Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
アラートだけでここまで分析できるの!?AI Agentで切り開くアラート対応の新時代
Search
nutslove
November 18, 2025
800
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
アラートだけでここまで分析できるの!?AI Agentで切り開くアラート対応の新時代
Cloud Native Days Winter 2025の登壇資料です。
よろしくお願いします!
nutslove
November 18, 2025
More Decks by nutslove
See All by nutslove
AI Gateway入門 - マルチLLM時代の交通整理 -
nutslove
1
57
Kubernetes(EKS)ネットワーク入門
nutslove
1
560
Context Engineeringの取り組み
nutslove
0
620
LangGraphで作ったアラート原因分析エージェントについて
nutslove
0
520
OpenTelemetry(ADOT)による自動計装
nutslove
1
340
MCP入門
nutslove
2
210
GitOpsで始めるクラウドリソース管理
nutslove
1
190
Thanos入門(Receiver構成)
nutslove
0
190
OpenTelemetryによるベンダーニュートラルな監視設定
nutslove
5
550
Featured
See All Featured
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
A Tale of Four Properties
chriscoyier
163
24k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Building an army of robots
kneath
306
46k
Faster Mobile Websites
deanohume
310
32k
Six Lessons from altMBA
skipperchong
29
4.3k
Everyday Curiosity
cassininazir
0
250
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Transcript
アラートだけでここまで分析できるの? AI Agentで切り開くアラート対応の新時代 2025/11/18 李俊起
自己紹介 2025/11/18 2 名前 李 俊起(イ ジュンギ) / Joonki Lee
所属 KINTOテクノロジーズ株式会社 Platform Group / Platform Engineer 関心分野 Observability Kubernetes 生成AI
話す内容 2025/11/18 3 • アラート原因分析AI Agent導入背景 • アーキテクチャ & 処理フロー
• Agentの機能追加/改善 • 実際の分析結果例 • 今後について • まとめ
2025/11/18 4 アラート原因分析AI Agent導入背景
アラート対応のつらさ 2025/11/18 5 良く分からない アラートが出てる けど何をどこから 調べればいいの? ナレッジが俗人化して いて対応できる人が 限られている
原因分析に時間がかかり、 対応/復旧までの時間 (MTTR)が長くなる
そこでAI Agentの出番 2025/11/18 6 複雑で状況に応じて柔軟な対応が必要な、 定型化が難しい作業にはAI Agentが適している
どういうAgentを作るか(最初の目標) 2025/11/18 7 • NewRelicからのアラート発報をトリガーに、原因分析を行い、 暫定対応のためのAWS CLIコマンドの提案から実行まで できるもの ➢ コマンドの実行は
