Поточные архитектуры продолжают набирать популярность, но докладов, которые идут дальше тривиальных примеров, по-прежнему немного.
Пора открывать капот и смотреть, как оно устроено.
Тем, кто решит впервые попробовать создать рабочее приложение при помощи Kafka Streams API, предстоит освоить немало новых вещей и соответствующим образом настроить мышление.
- С чего начать?
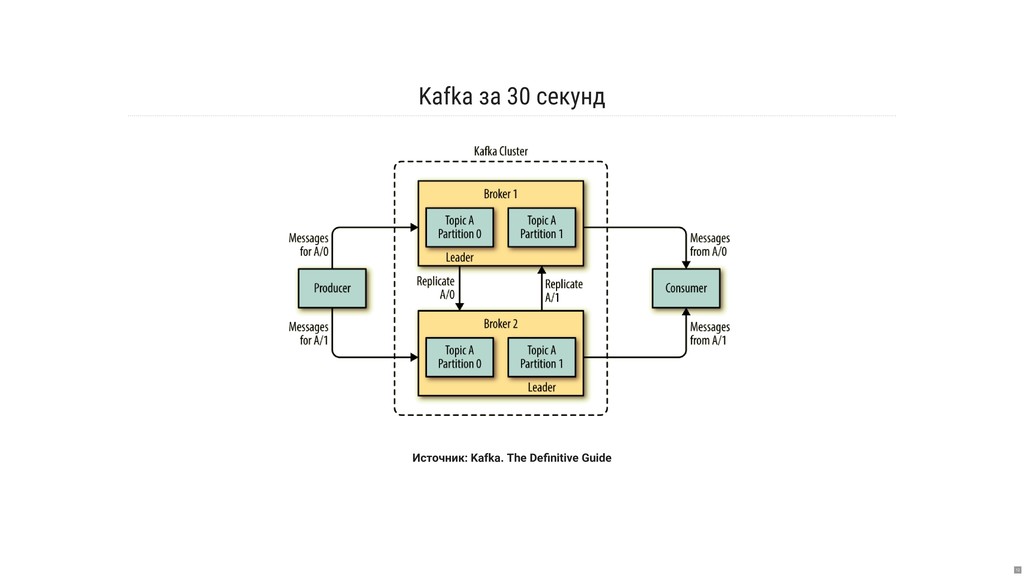
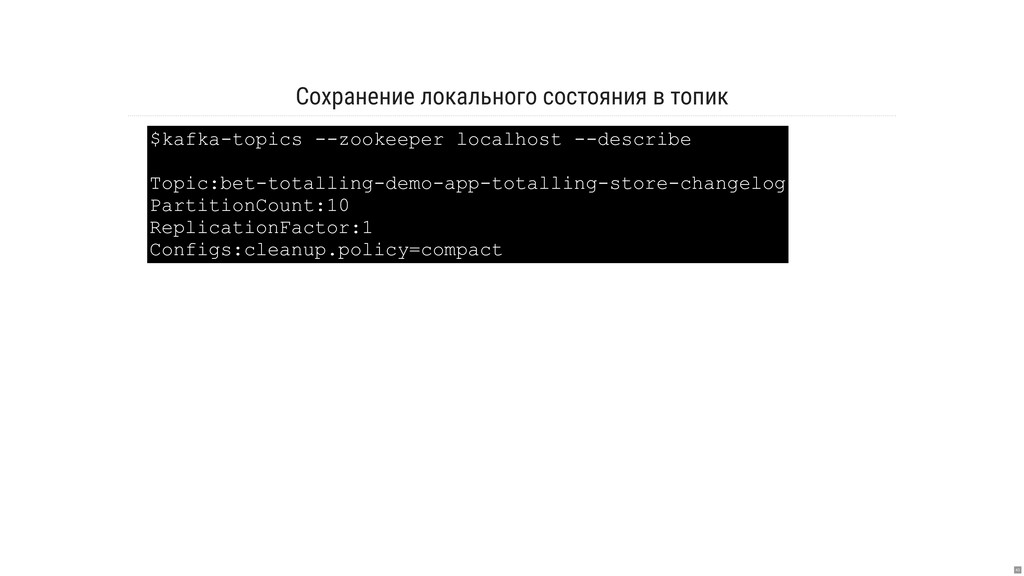
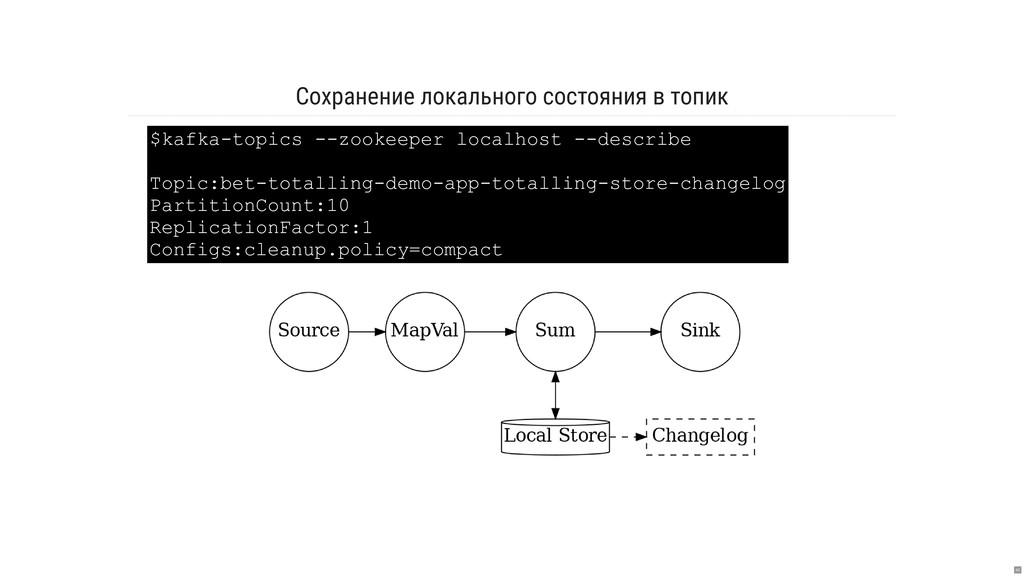
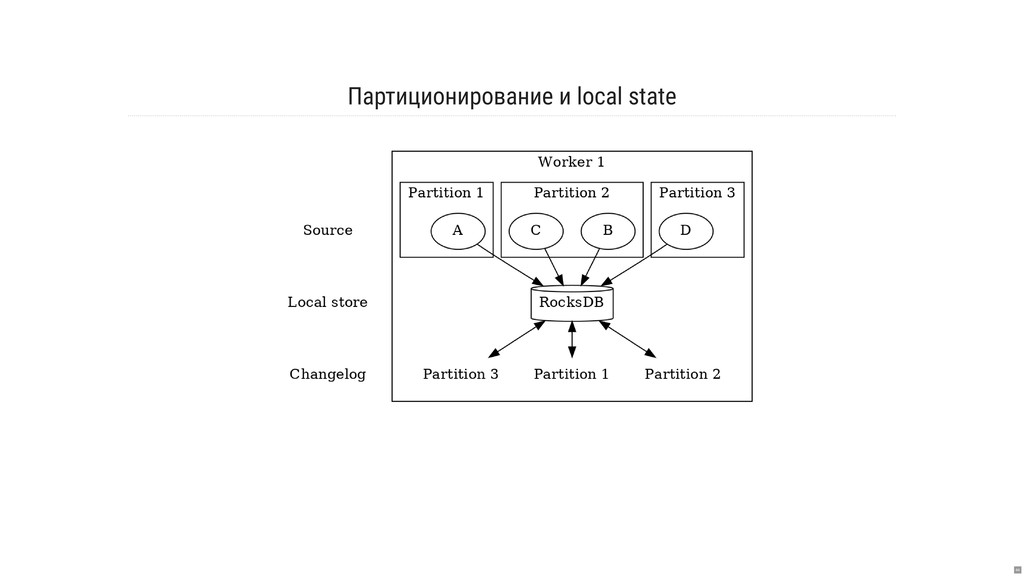
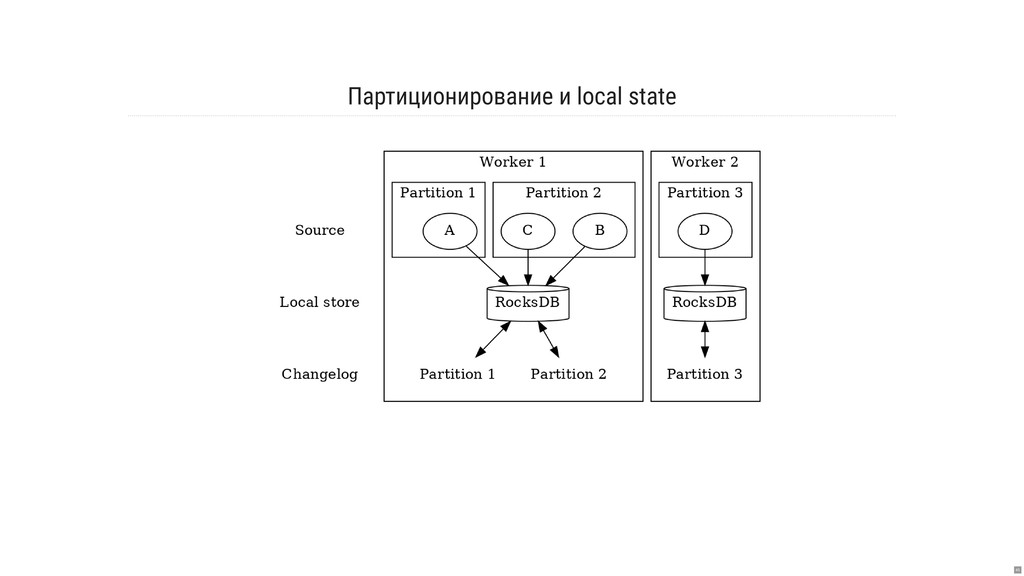
- Как работает хранение и репликация локального состояния?
