Presented at Silicon Valley Cloud Computing Group on July 18 2012 (http://www.meetup.com/cloudcomputing/events/71823882/)
Audio available at: http://g33ktalk.com/performance-and-fault-tolerance-for-the-netflix-api/
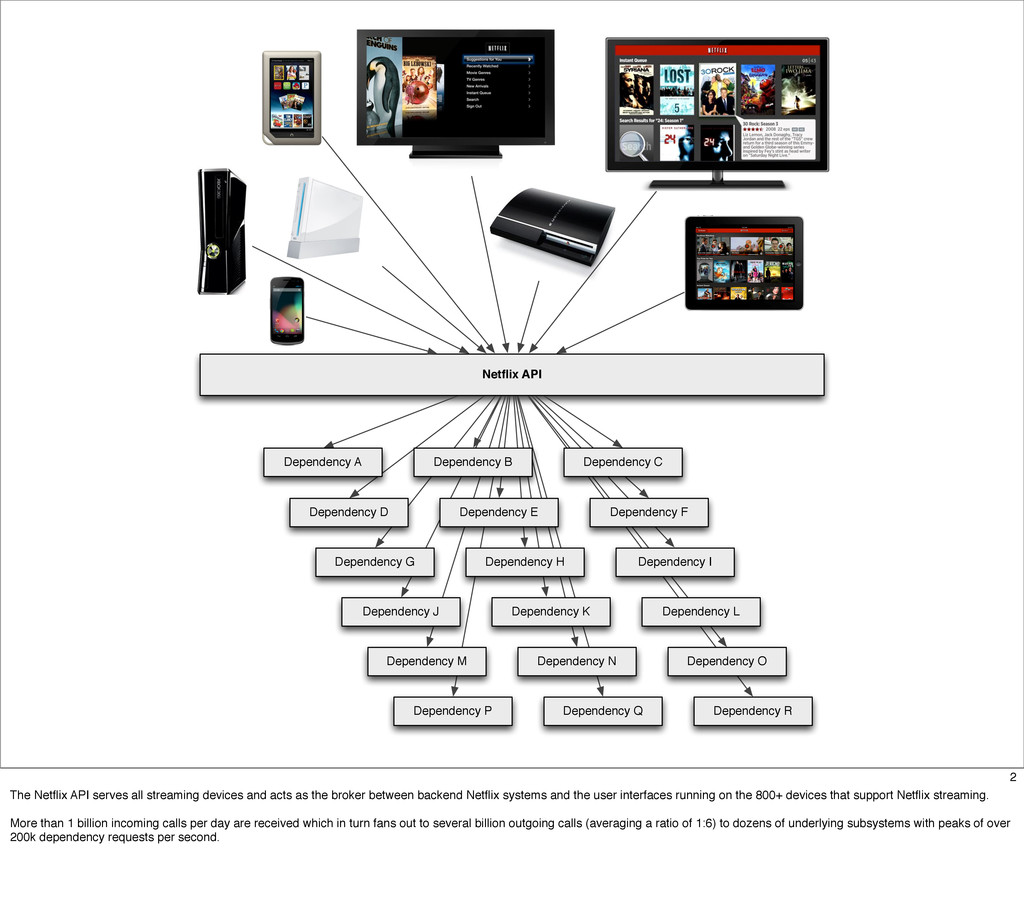
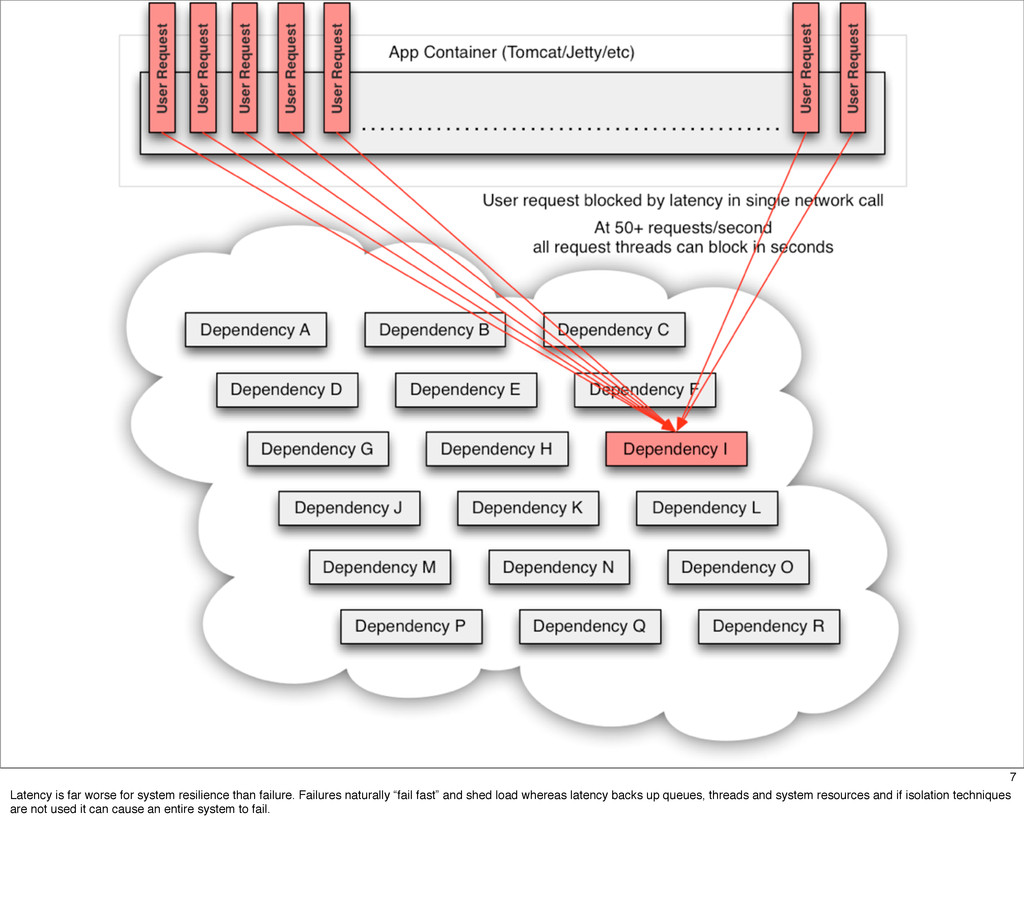
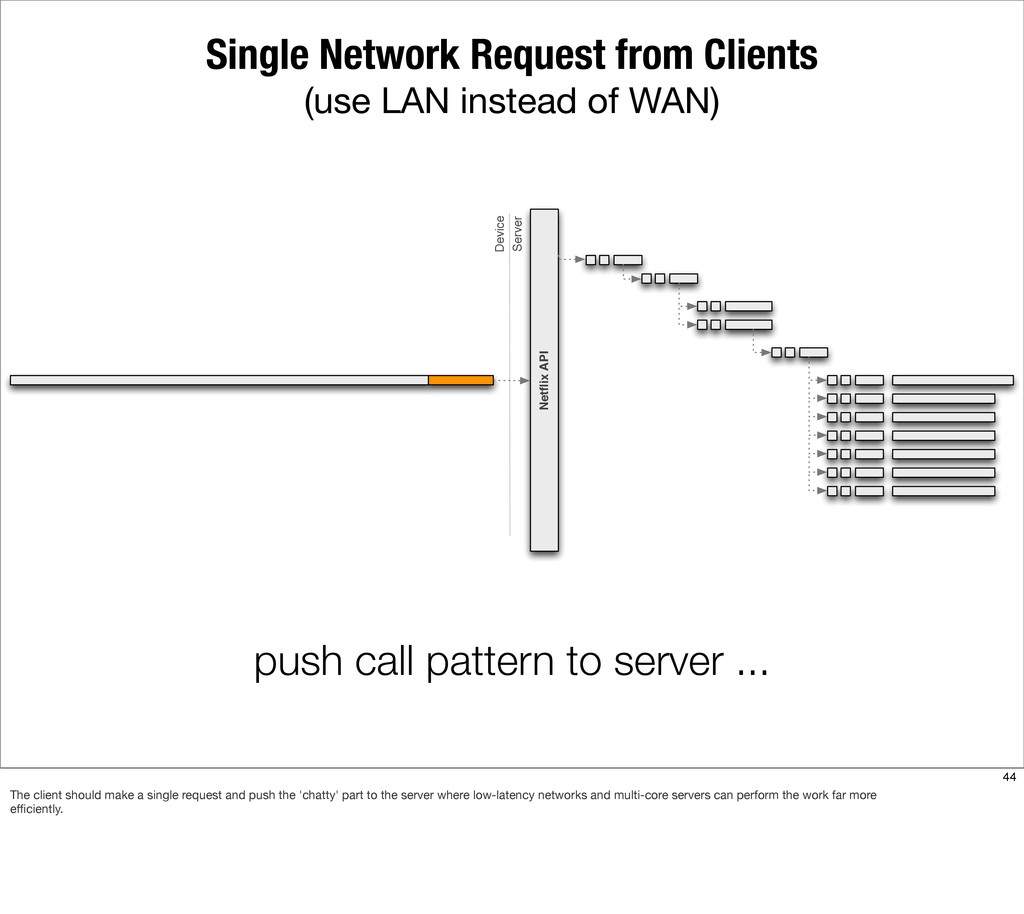
The Netflix API receives over a billion requests a day which translates into multiple billions of calls to underlying systems in the Netflix service-oriented architecture. These requests come from more than 800 different devices ranging from gaming consoles like the PS3, XBox and Wii to set-top boxes, TVs and mobile devices such as Android and iOS.
