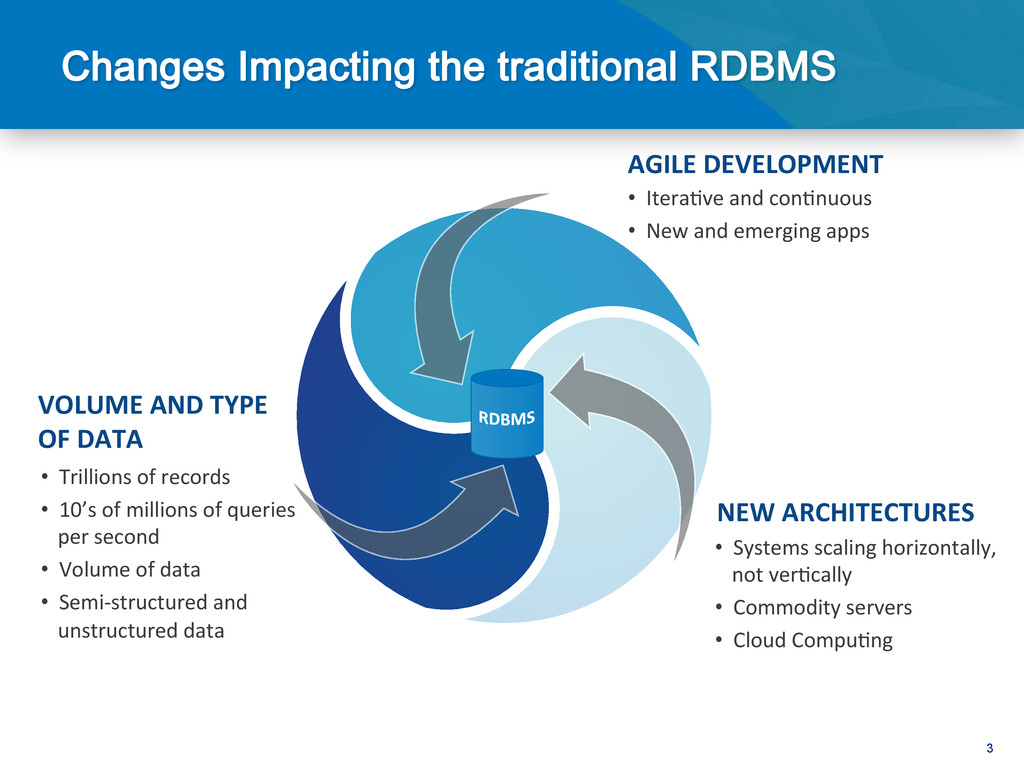
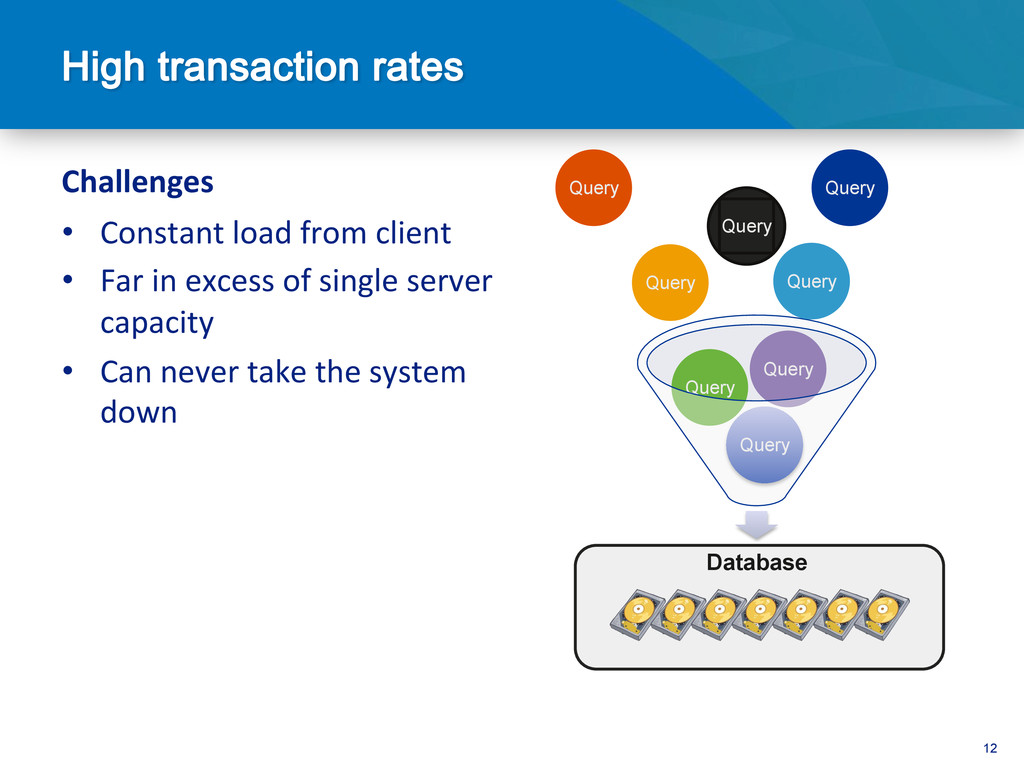
• Systems scaling horizontally, not ver@cally • Commodity servers • Cloud Compu@ng • Trillions of records • 10’s of millions of queries per second • Volume of data • Semi-‐structured and unstructured data • Itera@ve and con@nuous • New and emerging apps NEW ARCHITECTURES
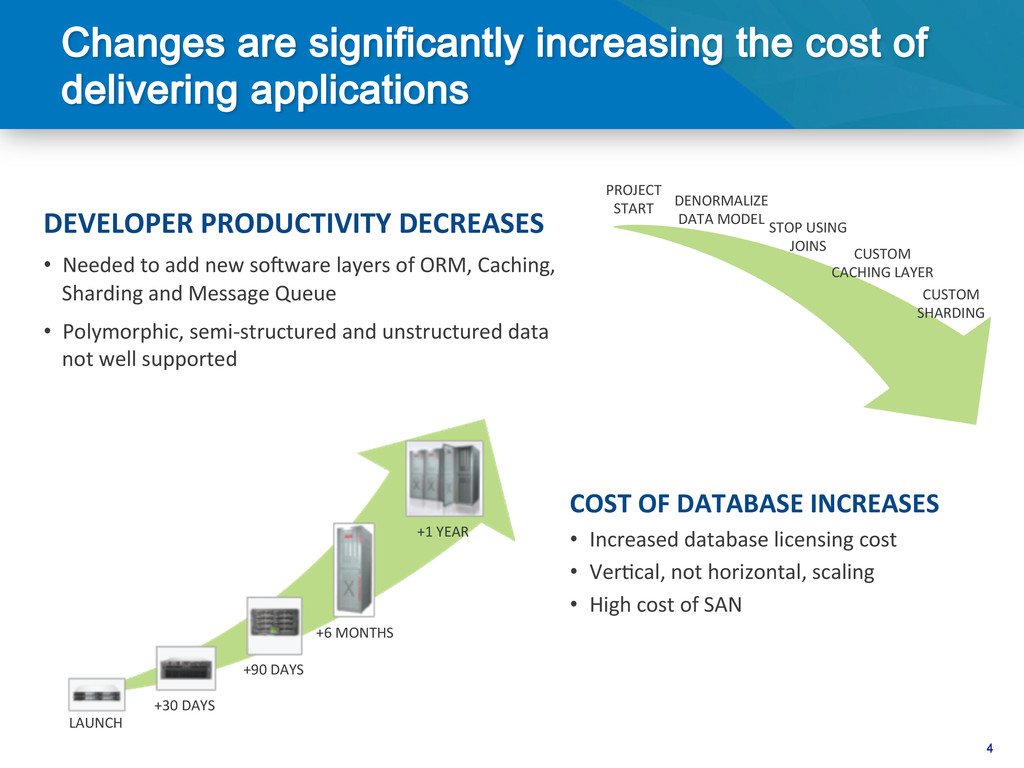
soPware layers of ORM, Caching, Sharding and Message Queue • Polymorphic, semi-‐structured and unstructured data not well supported COST OF DATABASE INCREASES • Increased database licensing cost • Ver@cal, not horizontal, scaling • High cost of SAN LAUNCH +30 DAYS +90 DAYS +6 MONTHS +1 YEAR PROJECT START DENORMALIZE DATA MODEL STOP USING JOINS CUSTOM CACHING LAYER CUSTOM SHARDING
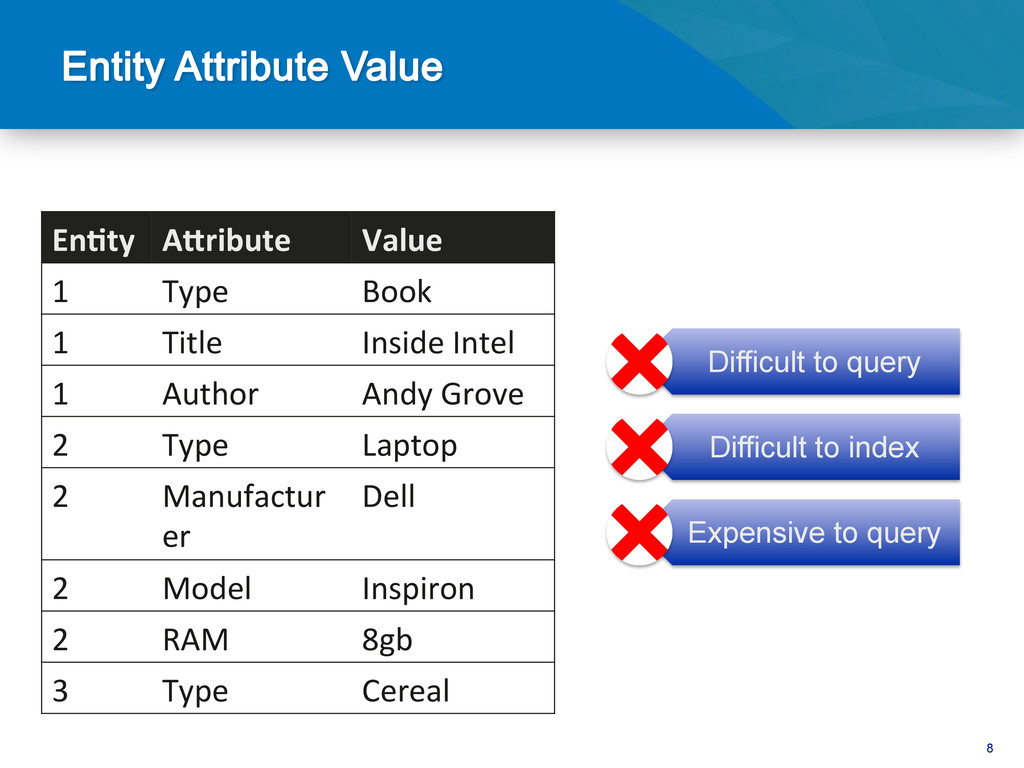
Book 1 Title Inside Intel 1 Author Andy Grove 2 Type Laptop 2 Manufactur er Dell 2 Model Inspiron 2 RAM 8gb 3 Type Cereal Difficult to query Difficult to index Expensive to query
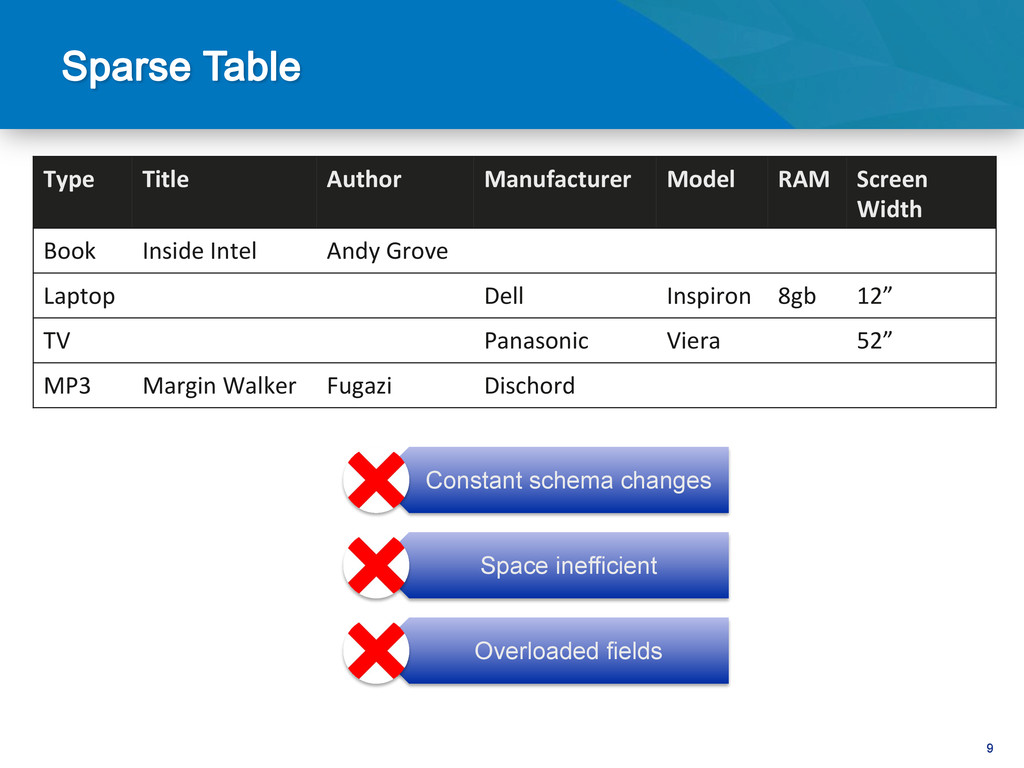
RAM Screen Width Book Inside Intel Andy Grove Laptop Dell Inspiron 8gb 12” TV Panasonic Viera 52” MP3 Margin Walker Fugazi Dischord Constant schema changes Space inefficient Overloaded fields
