Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
新卒2年目がデータ分析API開発に挑戦【Stapy#88】/data-science-api-begginer
Search
松井宏典
December 16, 2022
Programming
0
520
新卒2年目がデータ分析API開発に挑戦【Stapy#88】/data-science-api-begginer
【Stapy#88】
2022/12/15に開催されたみんなのPython勉強会で発表した際の資料です。
https://startpython.connpass.com/event/266128/
松井宏典
December 16, 2022
Tweet
Share
Other Decks in Programming
See All in Programming
Rethinking UI building strategies @ SFI 2024
letelete
0
270
Behind VS Code Extensions for JavaScript / TypeScript Linnting and Formatting
unvalley
5
910
Azure OpenAI Serviceのプロンプトエンジニアリング入門
tomokusaba
3
690
Goのエラースタックトレースの歴史と今後
sonatard
7
1.3k
try! Swift Tokyo 初参加報告LT
hinakko2
0
220
Hanami and htmx
bkuhlmann
0
210
障害対応を起点としたもっといい開発と運用のサイクル作りのためにできること / Hatena Enginner Seminar #29
polamjag
0
140
『Railsオワコン』と言われる時代に、なぜブルーモ証券はRailsを選ぶのか
free_world21
0
130
⼤規模⾔語モデルの拡張(RAG)が 終わったかも知れない件について
nearme_tech
23
15k
今、知っておきたい! 生成AIエージェントの世界
elith
3
360
スクラムガイドのスプリントレトロスペクティブを改めて読みかえしてみた / Re-reading the Sprint Retrospective Section in the Scrum Guide
mackey0225
3
420
GitHub Actionsで泣かないためにやっておきたい設定 / Recommended GHA settings to avoid crying
pinkumohikan
3
530
Featured
See All Featured
5 minutes of I Can Smell Your CMS
philhawksworth
199
19k
Why Our Code Smells
bkeepers
PRO
331
56k
A designer walks into a library…
pauljervisheath
200
23k
Facilitating Awesome Meetings
lara
42