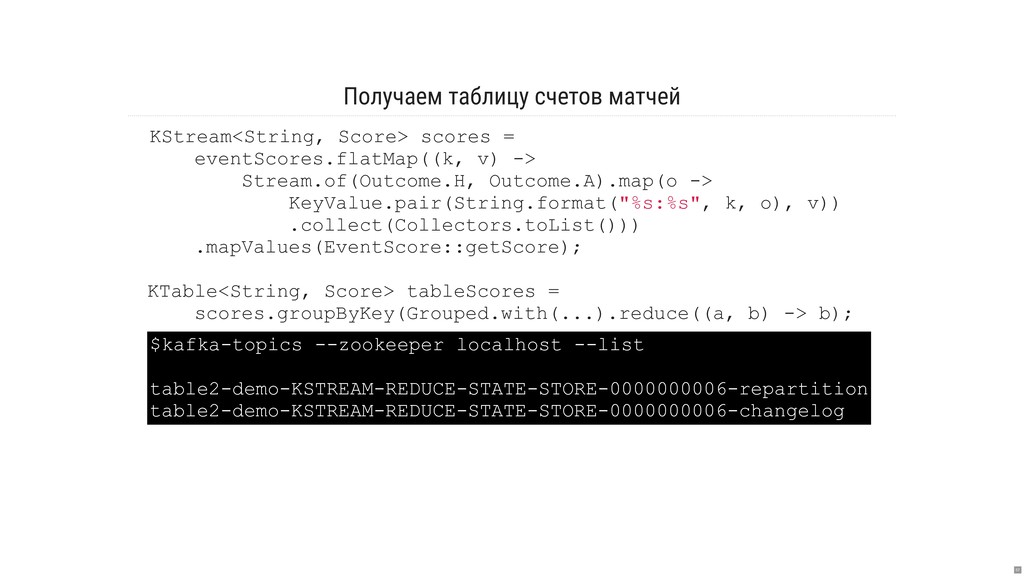
- Что такое RocksDB и как её возможности используются в Kafka Streams «под капотом»?
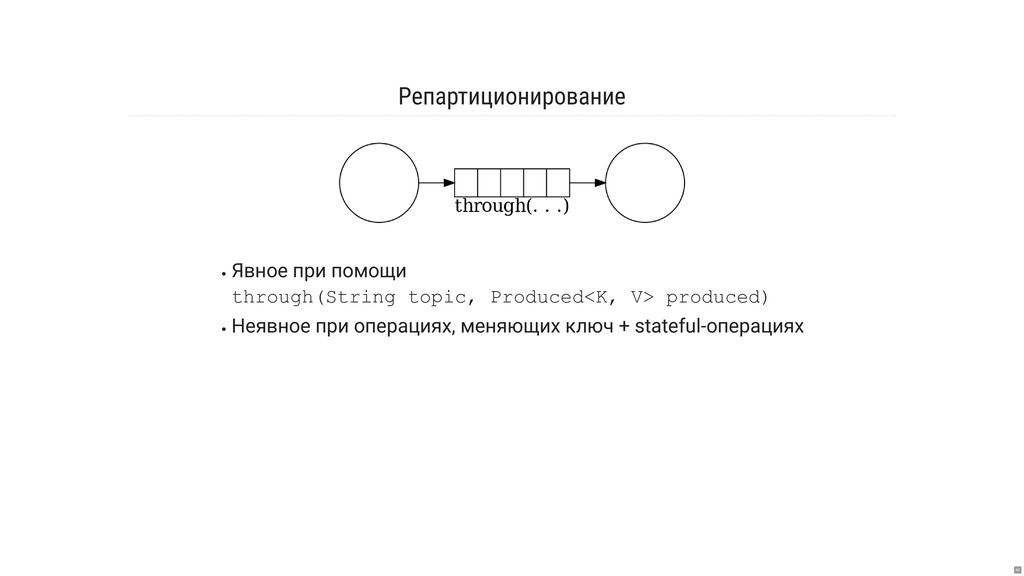