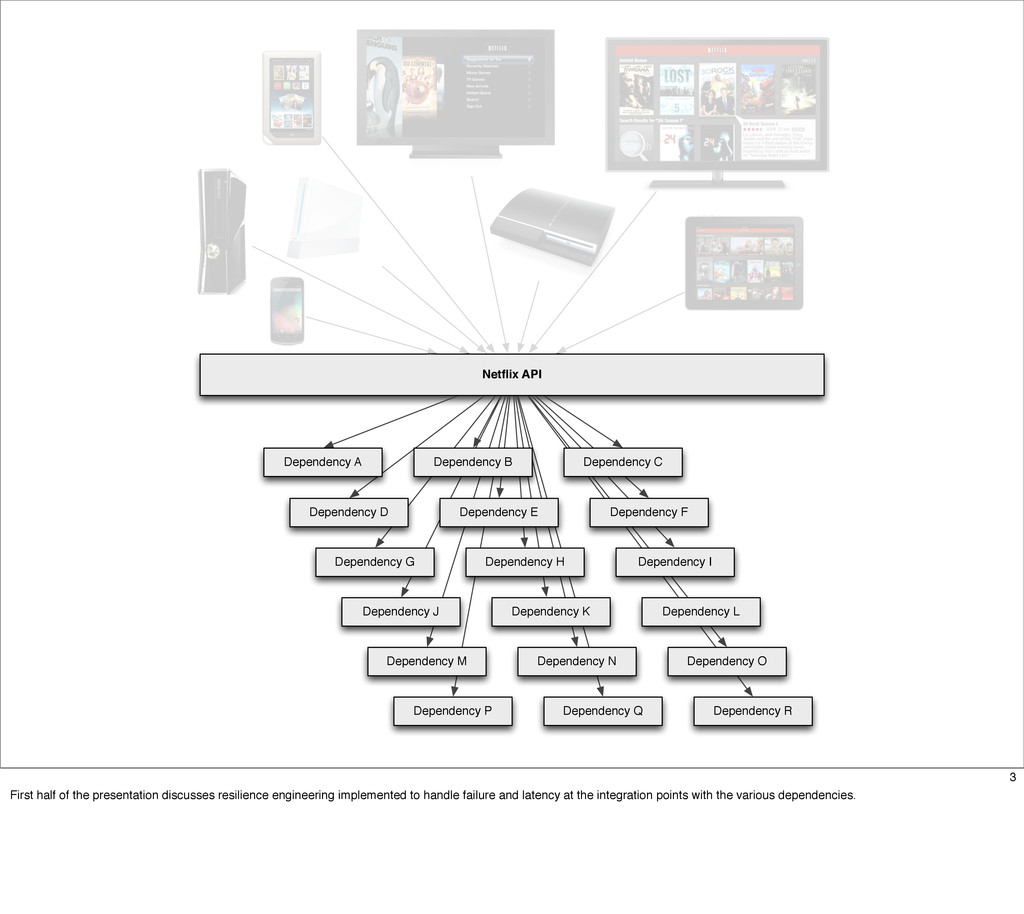
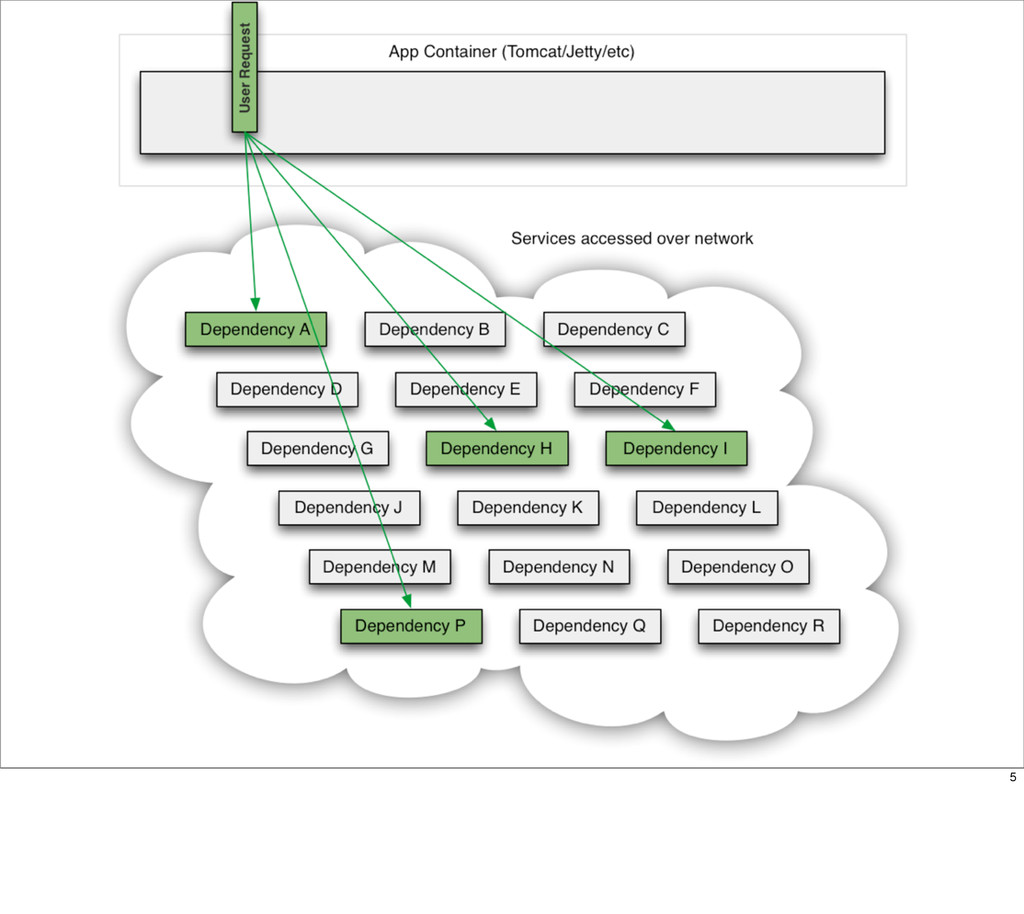
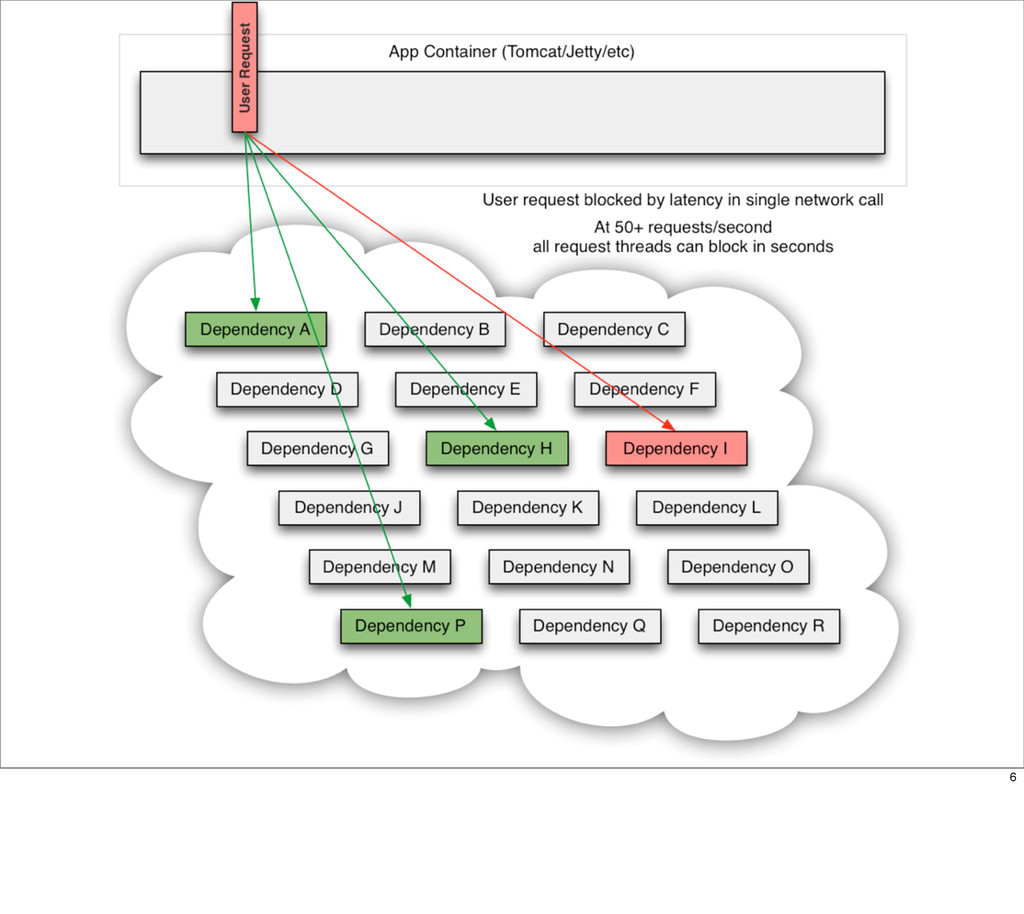
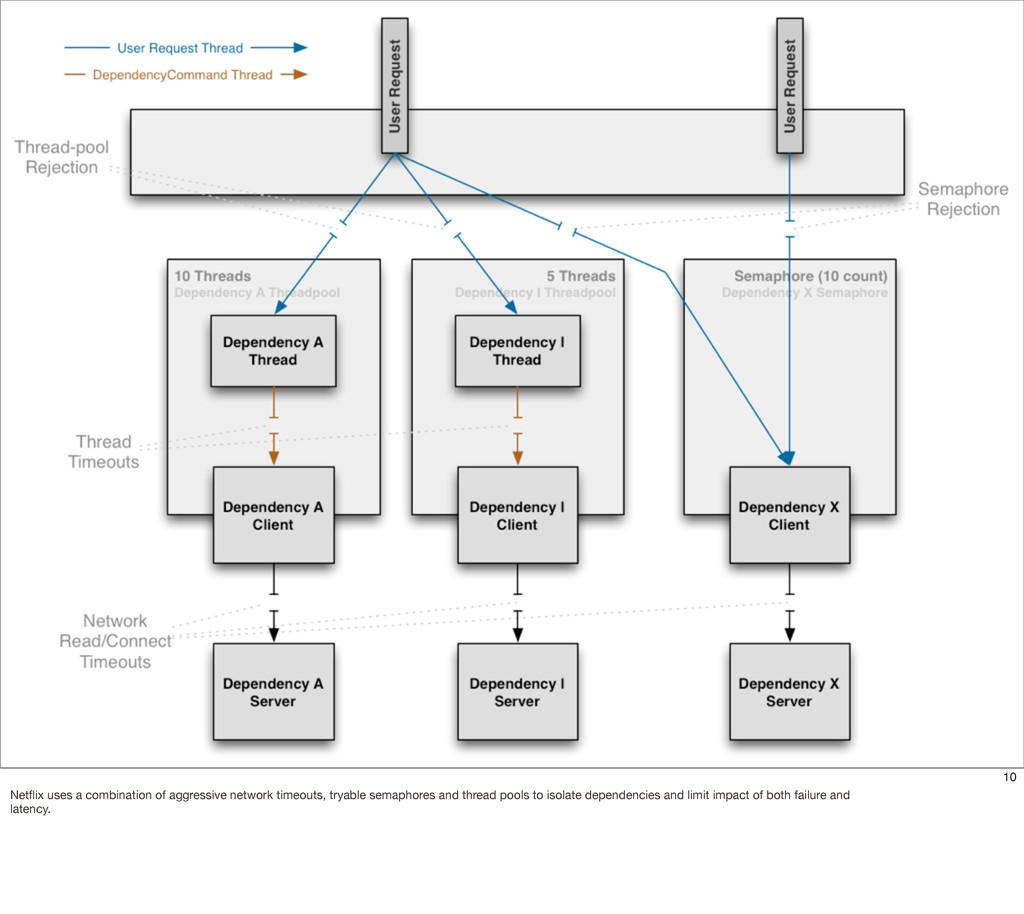
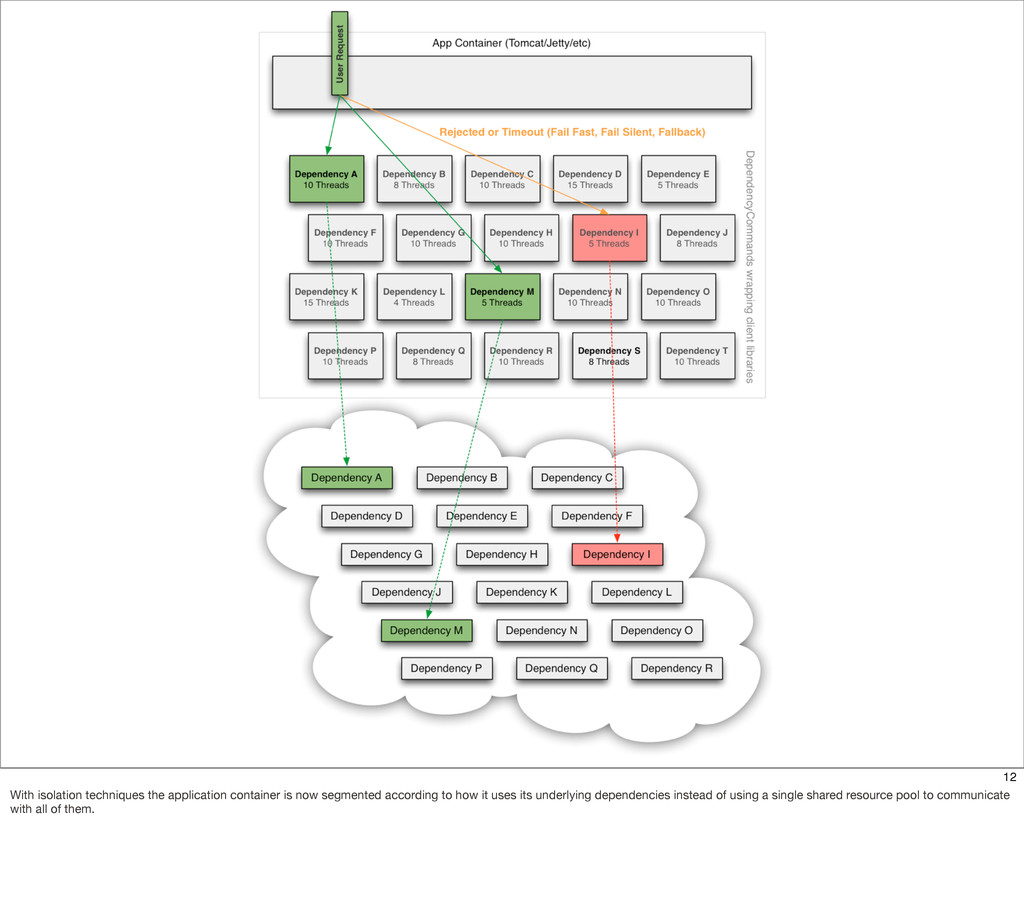
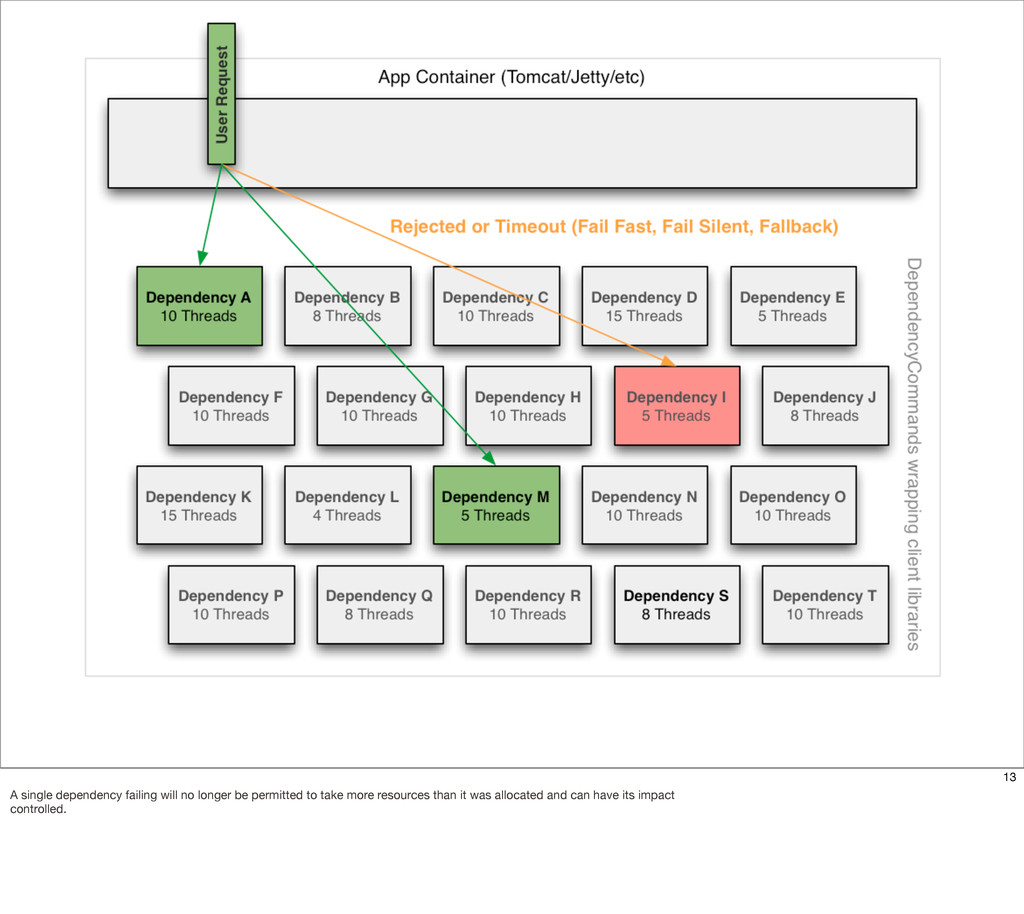
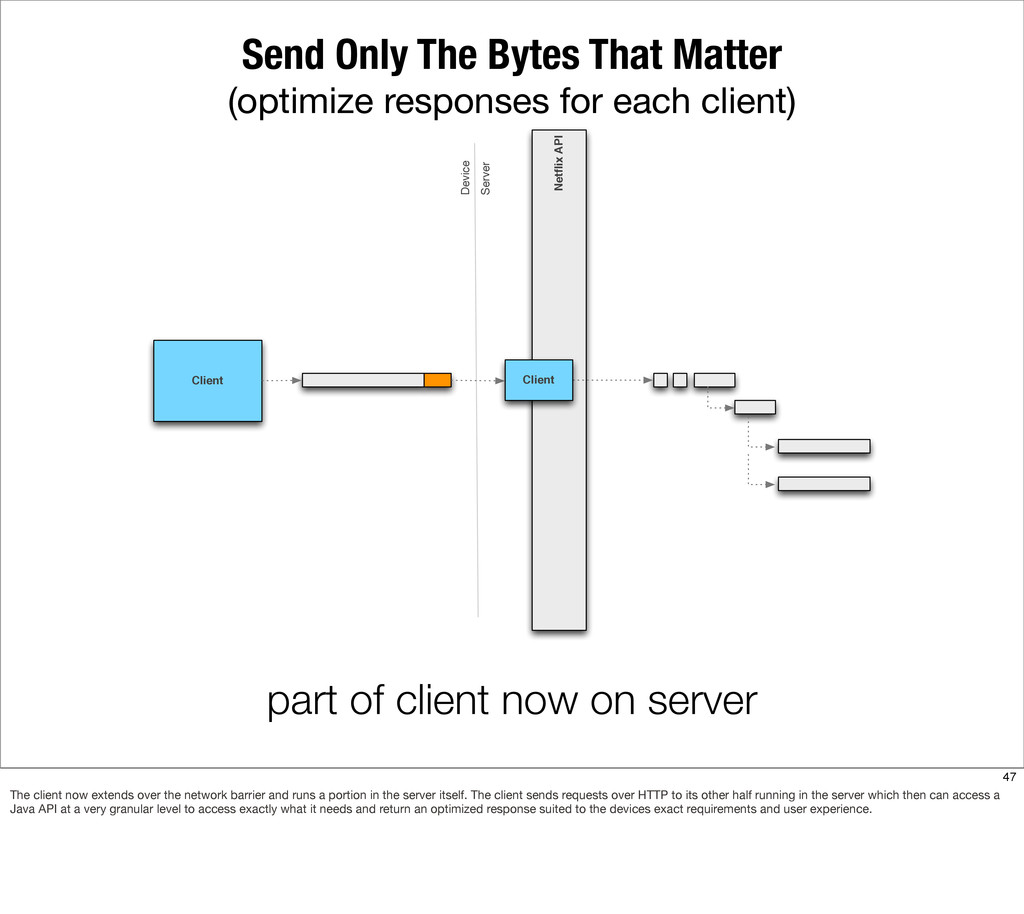
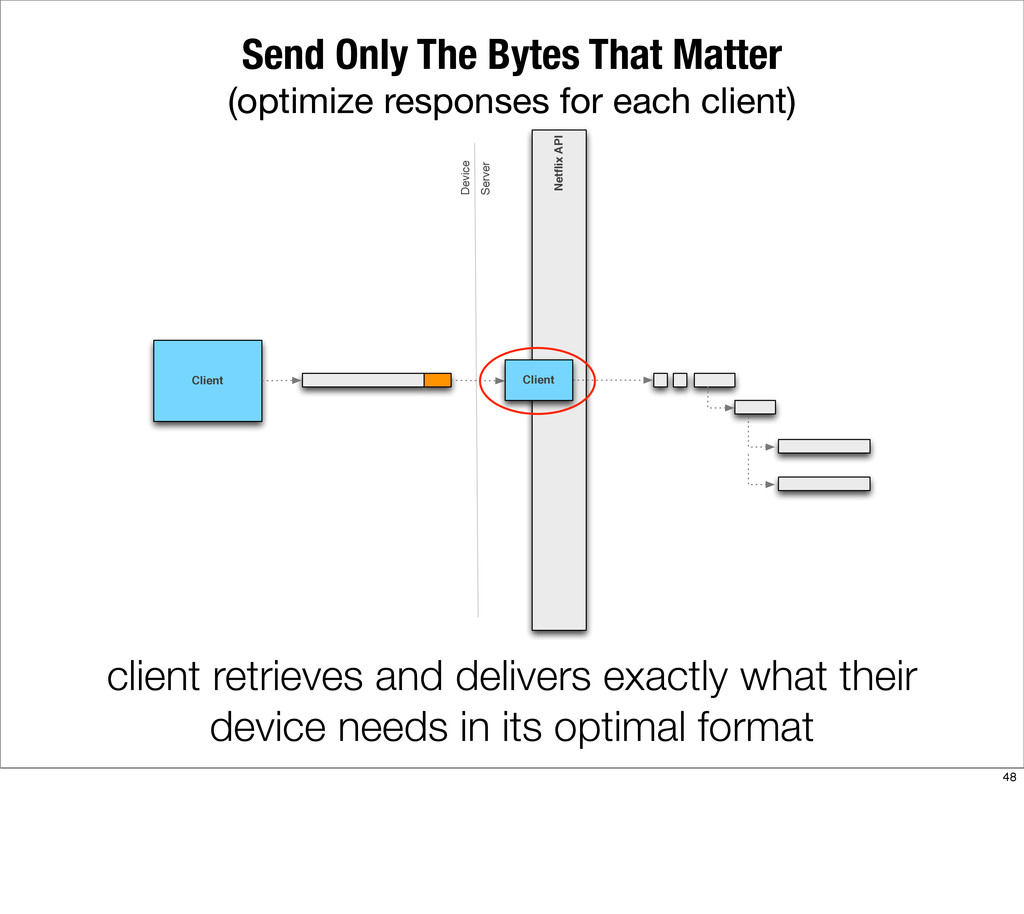
