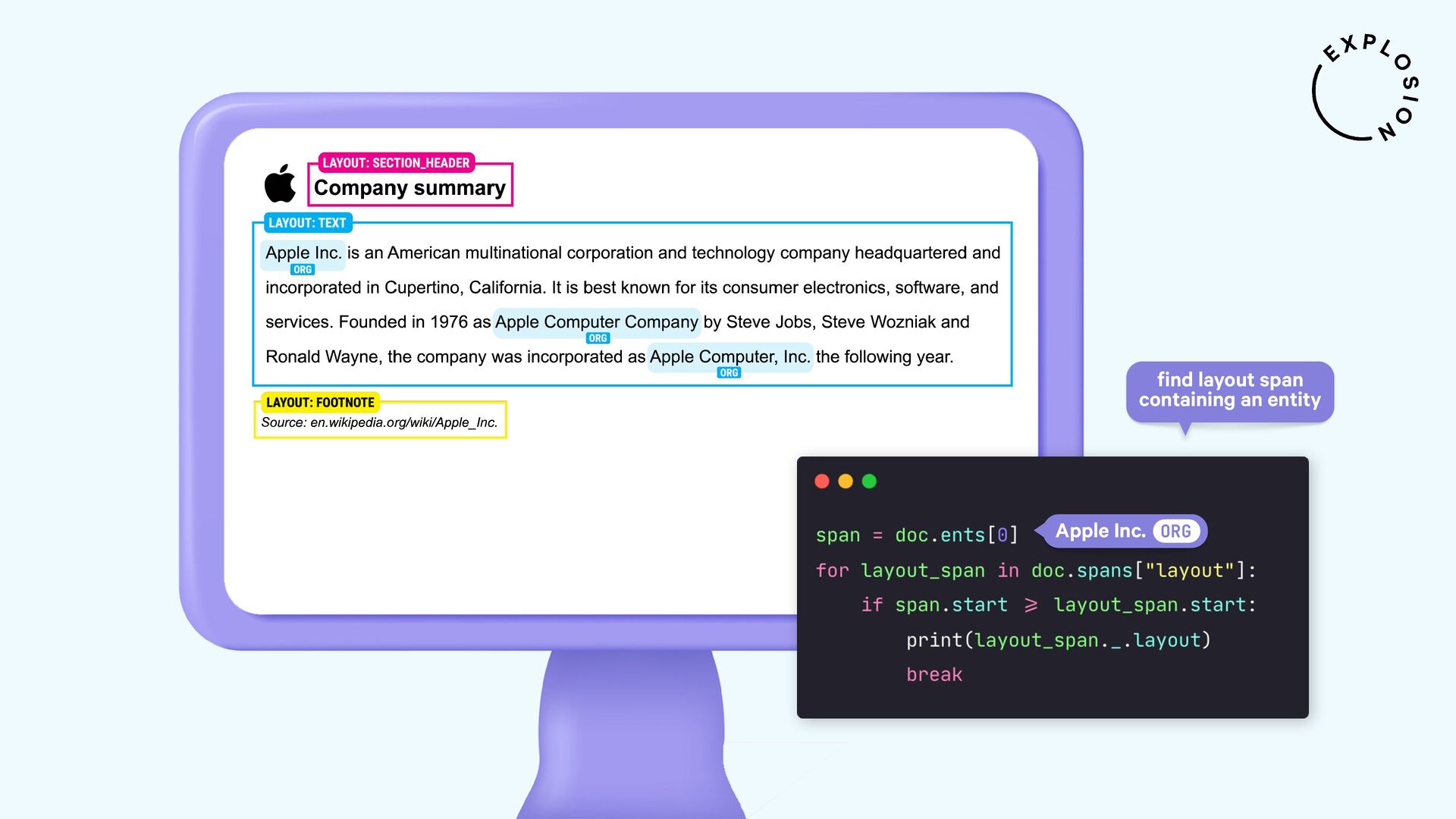
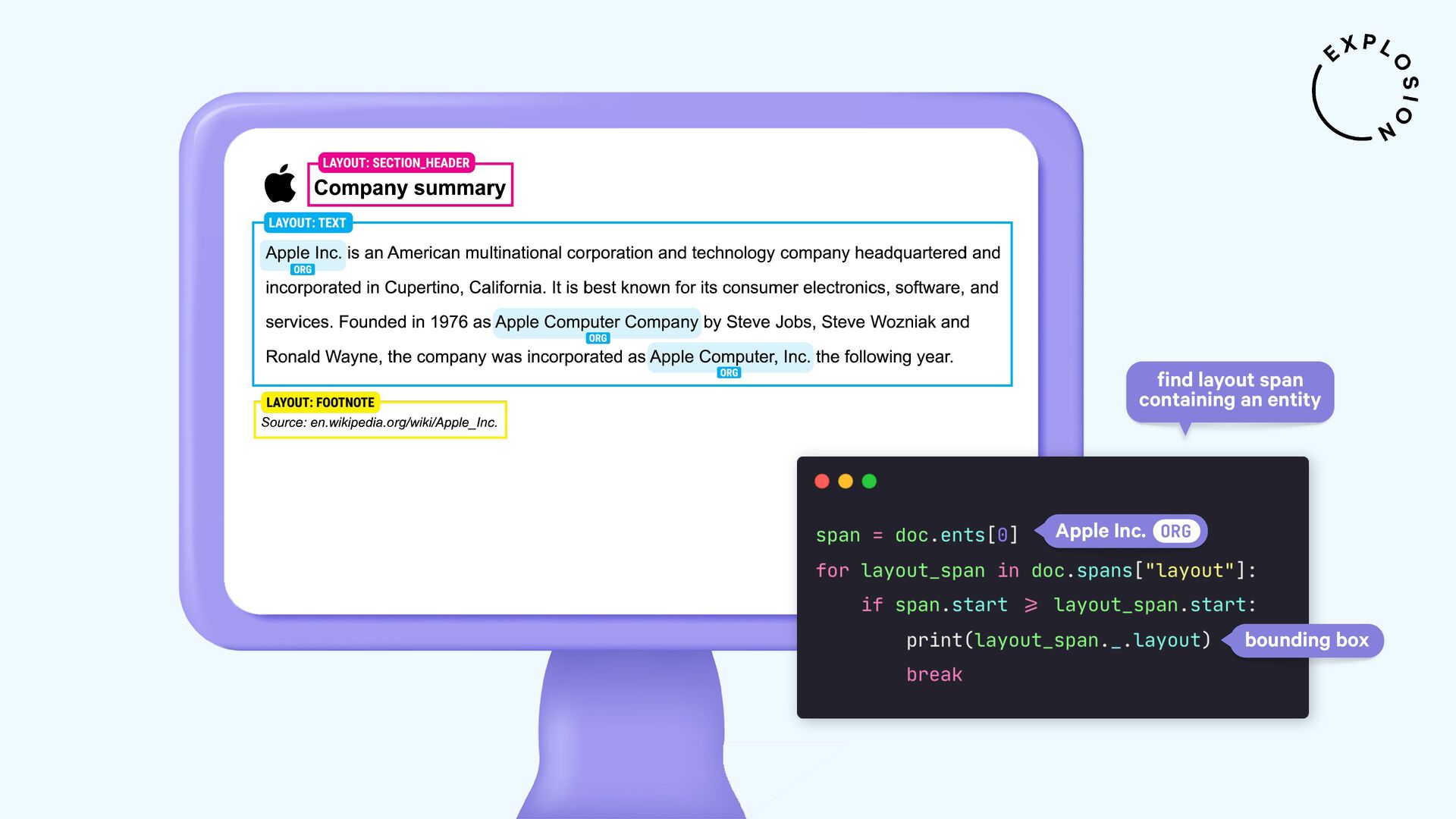
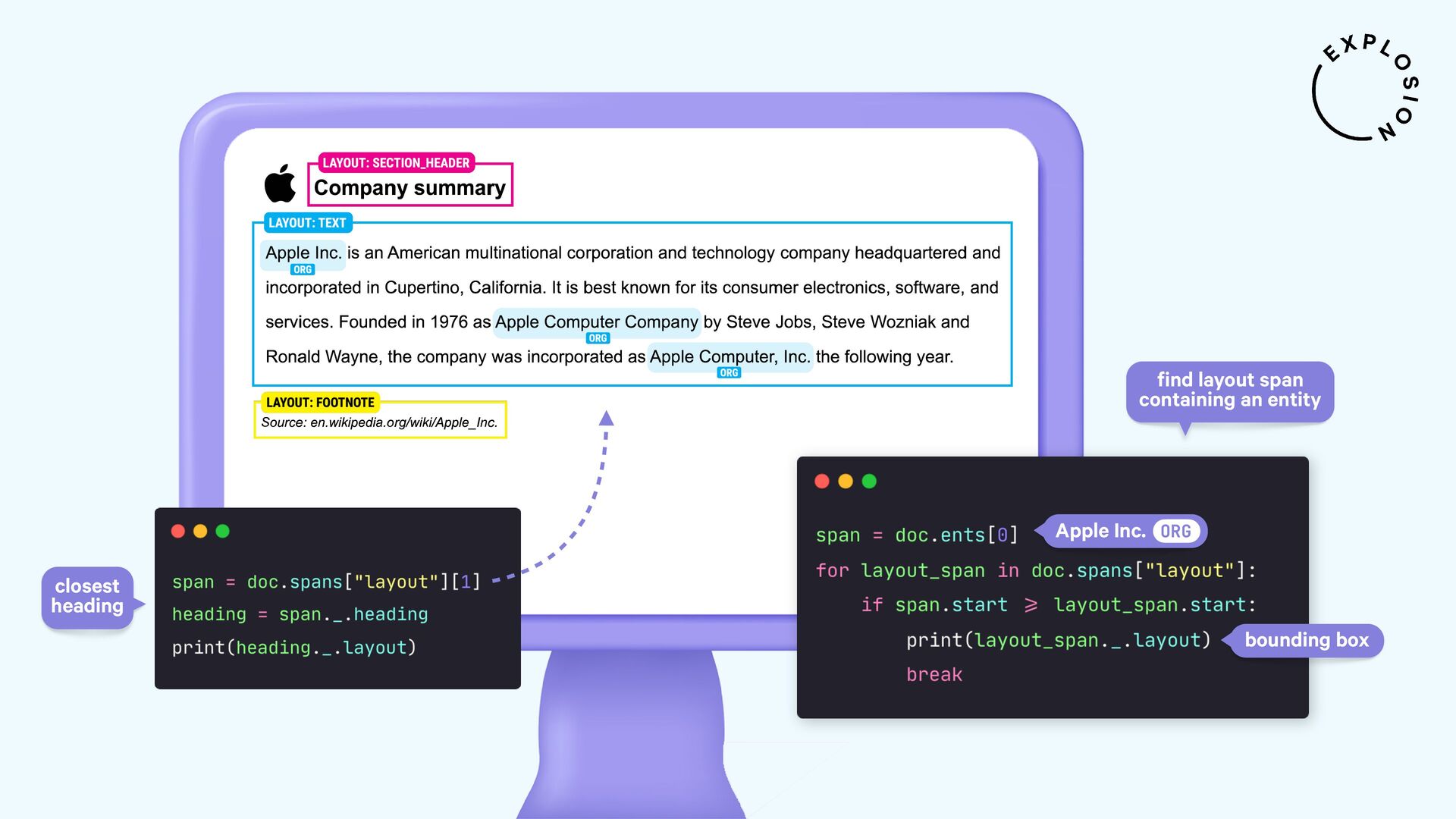
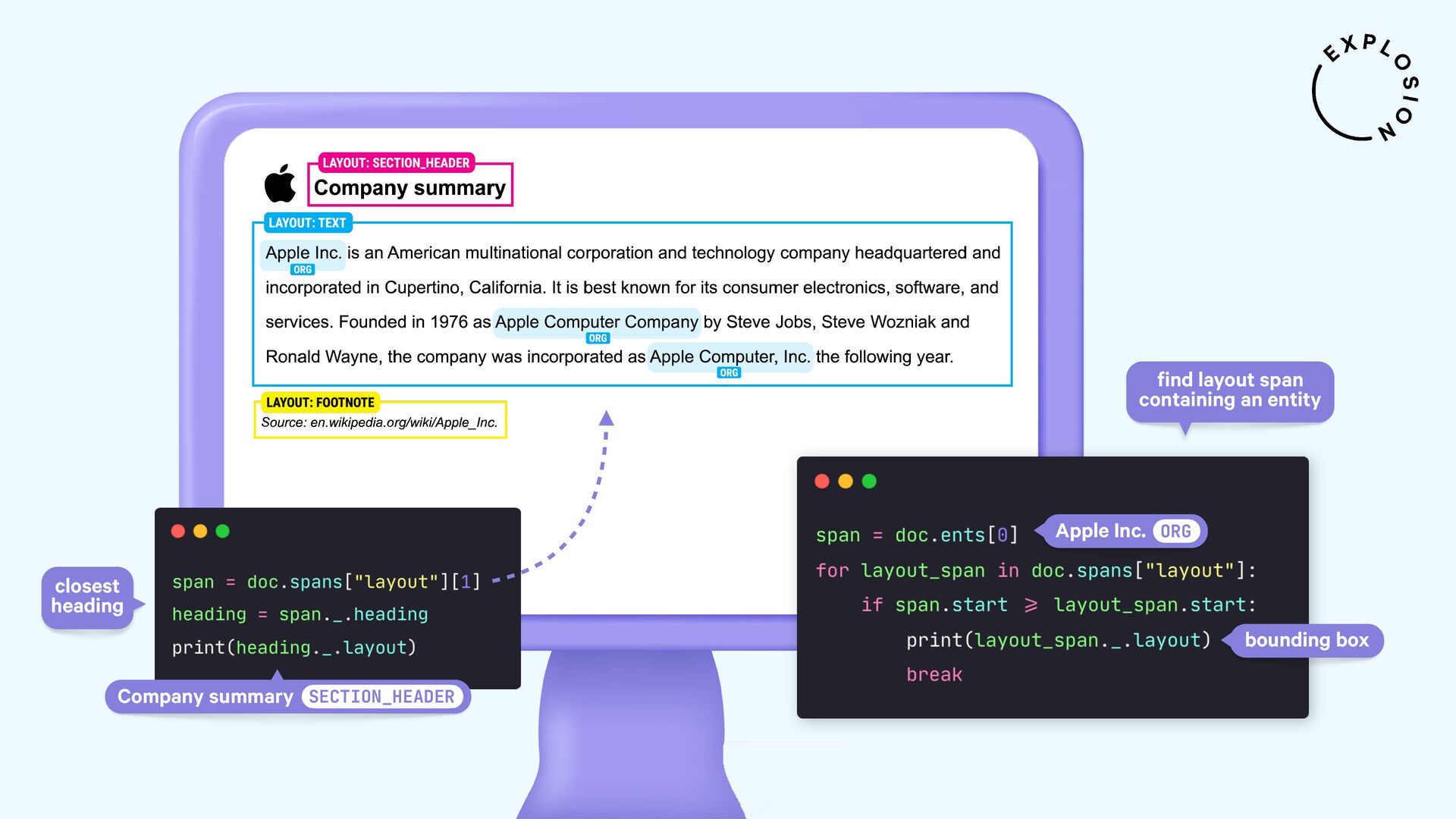
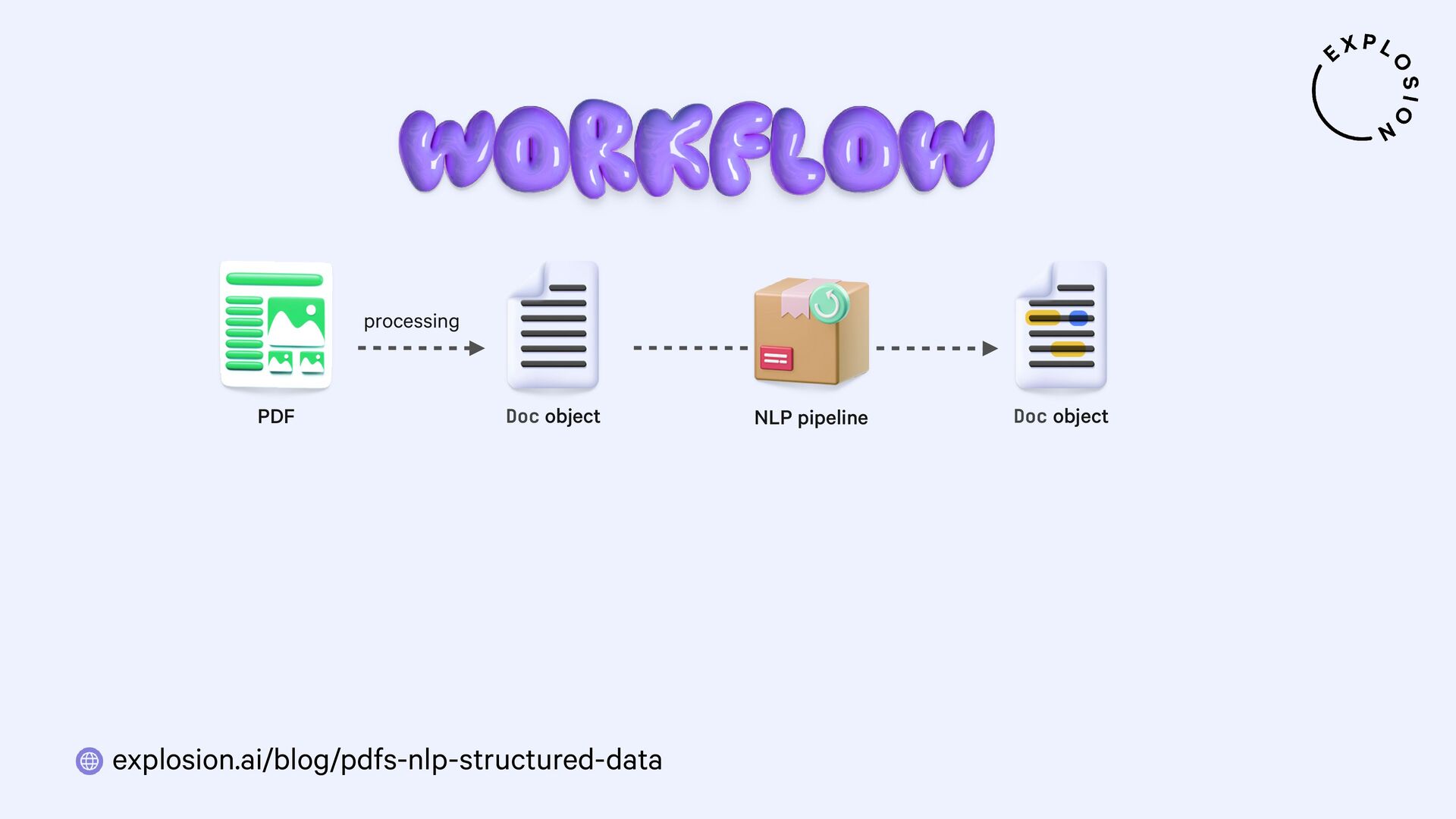
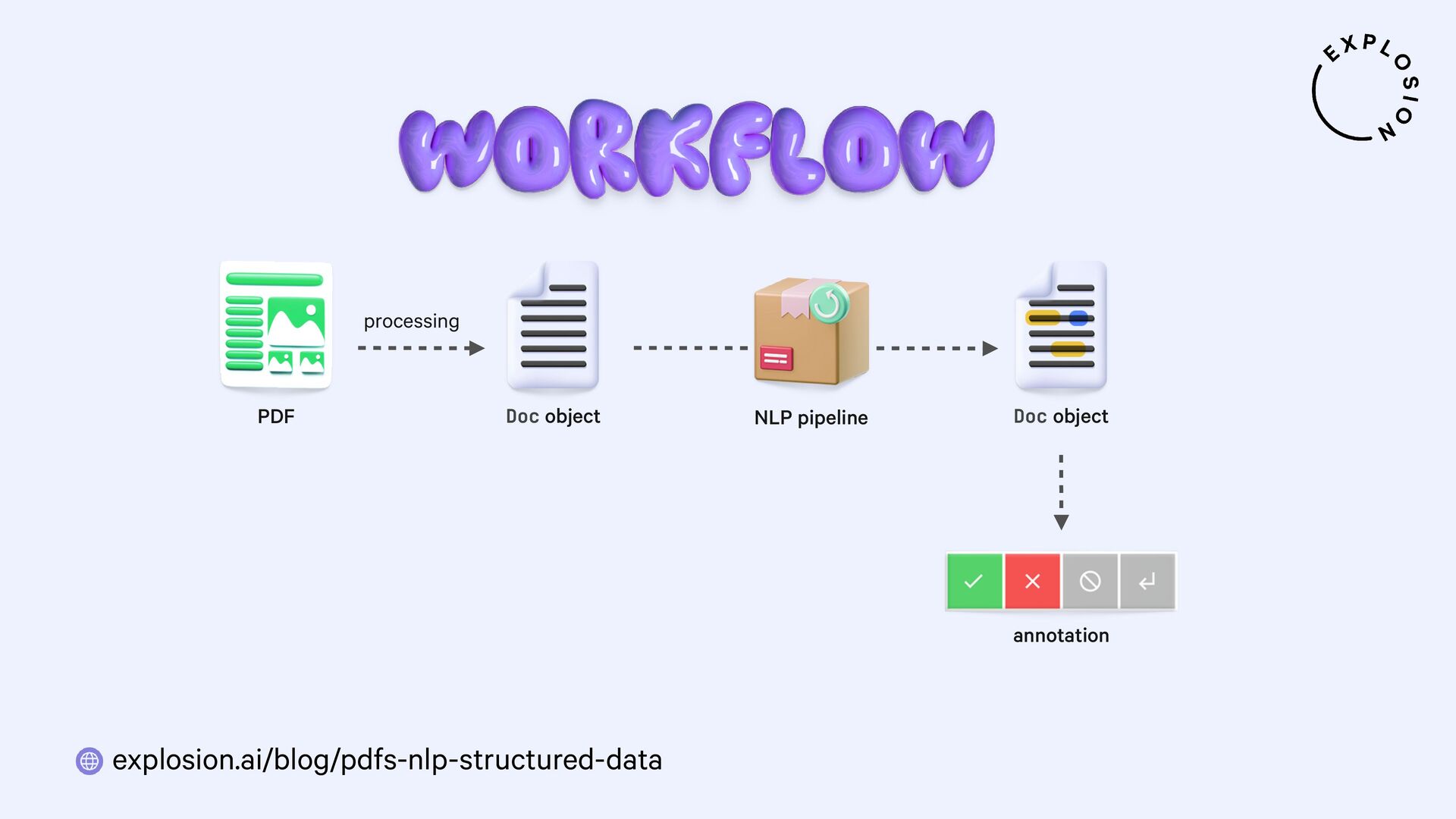
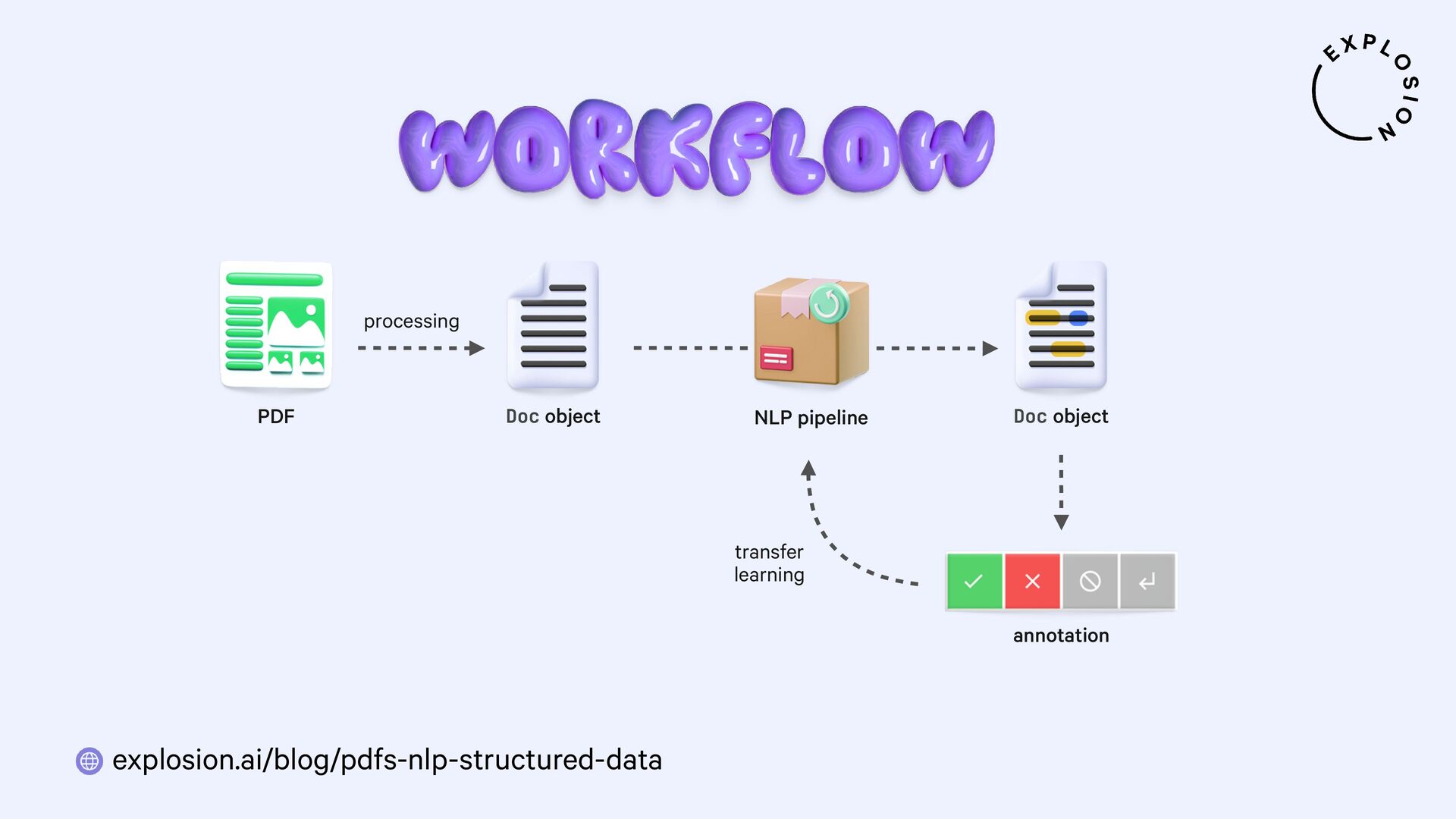
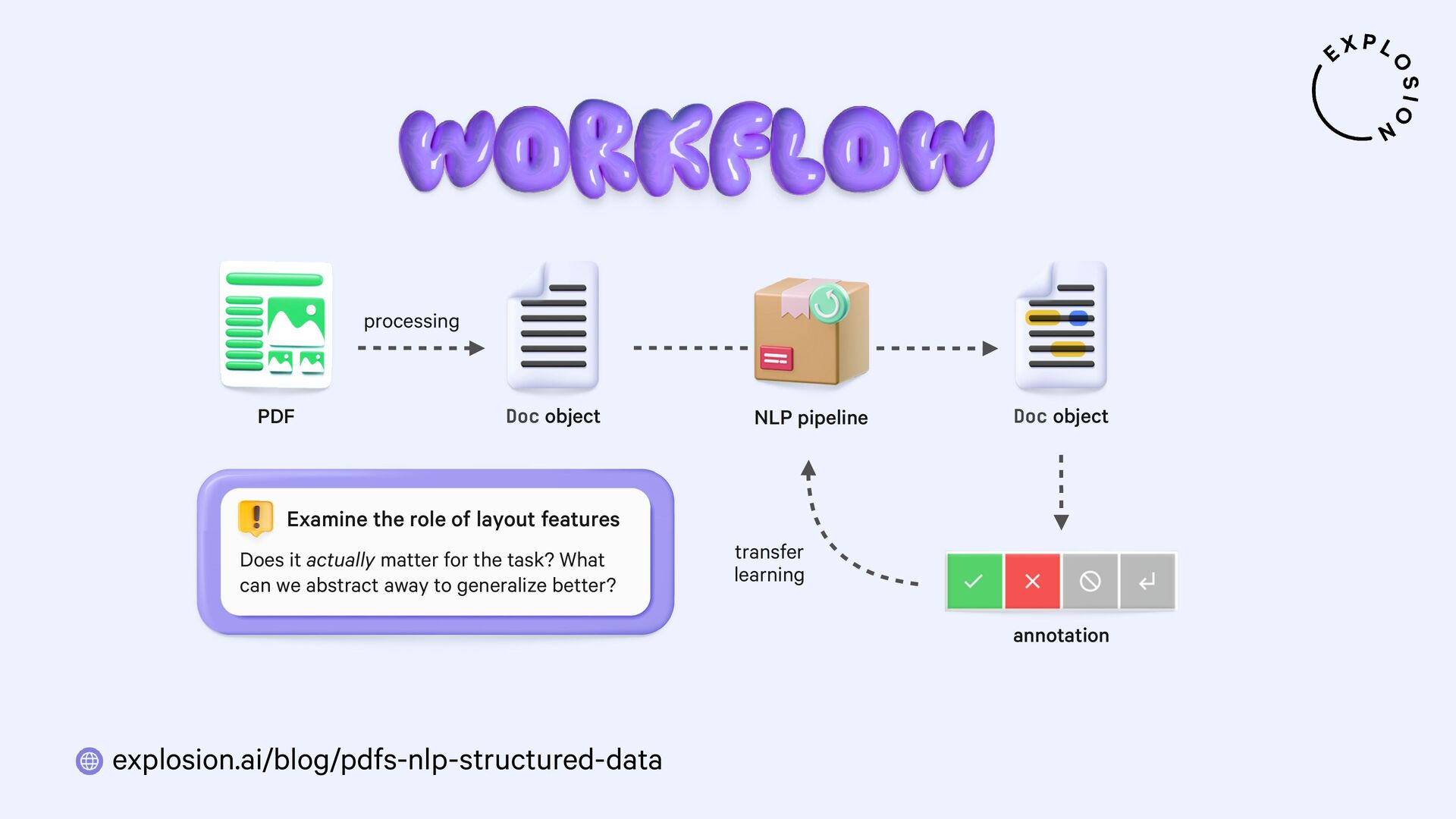
NLP and data science could be so easy if all of our data came as clean and plain text. But in practice, a lot of it is hidden away in PDFs, Word documents, scans and other formats that have been a nightmare to work with. In this talk, I'll present a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem. I'll show you how you can go from PDFs to structured data and even build fully custom information extraction pipelines for your specific use case.