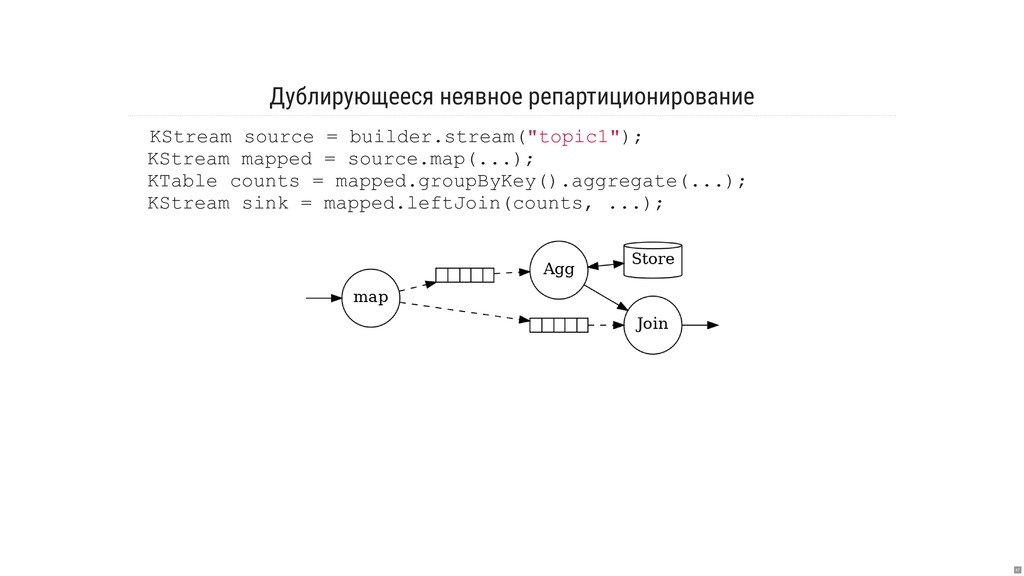
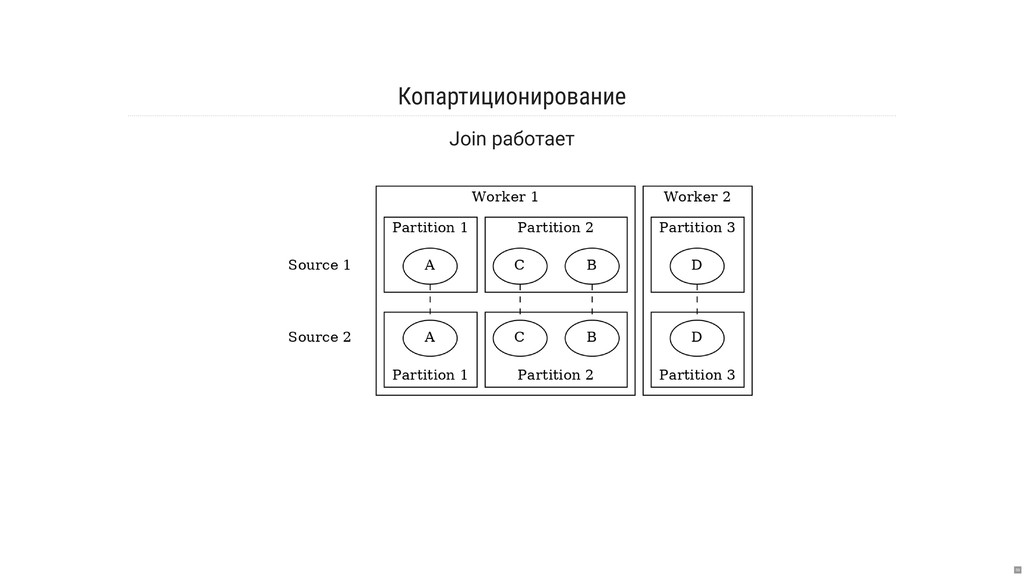
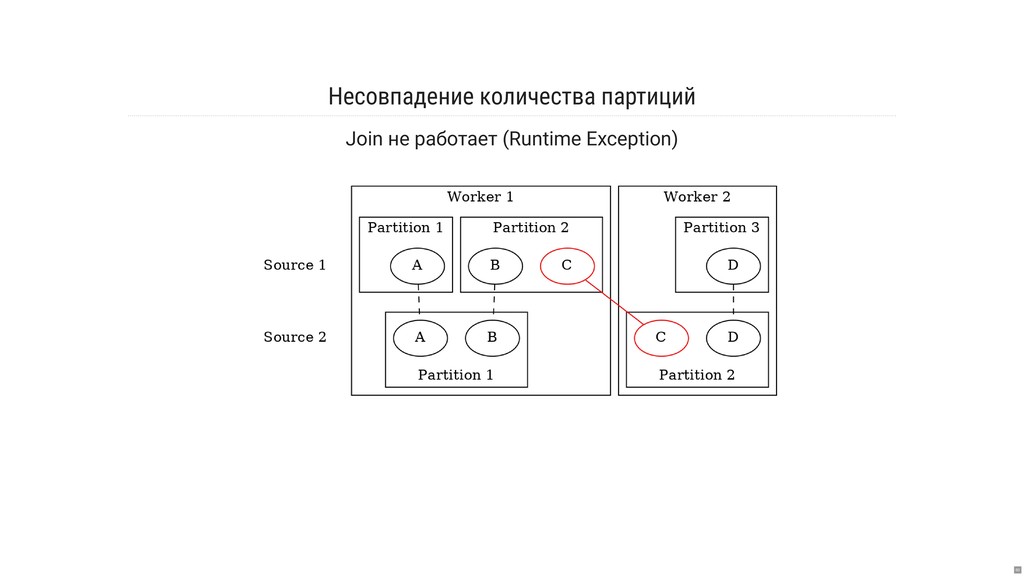
- Что за страшные слова: «репартиционирование» и «копартиционирование»?
