Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ベクトルデータベースあれこれ ~RAGのために~
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
murakami0923
July 15, 2025
24
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ベクトルデータベースあれこれ ~RAGのために~
murakami0923
July 15, 2025
More Decks by murakami0923
See All by murakami0923
会議の議事録作成を省力化したい
murakami0923
0
39
2022/10/21 bitstar CROSS 2022 in EZO AWS ECSでのバックエンドの開発について
murakami0923
0
120
2022/08/06 JavaDo n+1問題に気を付けよう
murakami0923
0
380
Featured
See All Featured
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
Faster Mobile Websites
deanohume
310
32k
Test your architecture with Archunit
thirion
1
2.3k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
250
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
Mobile First: as difficult as doing things right
swwweet
225
10k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Speed Design
sergeychernyshev
33
1.9k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Building AI with AI
inesmontani
PRO
1
1.1k
Transcript
© 2025 Masashi Murakami All Right Reserved. 1 ベクトルデータベースあれこれ ~RAGのために~
2025/07/11 村上 將志
© 2025 Masashi Murakami All Right Reserved. 2 ベクトルデータベースって?
© 2025 Masashi Murakami All Right Reserved. 3 ベクトルデータベースって? 定義:情報を数値の配列(ベクトル)として保存するデータベースです。従来のデータベースが文
字や数字をそのまま保存するのに対し、意味や特徴を数値化して保存します。 できること:文章、画像、音声などの類似性を高速で検索できます。「この商品に似た商品を探 す」「この質問と関連する情報を見つける」といった、「意味的な近さ」での検索が可能です。 活用例:ECサイトでの類似商品表示、検索エンジンでの質問意図理解、ユーザー好みに基づく推薦 システム、AIチャットボットでの関連情報検索、RAG(AIが関連文書を検索して最新情報で回答生 成)など。AIと組み合わせることで、より賢い検索や推薦を実現する重要な技術です。 by Claude.ai
© 2025 Masashi Murakami All Right Reserved. 4 そもそも、RAGって? RAGは、Retrieval-Augmented
Generationの略で、「検索拡張生成」と略されます。 RAGは、AI が質問に答える際に、事前に用意されたデータベースから関連情報を検索し、その情報 を参考にして回答を生成する技術です。 RAGを使うことで、AIは最新の企業情報や専門知識を正確に反映した回答ができるようになりま す。また、根拠となる情報源を示せるため、信頼性の高い対話が可能です。 活用例として、社内FAQ システムがあります。従業員が「有給申請の方法は?」と質問すると、 RAGシステムが社内規定から該当部分を検索し、最新のルールに基づいて正確な手続きを案内しま す。他にも、カスタマーサポート、医療相談、法律相談など、専門知識が必要な分野で広く活用さ れています。RAGにより、AIがより実用的で信頼できるアシスタントとして機能します。 by Claude.ai
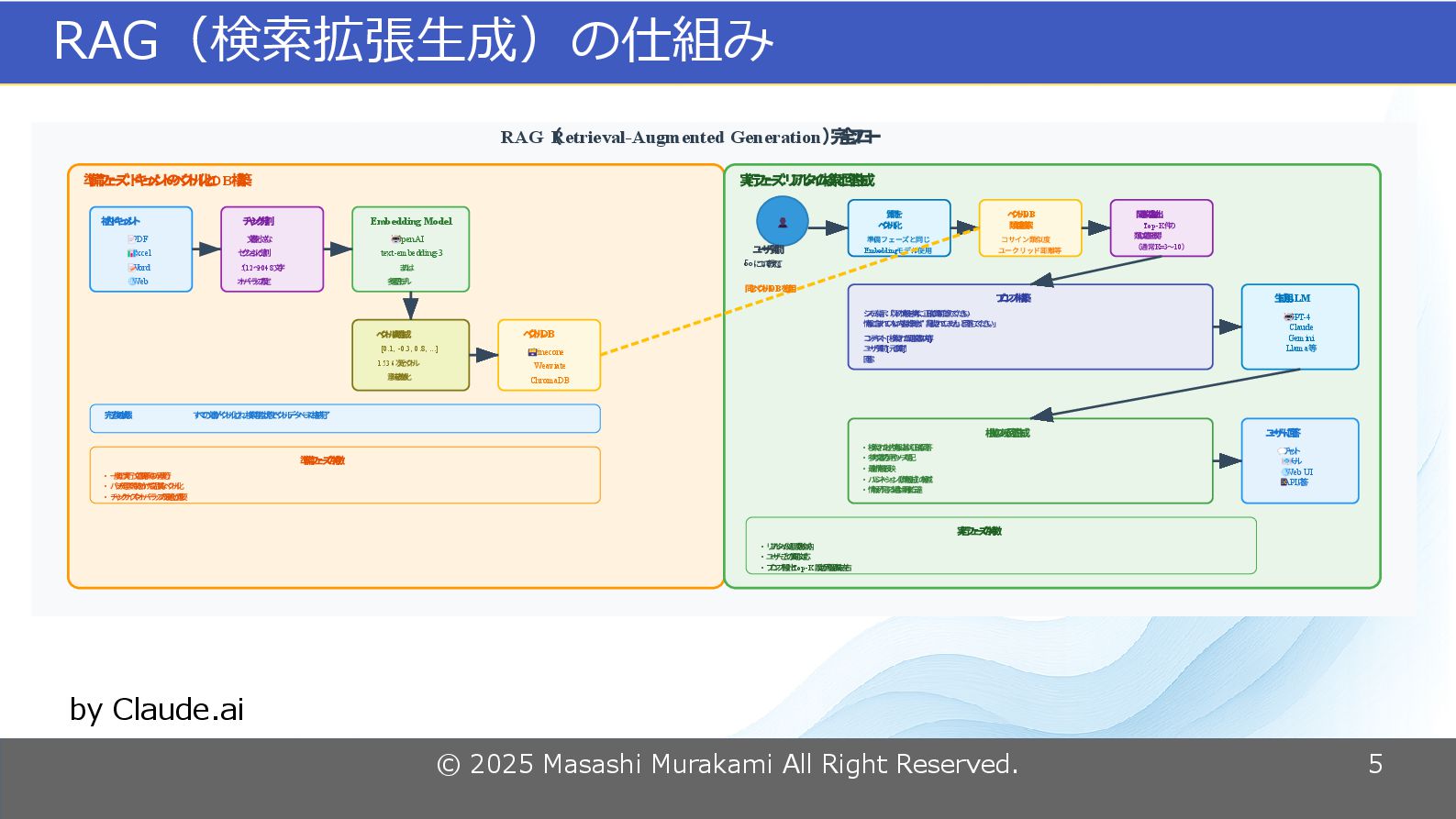
© 2025 Masashi Murakami All Right Reserved. 5 RAG(検索拡張生成)の仕組み RAG
Retrieval-Augmented Generation ( ) 完 全 フ ロ ー DB 準 備 フ ェ ー ズ : ド キ ュ メ ン ト の ベ ク ト ル 化 と 構 築 社 内 ド キ ュ メ ン ト PDF 📄 Excel 📊 Word 📝 Web 🌐 チ ャ ン ク 分 割 文 書 を 小 さ な セ ク シ ョ ン に 分 割 512 2048 ( 〜 文 字 ) オ ー バ ー ラ ッ プ 設 定 Embedding Model OpenAI 🤖 text-embedding-3 ま た は 多 言 語 モ デ ル ベ ク ト ル 表 現 生 成 [0.1, -0.3, 0.8, ...] 