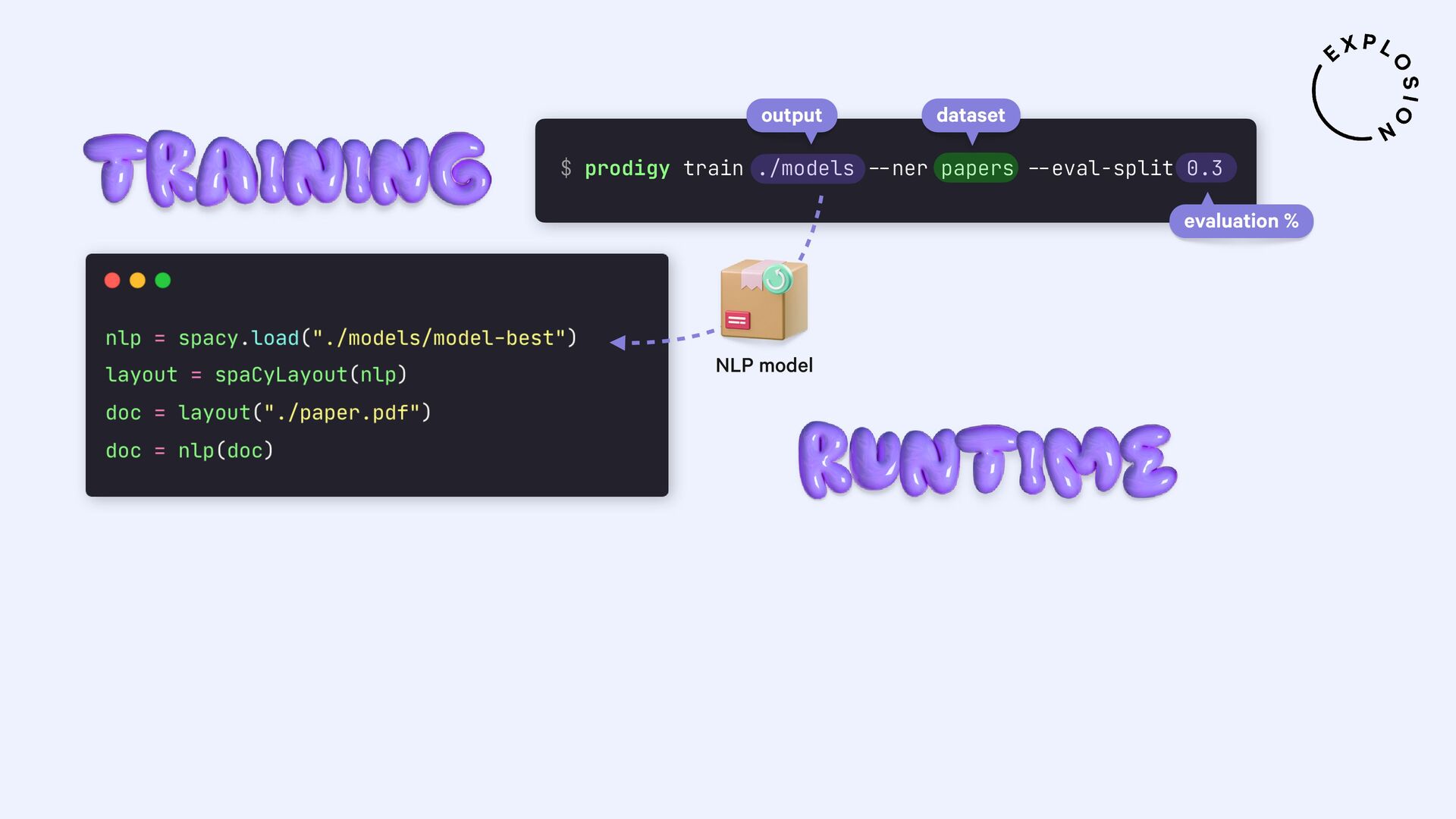
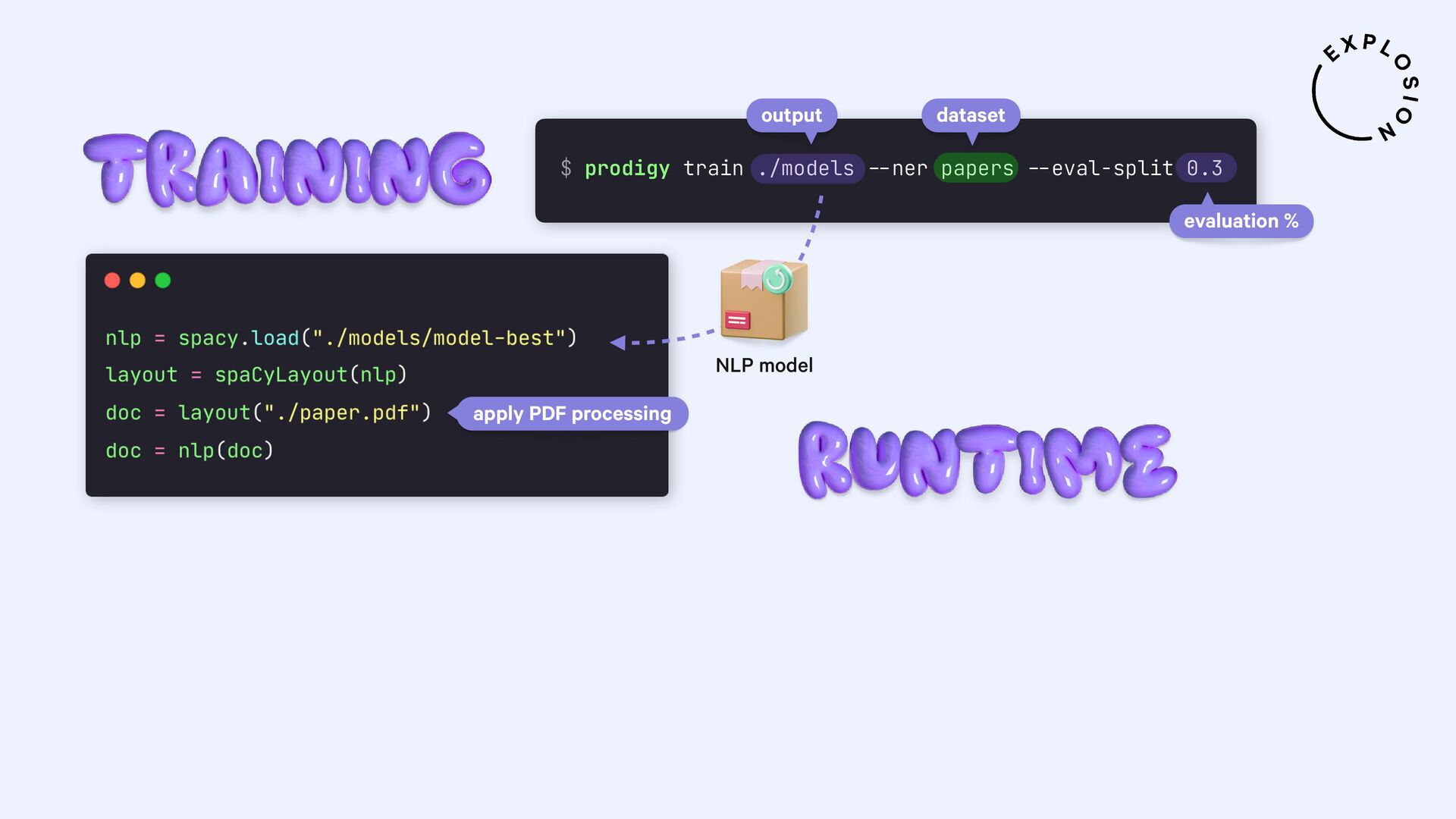
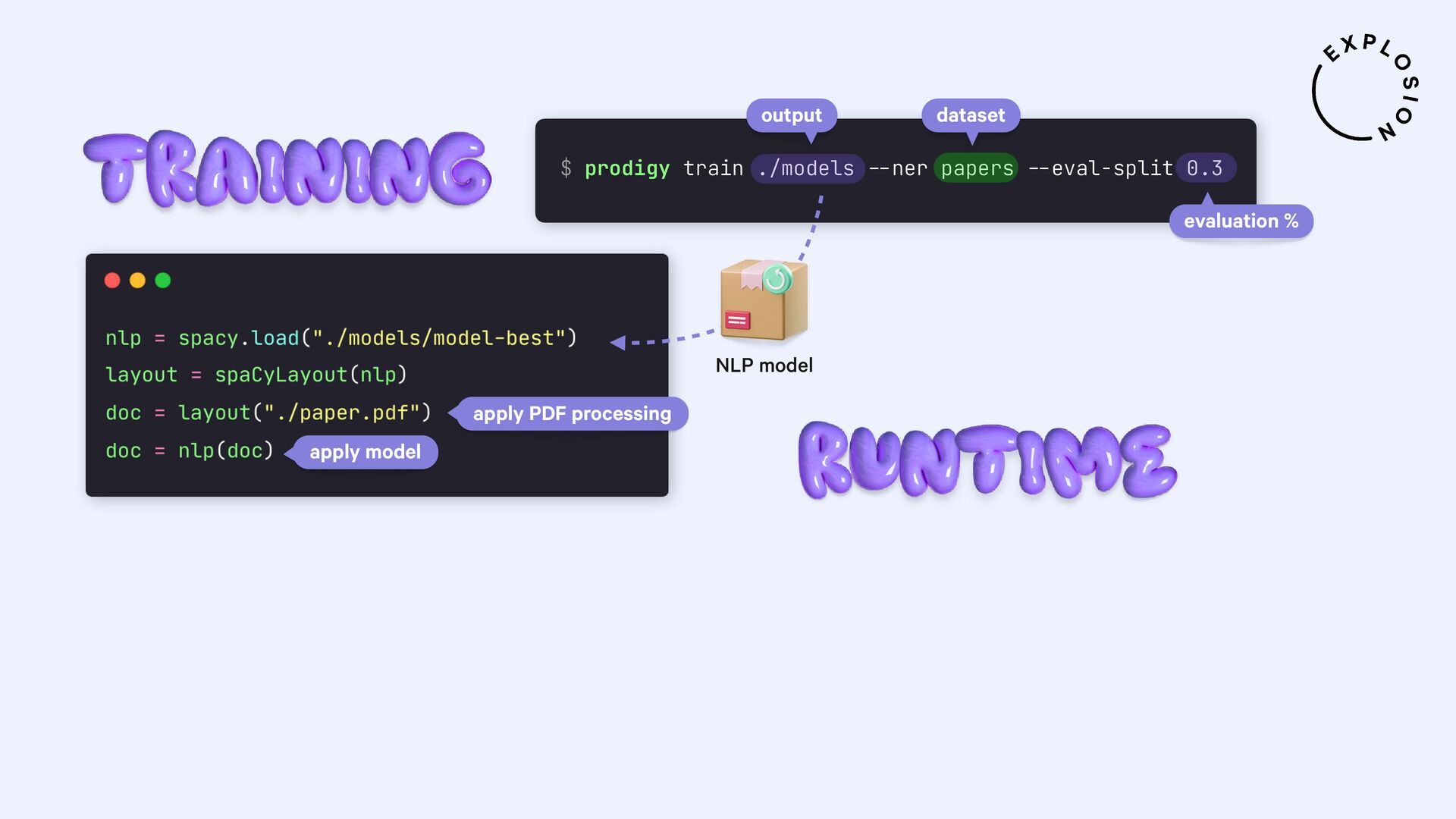
For the practical examples, I'll be using spaCy, and the new Docling library and layout analysis models. I'll also cover Optical Character Recognition (OCR) for image-based text, how to convert tabular data to pandas DataFrames, and strategies for creating training and evaluation data for information extraction tasks like text classification and entity recognition using PDFs and other documents as inputs.
Blog post: https://explosion.ai/blog/pdfs-nlp-structured-data
https://explosion.ai/blog/pdfs-nlp-structured-data
Blog post this talk is based on, featuring how to build end-to-end document understanding and information extraction pipelines for industry use cases.