8gb 12” Manufacturer Model Screen Width Panasonic Viera 52” Title Author Manufacturer Margin Walker Fugazi Dischord Querying is difficult Hard to add more types
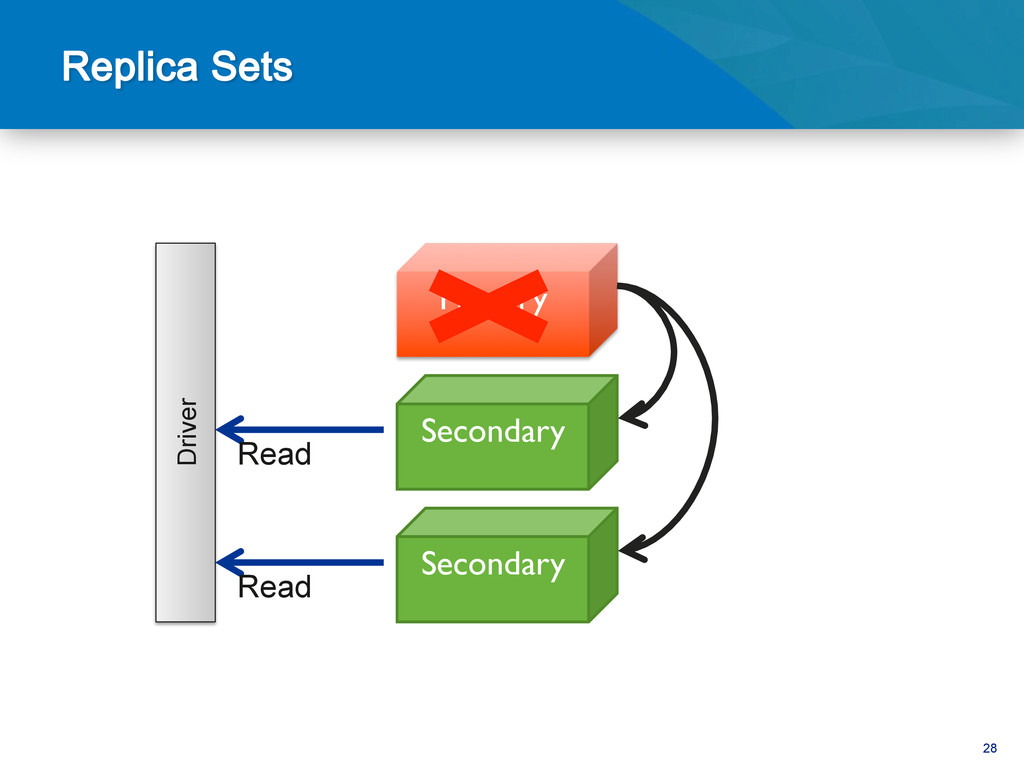
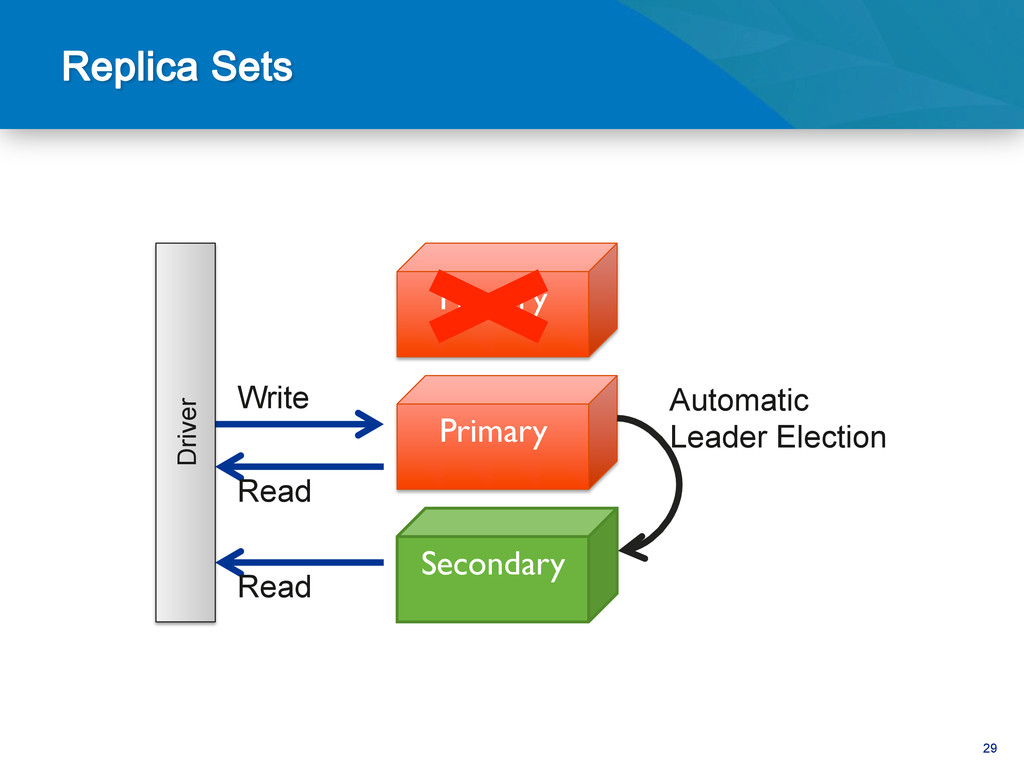
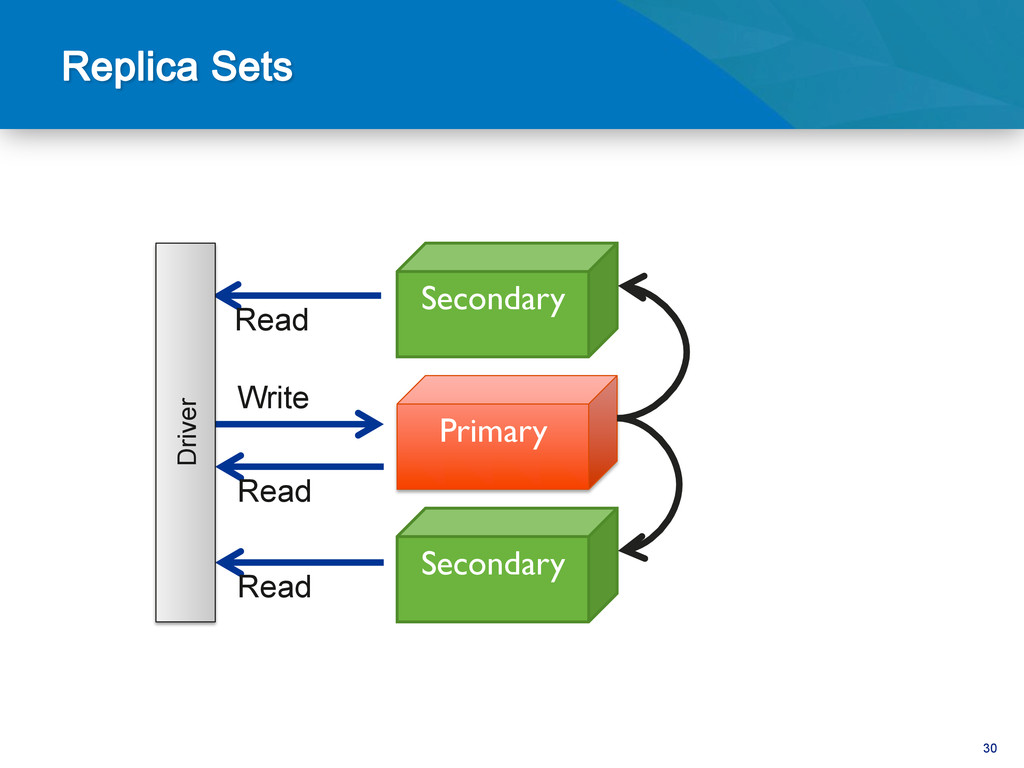
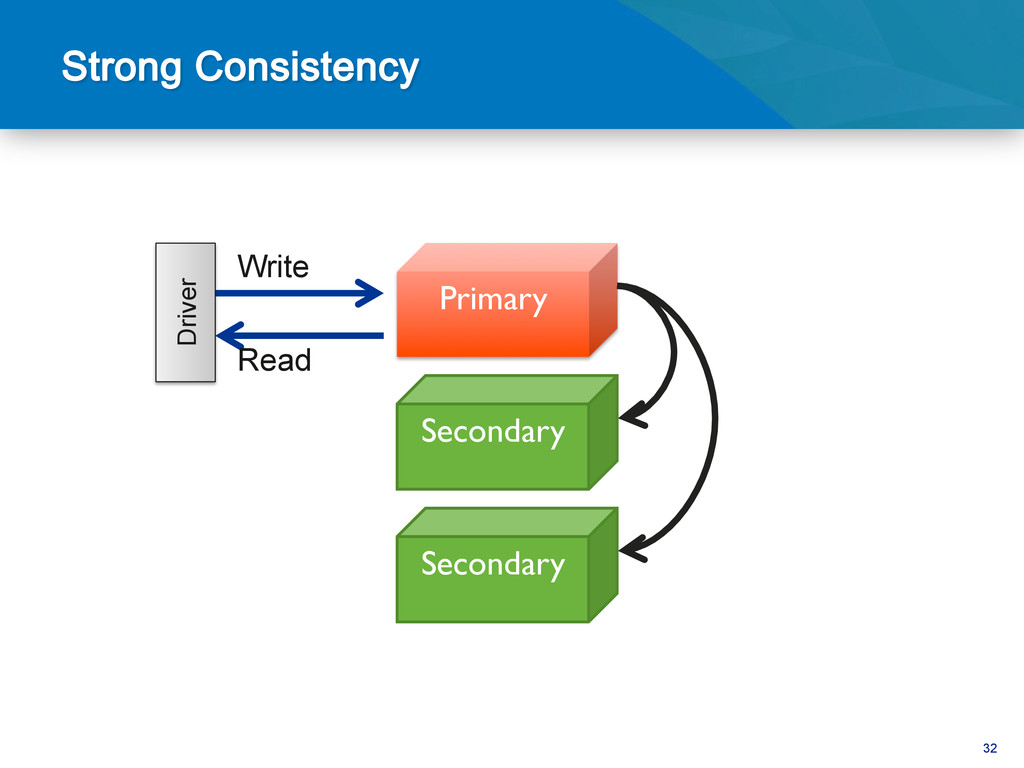
be hard • Dependent on joins Complex Objects • Vertical scaling • Poor data locality High transaction rate • Difficult to maintain consistency & HA • HA a bolt-on to many RDBMS High Availability • Schema changes • Monolithic data model Agile Development
ObjectId("4c4ba5c0672c685e5e8aabf3"), author : ”Jared", date : "Sat Jul 24 2010 19:47:11 GMT-‐0700 (PDT)", text : ”NoSQL Now 2012", tags : [ ”NoSQL", ”MongoDB" ] } Notes: -‐ _id is unique, but can be anything you’d like
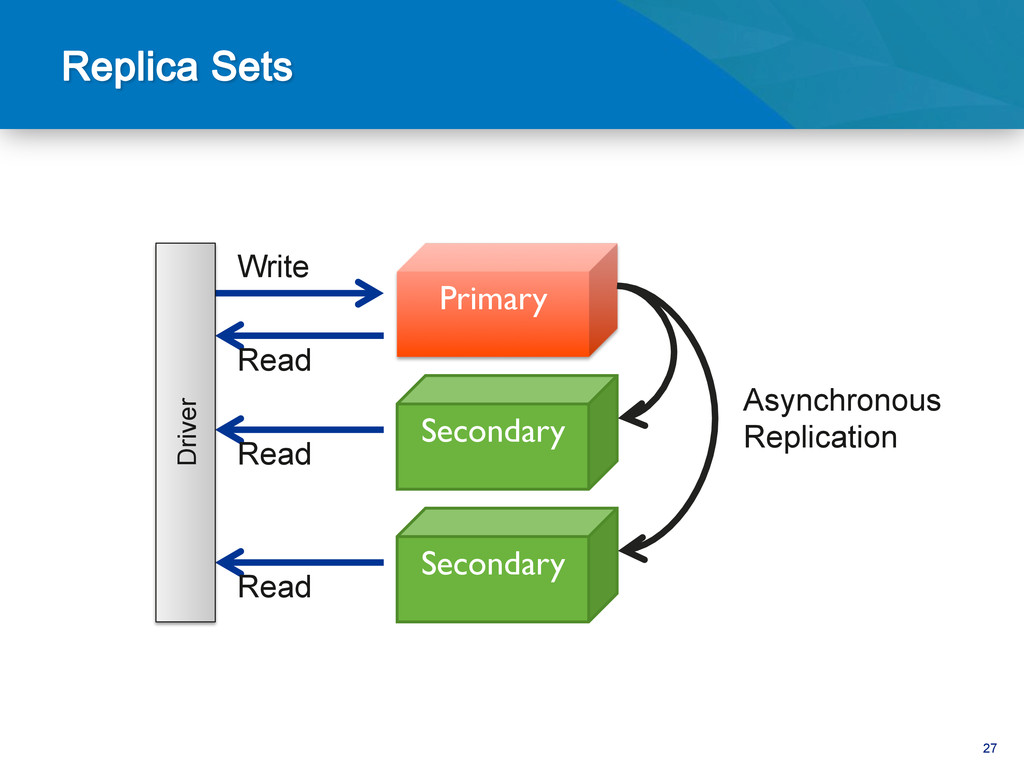
up to date wins – Up to date == within 10 seconds of primary • If a higher priority member catches up, it will force elec@on and win Primary priority = 3 Secondary priority = 2 Secondary priority = 1
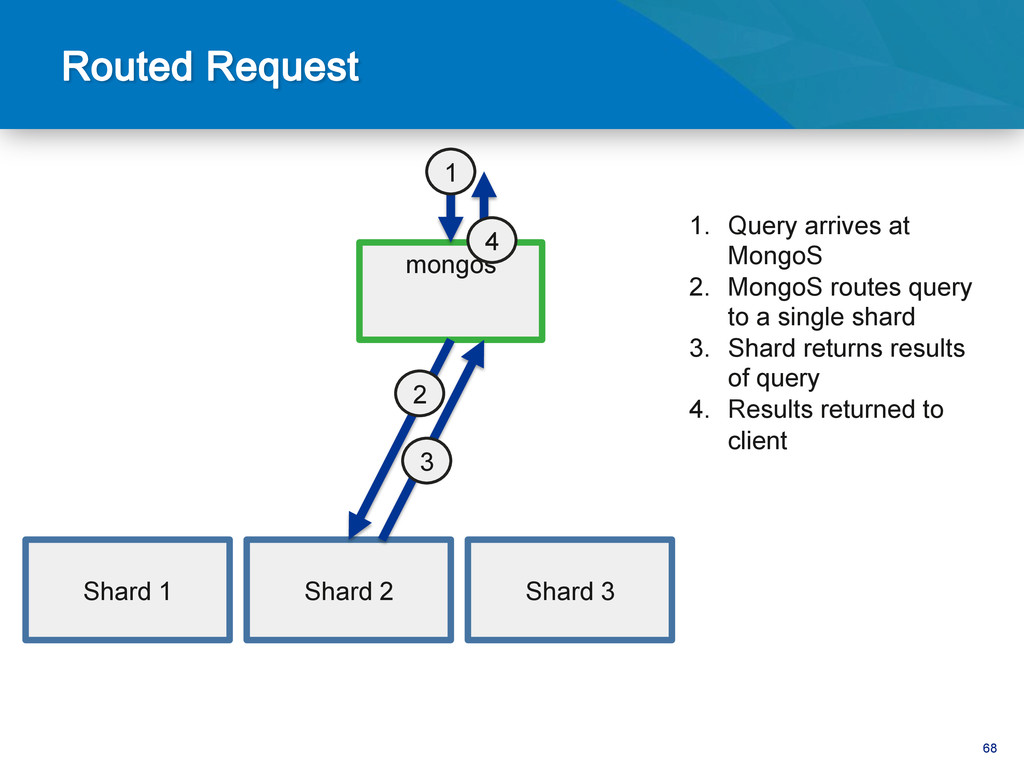
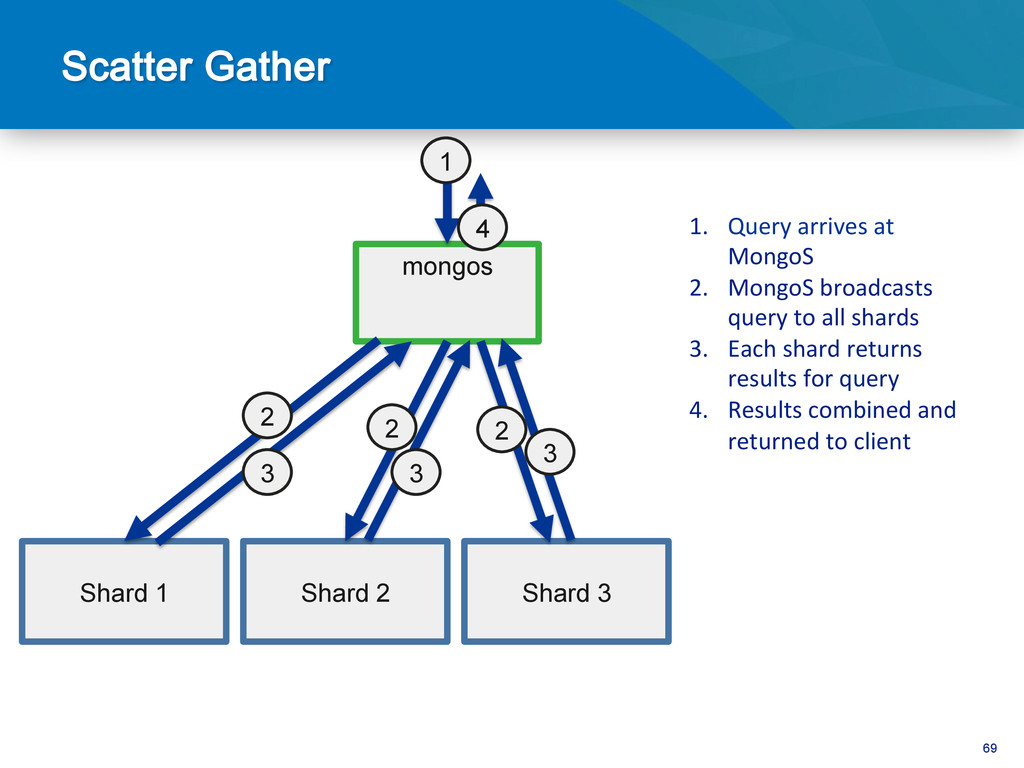
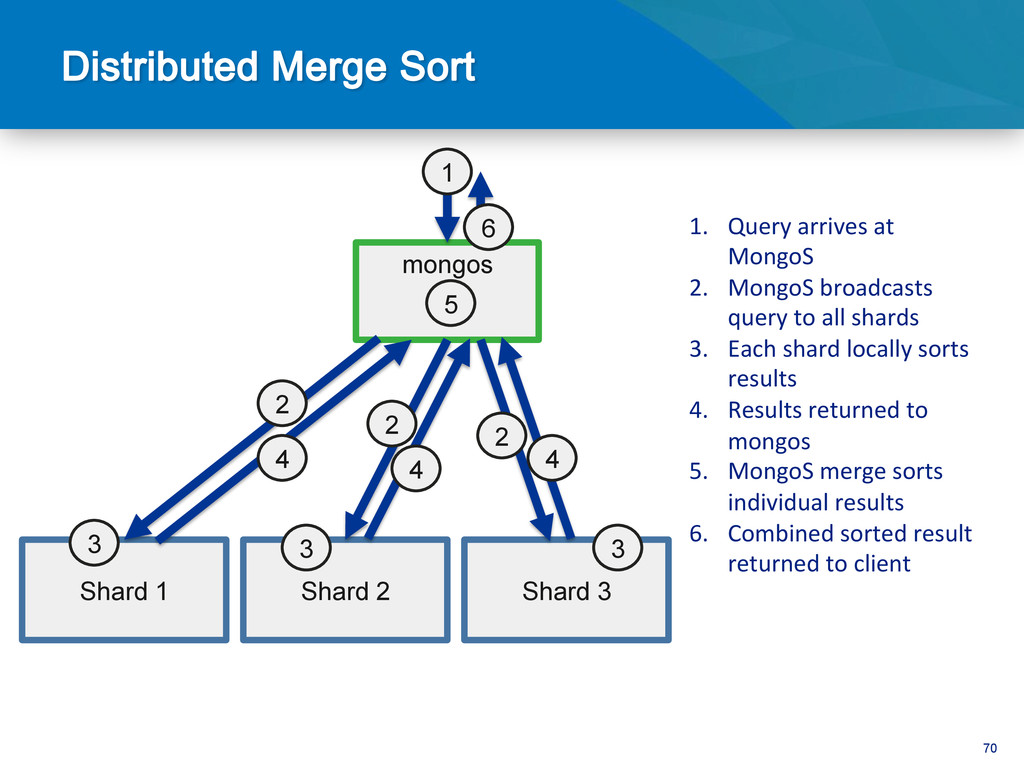
