Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
5兆レコードを超える DMMデータ基盤の開発と運用のリアル
Search
Kei
July 03, 2025
38
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
5兆レコードを超える DMMデータ基盤の開発と運用のリアル
Kei
July 03, 2025
More Decks by Kei
See All by Kei
AI Readyなデータ基盤構築は、なぜ大企業では進みづらいのか ─現場での試行錯誤から考える、乗り越え方のヒント
takaha4k
0
330
2025.11.4 Data Engineering Summit 前夜祭 データエンジニアあるある言いたい
takaha4k
0
71
20240927_bq-sushi-dmm登壇資料
takaha4k
0
15
知られざるDMMデータエンジニアの生態 〜かつてツチノコと呼ばれし者〜
takaha4k
5
2.6k
Featured
See All Featured
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Faster Mobile Websites
deanohume
310
32k
We Have a Design System, Now What?
morganepeng
55
8.2k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
170
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Agile that works and the tools we love
rasmusluckow
331
22k
How to Talk to Developers About Accessibility
jct
2
280
Transcript
5兆レコードを超える DMM データ基盤の 開発と運用のリアル 2025.05.28 Data & AI Summit '25
Spring 合同会社DMM.com 高橋 慶
Table of Contents はじめに DMM 全社データ基盤を支える技術 開発と運用のリアル おわりに 01 02
03 04
はじめに 01
Place Image Here 合同会社 DMM.com 開発統括本部 データ基盤開発部 高橋 慶 @takaha4k DMM は2社目(社歴1年ちょっと)
双子(長男) 元大学ゴルフ部(いまはテニス)
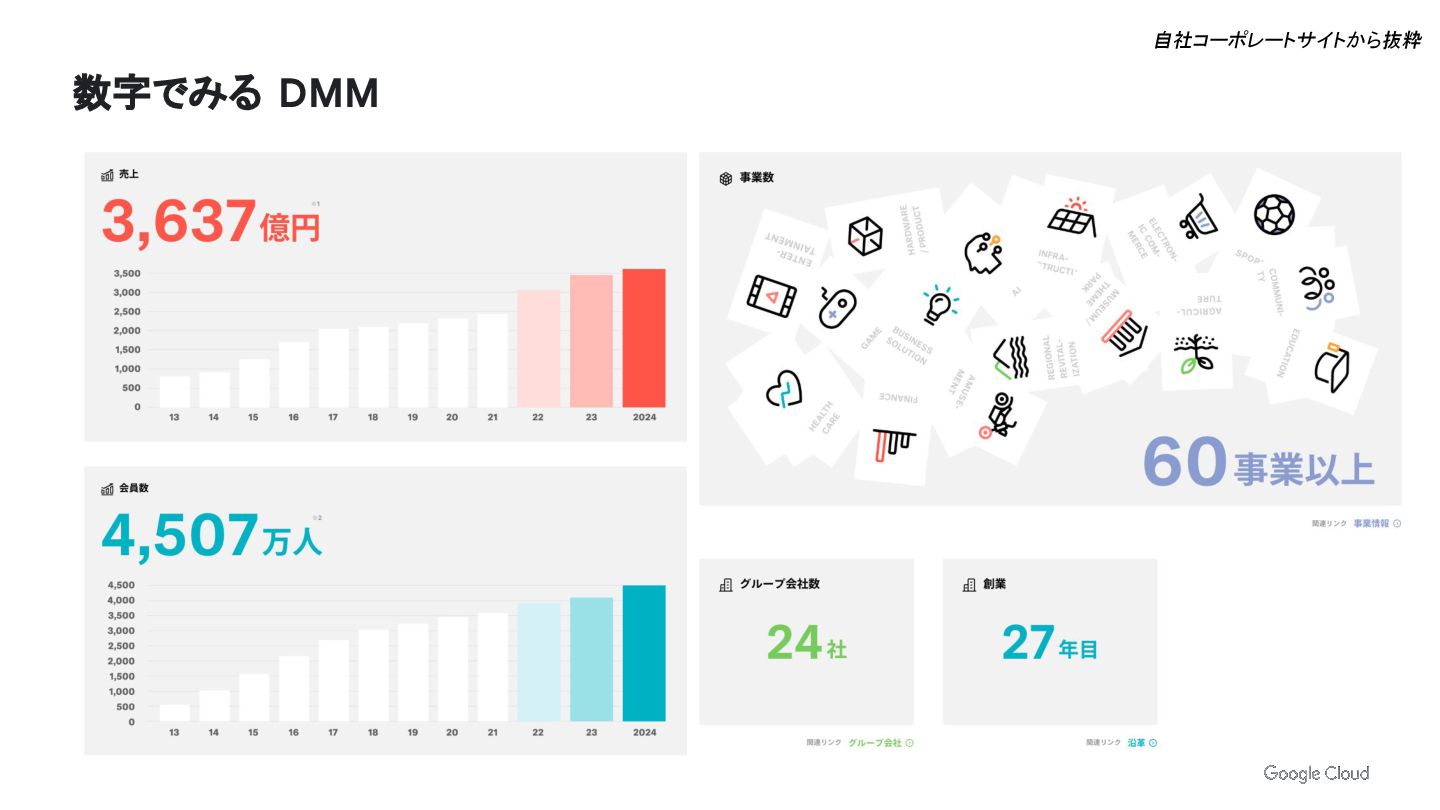
Place Image Here 数字でみる DMM 自社コーポレートサイトから抜粋
なんでもやっている DMM 自社コーポレートサイトから抜粋