human-in-the-loop で人が介入 • アラートの通知から原因分析結果の通知、コマンド実行まで、 すべてSlack上で行えるようにする(ChatOps)
AI Agentフレームワークの選定 2025/11/18 8 • 今はADKやOpenAI Agents SDKなど、様々なフレームワークが あるが、当時(2025年1月)はあまり選択肢がなく、 Bedrock
AgentsとLangGraphを比較検討し、 以下の理由でLangGraphを採用 ➢ 簡単にReact Agentが作れる ➢ 細かなフローの制御が可能 ➢ LangSmithやLangfuseへのトレースの連携が可能
2025/11/18 9 アーキテクチャ & 処理フロー
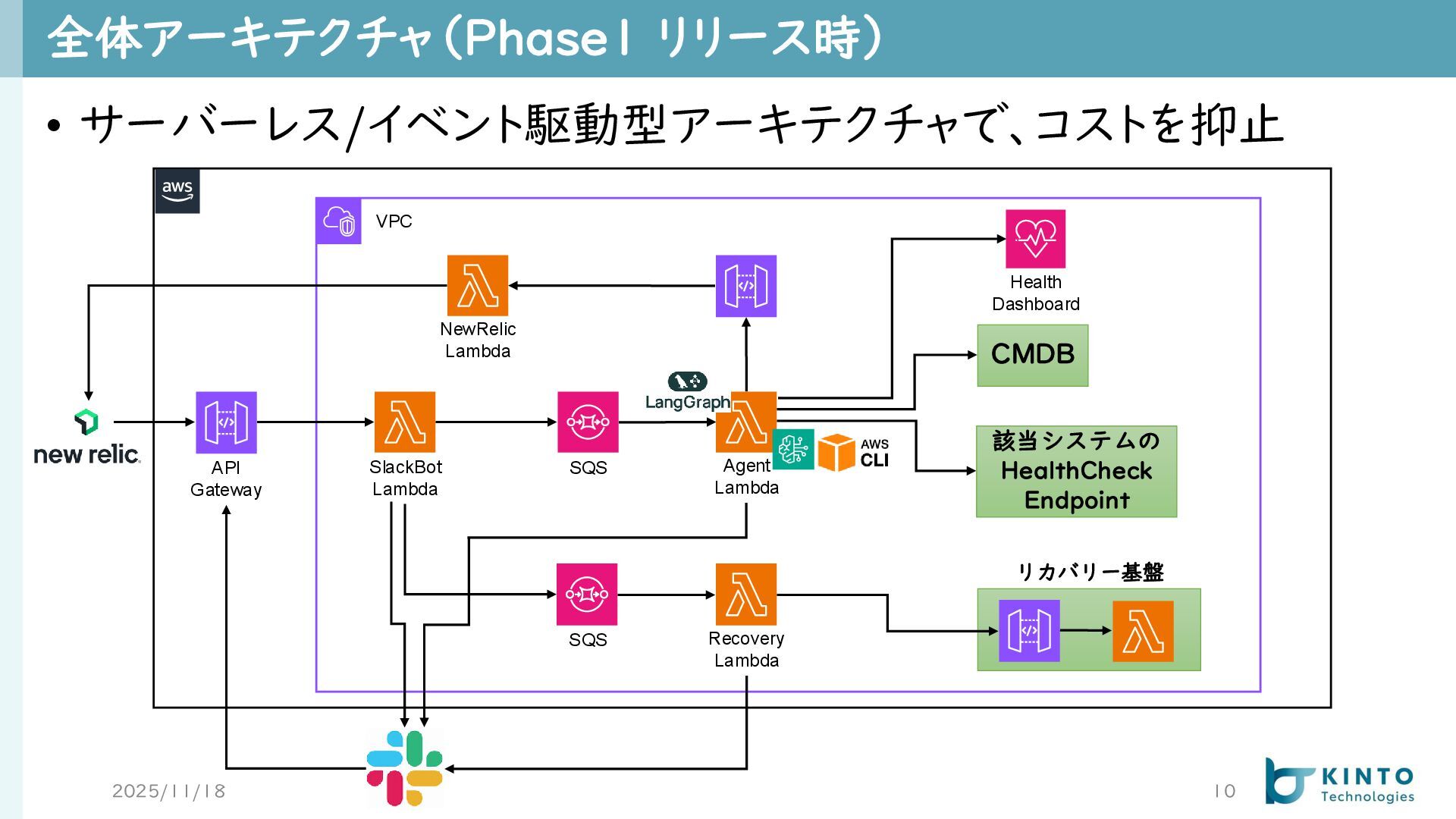
全体アーキテクチャ(Phase1 リリース時) 2025/11/18 10 • サーバーレス/イベント駆動型アーキテクチャで、コストを抑止 VPC API Gateway SlackBot
Lambda SQS NewRelic Lambda CMDB Health Dashboard リカバリー基盤 SQS Recovery Lambda Agent Lambda 該当システムの HealthCheck Endpoint
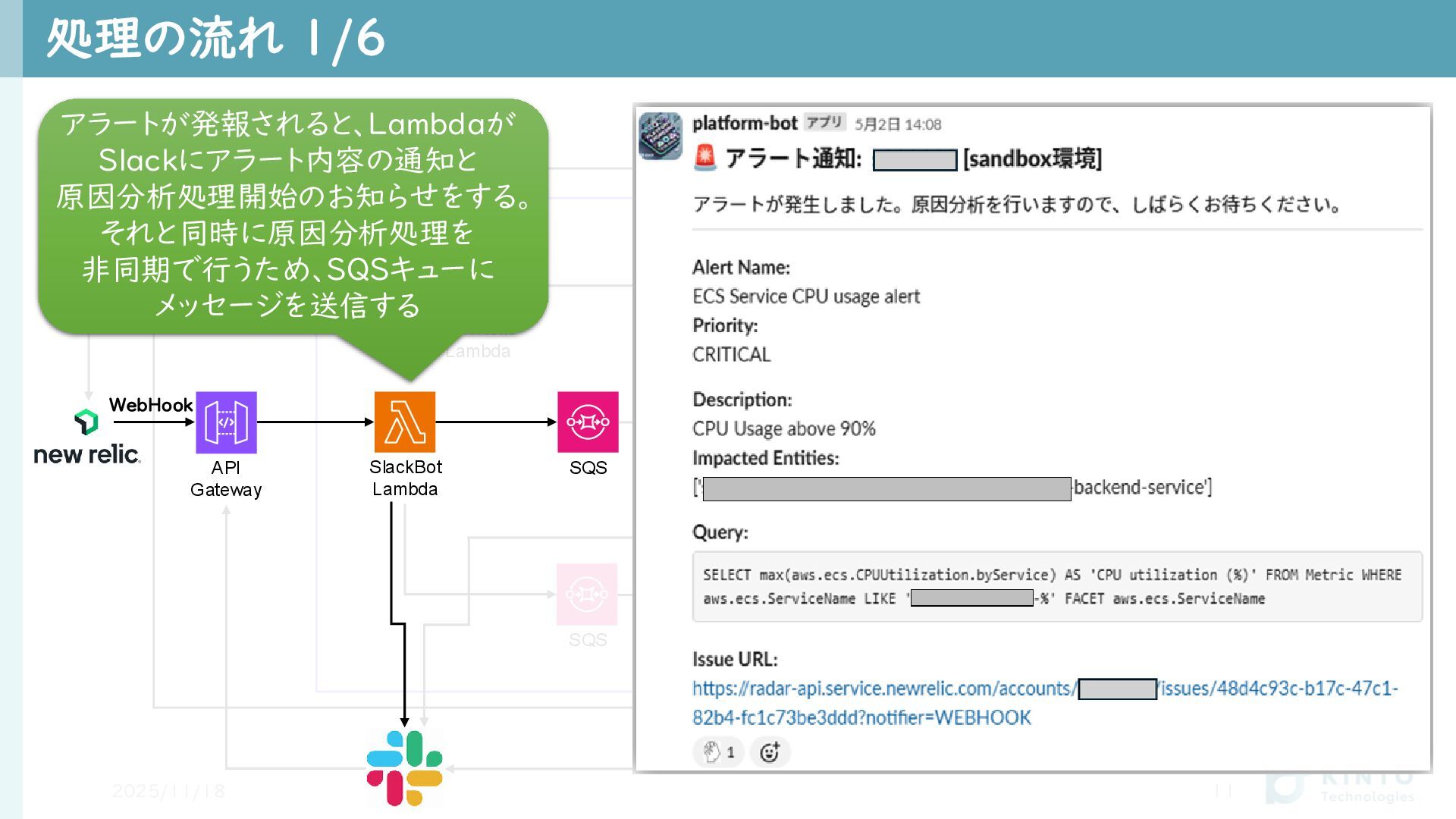
処理の流れ 1/6 2025/11/18 11 VPC NewRelic Lambda CMDB Health Dashboard
リカバリー基盤 SQS Recovery Lambda Agent Lambda 該当システムの HealthCheck Endpoint API Gateway SlackBot Lambda SQS アラートが発報されると、Lambdaが Slackにアラート内容の通知と 原因分析処理開始のお知らせをする。 それと同時に原因分析処理を 非同期で行うため、SQSキューに メッセージを送信する WebHook
※補足: なぜo11yツールのSlack通知を使わないのか 2025/11/18 12 • o11yツールからSlack Integrationで、直接Slackに通知し、 Slack投稿をトリガーに、処理を開始する方法もある • しかし、通知内容が1つのブロックに非構造化(plain
text)データ に入っているため、データ抽出が困難 • Webhookの方がデータ整形とSlackへの通知の手間は増えるが、 構造化(json)データで連携されるため、必要なデータの抽出が 容易なので、Webhook方式を選択
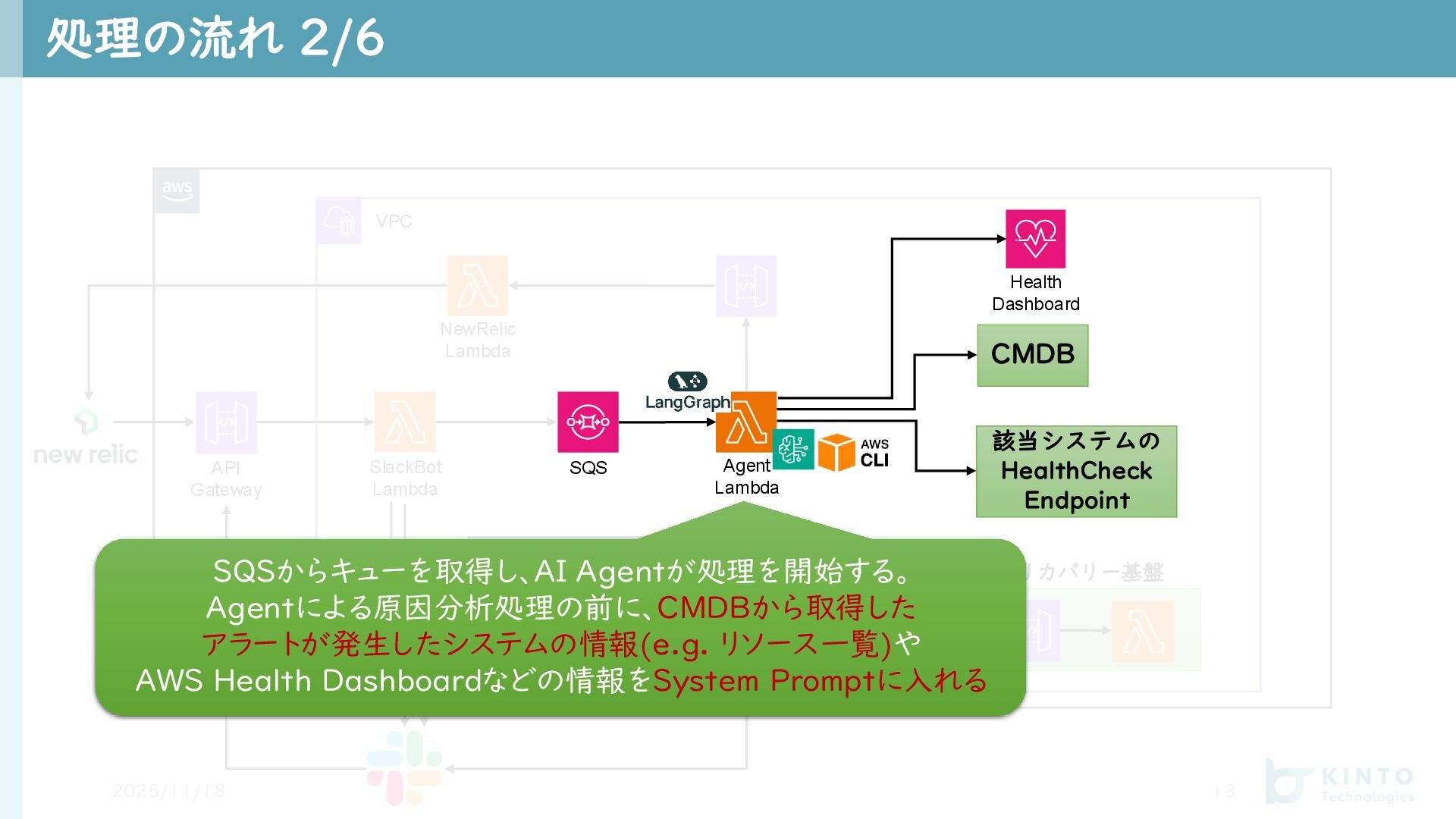
API Gateway SlackBot Lambda 処理の流れ 2/6 2025/11/18 13 VPC NewRelic
Lambda リカバリー基盤 SQS Recovery Lambda CMDB Health Dashboard Agent Lambda 該当システムの HealthCheck Endpoint SQSからキューを取得し、AI Agentが処理を開始する。 Agentによる原因分析処理の前に、CMDBから取得した アラートが発生したシステムの情報(e.g. リソース一覧)や AWS Health Dashboardなどの情報をSystem Promptに入れる SQS
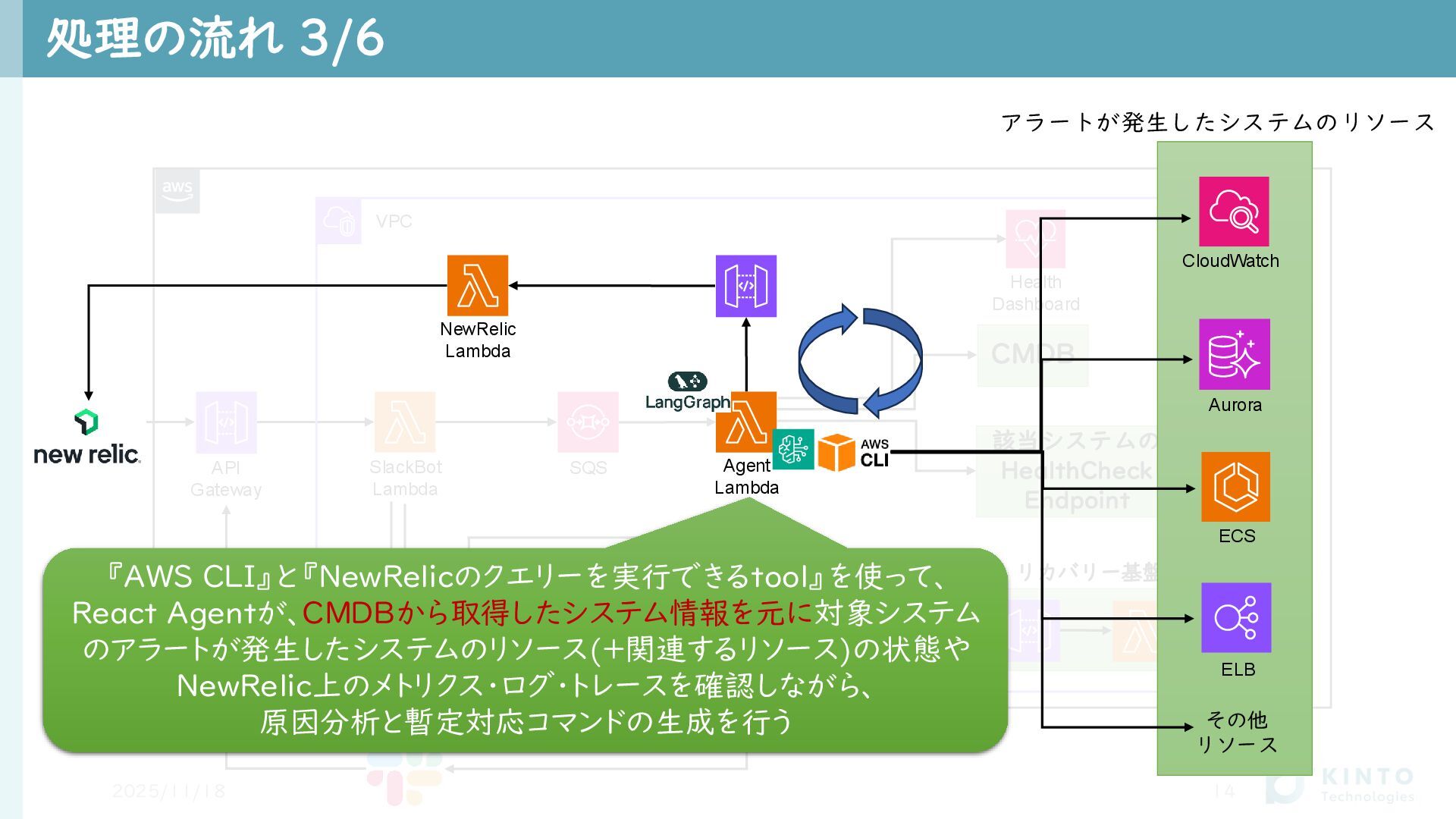
CMDB Health Dashboard 該当システムの HealthCheck Endpoint SQS API Gateway SlackBot
Lambda 処理の流れ 3/6 2025/11/18 14 VPC リカバリー基盤 SQS Recovery Lambda Agent Lambda NewRelic Lambda CloudWatch Aurora ECS ELB その他 リソース アラートが発生したシステムのリソース 『AWS CLI』と『NewRelicのクエリーを実行できるtool』を使って、 React Agentが、CMDBから取得したシステム情報を元に対象システム のアラートが発生したシステムのリソース(+関連するリソース)の状態や NewRelic上のメトリクス・ログ・トレースを確認しながら、 原因分析と暫定対応コマンドの生成を行う
