Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kaggle_MAP_3rd_place.pdf
Search
monsaraida
November 27, 2025
420
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kaggle_MAP_3rd_place.pdf
monsaraida
November 27, 2025
Featured
See All Featured
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
We Are The Robots
honzajavorek
0
270
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Are puppies a ranking factor?
jonoalderson
1
3.7k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Building Adaptive Systems
keathley
44
3.1k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Transcript
MAPコンペ 3rd Placeの紹介 mosaraida&Masaya MAP, Jigsaw, Code Golf 振り返り会 by
関東Kaggler会 - MAP LT②
Masaya
自己紹介 Masaya (荻野 聖也) X: @lol_ha_irrohas • 工学部出身 Kaggleは触っておくか~ぐらい •
AIエンジニア(2021/04~) ◦ NLP・画像 ◦ プロダクト開発 • Applied Research Engineer(2025/11~) ◦ AI Agent 採用強化中!! (KagglerのJoin待ってます。。。!!) 略歴
Overview : 3rd Place [monsaraida-model-2-b] LoRA SFT: Qwen3-14B SequenceClassification (multi-task)
Prompt: base + choices + hints EMA, label smoothing, R-Drop monsaraida’s pipeline 2nd stage (inference on 50% of the test set) [Masaya-model-1] LoRA SFT: Qwen2.5-32B-Instruct CausalLM (Question-wise label pruning) Prompt: base + choices [monsaraida-model-1-a] LoRA SFT: Qwen3-14B SequenceClassification (multi-task) Prompt: base + choices + hints EMA, label smoothing, R-Drop, AWP Private = 0.945 Public = 0.950 CV = 0.949 Private = 0.945 Public = 0.949 CV = 0.948 [Masaya-model-2] QLoRA SFT: Qwen2.5-72B-Instruct quantized with AutoRound (GPTQ) CausalLM (Question-wise label pruning) Prompt: base + choices Private = 0.946 Public = 0.950 Private = 0.944 Public = 0.949 CV = 0.949 [monsaraida-model-2-a] LoRA SFT: Qwen3-14B SequenceClassification (multi-task) Prompt: base + choices + hints EMA, label smoothing, R-Drop Private = 0.944 Public = 0.950 CV = 0.948 [Masaya+monsaraida-model-1] LoRA SFT: Qwen2.5-32B-Instruct CausalLM (Question-wise label pruning) Prompt: