the ground up! Embrace both batch (training) & interactive apps (dev & inference) Job queues & scheduler (Sokovan) for batch jobs like ML training, data processing, ... App proxy for interactive apps like Jupyter notebooks, code-server, Triton Server, ... Unleash the potential of latest hardware advancements (NUMA, RDMA, GPUDirectStorage, ...) Full-fledged enterprise-grade administration (users, keypairs, projects, billing, stats, ...) • Pros Super-fast: native integration with hardware details (NUMA, GPUDirectStorage, etc.) Super-customizable: plugin architecture for schedulers, accelerators, storage, etc. • Cons Extra efforts to integrate with the existing ecosystem (...but we have Docker!) Our Approach (v2) 7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
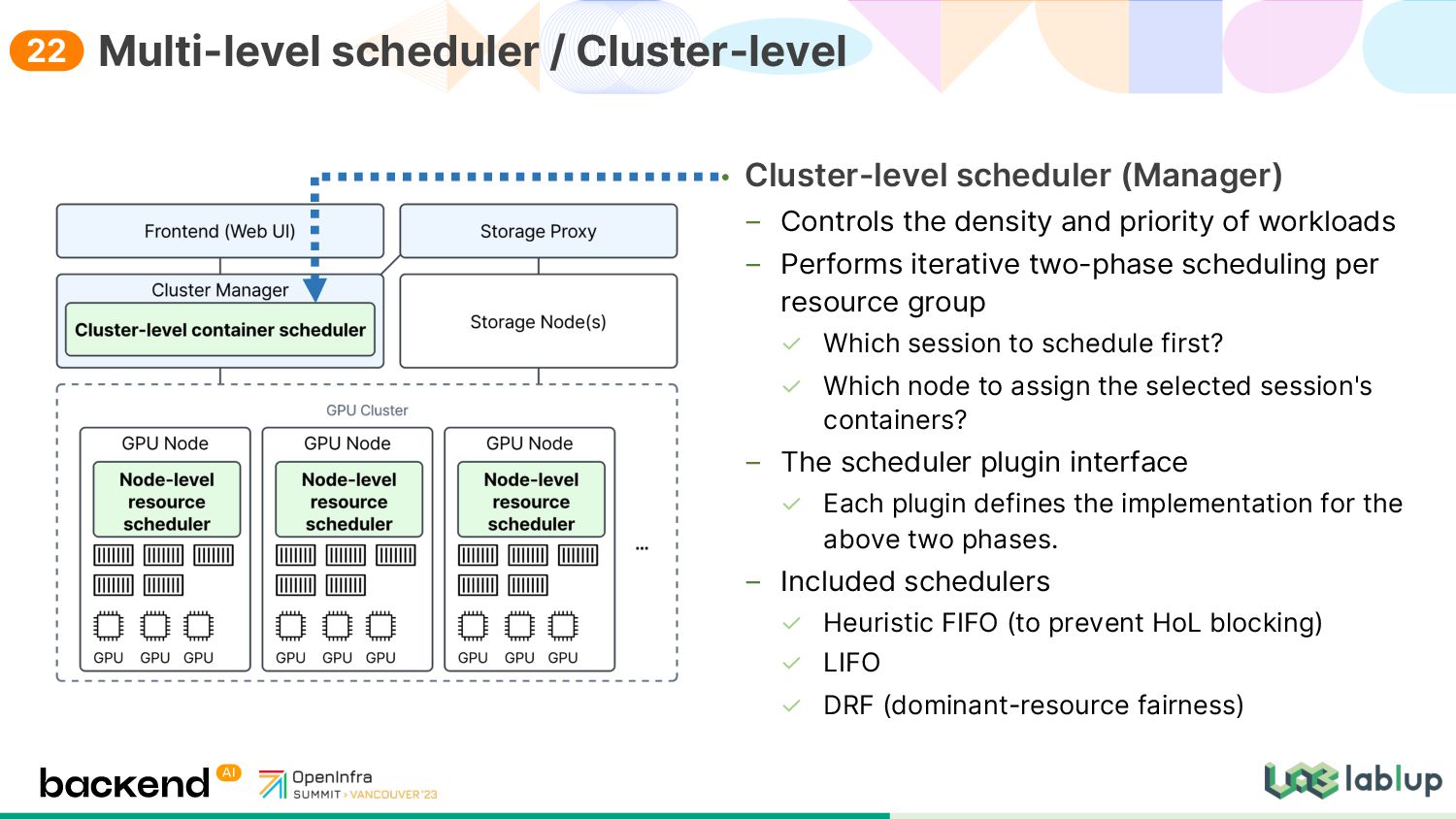{kind=link}
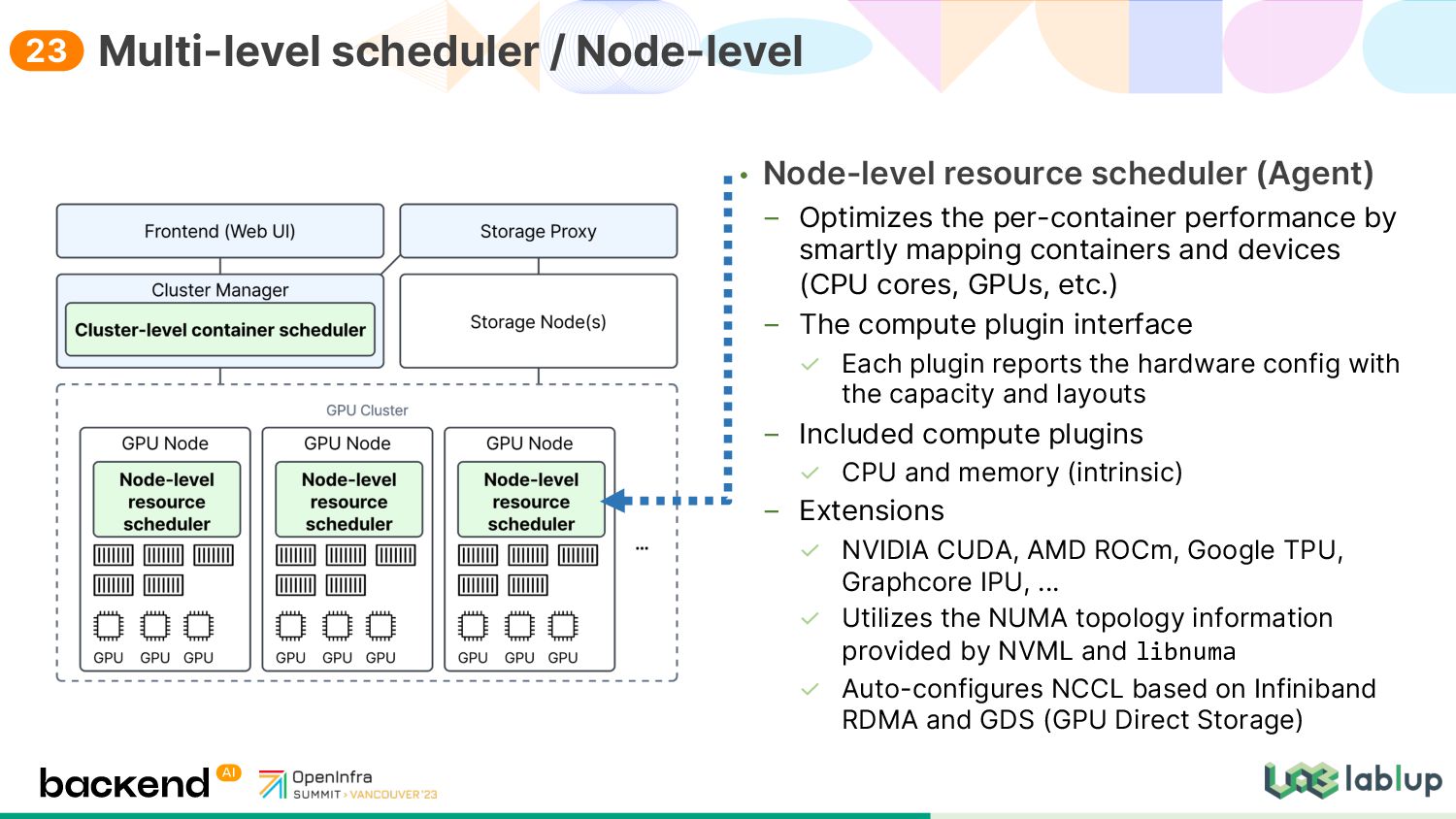{kind=link}
{kind=link}
{kind=link}
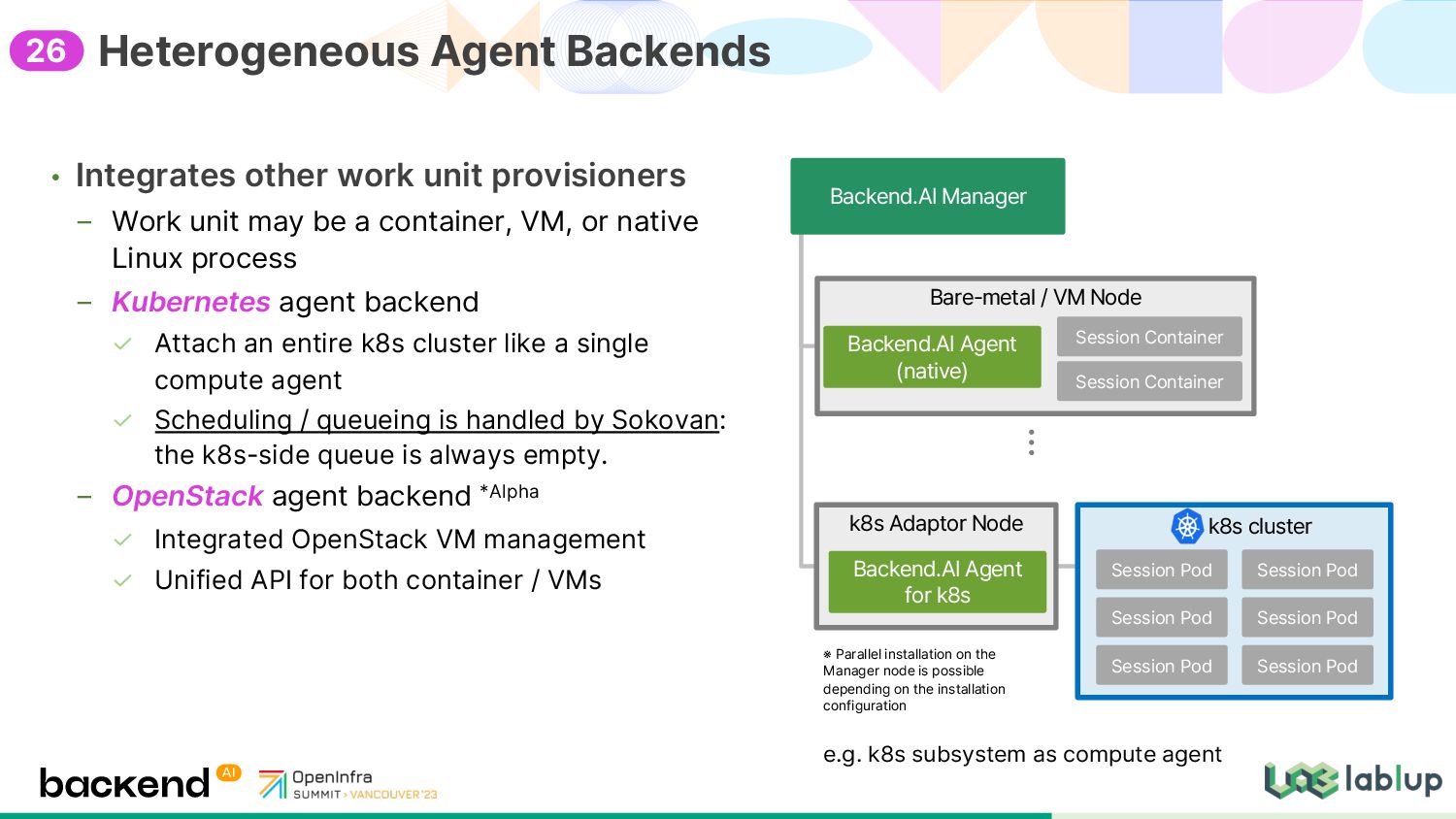{kind=link}