NewRelic Lambda CMDB Health Dashboard 該当システムの HealthCheck Endpoint SQS API
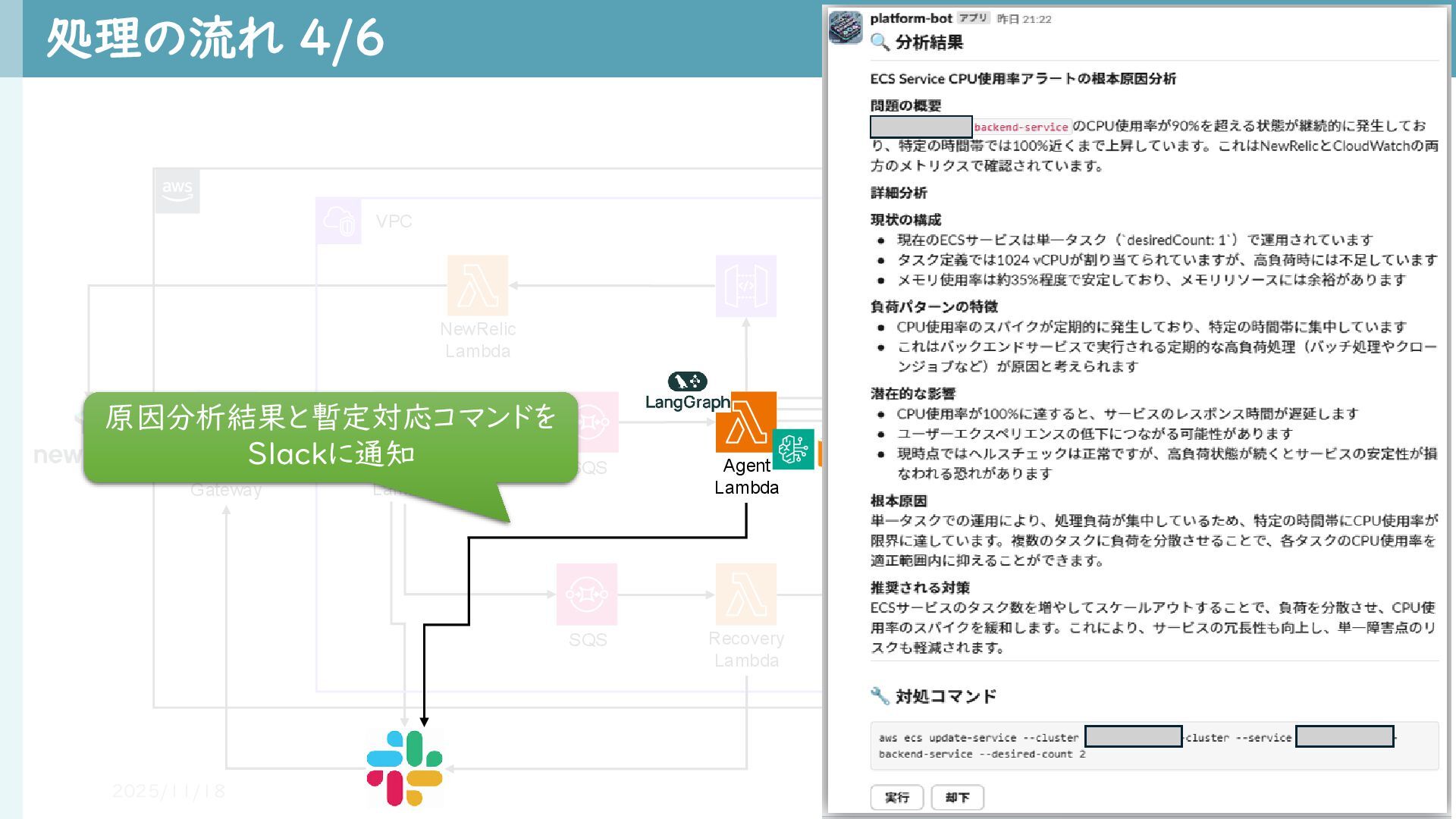
Gateway SlackBot Lambda 処理の流れ 4/6 2025/11/18 15 VPC リカバリー基盤 SQS Recovery Lambda Agent Lambda 原因分析結果と暫定対応コマンドを Slackに通知
Agent Lambda NewRelic Lambda CMDB Health Dashboard 該当システムの HealthCheck Endpoint
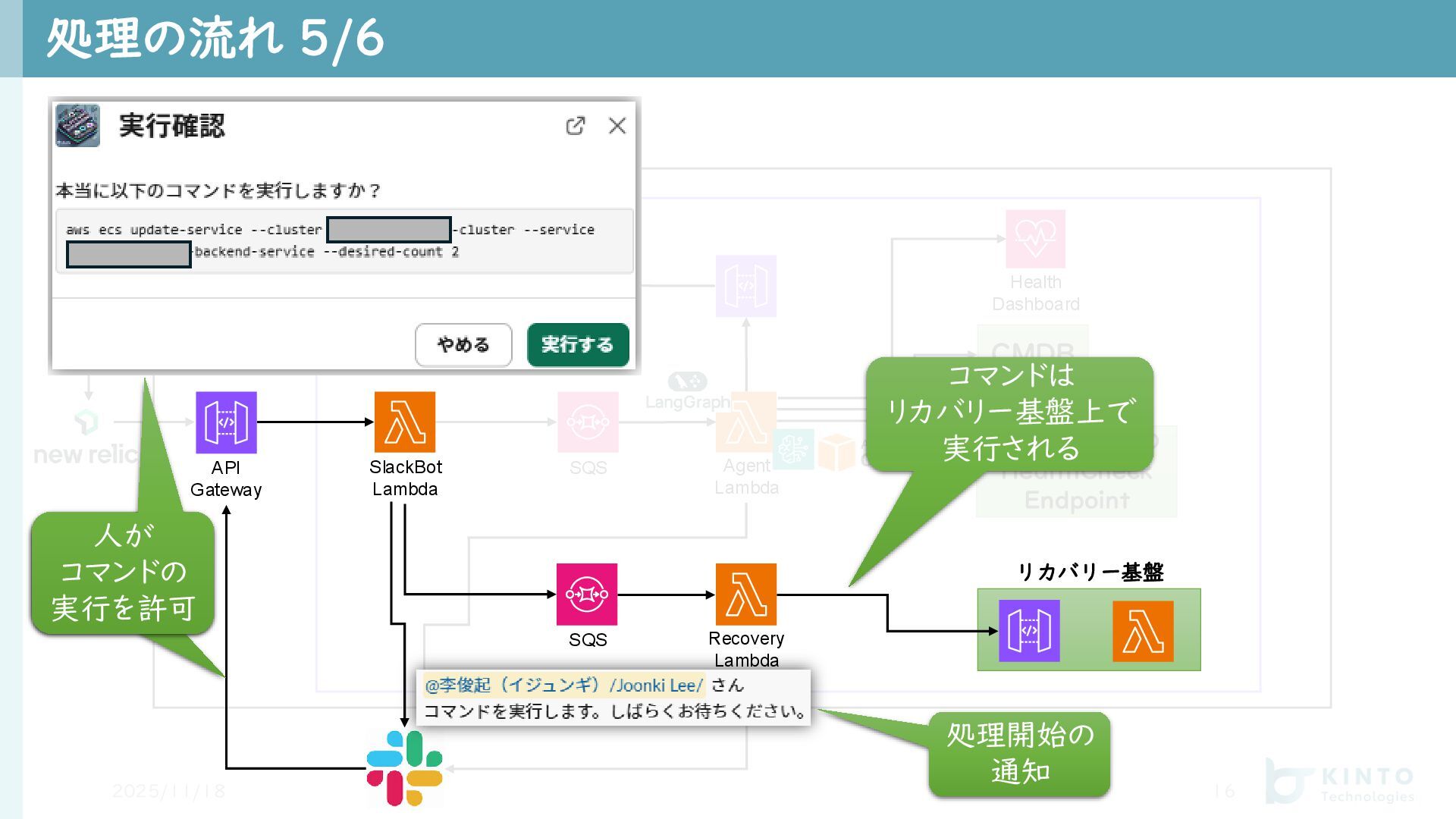
SQS 処理の流れ 5/6 2025/11/18 16 VPC API Gateway SlackBot Lambda リカバリー基盤 SQS Recovery Lambda 人が コマンドの 実行を許可 処理開始の 通知 コマンドは リカバリー基盤上で 実行される
API Gateway SlackBot Lambda リカバリー基盤 SQS Agent Lambda NewRelic Lambda
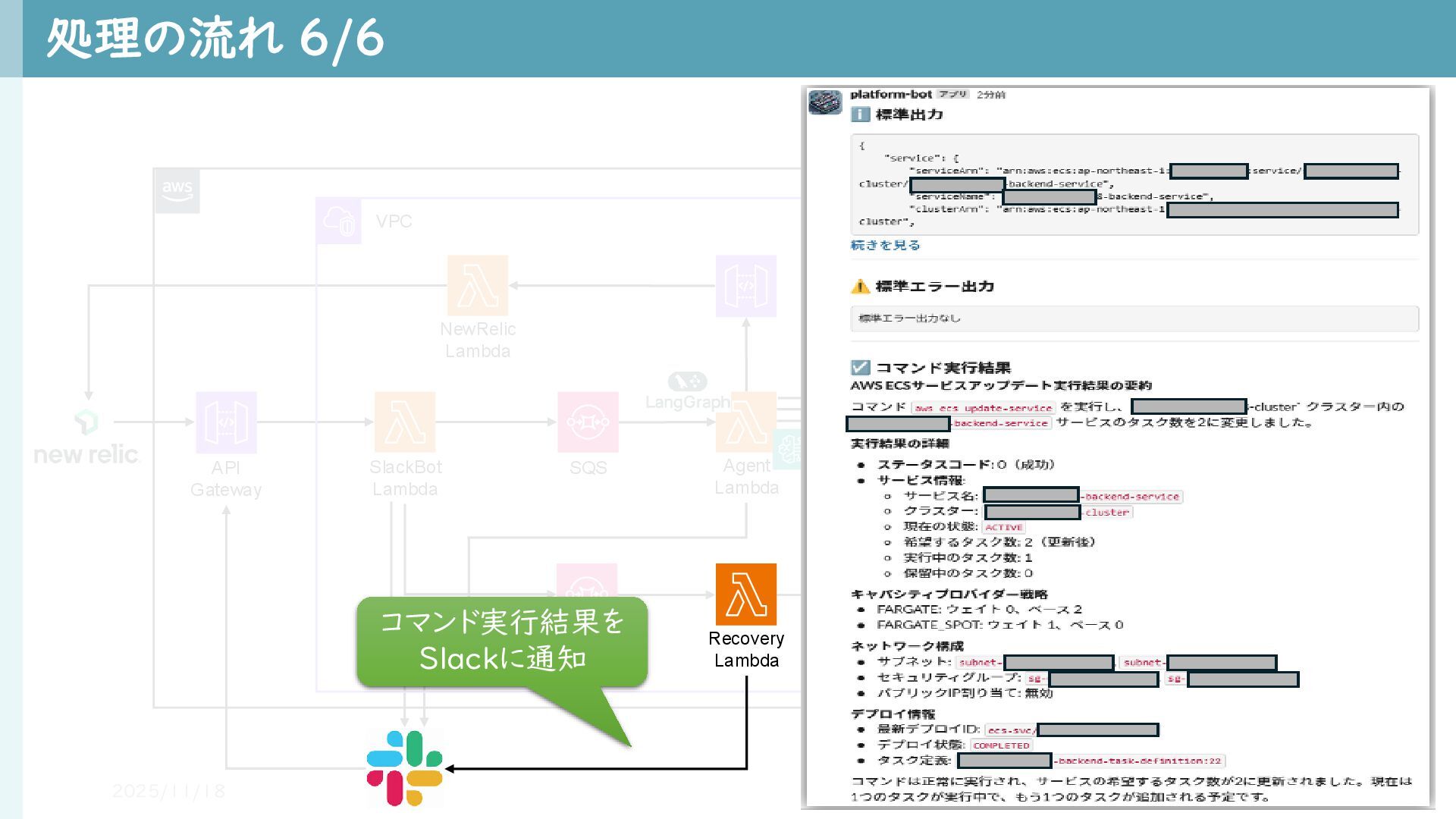
CMDB Health Dashboard 該当システムの HealthCheck Endpoint SQS 処理の流れ 6/6 2025/11/18 17 VPC Recovery Lambda コマンド実行結果を Slackに通知
Phase1 リリース後のフィードバック • インフラレイヤーだけではなく、アプリレイヤーまで調べてほしい • NewRelicだけではなく、CloudWatchアラームとGrafanaからの アラートにも対応してほしい • コマンドを実行して良いか判断ができず、逆に勝手に実行されない か不安
• Agentが何を実行して、何を根拠にその結論に至ったのか確認し たい • 過去対応履歴など、ドメイン知識を踏まえて調査できるようにしてほ しい 2025/11/18 18
2025/11/18 19 Codebase Analysis
実現したいこと 2025/11/18 20 • Githubリポジトリ上のコードとアラート(障害)の関連性を調べて、 コード側に原因がある場合は、問題箇所と修正案を提案する • SlackからGithub issueの起票ができて、さらにGithub issueの
起票をトリガーに、AIによるPRの作成までできるようにする
Codebase AnalysisとしてClaude Codeを使用 2025/11/18 21 • Claude CodeをAPIとしてラッピングし、 AgentにToolとして追加 •
実行有無/実行タイミング/関連性を調査するためのメッセージ (e.g. アプリーログ)はLLMが判断 • 調査対象のGithubリポジトリはCMDBから取得 • 初回リクエスト時にEFSにCloneしておき、2回目以降は更新が あった場合のみPullして更新
Github issue起票 & Claude Code Actionsとの連携 2025/11/18 22 • SlackからGithub
issue起票、さらにissue起票をトリガーに Claude Code Actionsの起動まで可能 Claude起動ありでGithub issueを起票すると Claudeメンション付きでissueが作成され、 Claude Code Actionsが起動される。 設定次第で自動PR作成まで可能。
これで万事解決? 2025/11/18 23 これでアプリレイヤーの対応までできるようになった。 めでたし~めでたし~ ...と言いたいところだが...