base + choices EMA Private = 0.945 Public = 0.951 CV = 0.950 Masaya’s pipeline 1st stage (inference on the entire test set) Final Results Private = 0.948 (3rd) Public = 0.954 (1st) Ensemble まとめ • monsaraidaモデルとMasayaモデルのシン プルアンサンブル ◦ SeqClassification ◦ Causal LM →モデル設計の方向性が大幅に違っていたの で、精度大幅向上👆 • Prompt Engineering ◦ 特徴量を与える ◦ 選択肢の削減(CausalLM) 所感 • 単一モデルの精度を高めることが大事 • 推論時間に収まる限界を攻めるのが大事
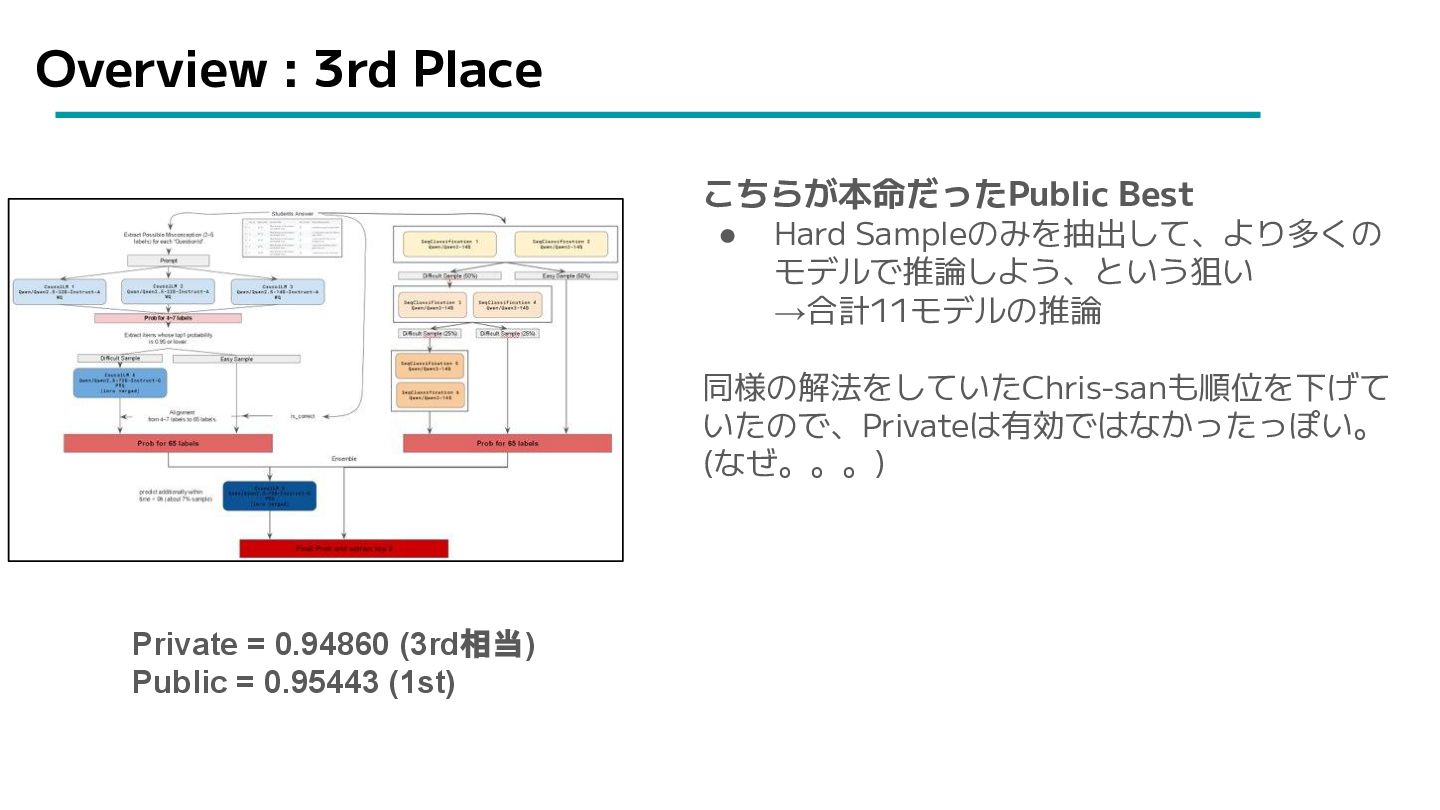
Overview : 3rd Place こちらが本命だったPublic Best • Hard Sampleのみを抽出して、より多くの モデルで推論しよう、という狙い
→合計11モデルの推論 同様の解法をしていたChris-sanも順位を下げて いたので、Privateは有効ではなかったっぽい。 (なぜ。。。) Private = 0.94860 (3rd相当) Public = 0.95443 (1st)
Masaya Pipelineをざっくりと Causal LMを主軸に、 メリット • vLLMと相性良し! ◦ 推論の高速化 •
ラベルが可変でも柔軟に対応可! ◦ Eediコンペでも活躍 デメリット • 学習が地味にムズイ ◦ 発散(lossがnan)したり、 ◦ lrの調整で精度が大幅に変わったり、 ※Eediの解法より 選択肢に意味を与えて、その選択肢をTokenとして予測 させる • Yes / No (Point Wise) • A, B, C,...(List Wise) 偉大な参考資料 • ktrさんのatmaCup#17の解法(リンク) • kutoさんの勉強会の資料(リンク)
