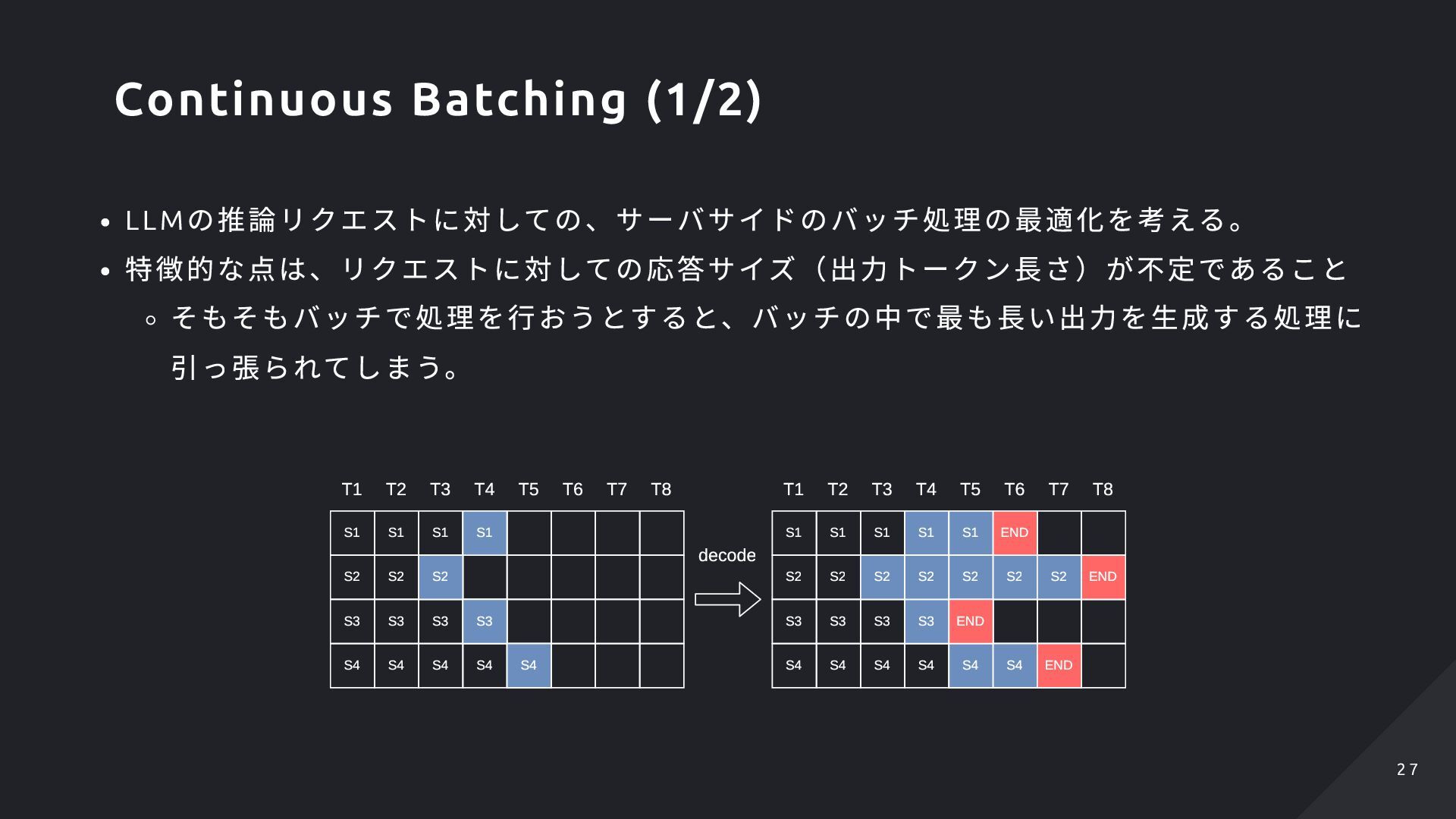
ト的な定型文が多用される。 LLM では入力トークンに対して計算処理を行う が、文章が定形である場合は計算結果が同じにな る特性がある。 User Please translate the following english to japanese: Would you like to tell me how to ... LLM Please translate the following english to japanese: Your suggestion is really helpful but... Prompt Template ユーザリクエストの特性とLLM による計算の特性 6 6
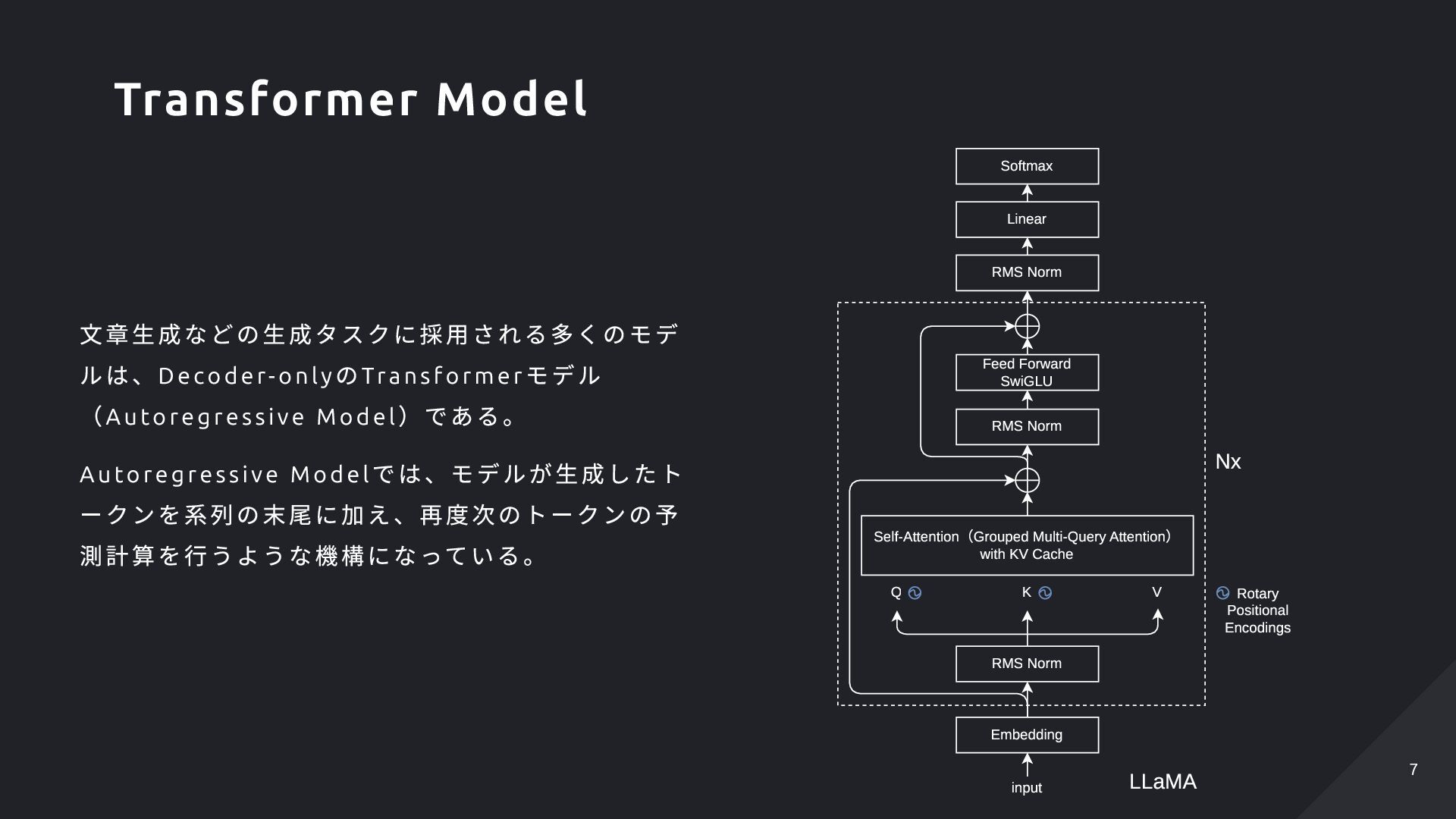
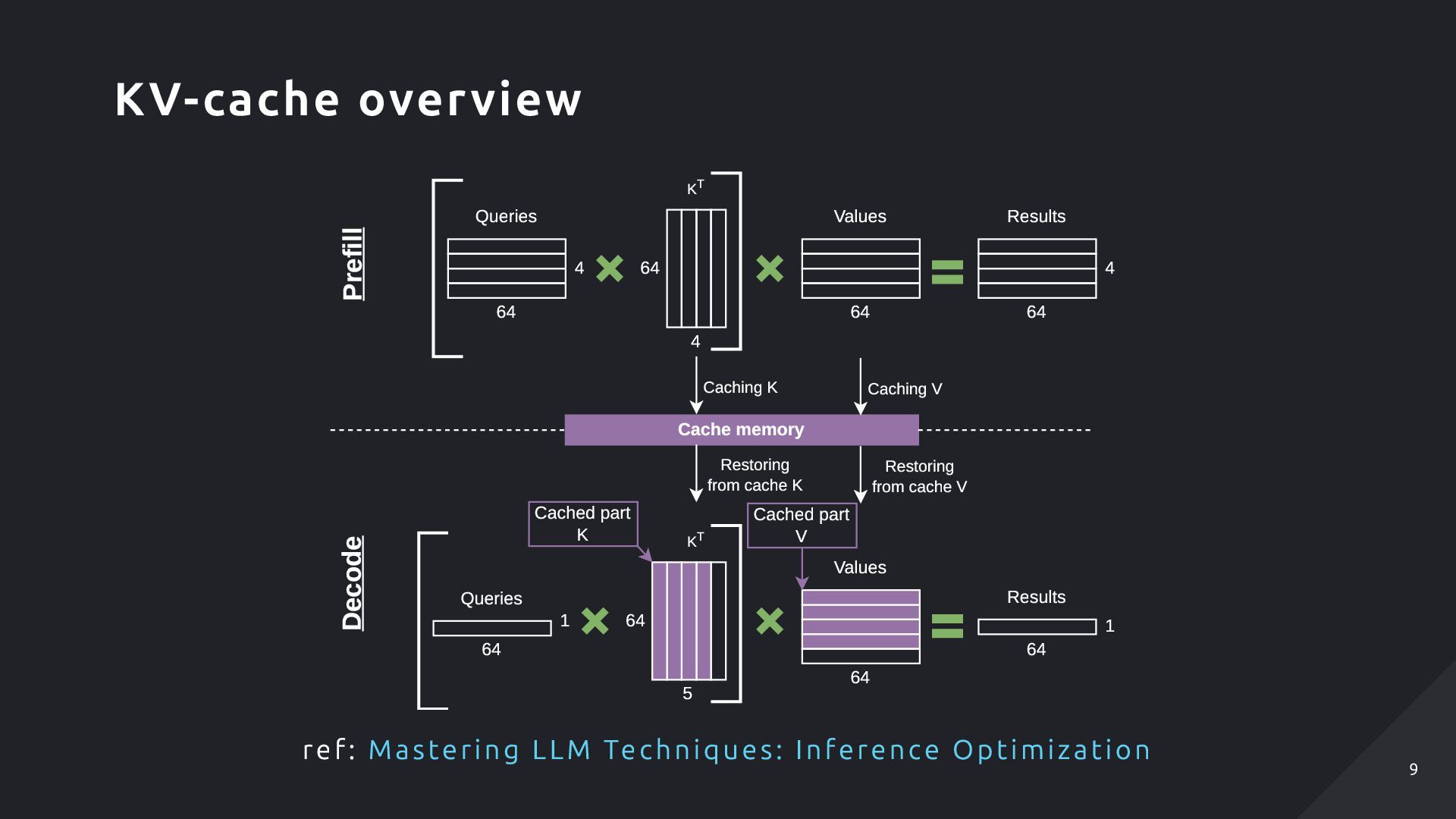
Results 64 4 Caching K Caching V Restoring from cache K Restoring from cache V Queries 1 64 64 5 KT Values 64 Results 64 1 Cached part K Cached part V Prefill Decode ref: Mastering LLM Techniques: Inference Optimization KV-cache overview 9 9
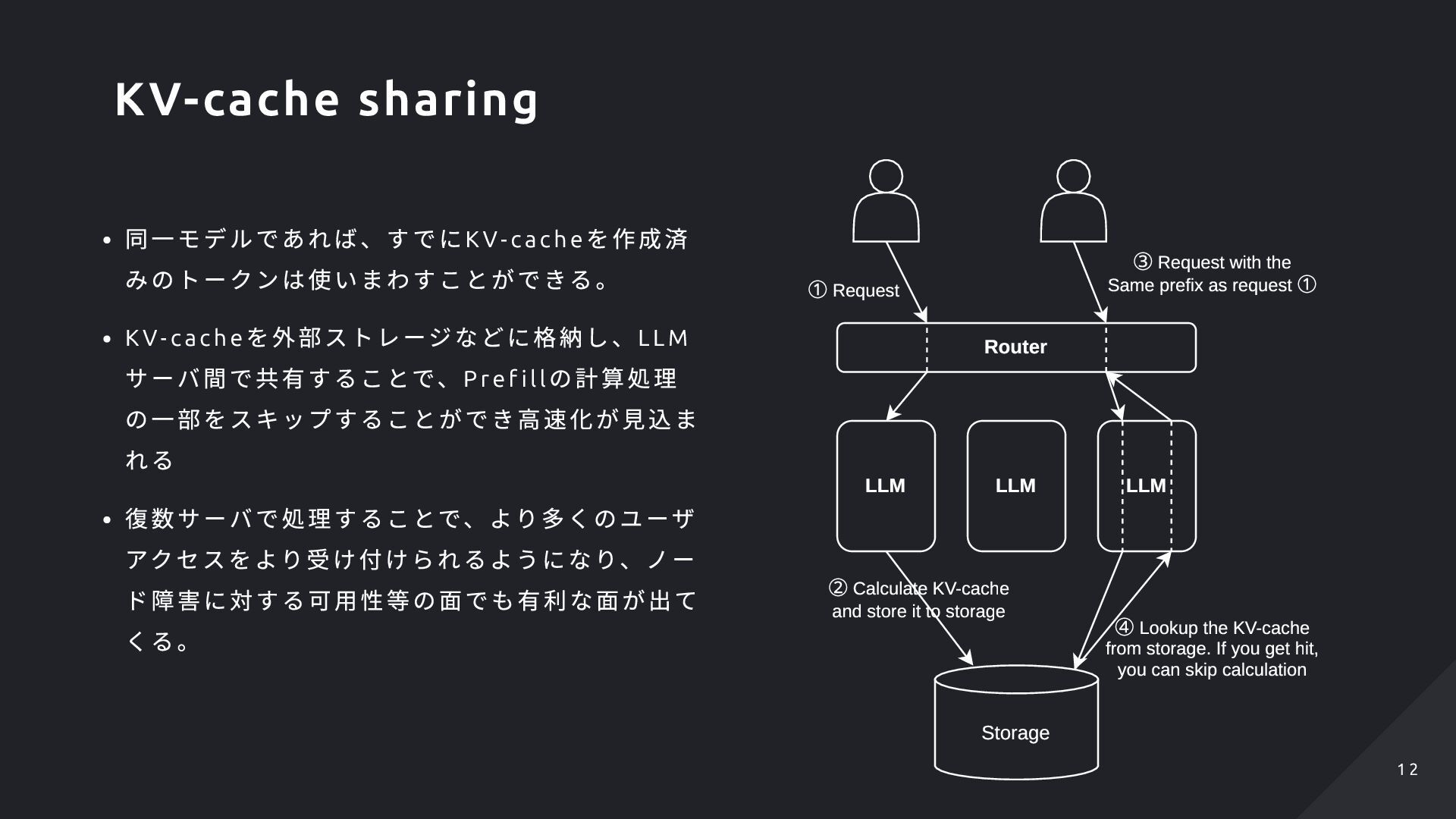
f ill の計算処理 の一部をスキップすることができ高速化が見込ま れる 復数サーバで処理することで、より多くのユーザ アクセスをより受け付けられるようになり、ノー ド障害に対する可用性等の面でも有利な面が出て くる。 