Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
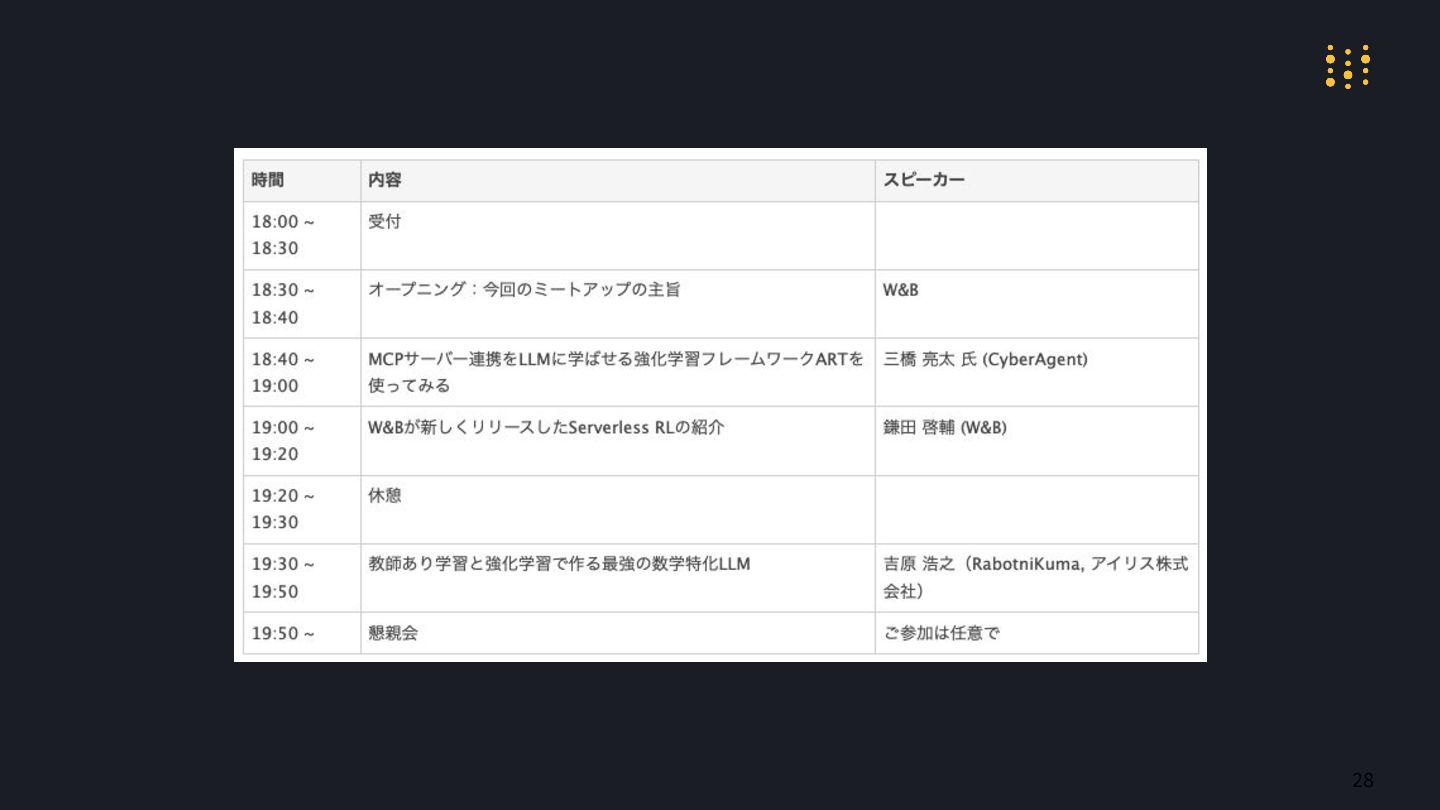
W&Bが新しくリリースしたServerless RLの紹介 (W&B 鎌田啓輔)
Search
Keisuke Kamata
December 02, 2025
370
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
W&Bが新しくリリースしたServerless RLの紹介 (W&B 鎌田啓輔)
Keisuke Kamata
December 02, 2025
More Decks by Keisuke Kamata
See All by Keisuke Kamata
Physical AIを支えるWeights & Biases
olachinkei
1
440
W_Bハッカソン説明会202602.pdf
olachinkei
0
520
MCPサーバー連携をLLMに学ばせる強化学習フレームワークARTを使ってみる (CyberAgent 三橋 亮太)
olachinkei
1
540
WeaveでMCPを記録する & W&BのMCP
olachinkei
1
340
LLMアプリケーションの品質担保に向けた プラクティスと LLMオブザーバビリティツール
olachinkei
1
330
生成AI開発を加速するNVIDIA NIMとNVIDIA NeMo