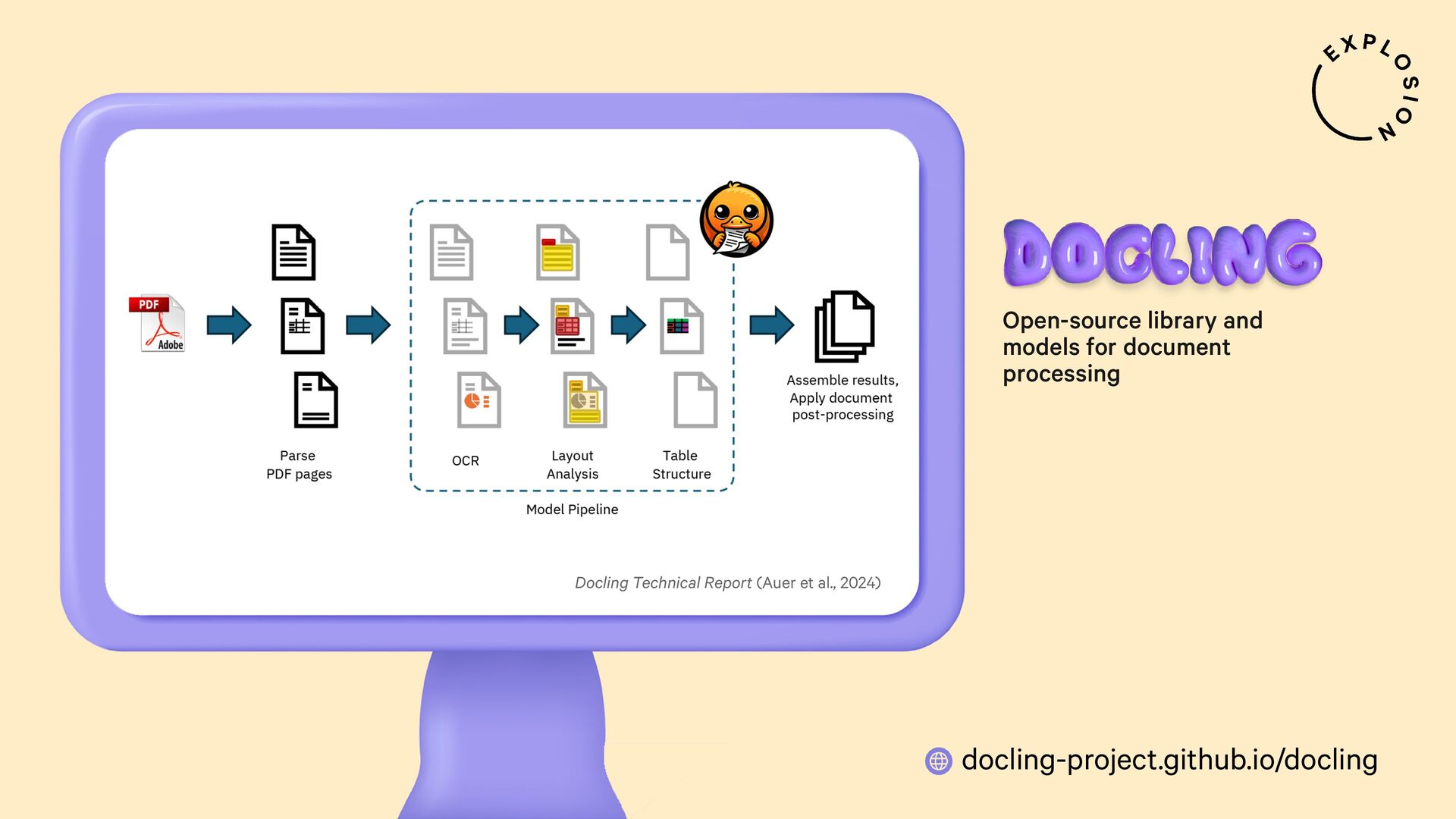
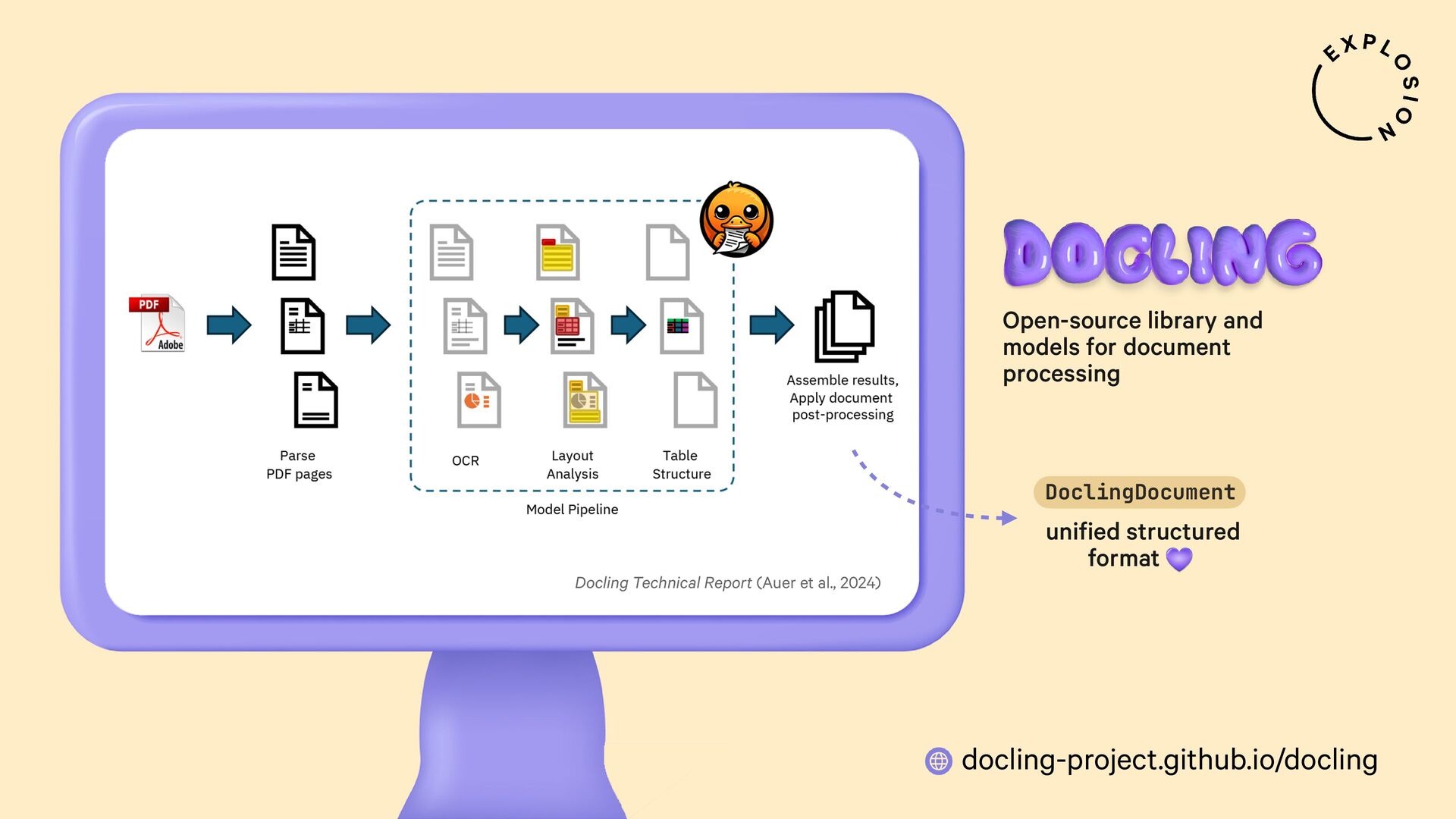
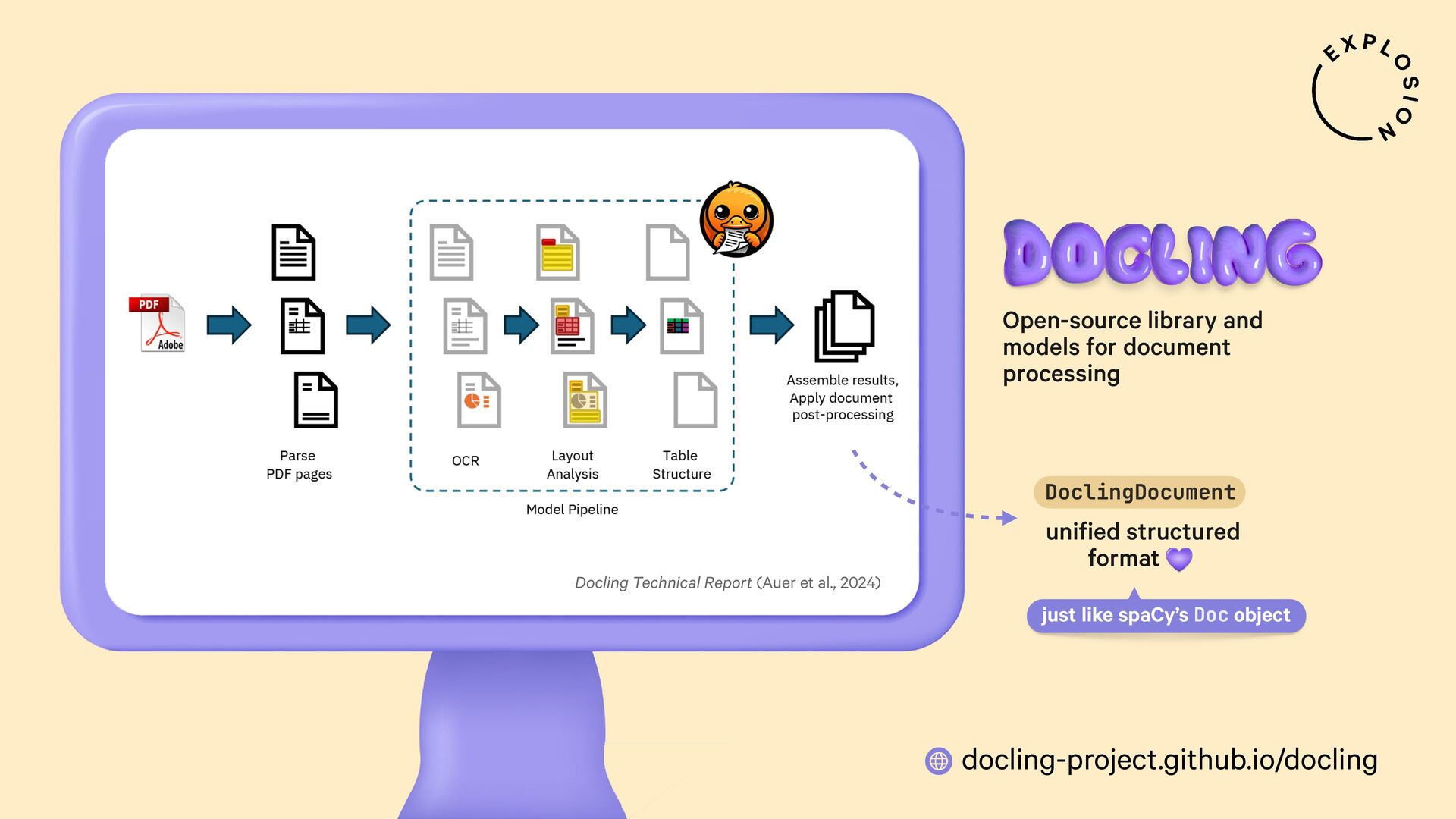
https://docling-project.github.io/docling/
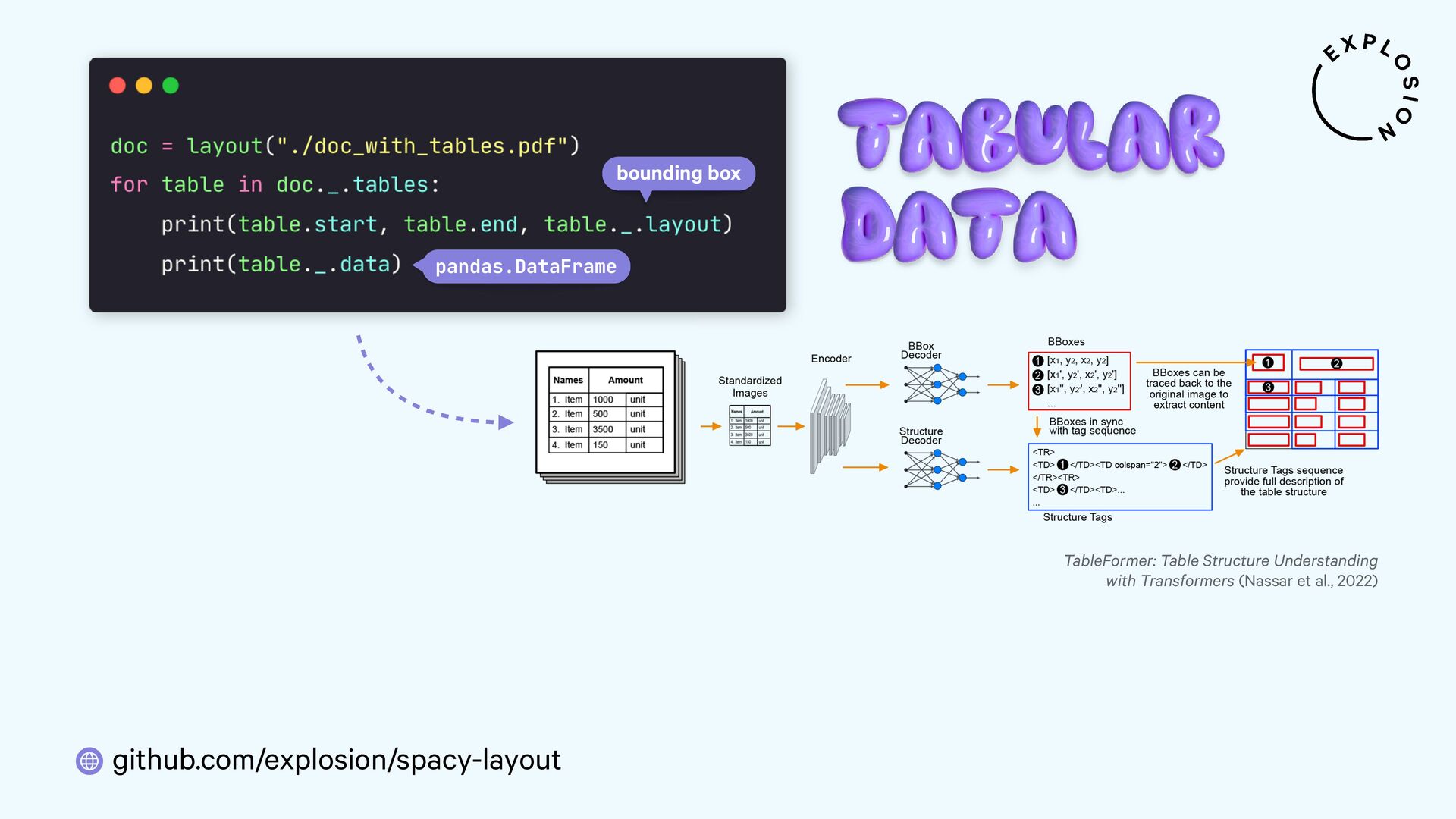
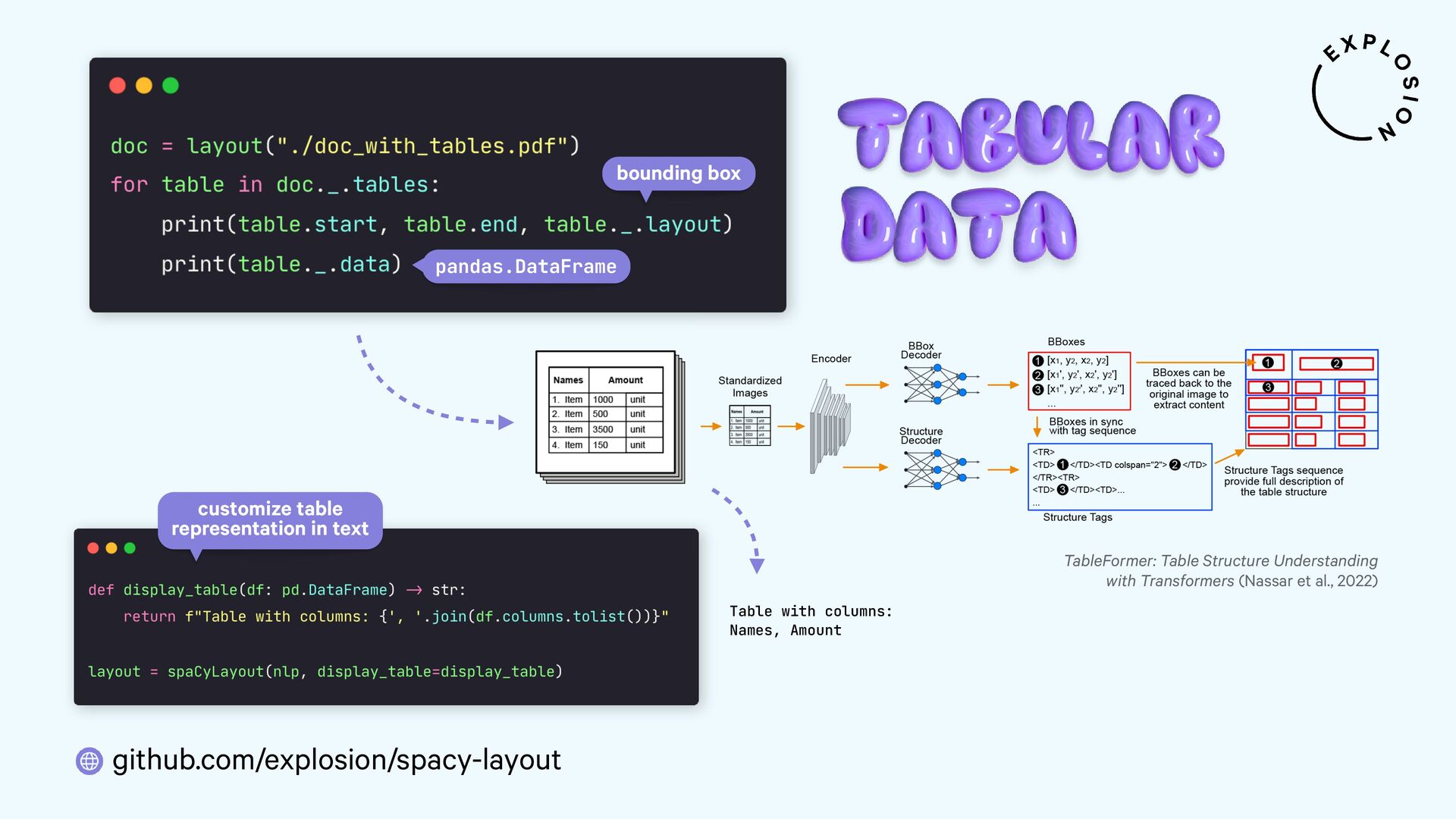
Open-source library and models for processing PDFs, Word documents and similar formats, including features for layout analysis, OCR and table structure recognition.