今回のコンペでCausal LMが生きた点 MAPコンペでは課題設定が閉じている • train / testで登場するQuestionId(大カテゴリ)は同 じ • 各QuestionIdで登場するラベルが同じ
• 生徒の解答の正誤で labelのprefix(“True” / ”False”)が逆算可能 つまり、何が言いたいかというと。。。 input_dfを見ると、各サンプルの ラベル数は高々5個 ~7個程度に絞ることができる 。 →この状況がCausal LMと相性が良かった。 候補を並べて「どれが正解?」と聞くだけ 候補が Correct:NA Neither:NA Misconception:FlipChange Misconception:Mult Misconception:SwapDividend のみ QuestionId StudentAnswer “意味”をTokenに含めることができ、 可変なラベル構成にも対応可能。 →Input tokenの節約 これをDebertaで実現しようとすると、(i)headで 全てのclass数を用意、(ii)pair wiseな推論、(iii) 特殊トークンの用意 あたり? True_ or False 後処理で利用
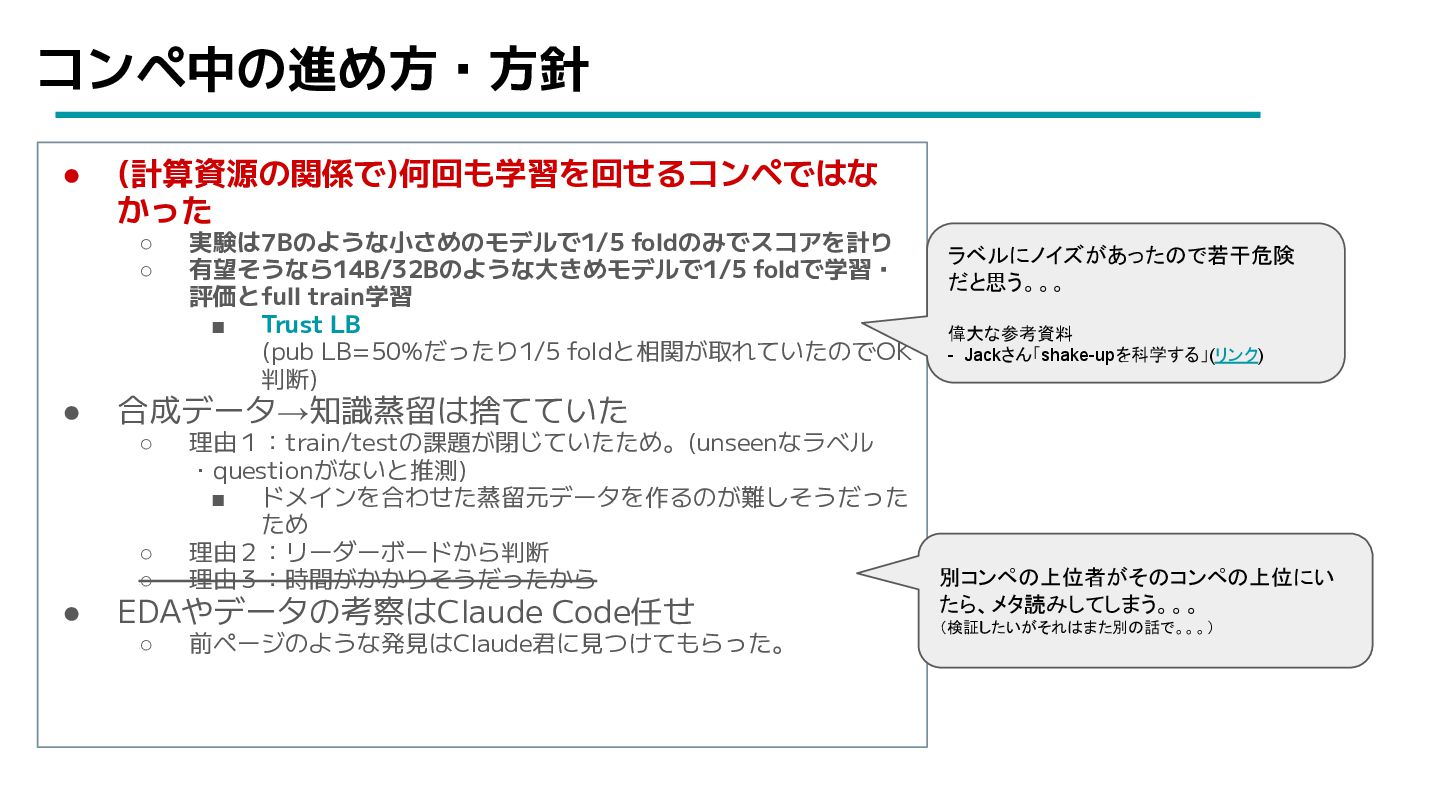
コンペ中の進め方・方針 • (計算資源の関係で)何回も学習を回せるコンペではな かった ◦ 実験は7Bのような小さめのモデルで1/5 foldのみでスコアを計り ◦ 有望そうなら14B/32Bのような大きめモデルで1/5 foldで学習・
評価とfull train学習 ▪ Trust LB (pub LB=50%だったり1/5 foldと相関が取れていたのでOK 判断) • 合成データ→知識蒸留は捨てていた ◦ 理由1:train/testの課題が閉じていたため。(unseenなラベル ・questionがないと推測) ▪ ドメインを合わせた蒸留元データを作るのが難しそうだった ため ◦ 理由2:リーダーボードから判断 ◦ 理由3:時間がかかりそうだったから • EDAやデータの考察はClaude Code任せ ◦ 前ページのような発見はClaude君に見つけてもらった。 ラベルにノイズがあったので若干危険 だと思う。。。 偉大な参考資料 - Jackさん「shake-upを科学する」(リンク) 別コンペの上位者がそのコンペの上位にい たら、メタ読みしてしまう。。。 (検証したいがそれはまた別の話で。。。)