Sorted by shard key Routed in order db.users.find().sort({email:-1}) Find by non shard key Sca^er Gather db.users.find({state:”CA”}) Sorted by non shard key Distributed merge sort db.users.find().sort({state:1})
1. Query arrives at MongoS 2. MongoS broadcasts query to all shards 3. Each shard returns results for query 4. Results combined and returned to client 2 2 3 3 2 3
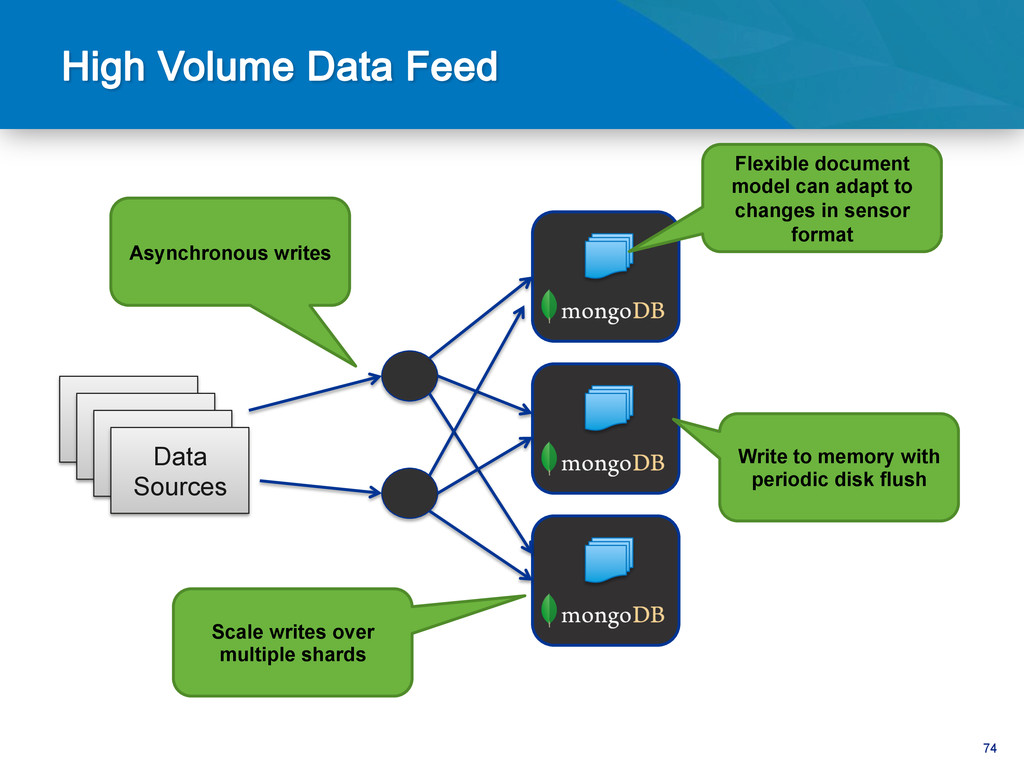
structured Machine Generated Data • High frequency trading Stock Market Data • Multiple sources of data • Each changes their format constantly Social Media Firehose
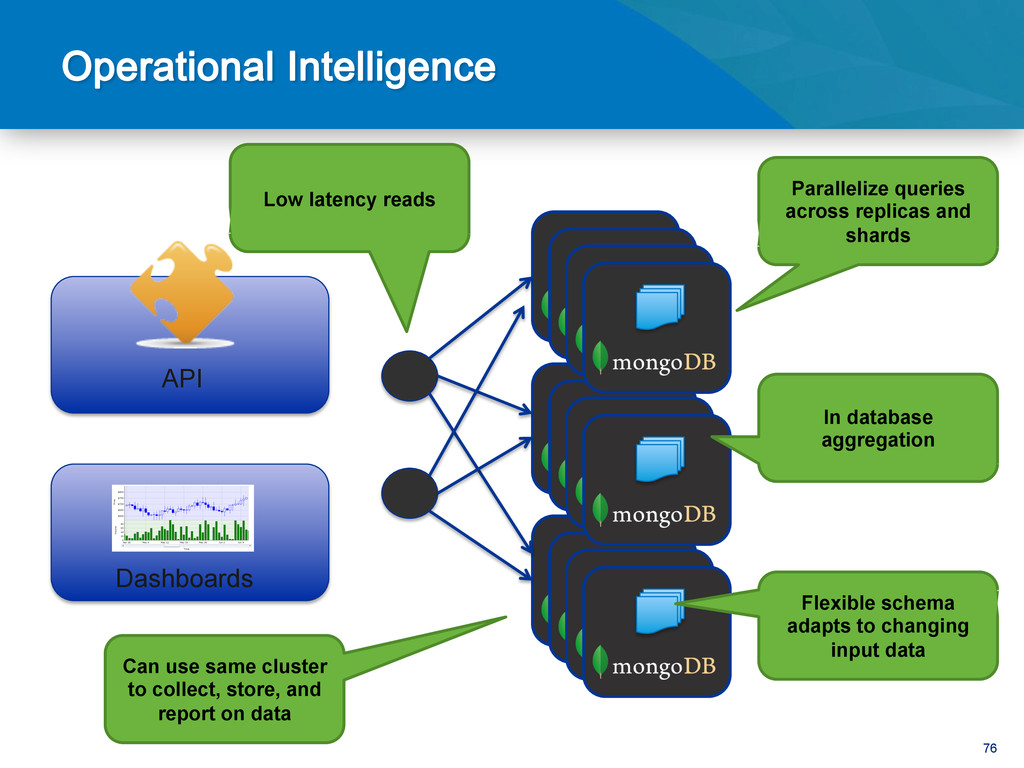
strict latency requirements Ad Targeting • Expose report data to millions of customers • Report on large volumes of data • Reports that update in real time Real time dashboards • What are people talking about? Social Media Monitoring
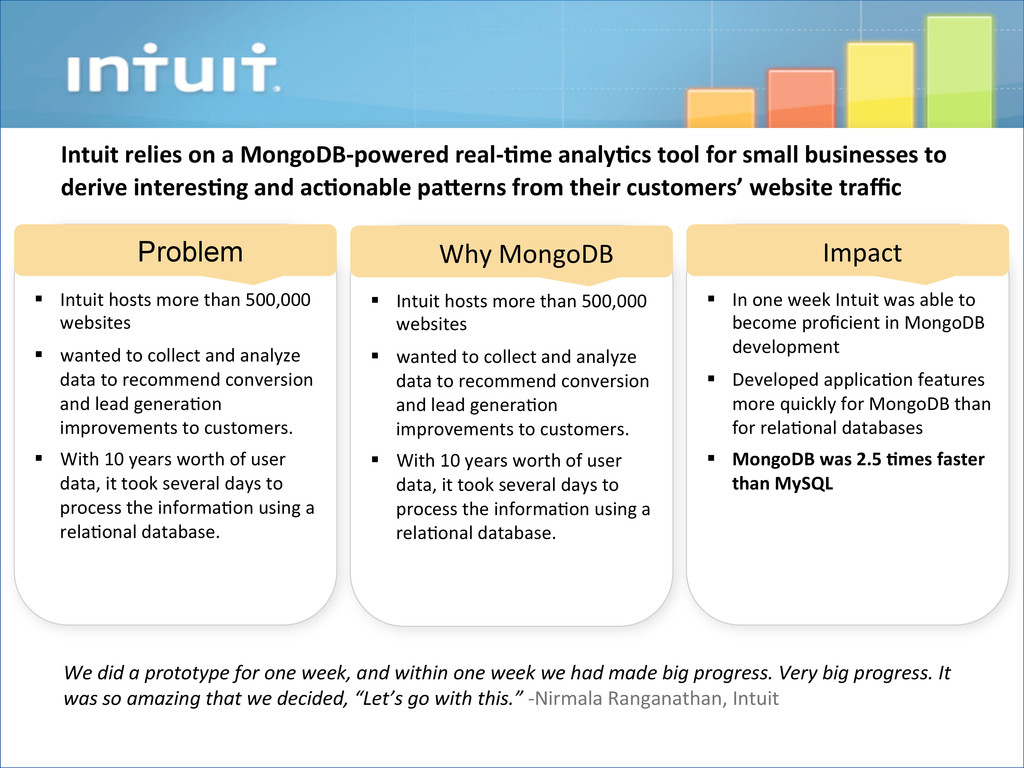
§ wanted to collect and analyze data to recommend conversion and lead genera@on improvements to customers. § With 10 years worth of user data, it took several days to process the informa@on using a rela@onal database. Problem § Intuit hosts more than 500,000 websites § wanted to collect and analyze data to recommend conversion and lead