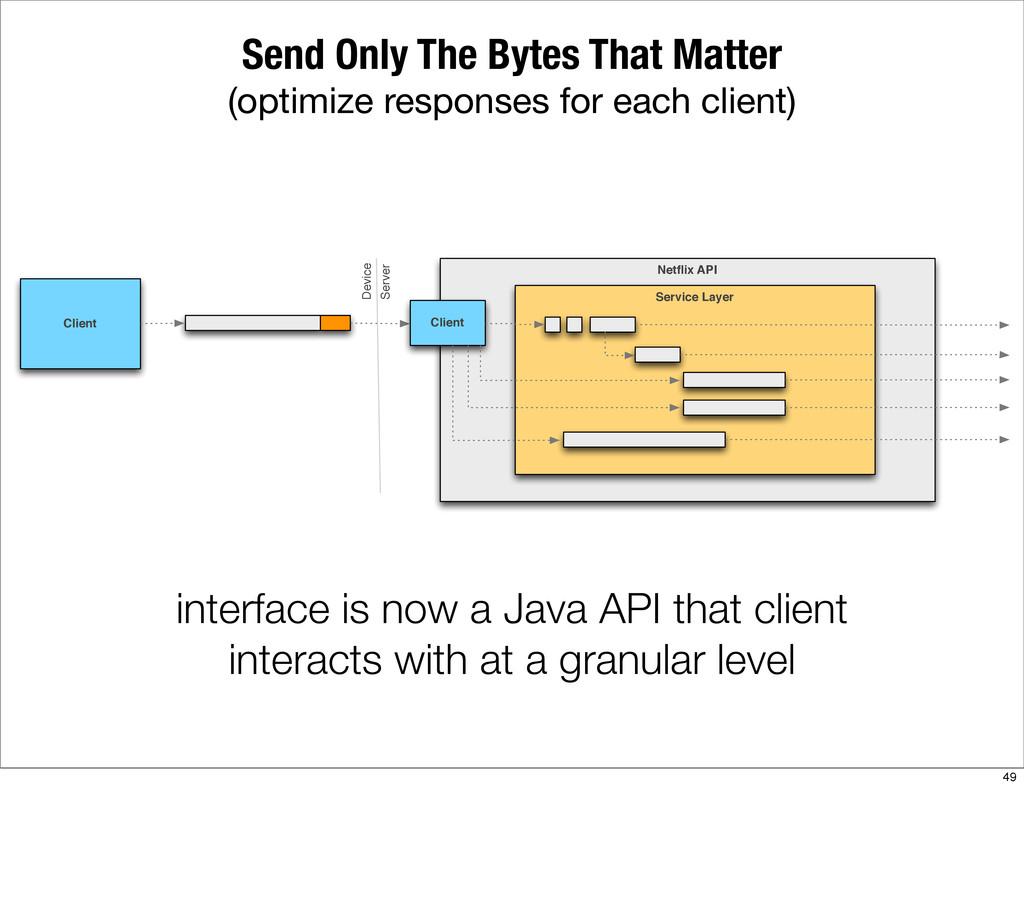
This presentation describes how the Netflix API supports those devices and achieves fault tolerance in a distributed architecture while depending on dozens of systems which can fail at any time. It also explains how a new system design allows each device to optimize API calls to their unique needs and