LLM LLM LLM Storage ① Request ② Calculate KV-cache and store it to storage Router ③ Request with the Same prefix as request ① ④ Lookup the KV-cache from storage. If you get hit, you can skip calculation KV-cache sharing 1 2 1 2
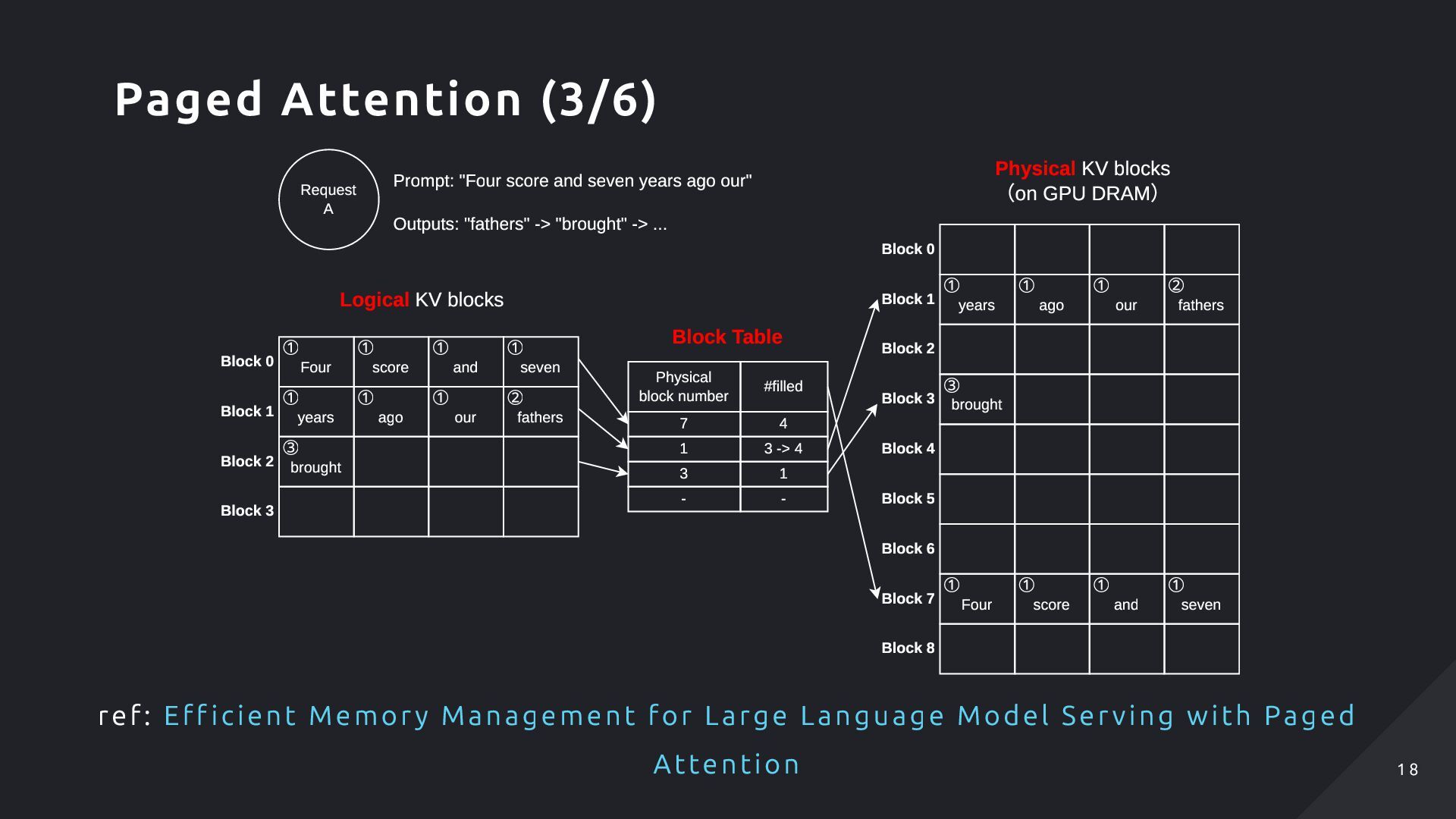
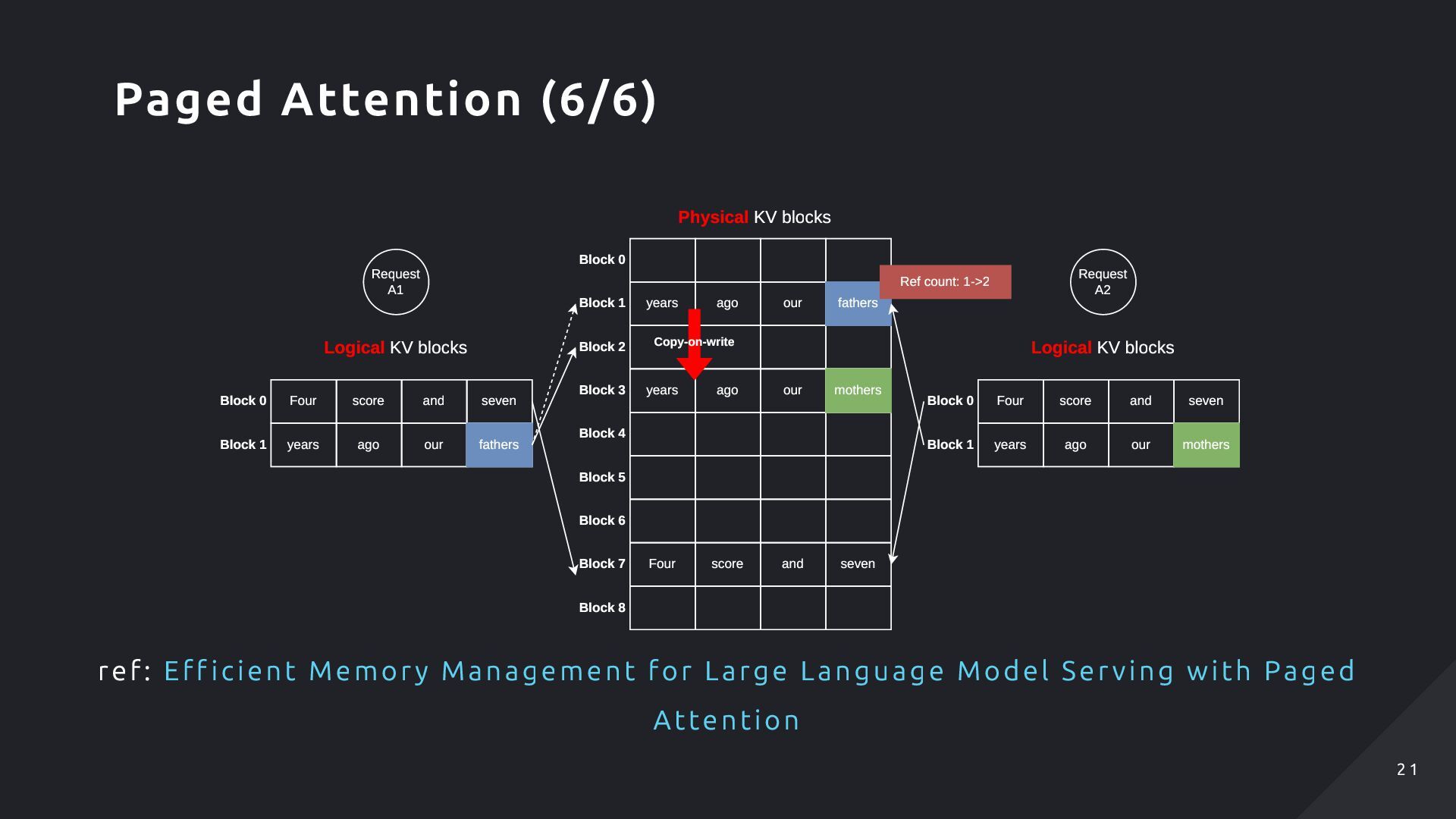
ago ① our ① fathers ② ③ brought ① Four score ① and ① seven ① ① years ago ① our ① fathers ② ③ brought Physical block number #filled 7 4 1 3 -> 4 3 1 - - Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Block 8 Physical KV blocks (on GPU DRAM) Block 0 Block 1 Block 2 Block 3 Request A Prompt: "Four score and seven years ago our" Outputs: "fathers" -> "brought" -> ... Logical KV blocks Block Table ref: Eff icient Memory Management for Large Language Model Serving with Paged Attention Paged Attention (3/6) 1 8 1 8
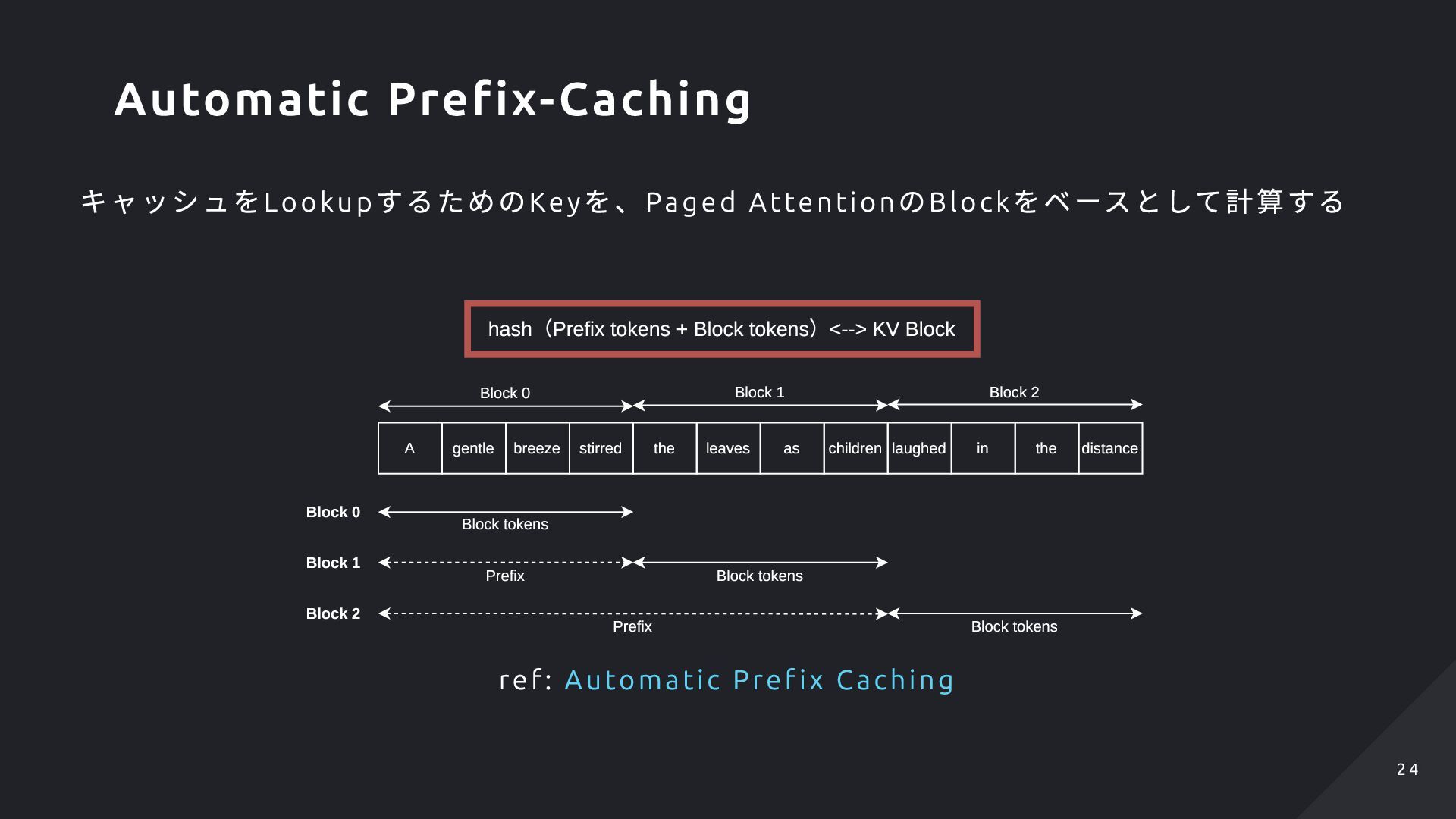
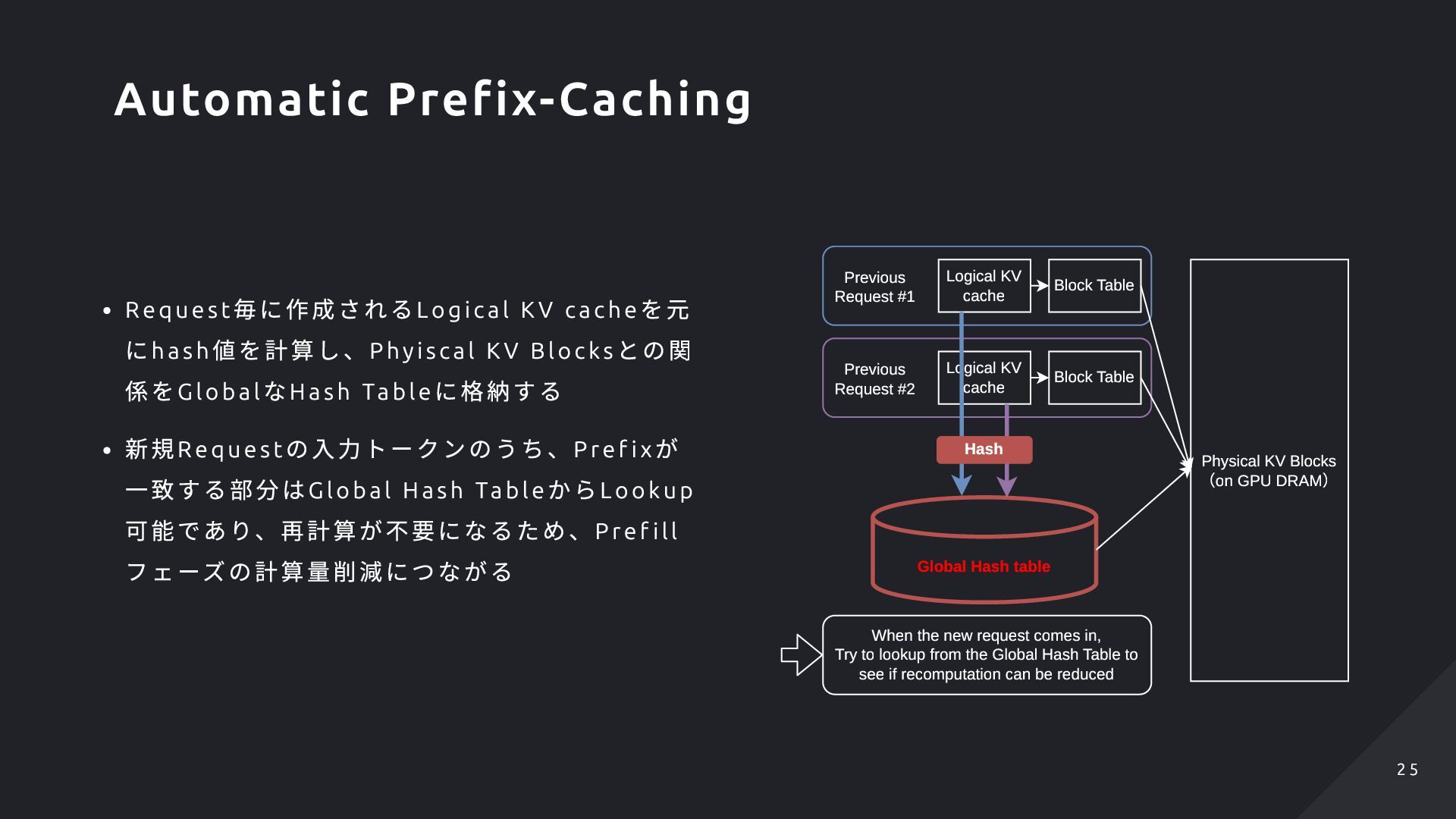