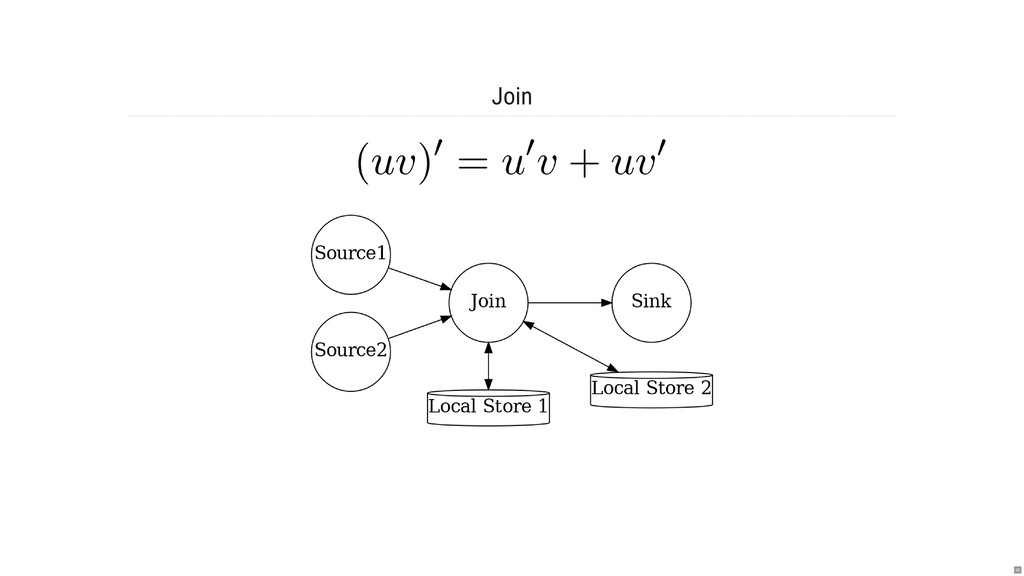
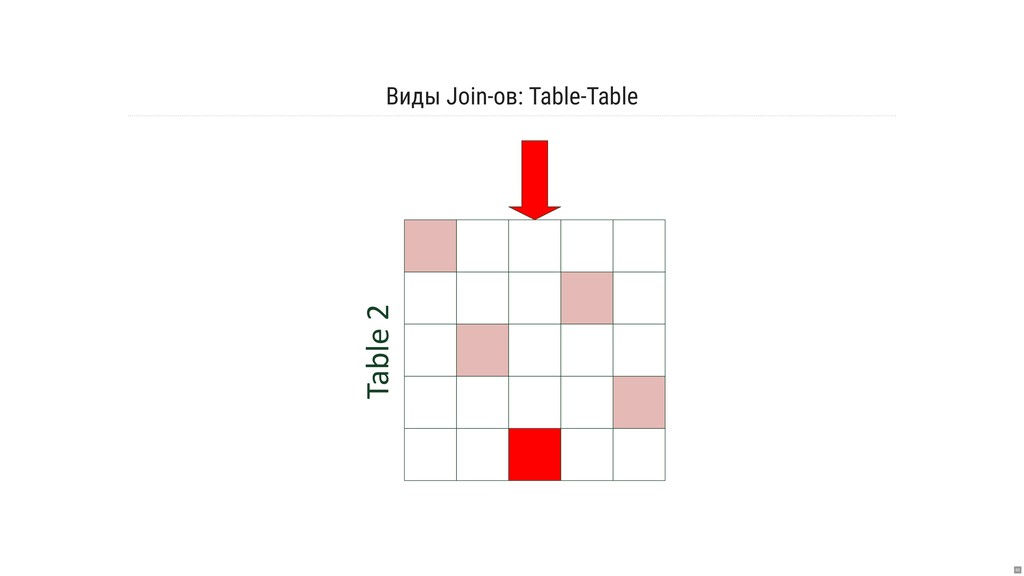
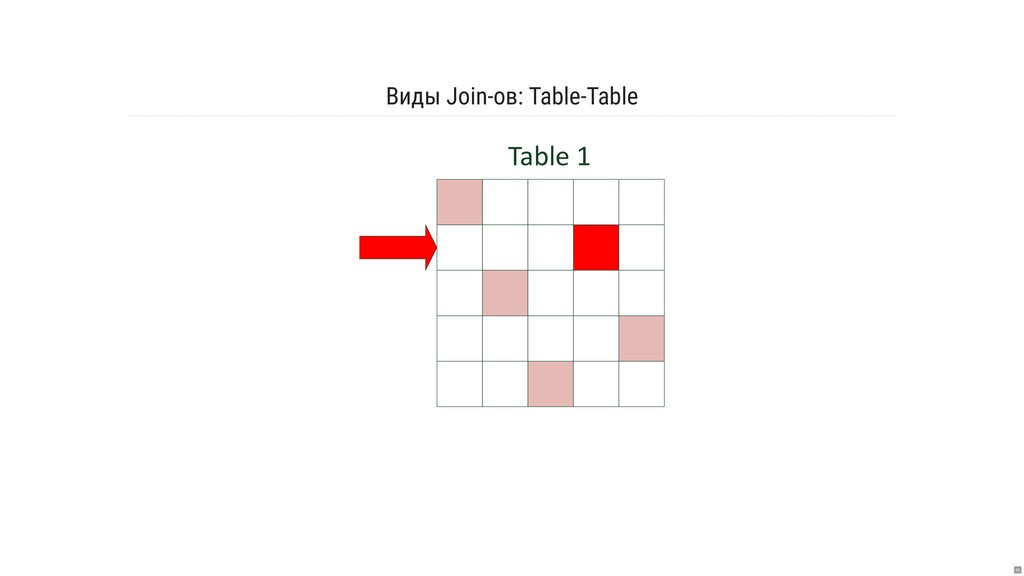