leverage concurrency on the server-side to improve their performance.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
!["Timeout guard" daemon prio=10 tid=0x00002aaacd5e5000 nid=0x3aac runnable [0x00002aaac388f000] java.lang.Thread.State: RUNNABLE](https://files.speakerdeck.com/presentations/5009e377d46e8b0002016fad/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
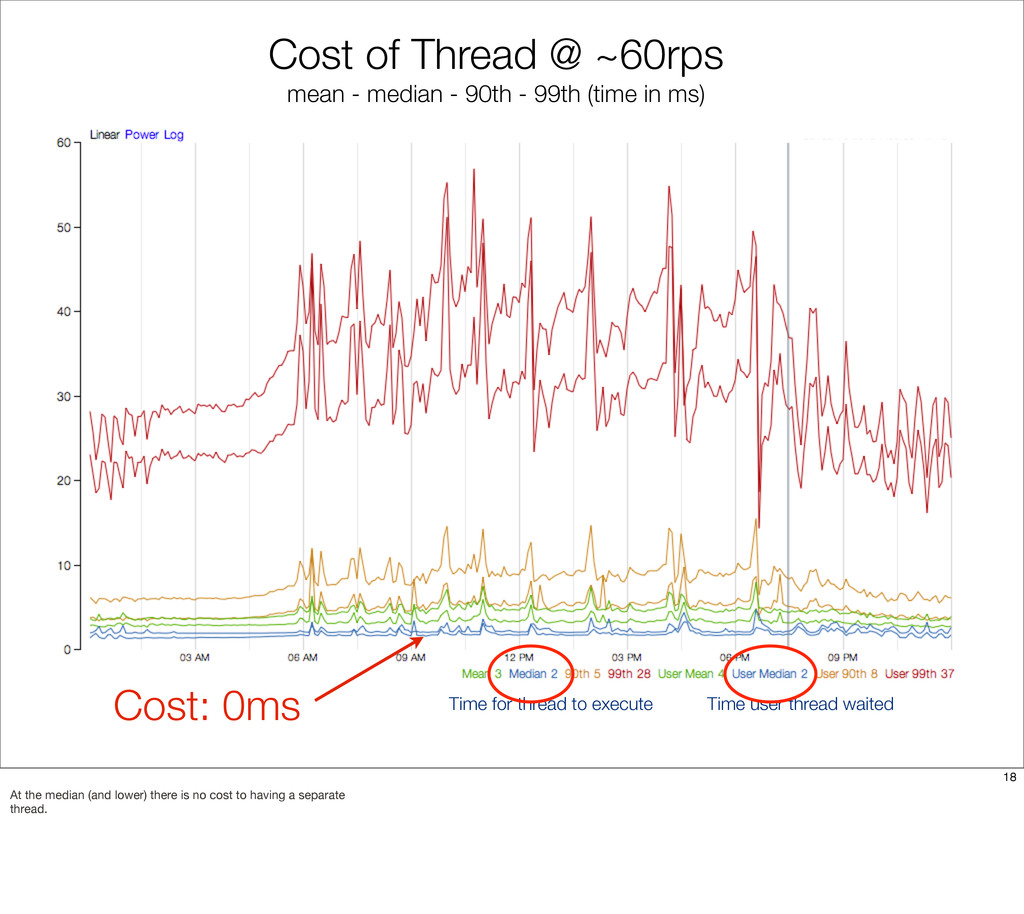{kind=link}
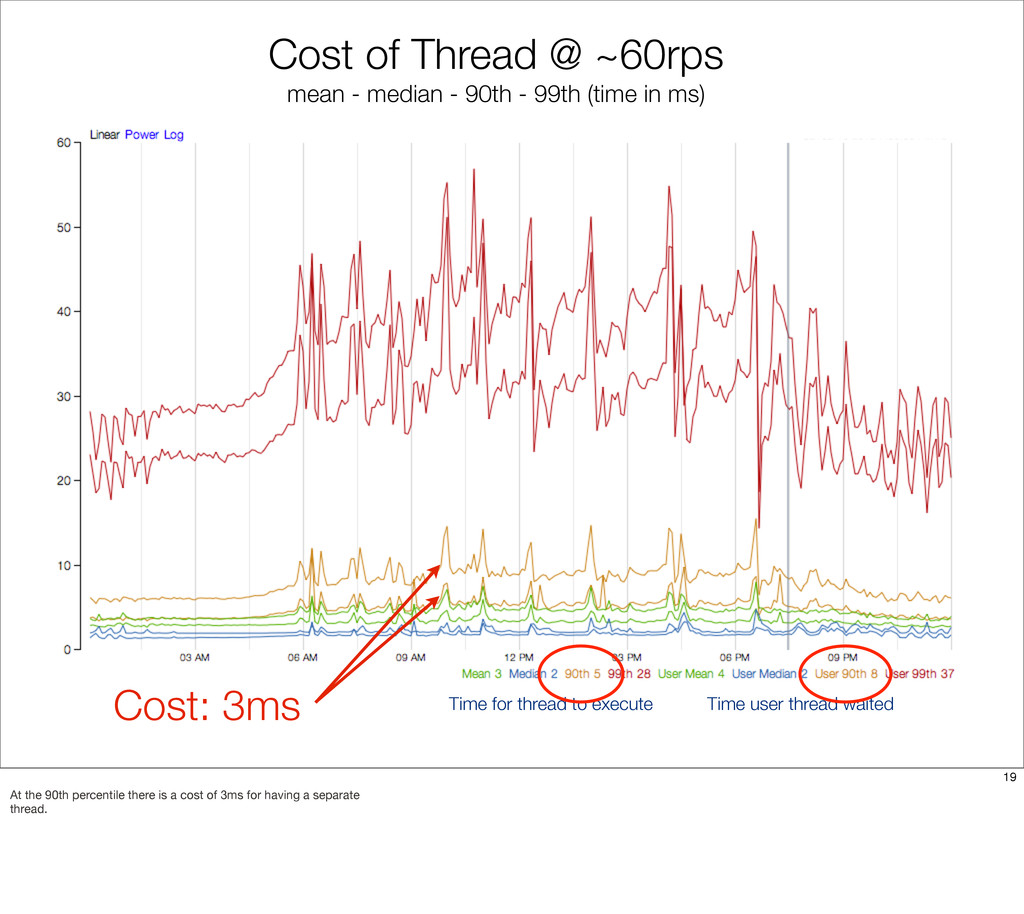{kind=link}
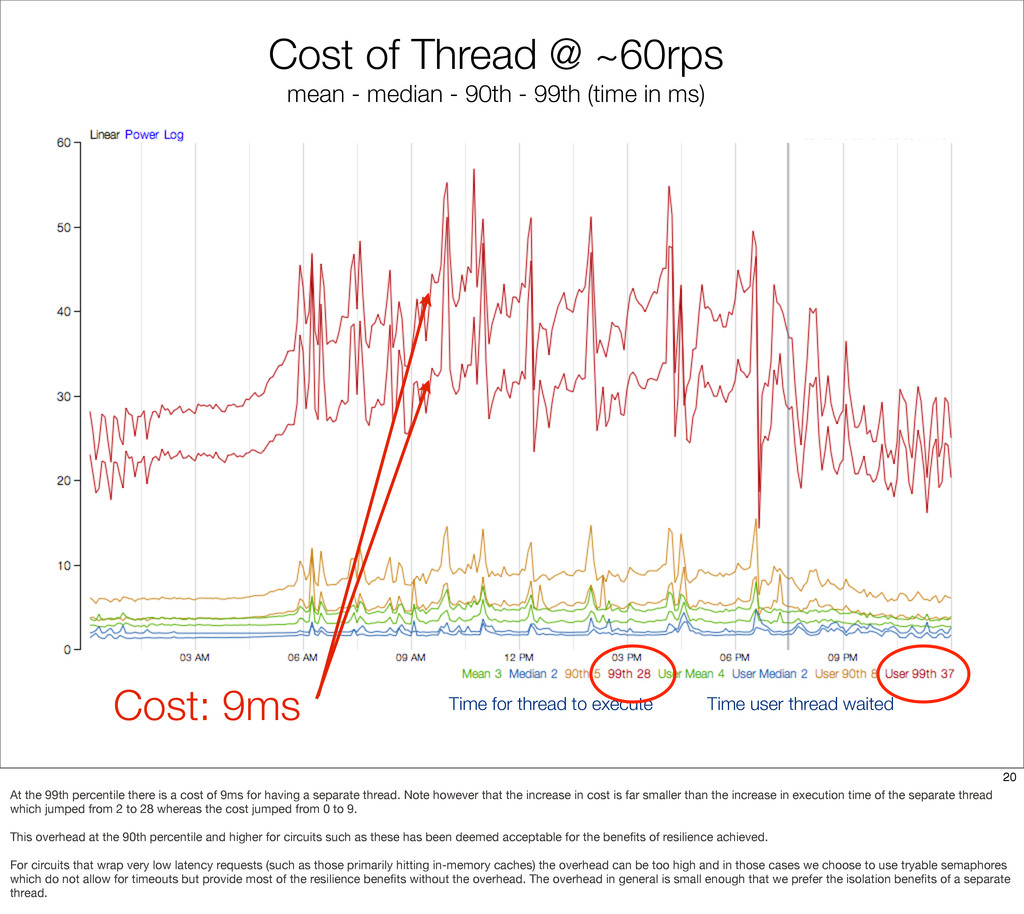{kind=link}
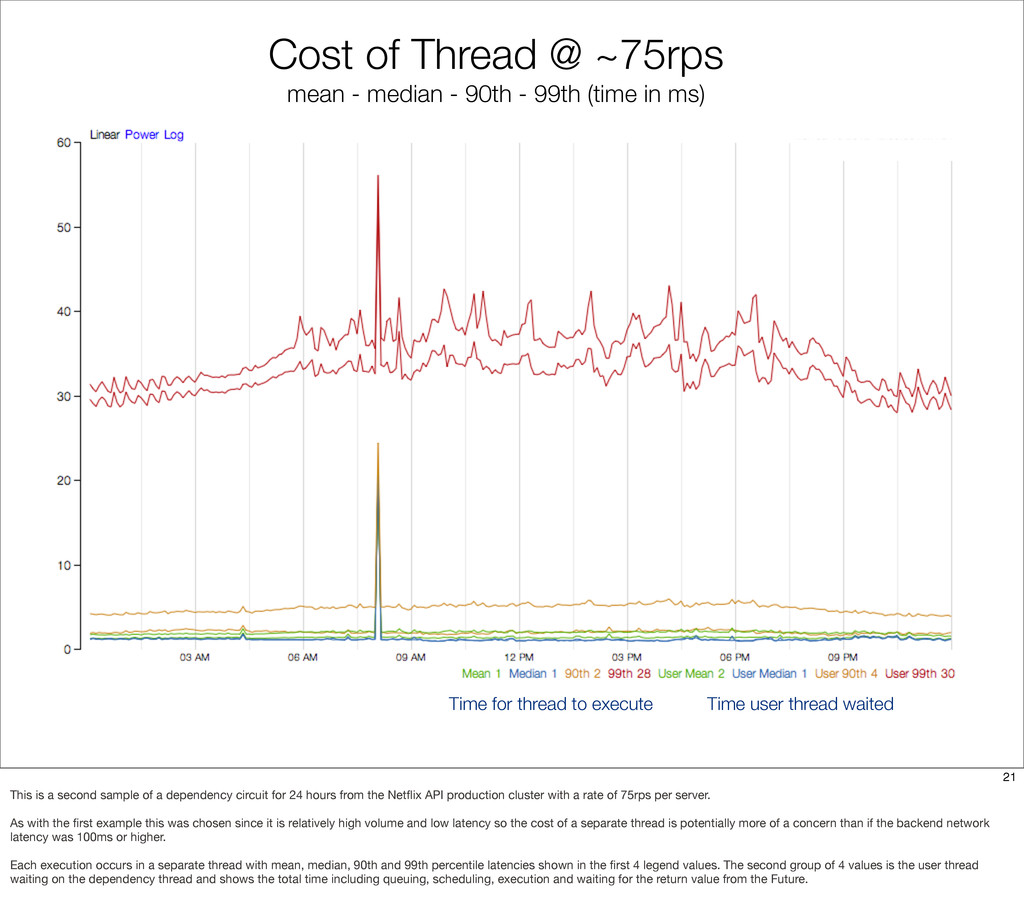{kind=link}
{kind=link}
{kind=link}
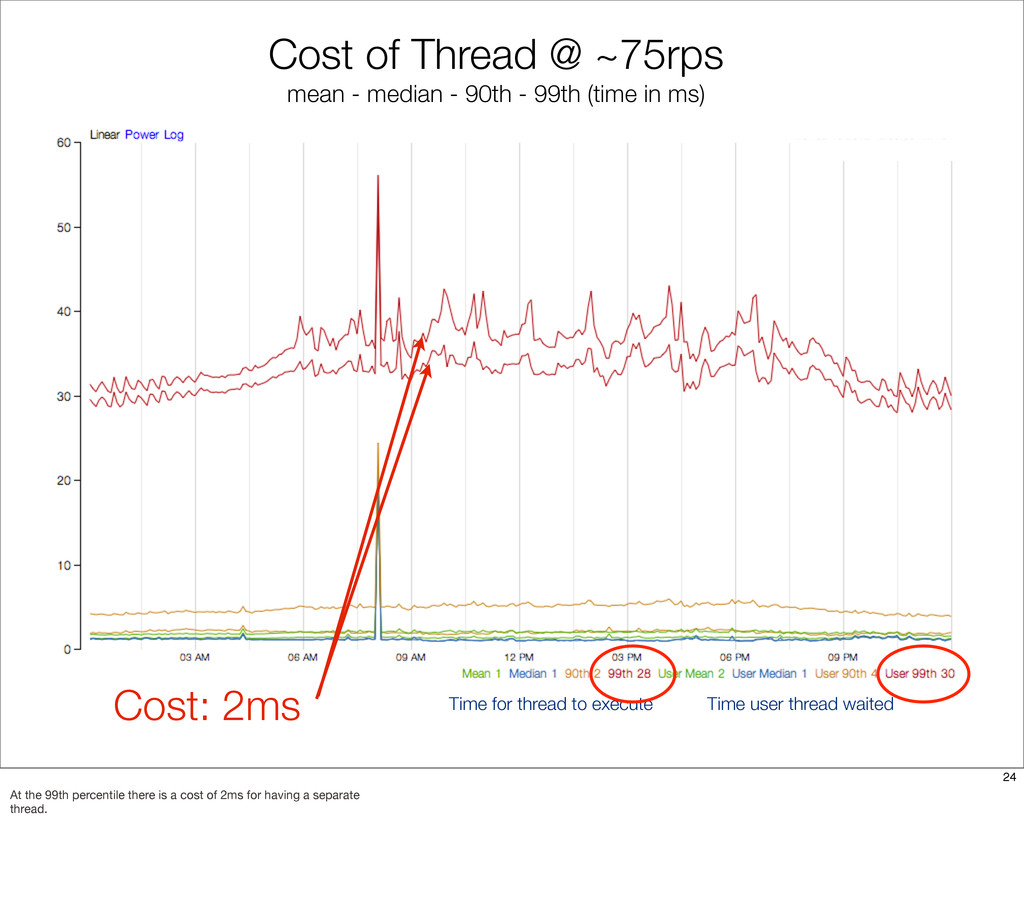{kind=link}