数字でみる DMM のデータ基盤( BigQuery) 2025.05.27 時点 保存レコード数 5.3 兆件 直近
180 日間 実行クエリ数 1,600 万回以上
レコード数などは、 INFORMATION_SCHEMA.TABLE_STORAGE ジョブ数などは、 INFORMATION_SCHEMA.JOBS_BY_PROJECT BigQuery では簡単に 統計情報を取得できる -- データ基盤のレコード数を取得する例 SELECT
table_schema, SUM(TOTAL_ROWS) FROM `region-us`.INFORMATION_SCHEMA.TABLE_STORAGE GROUP BY 1
DMM 全社データ基盤を 支える技術 02
Vertex AI Dataflow Pub/Sub Composer BigQuery Datastream Looker Dataplex Cloud
Build Cloud Storage Cloud Functions データ 基盤を支える主な技術
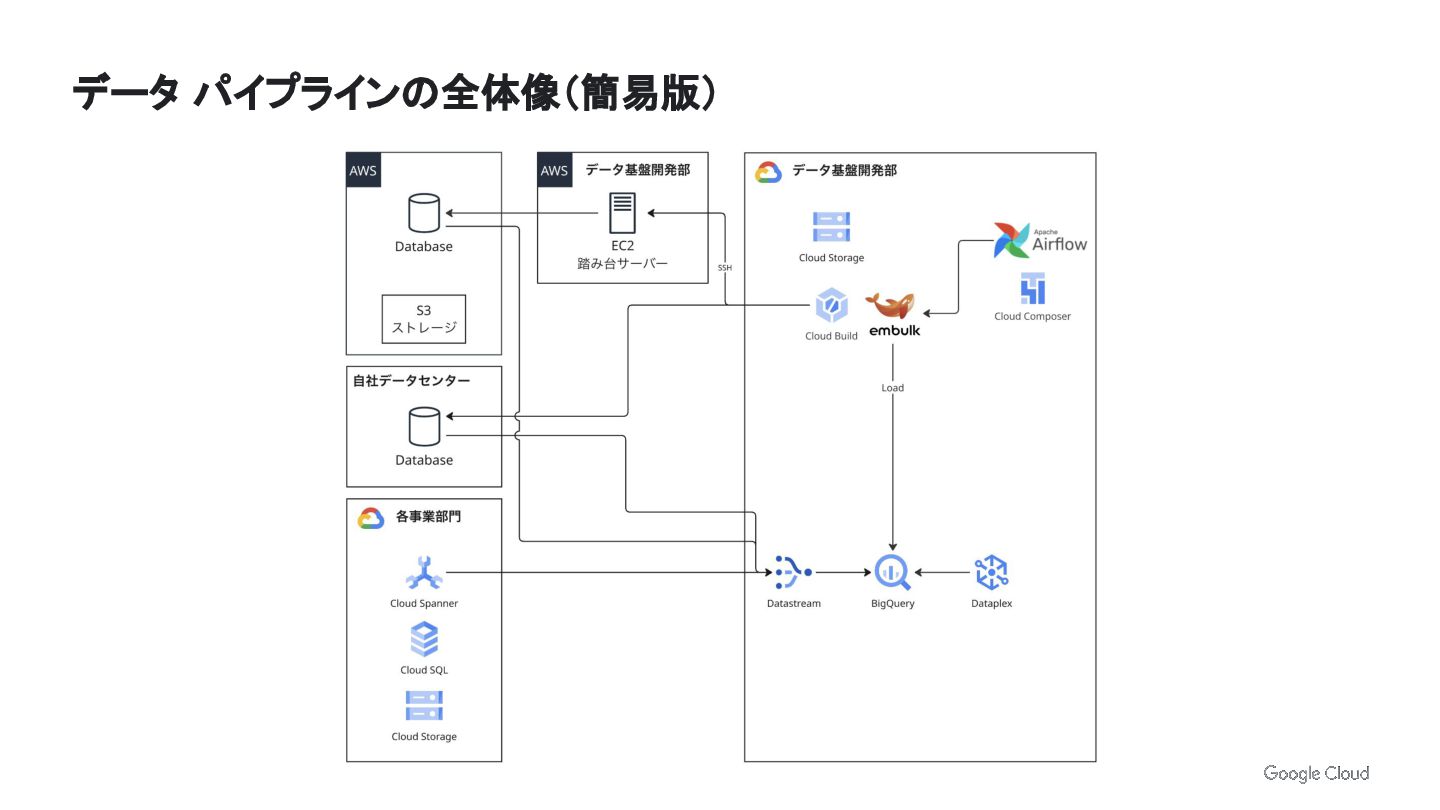
データ パイプラインの全体像(簡易版)
人物 役割 内容 Airflow の管理人 Airflow をクラウド上で安定運用してくれる 指揮者 何をどの順で動かすか決める Embulk
のエンジン Embulk をクラウド上で実行する環境 作業員 データを取り出して運ぶ データ パイプラインの主要登場人物