1536 次 元 ベ ク ト ル 意 味 を 数 値 化 DB ベ ク ト ル Pinecone 🗃️ Weaviate ChromaDB : 完 了 後 の 状 態 す べ て の 文 書 が ベ ク ト ル 化 さ れ 、 検 索 可 能 な 状 態 で ベ ク ト ル デ ー タ ベ ー ス に 格 納 完 了 準 備 フ ェ ー ズ の 特 徴 • 一 度 だ け 実 行 ( 文 書 更 新 時 の み 再 実 行 ) • バ ッ チ 処 理 で 時 間 を か け て 高 品 質 な ベ ク ト ル 化 • チ ャ ン ク サ イ ズ や オ ー バ ー ラ ッ プ の 最 適 化 が 重 要 実 行 フ ェ ー ズ : リ ア ル タ イ ム 検 索 と 回 答 生 成 👤 ユ ー ザ ー 質 問 ◦◦ 「 に つ い て 教 え て 」 質 問 を ベ ク ト ル 化 準備フェーズと同じ Embedding モデル使用 DB ベ ク ト ル 類 似 度 検 索 コサイン類似度 ユークリッド距離等 関 連 文 書 抽 出 Top-K 件 の 類 似 文 書 を 取 得 K=3 10 (通常 〜 ) プ ロ ン プ ト 構 築 シ ス テ ム 指 示 : 「 以 下 の 情 報 を 参 考 に 、 正 確 に 質 問 に 答 え て く だ さ い 。 情 報 に 含 ま れ て い な い 内 容 は 推 測 せ ず 、 『 記 載 さ れ て い ま せ ん 』 と 回 答 し て く だ さ い 。 」 [ ] コ ン テ キ ス ト :検 索 さ れ た 関 連 文 書 の 内 容 [ ] ユ ー ザ ー 質 問 :元 の 質 問 回 答 : LLM 生 成 用 GPT-4 🤖 Claude Gemini Llama 等 根 拠 の あ る 回 答 生 成 • 検 索 さ れ た 社 内 情 報 に 基 づ く 正 確 な 回 答 • 参 考 文 書 の 引 用 や ソ ー ス 明 記 • 最 新 情 報 を 反 映 • ハ ル シ ネ ー シ ョ ン ( 誤 情 報 生 成 ) の 軽 減 • 情 報 が 不 足 す る 場 合 は 明 確 に 伝 達 ユ ー ザ ー に 回 答 チ ャ ッ ト 💬 メ ー ル 📧 Web UI 🌐 API 応 答 📱 実 行 フ ェ ー ズ の 特 徴 • リ ア ル タ イ ム 処 理 ( 数 秒 以 内 ) • ユ ー ザ ー ご と の 質 問 に 対 応 • Top-K プ ロ ン プ ト 設 計 と 設 定 が 回 答 品 質 を 左 右 DB 同 じ ベ ク ト ル を 使 用 by Claude.ai
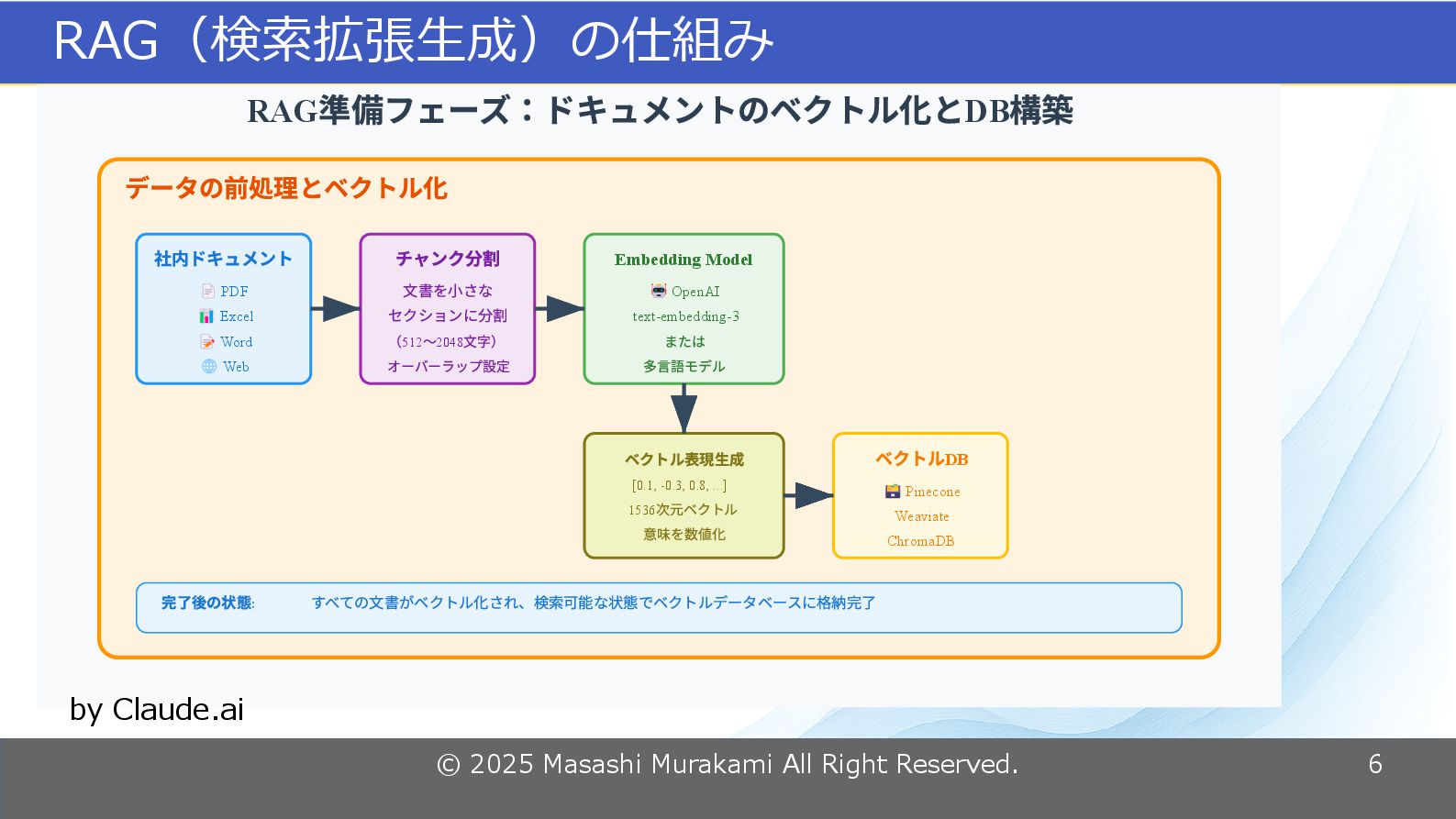