所感 • LLMコンペは、(モデルのデカさ) x (モデルの数=推論速度)が重要なファクター ◦ 早めにアンサンブル含めたパイプラインを組んでおくほうがよさそう。 ▪ 推論時間を計測しておく(参考記事←微妙にAPIの仕様変わってた) ◦
そのうえで、いかに単体モデルの精度を伸ばしていけるかと多様性を作れるか、が金圏に入れ るかどうかな印象 • 今回はチームマージがかなり上振れた ◦ モデル設計の方向性がだいぶ違っていたので混ぜ合わせるだけで伸びた ◦ 金圏同士でマージするのが金メダルの近道(←それはそう) • Deberta時代に流行ってた学習手法は結構効いた ◦ monsaraida-sanに感謝🙏
monsaraida
自己紹介 : monsaraida / 宮原 正典 (みやはらまさのり) • 業務 ◦
AIエンジニア ◦ 予測分析ツール開発のPL • 趣味 ◦ Kaggle (完全な業務外活動) ◦ 9歳/5歳の娘達と遊ぶこと https://www.linkedin.com/posts/sony_technology_kaggle-sony-activity-7392463325227315202-TEso https://x.com/monsaraida https://www.sony.com/ja/SonyInfo/DiscoverSony /articles/202412/KaggleMaster/
MAP 3rd place solution : monsaraida 担当部分 [monsaraida-model-2-b] LoRA SFT:
Qwen3-14B SequenceClassification (multi-task) Prompt: base + choices + hints EMA, label smoothing, R-Drop monsaraida’s pipeline 2nd stage (inference on 50% of the test set) [Masaya-model-1] LoRA