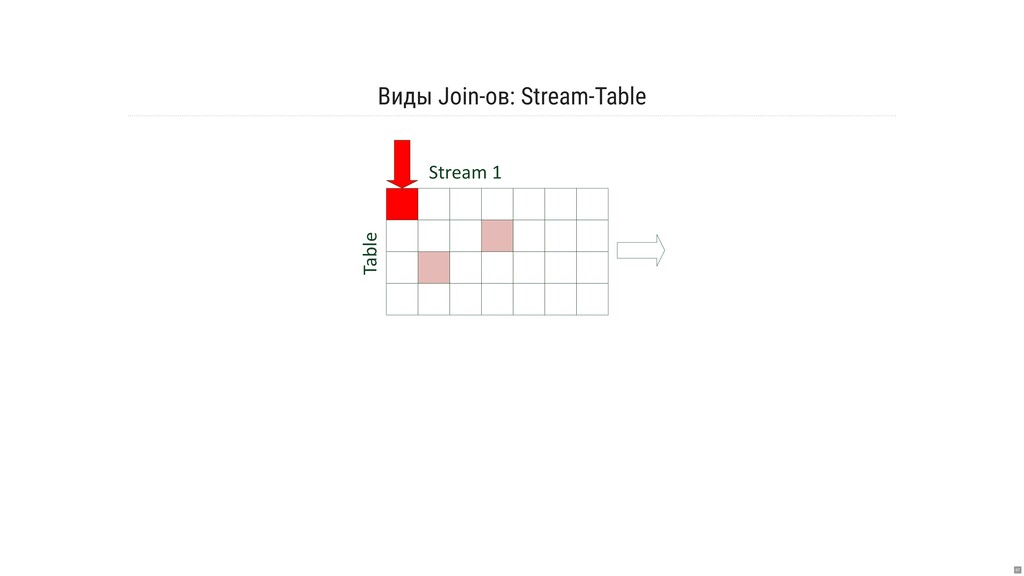
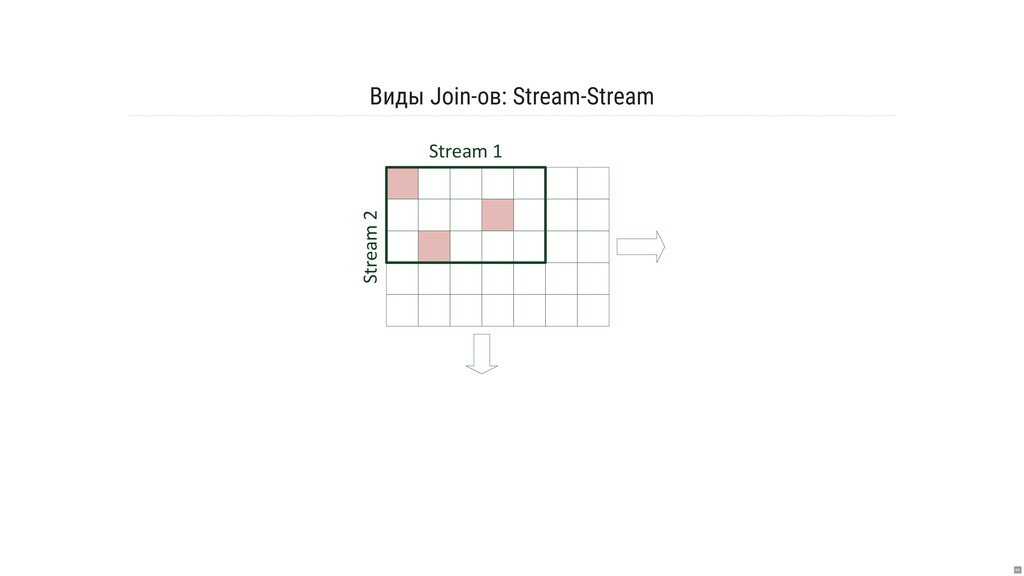
- Какова семантика джойнов и оконных операций?