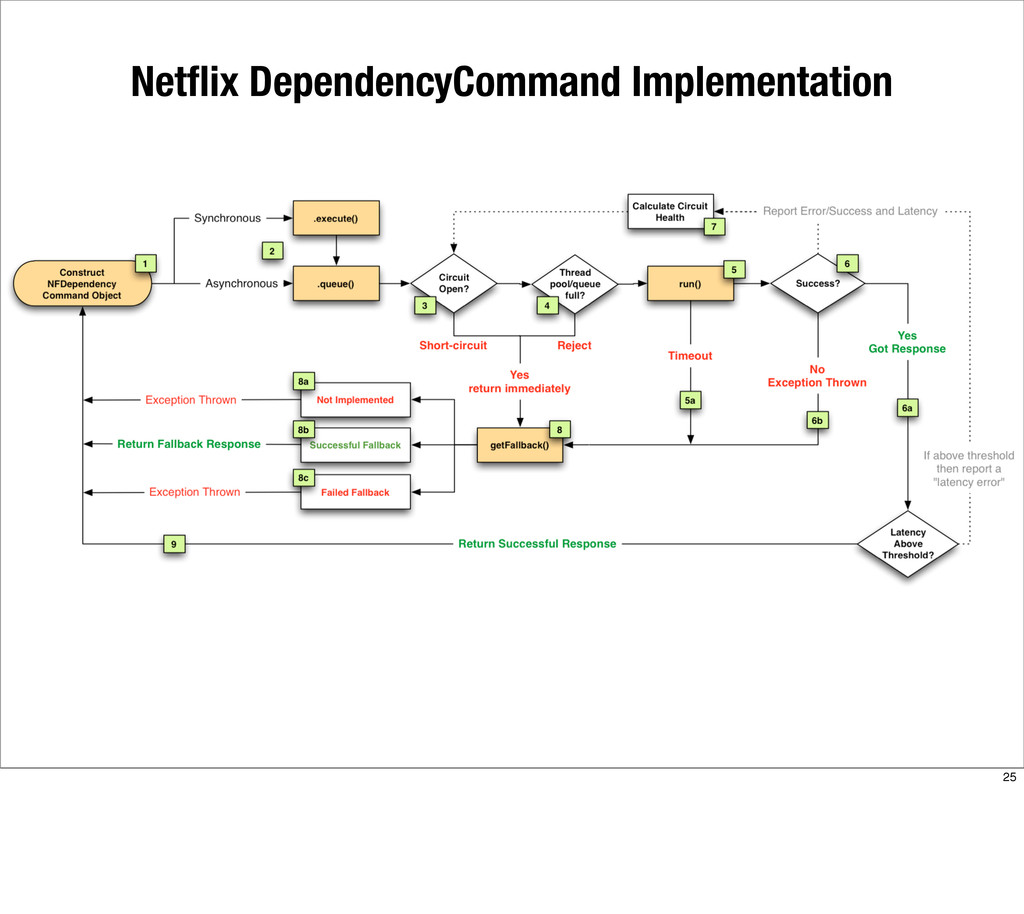{kind=link}
{kind=link}
{kind=link}
{kind=link}
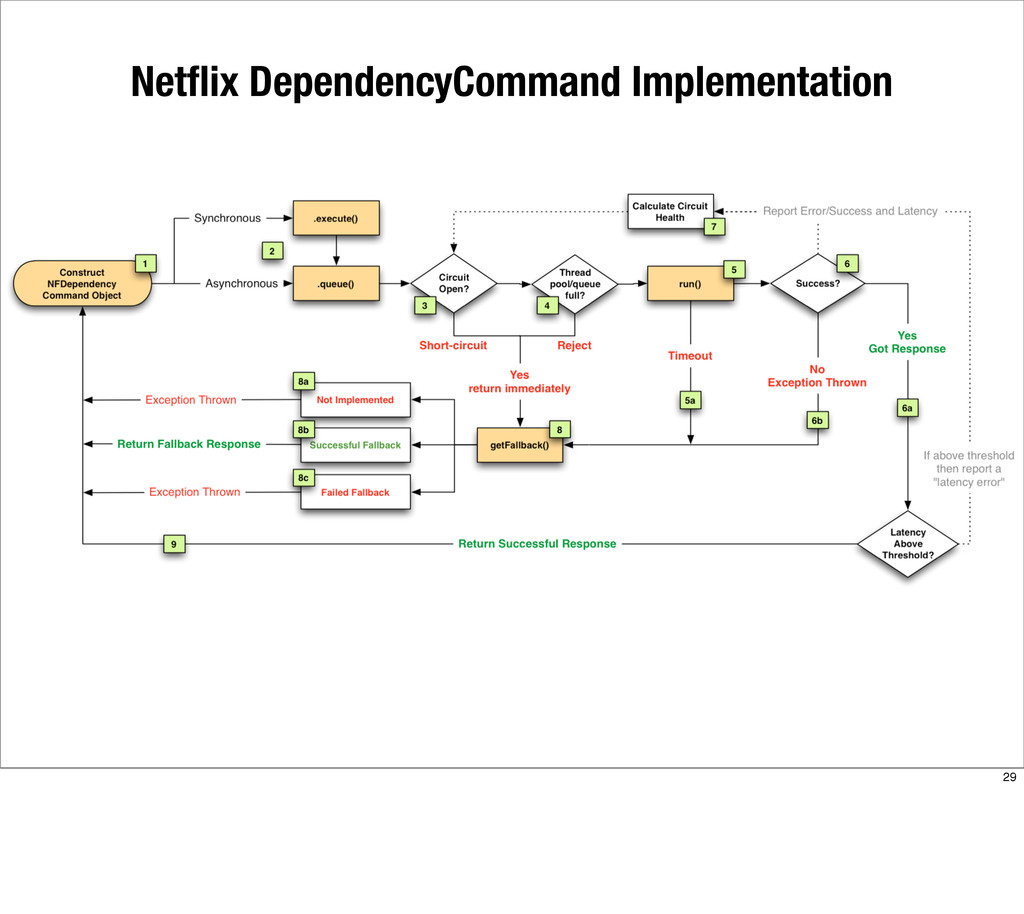{kind=link}
{kind=link}
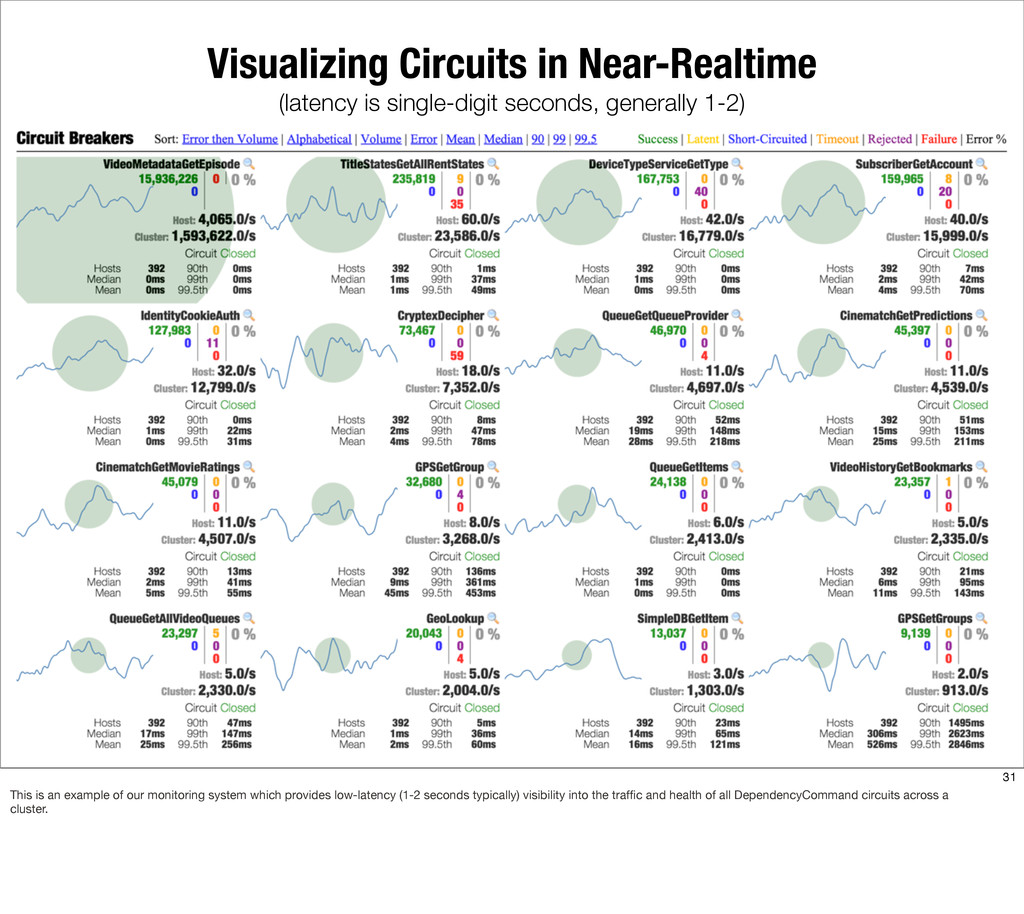{kind=link}
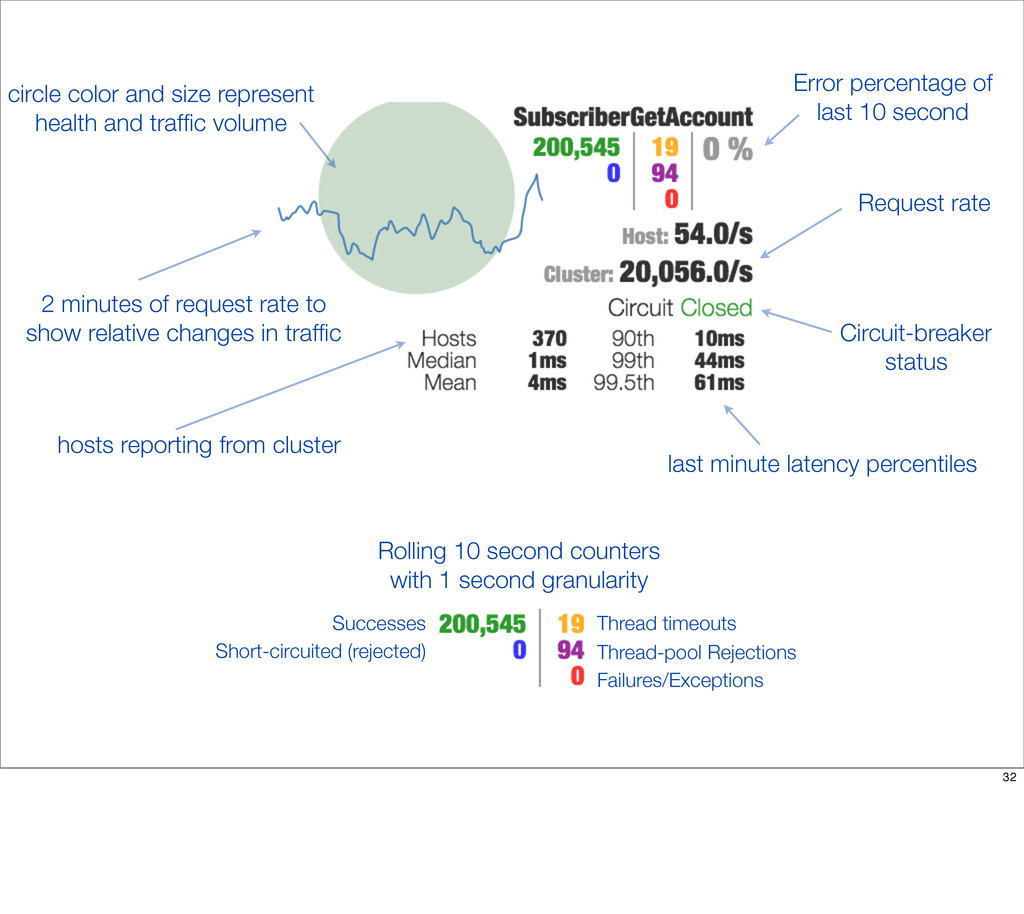{kind=link}
{kind=link}
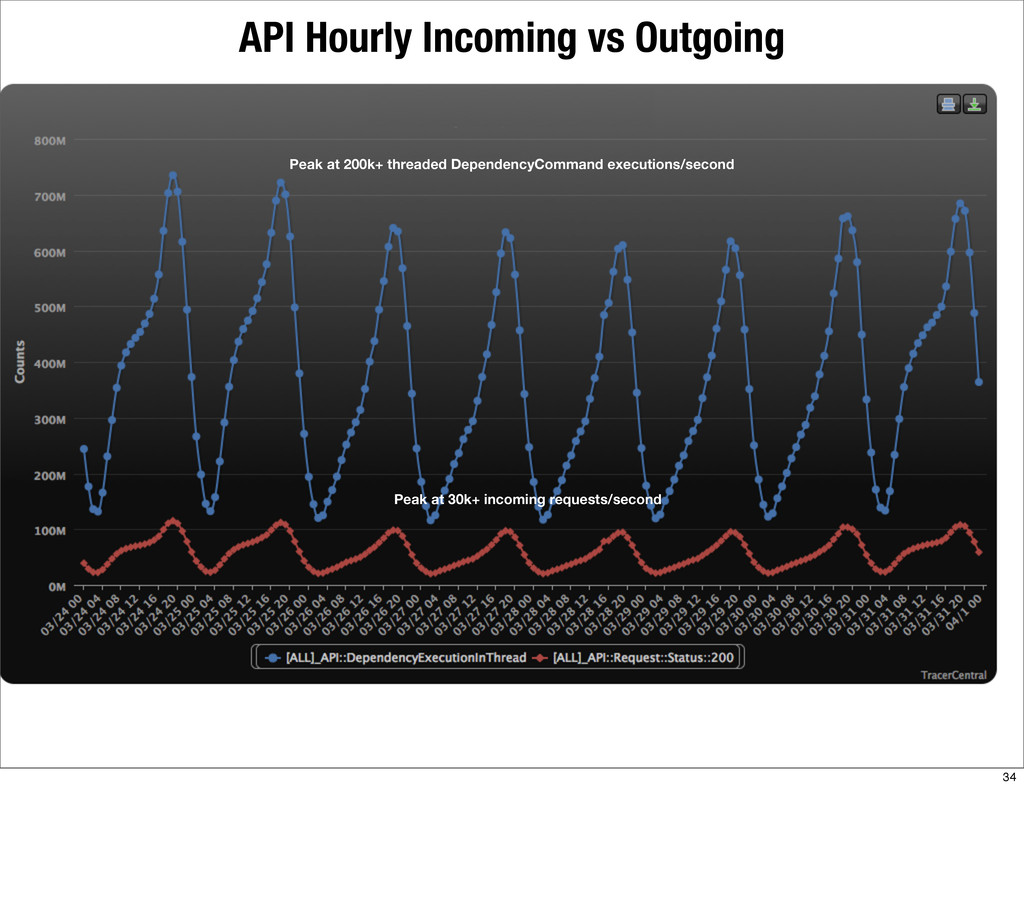{kind=link}
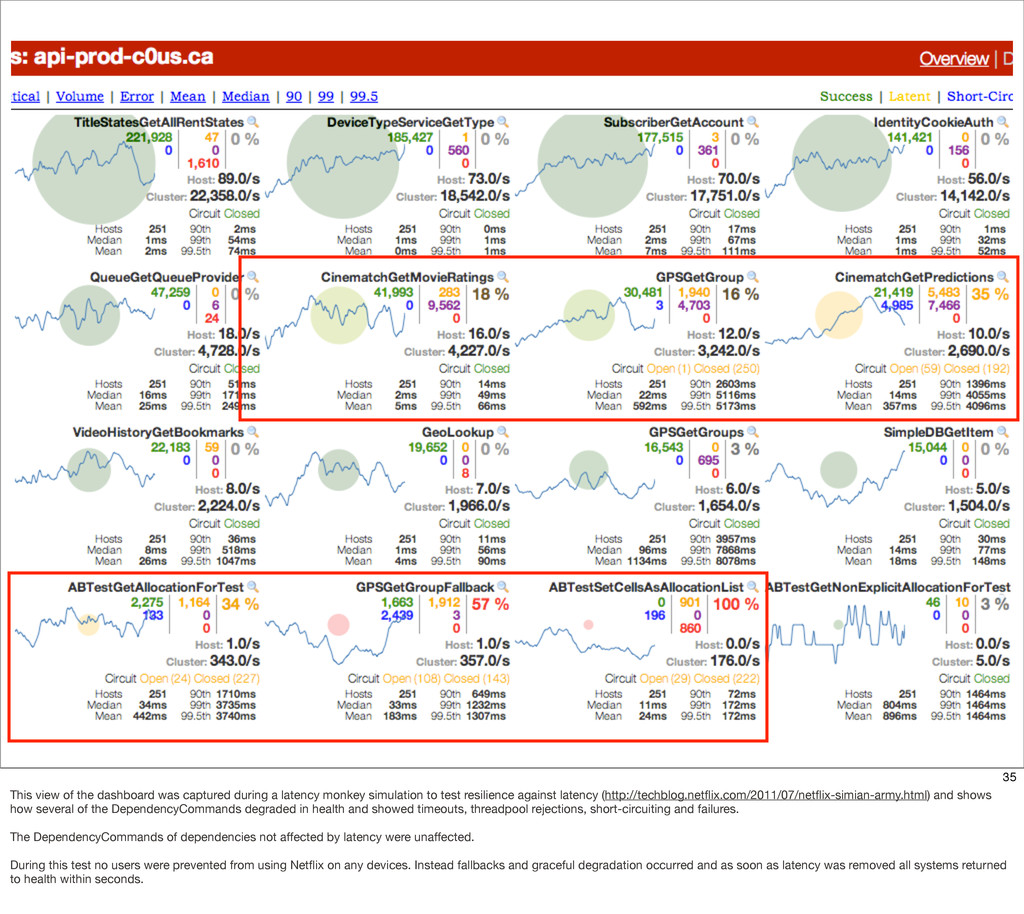{kind=link}