Codebase Analysis導入で別の課題が浮き彫りに 2025/11/18 24 • Lambdaの最大実行時間15分という制約で、 処理が途中で終わってしまうケースが出てきた • SQS →
EventBridge Pipes → Step Fuctions → ECS Task の構成に変更し、サーバーレス/イベント駆動型アーキテクチャはそ のまま維持しつつ、最大実行時間の制約を解消
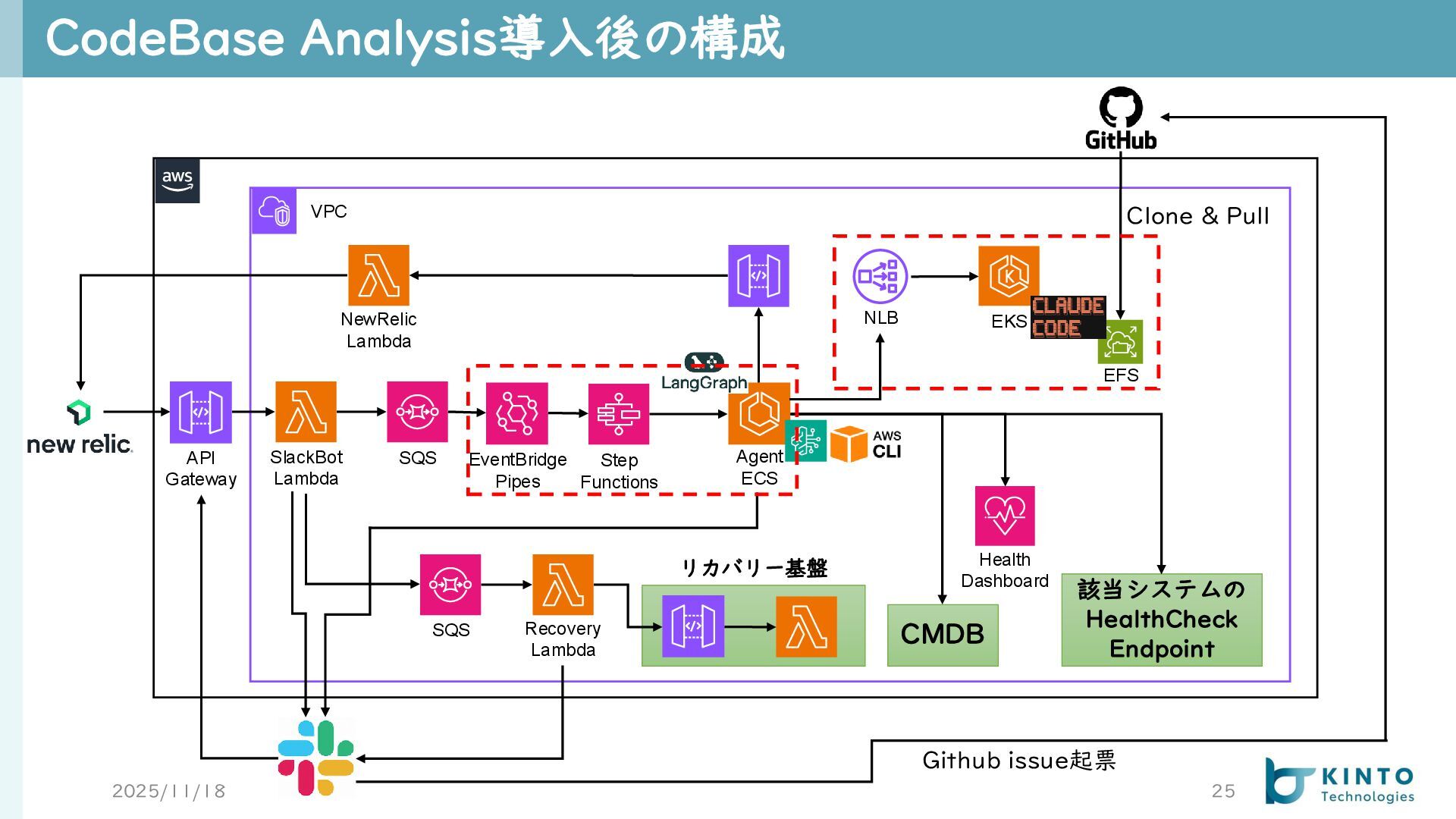
CodeBase Analysis導入後の構成 2025/11/18 25 VPC API Gateway SlackBot Lambda SQS
NewRelic Lambda CMDB Health Dashboard リカバリー基盤 SQS Recovery Lambda Agent ECS EventBridge Pipes Step Functions NLB EKS 該当システムの HealthCheck Endpoint EFS Github issue起票 Clone & Pull
2025/11/18 26 複数のo11yツールへの対応
アラート発報元の判別 / 分岐処理 2025/11/18 27 • o11yツールによって連携されるアラートデータのフォーマットが 異なるため、ツールに応じた分岐処理が必要 • アラートを受信する最初のLambdaで「user-agent」ヘッダーの
値から発報元を判定し、対応するツールに合わせてデータを抽出し たうえで、Slackには同じフォーマットで通知
アラート発報元ごとにTool、System Promptを使い分け 2025/11/18 28 • o11yツールごとにAgentの処理を最適化 1. LLMが誤ったToolを選択しないように、アラート発報元ごとに使用でき るToolを制限 2.
使うToolが異なると、ToolのFew Shotなど、System Promptも変わ るので、アラート発報元ごとに専用のSystem Promptを使用
o11yツールの違いによる差分 2025/11/18 29 • 連携されるデータが異なる ➢ Grafanaからはアラートに設定されているクエリーが連携されず、直接 該当アラートに設定されているクエリーをGrafanaから取得 • AgentのToolの数
➢ NewRelicではAgentのToolとして2つだけだったが、Grafanaを始め とするOSS製のモニタリング基盤では、メトリクスはThanos、ログはLoki、 トレースはTempoみたいに多数のToolが必要
2025/11/18 30 復旧コマンドの実行について
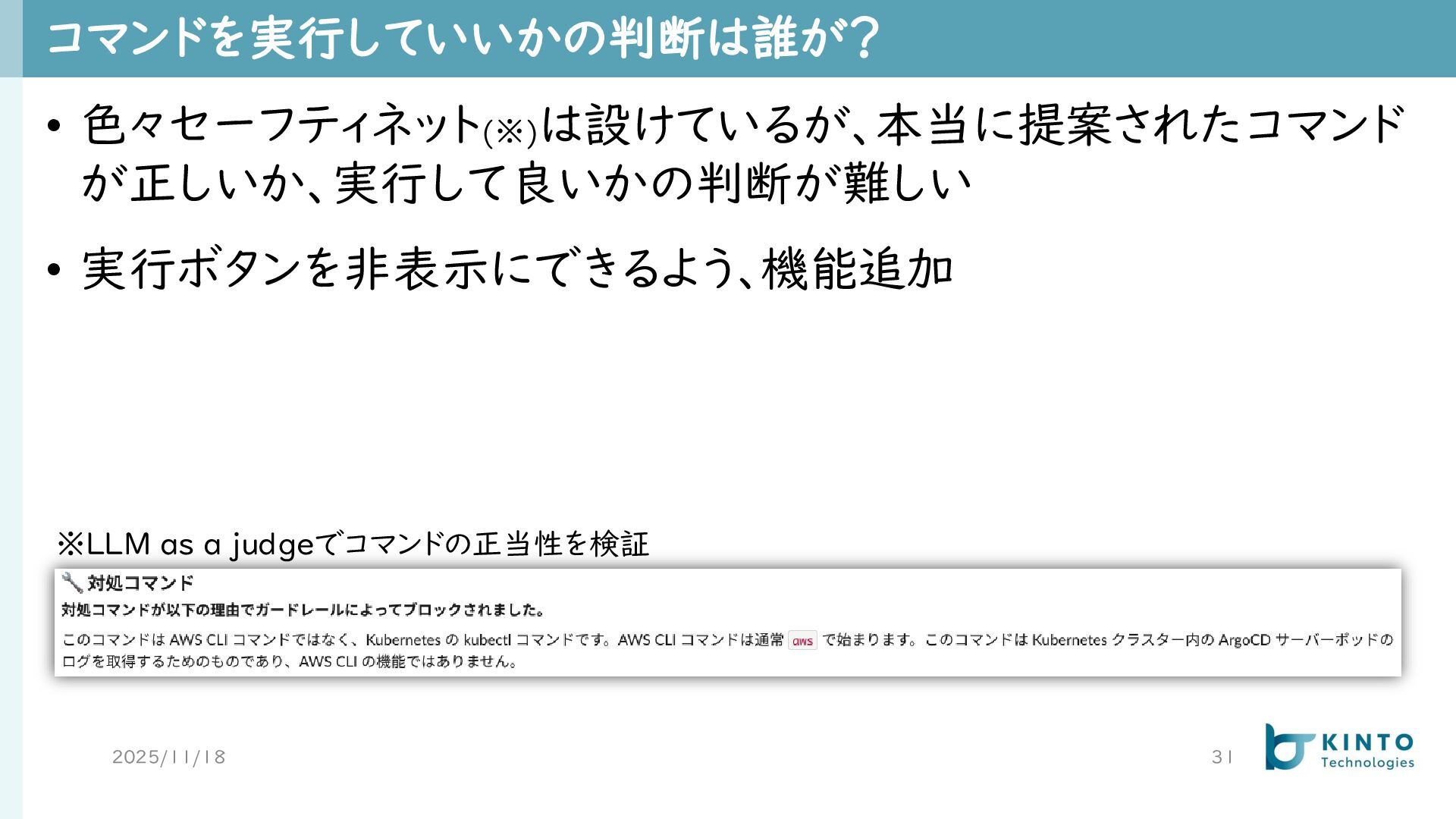
コマンドを実行していいかの判断は誰が? 2025/11/18 31 • 色々セーフティネット(※) は設けているが、本当に提案されたコマンド が正しいか、実行して良いかの判断が難しい • 実行ボタンを非表示にできるよう、機能追加 ※LLM
as a judgeでコマンドの正当性を検証