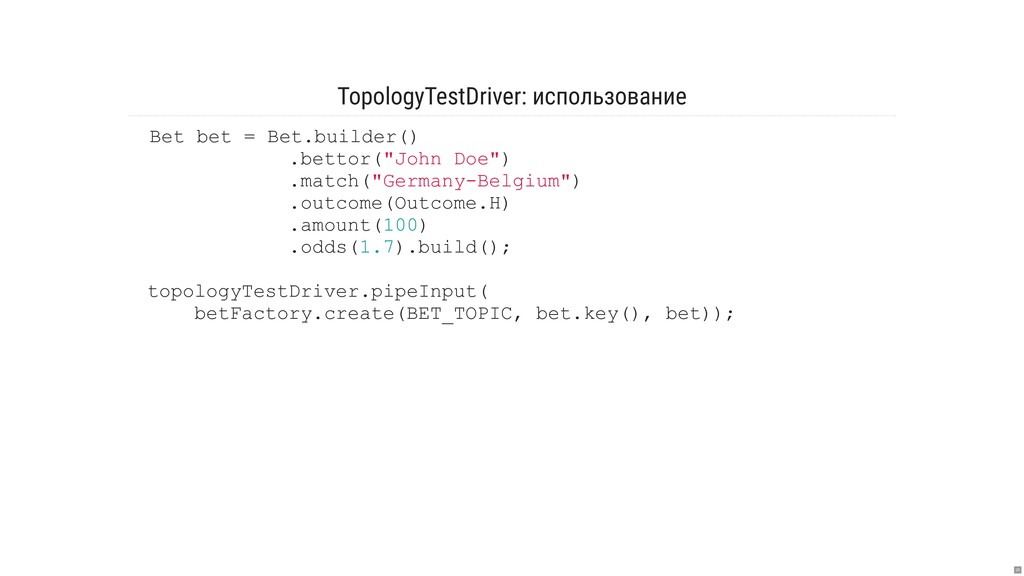
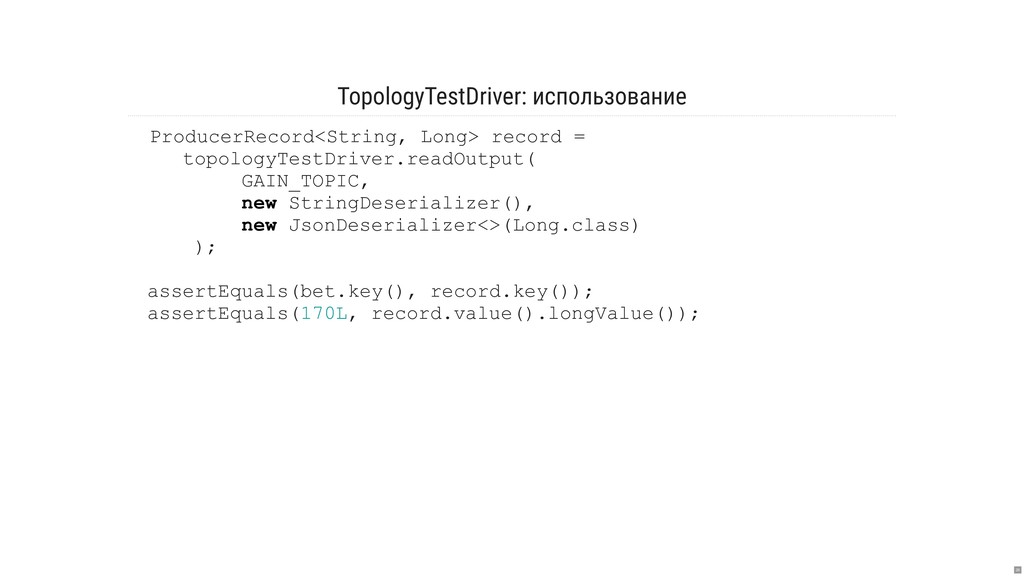
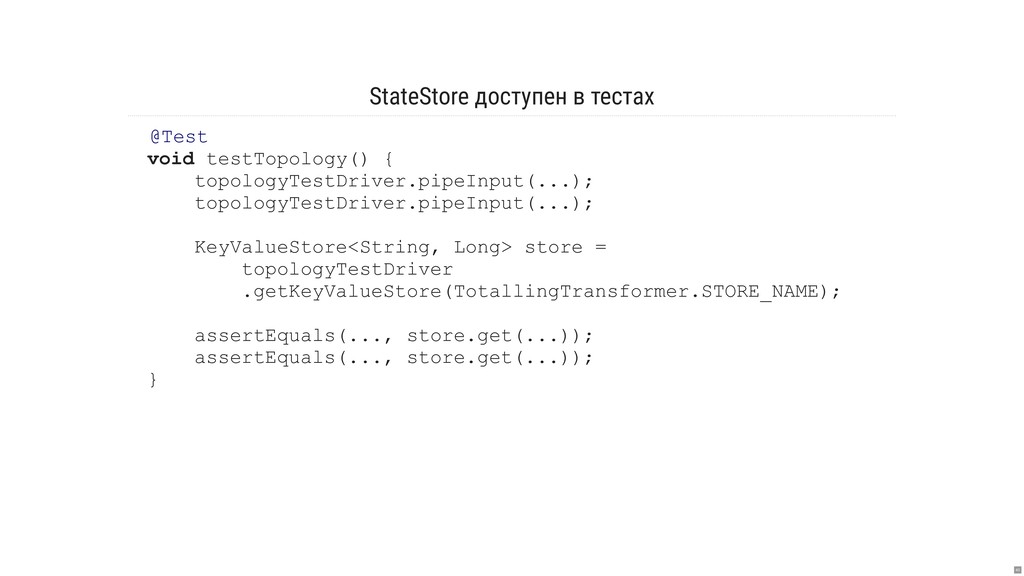
- Как писать тесты?