© 2025 Masashi Murakami All Right Reserved. 6 RAG(検索拡張生成)の仕組み RAG
DB 準備フェーズ:ドキュメントのベクトル化と 構築 データの前処理とベクトル化 社内ドキュメント PDF 📄 Excel 📊 Word 📝 Web 🌐 チャンク分割 文書を小さな セクションに分割 512 2048 ( 〜 文字) オーバーラップ設定 Embedding Model OpenAI 🤖 text-embedding-3 または 多言語モデル ベクトル表現生成 [0.1, -0.3, 0.8, ...] 1536 次元ベクトル 意味を数値化 DB ベクトル Pinecone 🗃️ Weaviate ChromaDB : 完了後の状態 すべての文書がベクトル化され、検索可能な状態でベクトルデータベースに格納完了 by Claude.ai
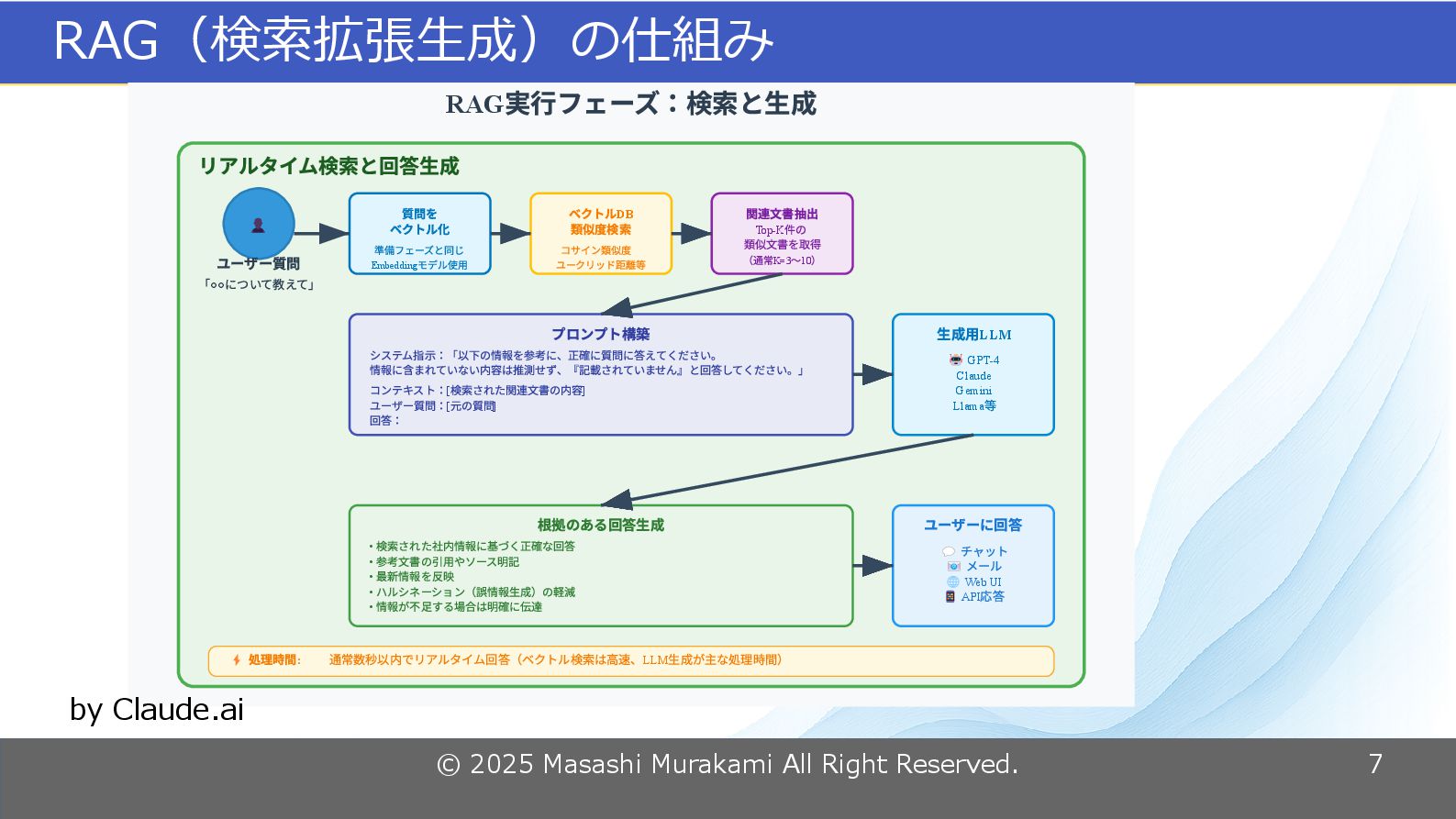
© 2025 Masashi Murakami All Right Reserved. 7 RAG(検索拡張生成)の仕組み RAG
実行フェーズ:検索と生成 リアルタイム検索と回答生成 👤 ユーザー質問 ◦◦ 「 について教えて」 質問を ベクトル化 準備フェーズと同じ Embedding モデル使用 DB ベクトル 類似度検索 コサイン類似度 ユークリッド距離等 関連文書抽出 Top-K 件の 類似文書を取得 K=3 10 (通常 〜 ) プロンプト構築 システム指示:「以下の情報を参考に、正確に質問に答えてください。 情報に含まれていない内容は推測せず、『記載されていません』と回答してください。」 [ ] コンテキスト: 検索された関連文書の内容 [ ] ユーザー質問: 元の質問 回答: LLM 生成用 GPT-4 🤖 Claude Gemini Llama 等 根拠のある回答生成 • 検索された社内情報に基づく正確な回答 • 参考文書の引用やソース明記 • 最新情報を反映 • ハルシネーション(誤情報生成)の軽減 • 情報が不足する場合は明確に伝達 ユーザーに回答 チャット 💬 メール 📧 Web UI 🌐 API 応答 📱 : 処理時間 ⚡ LLM 通常数秒以内でリアルタイム回答(ベクトル検索は高速、 生成が主な処理時間) by Claude.ai
© 2025 Masashi Murakami All Right Reserved. 8 各ベクトルデータベースと利用方法調査
© 2025 Masashi Murakami All Right Reserved. 9 ベクトルデータベースの選択肢 オープンソースのベクトルデータベースとして、下記を比較します。