5.6k
No one is an island. Learnings from fostering a developers community.
thoeni
16
2.1k
The Power of CSS Pseudo Elements
geoffreycrofte
60
5k
Building Flexible Design Systems
yeseniaperezcruz
319
37k
Build your cross-platform service in a week with App Engine
jlugia
225
17k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
78
42k
Building Effective Engineering Teams - LeadDev
addyosmani
28
1.8k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
352
28k
Become a Pro
speakerdeck
PRO
11
4.5k
Transcript
新卒2年目がデータ分析APIの開発に挑戦した話 松井 宏典 株式会社スカラパートナーズ
目次 • 自己紹介 • 会社紹介 • 分析データAPIの実装内容 • AWSの話 •
クラスタリング • Pythonでの実装 • まとめなど 2/24
自己紹介 松井宏典(まつい こうすけ) 名前 Python:pandas, scikit-learn, Django aws:Lambda, S3 スキル 株式会社スカラパートナーズ(2年目)
所属 画像認識、データ分析、その他R&D 主に機械学習に関する案件を担当。 頑張ってできることを増やしています。 業務など 3/99
会社紹介 - 株式会社スカラパートナーズ - 社会課題解決を軸にした共創型のビジネス • 新規事業の立ち上げ • ワーケーション事業
開発部の開発実績 • コロナワクチン予約システム • エールラボえひめ • ナンバープレート検出モジュール • データ分析 4/24
目次 • 自己紹介 • 会社紹介 • 分析データAPIの実装内容 • AWSの話 •
クラスタリング • Pythonでの実装 • まとめなど 5/24
開発背景 BUSINESS-ALLIANCE株式会社と共同開発 アンケートデータの分析・可視化サービス 分析処理を担うAPIの開発を担当 2つのAPIを開発 • クラスタリング • テキストマイニング
6/24 引用:BUSSINESS-ALLIANCE「事業概要」 (https://business-alliance.co.jp/service/)
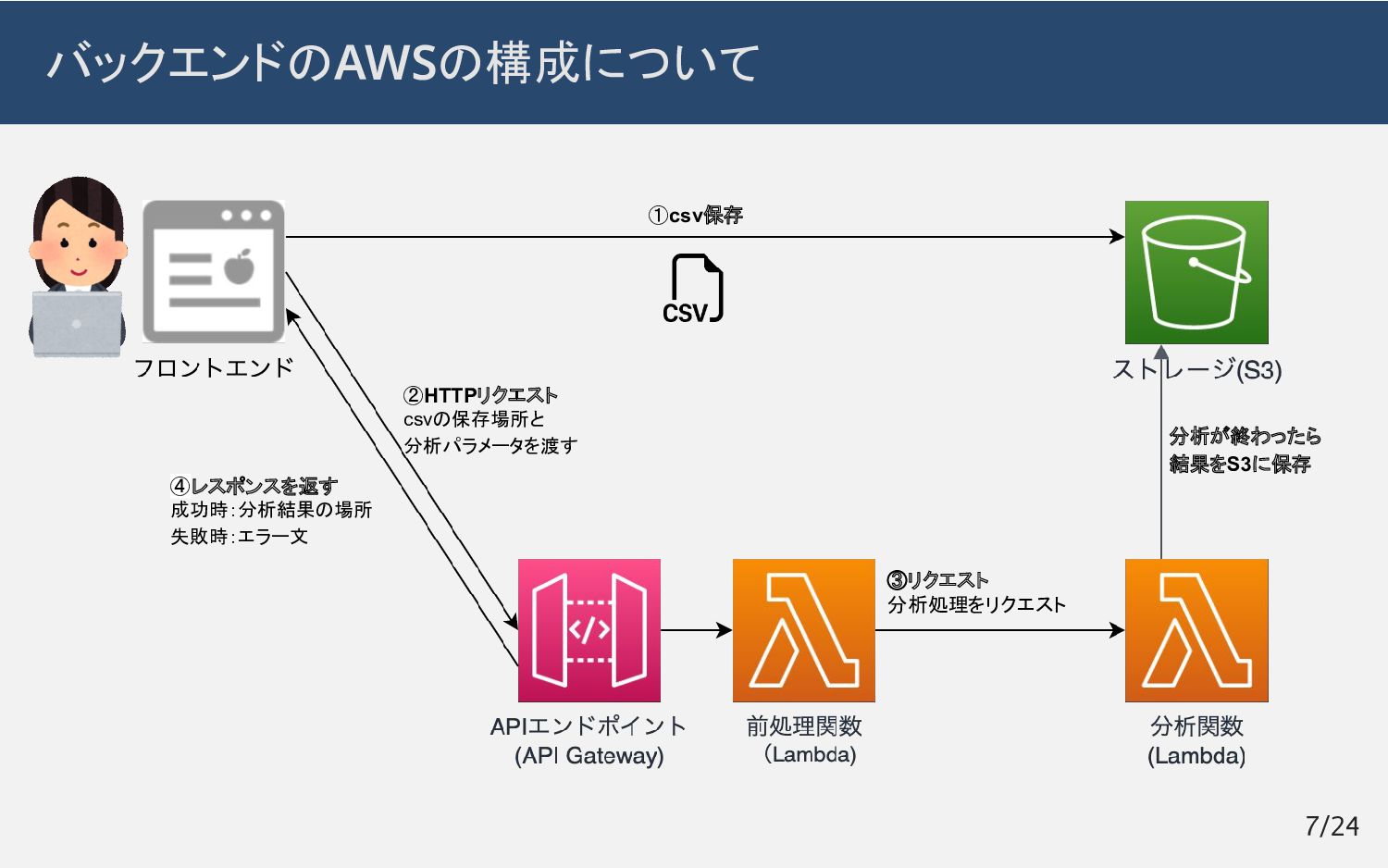
バックエンドのAWSの構成について ①csv保存 ②HTTPリクエスト csvの保存場所と 分析パラメータを渡す ③リクエスト 分析処理をリクエスト ④レスポンスを返す 成功時:分析結果の場所 失敗時:エラー文
分析が終わったら 結果をS3に保存 7/24
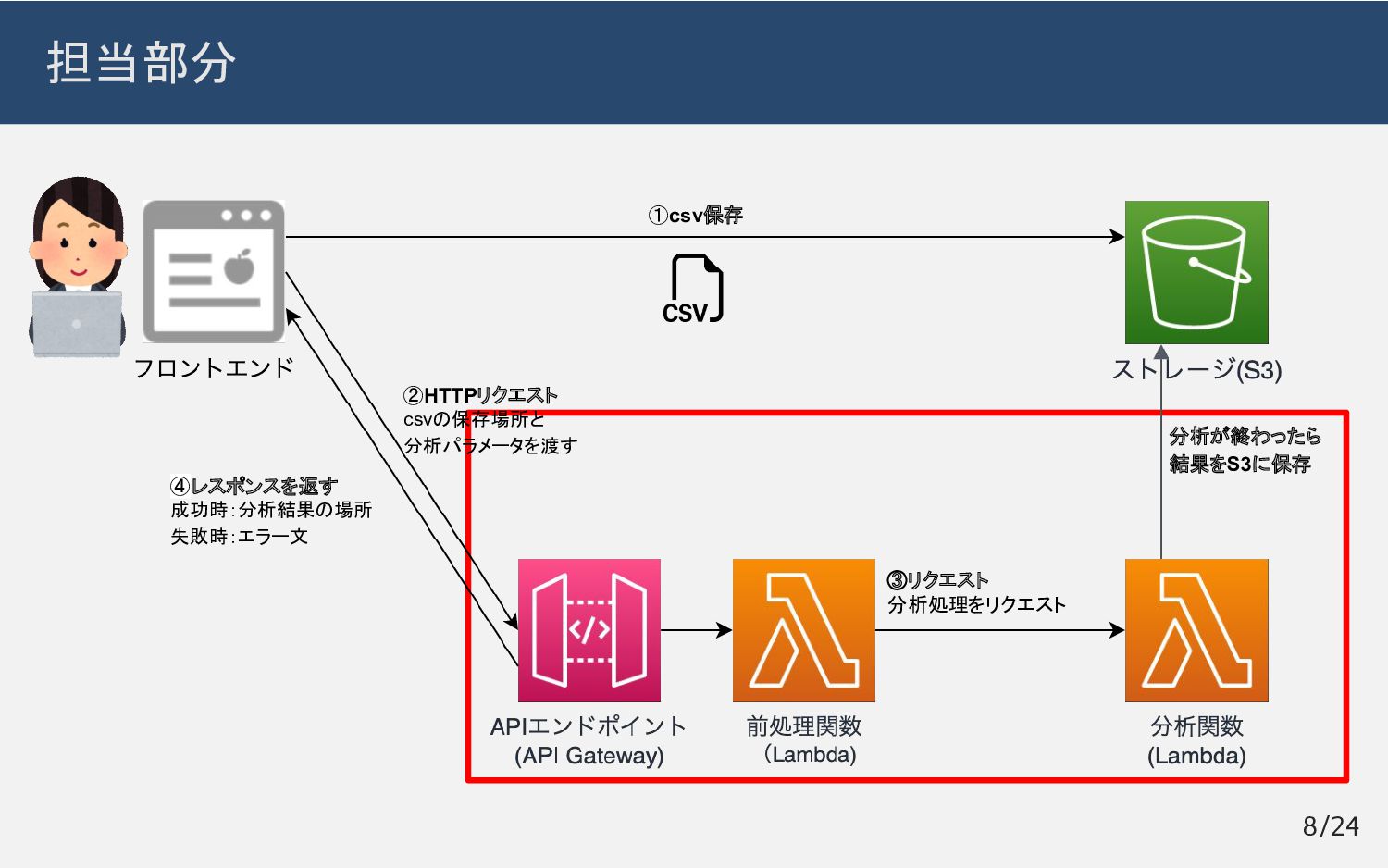