定型化された作業に対象を絞り込む 2025/11/18 32 • 運用手順が定まっていて、実行パターンが明確に定義されている 作業に限定 ➢ e.g. 障害発生時にCloudFrontの向き先をSorryページに切り替える •
RunBook実行基盤を作成し、原因分析Agentと連携して実行する 方法を模索中(構想段階)
2025/11/18 33 Incident Manager & RAG
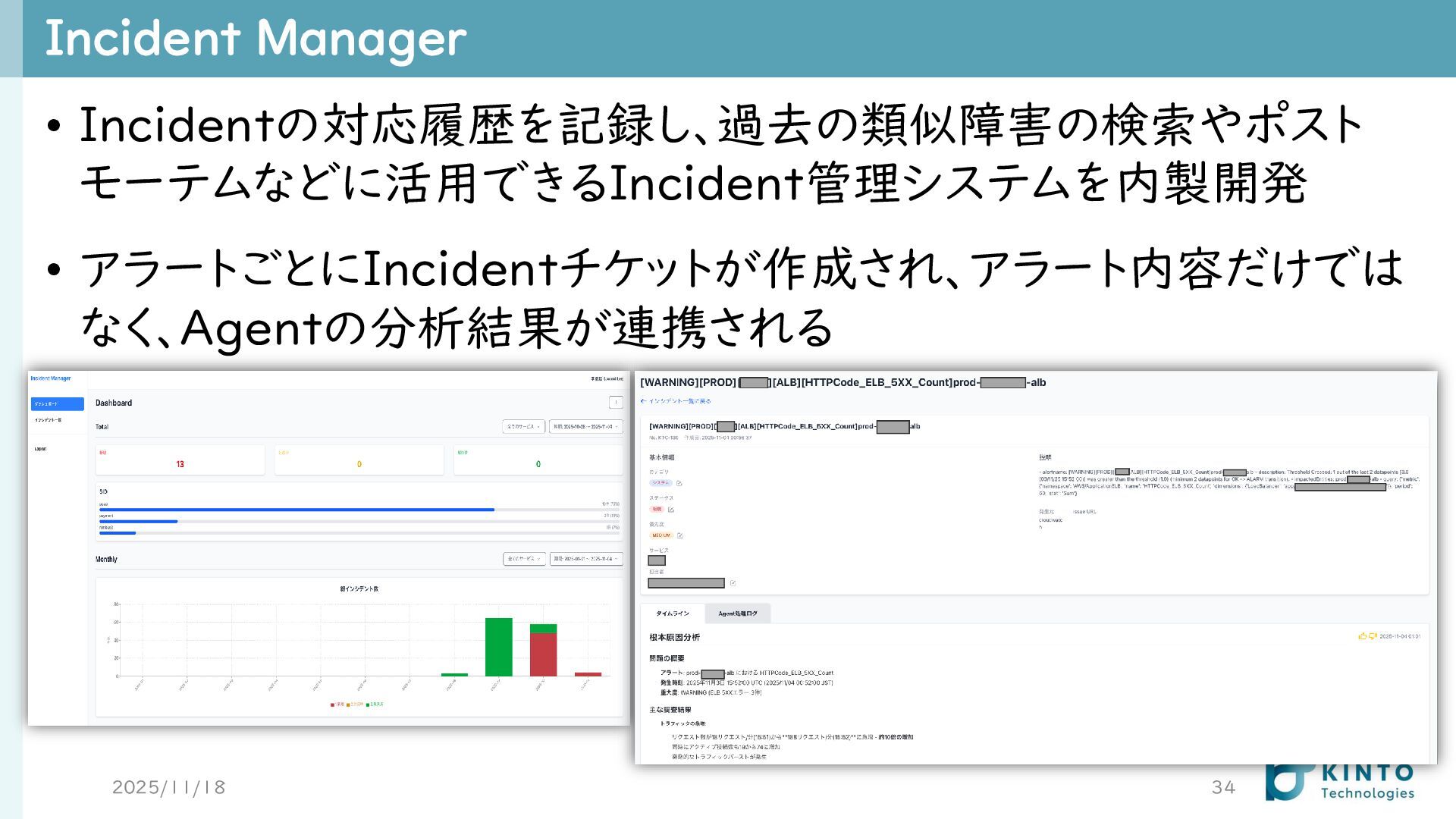
Incident Manager 2025/11/18 34 • Incidentの対応履歴を記録し、過去の類似障害の検索やポスト モーテムなどに活用できるIncident管理システムを内製開発 • アラートごとにIncidentチケットが作成され、アラート内容だけでは なく、Agentの分析結果が連携される
Incident Managerを内製開発した理由 2025/11/18 35 • Incidentのデータを自社環境で保持・管理したい • 対応履歴をRAGとして活用できるようにするうえで、 VectorStoreに入れるタイミングや内容などを完全に制御したい •
原因分析Agentとのネイティブな連携
Incident Managerのその他の機能(Agentの処理内容確認) 2025/11/18 36 • Agentがどういう処理を行なったか確認できるよう、Agentの処理 ログを別タグにて表示
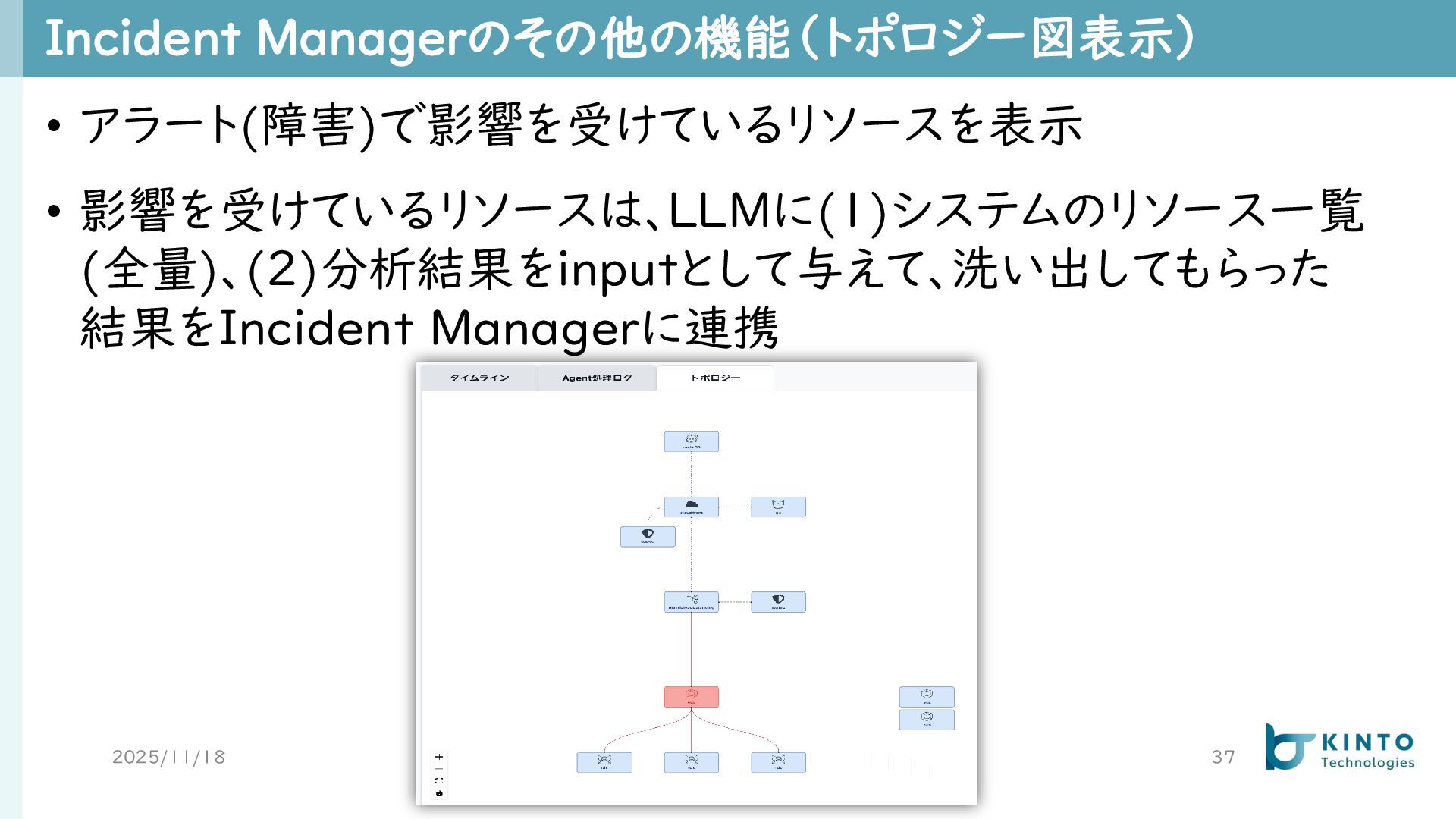
Incident Managerのその他の機能(トポロジー図表示) 2025/11/18 37 • アラート(障害)で影響を受けているリソースを表示 • 影響を受けているリソースは、LLMに(1)システムのリソース一覧 (全量)、(2)分析結果をinputとして与えて、洗い出してもらった 結果をIncident
Managerに連携
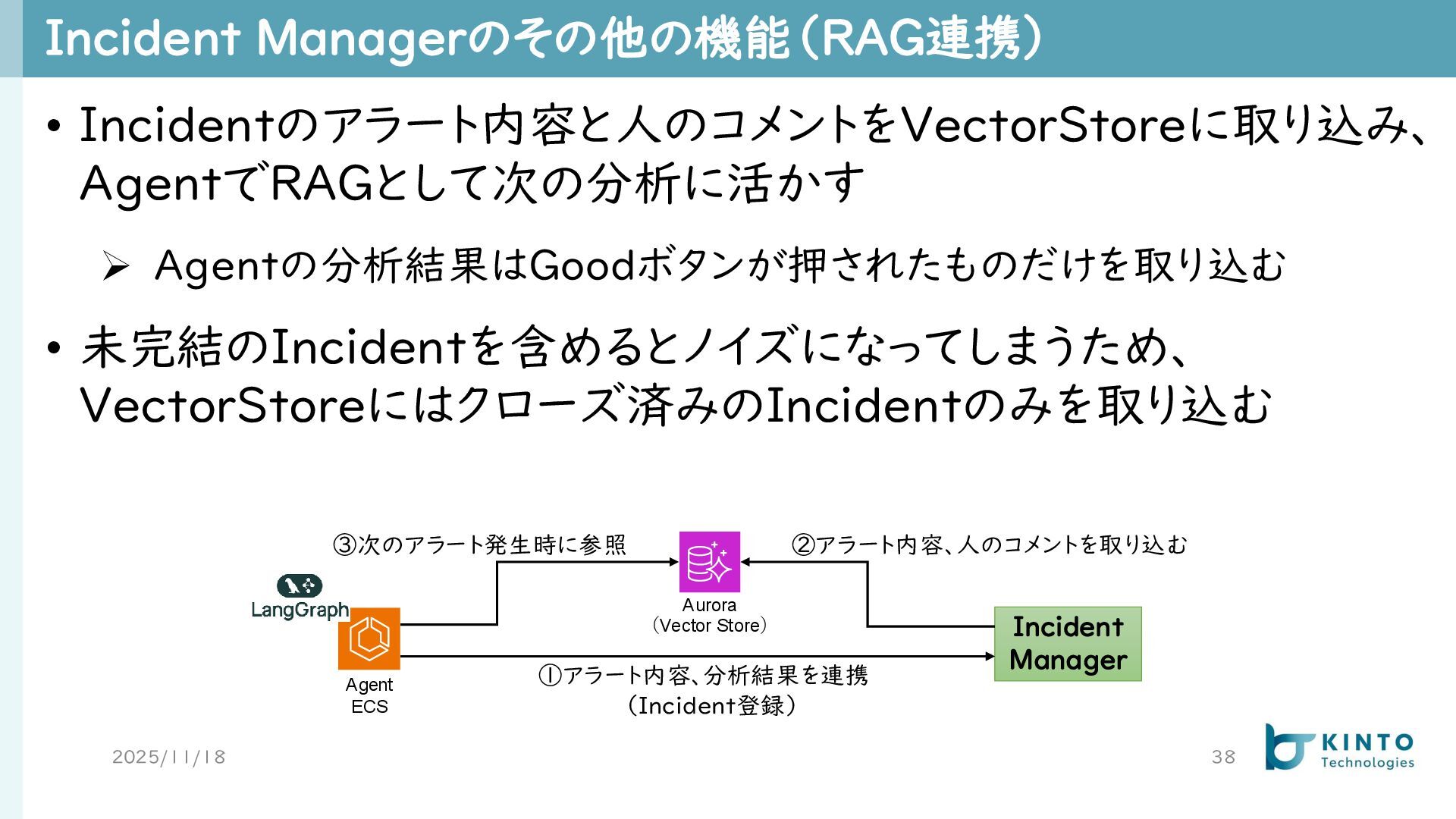
Incident Managerのその他の機能(RAG連携) 2025/11/18 38 • Incidentのアラート内容と人のコメントをVectorStoreに取り込み、 AgentでRAGとして次の分析に活かす ➢ Agentの分析結果はGoodボタンが押されたものだけを取り込む •
未完結のIncidentを含めるとノイズになってしまうため、 VectorStoreにはクローズ済みのIncidentのみを取り込む Agent ECS Incident Manager Aurora (Vector Store) ①アラート内容、分析結果を連携 (Incident登録) ②アラート内容、人のコメントを取り込む ③次のアラート発生時に参照
Vector Storeの選定 1/2 2025/11/18 39 • 最初はOpenSearchをバックエンドとした、Bedrock KnowledgeBaseで実装 • その後、コストの観点からAurora
Serverless(PostgreSQL)を バックエンドとした、 Bedrock KnowledgeBaseに変更 • PostgreSQLのBedrock KnowledgeBaseでは、一応ハイブリッ ト検索は使えるものの、日本語Tokenizerが存在せず、日本語の キーワード検索ができないことから、 Bedrock KnowledgeBase を使わず、素のpgvectorを利用する方法に変更
