Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
RethinkDB Primer
Search
Marcelo Alves
April 09, 2015
Programming
180
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
RethinkDB Primer
A short introduction to RethinkDB
Marcelo Alves
April 09, 2015
Other Decks in Programming
See All in Programming
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
2.4k
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
480
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
170
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
610
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
2.4k
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
Skillsは効率化、Agentsは"自分の拡張"——Builder時代のエージェント編成(CC Night 2026)
wemra
1
210
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
140
Performance Engineering for Everyone
elenatanasoiu
0
270
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
120
【やさしく解説 設計編・中級 #6】良いアーキテクチャとは ~ 一本の登り道の、行き先 ~
panda728
PRO
0
150
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
190
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
Leo the Paperboy
mayatellez
8
1.9k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Building Applications with DynamoDB
mza
96
7.1k
Navigating Weather and Climate Data
rabernat
0
320
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
RailsConf 2023
tenderlove
30
1.5k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Transcript
RethinkDB a primer
What is RethinkDB? An open-source distributed database built with .
"MongoDB with joins"
Features JSON data model Distributed joins, subqueries, aggregation and atomic
updates Hadoop-style map/reduce Friendly web and command-line administration tools Multi-datacenter replication and failover Sharding and replication Queries are automatically parallelized and distributed
Getting Started
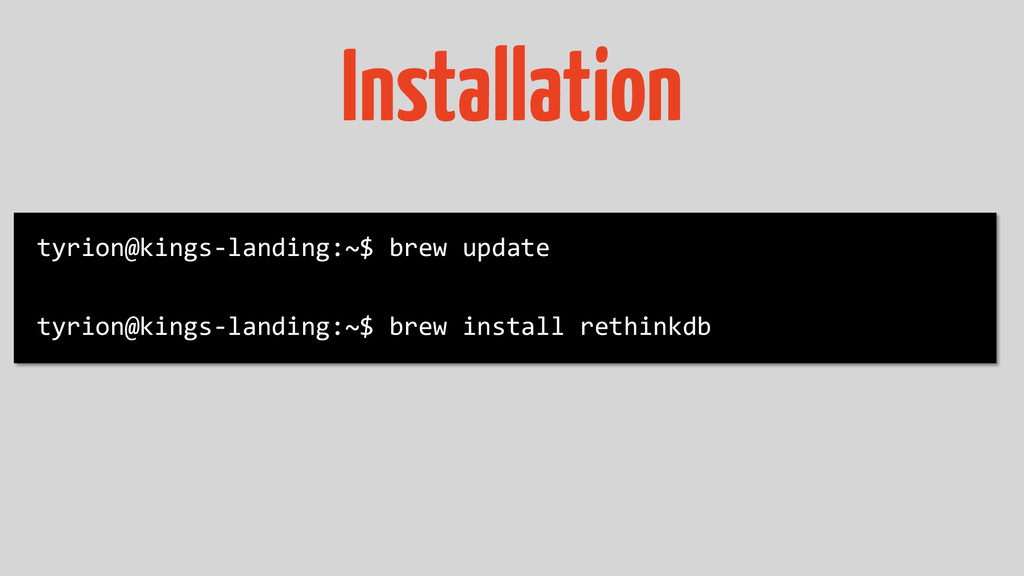
Installation tyrion@kings-landing:~$ brew update tyrion@kings-landing:~$ brew install rethinkdb
Set Up tyrion@kings-landing:~$ rethinkdb
Web UI
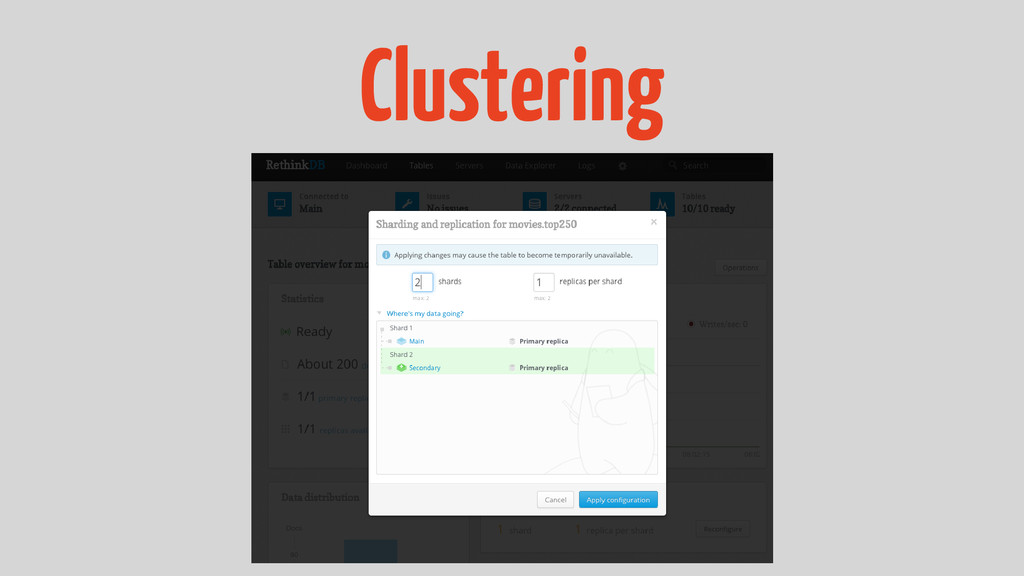
Clustering tyrion@kings-landing:~$ rethinkdb create –d /tmp/db1 tyrion@kings-landing:~$ rethinkdb –j –d
/tmp/db1 --port-offset 1
Clustering
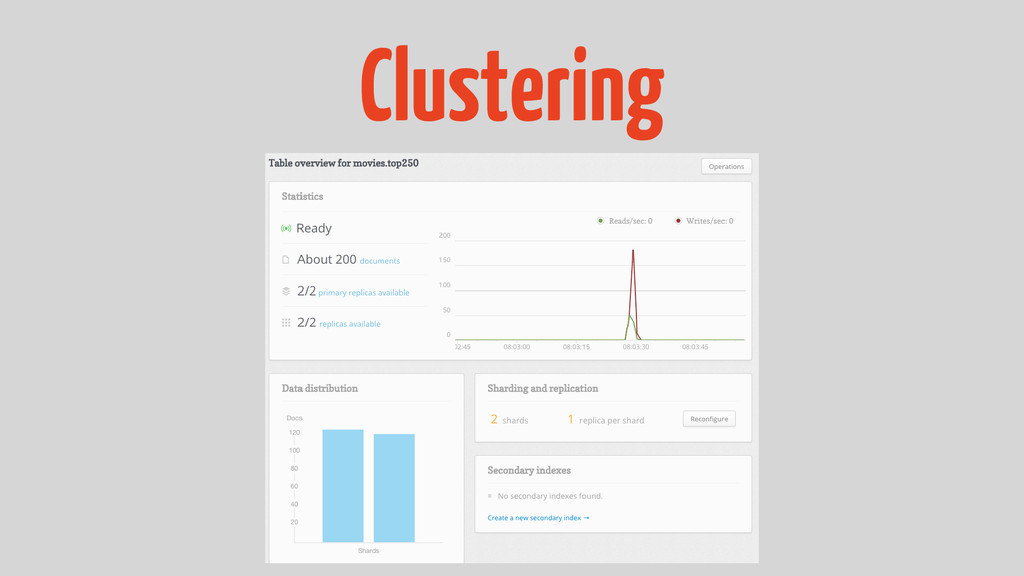
Clustering
Gem tyrion@kings-landing:~$ gem install rethinkdb [1] pry(main)> require "rethinkdb" [2]
pry(main)> include RethinkDB::Shortcuts [3] pry(main)> r.connect(host: 'localhost', database: 'marvel').repl()
Working with RethinkDB
Get All [1] pry(main)> r.table('characters').run
Get Document [1] pry(main)> r.table('characters').get(1).run
Filter [1] pry(main)> r.table('characters').filter({ age: 30 }).run
Update [1] pry(main)> r.table('characters').get(1).update({ age: 50}).run
Delete [1] pry(main)> r.table('characters').get(1).delete.run
ReQL
Principles 1. ReQL embeds into your programming language. 2. All
ReQL queries are chainable. 3. All queries execute on the server.