担当部分 ①csv保存 ②HTTPリクエスト csvの保存場所と 分析パラメータを渡す ③リクエスト 分析処理をリクエスト ④レスポンスを返す 成功時:分析結果の場所 失敗時:エラー文
分析が終わったら 結果をS3に保存 8/24
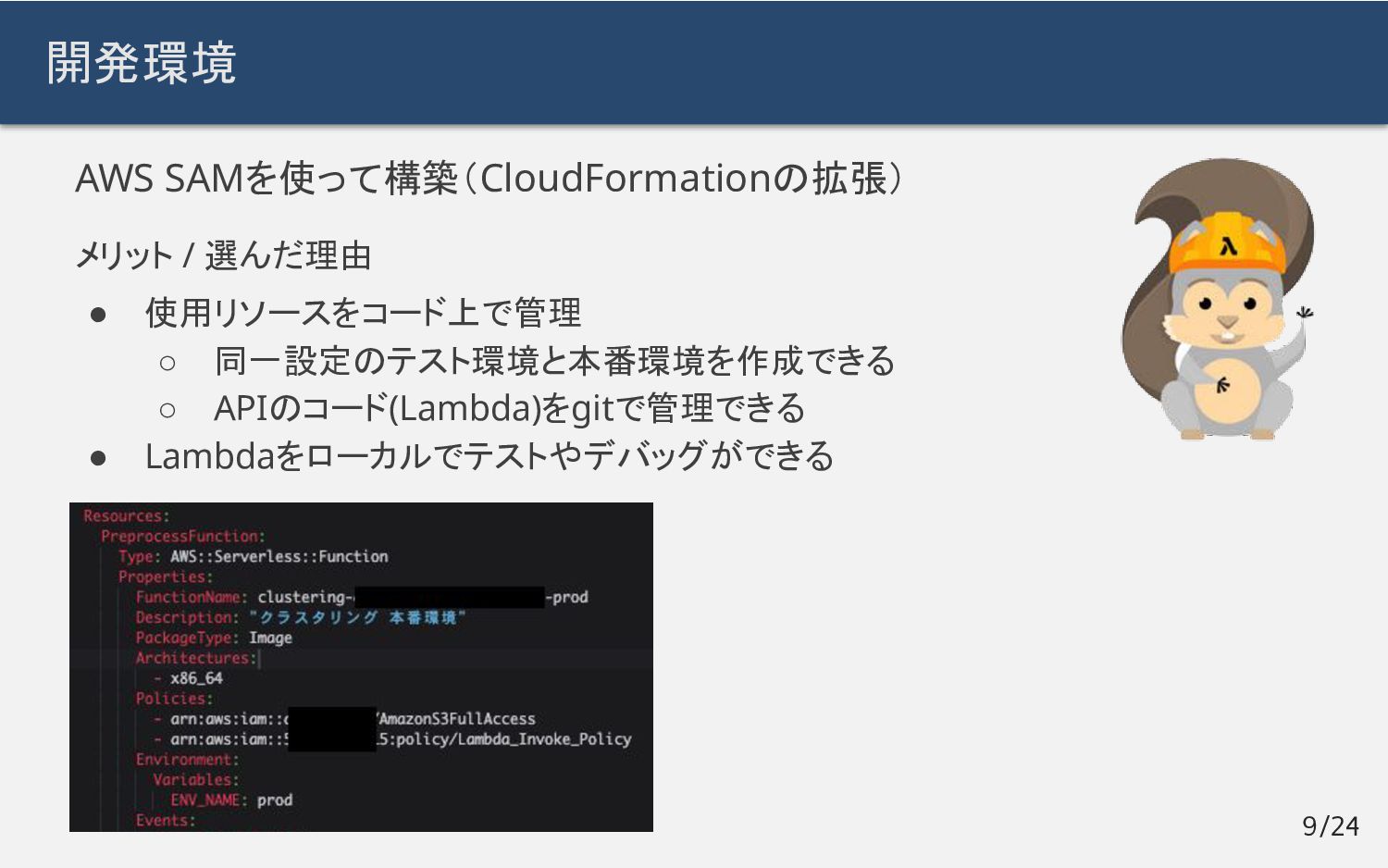
AWS SAMを使って構築(CloudFormationの拡張) メリット / 選んだ理由 • 使用リソースをコード上で管理 ◦ 同一設定のテスト環境と本番環境を作成できる
◦ APIのコード(Lambda)をgitで管理できる • Lambdaをローカルでテストやデバッグができる 開発環境 9/24
目次 • 自己紹介 • 会社紹介 • 分析データAPIの実装内容 • AWSの話 •
クラスタリング • Pythonでの実装 • まとめなど 10/24
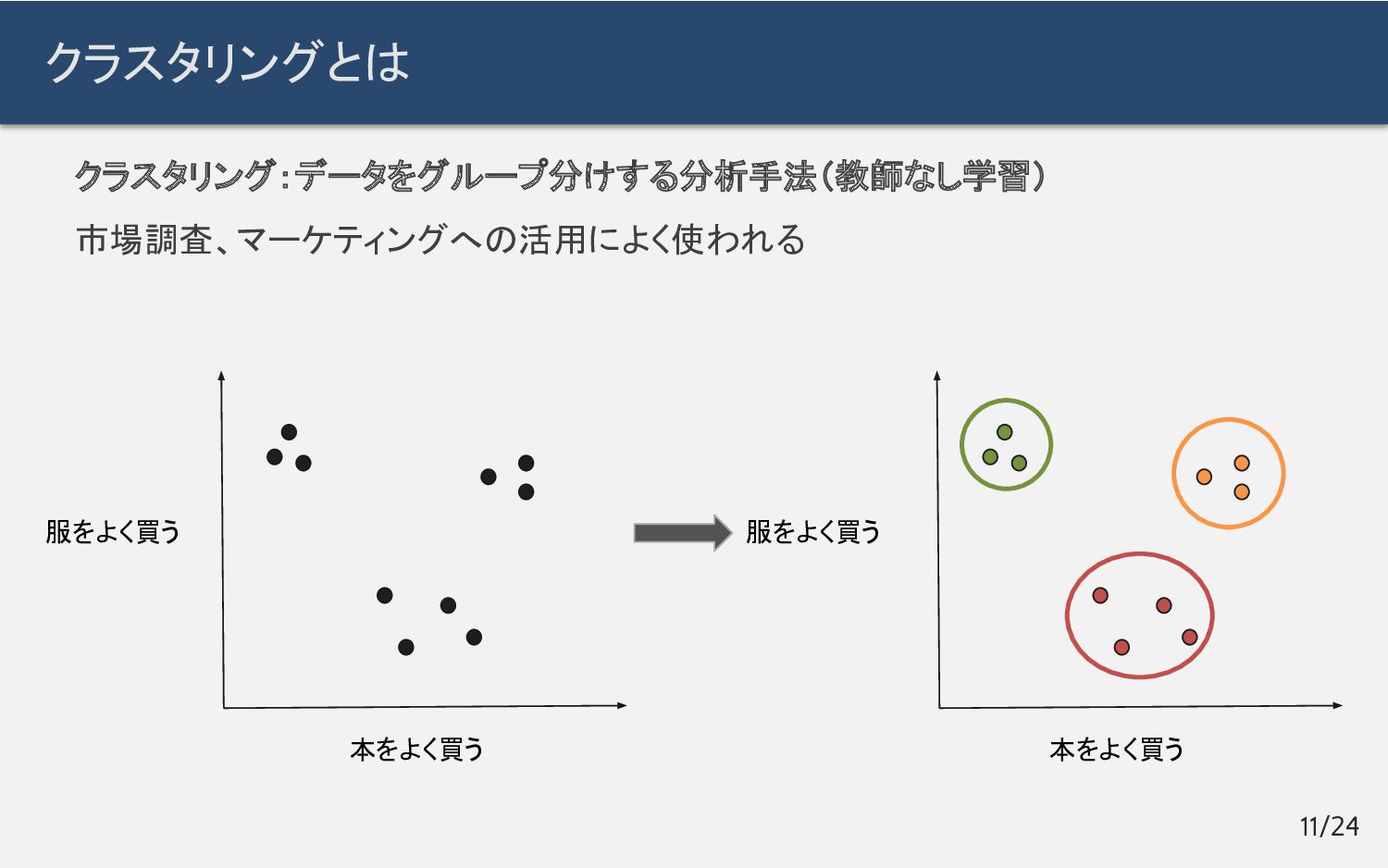
クラスタリングとは 11/24 本をよく買う 服をよく買う 本をよく買う 服をよく買う クラスタリング:データをグループ分けする分析手法(教師なし学習) 市場調査、マーケティングへの活用によく使われる
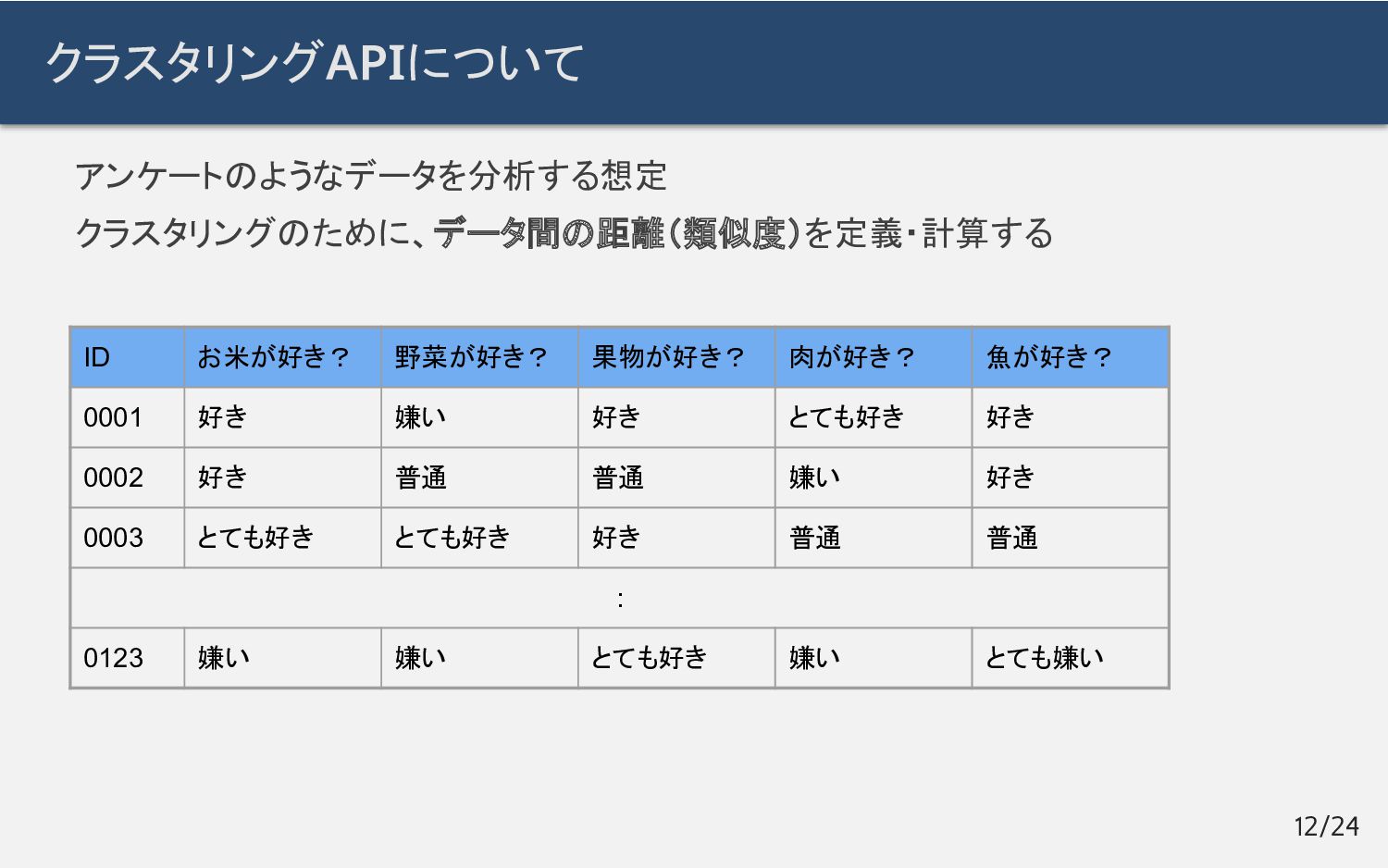
クラスタリングAPIについて アンケートのようなデータを分析する想定 クラスタリングのために、データ間の距離(類似度)を定義・計算する 12/24 ID お米が好き? 野菜が好き? 果物が好き? 肉が好き?
