vs 英語 45% 程度(Common Crawl) でも、⽇本語でも⼗分使える プログラミング⾔語 Python 以外の⾔語においても ある程度ワークするであろう(というロジックは成り⽴つ) Statistics of Common Crawl Monthly Archives by commoncrawl
万トークン(⼩説 200 ページくらい) ◦ Gemini シリーズ: 100 万トークン(⼩説 1000 ページくらい) ◦ → ⻑時間動かしてると履歴がモデルの限界を超えてしまう • 推論モデルにおける課題 ◦ 思考ステップが多いと、コンテキスト⻑の限界を超えるため 単純なタスクも解けなくなる LLM ⾃⾝の技術的制約 The Illusion of the Illusion of Thinking A Comment on Shojaee et al. (2025)
Own your prompts 3. Own your context window 4. Tools are just structured outputs 5. Unify execution state and business state 6. Launch / Pause / Resume with simple APIs LLM ベースのソフトウェアを作る上で経験上⾒出された 12 の設計原則 7. Contact humans with tool calls 8. Own your control flow 9. Compact Errors into Context Window 10. Small, Focused Agents 11. Trigger from anywhere, meet users where they are 12. Make your agent a stateless reducer
段で出⼒トークンが 32 万 • 上限トークンを超過:正答率が 0% に • 複雑なタスクほど出⼒が膨⼤に The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity The Illusion of the Illusion of Thinking A Comment on Shojaee et al. (2025)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
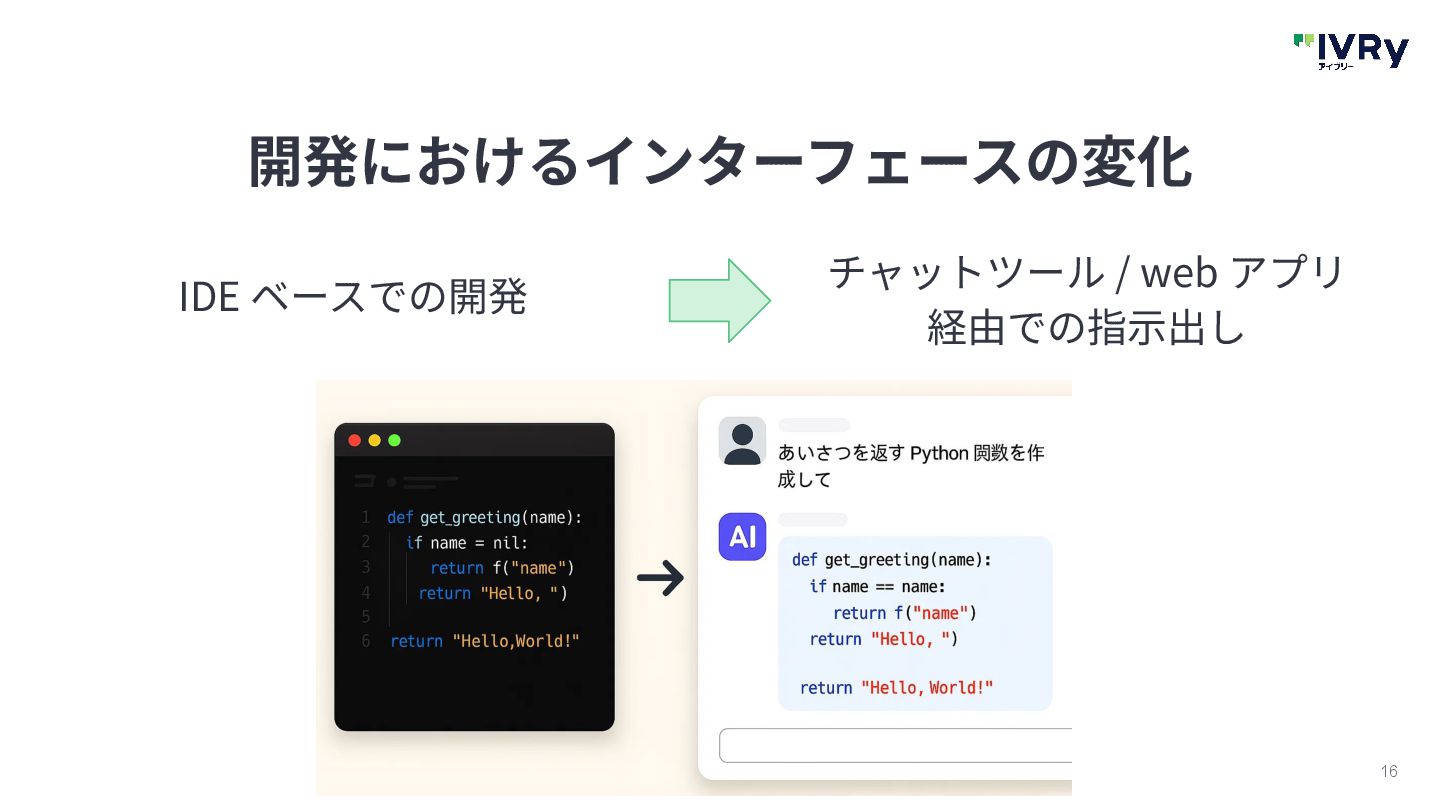{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
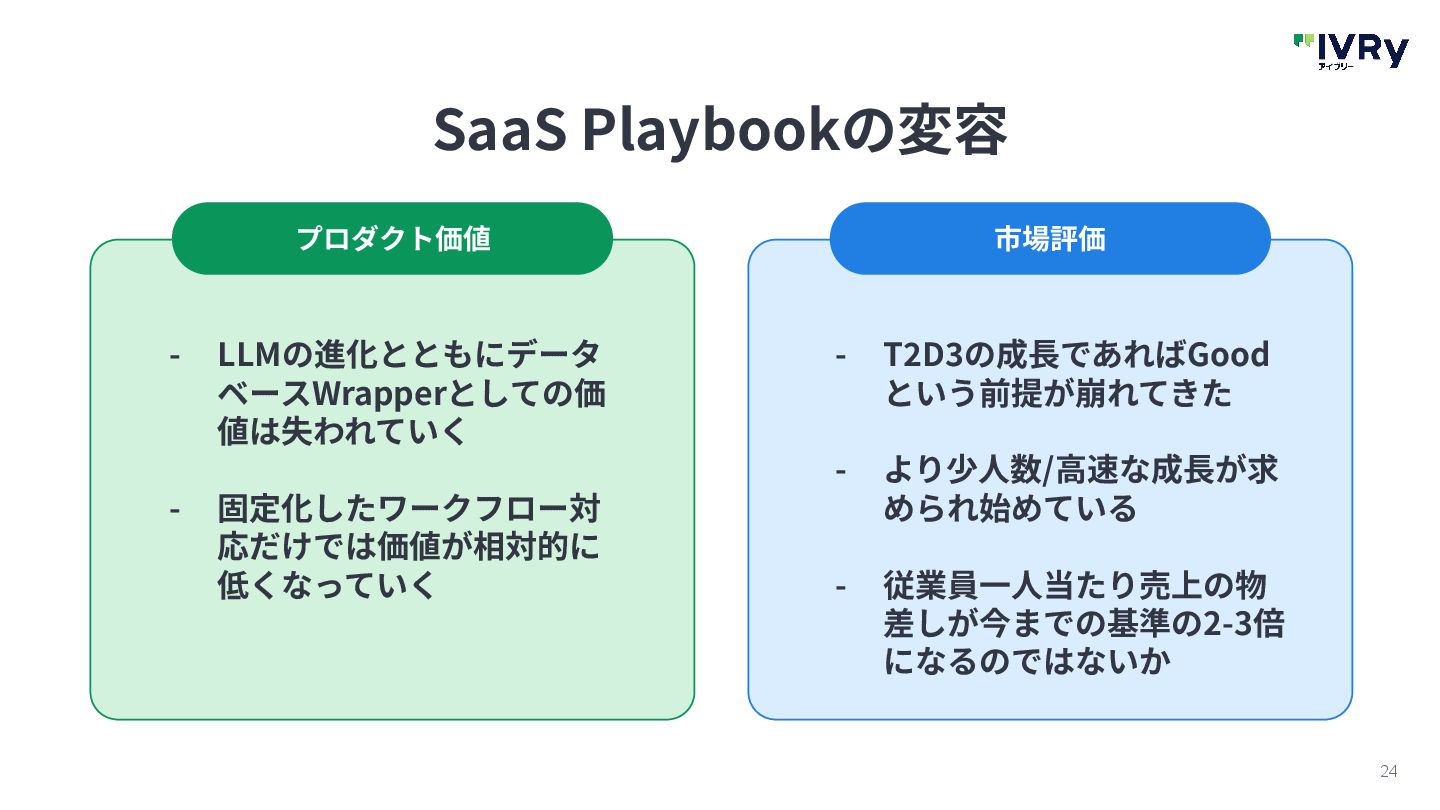{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}