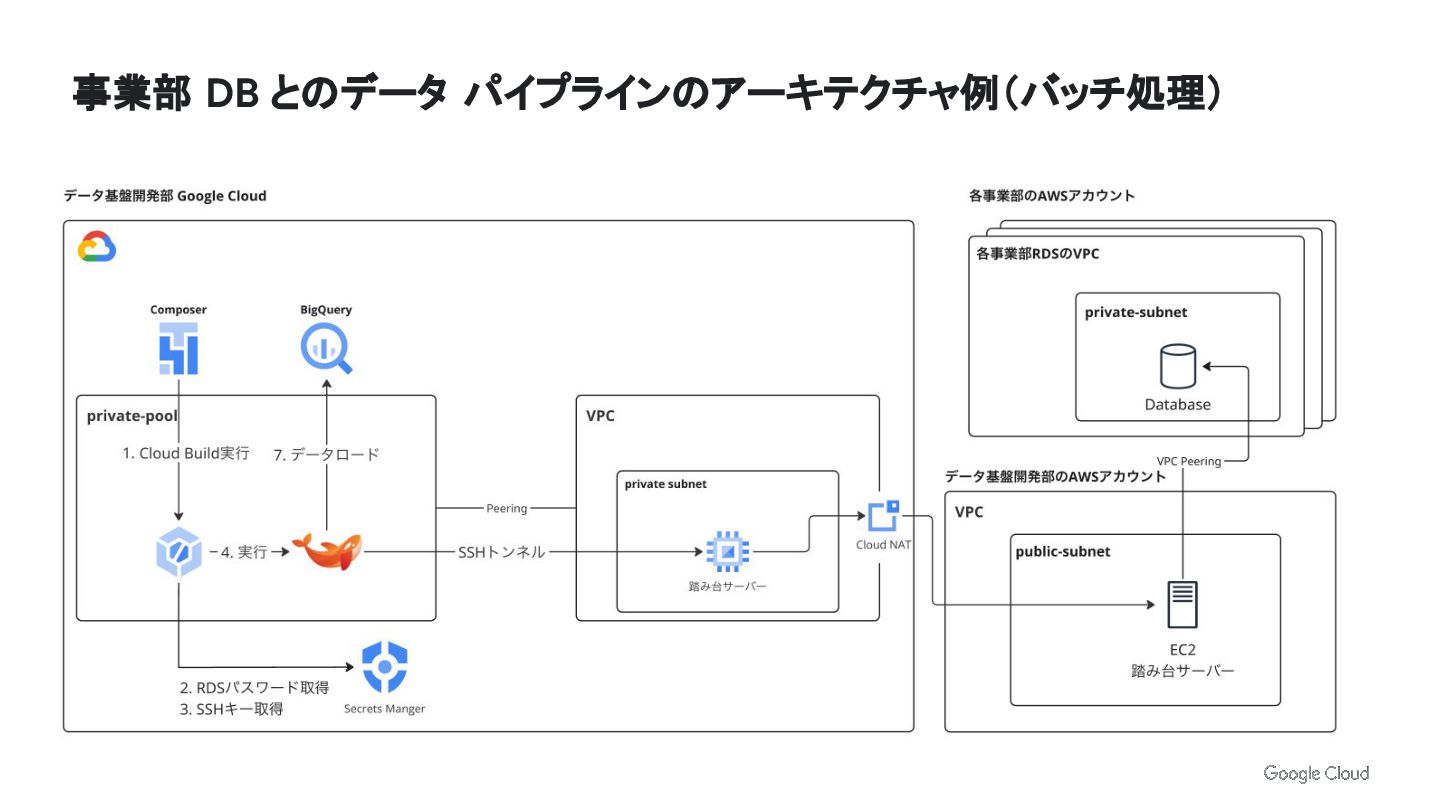
事業部 DB とのデータ パイプラインのアーキテクチャ例(バッチ処理)
CloudBuild のステップ構成 1. 踏み台サーバ IP を取得するた めにトークン取得 2. 踏み台サーバ IP
取得 3. SSHトンネルで、MySQL 接続 4. Embulk を実行 MySQL → BigQuery データ取り込み steps: - name: gcr.io/cloud-builders/gcloud script: |- gcloud auth print-identity-token \ --impersonate-service-account="***@***.gserviceaccount.com" \ > /workspace/token.txt; - name: 'docker.pkg.dev/★/★/embulk-container' script: |- token=$(cat /workspace/token.txt); ip_address=$(~/get_ec2_ip_address.sh ${token}); echo "${SSH_PRIVATE_KEY}" > /workspace/private.key; chmod 600 /workspace/private.key; ssh -i /workspace/private.key -p 10022 \ -o StrictHostKeyChecking=no \ -o ServerAliveInterval=60 \ -o TCPKeepAlive=yes \ -f -N -4 \ -L 3306:${MYSQL_DB_HOST}:${MYSQL_DB_PORT:-3306} \ ec2-user@${ip_address}; embulk run ${EMBULK_CONF:-~/configs/in_mysql_out_bq.yml.liquid}; ※一部簡略化しています cloudbuild.yaml
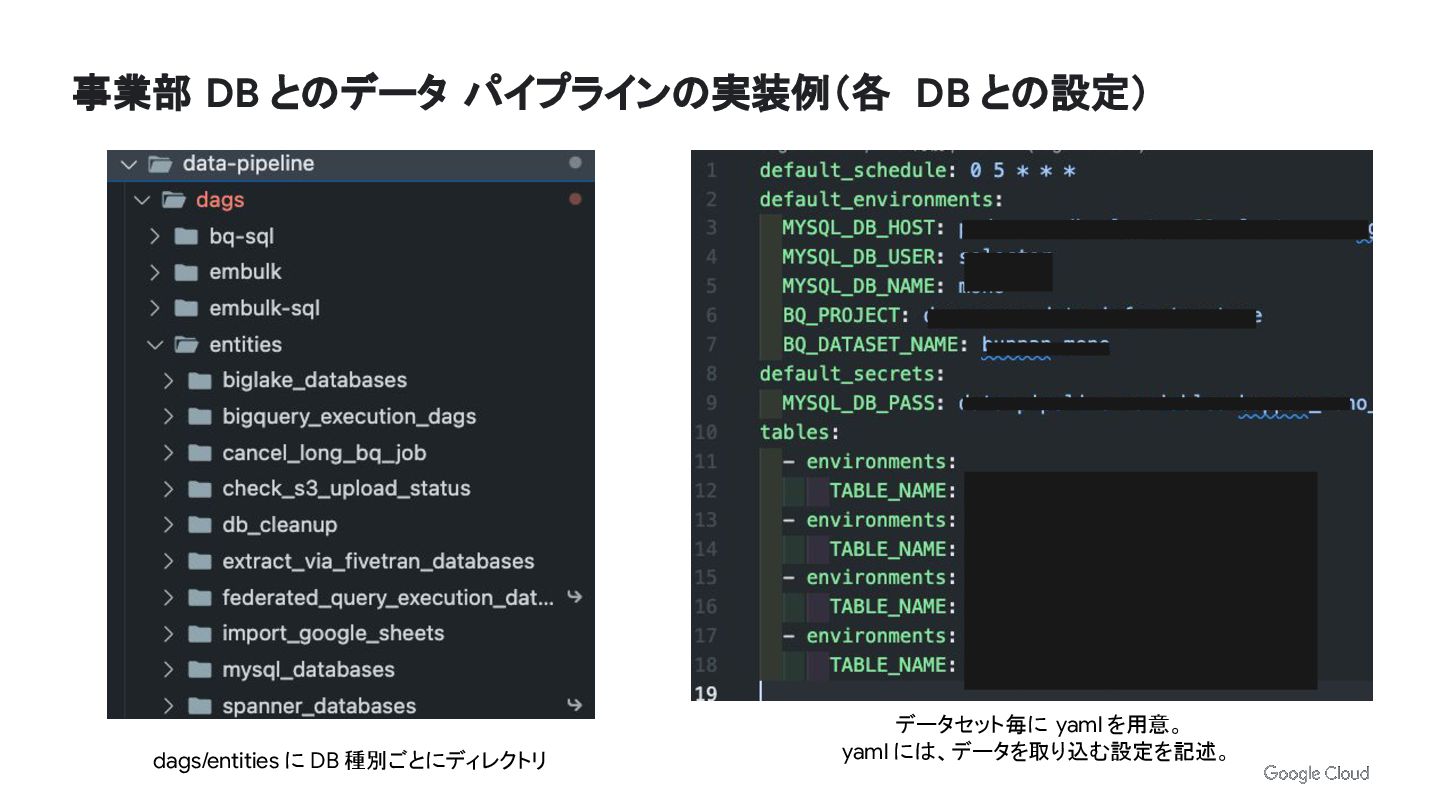
事業部 DB とのデータ パイプラインの実装例(各 DB との設定) dags/entities に DB 種別ごとにディレクトリ
データセット毎に yaml を用意。 yaml には、データを取り込む設定を記述。
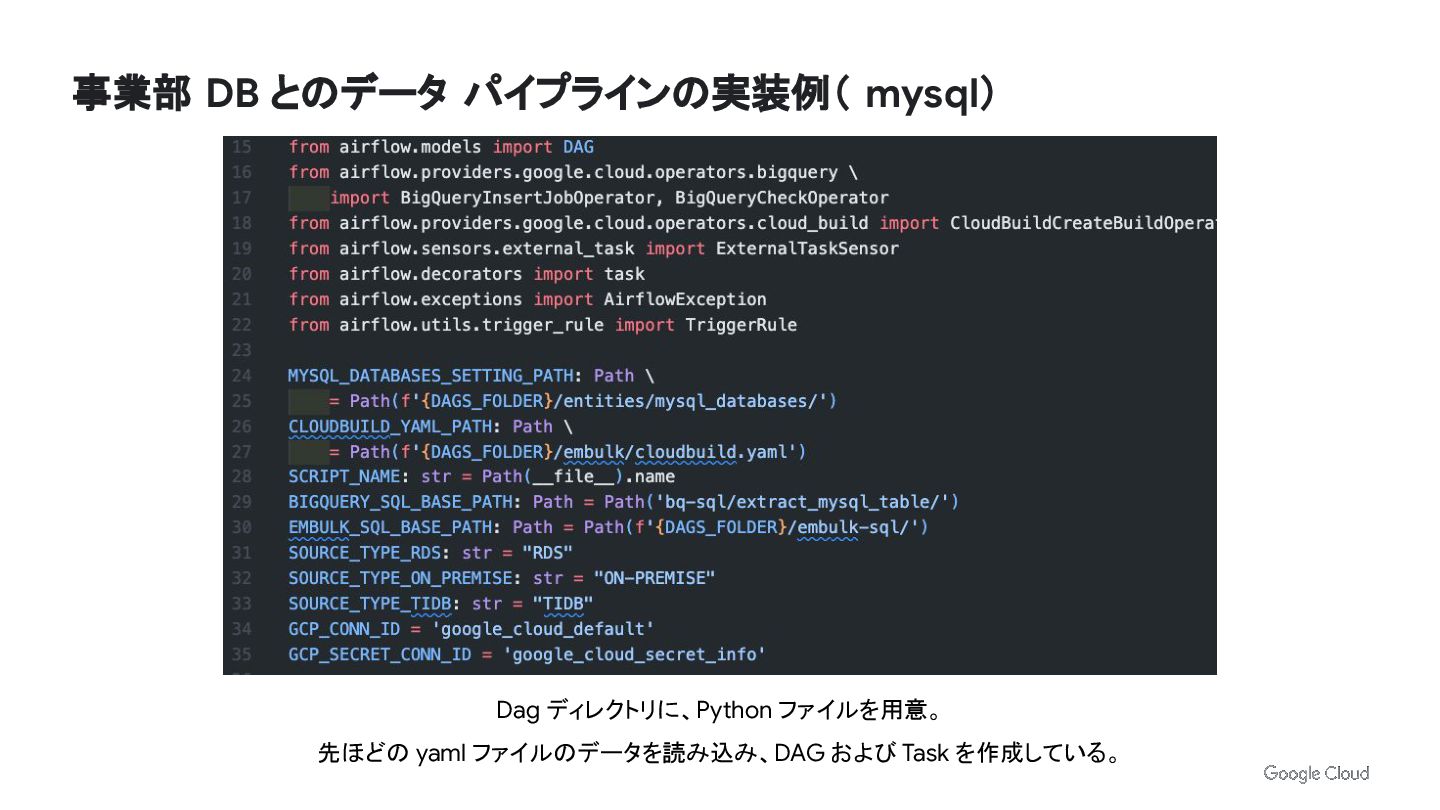
事業部 DB とのデータ パイプラインの実装例( mysql) Dag ディレクトリに、Python ファイルを用意。 先ほどの yaml
ファイルのデータを読み込み、DAG および Task を作成している。
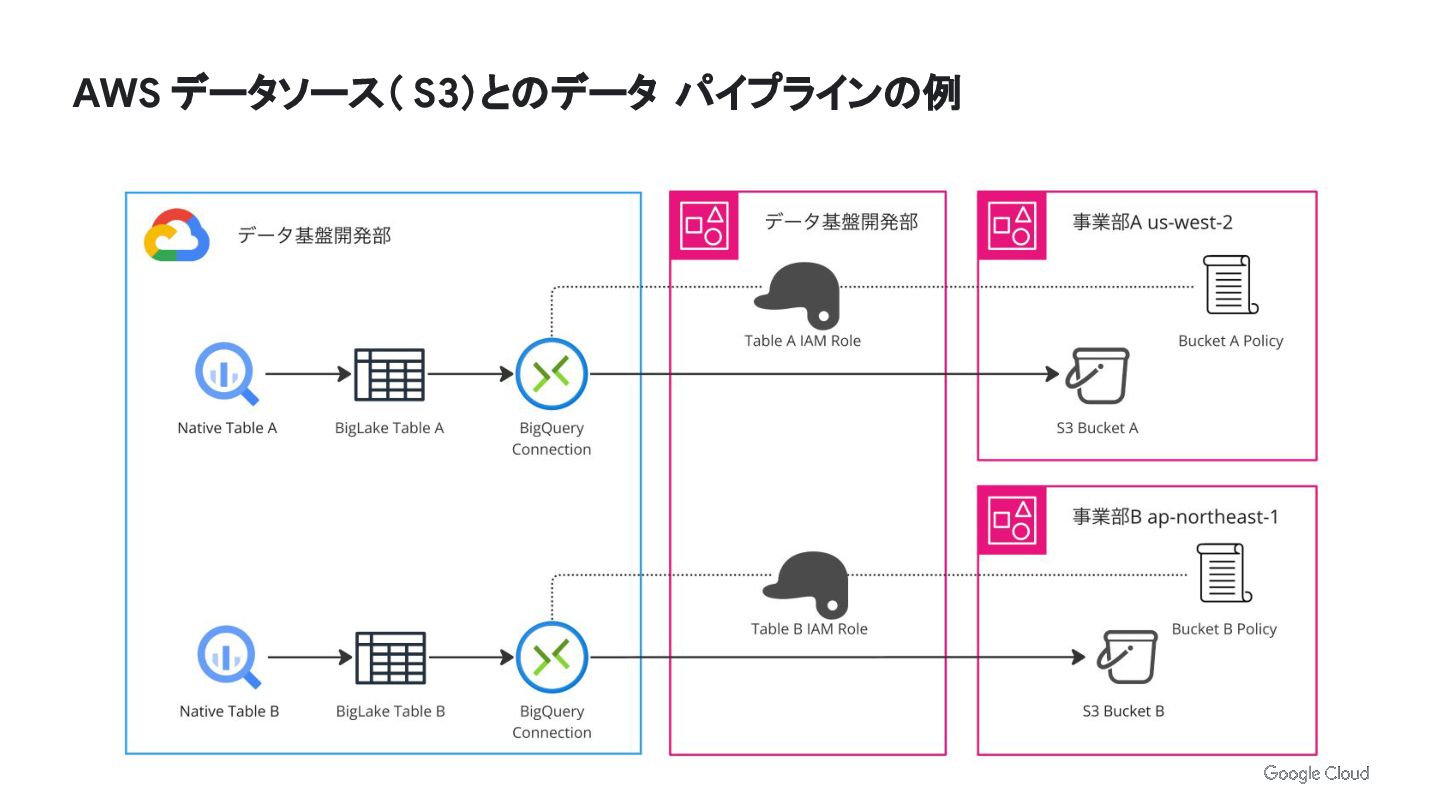
AWS データソース( S3)とのデータ パイプラインの例
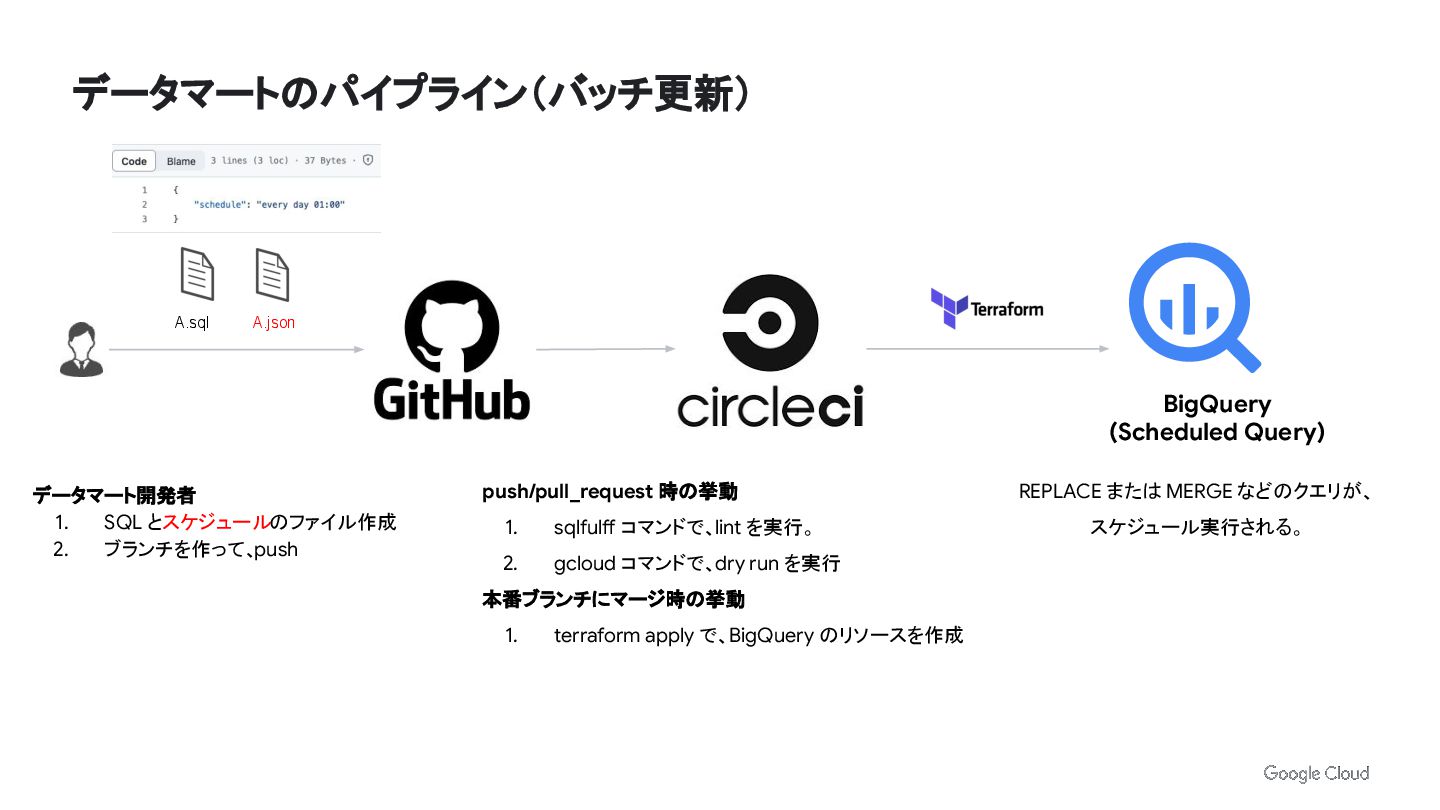