魚が好き? 0001 好き 嫌い 好き とても好き 好き 0002 好き 普通 普通 嫌い 好き 0003 とても好き とても好き 好き 普通 普通 : 0123 嫌い 嫌い とても好き 嫌い とても嫌い
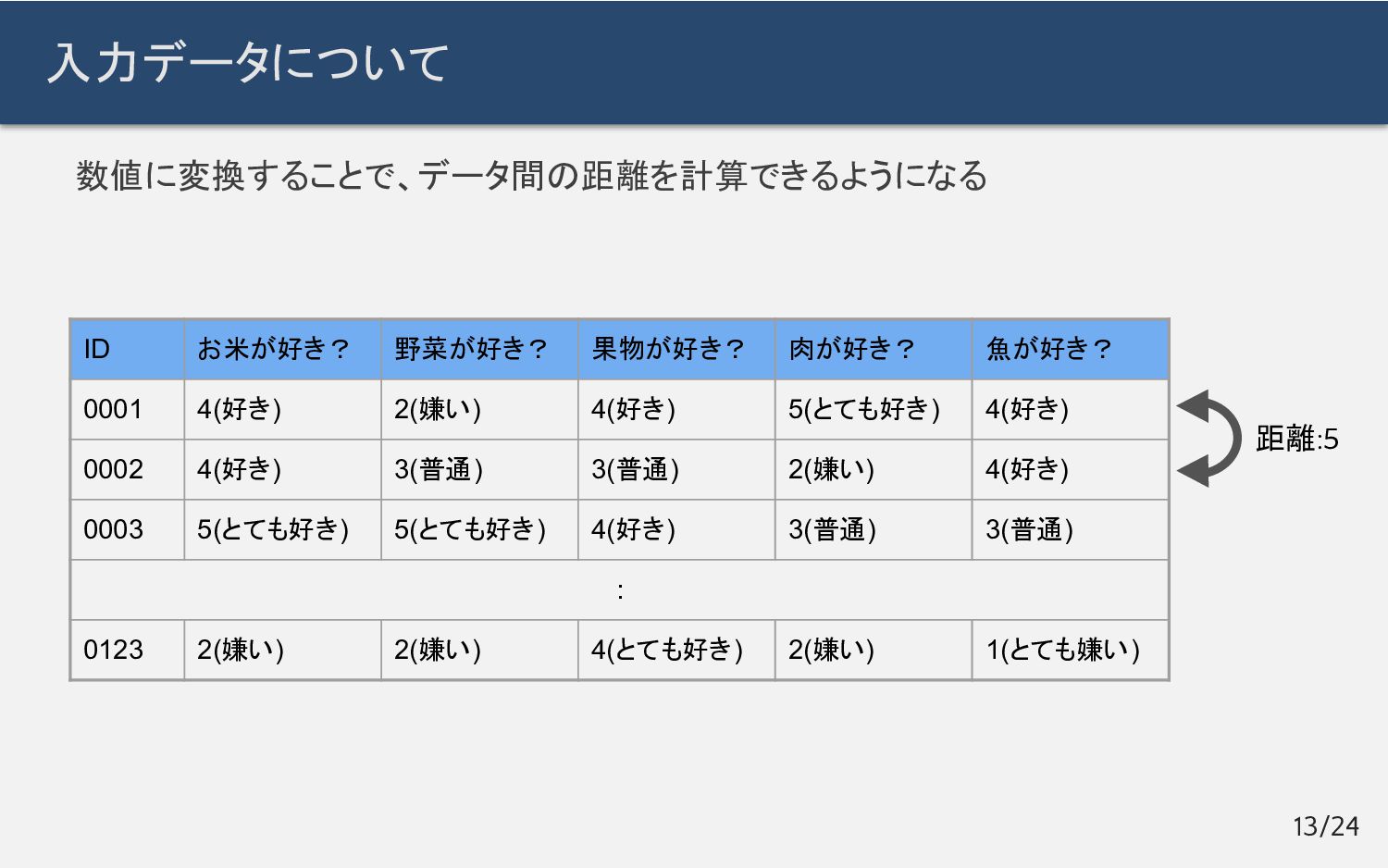
数値に変換することで、データ間の距離を計算できるようになる 入力データについて 13/24 ID お米が好き? 野菜が好き? 果物が好き? 肉が好き? 魚が好き?
0001 4(好き) 2(嫌い) 4(好き) 5(とても好き) 4(好き) 0002 4(好き) 3(普通) 3(普通) 2(嫌い) 4(好き) 0003 5(とても好き) 5(とても好き) 4(好き) 3(普通) 3(普通) : 0123 2(嫌い) 2(嫌い) 4(とても好き) 2(嫌い) 1(とても嫌い) 距離:5
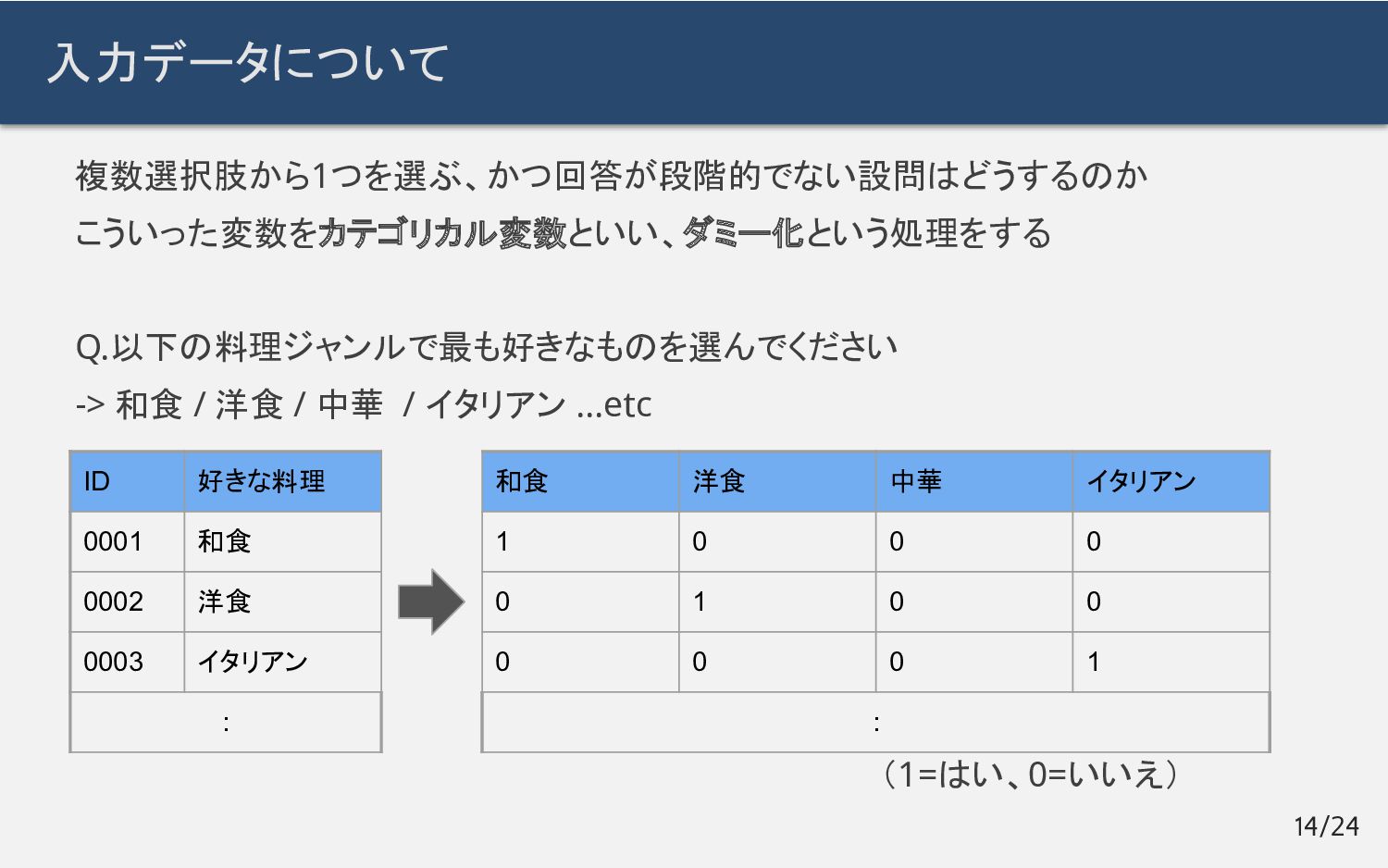
入力データについて 複数選択肢から1つを選ぶ、かつ回答が段階的でない設問はどうするのか こういった変数をカテゴリカル変数といい、ダミー化という処理をする Q.以下の料理ジャンルで最も好きなものを選んでください -> 和食 / 洋食 /
中華 / イタリアン …etc 14/24 ID 好きな料理 0001 和食 0002 洋食 0003 イタリアン : 和食 洋食 中華 イタリアン 1 0 0 0 0 1 0 0 0 0 0 1 : (1=はい、0=いいえ)
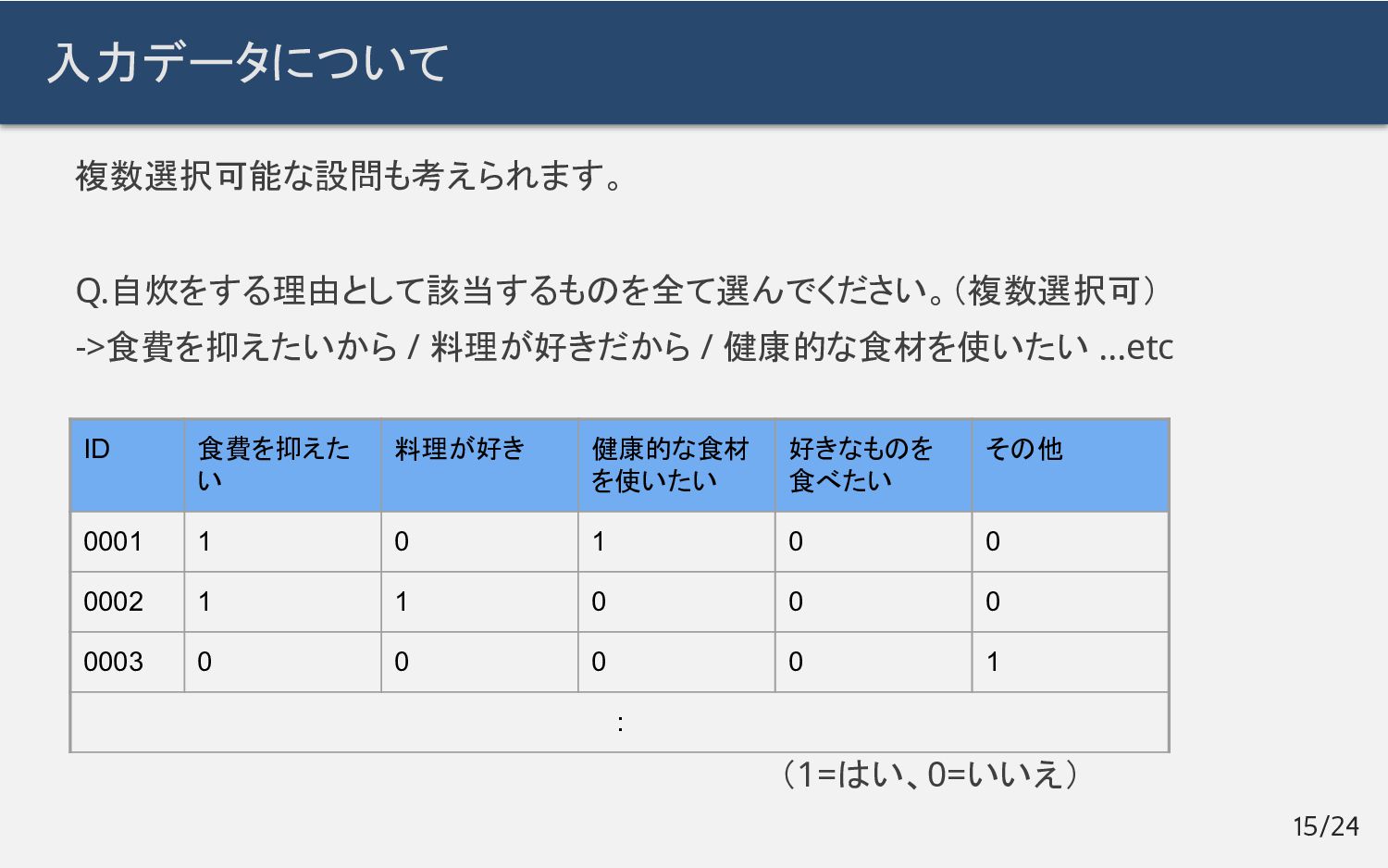
入力データについて 複数選択可能な設問も考えられます。 Q.自炊をする理由として該当するものを全て選んでください。(複数選択可) ->食費を抑えたいから / 料理が好きだから / 健康的な食材を使いたい