• Chroma • MySQL • Elasticsearch • Apache Solr • pgvector
© 2025 Masashi Murakami All Right Reserved. 10 利用方法調査 データベースに複数の文字列を登録し、キーワードで検索して類似性の高いデータを取得するため
のプログラムをJupyter Notebookの形式で作成します。 主に行う処理は、 • 埋め込みモデル(Embeddings)の定義 • 文字列を埋め込みモデルでベクトル化し、元の文字列とともにデータベースへ登録 • キーワードと件数を指定して検索し、類似性の高い情報から並べて表示 – ※RDBMSでいう、 SELECT * FROM *** WHERE *** LIKE ‘%キーワード%’ LIMIT 2; (キーワードを含む(近い)データを2件取得する 的な検索ができるか? とします。
© 2025 Masashi Murakami All Right Reserved. 11 利用方法調査 RAG構築調査のためのDocker環境定義、Jupyter
Notebookファイルなどを https://github.com/murakami0923/llm-rag-examples/tree/develop に入れてあります。 ※現在、「develop」ブランチで作成中
© 2025 Masashi Murakami All Right Reserved. 12 Chroma
© 2025 Masashi Murakami All Right Reserved. 13 Chroma •
LLMを扱うアプリケーション向けにカスタマイズされた、オープンソースのベクトルデータ ベースです。 • ライセンスは、Apache License 2.0です。 • LangChain、LangGraph等でRAGを構築するなどのハンズオンでも、Chromaが使われること が多いです。
© 2025 Masashi Murakami All Right Reserved. 14 Chroma サンプル:chromadb-ex01.ipynb
特徴: • 特にサーバ等を用意することなく、簡単に利用できます。 • ベクトルデータベースは、サンプルではメモリ上に展開されます。 – ※永続化も可能なようですが、まだ試していません。 • 検索の際、取得するデータの数を指定できます。 – ※スコア値の高いものから順に取得できます。
© 2025 Masashi Murakami All Right Reserved. 15 MySQL
© 2025 Masashi Murakami All Right Reserved. 16 MySQL •