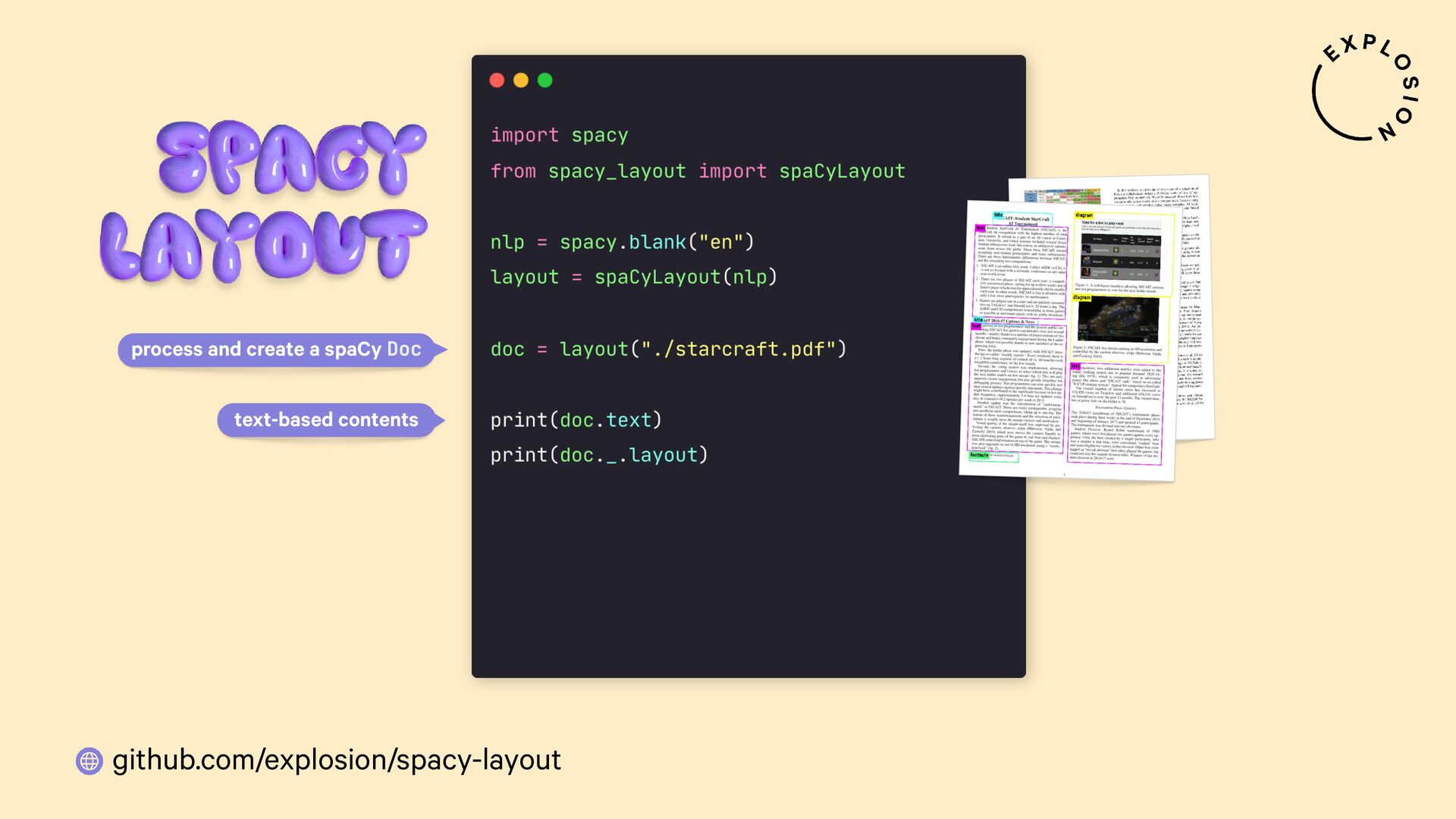
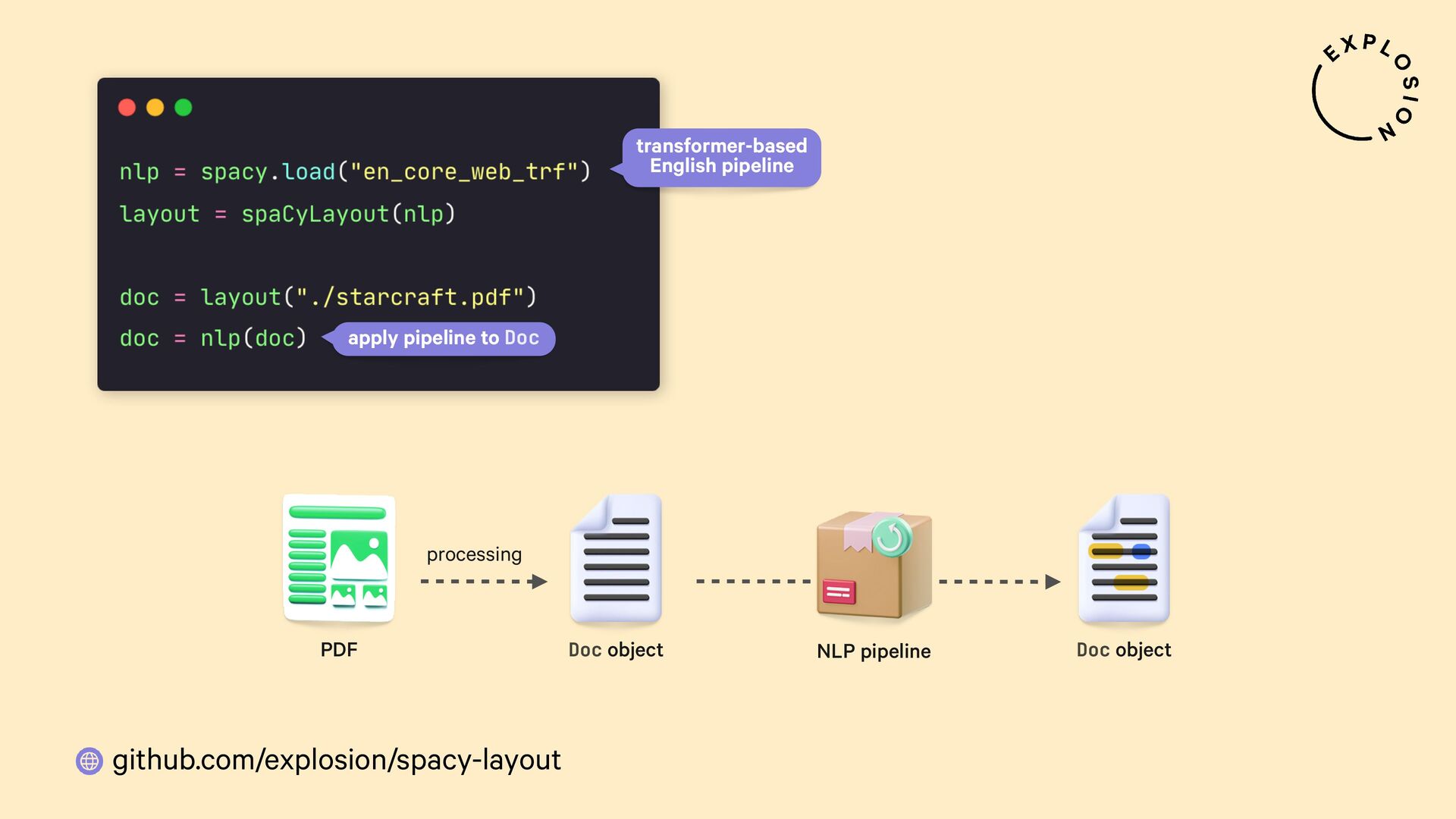
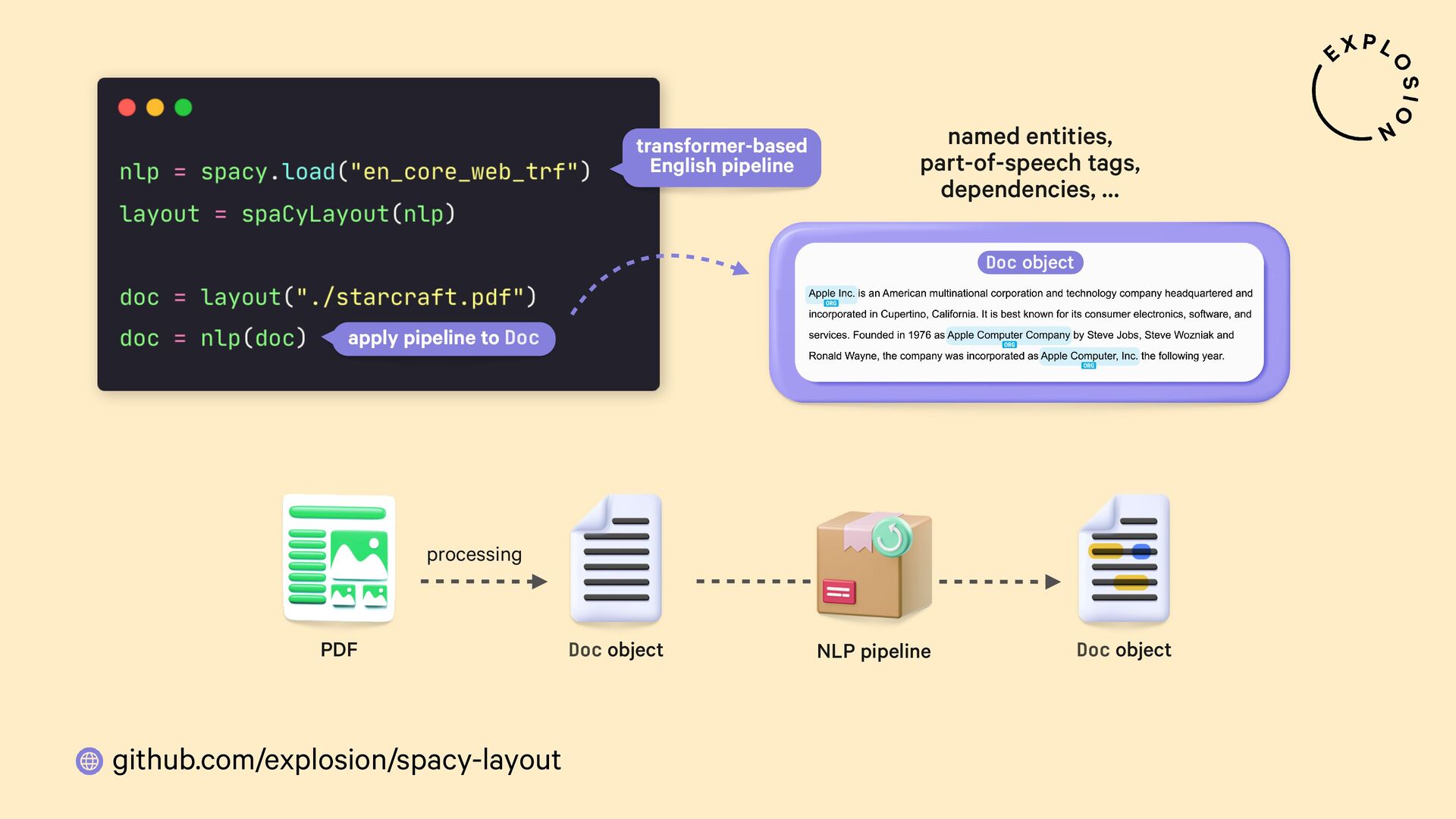
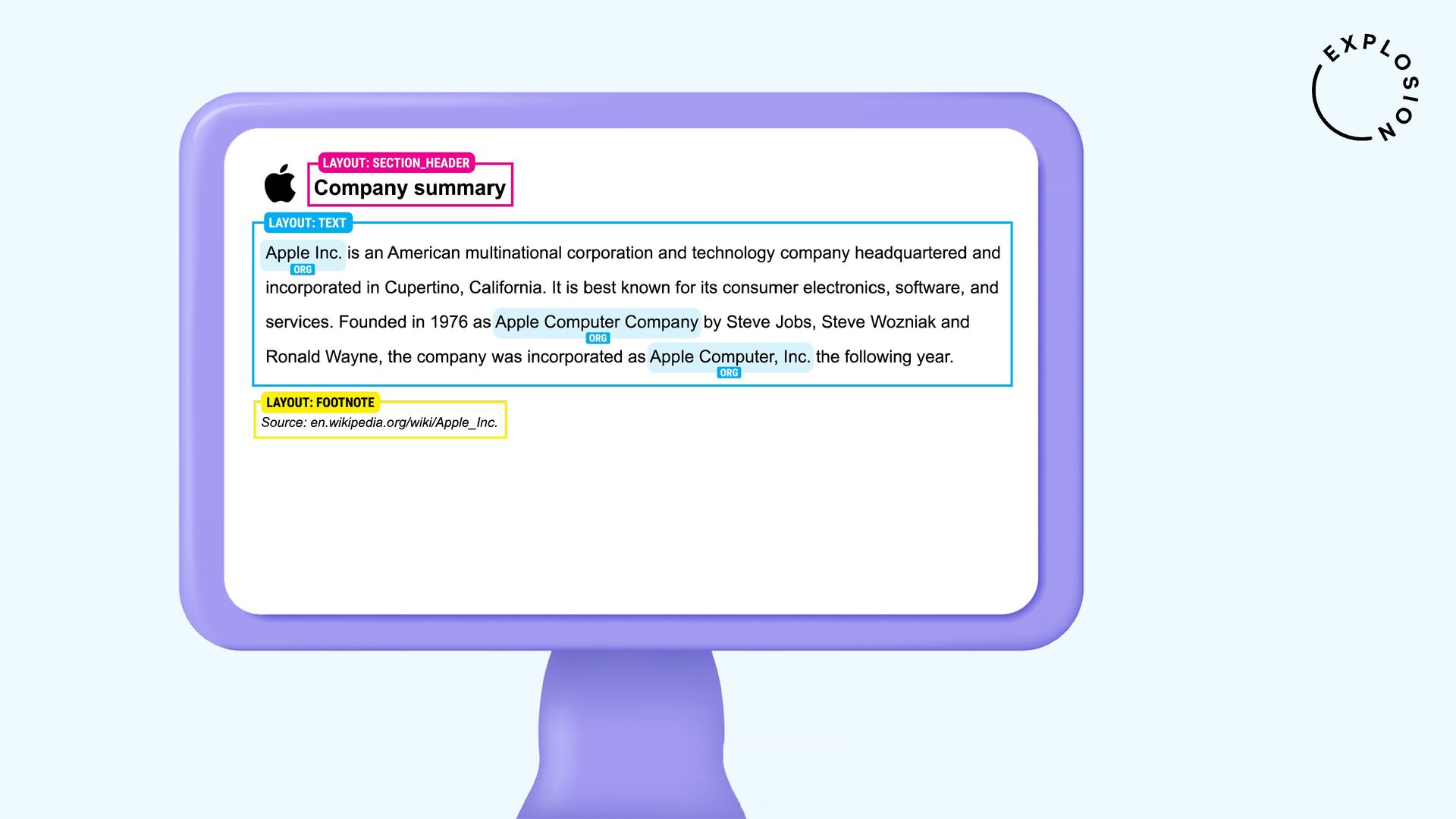
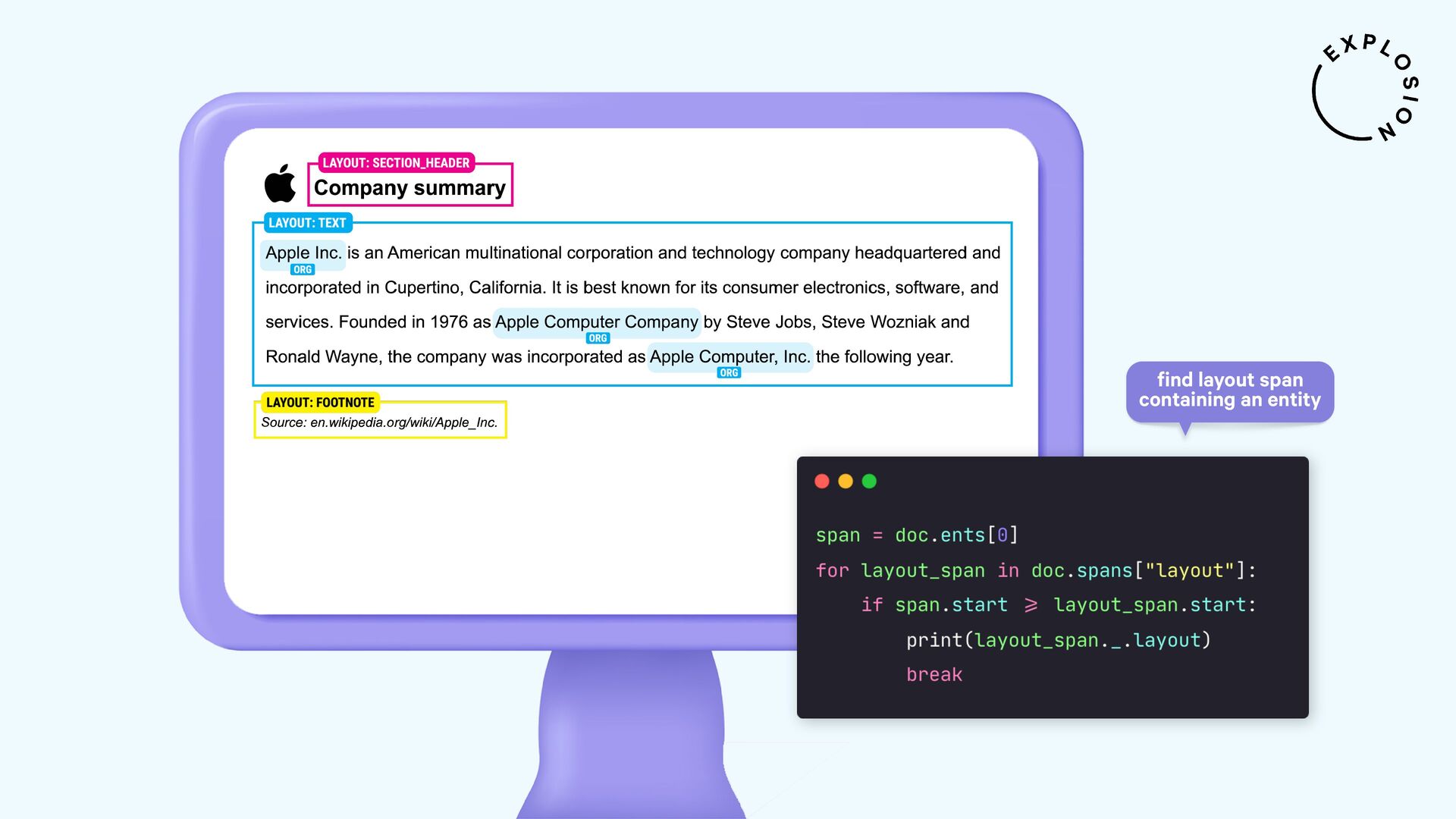
https://github.com/explosion/spacy-layout
Open-source library and plugin for processing PDFs, Word documents and more with spaCy, powered by Docling.