データマートのパイプライン(バッチ更新) BigQuery (Scheduled Query) A.sql A.json データマート開発者 1. SQL とスケジュールのファイル作成
2. ブランチを作って、push push/pull_request 時の挙動 1. sqlfulff コマンドで、lint を実行。 2. gcloud コマンドで、dry run を実行 本番ブランチにマージ時の挙動 1. terraform apply で、BigQuery のリソースを作成 REPLACE または MERGE などのクエリが、 スケジュール実行される。
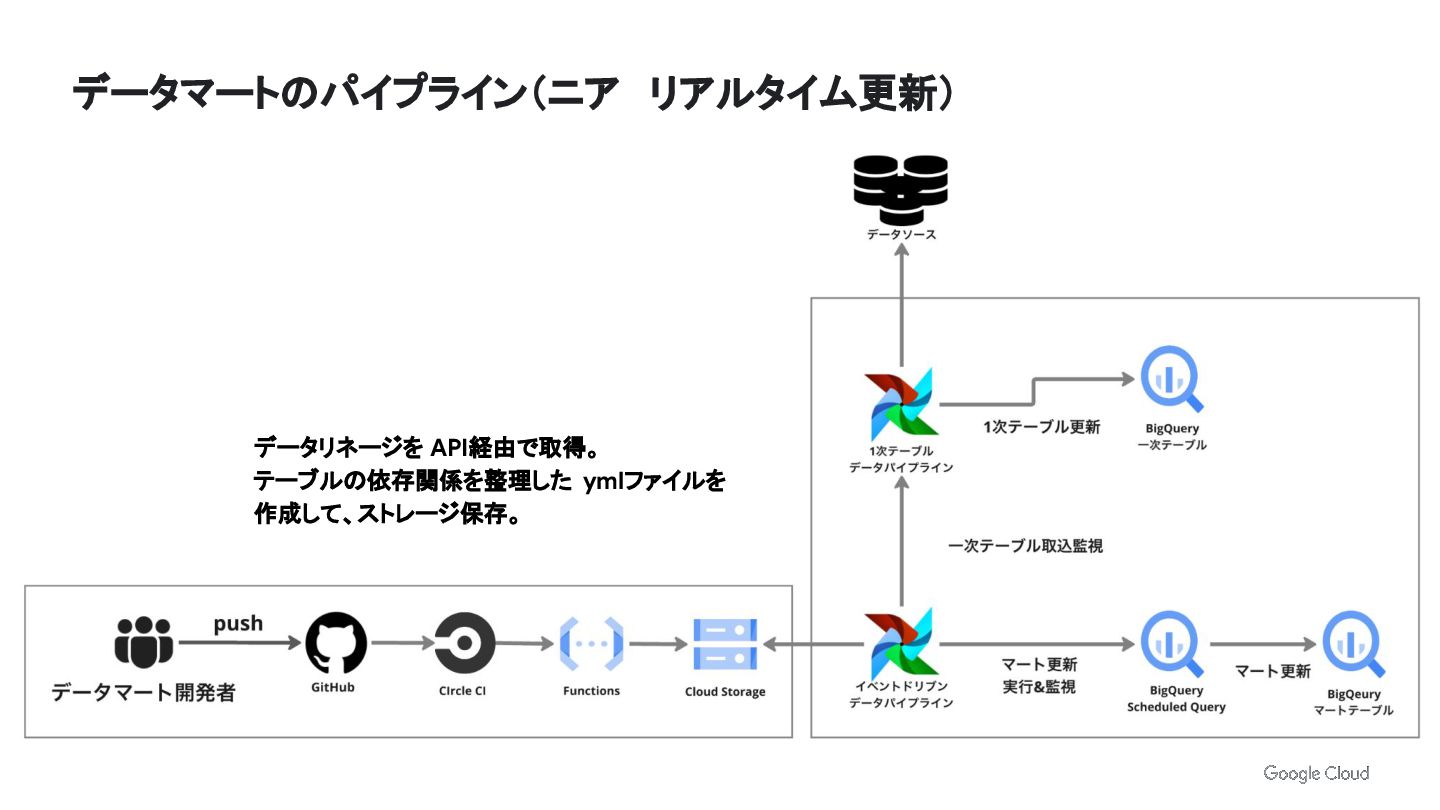
データマートのパイプライン(ニア リアルタイム更新) データリネージを API経由で取得。 テーブルの依存関係を整理した ymlファイルを 作成して、ストレージ保存。
開発と運用のリアル 03
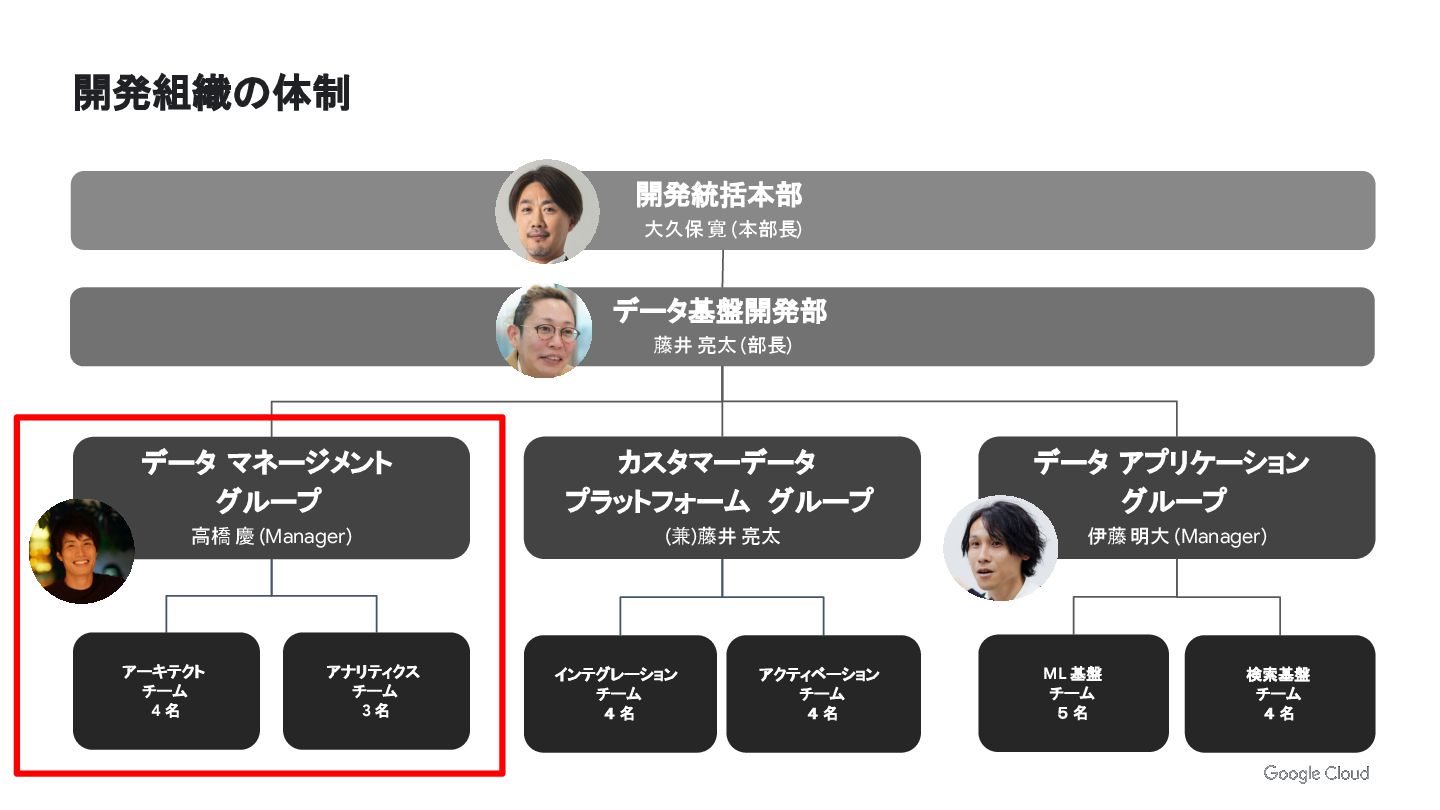
開発組織の体制 検索基盤 チーム 4 名 ML 基盤 チーム 5 名
データ マネージメント グループ 高橋 慶 (Manager) データ基盤開発部 藤井 亮太 (部長) アクティベーション チーム 4 名 インテグレーション チーム 4 名 カスタマーデータ プラットフォーム グループ (兼)藤井 亮太 データ アプリケーション グループ 伊藤 明大 (Manager) アナリティクス チーム 3 名 アーキテクト チーム 4 名 開発統括本部 大久保 寛 (本部長)