Vector Storeの選定 2/2 2025/11/18 40 • pgvectorのセマンティック検索と、BM25によるキーワード検索を 組み合わせたハイブリッド検索 + Rerankを試すも期待通りの結果
が得られず ➢ クエリーとログの内容的に類似度が高いものより、タイムスタンプが近いも のが上位に来たり • 結局、現在はpgvectorのセマンティック検索だけにしている ➢ 検索(取得)件数は10件など、多めにしている
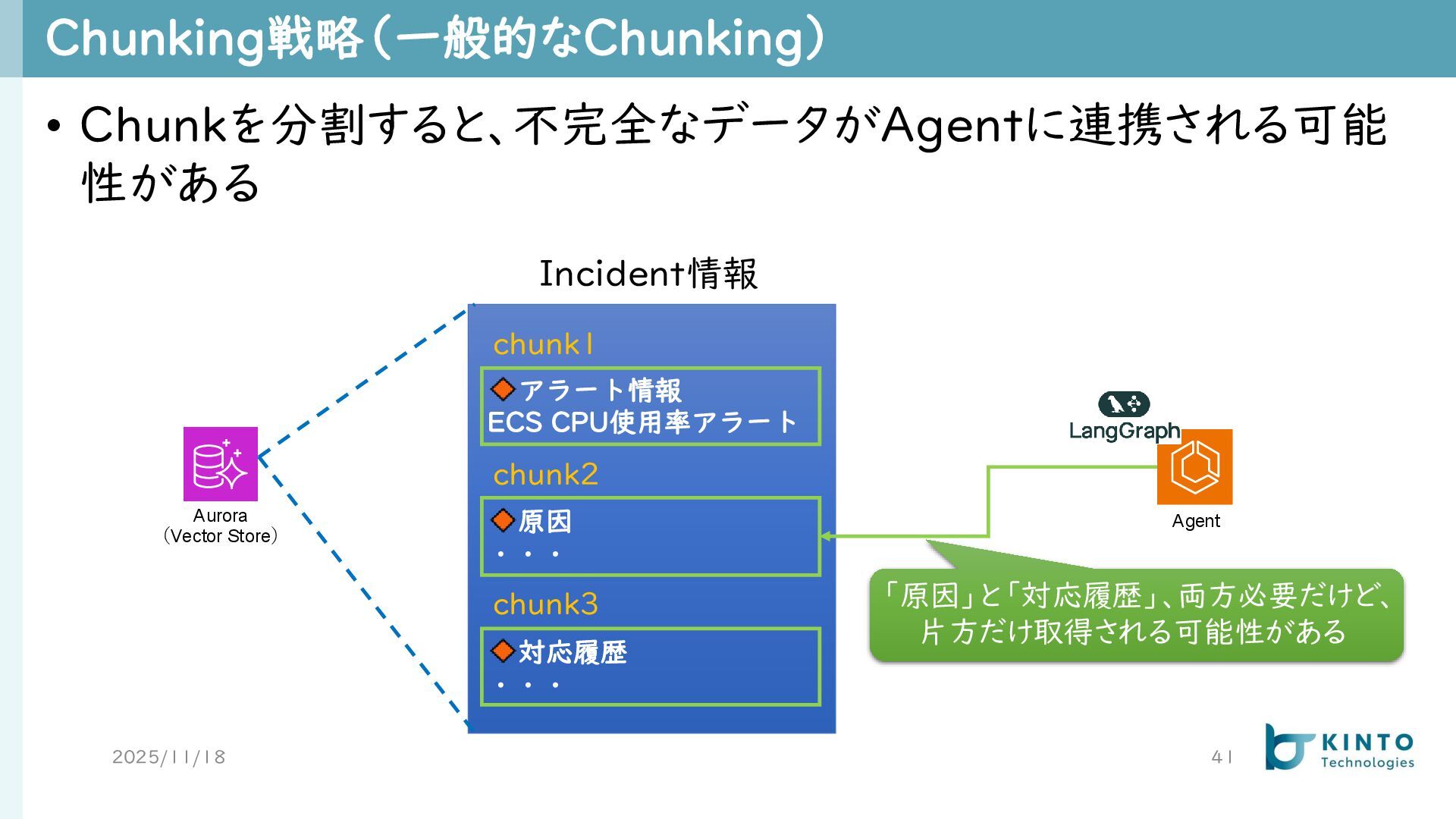
Chunking戦略(一般的なChunking) 2025/11/18 41 • Chunkを分割すると、不完全なデータがAgentに連携される可能 性がある Aurora (Vector Store) アラート情報
ECS CPU使用率アラート 原因 ・・・ 対応履歴 ・・・ Incident情報 chunk1 chunk2 chunk3 Agent 「原因」と「対応履歴」、両方必要だけど、 片方だけ取得される可能性がある
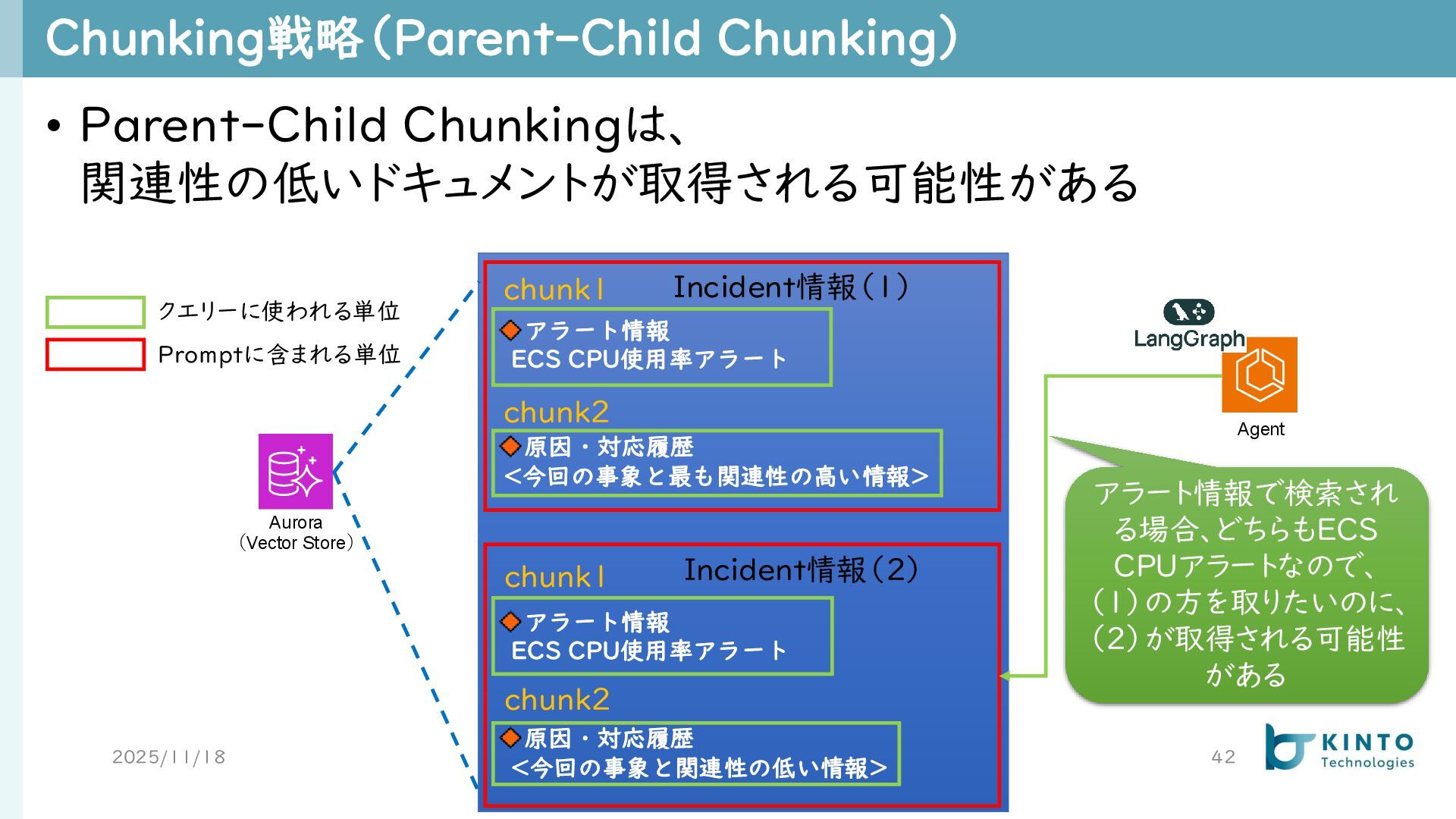
Chunking戦略(Parent-Child Chunking) 2025/11/18 42 • Parent-Child Chunkingは、 関連性の低いドキュメントが取得される可能性がある Aurora (Vector
Store) アラート情報 ECS CPU使用率アラート 原因・対応履歴 <今回の事象と最も関連性の高い情報> アラート情報 ECS CPU使用率アラート 原因・対応履歴 <今回の事象と関連性の低い情報> Incident情報(1) chunk1 chunk2 Agent アラート情報で検索され る場合、どちらもECS CPUアラートなので、 (1)の方を取りたいのに、 (2)が取得される可能性 がある Incident情報(2) chunk1 chunk2 クエリーに使われる単位 Promptに含まれる単位
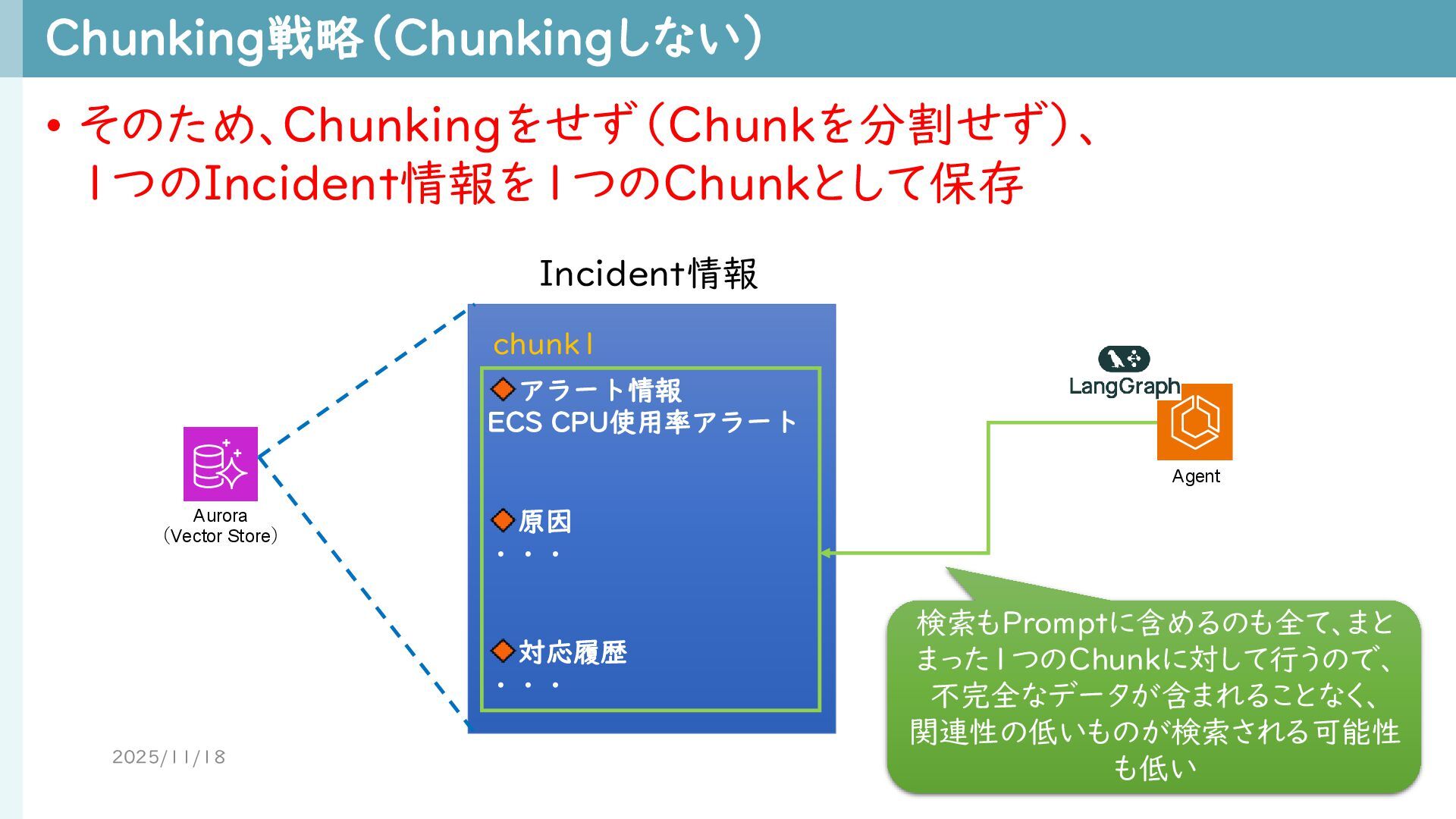
Chunking戦略(Chunkingしない) 2025/11/18 43 • そのため、Chunkingをせず(Chunkを分割せず)、 1つのIncident情報を1つのChunkとして保存 Aurora (Vector Store) アラート情報
ECS CPU使用率アラート 原因 ・・・ 対応履歴 ・・・ Incident情報 chunk1 Agent 検索もPromptに含めるのも全て、まと まった1つのChunkに対して行うので、 不完全なデータが含まれることなく、 関連性の低いものが検索される可能性 も低い
データ検索のタイミング & クエリー (処理の最初に実施) 2025/11/18 44 • Agent処理の最初のステップで、アラート内容だけで検索をすると、 同じアラートの数あるIncidentから、現在のアラートと関連性の高 い履歴の検索ができない可能性がある
