Apresentação de Análise Léxica de Compiladores que realizei no curso de graduação em Ciência da Computação (UFMA) na cadeira de Compiladores I (Setembro de 2009).
uma sequência de caracteres à procura de certos padrões e a organiza em unidades lógicas denominadas de tokens. - Cada token pode ser representado por uma determinada sequência de caracteres. - Cada token representa uma unidade de informação do programa-fonte. ANÁLISE LÉXICA
Categorias estas que são padronizadas para as diferentes linguagens de programação. - Exemplos de categorias são: - palavras reservadas (if, while, etc.); - símbolos especiais (operadores aritméticos, atribuição, etc.); - identificadores (geralmente sequência de caracteres composta de letras e dígitos iniciadas por uma letra); - literais ou constantes (contantes numéricas, cadeias de caracteres) TOKENS
um reconhecimento de padrões, mostraremos um pouco dos métodos usados para execução deste processo. Estes métodos são basicamente: - Expressões Regulares - Autômatos Finitos MÉTODOS PARA ANÁLISE LÉXICA
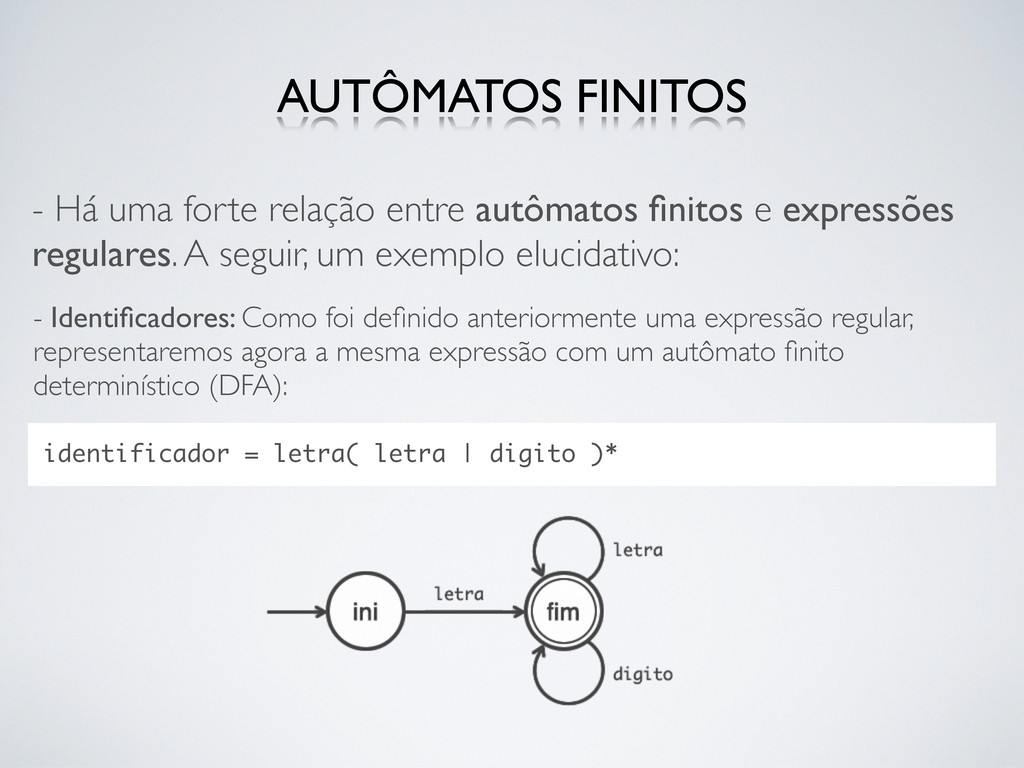
regulares. A seguir, um exemplo elucidativo: AUTÔMATOS FINITOS - Identificadores: Como foi definido anteriormente uma expressão regular, representaremos agora a mesma expressão com um autômato finito determinístico (DFA): identificador = letra( letra | digito )*
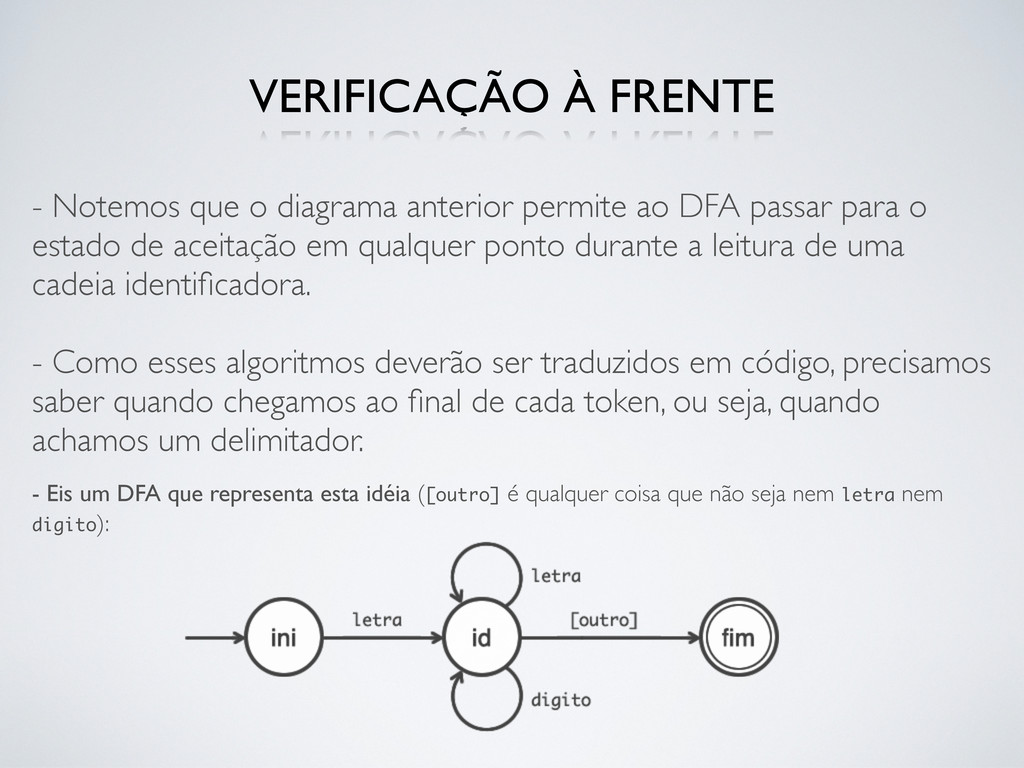