olachinkei
2
1.4k
Weaveを用いた生成AIアプリケーションの評価_モニタリンングと実践例.pdf
olachinkei
2
640
20240917_wandb_Monthly_meetup_TIS
olachinkei
0
650
Nejumi Leaderboard release 20240702
olachinkei
1
440
Featured
See All Featured
How STYLIGHT went responsive
nonsquared
100
6.2k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
780
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
980
Writing Fast Ruby
sferik
630
63k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
260
Unsuck your backbone
ammeep
672
58k
Navigating Weather and Climate Data
rabernat
0
430
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
470
Transcript
W&B Training (Serverless RL)
2 • Deep Learning / 生成AI • ヘルスケア / タンパク質言語モデル
• 動物実験 • 生体信号処理 • 因果推論 • オフラインABテスト Keisuke Kamata • 機械学習 • ヘルスケア/コロナ対策 @olachinkei 工学部・情報学研究科 Engagement Manager Lead Data Scientist Healthcare team lead Manager, AI Solution Engineer 最近の生成 AI周りの活動 • Nejumi Leaderboardの開発 • BioNeMo2 Contributor • 日本語wandbot開発 / 社内エージェント開発中 • … ブログ・ホワイトペーパーなど • W&B生成AIホワイトペーパー • AI Agent評価ブログ • 人手評価と自動評価の比較 with いちから • MCPブログ • GENIAC評価ガイド作成 • …
3 LLM開発における強化学習 (RL)の進化とオンザジョブ RLの重要性 • RLの手法は急速に発展し、LLMの人間の意図に沿った振る舞いの調整(PPO, DPOなど)から、高度な推論能力の獲得 (GRPOなど)を実現してきた • それでも「汎用モデル」と、企業が求める「実務要件」の間にはギャップがある。
• 企業固有のタスクに合わせてモデルを再調整するためにSFTをしたいが十分なデータがないケースが多いそのギャップを 埋める期待をされているのが「オンザジョブRL」
