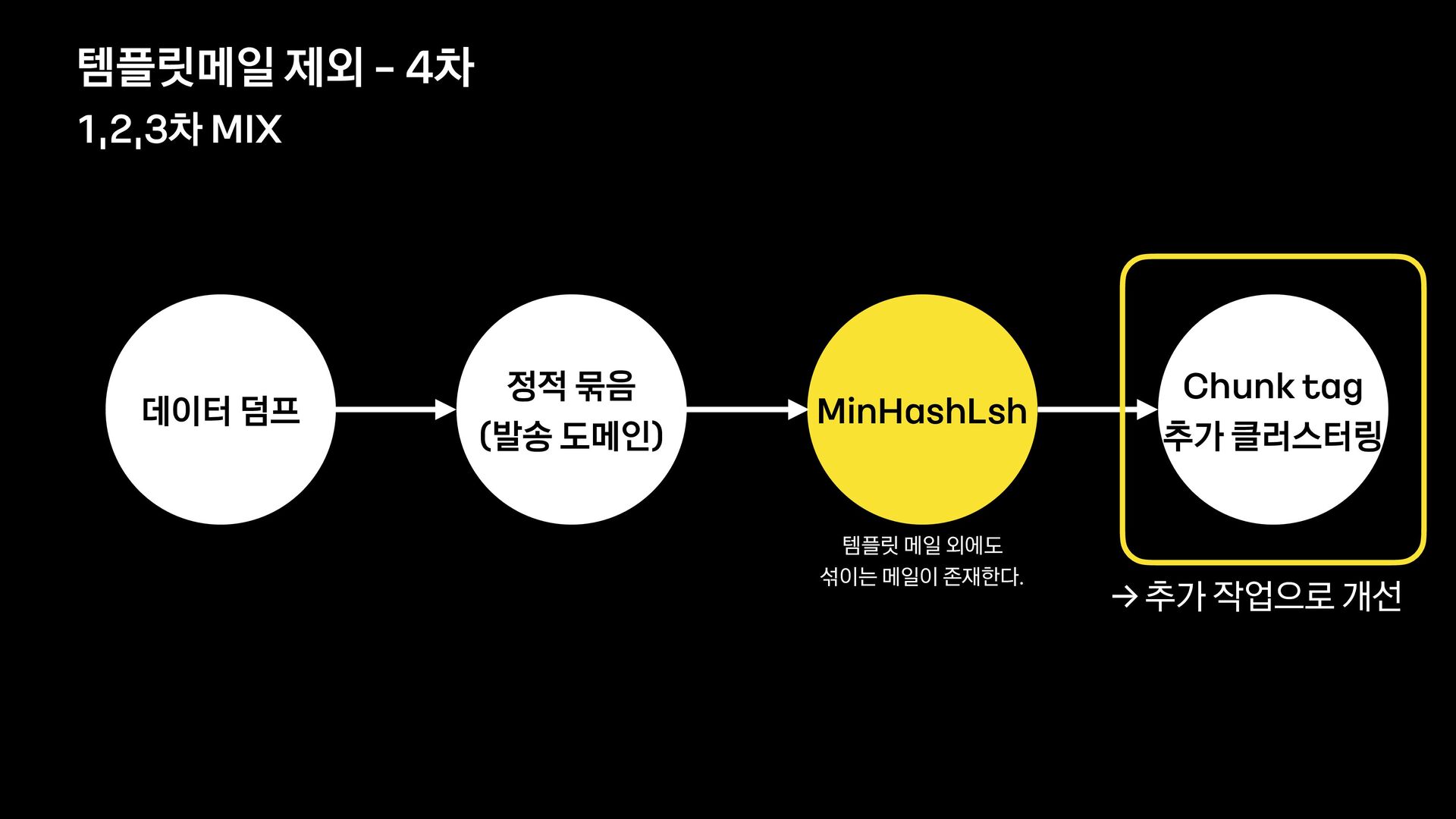
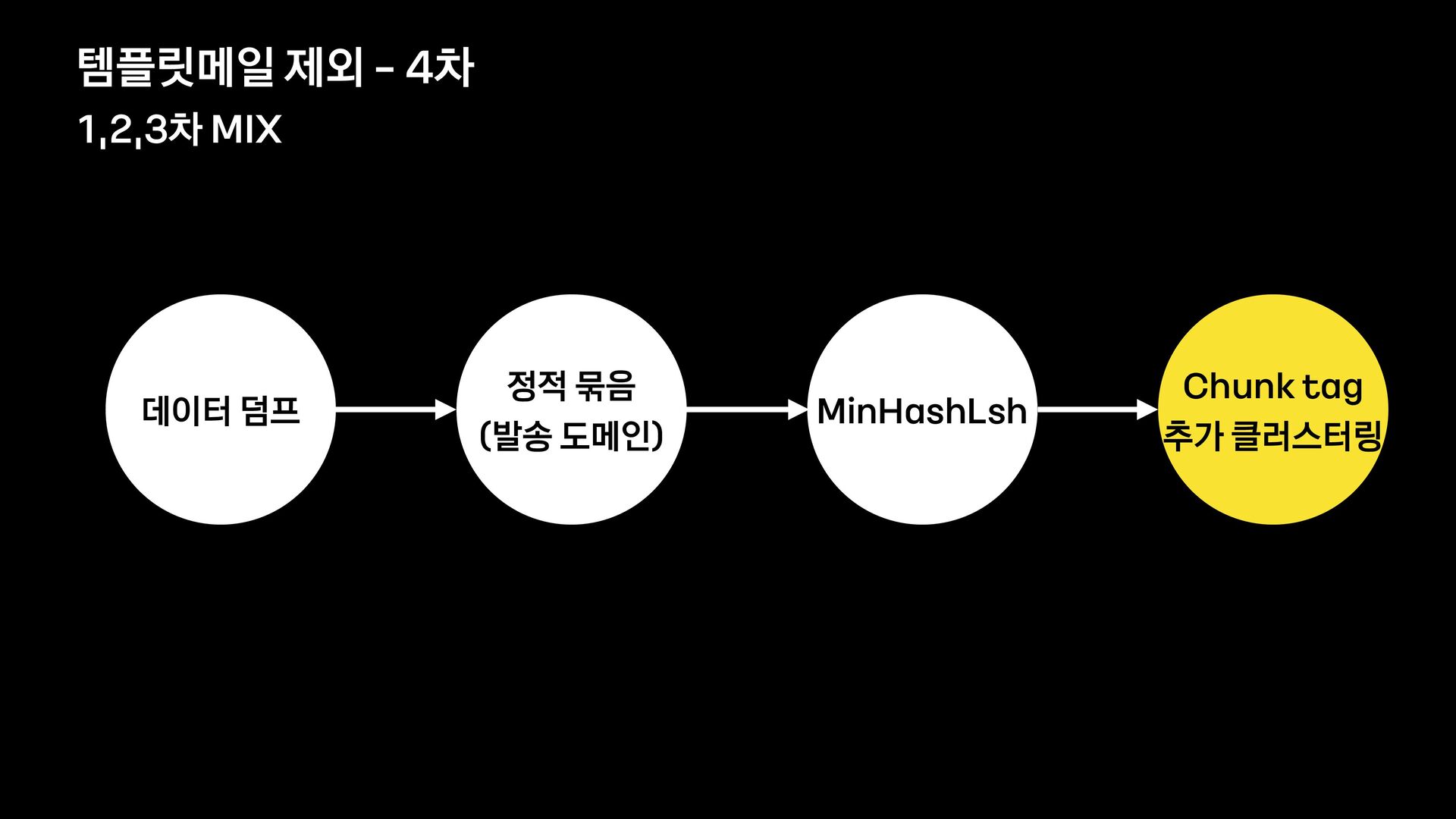
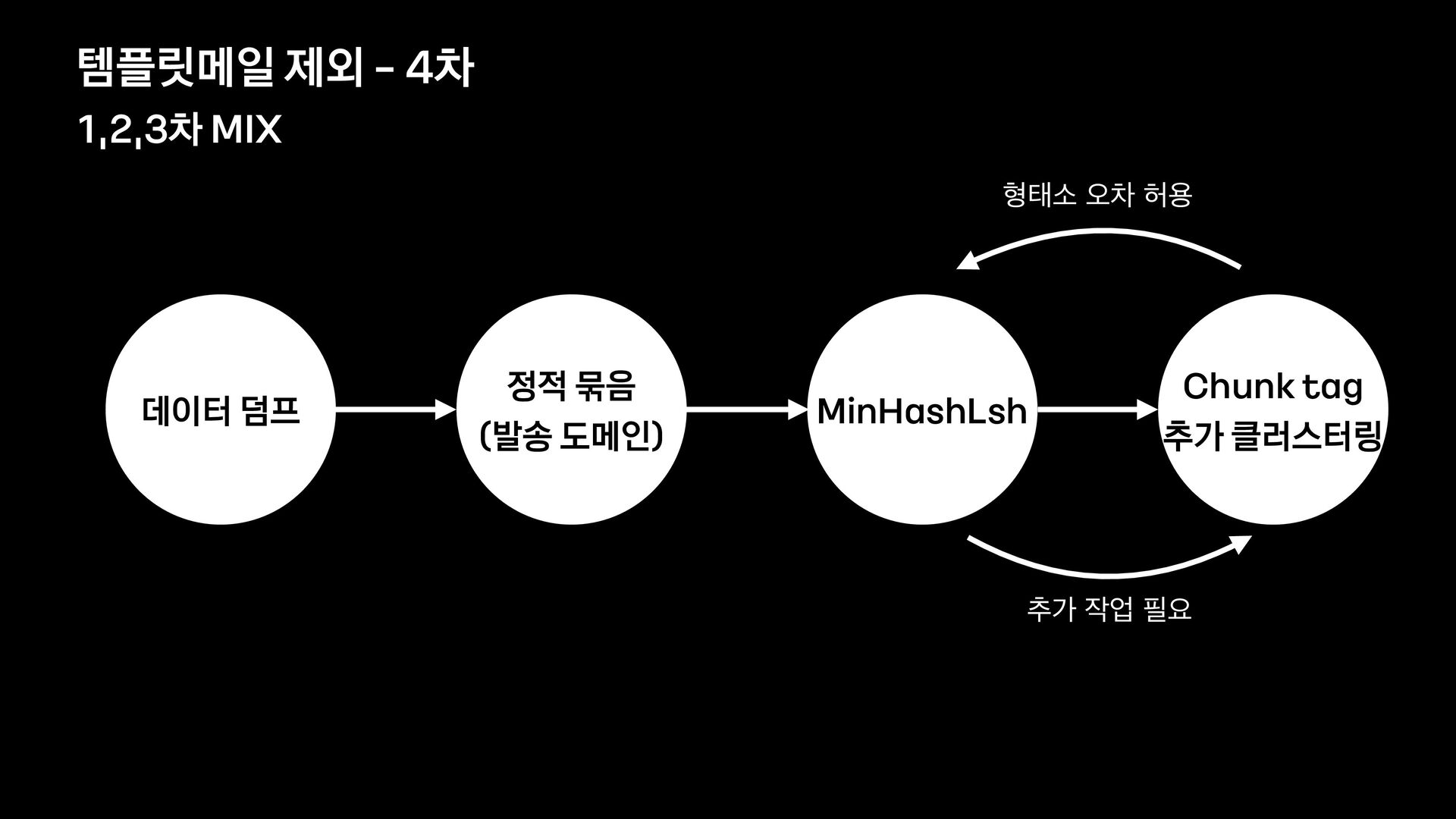