genera@on improvements to customers. § With 10 years worth of user data, it took several days to process the informa@on using a rela@onal database. Why MongoDB § In one week Intuit was able to become proficient in MongoDB development § Developed applica@on features more quickly for MongoDB than for rela@onal databases § MongoDB was 2.5 1mes faster than MySQL Impact Intuit relies on a MongoDB-‐powered real-‐1me analy1cs tool for small businesses to derive interes1ng and ac1onable paFerns from their customers’ website traffic We did a prototype for one week, and within one week we had made big progress. Very big progress. It was so amazing that we decided, “Let’s go with this.” -‐Nirmala Ranganathan, Intuit
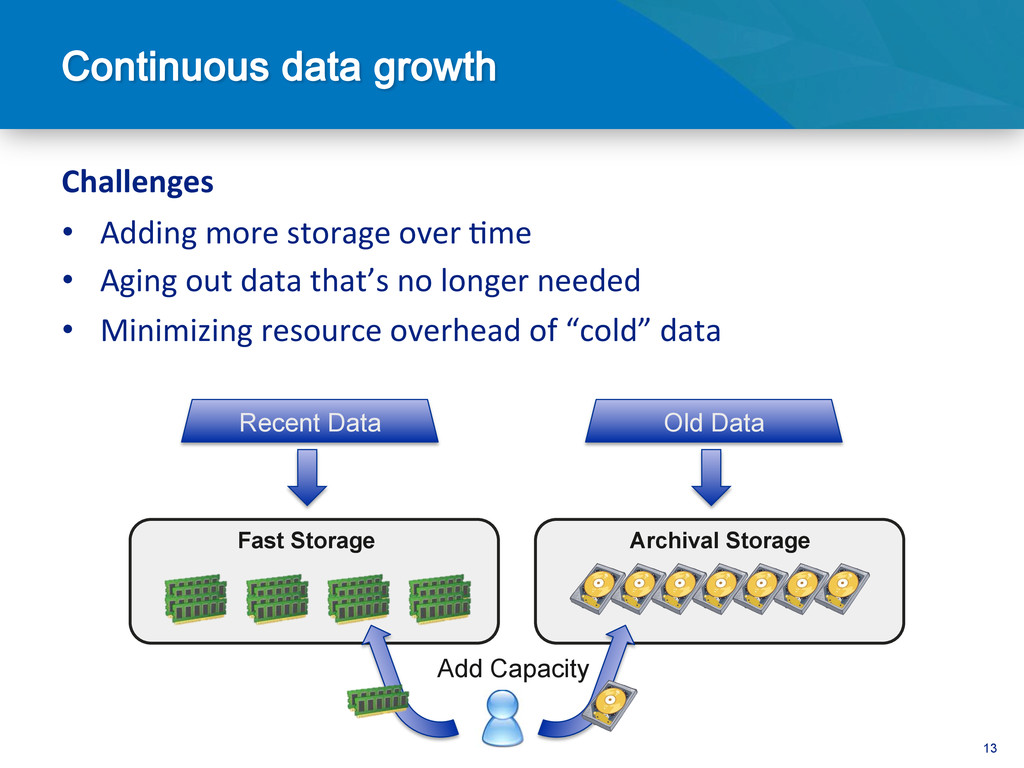
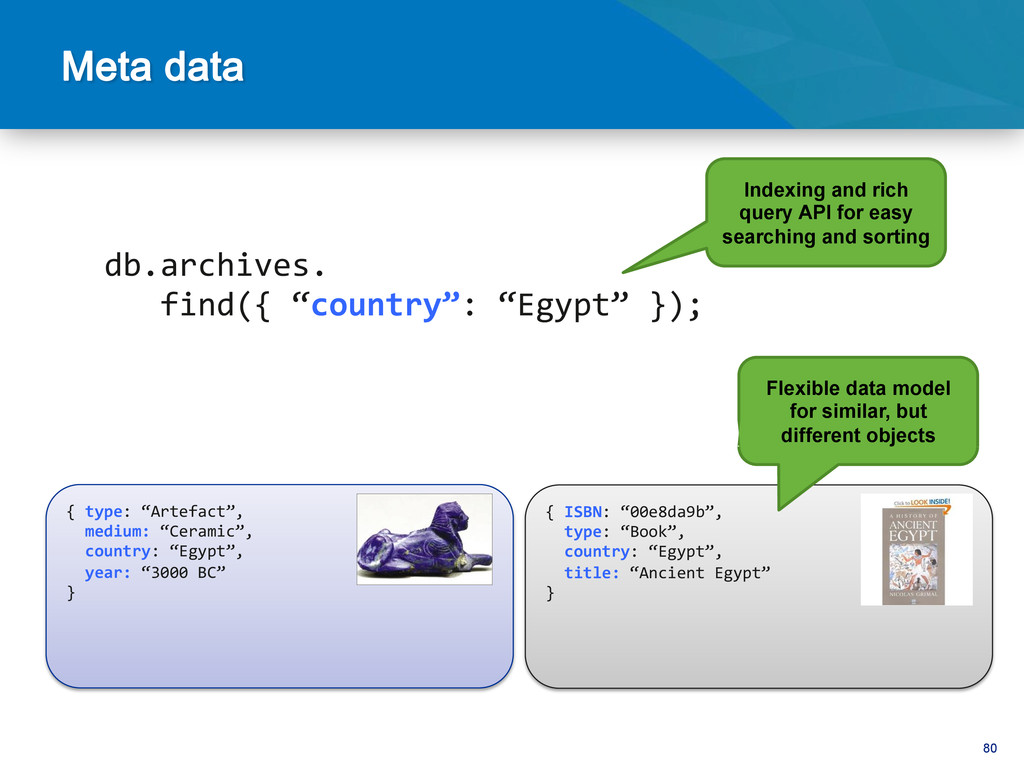
library Data Archiving • Have data sources that you don’t have access to • Stores meta-data on those stores and figure out which ones have the content Information discovery • Retina scans • Finger prints Biometrics
country: “Egypt”, title: “Ancient Egypt” } { type: “Artefact”, medium: “Ceramic”, country: “Egypt”, year: “3000 BC” } Flexible data model for similar, but different objects Indexing and rich query API for easy searching and sorting db.archives. find({ “country”: “Egypt” });