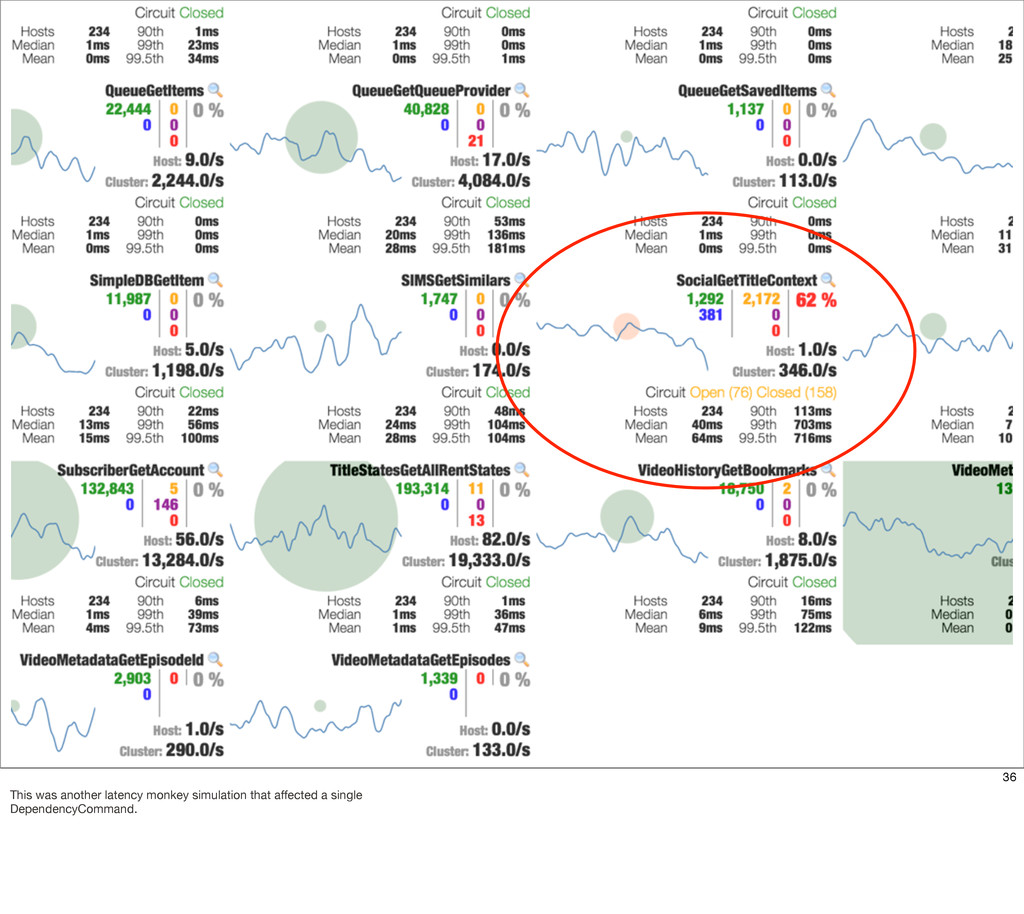{kind=link}
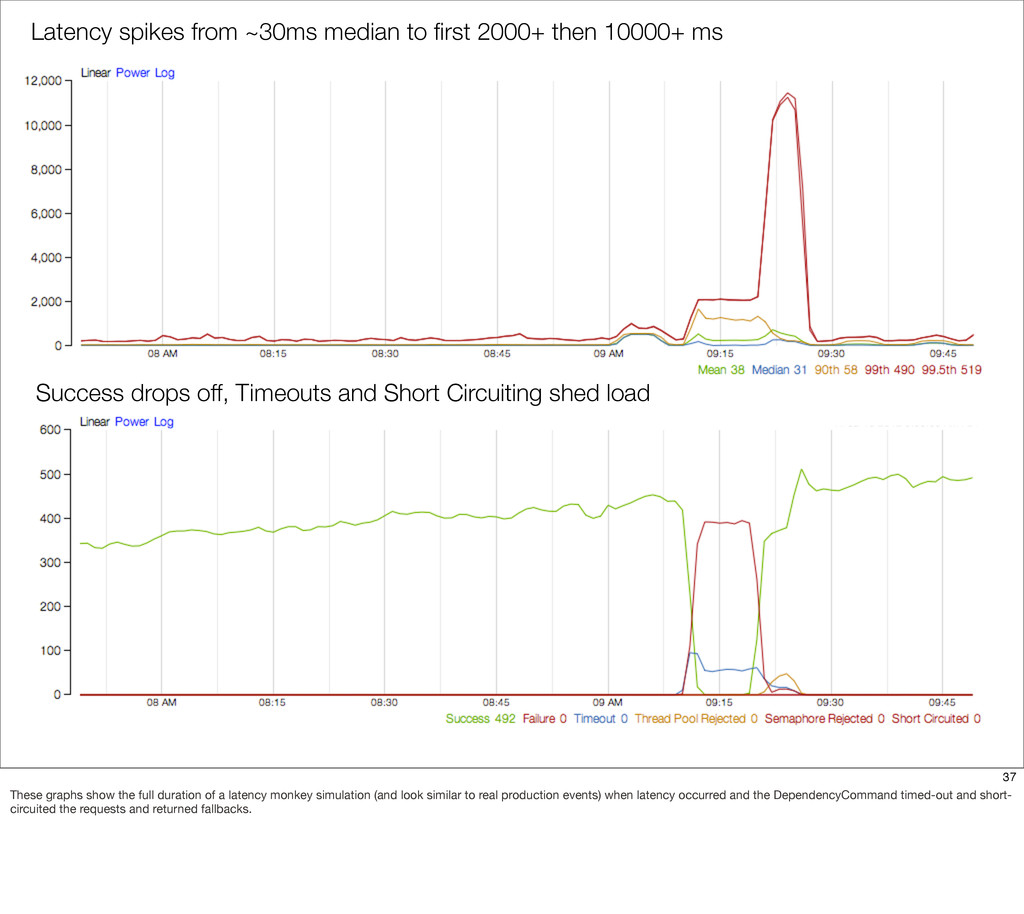{kind=link}
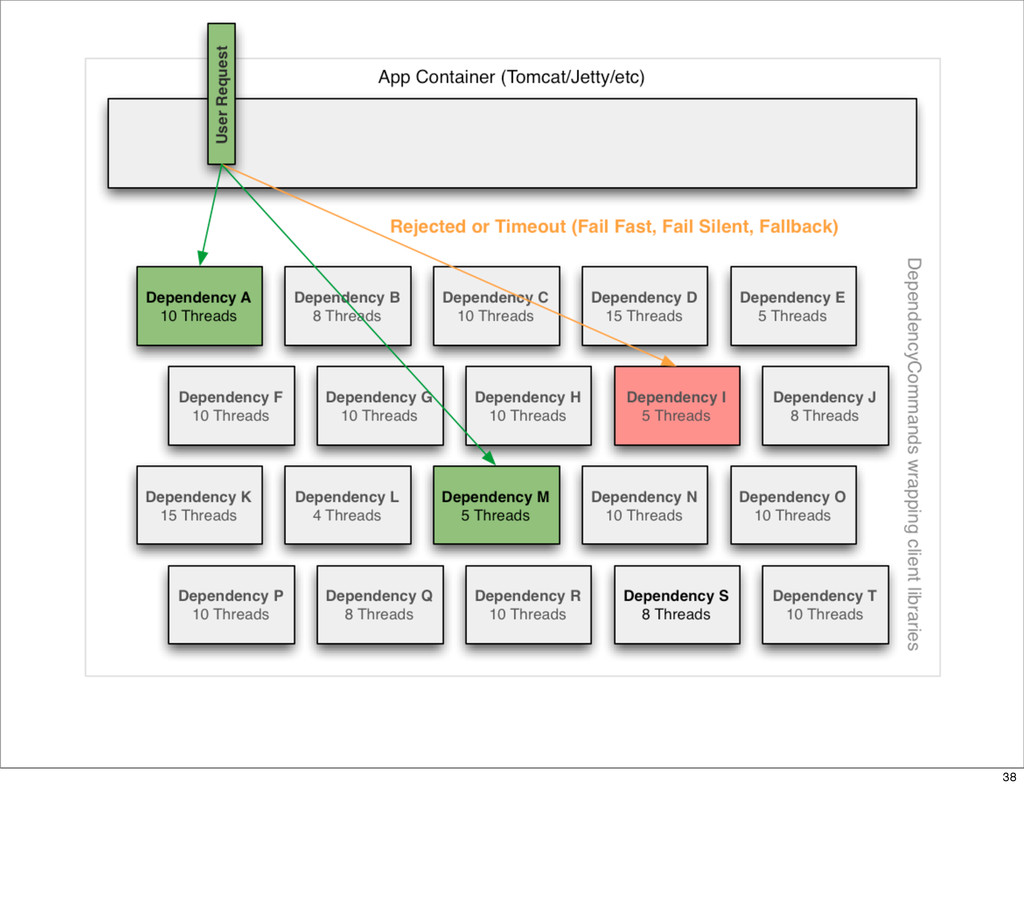{kind=link}
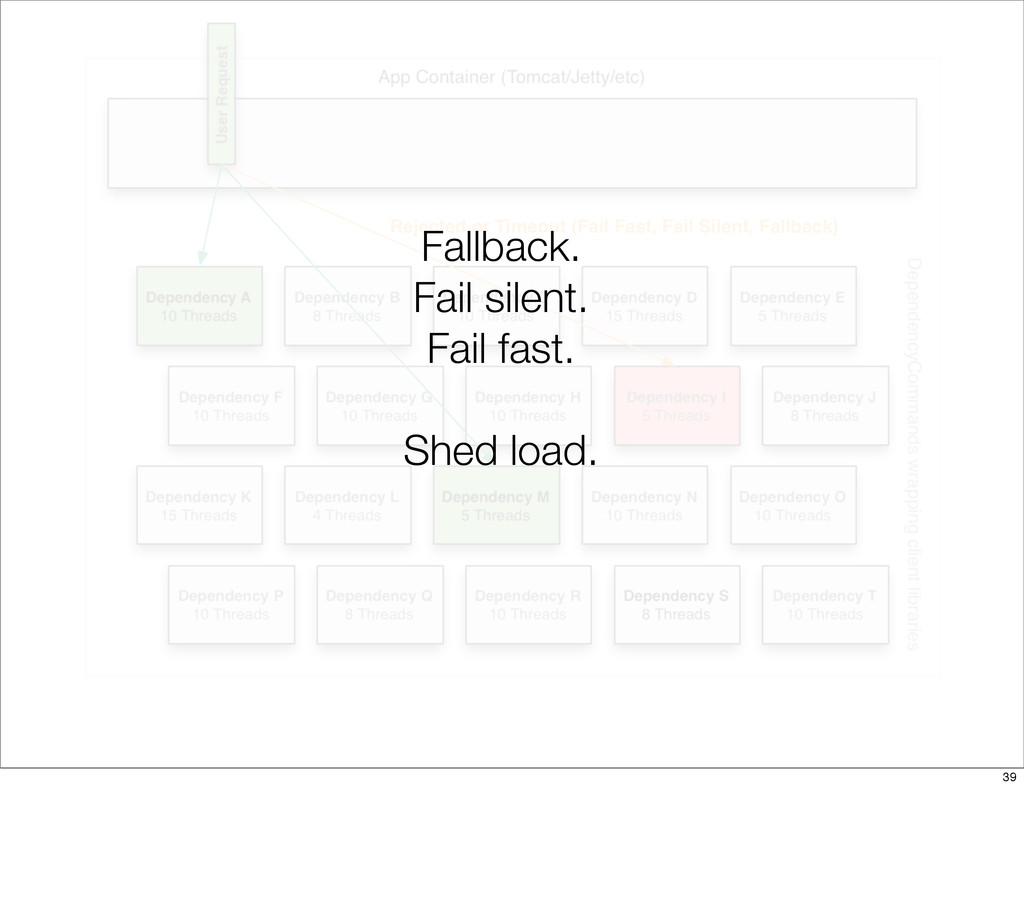{kind=link}
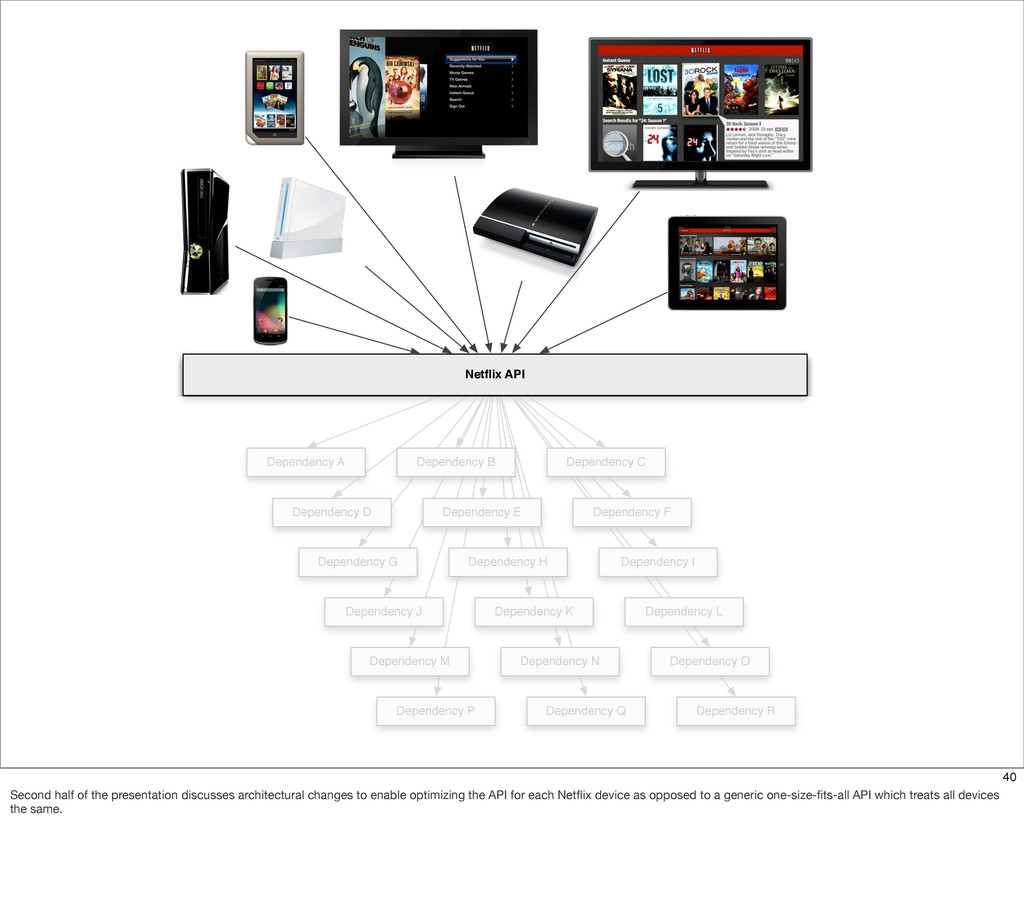{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