…etc 15/24 ID 食費を抑えた い 料理が好き 健康的な食材 を使いたい 好きなものを 食べたい その他 0001 1 0 1 0 0 0002 1 1 0 0 0 0003 0 0 0 0 1 : (1=はい、0=いいえ)
目次 • 自己紹介 • 会社紹介 • 分析データAPIの実装内容 • AWSの話 •
クラスタリング • Pythonでの実装 • まとめなど 16/24
• pandas ◦ データ解析を容易にするライブラリ ◦ DataFrame型は、二次元のテーブルデータを表す ◦ 数表および時系列データの操作が簡単 • scikit-learn
◦ オープンソースの機械学習ライブラリ ◦ 今回はクラスタリングで使用 ◦ 他にも、分類、回帰などのアルゴリズムも使える • boto3 ◦ AWSをPythonから操作するためのライブラリ ◦ 今回は、Lambda上からS3にアクセスするのに使用 主な使用ライブラリ 17/24
クラスタリングのコード例 18/24
• フロント側からパラメータを受け取る ◦ クラスタリングする数など • 解析結果を可視化できるような出力 ◦ クロス集計 ◦ レーダーチャート
• テキストマイニングのAPIを別で作成 ◦ 自由回答のあるアンケートを想定 ◦ 単語集計、共起ネットワークの生成 その他の実装内容 19/24
目次 • 自己紹介 • 会社紹介 • 分析データAPIの実装内容 • AWSの話 •
クラスタリング • Pythonでの実装 • まとめなど 20/24
距離定義の話 • 距離をどう定義するのが”一般的か”で悩んだ • 結論、細かい調整はデータや調査の目的次第 ◦ 質量混在データはgower距離 ◦ 標準化(平均0, 分散1)して相対的に距離計算