for millions of customers) par@@oning by func@on. § Home-‐grown key value store on top of their Oracle database offered sub-‐par performance § Codebase for this hybrid store became hard to manage § High licensing, HW costs Problem § JSON-‐based data structure § Provided Shu^erfly with an agile, high performance, scalable solu@on at a low cost. § Works seamlessly with Shu^erfly’s services-‐based architecture Why MongoDB § 500% cost reduc@on and 900% performance improvement compared to previous Oracle implementa@on § Accelerated @me-‐to-‐market for nearly a dozen projects on MongoDB § Improved Performance by reducing average latency for inserts from 400ms to 2ms. Impact ShuFerfly uses MongoDB to safeguard more than six billion images for millions of customers in the form of photos and videos, and turn everyday pictures into keepsakes The “really killer reason” for using MongoDB is its rich JSON-‐based data structure, which offers ShuKerfly an agile approach to develop soNware. With MongoDB, the ShuKerfly team can quickly develop and deploy new applicaPons, especially Web 2.0 and social features. -‐Kenny Gorman, Director of Data Services
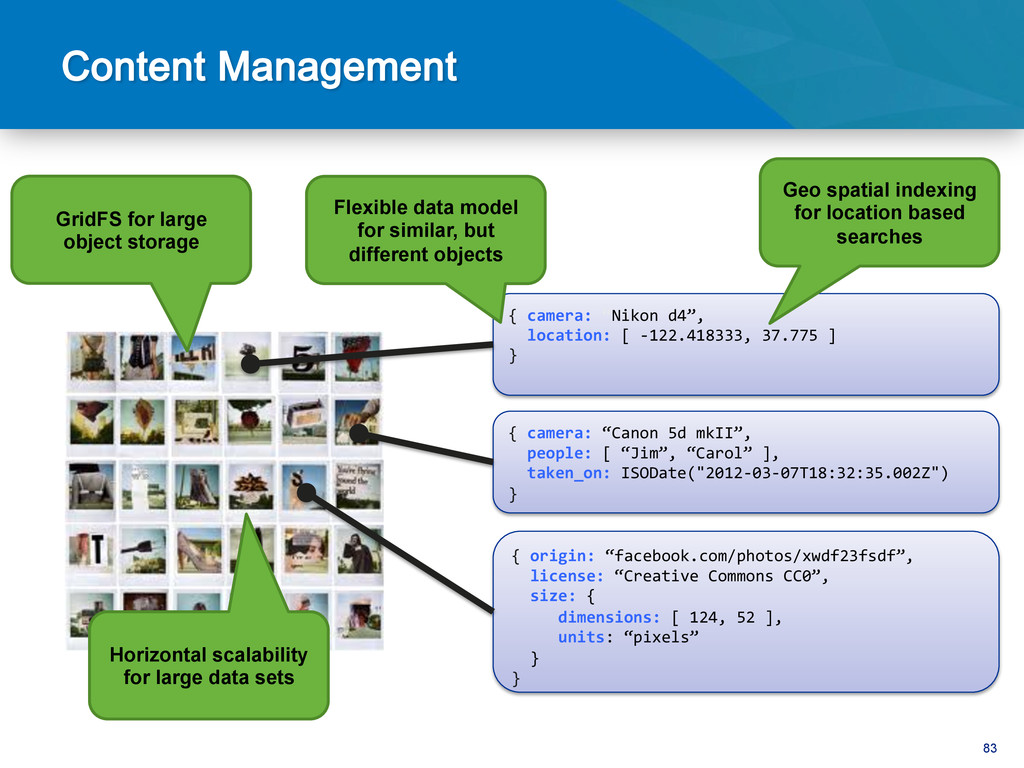
content, layout News Site • Generate layout on the fly for each device that connects • No need to cache static pages Multi-Device rendering • Store large objects • Simple modeling of metadata Sharing
37.775 ] } { camera: “Canon 5d mkII”, people: [ “Jim”, “Carol” ], taken_on: ISODate("2012-‐03-‐07T18:32:35.002Z") } { origin: “facebook.com/photos/xwdf23fsdf”, license: “Creative Commons CC0”, size: { dimensions: [ 124, 52 ], units: “pixels” } } Flexible data model for similar, but different objects Horizontal scalability for large data sets Geo spatial indexing for location based searches GridFS for large object storage
a system build on con@nuous stream of high-‐ quality text pulled from online sources § Adding too much data too quickly resulted in outages; tables locked for tens of seconds during inserts § Ini@ally launched en@rely on MySQL but quickly hit performance road blocks Problem Life with MongoDB has been good for Wordnik. Our code is faster, more flexible and dramaPcally smaller. Since we don’t spend Pme worrying about the database, we can spend more Pme wriPng code for our applicaPon. -‐Tony Tam, Vice President of Engineering