Embeds into your Language [1] pry(main)> require "rethinkdb" [2] pry(main)>
include RethinkDB::Shortcuts [3] pry(main)> r.connect(host: 'localhost', database: 'marvel').repl() [1] pry(main)> r.table('characters').get(1).delete.run
Chainable Queries [1] pry(main)> r.table('characters').run [2] pry(main)> r.table('characters').pluck('last_name').distinct().run [3] pry(main)>
r.table('characters').pluck('last_name').distinct().count().run
Server-Side Execution [1] pry(main)> query = r.table('characters').pluck('last_name').distinct [2] pry(main)> query.run
Examples
Filter + Contains [1] pry(main)> r.table('user').filter{|user| user['emails'].contains('
[email protected]
')}.run
Filter Dates [1] pry(main)> r.table("posts").filter{ |post| [2] pry(main)> post.during(r.time(2012, 1,
1, 'Z'), r.time(2013, 1, 1, 'Z')) [3] pry(main)> }.run
Filter + Pluck + Order + Limit [1] pry(main)> r.table('snippets').
[1] pry(main)* filter({lang: 'ruby'}). [1] pry(main)* pluck('id', 'title', 'created_at'). [1] pry(main)* order_by(r.desc('created_at')). [1] pry(main)* limit(10). [1] pry(main)* run()
Group + Merge [1] pry(main)> r.table('invoices').group( [1] pry(main)* [r.row['date'].year(), r.row['date'].month()]
[1] pry(main)* ).ungroup().merge( [1] pry(main)* {invoices: r.row['reduction'], month: r.row['group']} [1] pry(main)* ).without('reduction', 'group').order_by('month').run
Cool Features
Geospatial [1] pry(main)> point1 = r.point(-122.423246,37.779388) [2] pry(main)> point2 =
r.point(-117.220406,32.719464) [3] pry(main)> r.distance(point1, point2, {:unit => 'm'}).run [4] pry(main)> r.circle(point1, 2000).includes(point2).run
HTTP [1] pry(main)> r.table('comics').insert(r.http('http://foo.com/comics')).run
Changes [1] pry(main)> r.table('games').changes().run.each{|change| p change}
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Gem tyrion@kings-landing:~$ gem install rethinkdb [1] pry(main)> require "rethinkdb" [2]](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_10.jpg){kind=link}
{kind=link}
![Get All [1] pry(main)> r.table('characters').run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_12.jpg){kind=link}
![Get Document [1] pry(main)> r.table('characters').get(1).run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_13.jpg){kind=link}
![Filter [1] pry(main)> r.table('characters').filter({ age: 30 }).run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_14.jpg){kind=link}
![Update [1] pry(main)> r.table('characters').get(1).update({ age: 50}).run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_15.jpg){kind=link}
![Delete [1] pry(main)> r.table('characters').get(1).delete.run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
![Embeds into your Language [1] pry(main)> require "rethinkdb" [2] pry(main)>](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_19.jpg){kind=link}
![Chainable Queries [1] pry(main)> r.table('characters').run [2] pry(main)> r.table('characters').pluck('last_name').distinct().run [3] pry(main)>](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_20.jpg){kind=link}
![Server-Side Execution [1] pry(main)> query = r.table('characters').pluck('last_name').distinct [2] pry(main)> query.run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_21.jpg){kind=link}
{kind=link}
![Filter + Contains [1] pry(main)> r.table('user').filter{|user| user['emails'].contains('[email protected]')}.run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_23.jpg){kind=link}
![Filter Dates [1] pry(main)> r.table("posts").filter{ |post| [2] pry(main)> post.during(r.time(2012, 1,](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_24.jpg){kind=link}
![Filter + Pluck + Order + Limit [1] pry(main)> r.table('snippets').](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_25.jpg){kind=link}
![Group + Merge [1] pry(main)> r.table('invoices').group( [1] pry(main)* [r.row['date'].year(), r.row['date'].month()]](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_26.jpg){kind=link}
{kind=link}
![Geospatial [1] pry(main)> point1 = r.point(-122.423246,37.779388) [2] pry(main)> point2 =](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_28.jpg){kind=link}
![HTTP [1] pry(main)> r.table('comics').insert(r.http('http://foo.com/comics')).run](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_29.jpg){kind=link}
![Changes [1] pry(main)> r.table('games').changes().run.each{|change| p change}](https://files.speakerdeck.com/presentations/057a2c5e2abf456793e5c1d8a8771b88/slide_30.jpg){kind=link}
{kind=link}