4 日本での関心 & PPOからGRPOまでキャッチアップしたい方に https://note.com/olachin/n/n9706c13c8678
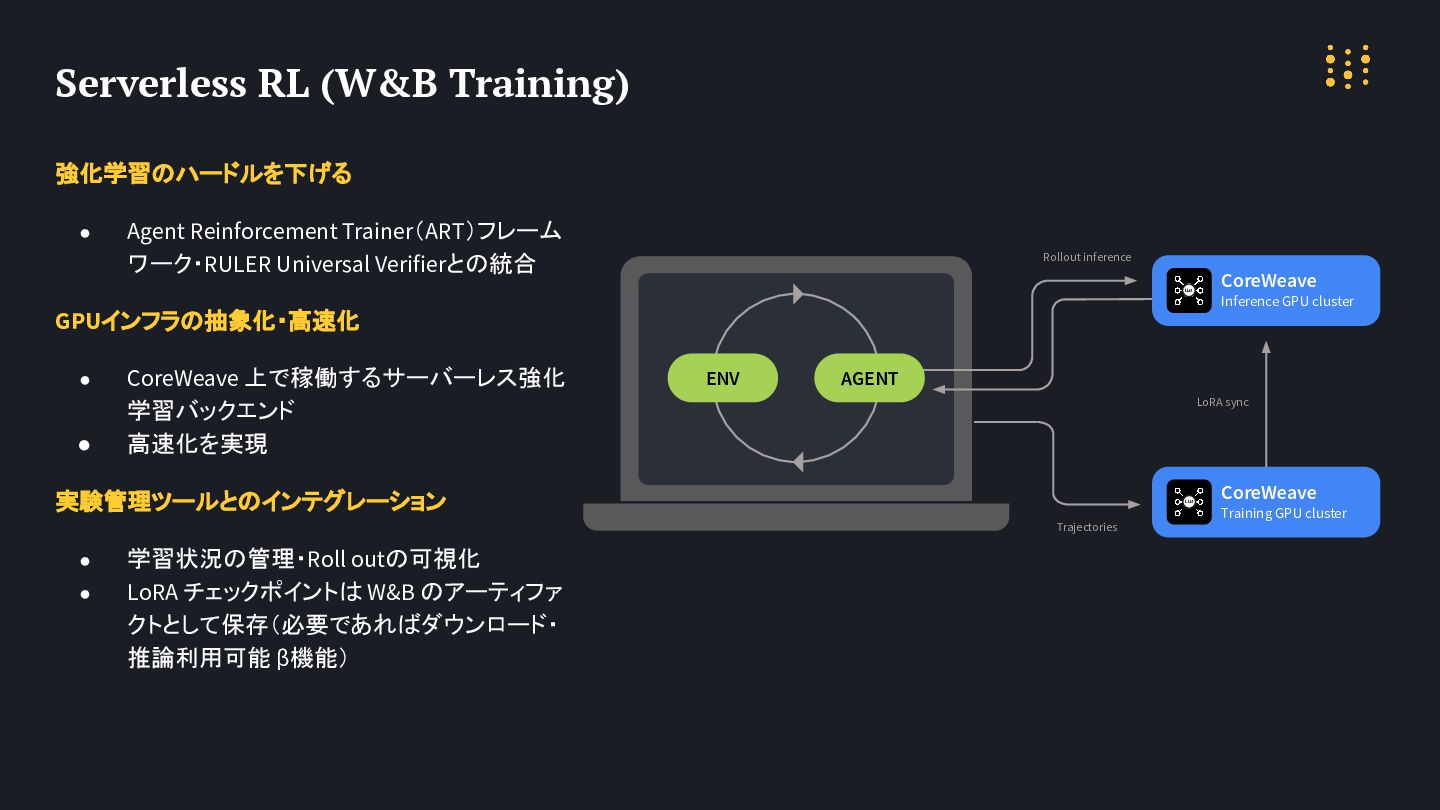
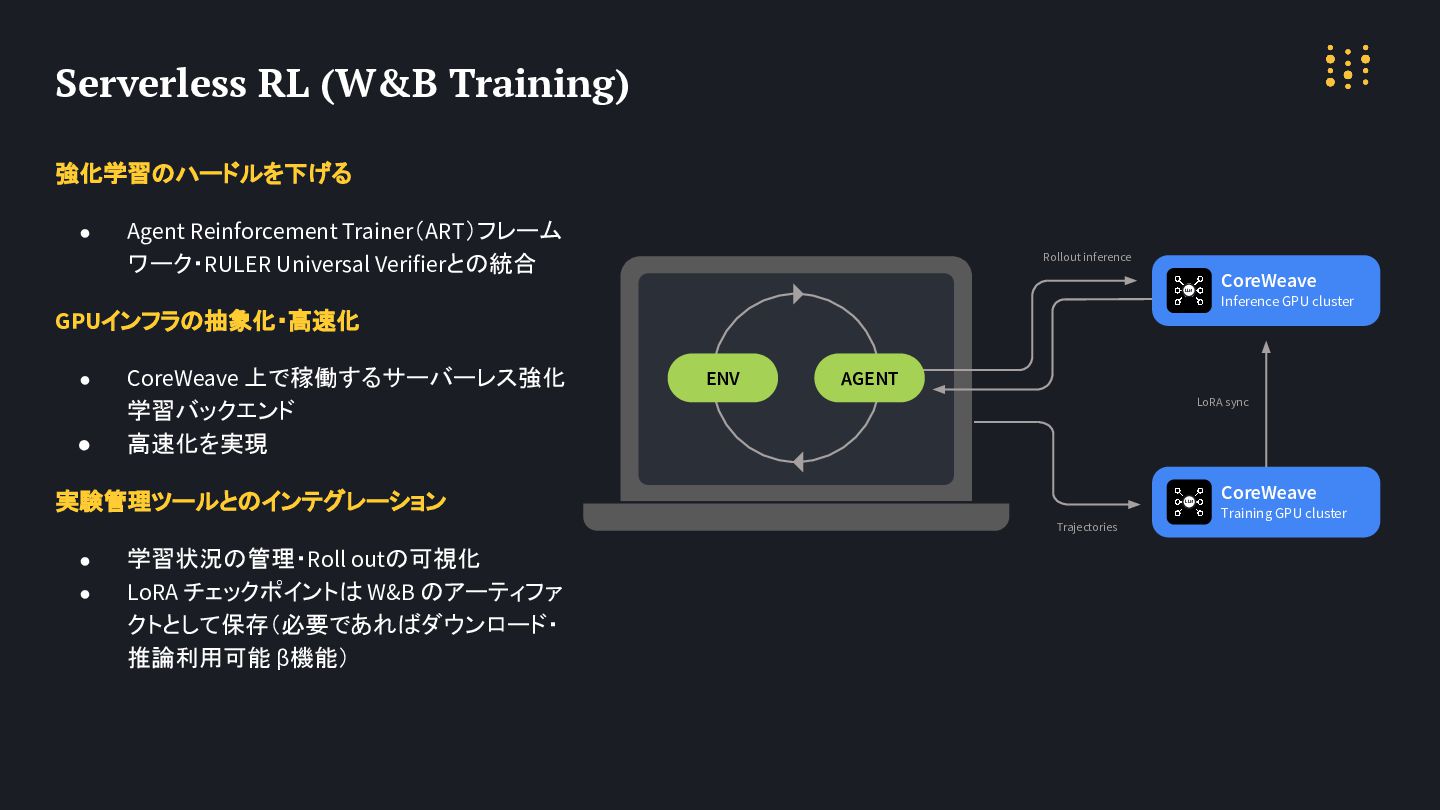
強化学習のハードルを下げる • Agent Reinforcement Trainer(ART)フレーム ワーク・RULER Universal Verifierとの統合 GPUインフラの抽象化・高速化 •
CoreWeave 上で稼働するサーバーレス強化 学習バックエンド • 高速化を実現 実験管理ツールとのインテグレーション • 学習状況の管理・Roll outの可視化 • LoRA チェックポイントは W&B のアーティファ クトとして保存(必要であればダウンロード・ 推論利用可能 β機能) Serverless RL (W&B Training) CoreWeave Inference GPU cluster CoreWeave Training GPU cluster Rollout inference Trajectories ENV LoRA sync AGENT LLM LLM
6 ARTとは • マルチターン対応 ◦ エージェント型のワークフローに最適化された設計 • フロントエンド/バックエンド分離 ◦ 既存コードベースへの統合が容易で、将来的には分散デ