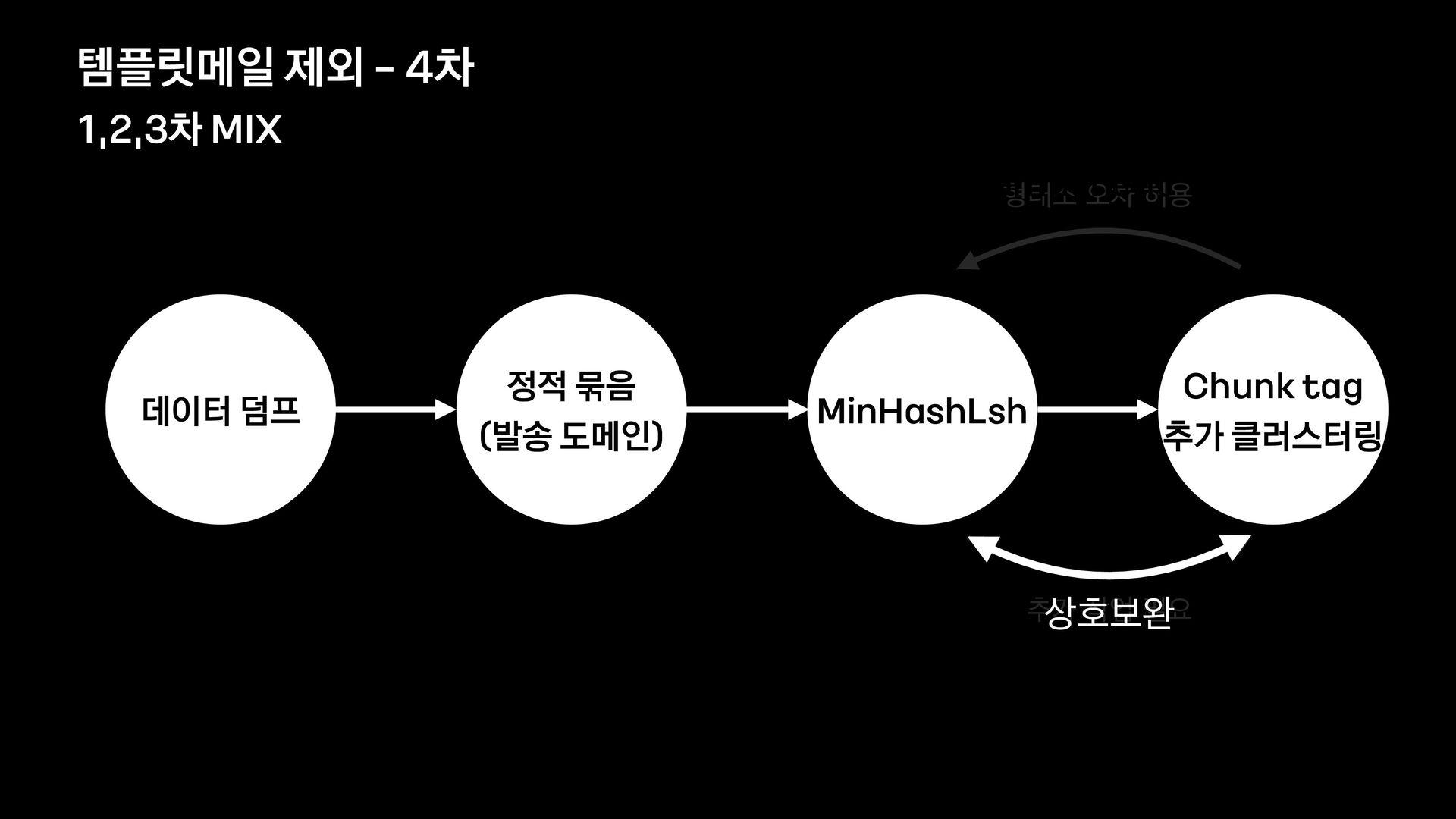
분석 문장 유사도 방법 제목에 가변 정보가 없는 메일을 묶어서 보여준다. 형태소 분석 후 명사구를 추출, 문장서 