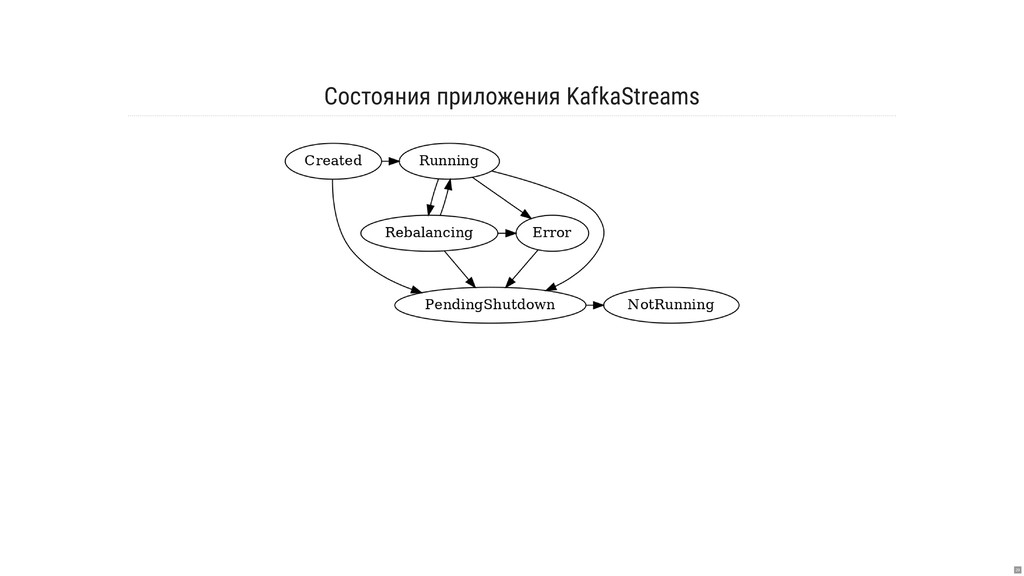
- Как отлаживать систему «на ходу»?
- Что делать с исключениями?
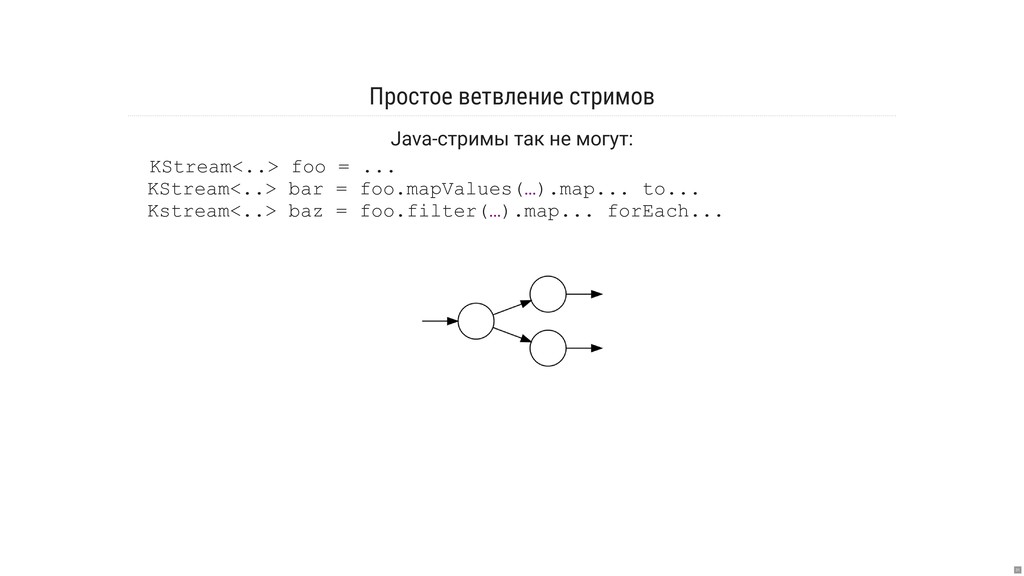
На эти вопросы мы попытаемся ответить, по пути рассмотрев несколько демо-примеров кода с использованием Spring, двигаясь от простого к сложному.
Доклад представляет собой расширенную версию доклада на конференции JPoint 2019.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Сохранение Timestamped-значений в RocksDB WindowKeySchema.java static Bytes toStoreKeyBinary(byte[] serializedKey, long](https://files.speakerdeck.com/presentations/00be9e2b604641ecbf91c6e2dc8f8049/slide_78.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![На этом всё! Спасибо! inponomarev/kstreams-examples @inponomarev [email protected] 88](https://files.speakerdeck.com/presentations/00be9e2b604641ecbf91c6e2dc8f8049/slide_99.jpg){kind=link}