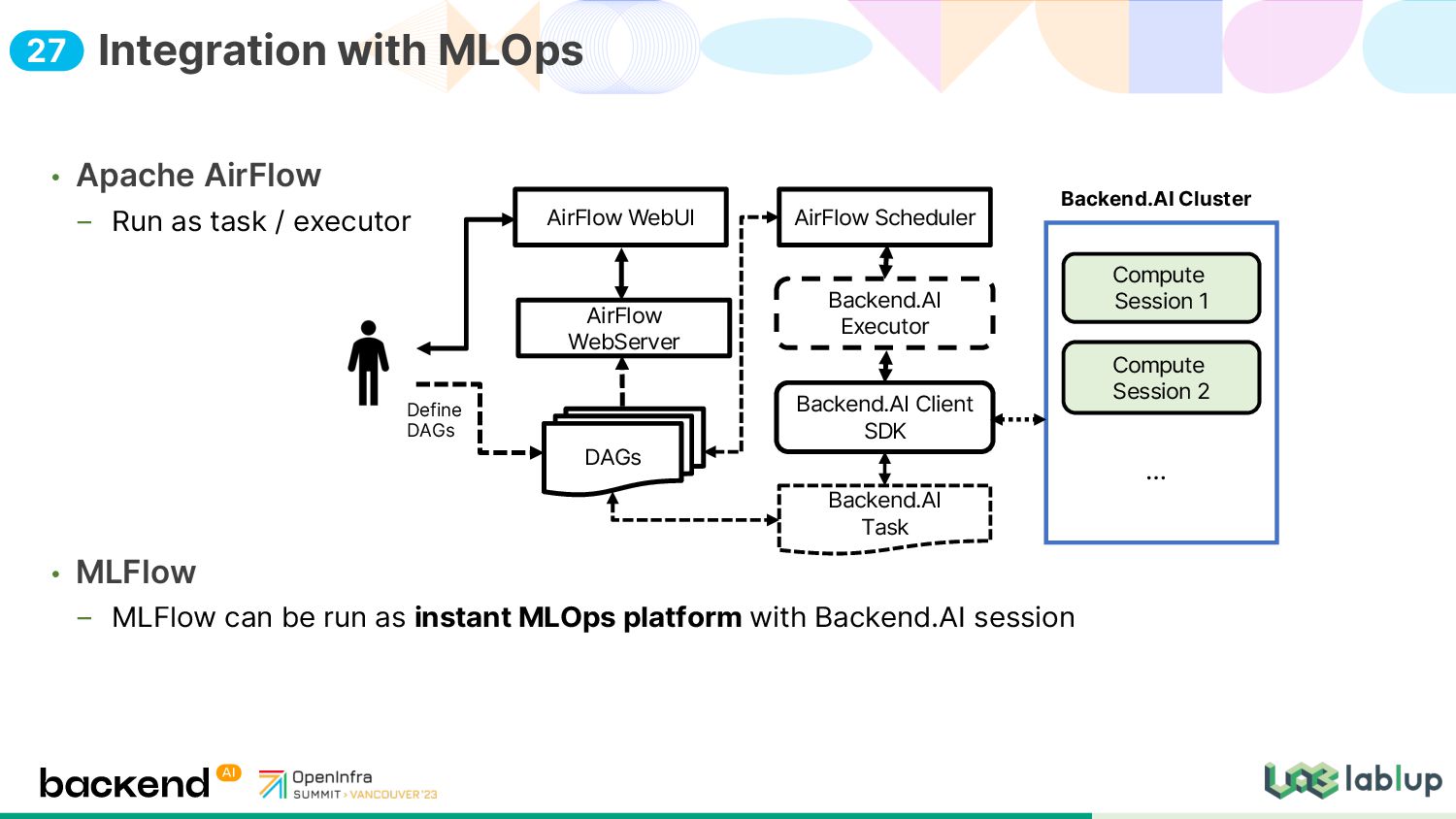{kind=link}
{kind=link}
{kind=link}
{kind=link}
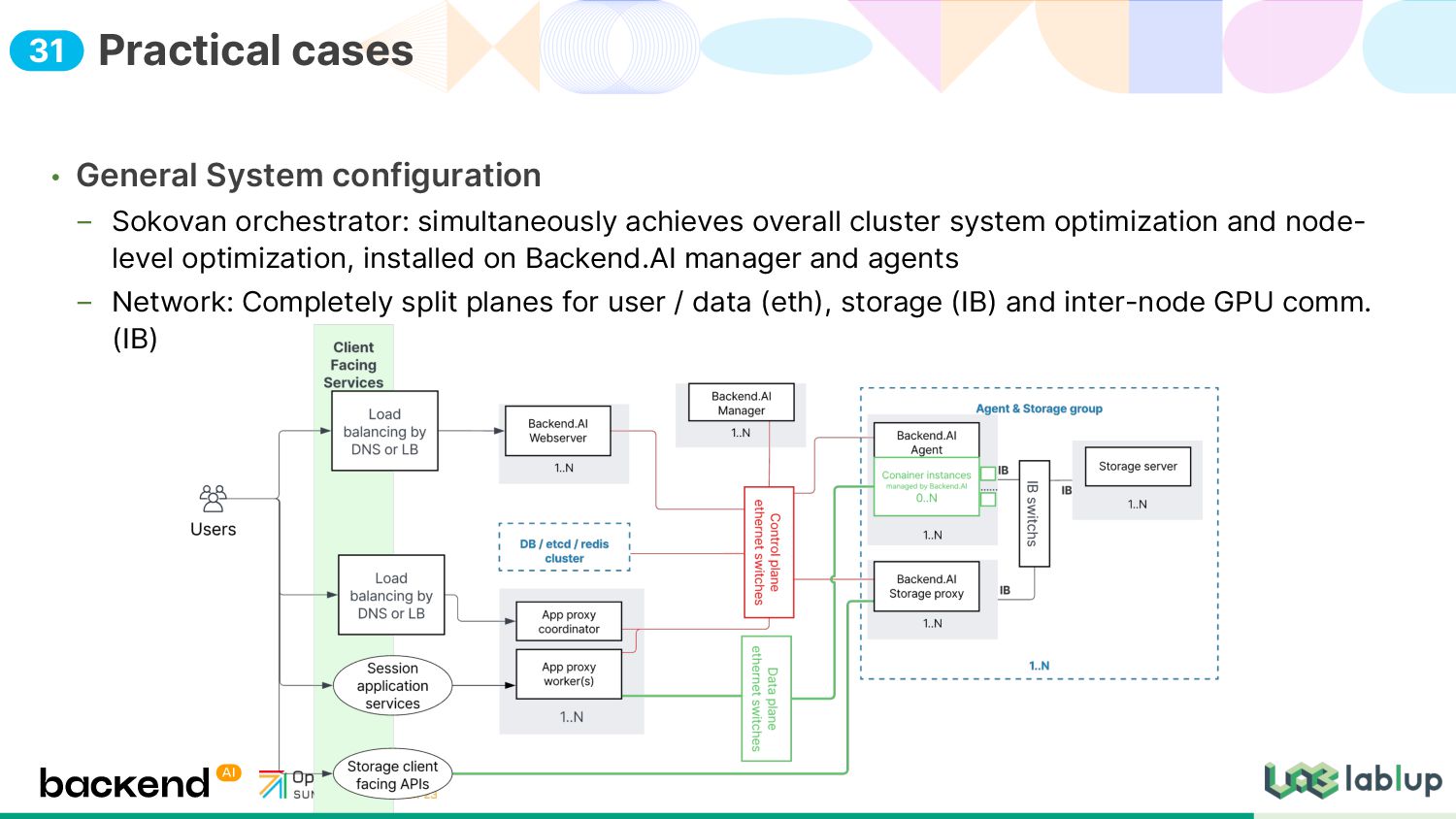{kind=link}
{kind=link}
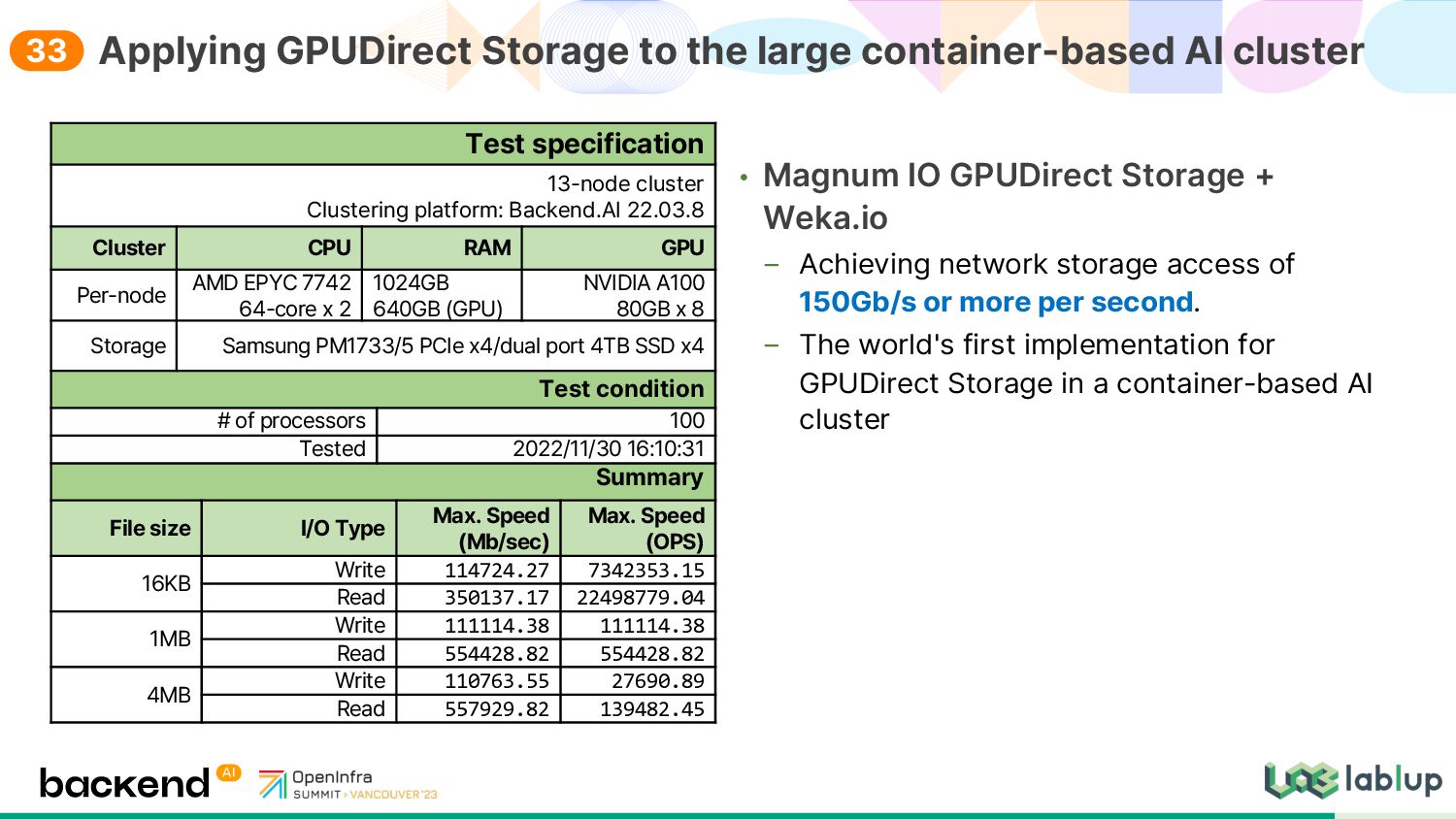{kind=link}