データ基盤開発組織のカルチャー 透明性 検査 適応 やさしさ • Slack で作業ログ • GitHub
Issue で管理 • サーベイツール • 定期的にふりかえり • 労力と効果の軸で判断 • 効果なかったら辞める • 技術マウント取らない • 困っている人を助ける
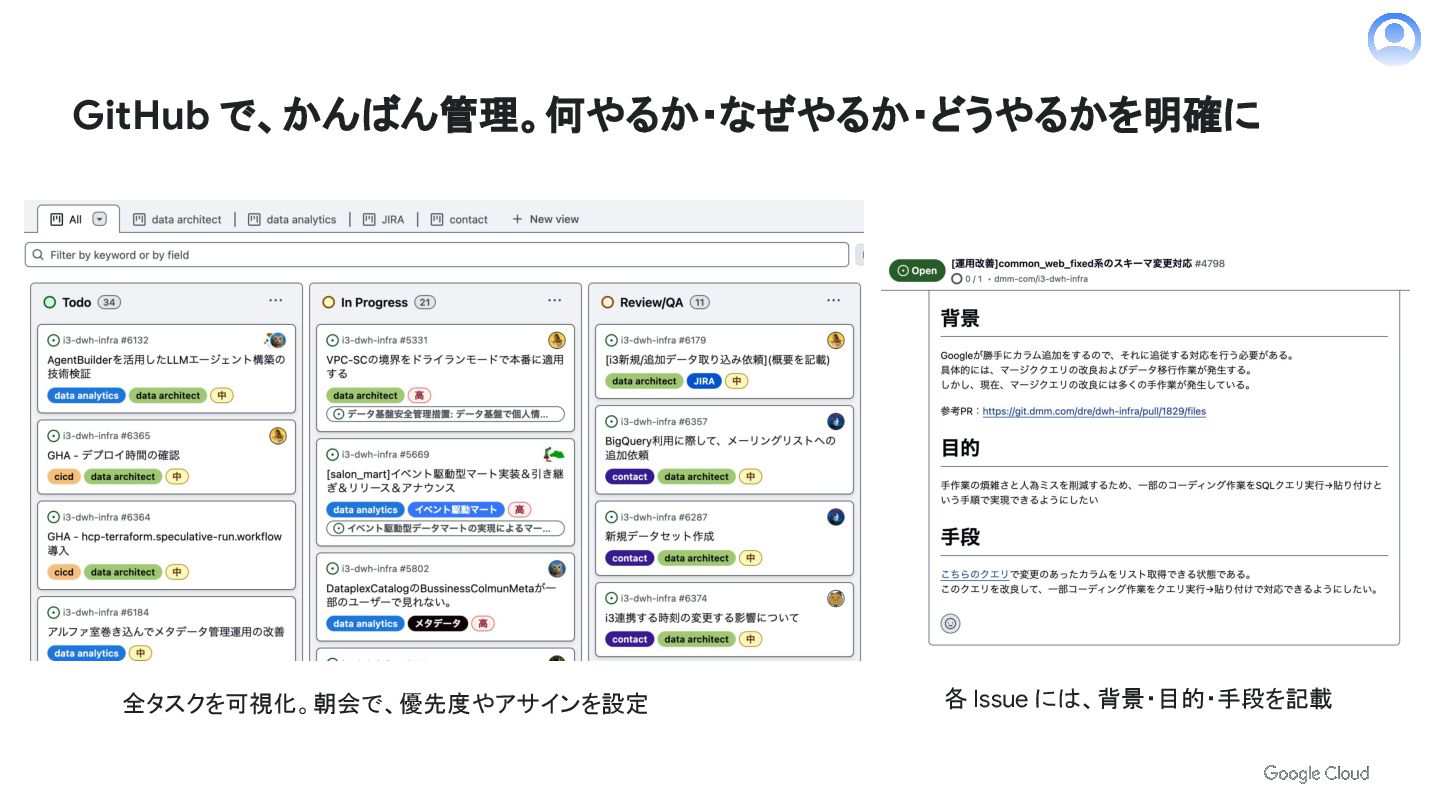
GitHub で、かんばん管理。何やるか・なぜやるか・どうやるかを明確に 全タスクを可視化。朝会で、優先度やアサインを設定 各 Issue には、背景・目的・手段を記載
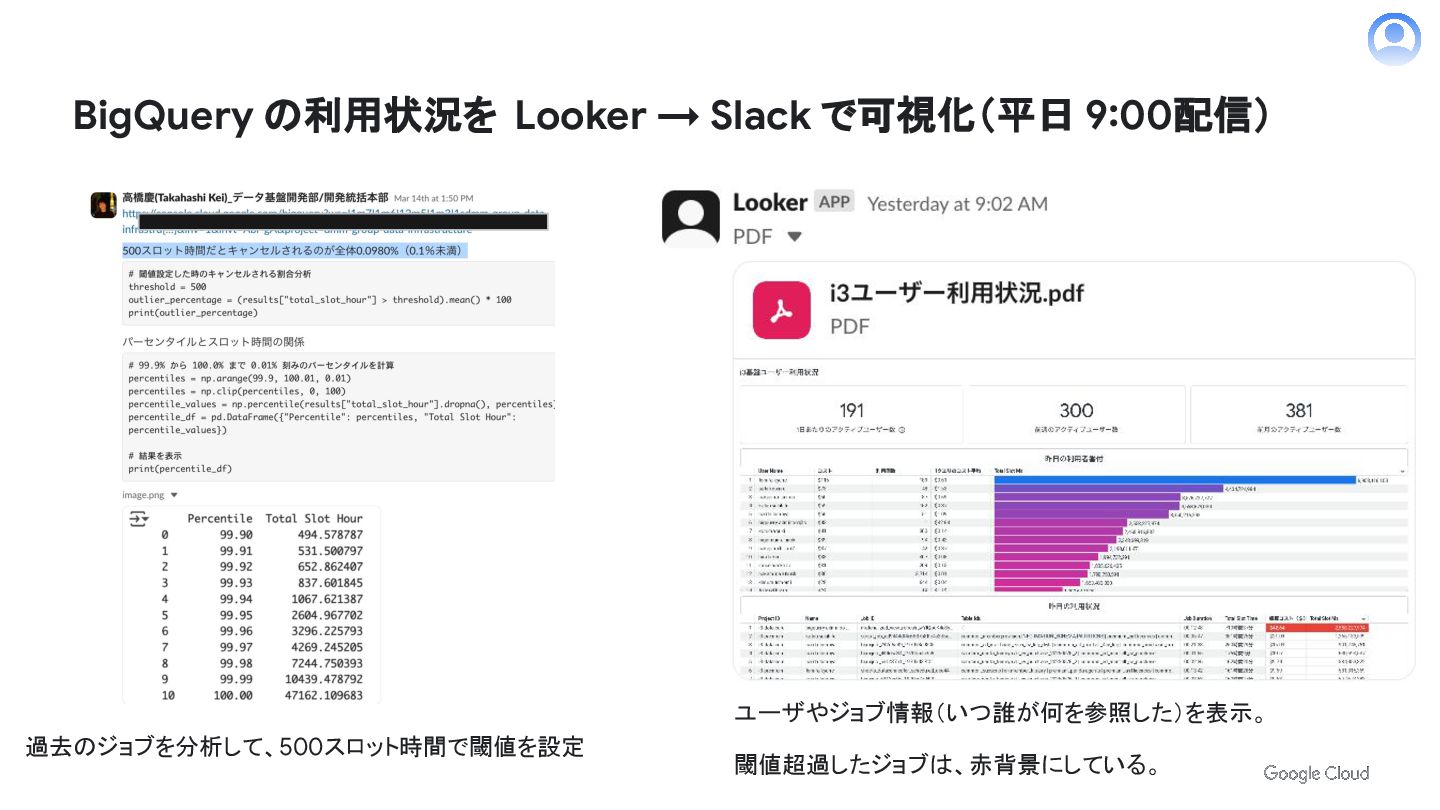
BigQuery の利用状況を Looker → Slack で可視化(平日 9:00配信) 過去のジョブを分析して、500スロット時間で閾値を設定 ユーザやジョブ情報(いつ誰が何を参照した)を表示。 閾値超過したジョブは、赤背景にしている。
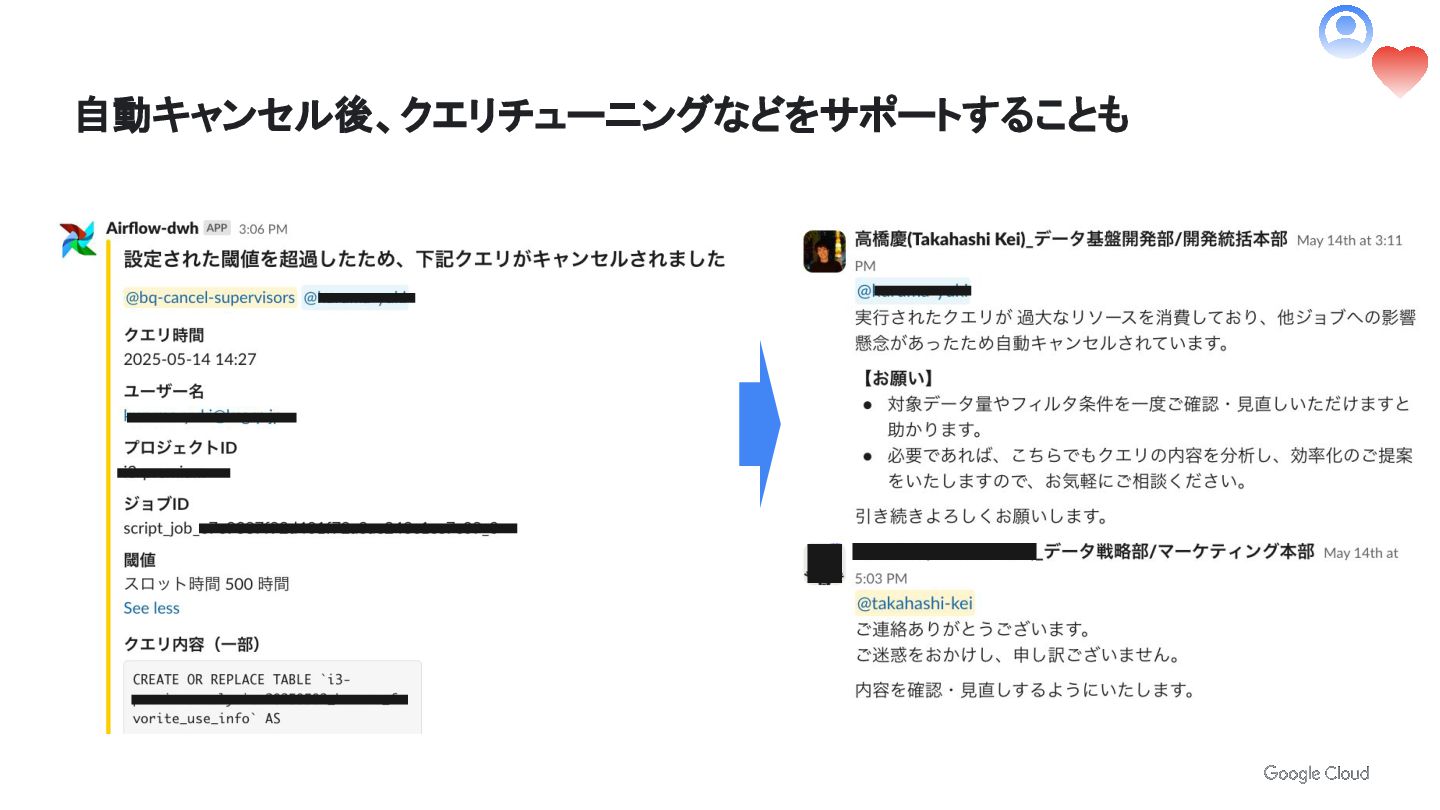
自動キャンセル後、クエリチューニングなどをサポートすることも
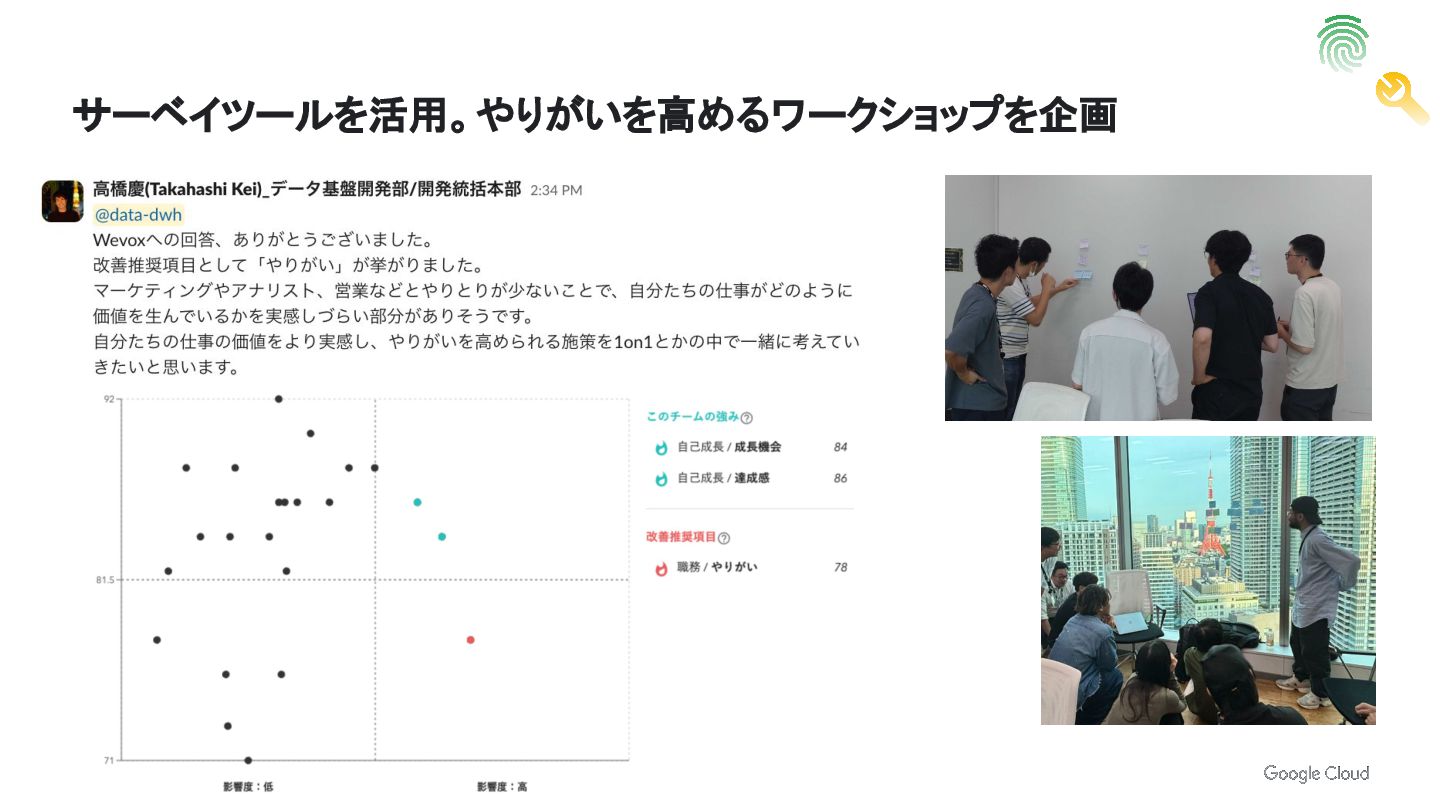
サーベイツールを活用。やりがいを高めるワークショップを企画