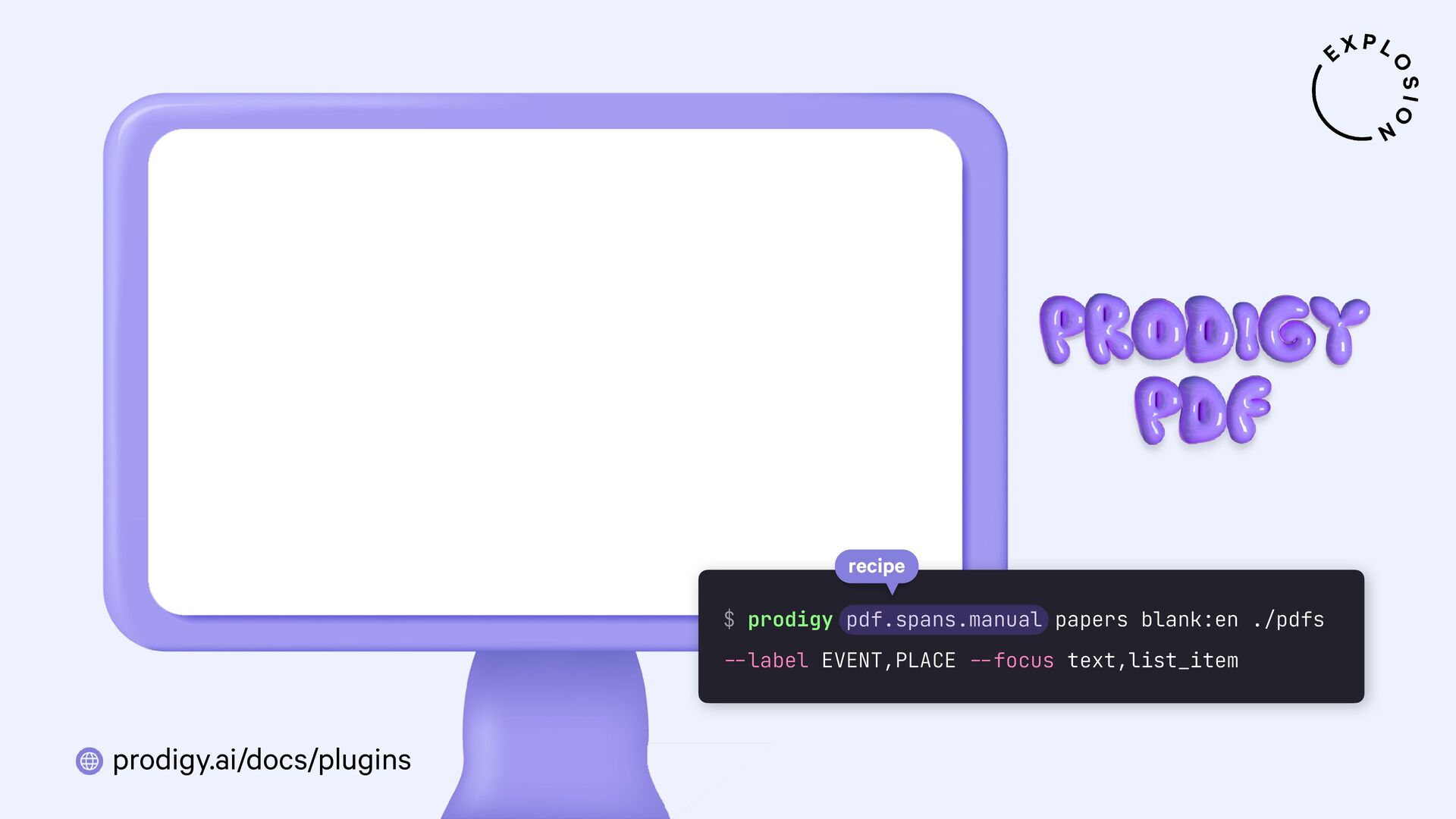
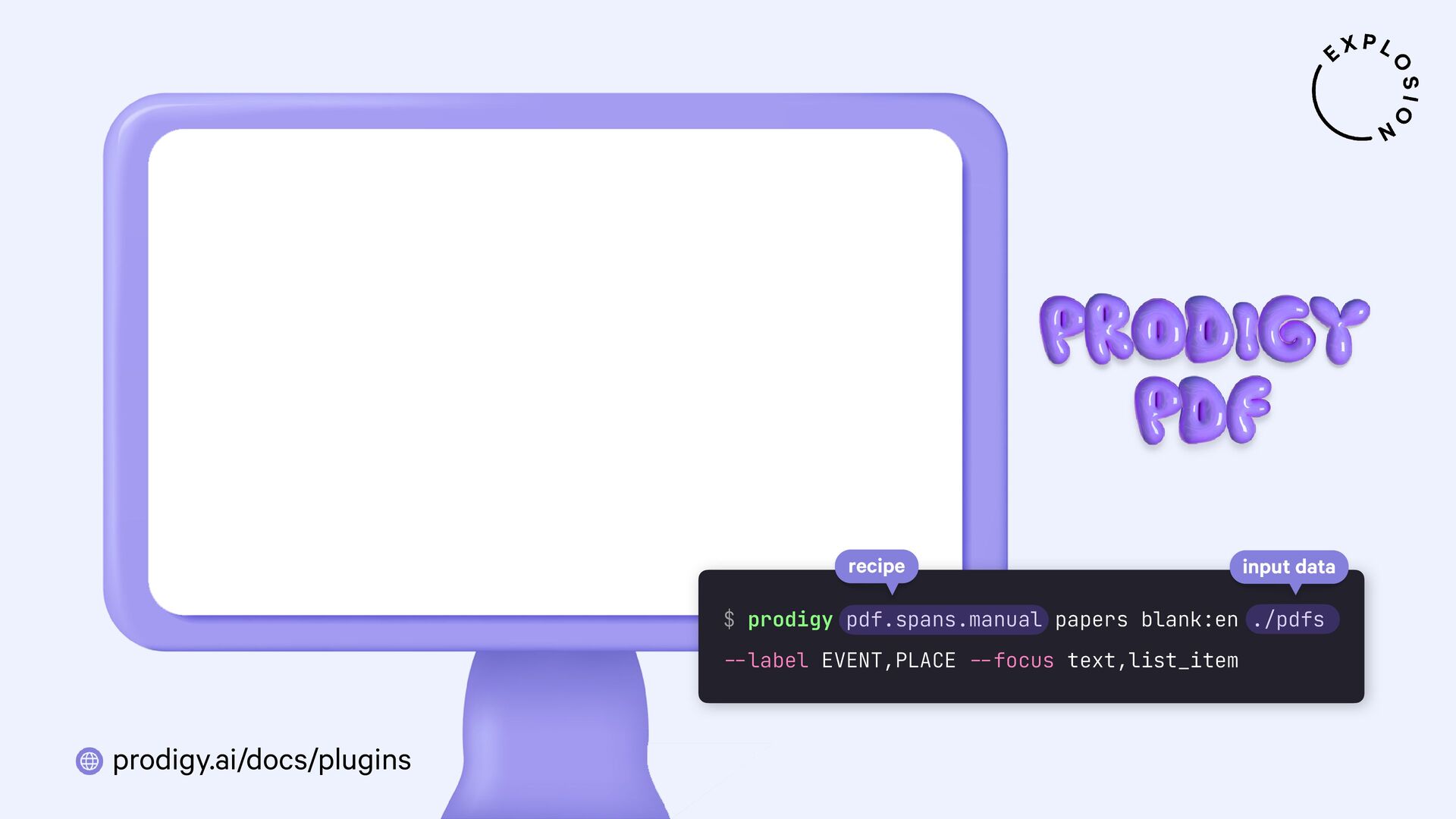
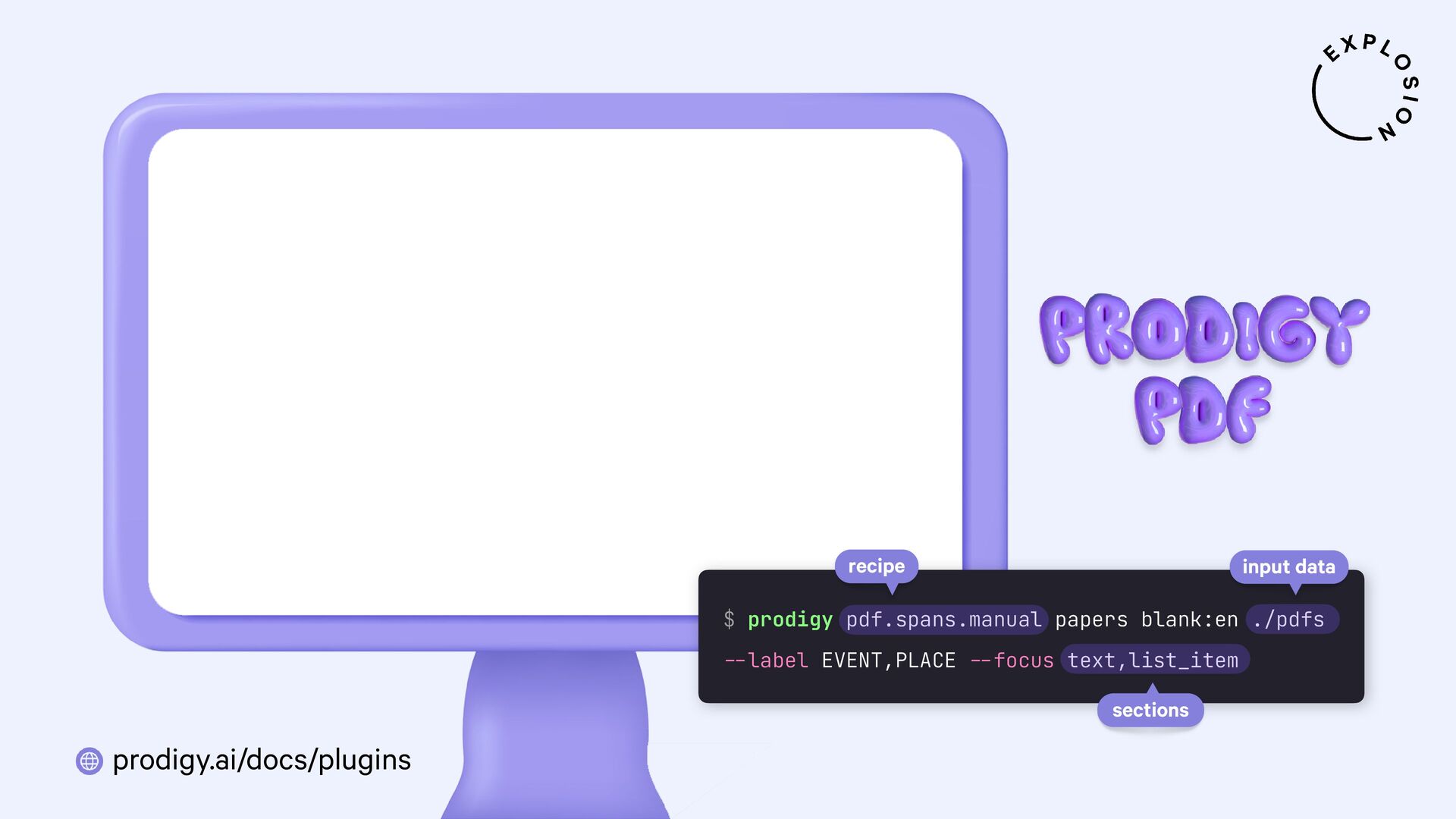
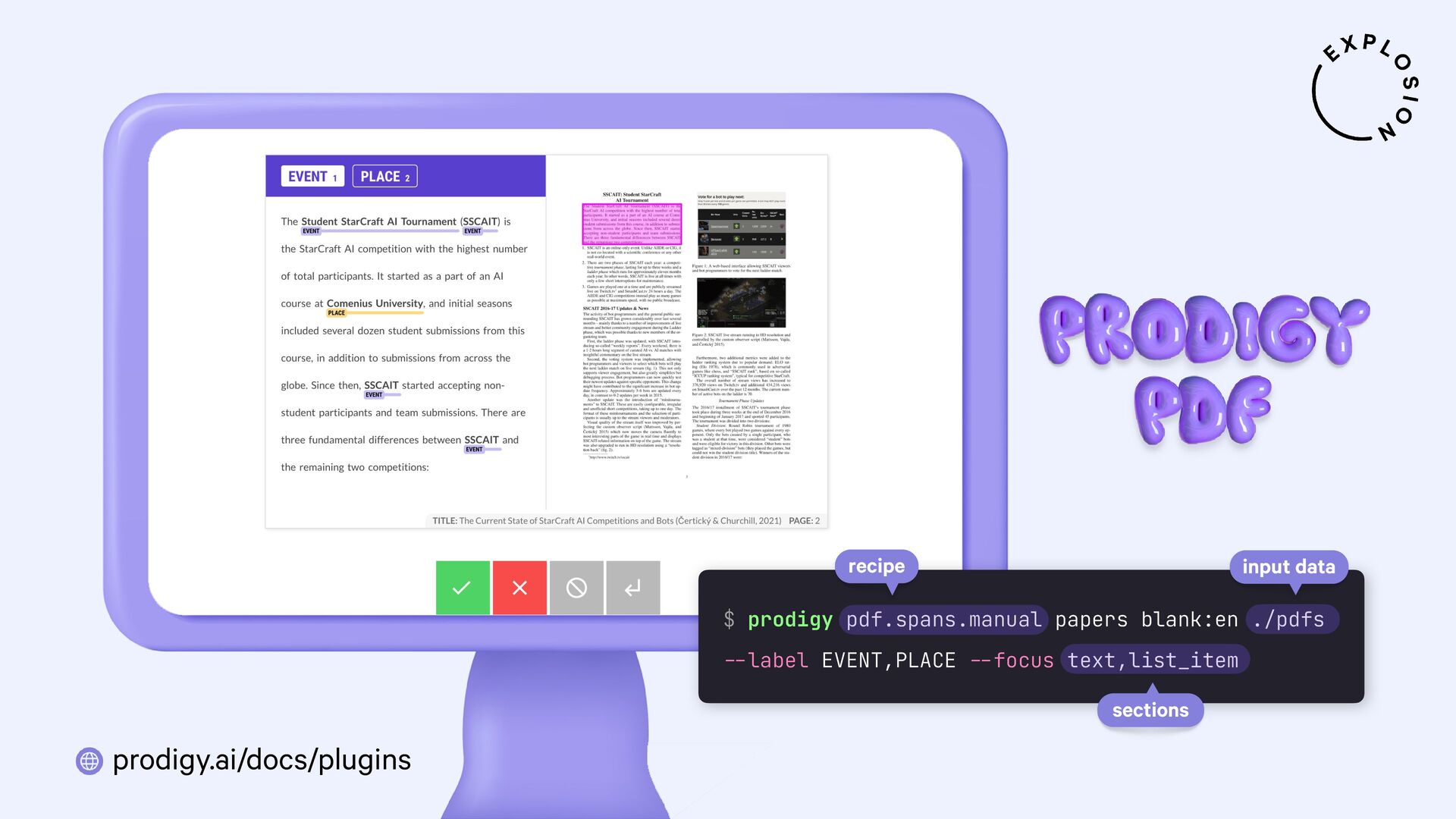
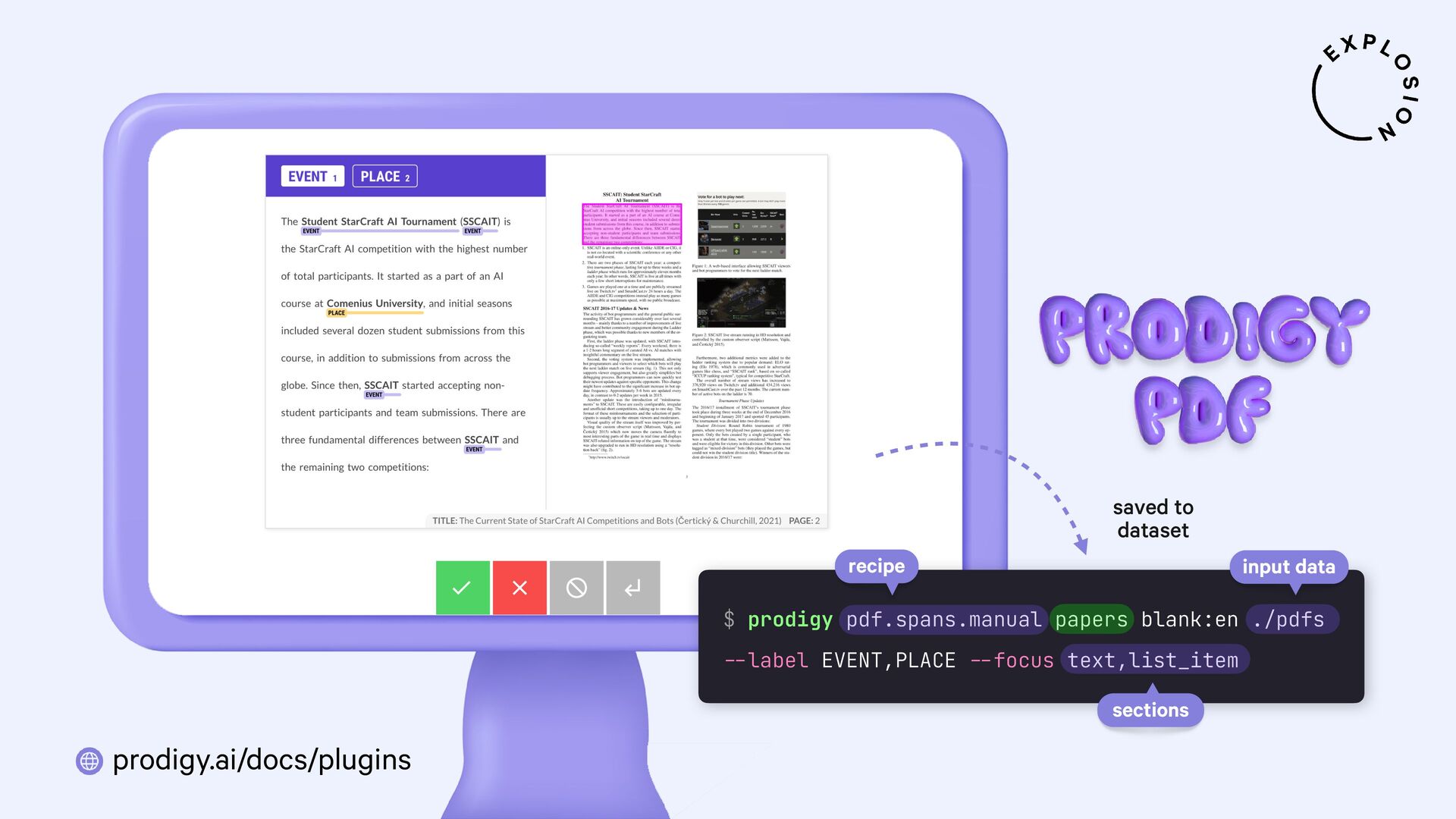
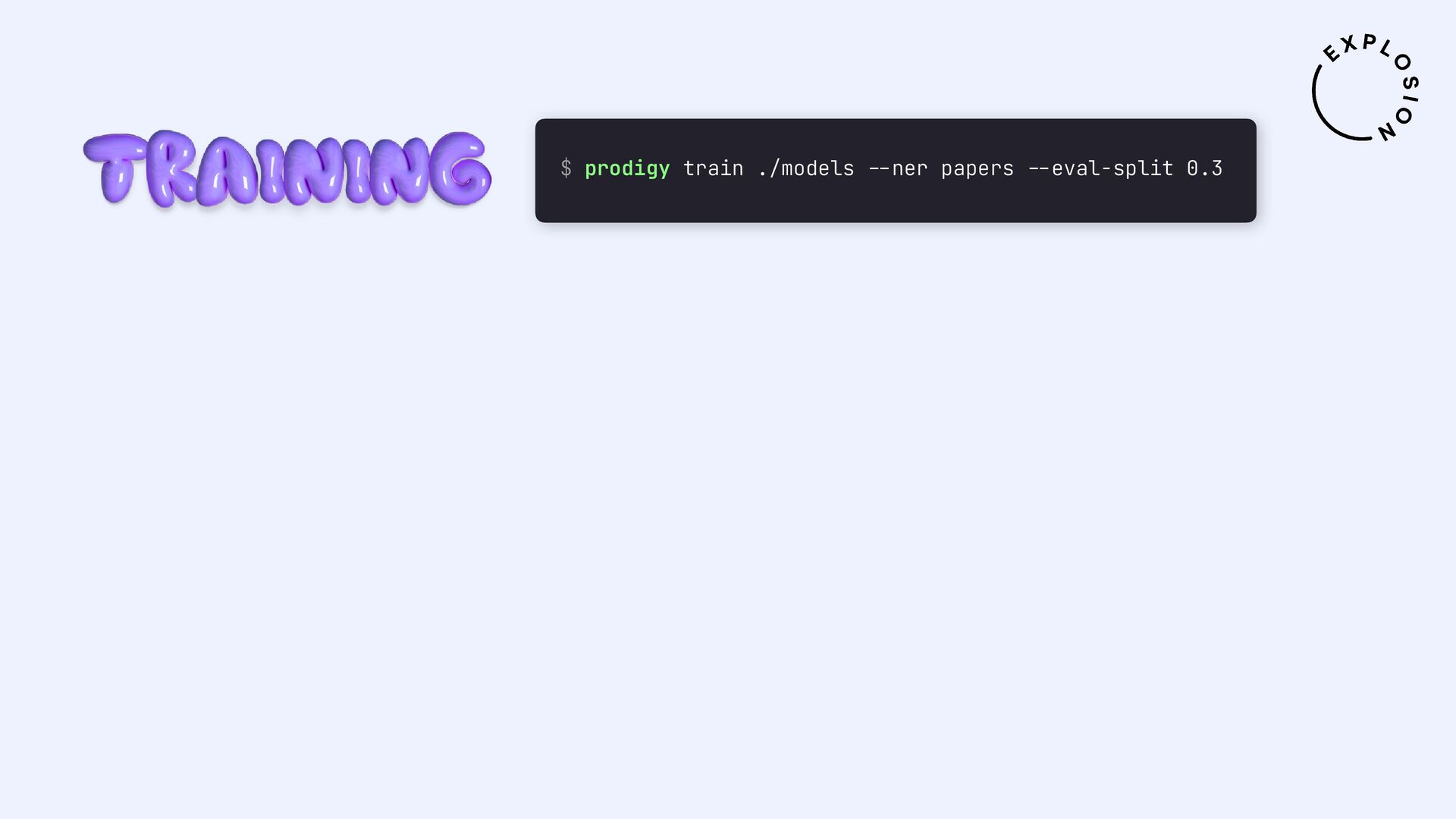
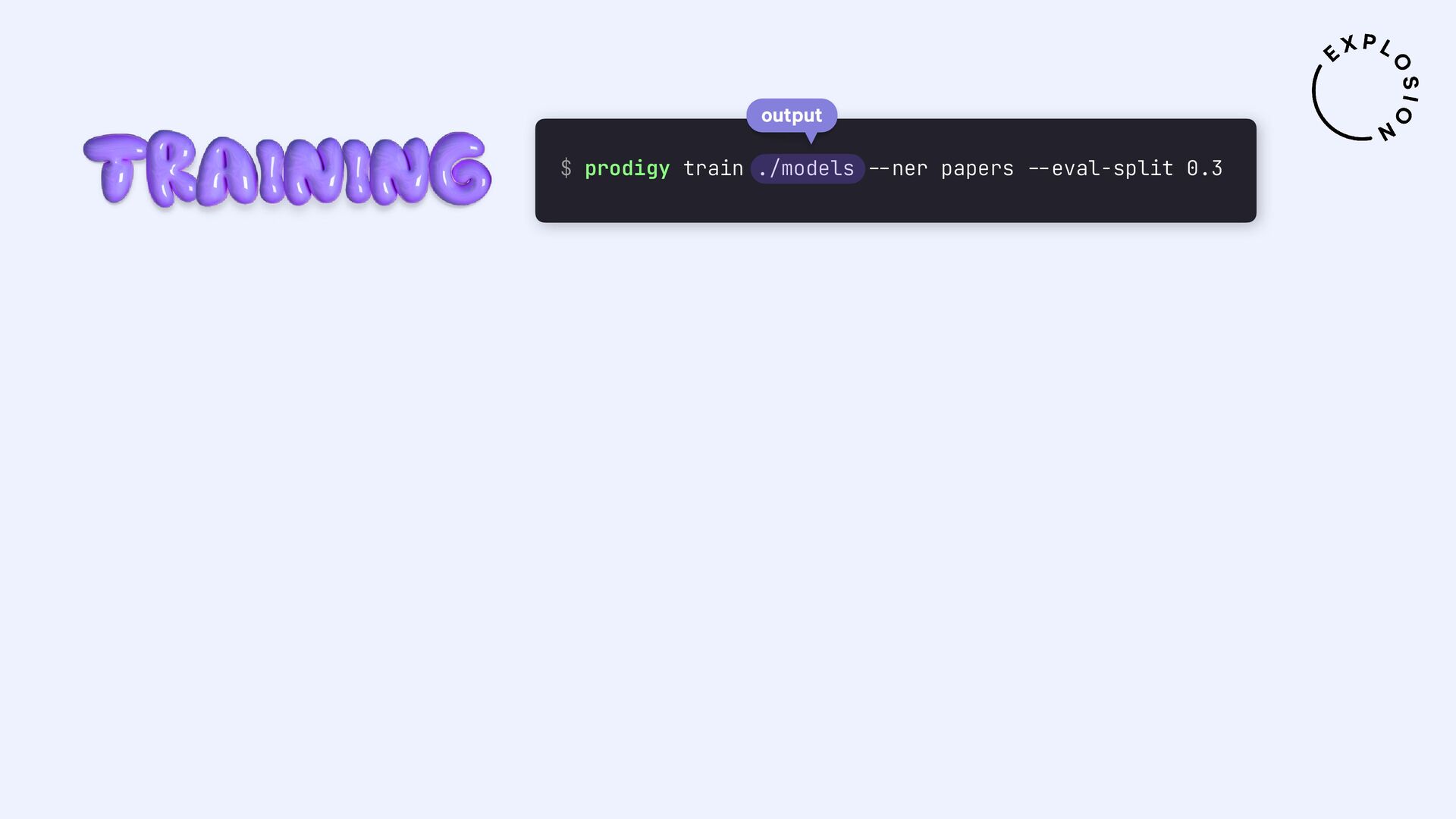