and Technical Co-‐founder § Migrated 5 billion records in a single day with zero down@me § MongoDB powers every website requests: 20m API calls per day § Ability to eliminated memcached layer, crea@ng a simplified system that required fewer resources and was less prone to error. Why MongoDB § Reduced code by 75% compared to MySQL § Fetch @me cut from 400ms to 60ms § Sustained insert speed of 8k words per second, with frequent bursts of up to 50k per second § Significant cost savings and 15% reduc@on in servers Impact Wordnik uses MongoDB as the founda@on for its “live” dic@onary that stores its en@re text corpus – 3.5T of data in 20 billion records
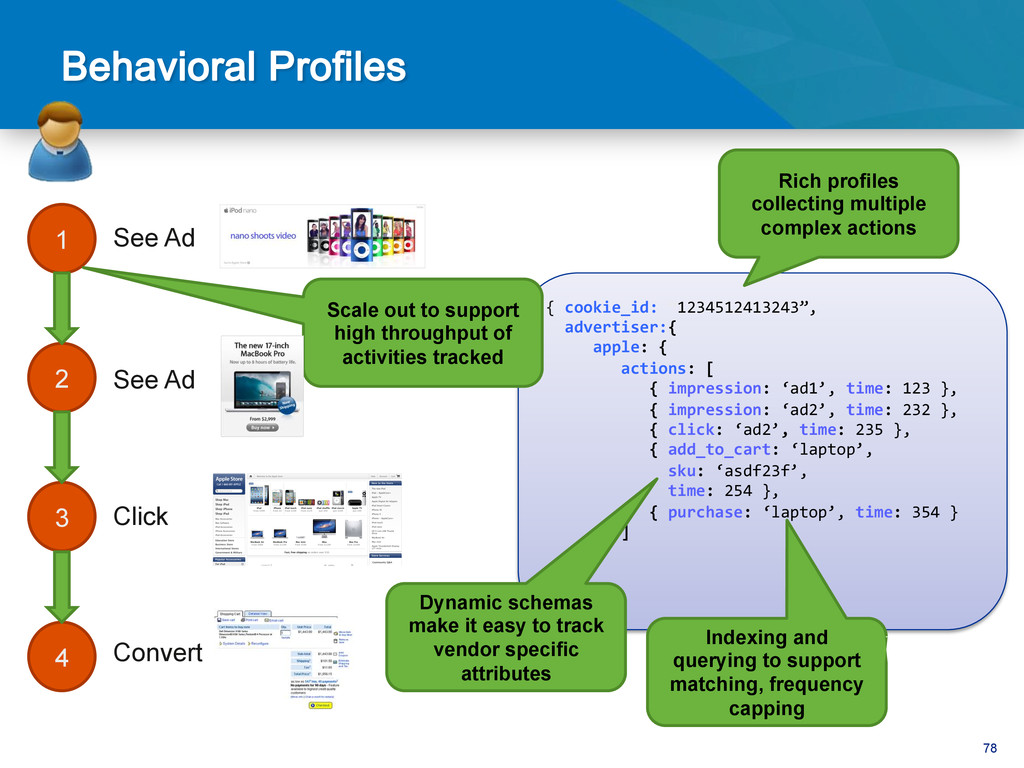
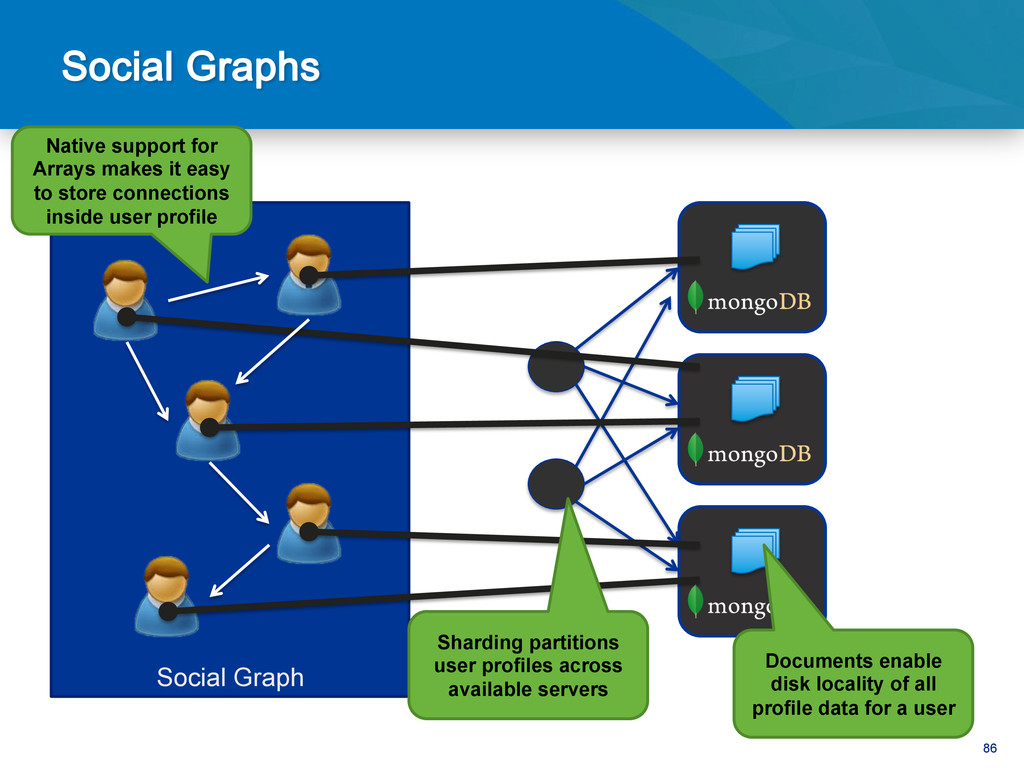
data for a user Sharding partitions user profiles across available servers Native support for Arrays makes it easy to store connections inside user profile
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
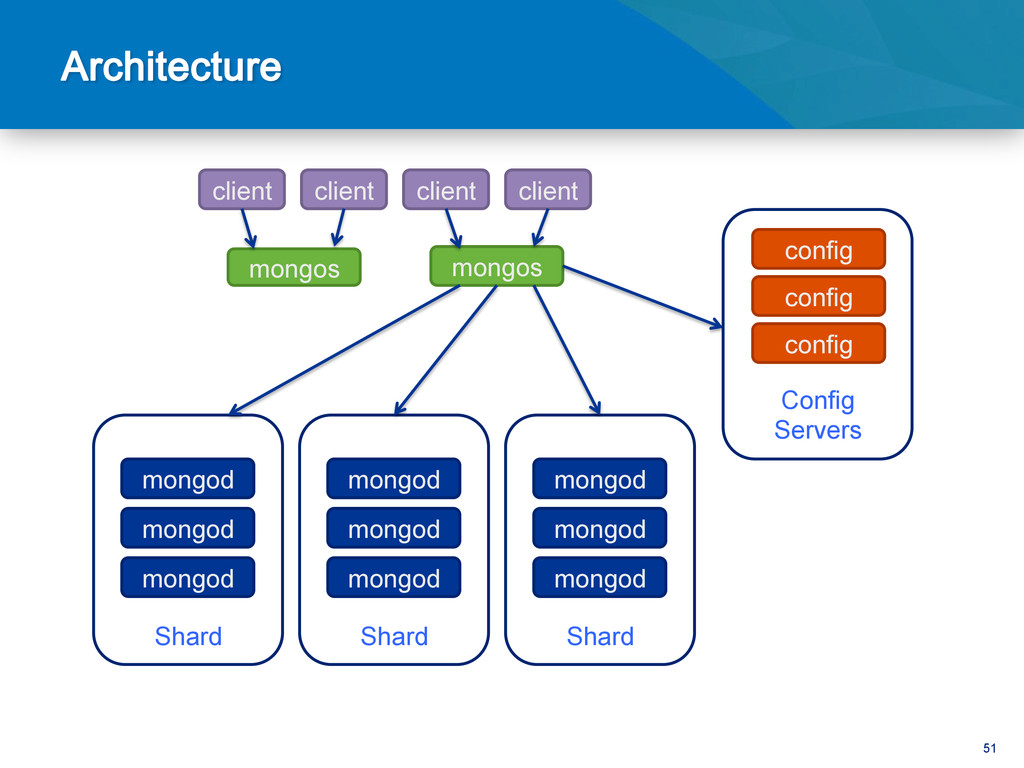{kind=link}
![52 { name: “Jared”, email: “[email protected]”, } { name: “Scott”,](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_51.jpg){kind=link}
{kind=link}