이를 제하고 비교하여 동일한 경우 묶어서 보여준다. 여러 문장들의 유사도를 계산, 유사한 메일들을 묶어서 보여준다. 한계 제목에 가변 정보가 있는 메일은 처리하기 어렵다. 형태소 분석 결과가 잘못된 경우 검수에 어려움이 있음 묶인 메일 중 템플릿 메일 외의 건이 존재한다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
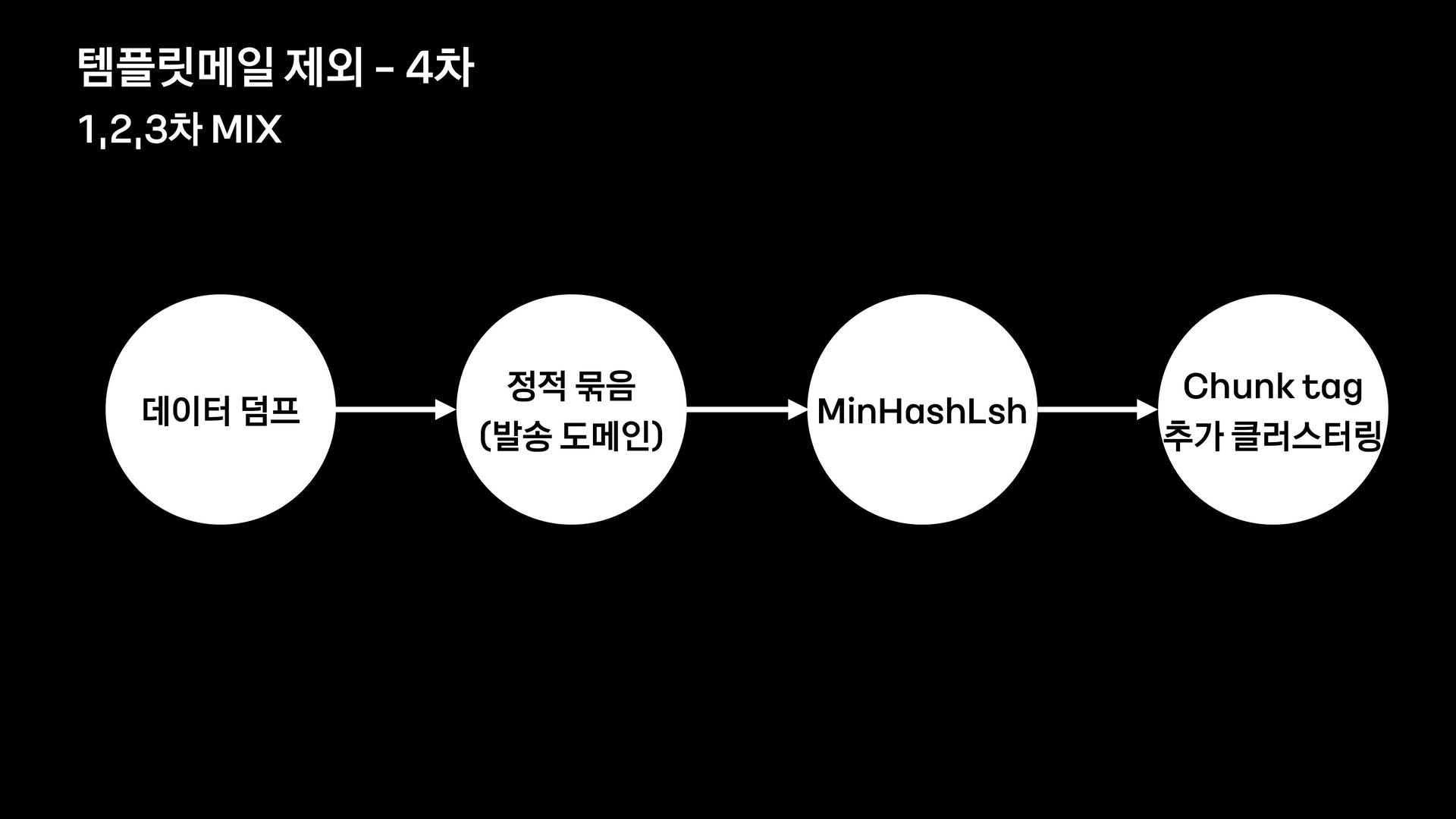
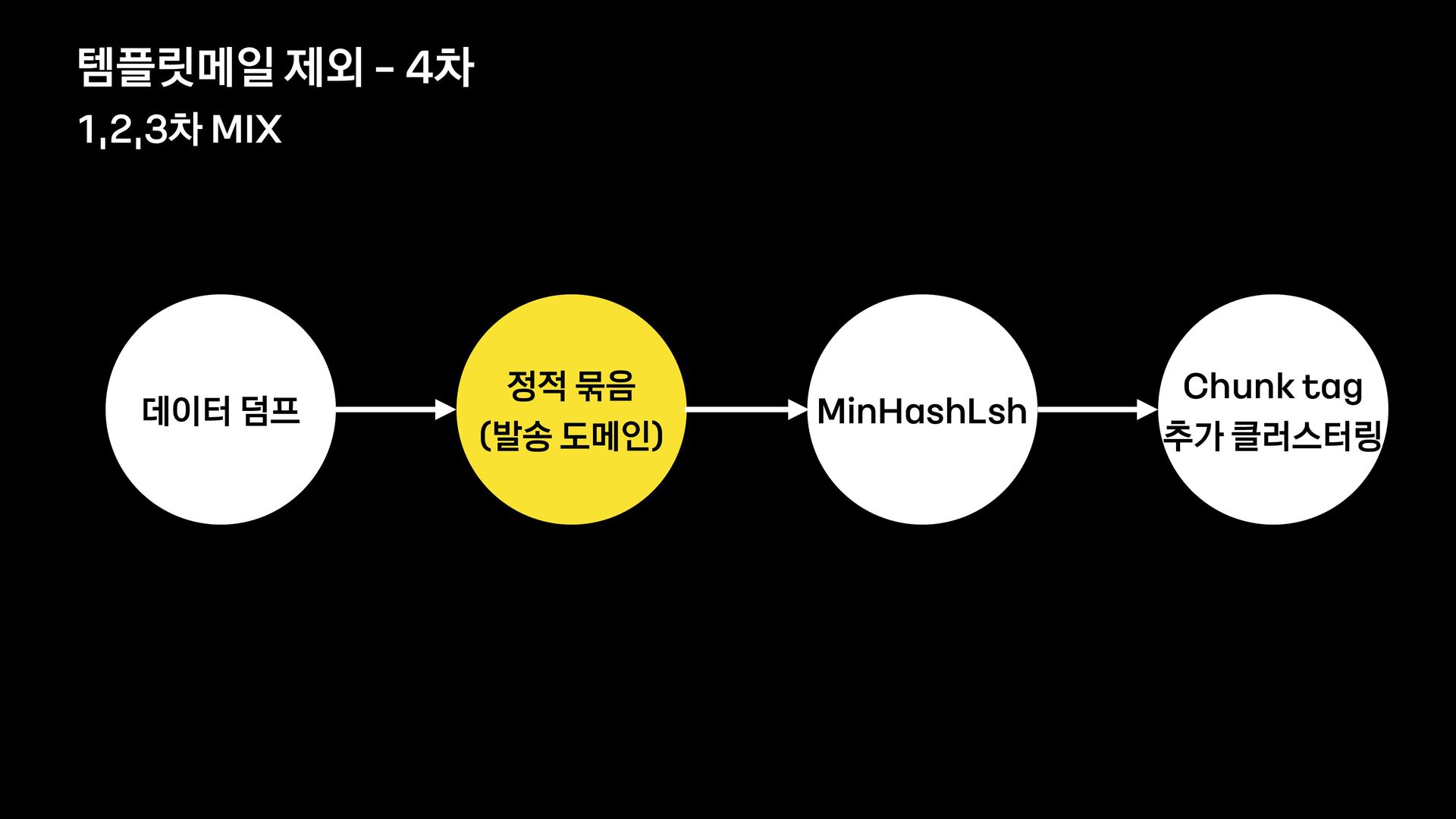
![Chunk tag 추가 클러스터링 [ X ] X ࣻૐ](https://files.speakerdeck.com/presentations/d35a09474718454f984784cf8597e159/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}