オープンソースのRDBMSです。 • ライセンスは、GPL v2または商用ライセンスです。 • MySQL 9.0で、「VECTOR」型がサポートされ、ベクトルデータを扱うことができるようにな りました。
© 2025 Masashi Murakami All Right Reserved. 17 MySQL サンプル:
• テーブル定義:init-db.sql • 登録処理:mysql9-vector-ex01-01-insert.ipynb • 検索処理:mysql9-vector-ex01-02-search.ipynb 特徴: • ドキュメントの文字列を埋め込みモデルでベクトル化し、元の文字列とともにinsertします。 • 検索の際は全レコードを検索する必要があります。 – 検索キーワードのベクトル化、および、検索キーワードとドキュメントの文字列の類似性 はDB自体の機能にはないため。 – MySQL HeatWaveでは、DBの機能でベクトル化がサポートされているため、検索の際に ソートして任意の数を取得できるようです。
© 2025 Masashi Murakami All Right Reserved. 18 Elasticsearch
© 2025 Masashi Murakami All Right Reserved. 19 Elasticsearch •
Elastic社が開発している、分散マルチテナント対応検索エンジンです。 • ライセンスは、8.16以降はAGPLv3下で利用できるオープンソース、あるいは、商用ライセン スから選択します。 – 以前はソースアベイラブル・ソフトウェアだった経緯もあり、ライセンスの扱いが流動的 です。 • Elasticsearch 8.0以降でベクトル検索がサポートされ、その後改良が行われ、オプションや検 索クエリの書き方が追加されてきました。
© 2025 Masashi Murakami All Right Reserved. 20 Elasticsearch(REST API)
サンプル: • 登録処理:elasticsearch-vector-ex01-01-request-insert.ipynb • 検索処理:elasticsearch-vector-ex01-02-request-search.ipynb 特徴: • Elasticsearchクライアントもありますが、Elasticsearchバージョンアップ後にクライアントの対 応まで時間がかかることがあり、REST APIでの操作を推奨する旨、サポートやコミュニティで 議論されているようなので、こちらではREST APIをrequestで操作しています。 • ドキュメントの文字列を埋め込みモデルでベクトル化し、元の文字列とともにインデックスし ます。 • 検索の際、取得するデータの数を指定できます。 – ※k近傍法で類似性の高いものから順に取得できます。