苦労したこと 21/24 回答者 肉が好き? 野菜が好き? 好きな料理 A 4 3 中華 B 4 5 中華 C 4 3 イタリアン BさんとCさんのどちらが Aさんに近い(似ている)か? カテゴリ変数と数値変数の 距離をどう比べるのか?
苦労したこと subprocessをLambda上で使用した際のメモリエラー • テキストマイニングAPIで、コマンド実行するためにsubprocessを使っていた • 連続でAPIを叩くとメモリ不足のエラー ◦ なぜか再現性がなく、とりあえずメモリ拡張したけど再発した •
subprocess.run(‘ls’)みたいなコマンドでも同様のバグ発生 ◦ コマンドの内容ではなく、subprocessの挙動の問題 • subprocessが子プロセスをコピーして生成する、みたいなのがエラーの原因? ◦ 加えて、Lambdaのライフサイクルがブラックボックス ◦ メモリ容量を監視することで、ちゃんとエラー発生を追えるようになった • 結局メモリ解放する処理を加えたら直った ◦ Lambdaでsubprocessは非推奨とのことだった 22/24
まとめ • データ分析の知識がかなりついた ◦ 適した手法、適していない手法などは知識が重要 ◦ 基礎的な数学知識はあって良かった • awsのサーバーレスアプリケーションの知識もついた ◦
Lambda, SAMなど • 保守性などに難ありかも ◦ テスト設計をあまりせずに開発をしていた ◦ 1人で書いていて可読性を犠牲にするときもしばしば.... 23/24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}