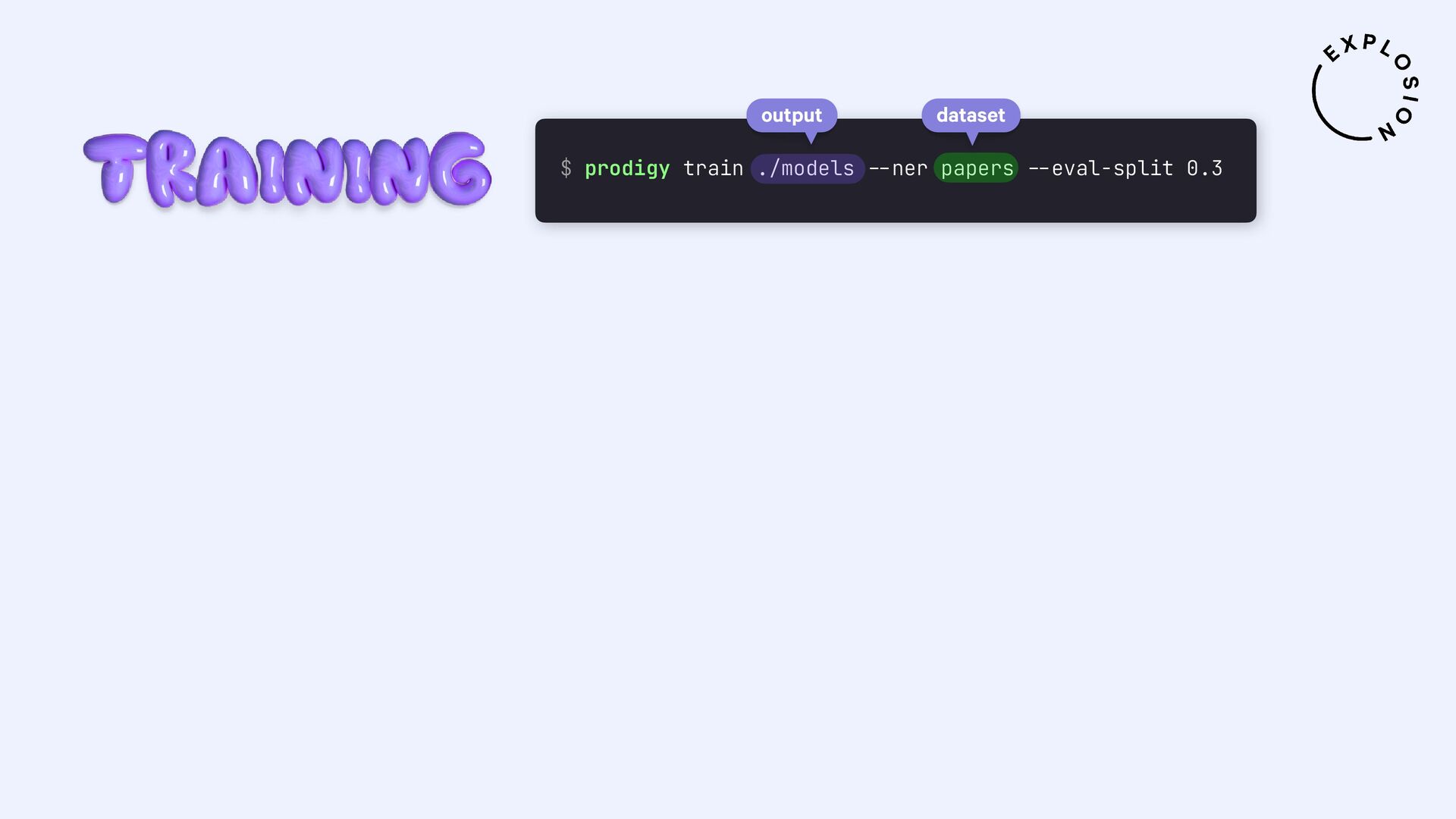
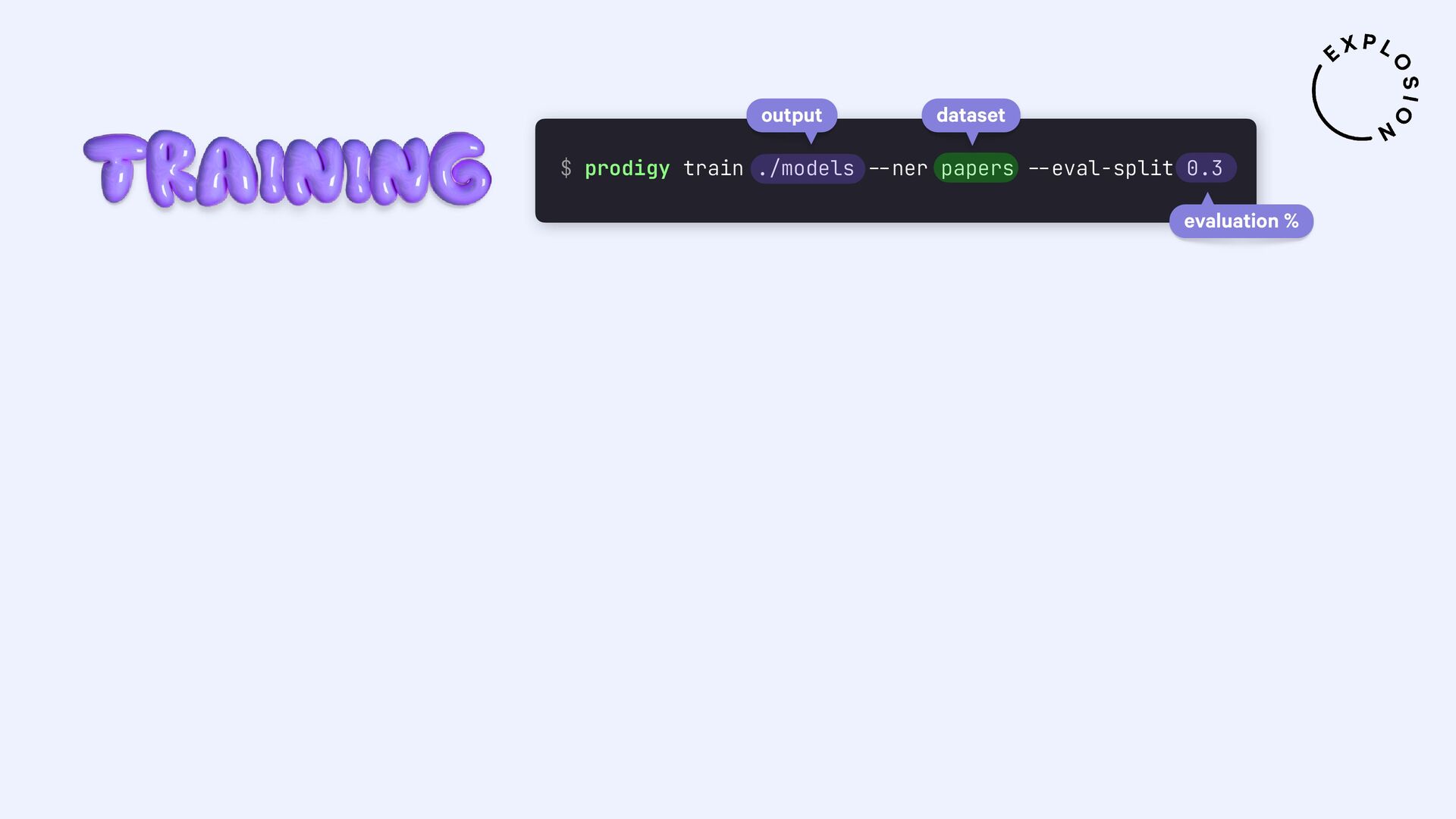
https://prodi.gy/docs/plugins#pdf
Plugin for the Prodigy annotation tool, including recipes for image-based and text-based PDF annotation.
https://arxiv.org/abs/2203.01017
Nassar et al., 2022
https://explosion.ai/blog/human-in-the-loop-distillation
Practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Explosion spaCy Prodigy Mastodon Bluesky explosion.ai spacy.io prodigy.ai @[email protected] @inesmontani.bsky.social](https://files.speakerdeck.com/presentations/33dca704091740449371d44dfa9cc599/slide_67.jpg){kind=link}