© 2025 Masashi Murakami All Right Reserved. 21 Elasticsearch(Elasticsearchクライアント) サンプル:
• 登録処理:elasticsearch-vector-ex02-01-es-client-insert.ipynb • 検索処理:elasticsearch-vector-ex02-02-es-client-search.ipynb 特徴: • Elasticsearchおよびクライアントのバージョンを 8.18.0 で統一し、前述のREST APIで行った のと同じ処理を、クライアントライブラリで操作しています。 • ドキュメントの文字列を埋め込みモデルでベクトル化し、元の文字列とともにインデックスし ます。 • 検索の際、取得するデータの数を指定できます。 – ※k近傍法で類似性の高いものから順に取得できます。
© 2025 Masashi Murakami All Right Reserved. 22 Apache Solr
© 2025 Masashi Murakami All Right Reserved. 23 Apache Solr
• Apacheソフトウェア財団が開発している、全文検索エンジンです。 • ライセンスは、Apache License 2.0です。 • Solr 9からベクトル検索機能が導入されました。
© 2025 Masashi Murakami All Right Reserved. 24 Apache Solr
サンプル: • 前処理:solr-vector-ex01-00-prepare.ipynb • 登録処理:solr-vector-ex01-01-insert.ipynb • 検索処理:solr-vector-ex01-02-search.ipynb 特徴: • 前処理として、コア、コレクションを作成し、スキーマ設定(フィールド追加)をします。 – フィールド追加時、使用するEmbeddingに応じて、次元数を指定する必要があります。 • ドキュメントの文字列を埋め込みモデルでベクトル化し、元の文字列とともにインデックスし ます。 • 検索の際、取得するデータの数を指定できます。 – ※k近傍法で類似性の高いものから順に取得できます。
© 2025 Masashi Murakami All Right Reserved. 25 pgvector
© 2025 Masashi Murakami All Right Reserved. 26 pgvector •
ベクトルデータの類似性検索機能を提供するPostgreSQLの拡張機能 • ライセンスは、The PostgreSQL License(独自のオープンソースライセンス)です。 – BSDやMITに似たライセンスのようです。