SFT: Qwen2.5-32B-Instruct CausalLM (Question-wise label pruning) Prompt: base + choices [monsaraida-model-1-a] LoRA SFT: Qwen3-14B SequenceClassification (multi-task) Prompt: base + choices + hints EMA, label smoothing, R-Drop, AWP Private = 0.945 Public = 0.950 CV = 0.949 Private = 0.945 Public = 0.949 CV = 0.948 [Masaya-model-2] QLoRA SFT: Qwen2.5-72B-Instruct quantized with AutoRound (GPTQ) CausalLM (Question-wise label pruning) Prompt: base + choices Private = 0.946 Public = 0.950 Private = 0.944 Public = 0.949 CV = 0.949 [monsaraida-model-2-a] LoRA SFT: Qwen3-14B SequenceClassification (multi-task) Prompt: base + choices + hints EMA, label smoothing, R-Drop Private = 0.944 Public = 0.950 CV = 0.948 [Masaya+monsaraida-model-1] LoRA SFT: Qwen2.5-32B-Instruct CausalLM (Question-wise label pruning) Prompt: base + choices EMA Private = 0.945 Public = 0.951 CV = 0.950 Masaya’s pipeline 1st stage (inference on the entire test set) Final Results Private = 0.948 (3rd) Public = 0.954 (1st) Ensemble https://www.kaggle.com/competitions/map-charting-student-math-misunderstandings/writeups/3rd-place-solution • プロンプトエンジニアリング ◦ 「他の選択肢」や「ヒント」を追加→たっ た数行の変更で効果抜群 • 検証戦略 ◦ (1) fold 0のみ (2) 5 fold平均 (3) 全学習で 複数シード平均 → 過学習を回避 • LoRA SFT マルチタスク学習 ◦ Qwen3-14B LoRA SFT (SeqCls) ◦ メイン65分類+補助2/3/36分類 • 汎化性向上 ◦ R-Drop / AWP → 精度改善 ◦ EMA → CV安定+精度改善 • 多段階推論 ◦ (1) test全体を推論 (2)確信度の低い50% のみ推論 → 推論高速化
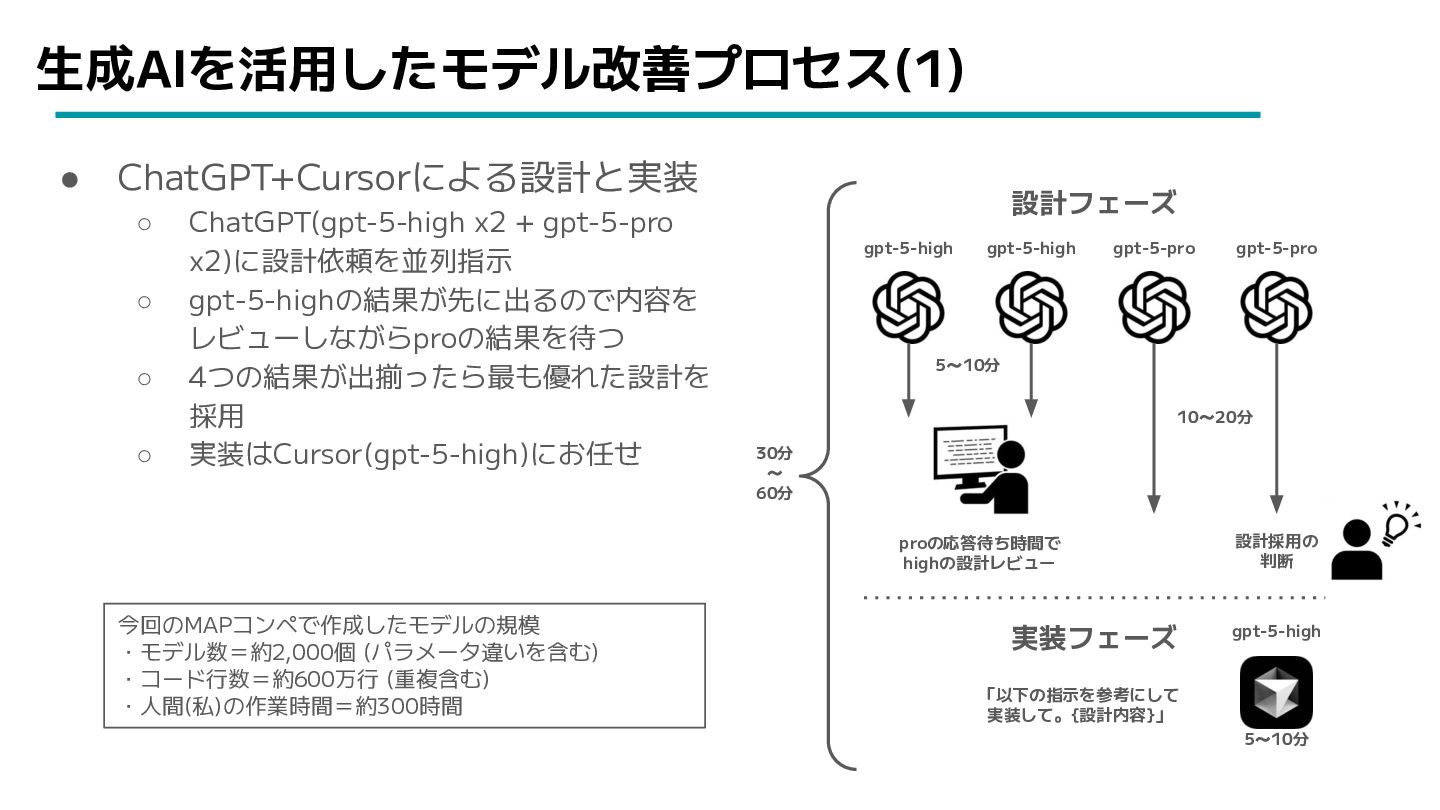
生成AIを活用したモデル改善プロセス(1) • ChatGPT+Cursorによる設計と実装 ◦ ChatGPT(gpt-5-high x2 + gpt-5-pro x2)に設計依頼を並列指示 ◦
gpt-5-highの結果が先に出るので内容を レビューしながらproの結果を待つ ◦ 4つの結果が出揃ったら最も優れた設計を 採用 ◦ 実装はCursor(gpt-5-high)にお任せ gpt-5-high gpt-5-high gpt-5-pro gpt-5-pro 5~10分 10~20分 設計フェーズ 実装フェーズ proの応答待ち時間で highの設計レビュー 設計採用の 判断 「以下の指示を参考にして 実装して。{設計内容}」 gpt-5-high 5~10分 30分 ~ 60分 今回のMAPコンペで作成したモデルの規模 ・モデル数=約2,000個 (パラメータ違いを含む) ・コード行数=約600万行 (重複含む) ・人間(私)の作業時間=約300時間
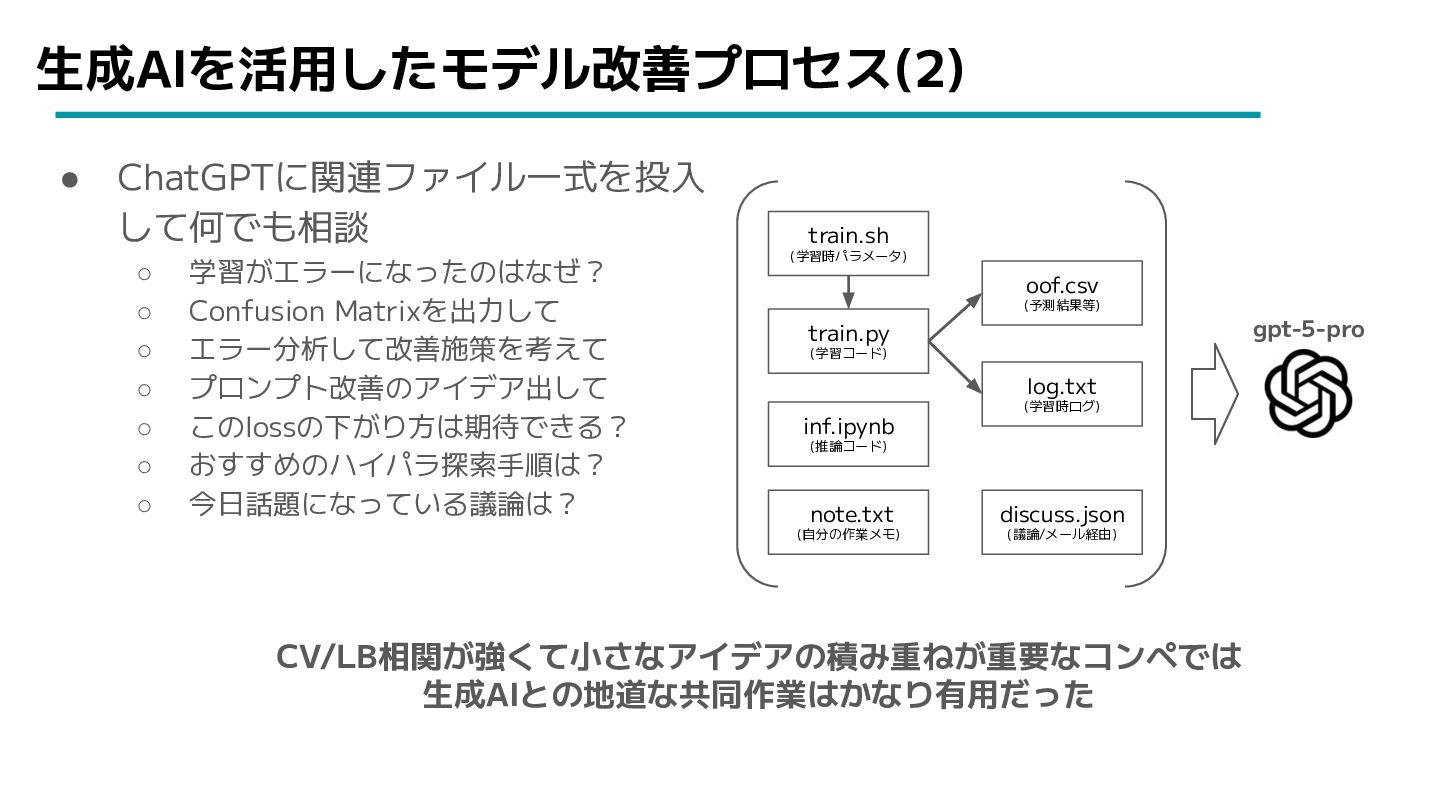