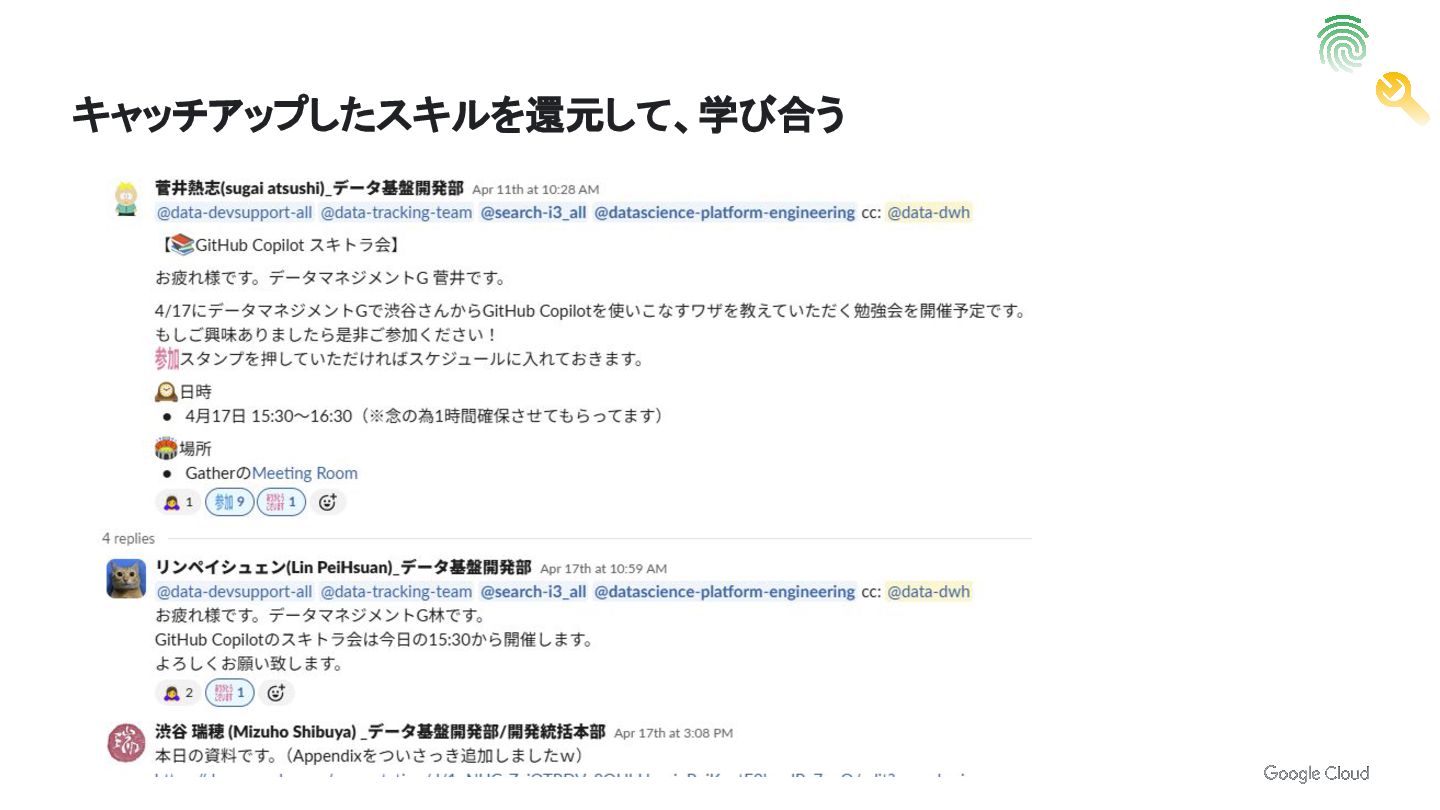
キャッチアップしたスキルを還元して、学び合う
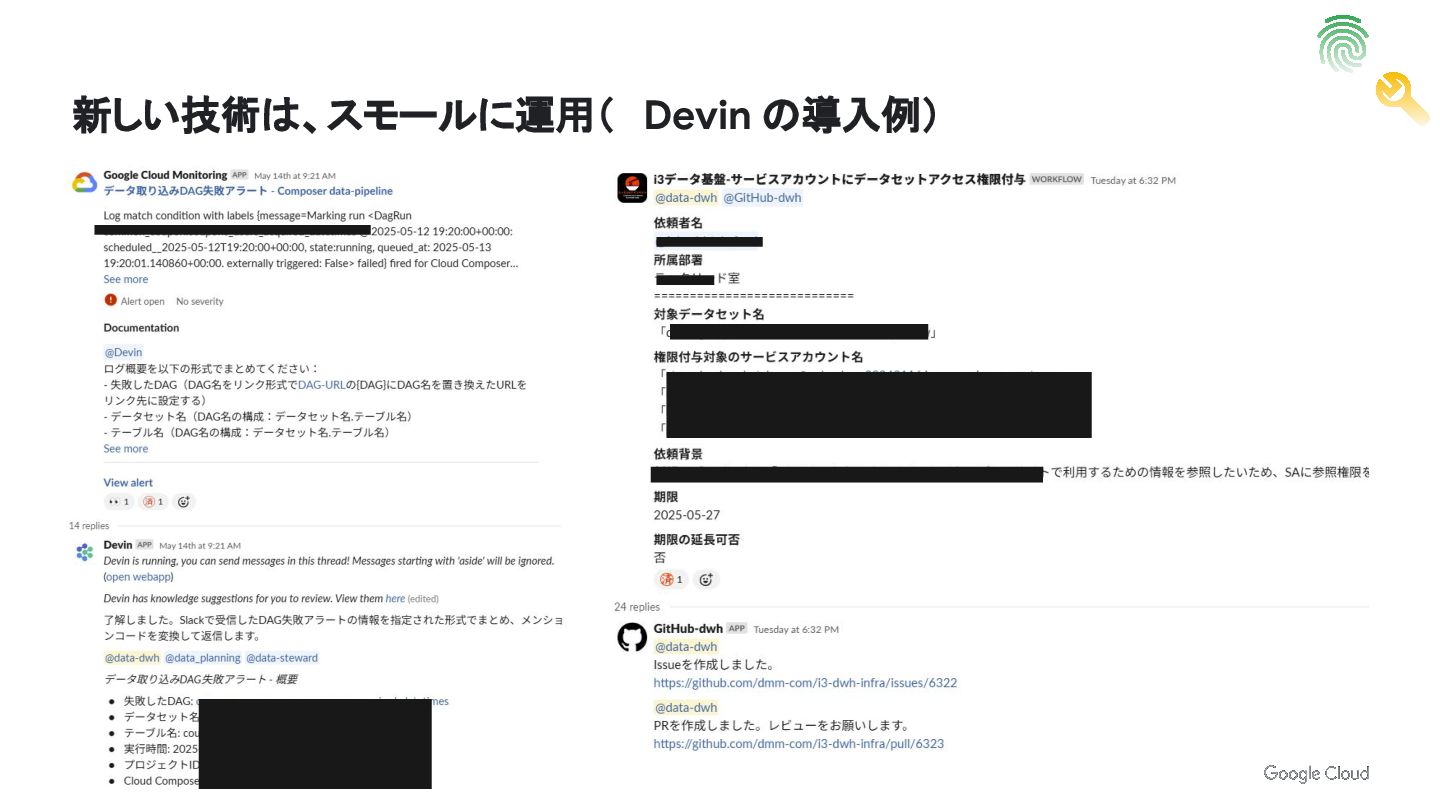
新しい技術は、スモールに運用( Devin の導入例)
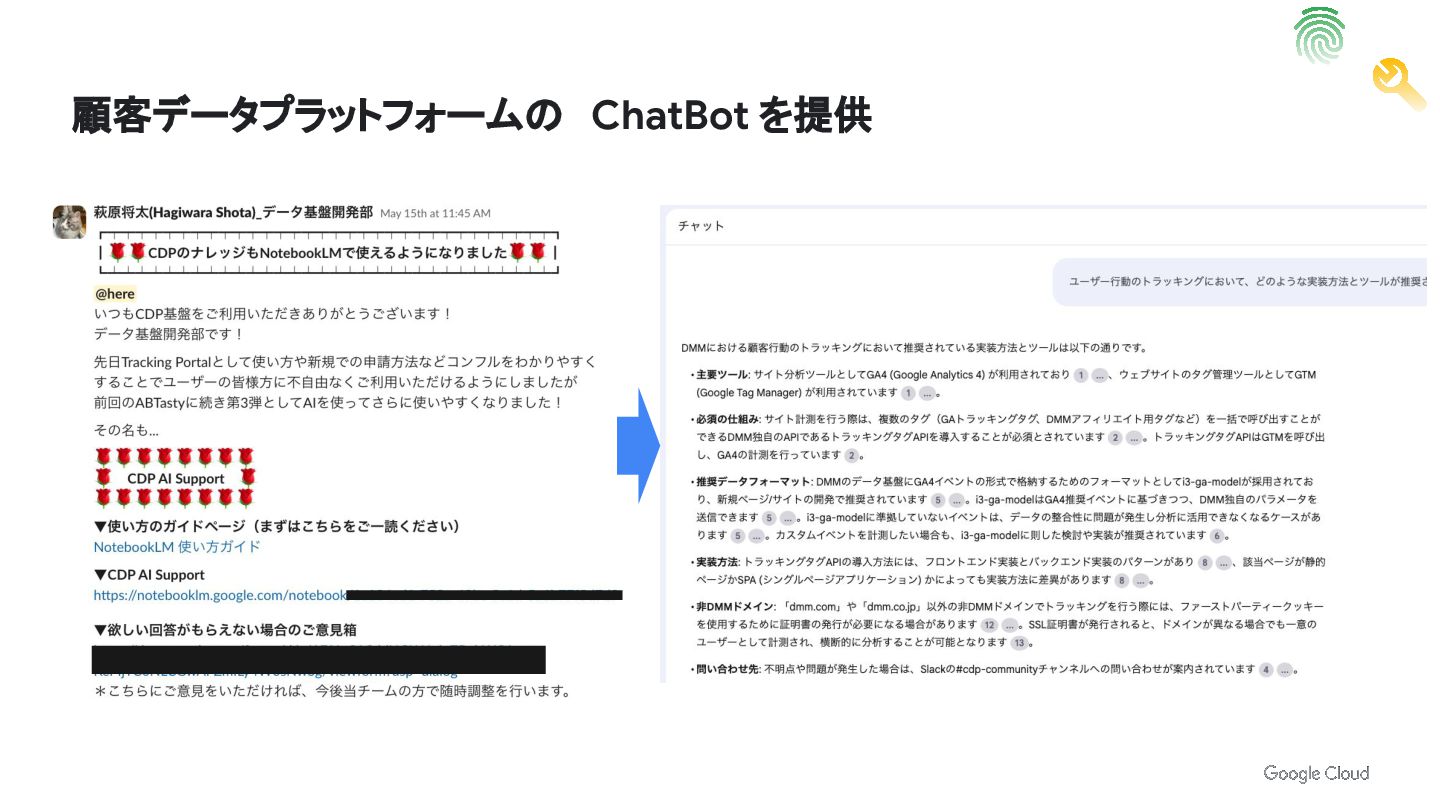
顧客データプラットフォームの ChatBot を提供
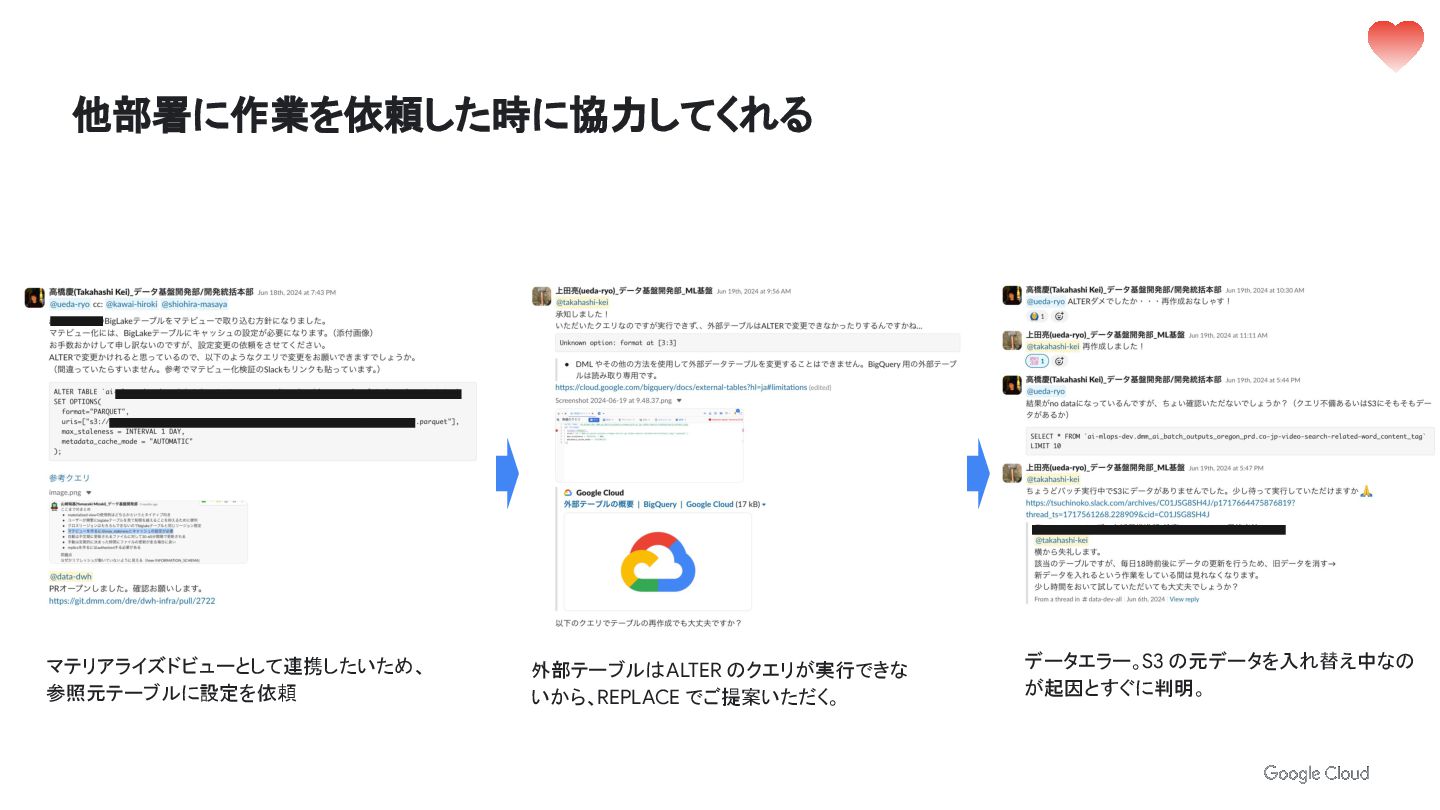
他部署に作業を依頼した時に協力してくれる マテリアライズド ビューとして連携したいため、 参照元テーブルに設定を依頼 外部テーブルは ALTER のクエリが実行できな いから、REPLACE でご提案いただく。 データエラー。S3
の元データを入れ替え中なの が起因とすぐに判明。
全社員対象としたデータ基盤ウェビナーを定期開催 (100~200 名が参加)
おわりに 現場の取り組みで感じたこと 06
任せてくれるトップがいると、その信頼に応える形で、現場が思い 切って動けるし、ものづくりに集中できる。 現場は裁量と責任を引き受けながら、チームの在り方から技術選 定、運用改善まで、自分たちで選び、動き、やり切る。 トップは、現場を信じて任せる 現場は、トップの信頼に応える
Thank you.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}