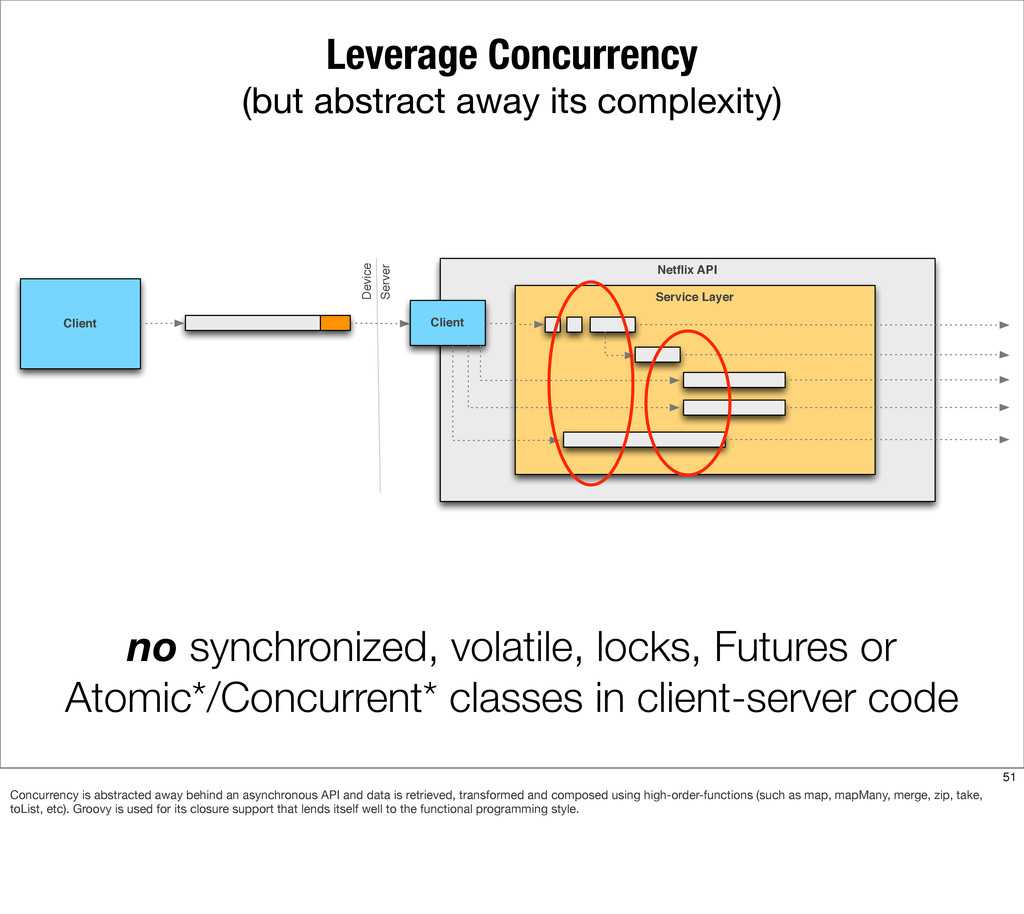{kind=link}
{kind=link}
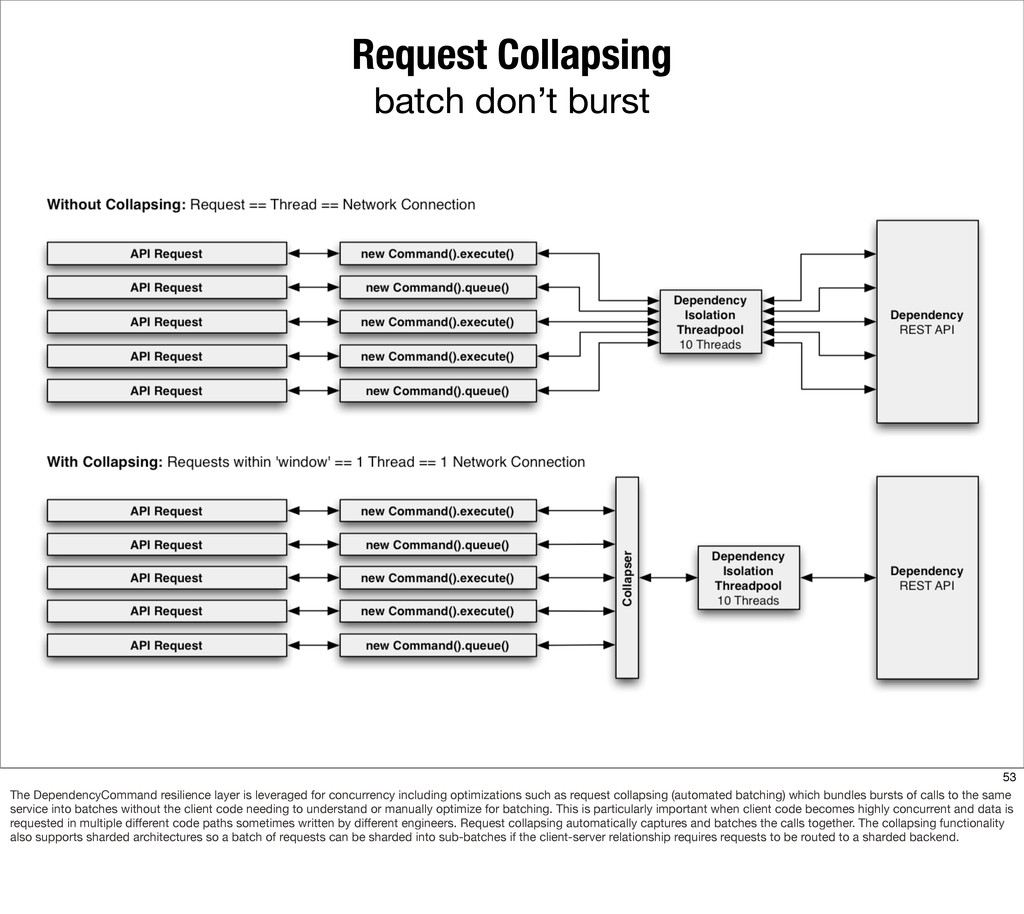{kind=link}
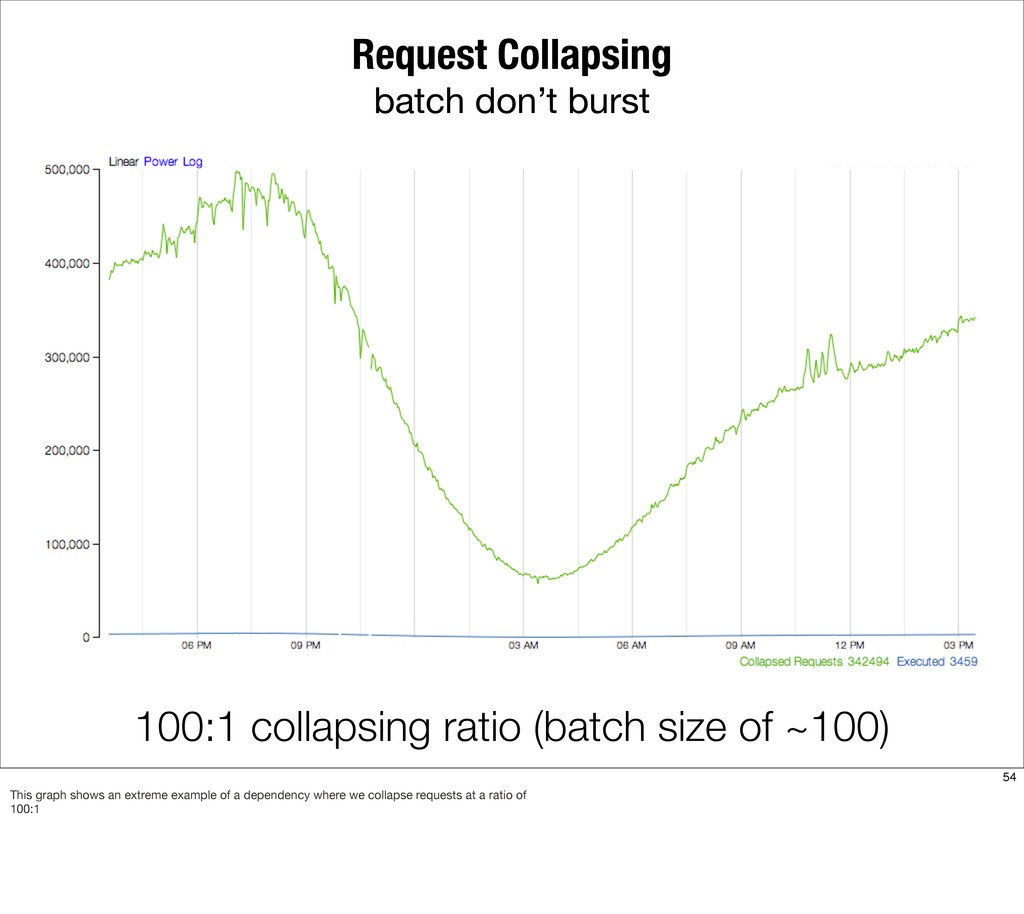{kind=link}
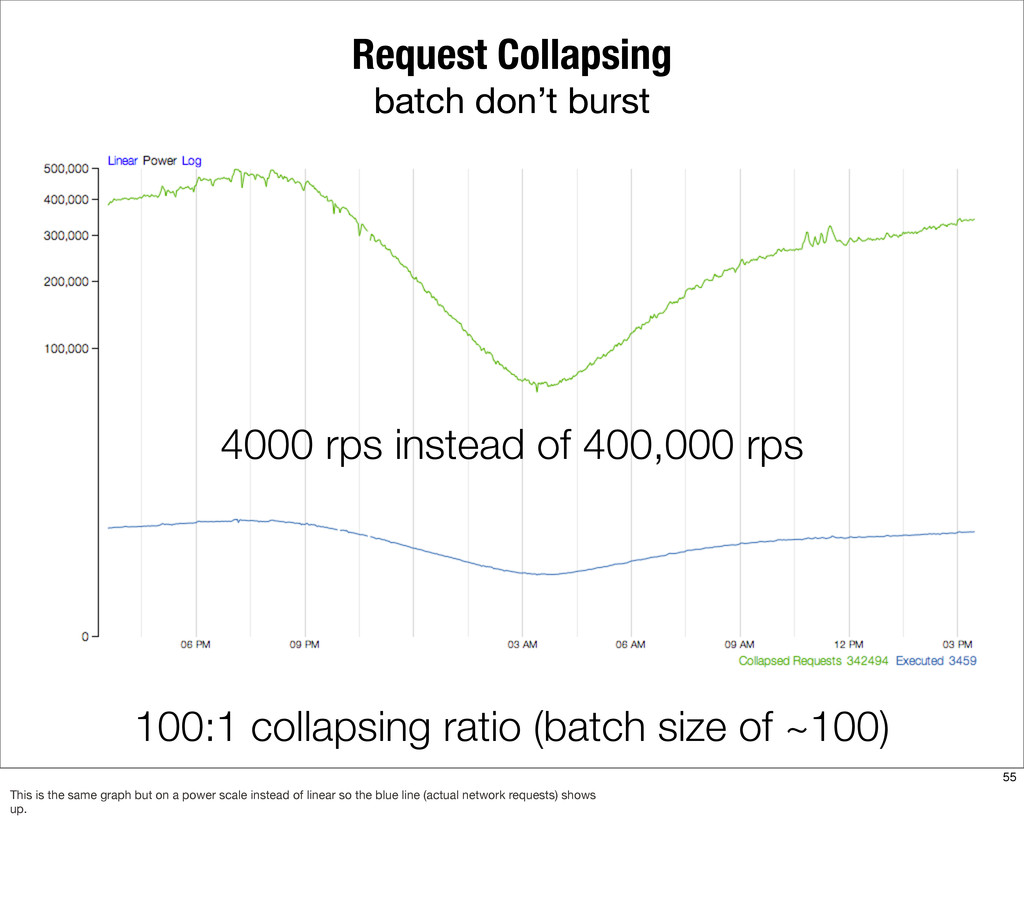{kind=link}
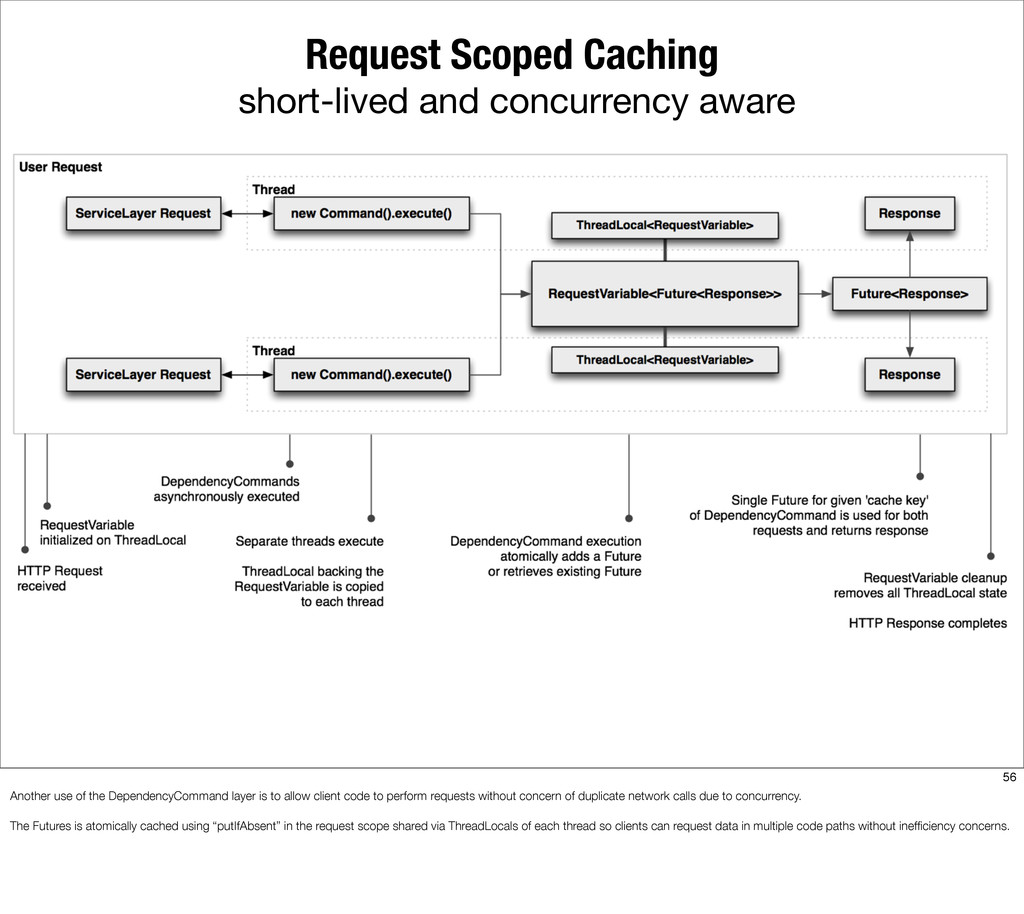{kind=link}
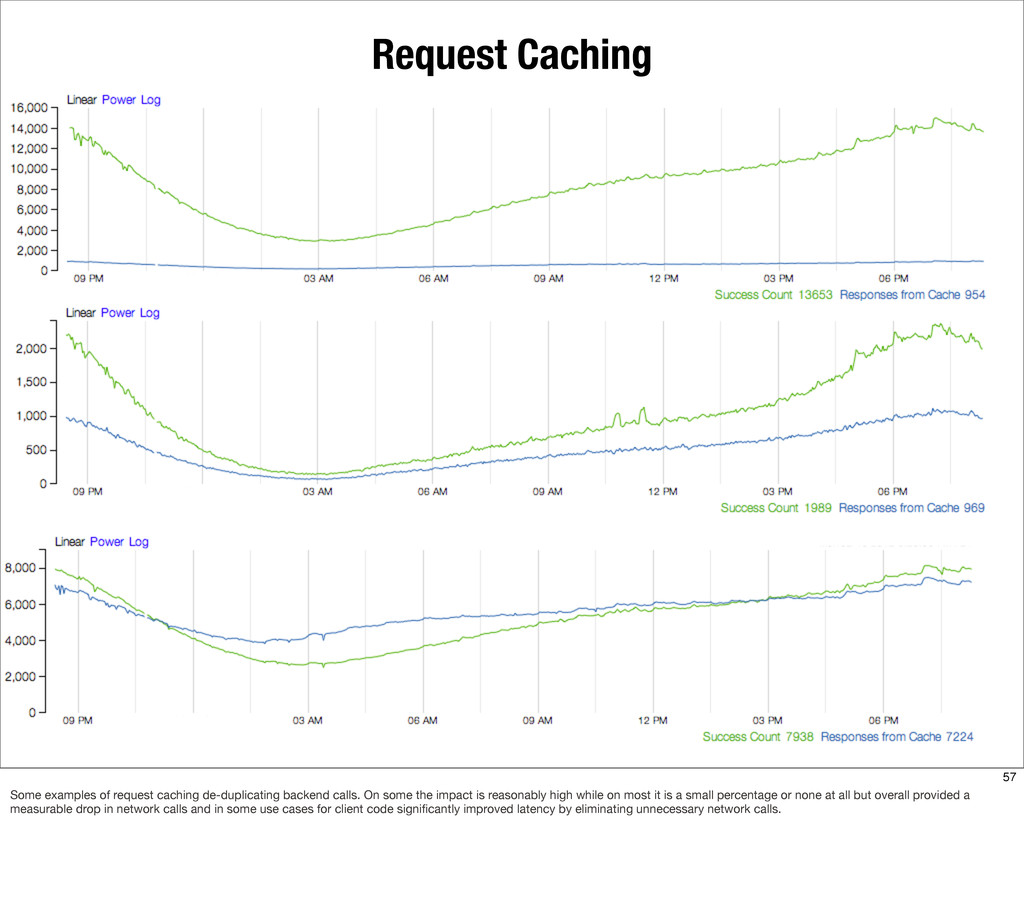{kind=link}
{kind=link}
{kind=link}