Blo cks との関 係をGlobal なHash Table に格納する 新規Request の入力トークンのうち、Pre f ix が 一致する部分はGlobal H ash Table からLookup 可能であり、再計算が不要になるため、Pref i ll フェーズの計算量削減につながる Logical KV cache Block Table Physical KV Blocks (on GPU DRAM) Logical KV cache Block Table Previous Request #1 Previous Request #2 Global Hash table Hash When the new request comes in, Try to lookup from the Global Hash Table to see if recomputation can be reduced Automatic Prefix-Caching 2 5 2 5
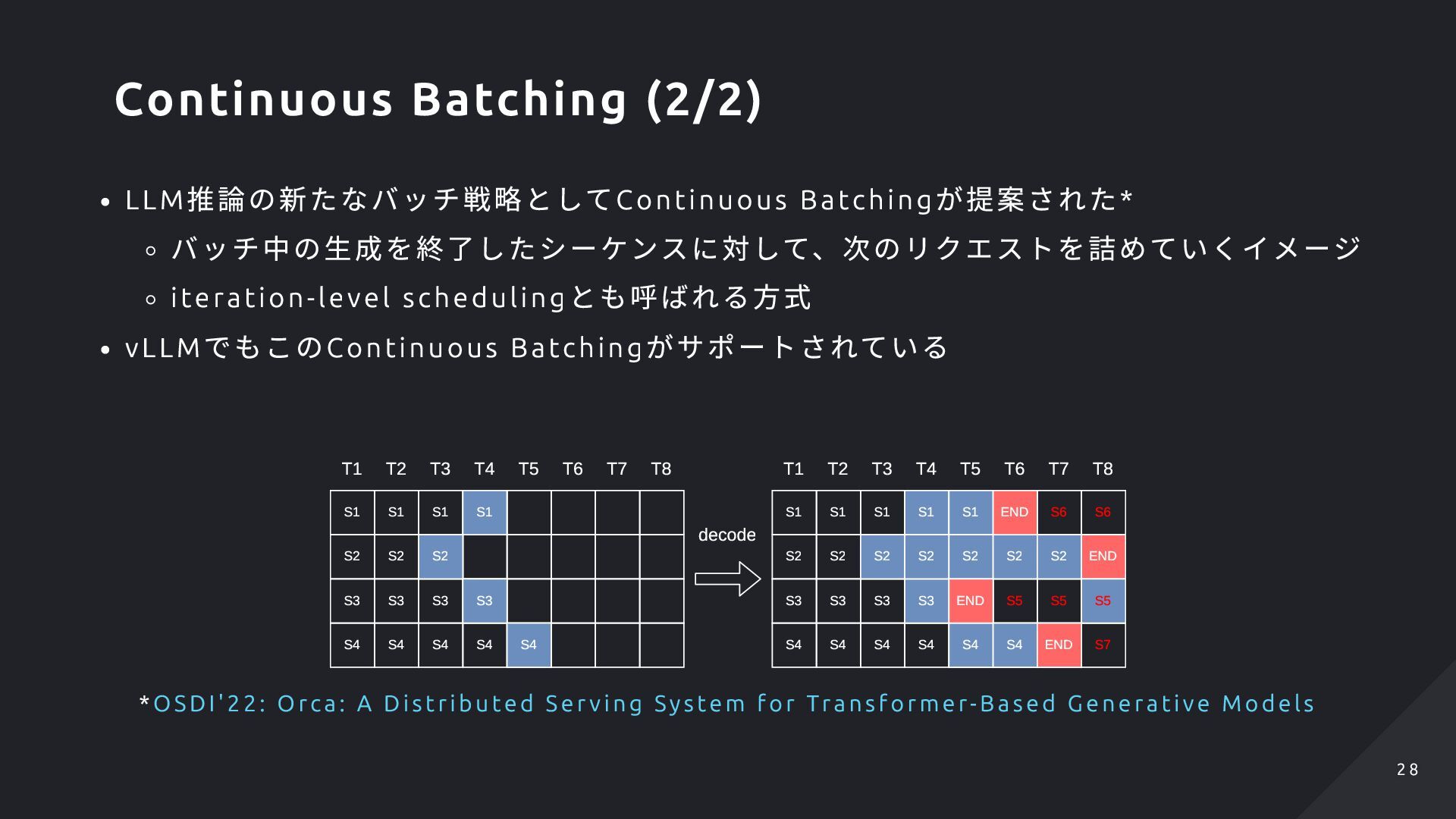
Batching がサポートされている S1 S2 S3 S4 S1 S2 S3 S4 S1 S3 S4 S1 S4 S2 S3 T1 T2 T3 T5 T6 T8 T7 S4 S1 S2 S3 S4 S1 S2 S3 S4 S1 S3 S4 S1 S4 S2 S3 T1 T2 T4 T3 T5 T6 T8 T7 S4 decode S1 S4 S2 S2 S2 S2 END END END END T4 S6 S6 S5 S5 S7 S5 *OSDI'22: Orca: A Di stri buted S e r v ing Sy ste m fo r Transfo rm er- Ba sed G enerative M od els Continuous Batching (2/2) 2 8 2 8
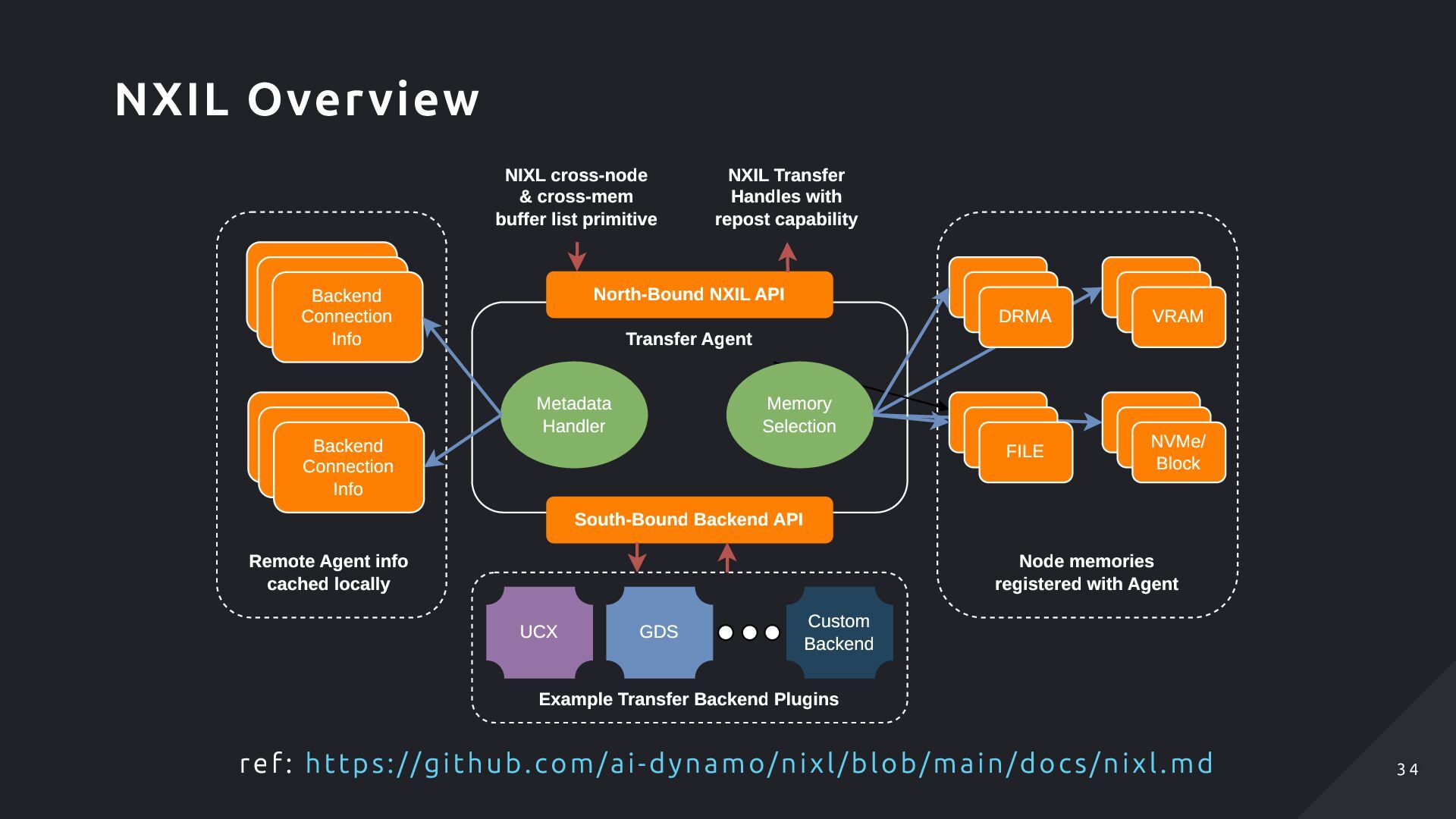