{kind=link}
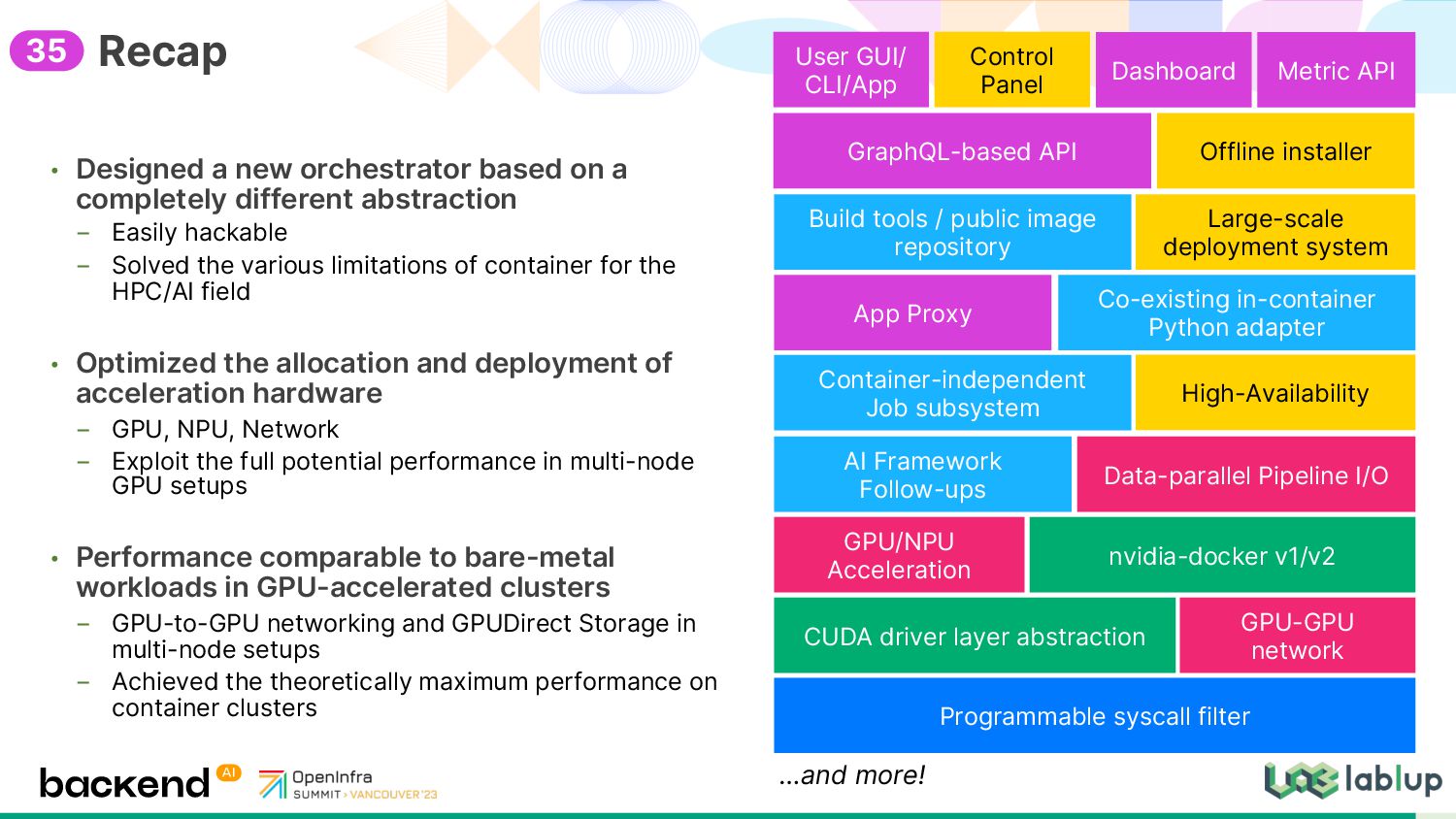{kind=link}
![Thank You! [email protected] [email protected] lablup/backend.ai Question? 36](https://files.speakerdeck.com/presentations/5e614dcdc6e6494e953d686f9e2e7a3b/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
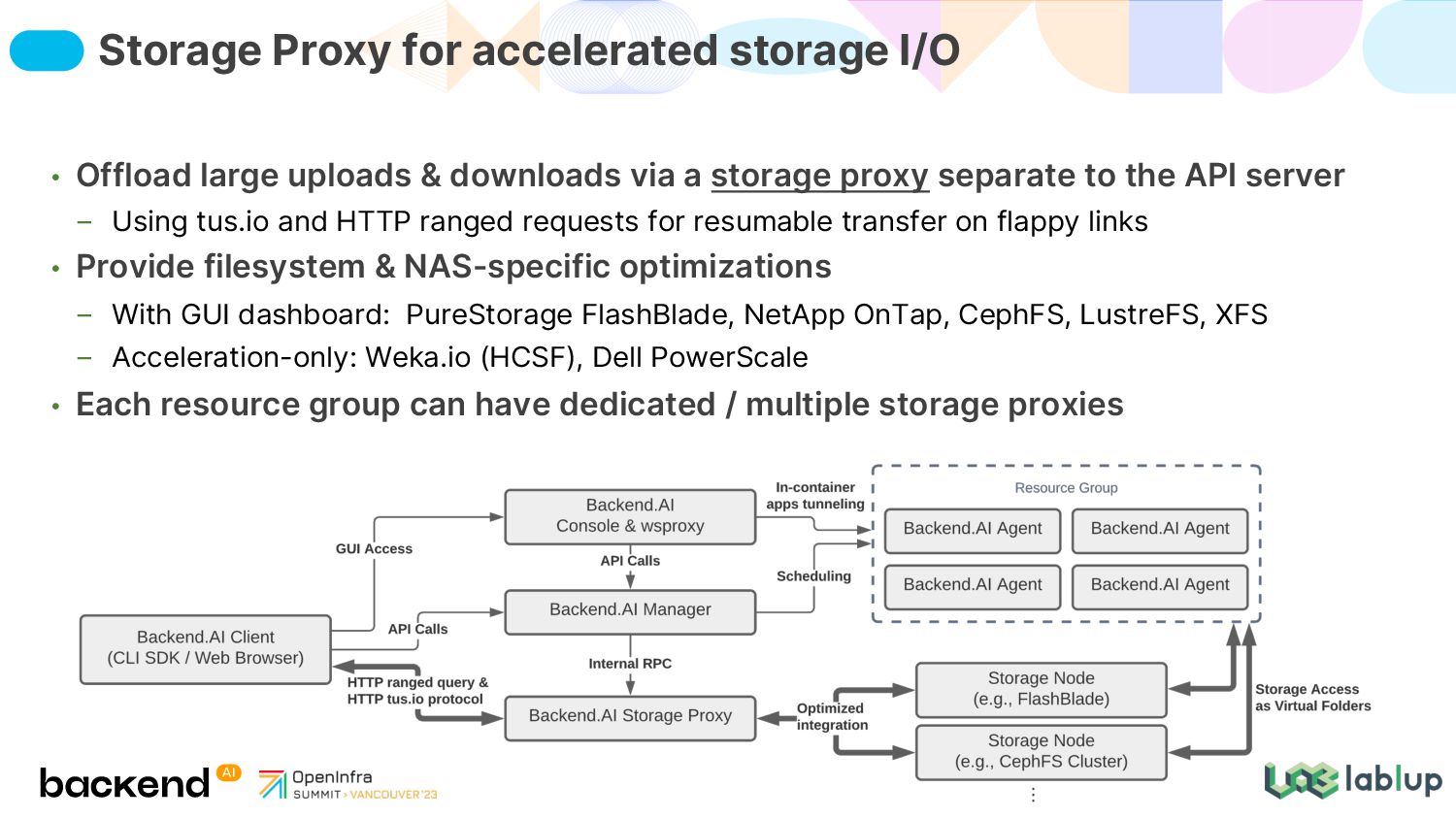{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}