生成AIを活用したモデル改善プロセス(2) • ChatGPTに関連ファイル一式を投入 して何でも相談 ◦ 学習がエラーになったのはなぜ? ◦ Confusion Matrixを出力して ◦
エラー分析して改善施策を考えて ◦ プロンプト改善のアイデア出して ◦ このlossの下がり方は期待できる? ◦ おすすめのハイパラ探索手順は? ◦ 今日話題になっている議論は? train.py (学習コード) oof.csv (予測結果等) log.txt (学習時ログ) discuss.json (議論/メール経由) train.sh (学習時パラメータ) note.txt (自分の作業メモ) inf.ipynb (推論コード) gpt-5-pro CV/LB相関が強くて小さなアイデアの積み重ねが重要なコンペでは 生成AIとの地道な共同作業はかなり有用だった
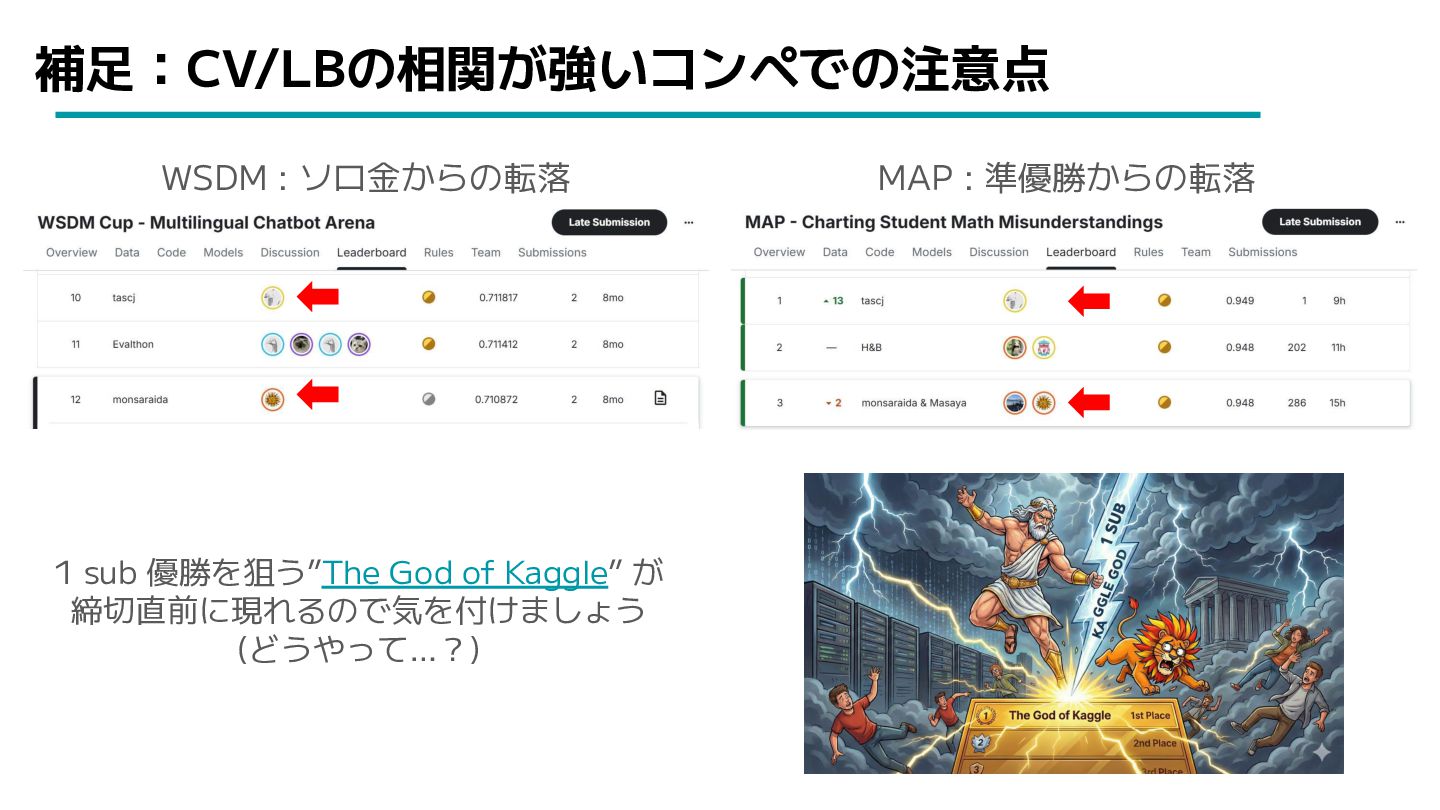
補足:CV/LBの相関が強いコンペでの注意点 WSDM : ソロ金からの転落 MAP : 準優勝からの転落 1 sub 優勝を狙う”The
God of Kaggle” が 締切直前に現れるので気を付けましょう (どうやって…?)
{kind=link}
{kind=link}
{kind=link}
![Overview : 3rd Place [monsaraida-model-2-b] LoRA SFT: Qwen3-14B SequenceClassification (multi-task)](https://files.speakerdeck.com/presentations/fbf31d21fed049cf805ed710b29d12b8/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MAP 3rd place solution : monsaraida 担当部分 [monsaraida-model-2-b] LoRA SFT:](https://files.speakerdeck.com/presentations/fbf31d21fed049cf805ed710b29d12b8/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}