Aurora (Vector Store) アラート情報 ECS CPU使用率アラート 原因・対応履歴 <今回の事象と最も関連性の高い情報> アラート情報 ECS CPU使用率アラート 原因・対応履歴 <今回の事象と関連性の低い情報> Incident情報(1) Agent まだ、アラートに関する情報が出 揃ってない処理の最初のタイミン グで、アラート内容だけ検索しても、 数多くの類似事象から関連性の 高い情報の検索が困難 Incident情報(2) “ECS CPU使用率”で検索
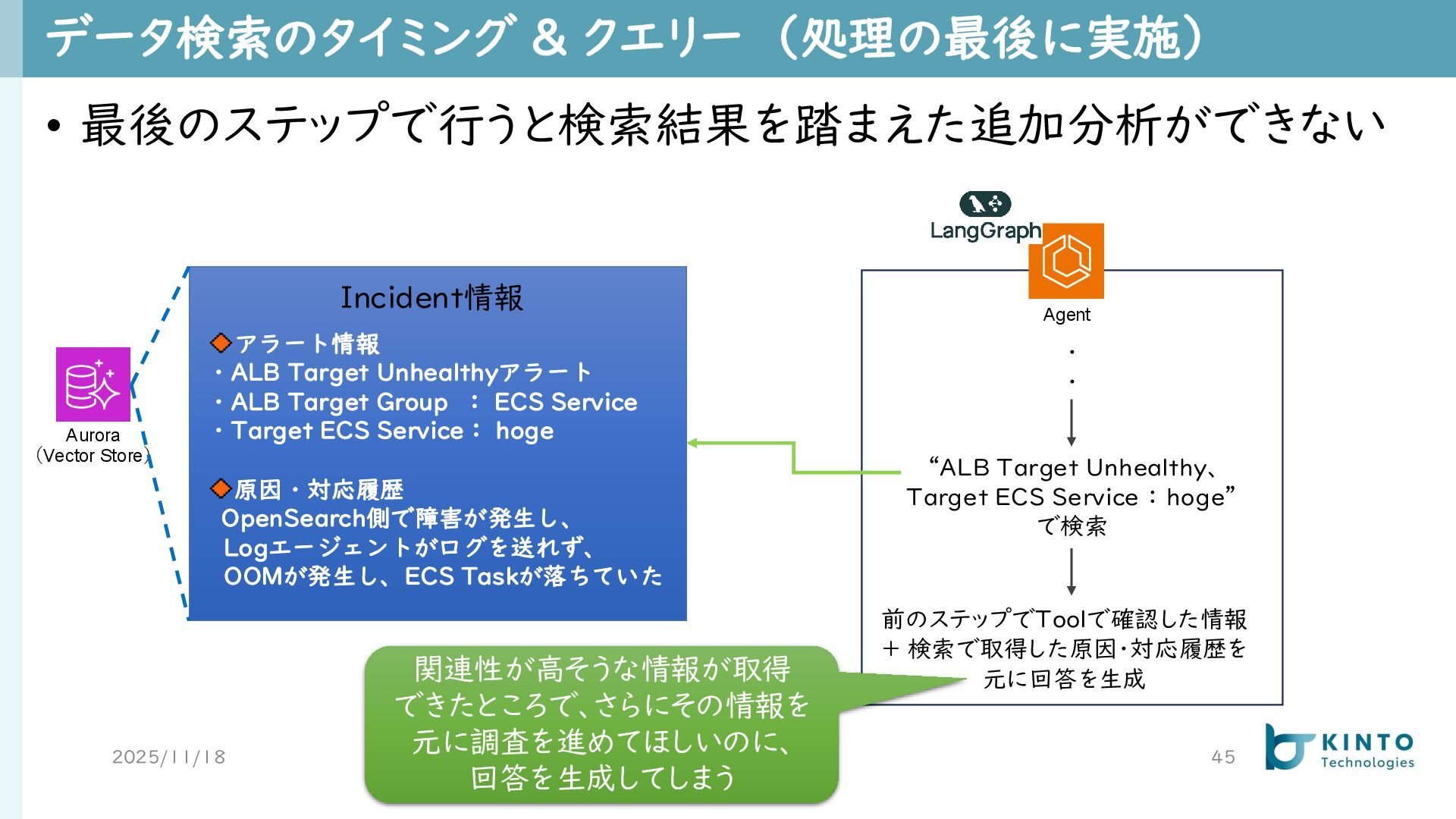
データ検索のタイミング & クエリー (処理の最後に実施) 2025/11/18 45 • 最後のステップで行うと検索結果を踏まえた追加分析ができない Aurora (Vector
Store) アラート情報 ・ALB Target Unhealthyアラート ・ALB Target Group : ECS Service ・Target ECS Service: hoge 原因・対応履歴 OpenSearch側で障害が発生し、 Logエージェントがログを送れず、 OOMが発生し、ECS Taskが落ちていた Incident情報 Agent 関連性が高そうな情報が取得 できたところで、さらにその情報を 元に調査を進めてほしいのに、 回答を生成してしまう ・ ・ “ALB Target Unhealthy、 Target ECS Service : hoge” で検索 前のステップでToolで確認した情報 + 検索で取得した原因・対応履歴を 元に回答を生成
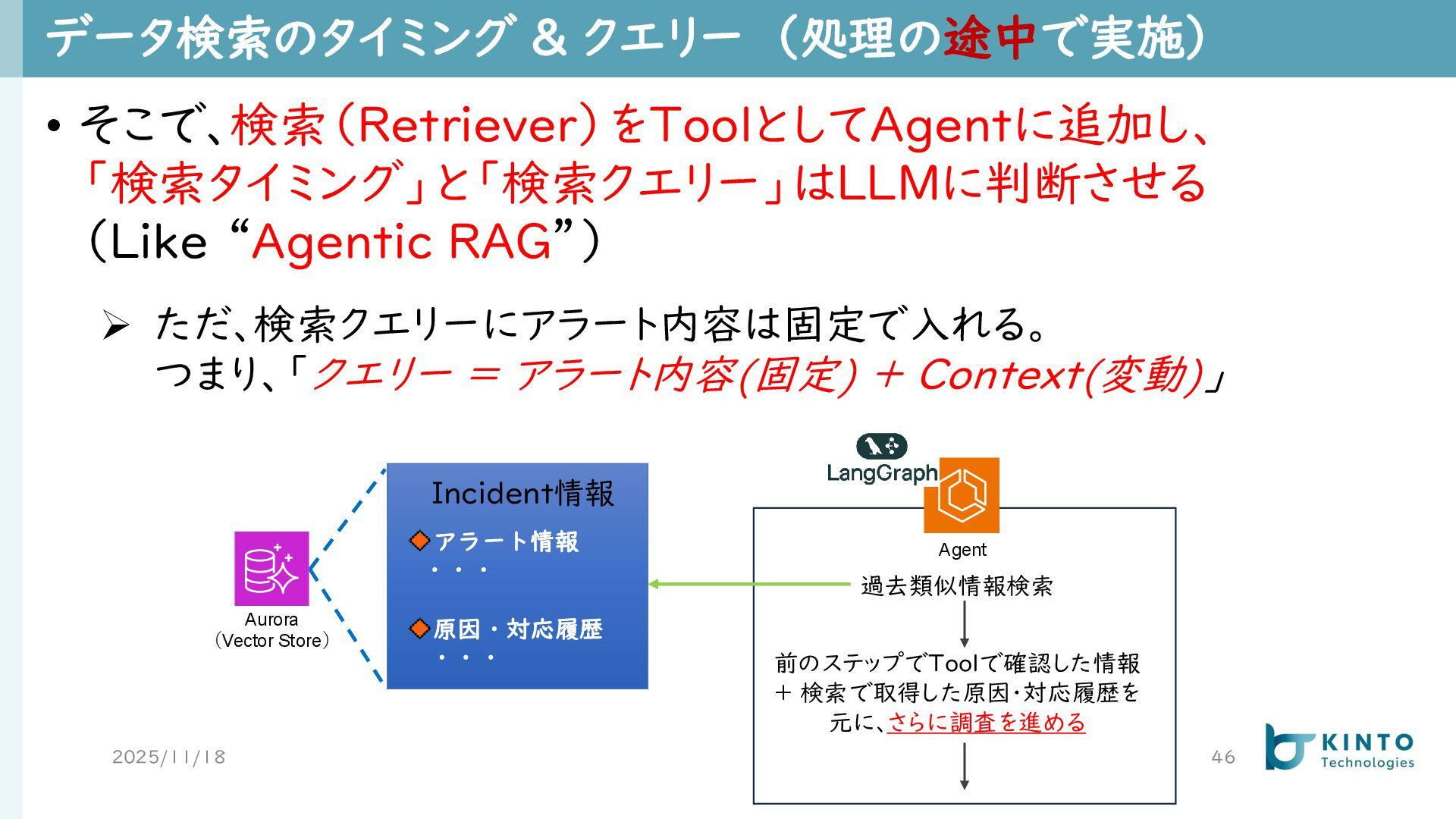
データ検索のタイミング & クエリー (処理の途中で実施) 2025/11/18 46 • そこで、検索(Retriever)をToolとしてAgentに追加し、 「検索タイミング」と「検索クエリー」はLLMに判断させる (Like
“Agentic RAG”) ➢ ただ、検索クエリーにアラート内容は固定で入れる。 つまり、「クエリー = アラート内容(固定) + Context(変動)」 Aurora (Vector Store) アラート情報 ・・・ 原因・対応履歴 ・・・ Incident情報 Agent 過去類似情報検索 前のステップでToolで確認した情報 + 検索で取得した原因・対応履歴を 元に、さらに調査を進める
※補足: Rerankや検索件数の絞り込みはしなくて大丈夫? 2025/11/18 47 • Naive RAGでは、検索結果をそのままSystem Promptに埋め込 んで、LLMに回答をさせるので、関連性の低い内容を除外する必要 がある
• 原因分析Agentでは、検索結果をそのまま使うのではなく、Agent にその中から今回の事象と関連するものだけを利用するよう、指示し ているので、関連性の低い履歴が混ざっていても影響が小さい ➢ 少しノイズとなるデータが混ざっていても、関連性の高いデータが漏れる より分析の質が高くなる可能性が高いため、取得件数を多めにしている • 追加で、システムIDをメタデータとして付与して、フィルタリングを することで対象システムの過去履歴だけを取得している