© 2025 Masashi Murakami All Right Reserved. 27 Apache Solr
サンプル: • 登録処理:pgvector-ex01-1-insert.ipynb • 検索処理:pgvector-ex01-2-search.ipynb 特徴: • ドキュメントの文字列を埋め込みモデルでベクトル化し、元の文字列とともにinsertします。 • 検索の際、 – embedding <-> %s::vector で、データのベクトルと検索キーワードのベクトルのコサイン距離を算出できます。 (%sの部分に検索キーワードをEmbeddingでベクトル化したものを渡します) • この値でソートすることで、近いものから順に取得できます。 – 取得するデータの数を指定できます。
© 2025 Masashi Murakami All Right Reserved. 28 さいごに
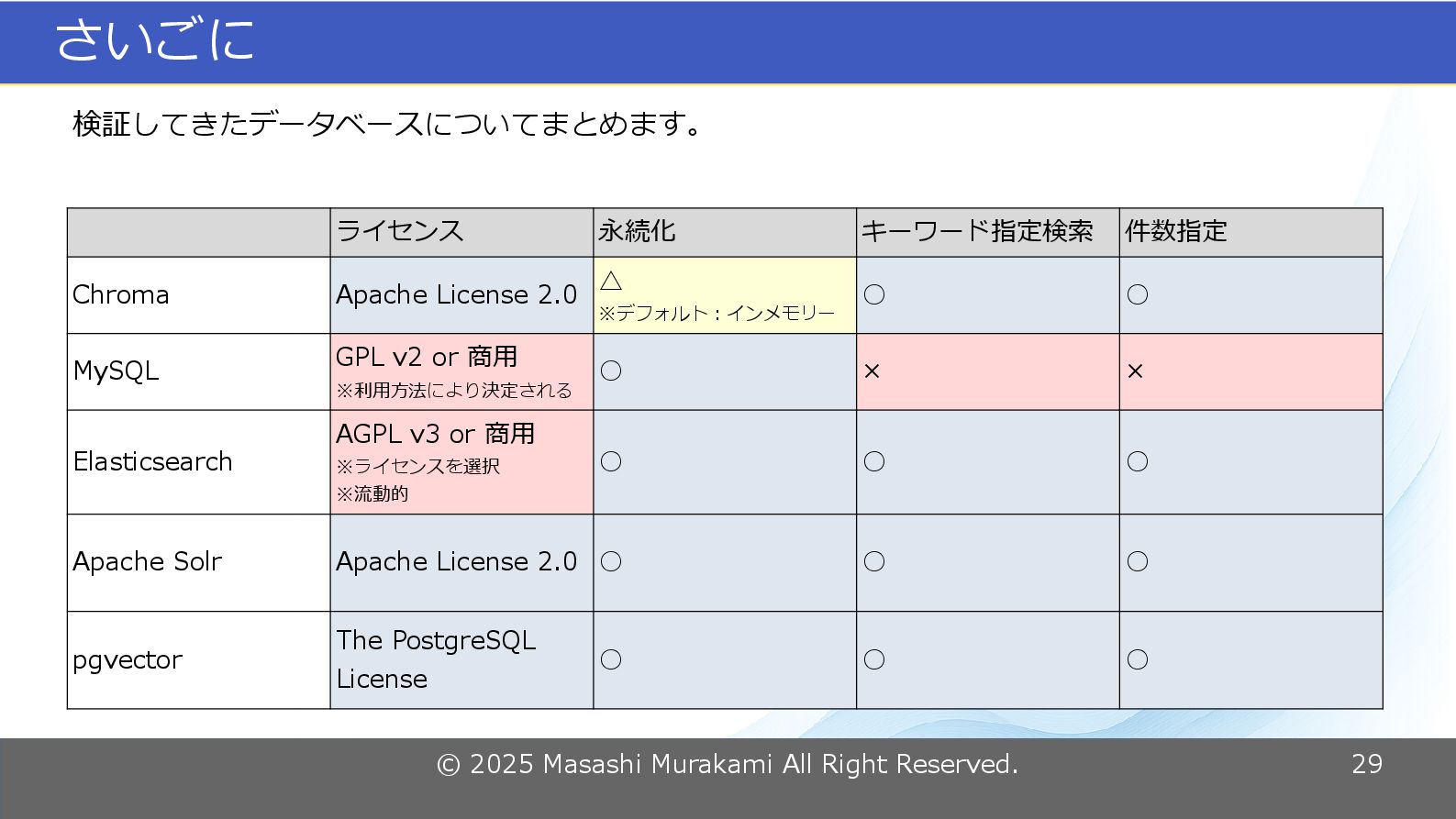
© 2025 Masashi Murakami All Right Reserved. 29 さいごに 検証してきたデータベースについてまとめます。
ライセンス 永続化 キーワード指定検索 件数指定 Chroma Apache License 2.0 △ ※デフォルト:インメモリー ◦ ◦ MySQL GPL v2 or 商用 ※利用方法により決定される ◦ × × Elasticsearch AGPL v3 or 商用 ※ライセンスを選択 ※流動的 ◦ ◦ ◦ Apache Solr Apache License 2.0 ◦ ◦ ◦ pgvector The PostgreSQL License ◦ ◦ ◦
© 2025 Masashi Murakami All Right Reserved. 30 今後挑戦したいこと •
BacklogのWikiページ等にある社内のドキュメントのデータベース化を試みます。 • ドキュメントをチャンクに分割し、検索精度の向上を試みます。 – どのように分割するか(改行の連続?句読点?)など、試行錯誤が必要だと考えます。 • ローカルのLLM(Ollama)あるいは外部LLMと連携し、LangChain、LangGraph等を用いて RAGの構築を試みます。 • 2025年に入って、RAGだけじゃなくて、CAGなんていう物も出てきたらしいので、試しry)
© 2025 Masashi Murakami All Right Reserved. 31 ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}