Backend API Backend Connection Info Backend Connection Info Backend Connection Info Backend Connection Info Backend Connection Info Backend Connection Info DRMA VRAM FILE NVMe/ Block Example Transfer Backend Plugins Remote Agent info cached locally Node memories registered with Agent NIXL cross-node & cross-mem buffer list primitive NXIL Transfer Handles with repost capability UCX GDS Custom Backend ref: https://github.com/ai-dynamo/nixl/blob/main/docs/nixl.md NXIL Overview 3 4 3 4
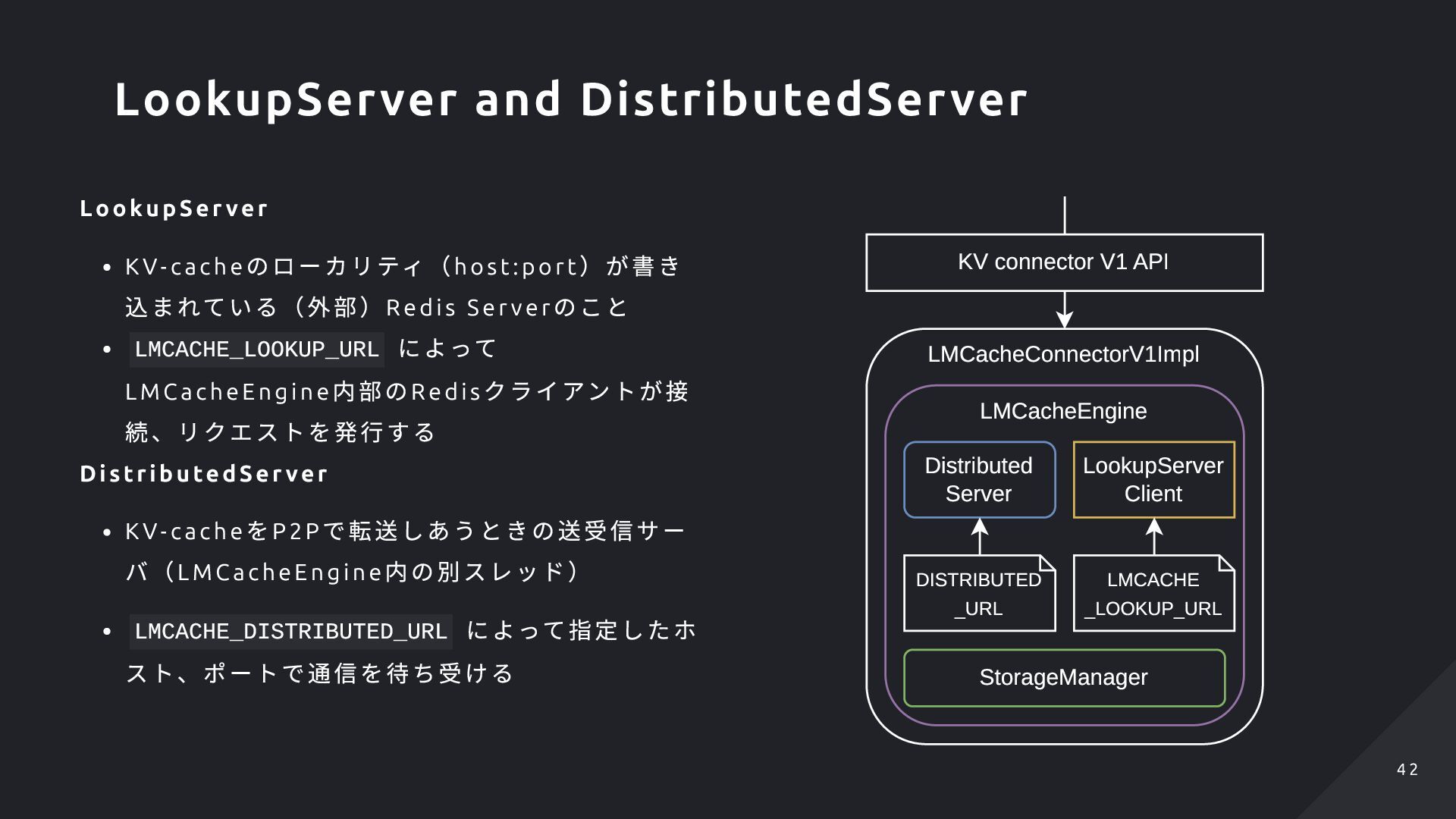
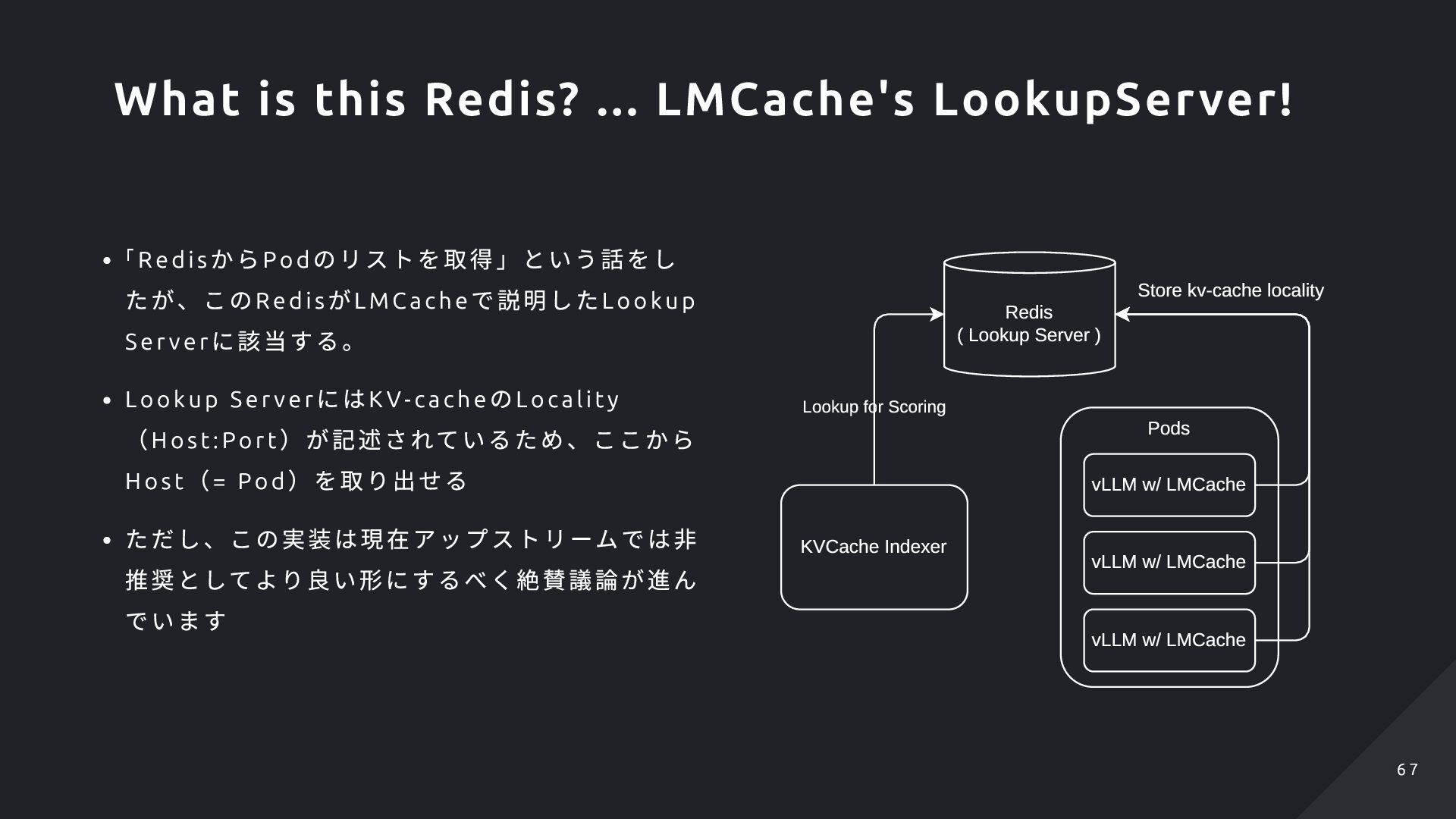
Se r ve r のこと LMCACHE_LOOKUP_URL によって LMC acheEngi ne 内部のRedi s クライアントが接 続、リクエストを発行する DistributedSer ver K V- cache をP2P で転送しあうときの送受信サー バ(LMC acheEngi ne 内の別スレッド) LMCACHE_DISTRIBUTED_URL によって指定したホ スト、ポートで通信を待ち受ける LMCacheConnectorV1Impl LMCacheEngine StorageManager Distributed Server LookupServer Client KV connector V1 API LMCACHE _LOOKUP_URL DISTRIBUTED _URL LookupServer and DistributedServer 4 2 4 2
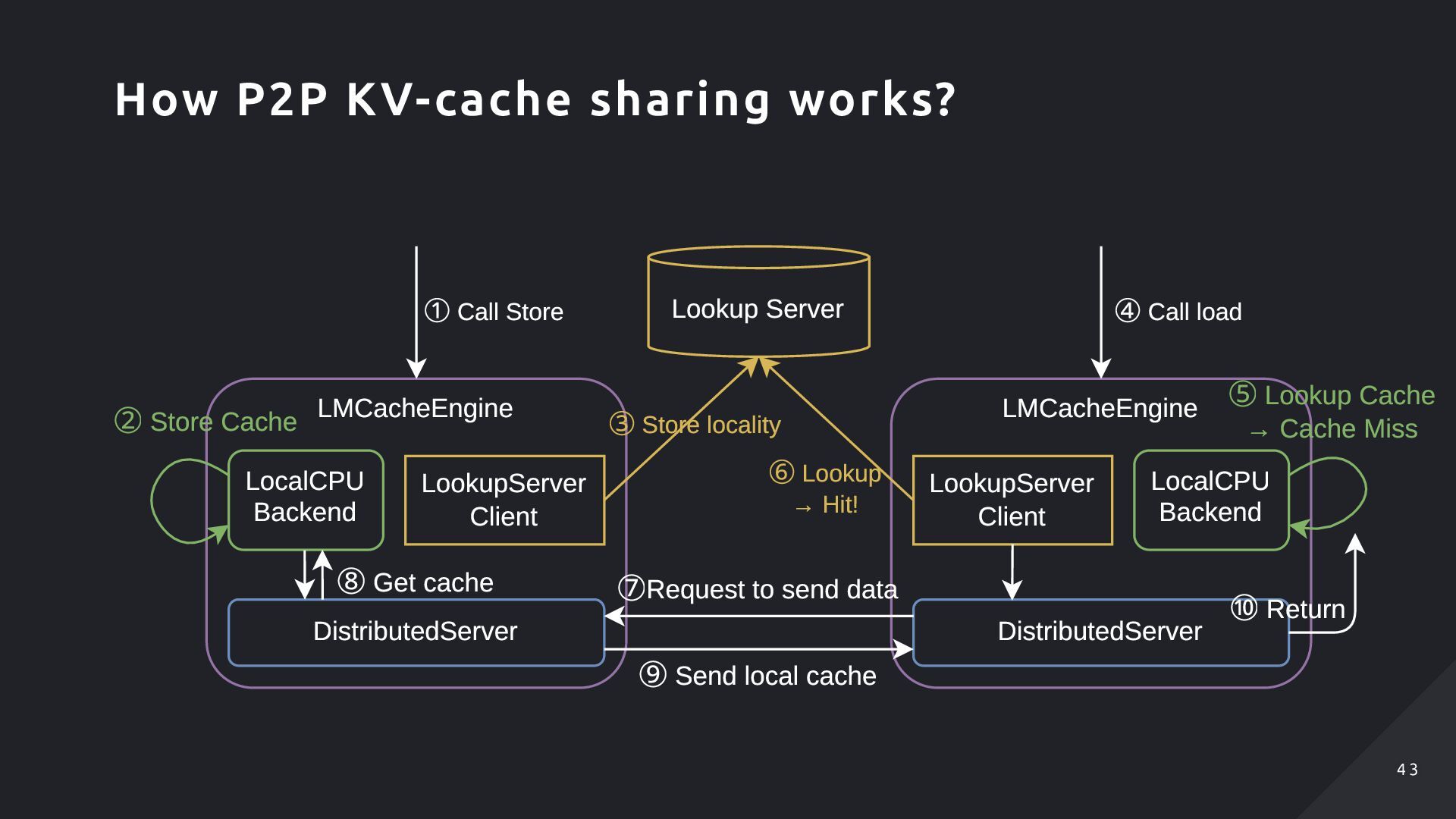