![54 -∞ +∞ [email protected] [email protected] [email protected]](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_53.jpg){kind=link}
![55 -∞ +∞ [email protected] [email protected] [email protected] Split!](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_54.jpg){kind=link}
![56 -∞ +∞ [email protected] [email protected] [email protected] Split! This is a](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_55.jpg){kind=link}
![57 -∞ +∞ [email protected] [email protected] [email protected]](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_56.jpg){kind=link}
![58 -∞ +∞ [email protected] [email protected] [email protected]](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_57.jpg){kind=link}
![59 -∞ +∞ [email protected] [email protected] [email protected] Split!](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_58.jpg){kind=link}
{kind=link}
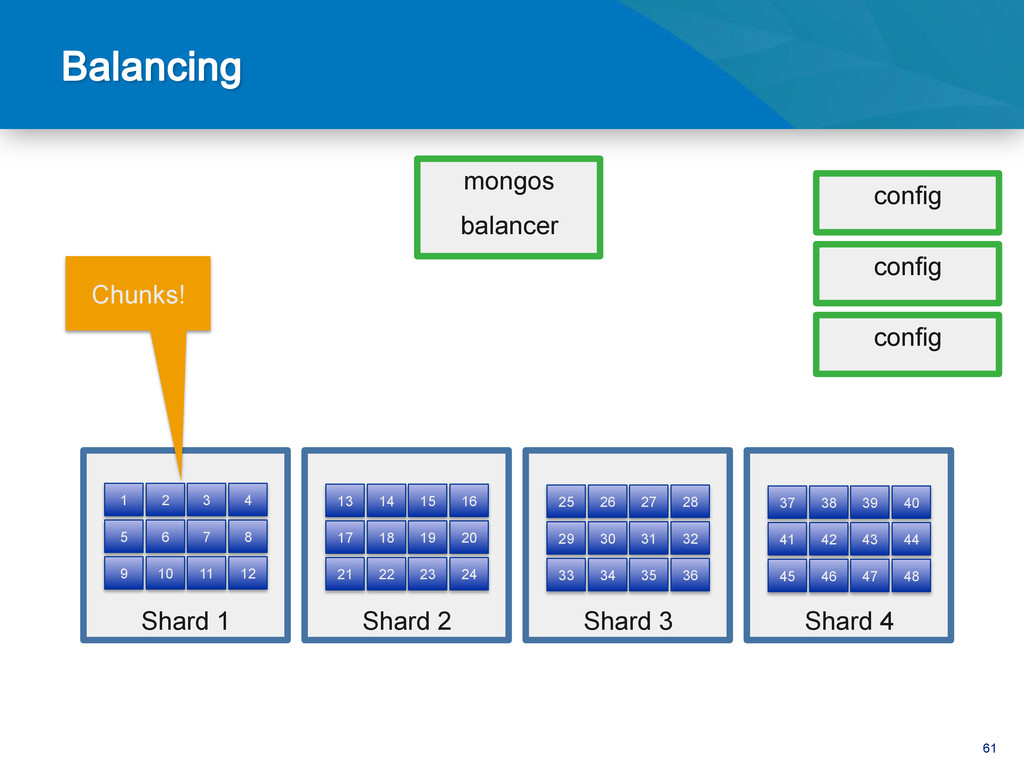{kind=link}
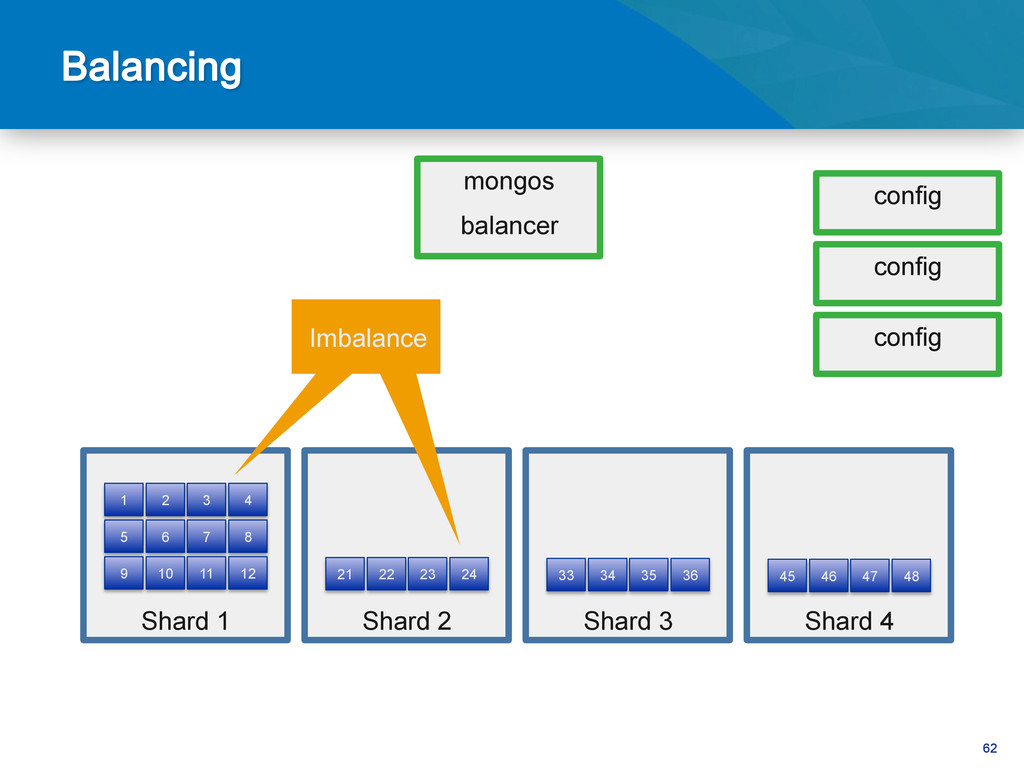{kind=link}
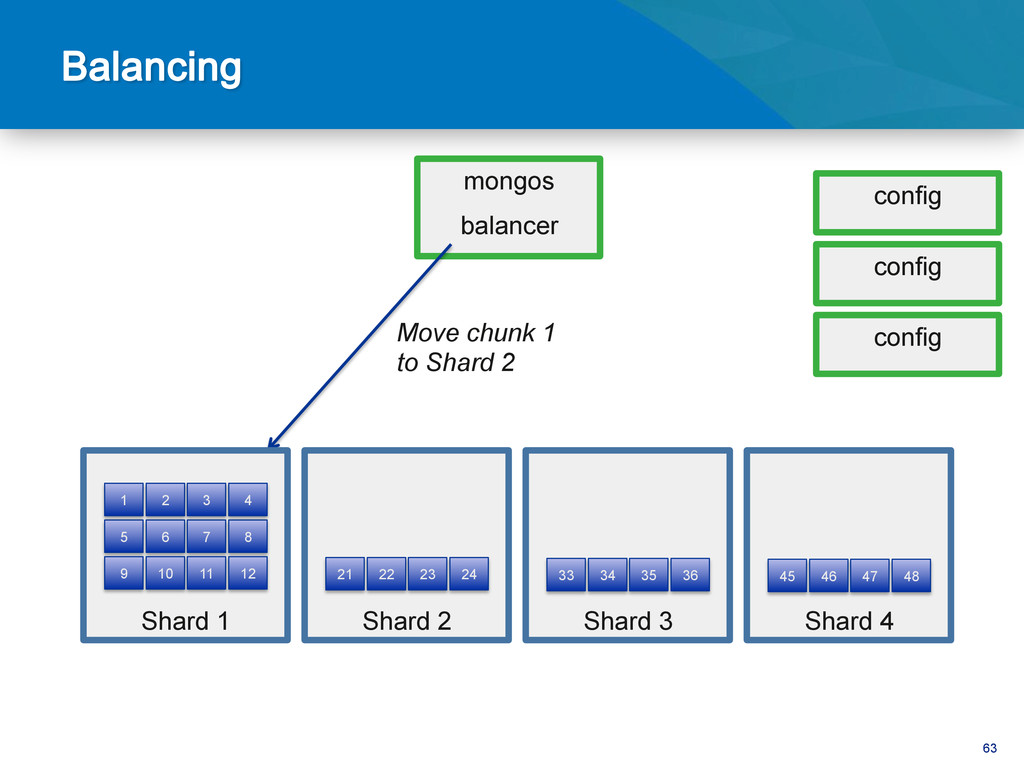{kind=link}
{kind=link}
{kind=link}
![66 By Shard Key Routed db.users.find( {email: “[email protected]”})](https://files.speakerdeck.com/presentations/5033bf62abb260000204e9f9/slide_65.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}