para o estado de aceitação em qualquer ponto durante a leitura de uma cadeia identificadora. - Como esses algoritmos deverão ser traduzidos em código, precisamos saber quando chegamos ao final de cada token, ou seja, quando achamos um delimitador. - Eis um DFA que representa esta idéia ([outro] é qualquer coisa que não seja nem letra nem digito): VERIFICAÇÃO À FRENTE
porém poucos algoritmos são úteis. - Algoritmos dessa natureza tendem a ser exponencialmente mais complexos devido ao número de estados que determinado autômato pode assumir. IMPLEMENTAÇÃO
como descrições de tokens. - A construção de tal algoritmo começa geralmente com expressões regulares e segue pela construção de um DFA até o programa final para Análise Léxica. ALGORITMO DE TRADUÇÃO DE UMA EXPRESSÃO REGULAR PARA DFA
regular para um NFA; - Conversão de um NFA para um DFA; - Minimização do número de estados de um DFA; - Construção de um algoritmo à partir de um DFA minimizado. ALGORITMO DE TRADUÇÃO DE UMA EXPRESSÃO REGULAR PARA DFA
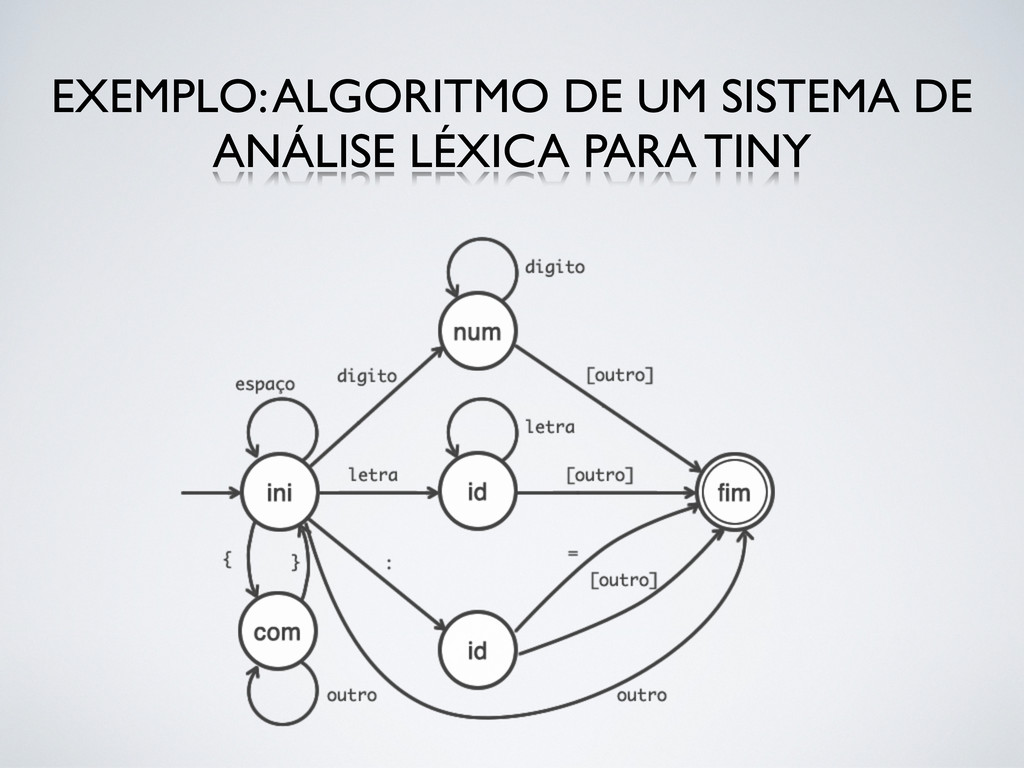
- análise léxica da linguagem TINY. É importante observar que este exemplo só diz respeito a identificação de comentários, literais numéricos, identificadores, atribuições e espaços em branco. EXEMPLO: ALGORITMO DE UM SISTEMA DE ANÁLISE LÉXICA PARA TINY
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}