Backend DistributedServer LookupServer Client ③ Store locality ① Call Store ② Store Cache ④ Call load ⑤ Lookup Cache → Cache Miss ⑥ Lookup → Hit! ⑦Request to send data ⑧ Get cache ⑨ Send local cache ⑩ Return How P2P KV-cache sharing works? 4 3 4 3
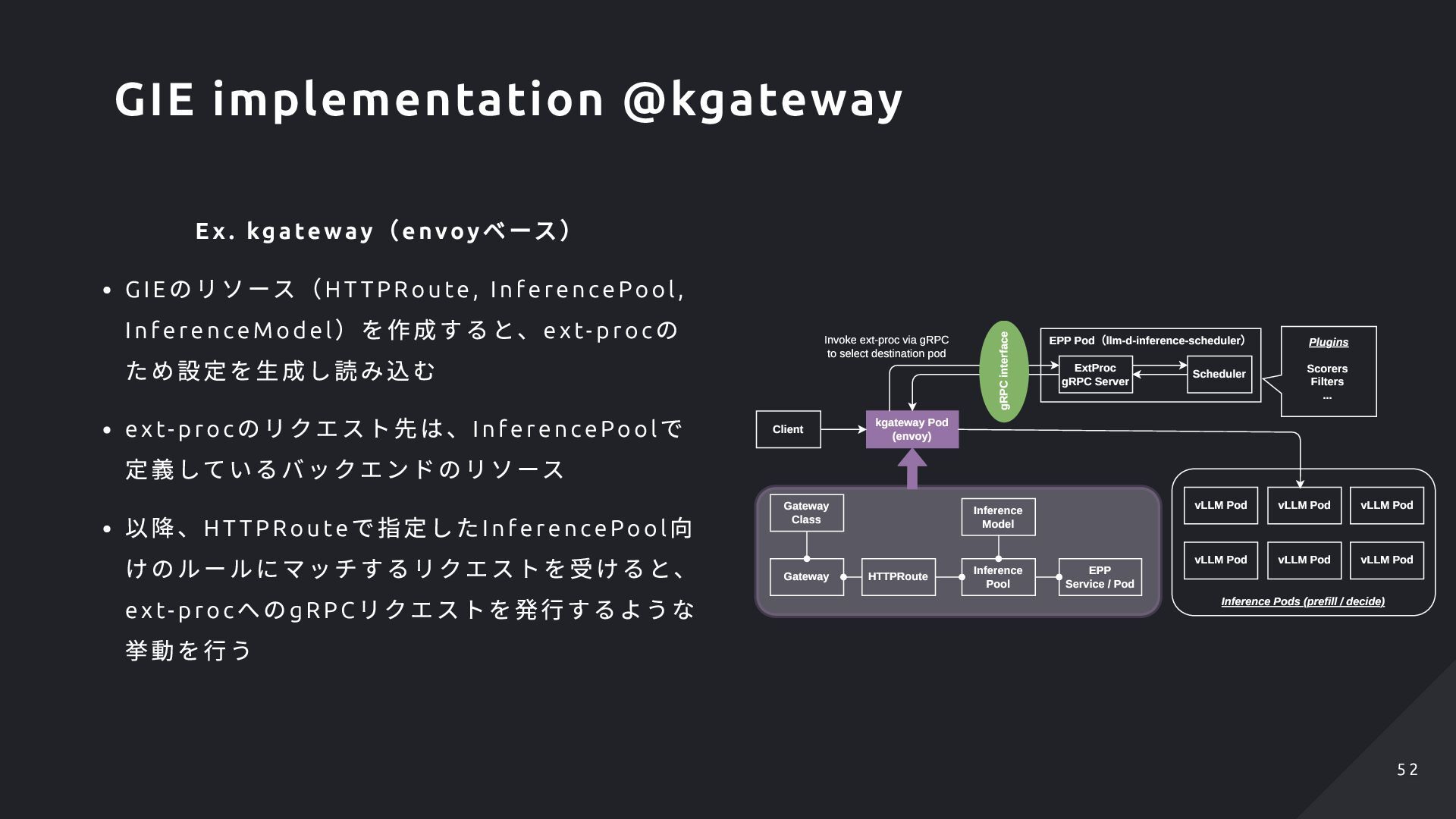
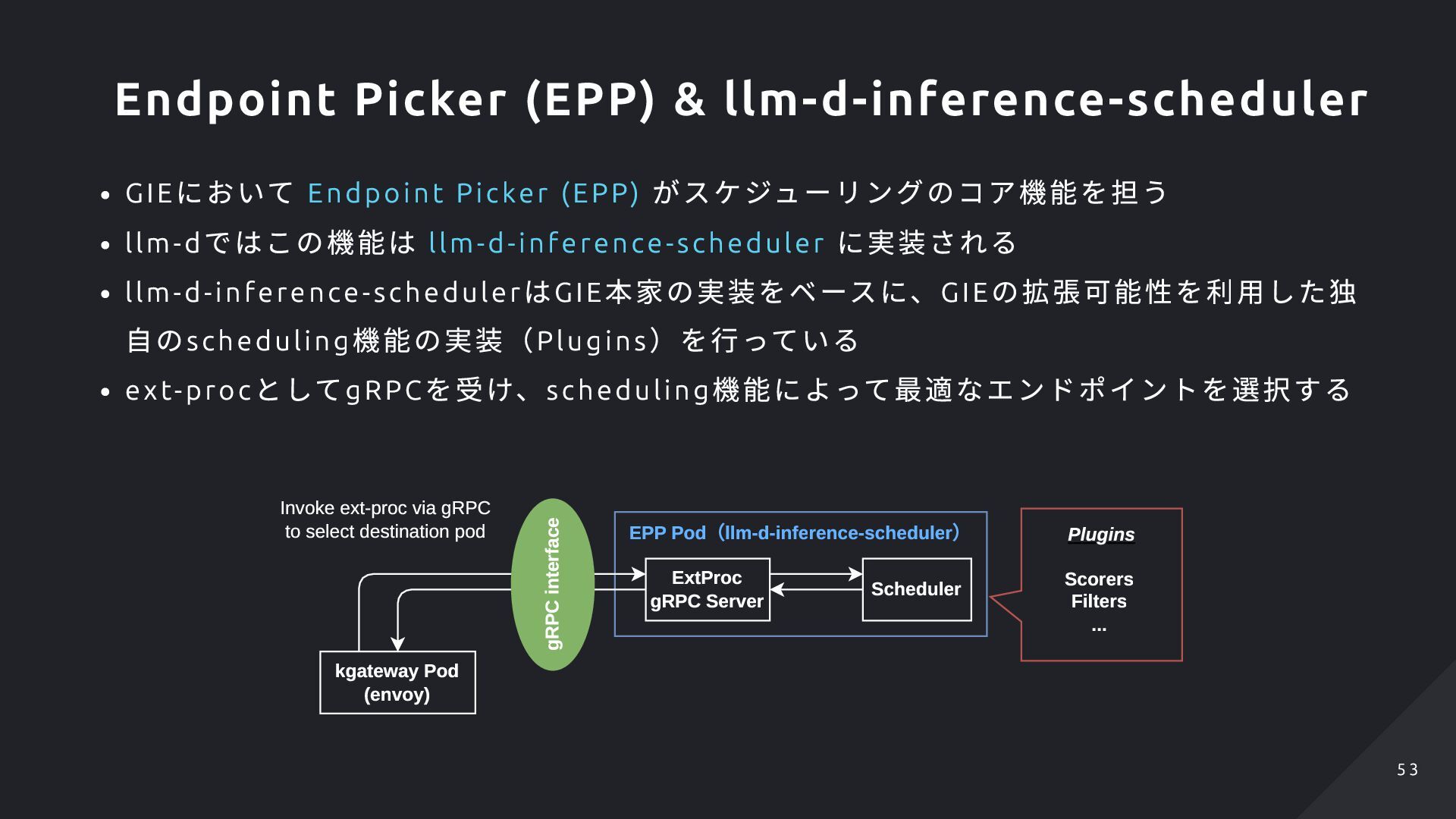
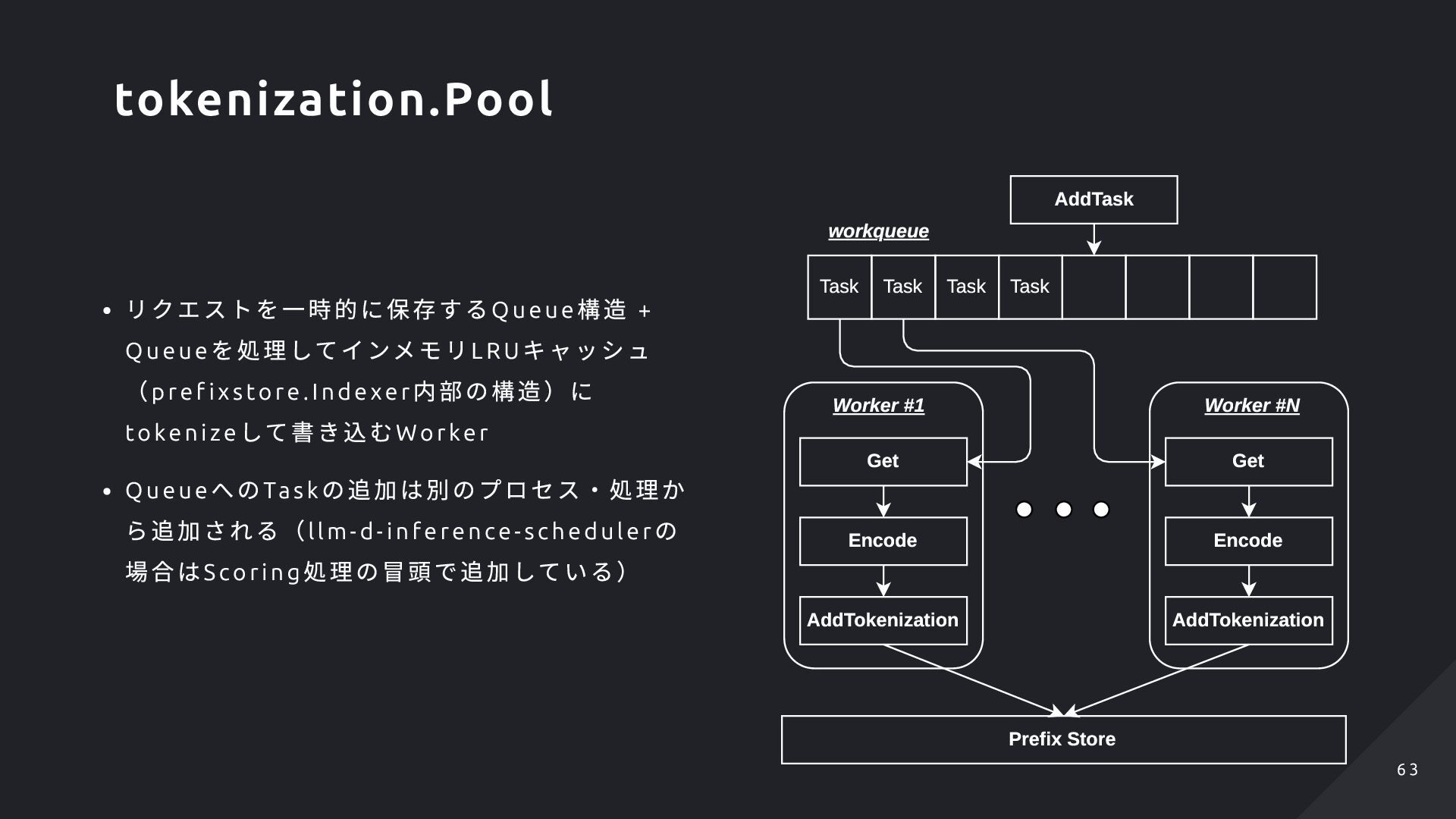
Inference Pool , InferenceModel )を作成すると、ex t-p roc の ため設定を生成し読み込む ext-proc のリクエスト先は、InferencePo ol で 定義しているバックエンドのリソース 以降、HT TPRoute で指定したInferencePo ol 向 けのルールにマッチするリクエストを受けると、 ext-proc へのgRPC リクエストを発行するような 挙動を行う Gateway Gateway Class HTTPRoute Inference Pool Inference Model kgateway Pod (envoy) EPP Pod(llm-d-inference-scheduler) ExtProc gRPC Server Scheduler Invoke ext-proc via gRPC to select destination pod vLLM Pod Scorers Filters ... Plugins gRPC interface vLLM Pod vLLM Pod vLLM Pod vLLM Pod vLLM Pod Inference Pods (prefill / decide) EPP Service / Pod Client GIE implementation @kgateway 5 2 5 2