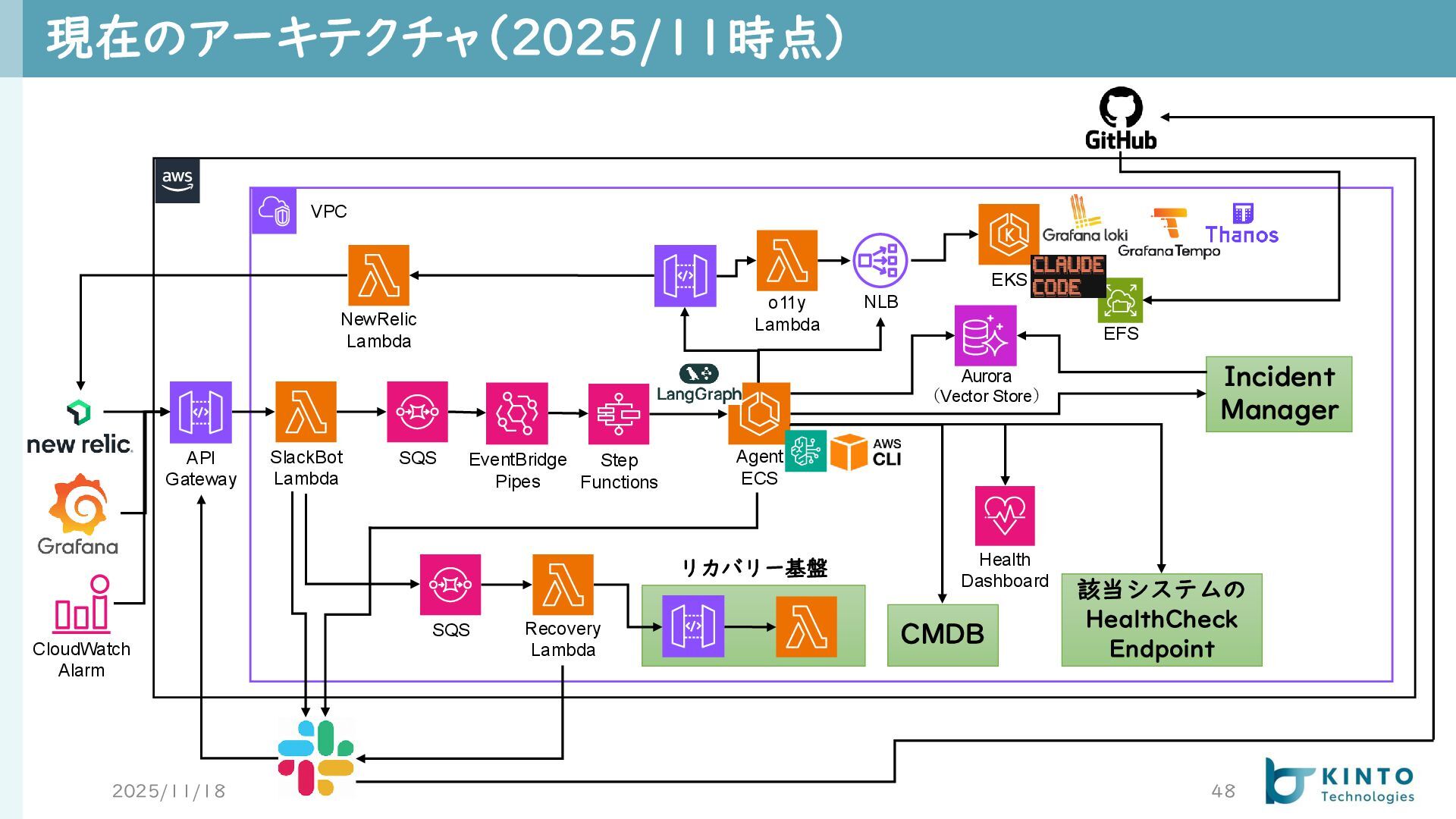
現在のアーキテクチャ(2025/11時点) 2025/11/18 48 VPC API Gateway SlackBot Lambda SQS NewRelic
Lambda CMDB Health Dashboard リカバリー基盤 SQS Recovery Lambda Agent ECS EventBridge Pipes Step Functions NLB EKS 該当システムの HealthCheck Endpoint EFS CloudWatch Alarm o11y Lambda Incident Manager Aurora (Vector Store)
2025/11/18 49 分析結果例
ALBのResponse遅延アラートからDB Index最適化を提案 2025/11/18 50 インフラリソースは 正常であることを 確認 ログからトレースIDを特定し、 さらにトレースから アラートの原因となったSQL
を特定 問題の原因を特定 対応方法を提案 (Index最適化)
2025/11/18 51 ALBのUnHealthyHostアラートに対して、対応不要と案内 ALBのTarget Group のヘルスチェックに失敗 したTargetを検知 新しいバージョンのECS Taskへのローリングアップデートによ る一時的なアラートで、すでに解決済みであり、対処不要と案内
エラーログから、エラーの原因のコードを特定し、コード修正を提案 2025/11/18 52 エラーログと関連するコード の部分を特定し、原因と なっているロジックを分析 コードの修正方法について提案 エラーログを元に調査
2025/11/18 53 今後について
ロードマップ 2025/11/18 54 • 再分析機能追加 ➢ 1回の分析/提案で終わるのではなく、人が追加のコンテキスト情報を 与えて、再分析/提案を実施できるようにする • ToolをMCPサーバとして公開
➢ アラート発生時だけではなく、通常時でも自然言語から テレメトリーデータの確認ができるようにする
2025/11/18 55 まとめ
1. System Prompt ➢ 指示を具体的に、かつ順序を立てて書く ➢ Toolの使い方についてFew Shotを記載する 2. Context
➢ ToolやRAGから取得する動的なContextだけではなく、静的なContextも重要 ➢ 固定的に必要な情報は、事前に取得してSystem Promptに埋め込む方が効果的 3. Tool ➢ AgentがTool選択に迷わないよう、機能を明確に分ける ➢ Descriptionは、引数の説明も含めて詳細かつ明確に記載する (私が思う)AI Agent開発で最も重要な3要素 2025/11/18 56 1つでも欠けると期待した出力や行動を 安定して得ることは難しくなる。
一緒に働く仲間を探しています 2025/11/18 57 クラウドプラットフォーム エンジニア カスタマーサクセス エンジニア AI x Platform
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}