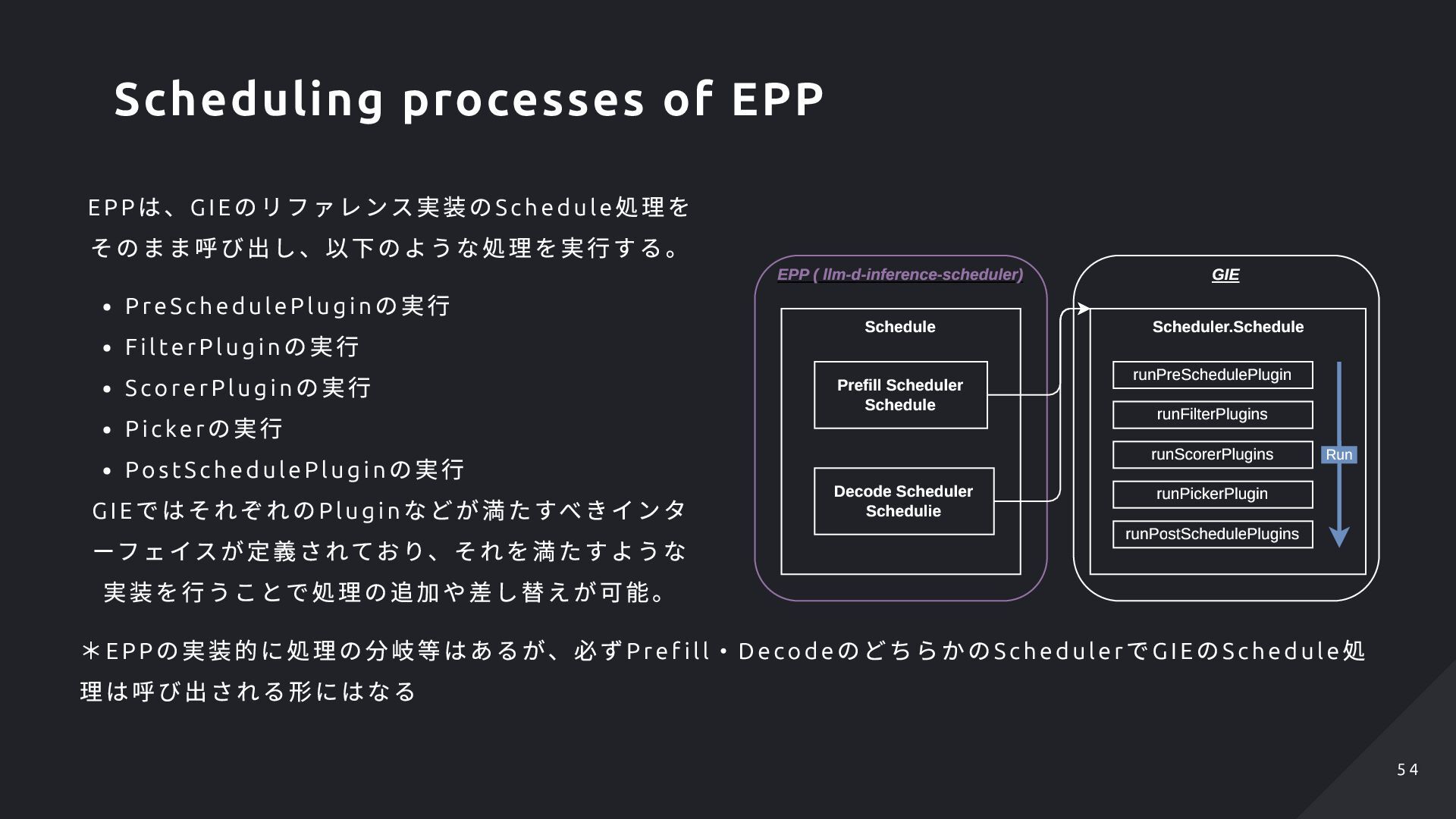
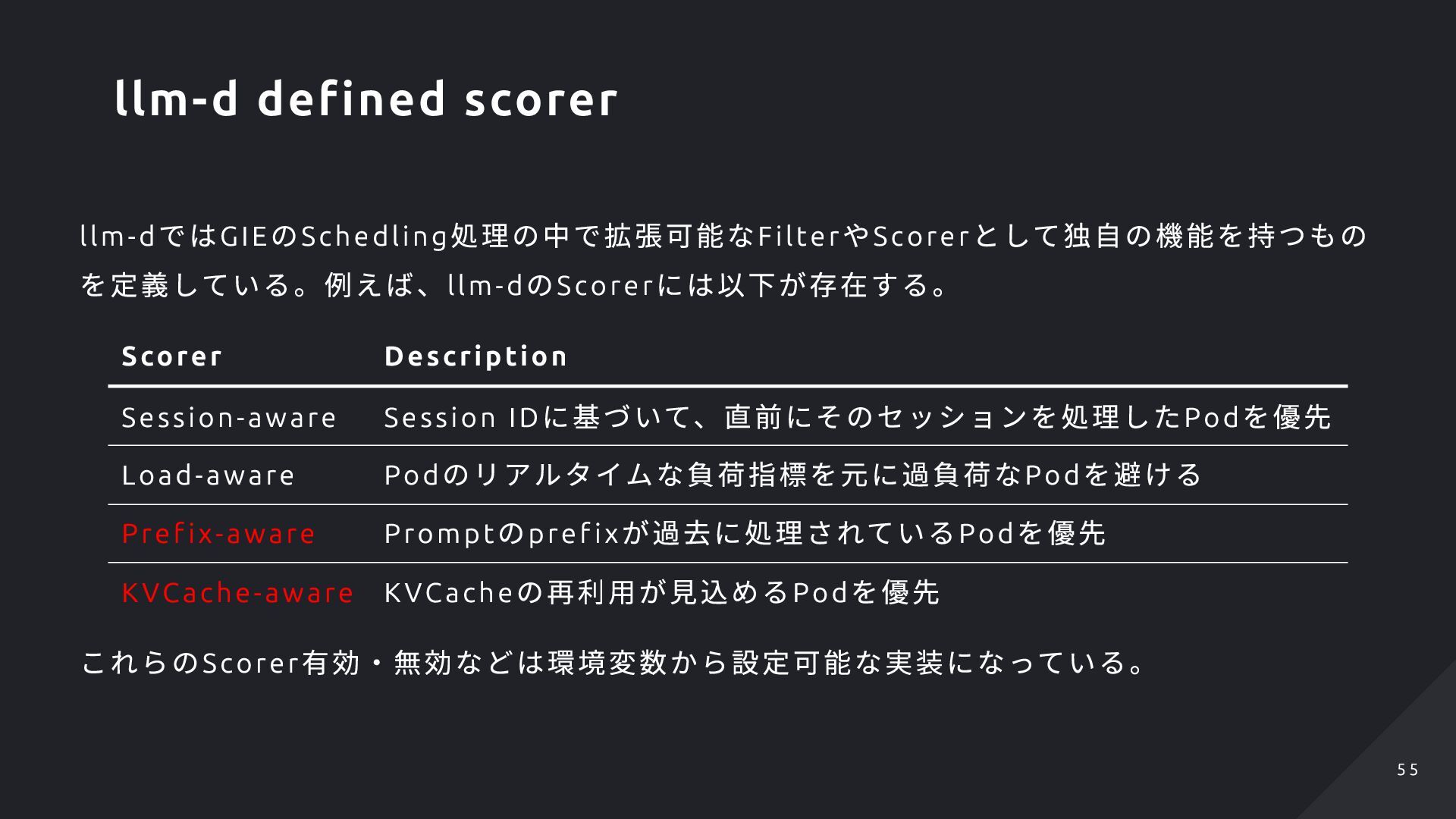
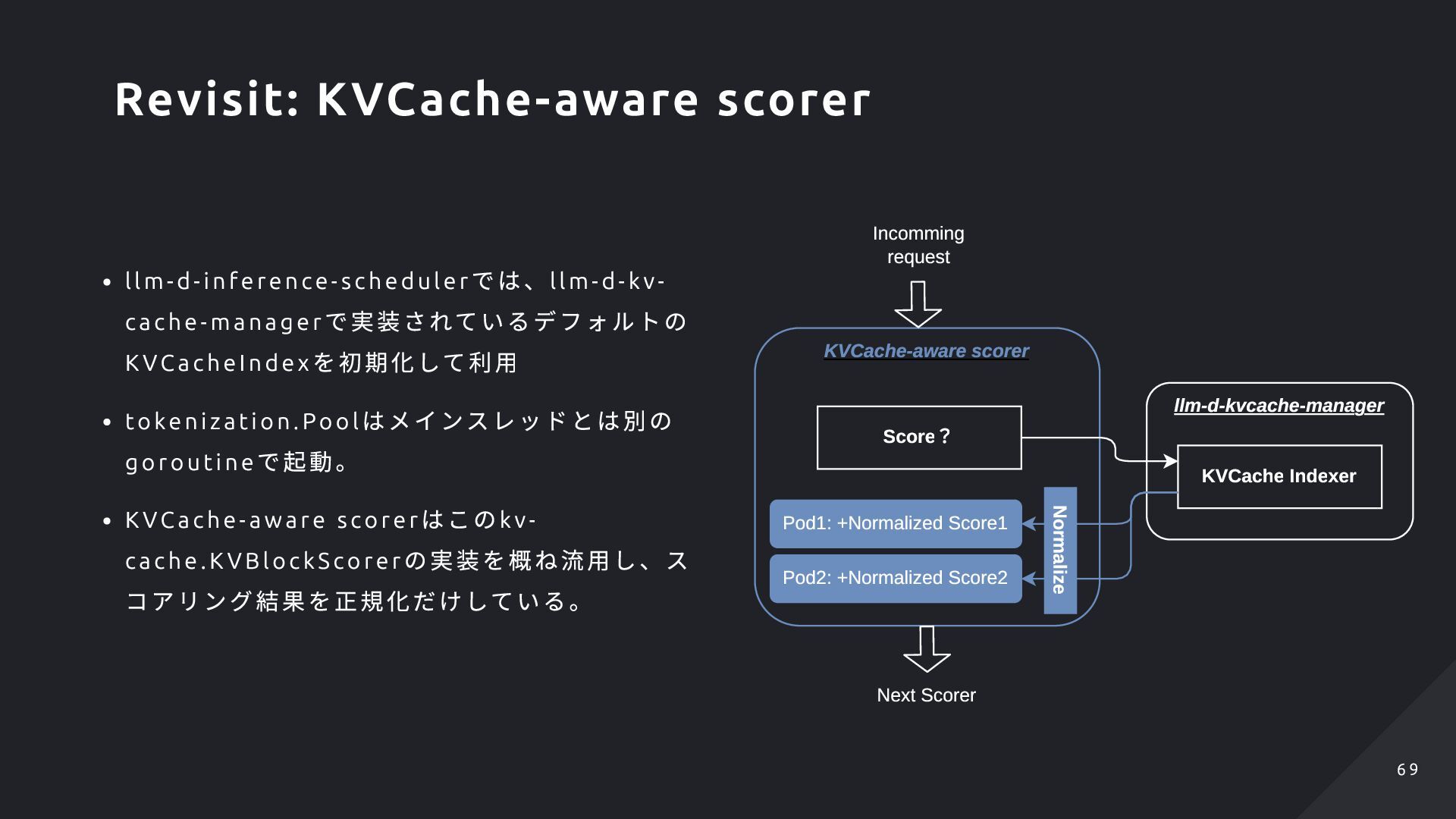
lterPlugi n の実行 ScorerPlugi n の実行 Pi cker の実行 PostSchedulePlugi n の実行 GIE ではそれぞれのPlugi n などが満たすべきインタ ーフェイスが定義されており、それを満たすような 実装を行うことで処理の追加や差し替えが可能。 Schedule GIE Scheduler.Schedule EPP ( llm-d-inference-scheduler) Prefill Scheduler Schedule Decode Scheduler Schedulie runPreSchedulePlugin runFilterPlugins runScorerPlugins runPickerPlugin runPostSchedulePlugins Run *EPP の実装的に処理の分岐等はあるが、必ずPre f ill・ Deco de のどちらかのSche duler でG IE のSch ed ule 処 理は呼び出される形にはなる Scheduling processes of EPP 5 4 5 4
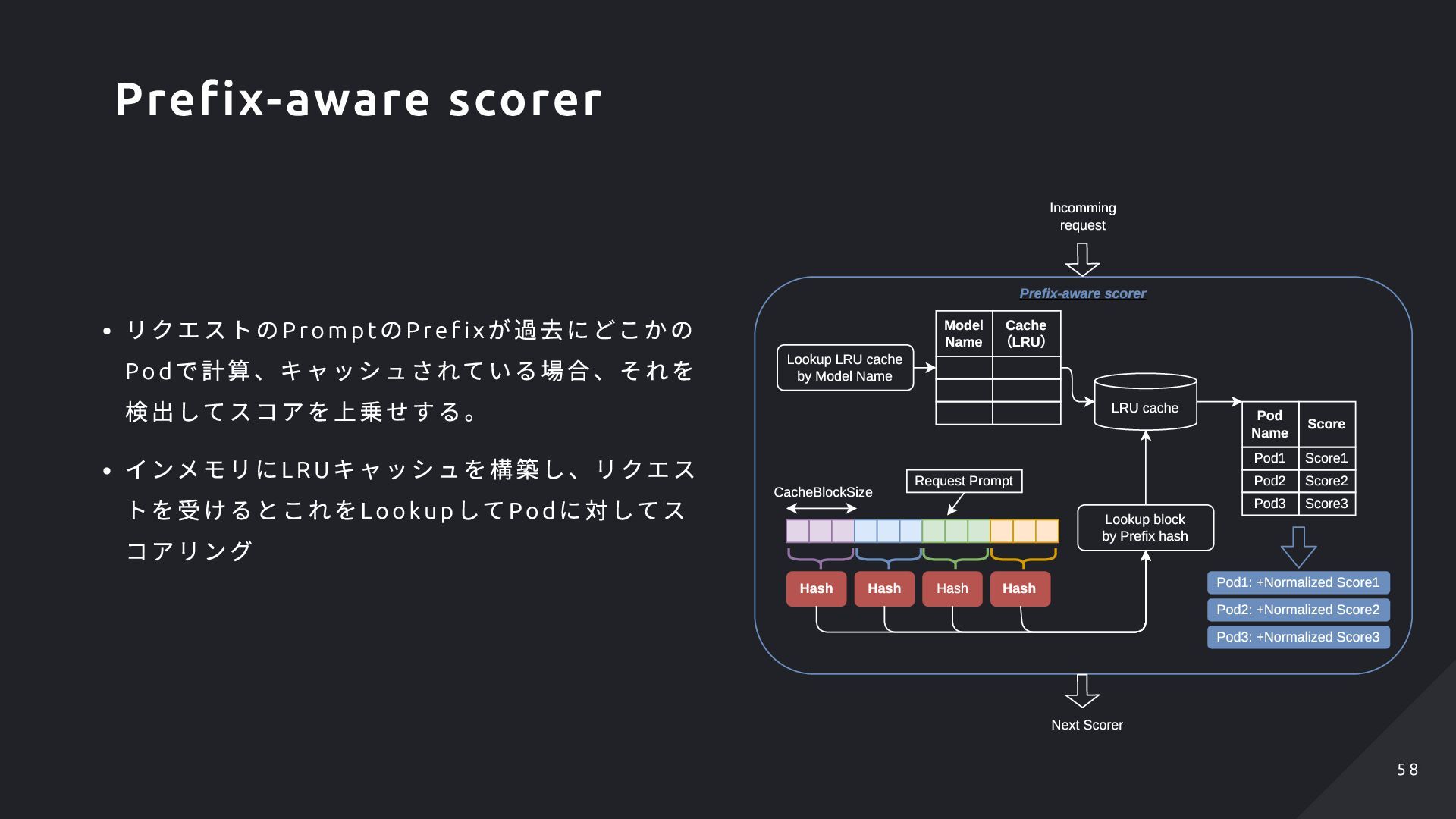
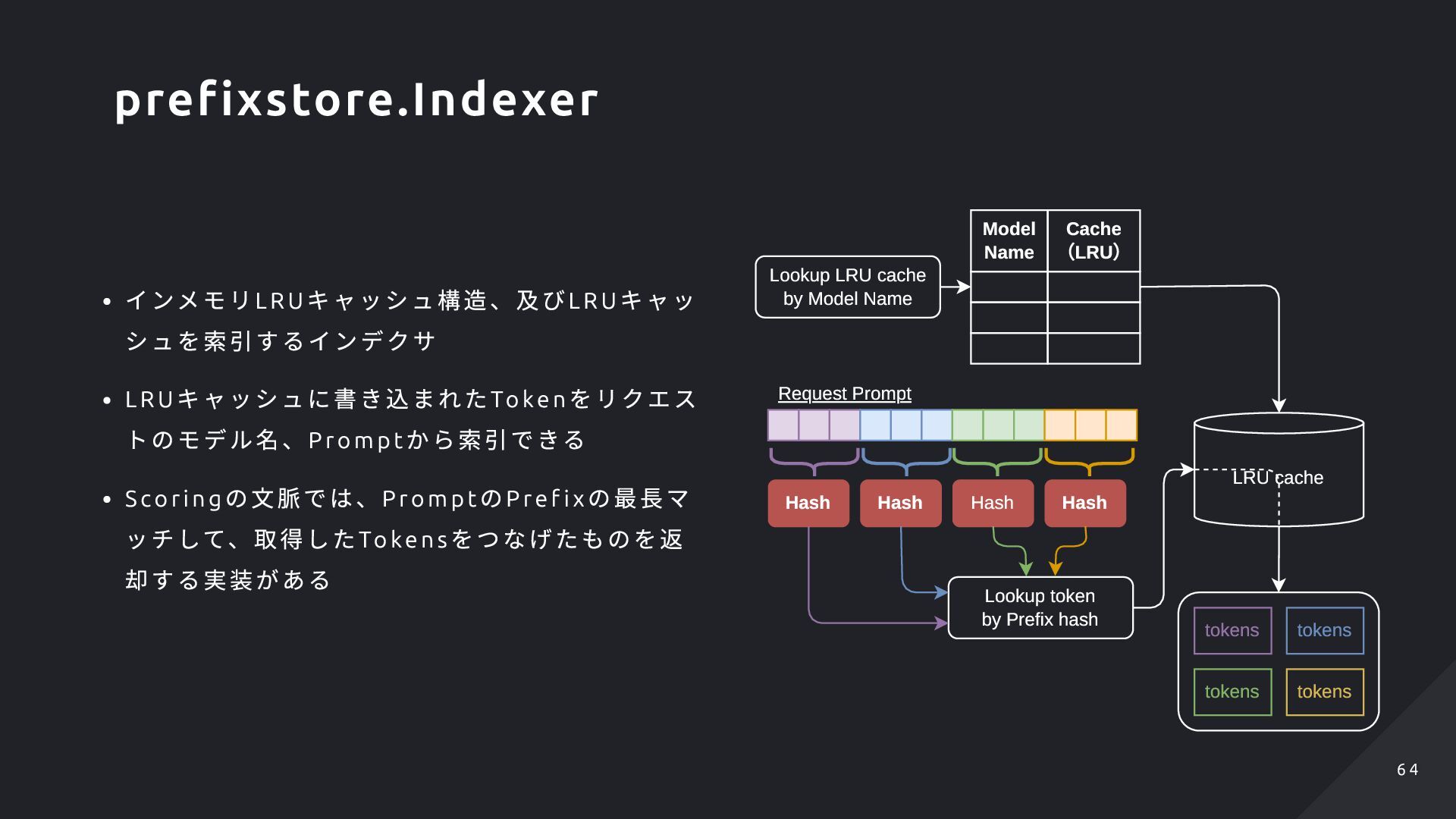
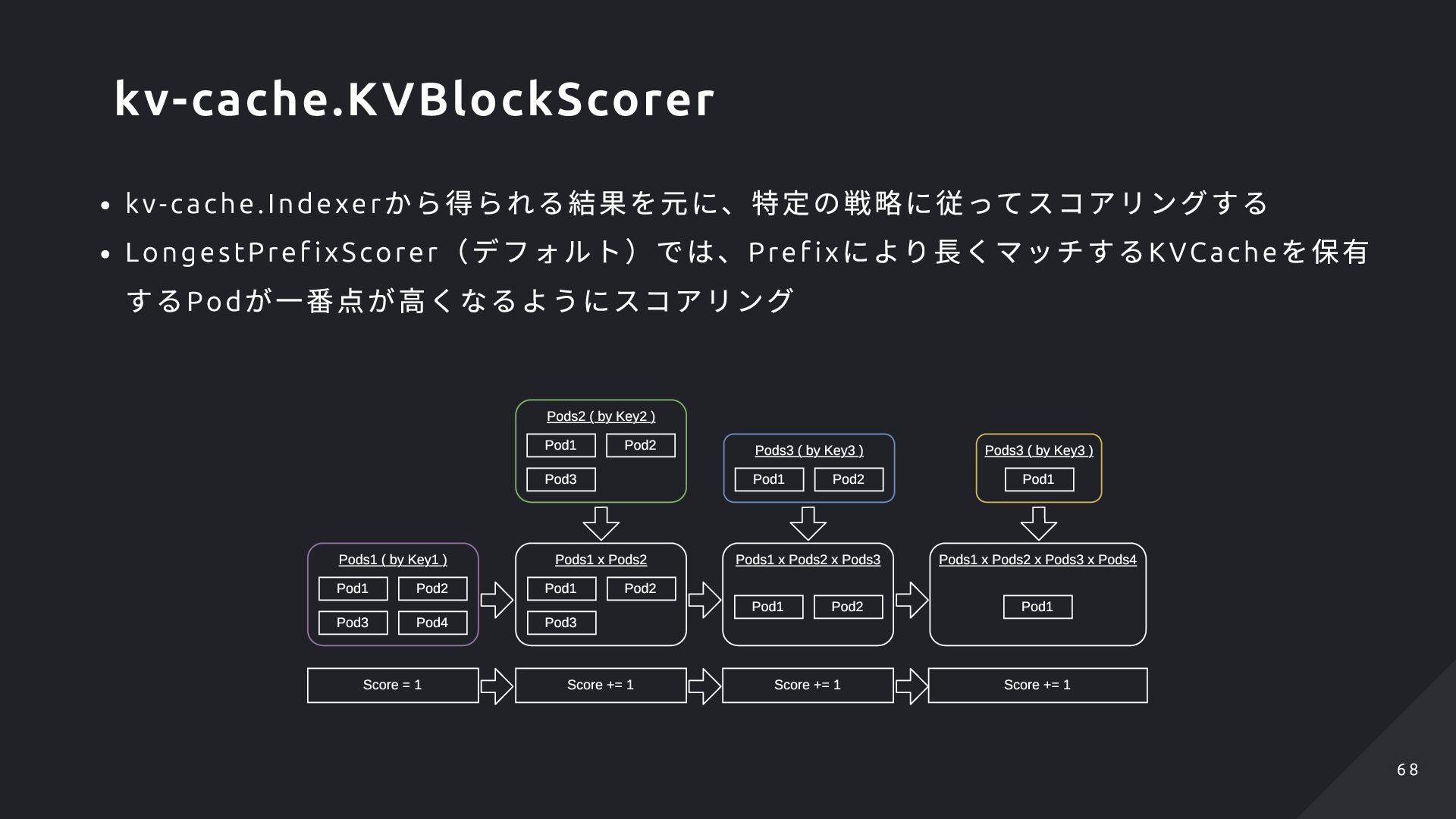
から索引できる Scori ng の文脈では、Prompt のPre f ix の最長マ ッチして、取得したTokens をつなげたものを返 却する実装がある Model Name Cache (LRU) Lookup LRU cache by Model Name LRU cache Hash Hash Hash Hash Lookup token by Prefix hash Request Prompt tokens tokens tokens tokens prefixstore.Indexer 6 4 6 4
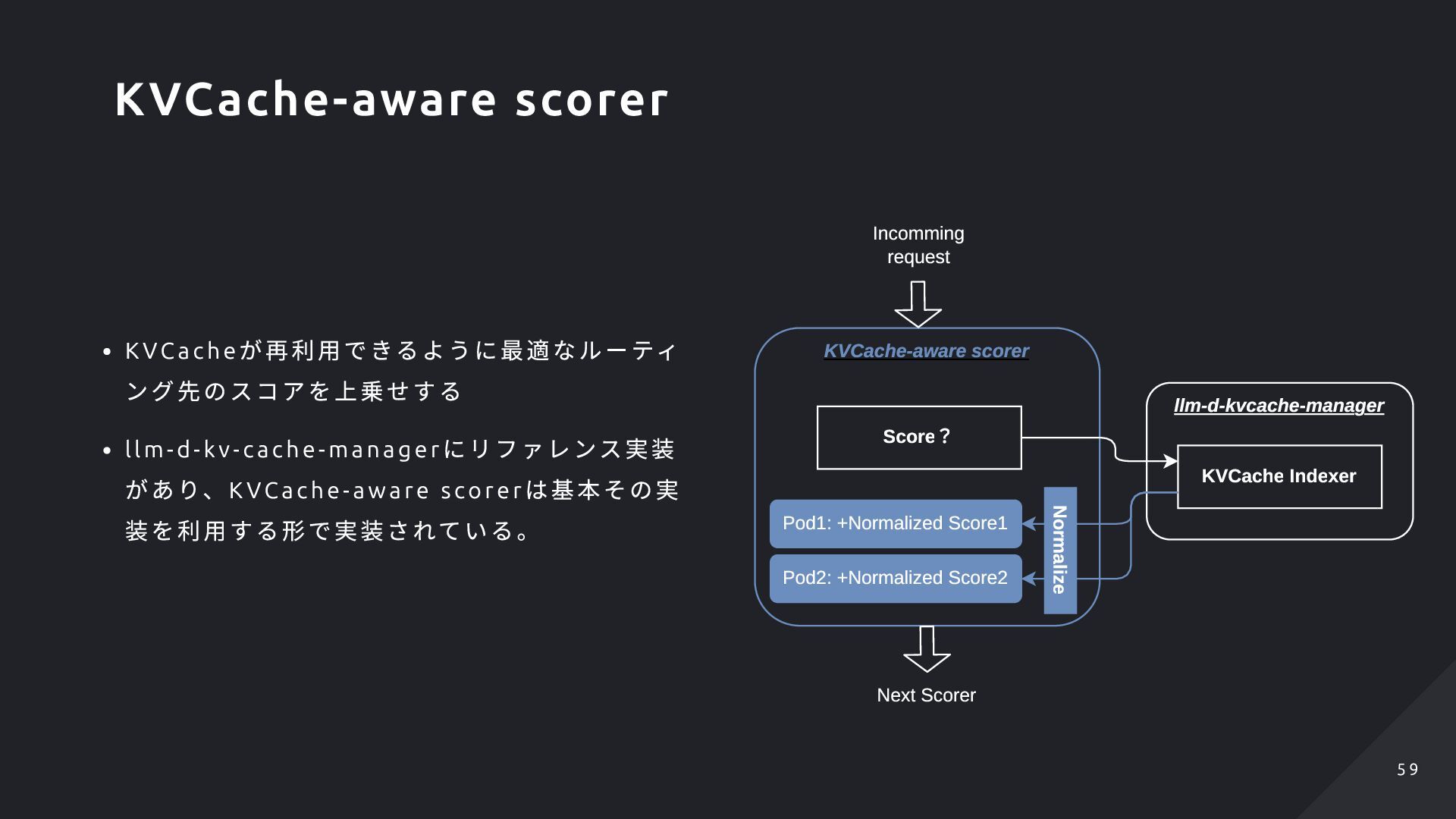
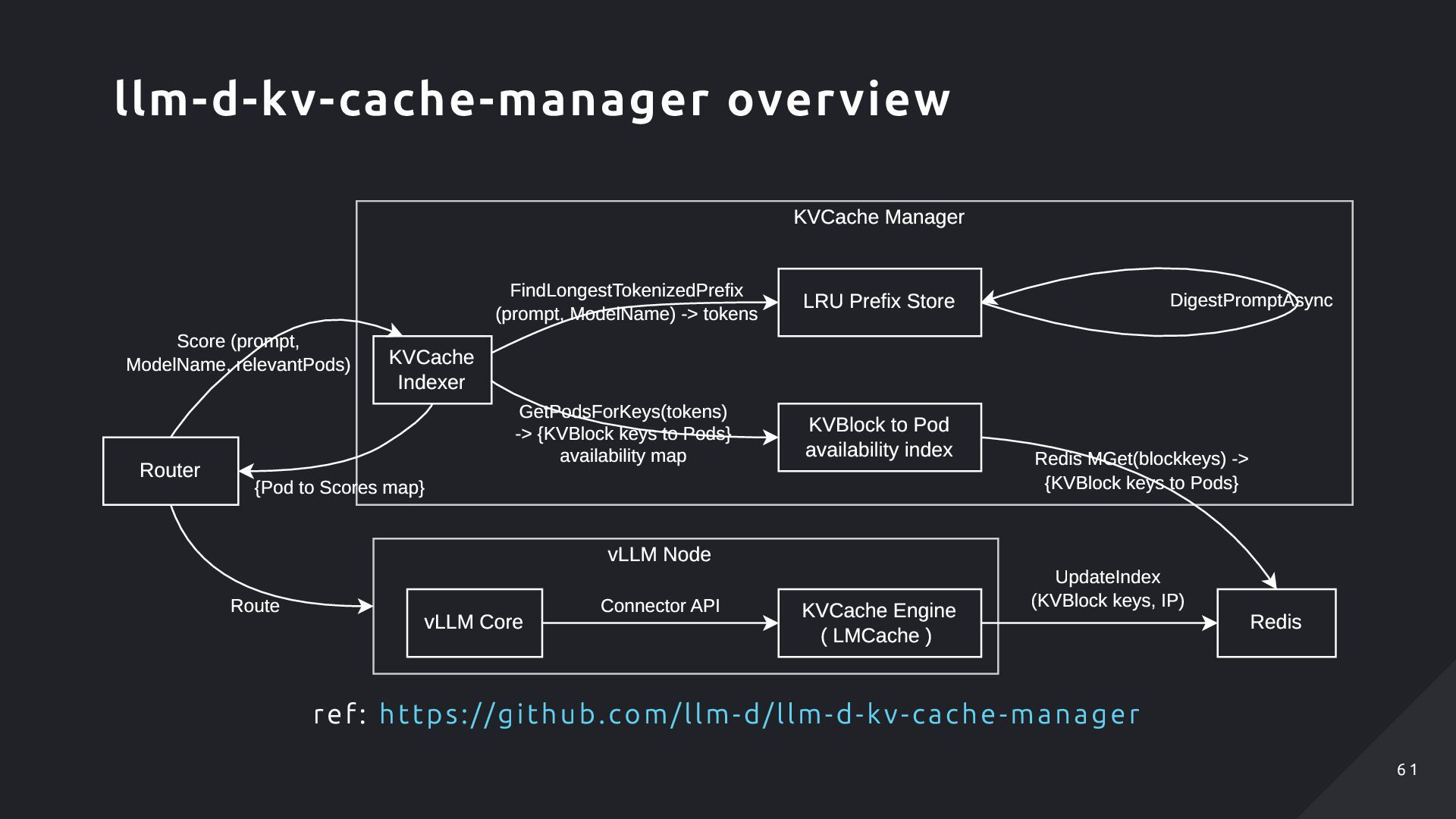
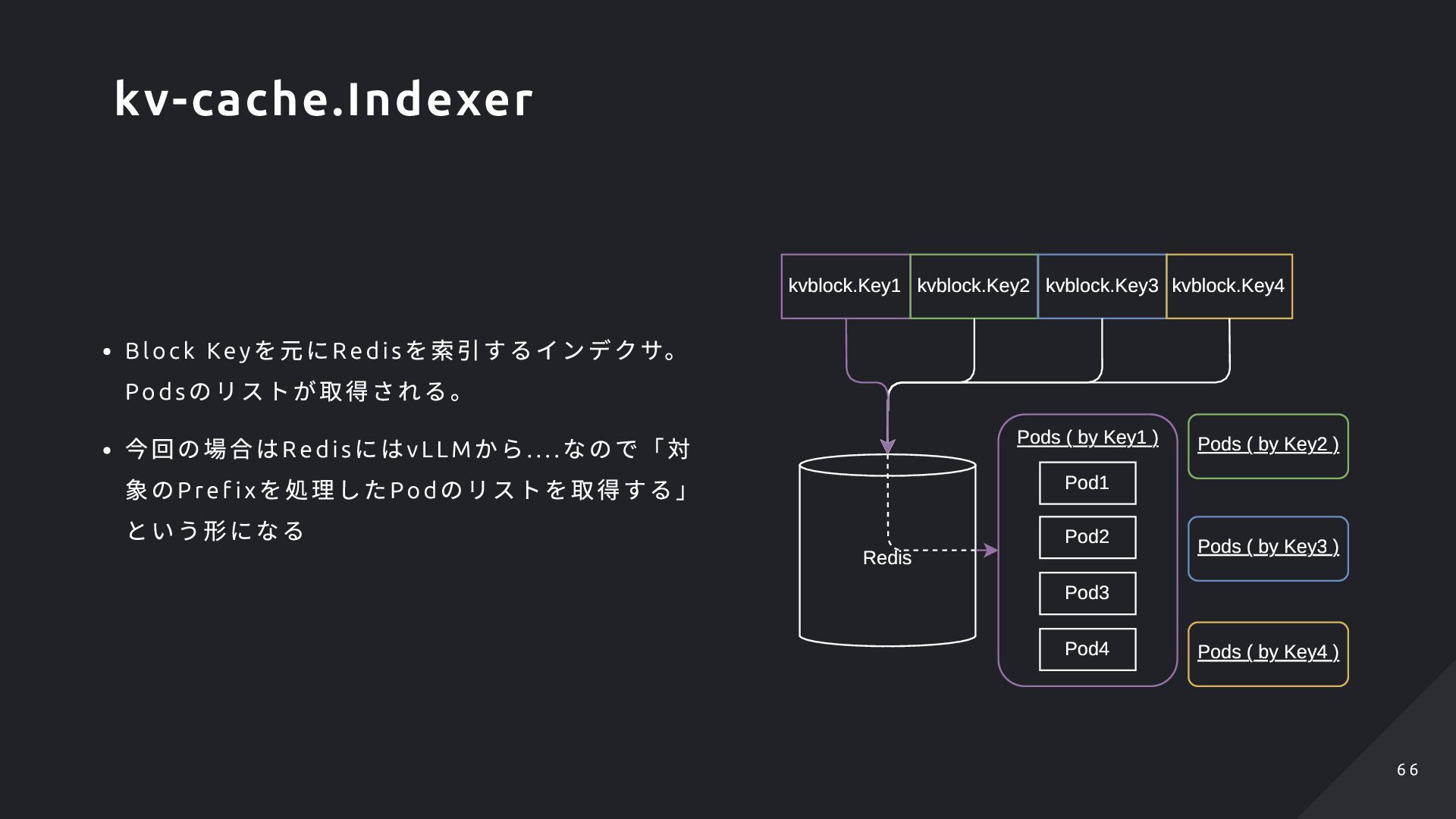
ver に該当する。 Lookup Ser ver にはK V- cache のLocalit y (Host :Port )が記述されているため、ここから Host (= Pod )を取り出せる ただし、この実装は現在アップストリームでは非 推奨としてより良い形にするべく絶賛議論が進ん でいます Redis ( Lookup Server ) KVCache Indexer Pods vLLM w/ LMCache vLLM w/ LMCache vLLM w/ LMCache Store kv-cache locality Lookup for Scoring What is this Redis? ... LMCache's LookupServer! 6 7 6 7
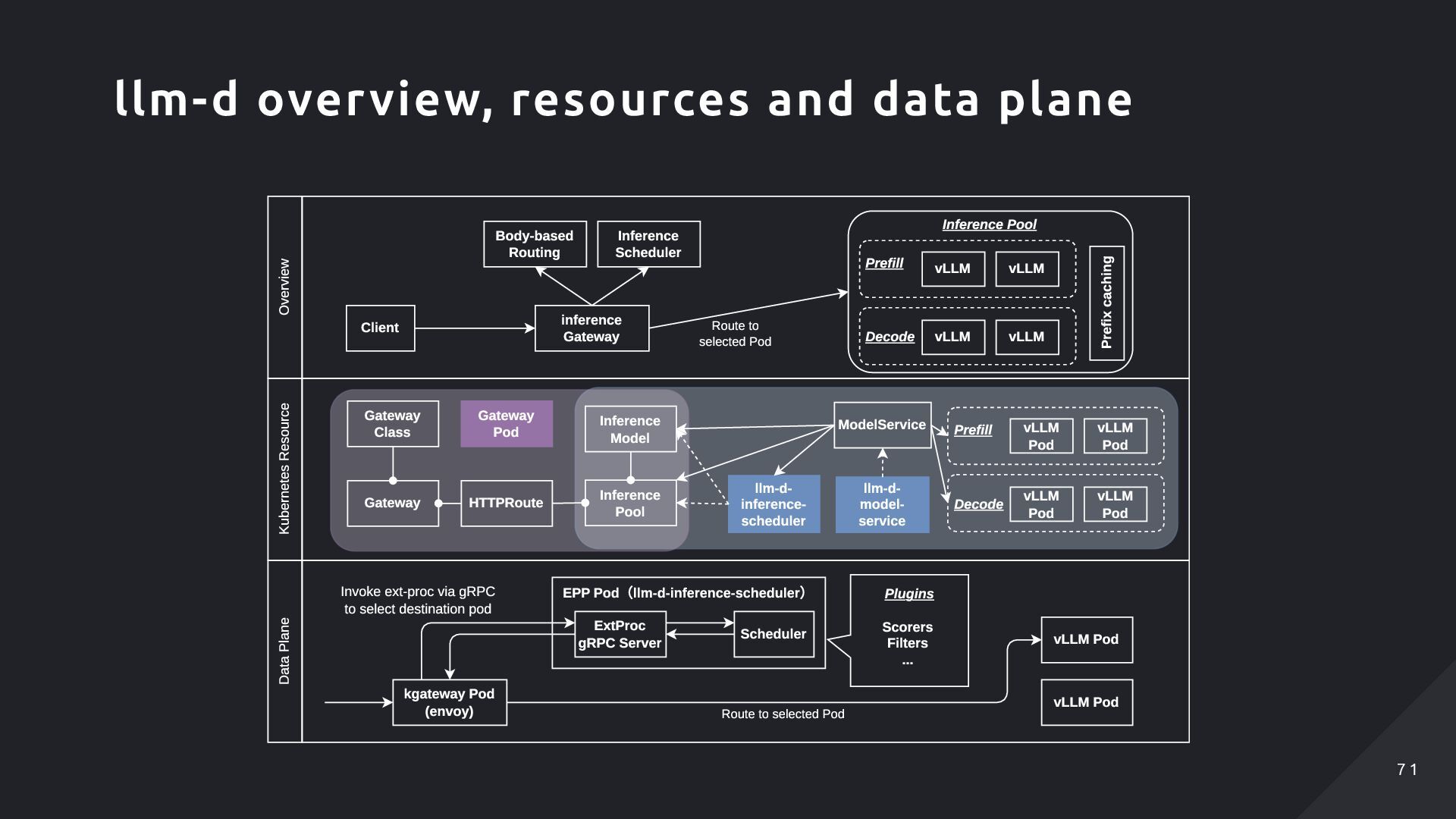
Pool Body-based Routing Inference Scheduler vLLM Prefix caching vLLM vLLM Prefill Decode Route to selected Pod Gateway Gateway Class HTTPRoute Inference Pool Inference Model llm-d- inference- scheduler Gateway Pod kgateway Pod (envoy) EPP Pod(llm-d-inference-scheduler) ExtProc gRPC Server Scheduler Invoke ext-proc via gRPC to select destination pod vLLM Pod vLLM Pod Route to selected Pod ModelService vLLM Pod vLLM Pod vLLM Pod vLLM Pod Prefill Decode llm-d- model- service Scorers Filters ... Plugins llm-d overview, resources and data plane 7 1 7 1
Serving with PagedAttention Mastering LLM Techniques: Inference Optimization How continuous batching enables 23x throughput in LLM inference while reducing p50 latency Continuous vs dynamic batching for AI inference Pref ixCaching - SGLang vs vLLM: Token-Level Radix Tree vs Block Level Hashing References 8 0 8 0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Token から(外部)Redi s の索引に利用するKe y (Block Key )を作成するプロセッサ tokens( []uint32](https://files.speakerdeck.com/presentations/45de3de5409a4c0a8a77e3a5128d3938/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}