プロイも可能 • OpenAI互換 ◦ 既存の推論コードをそのまま活用可能 • 効率的なメモリ使用 ◦ KVキャッシュのCPUオフロードにより、7BモデルをGoogle Colab無料枠でもトレーニング可能なレベルに LLMを強化学習でトレーニングする フレームワーク(HuggingFaceの GRPOTrainerやverlなど)の課題 • シングルターン想定 • マルチターンロールアウト対応後の エージェントトレーニング中の低い GPU使用率 • 既存コードベースとの統合 • LLM エージェントを GRPO(将来は PPO ・GSPOなども追加予定)で 手軽に強化学習 • 対応モデル: OpenPipe Qwen3 14B Instruct • 推論には vLLM、学習には TRL + Unsloth* を採用 (LoRAベース) *LoRA・QLoRAを “少ないメモリで高速化する ” ための最適化フレームワーク
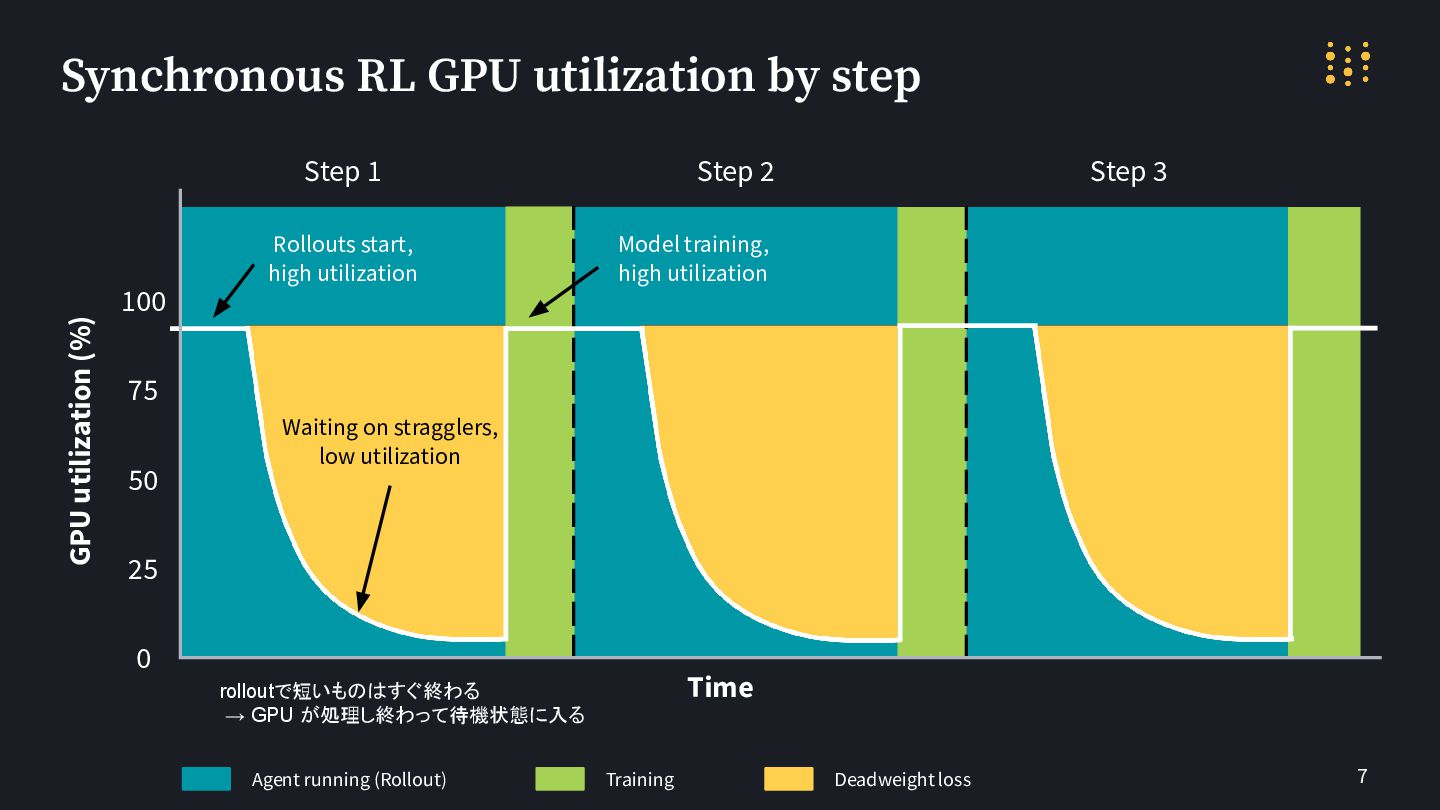
7 Step 1 Step 2 Step 3 Agent running (Rollout)
Training Deadweight loss Time GPU utilization (%) 100 75 50 25 0 Waiting on stragglers, low utilization Model training, high utilization Rollouts start, high utilization Synchronous RL GPU utilization by step rolloutで短いものはすぐ終わる → GPU が処理し終わって待機状態に入る
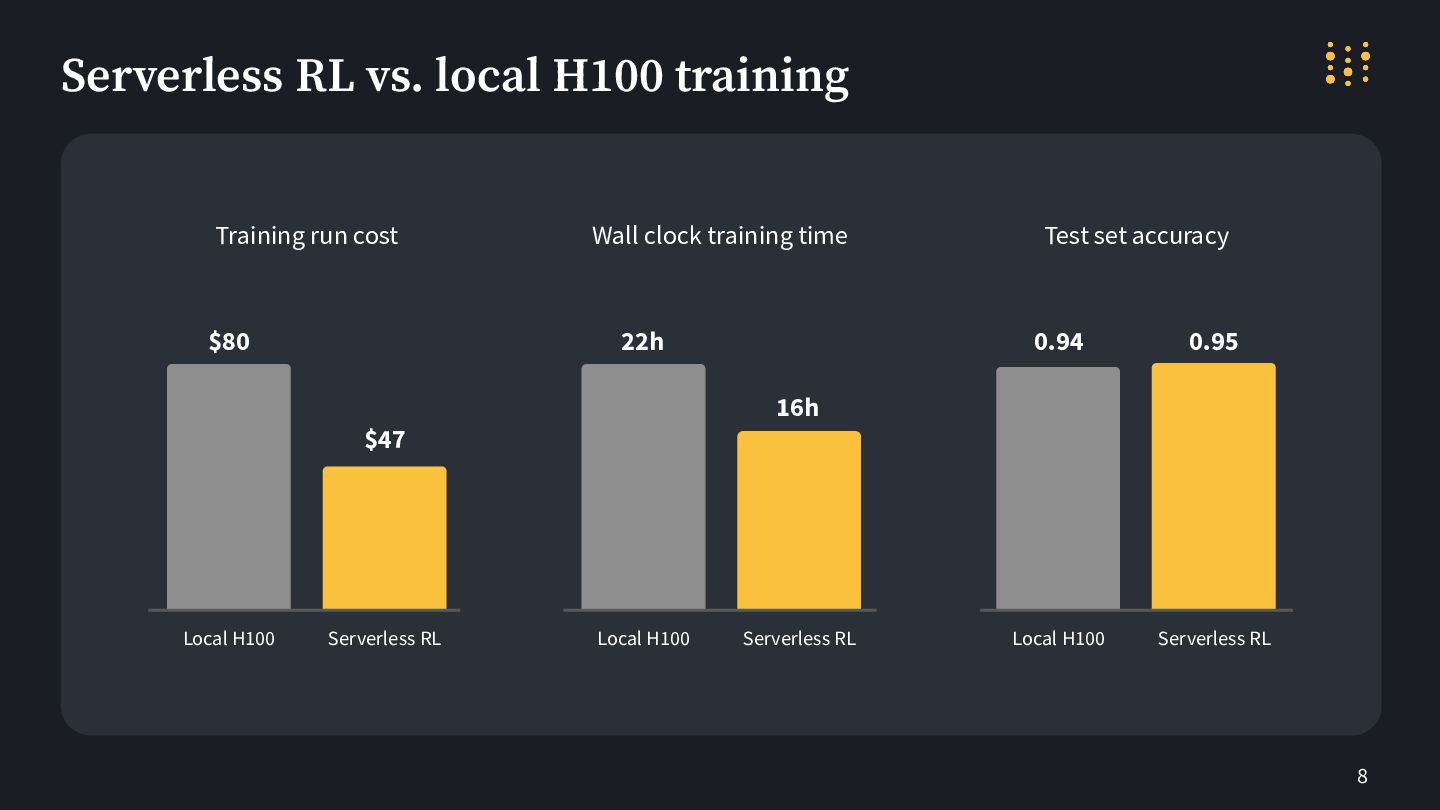
8 Serverless RL vs. local H100 training Local H100 $47
Serverless RL Local H100 Serverless RL Local H100 Serverless RL Training run cost Wall clock training time Test set accuracy $80 16h 22h 0.94 0.95
9 RULERとは • LLM が複数の軌跡を相対評価してスコアを生成する汎用的な報酬関数(プロンプトで設計) • ラベル不要・手作業の報酬設計不要・人手フィードバック不要 • ある入力について N
個の軌跡(trajectory) を 生成 • 共通部分を除いて LLM-as-judge にまとめて 提示 • LLM が 0〜1 で相対スコア を返す • そのスコアを GRPO に渡して学習 • 繰り返す 1. 絶対評価よりランキング評価の方がLLMが 得意 → 個別スコアより安定し、失敗点を発見しや すい 2. GRPO が相対スコアだけ使う → グループ間のスコア基準のズレ問題を無 視できる → キャリブレーション不要でロバスト Script: https://github.com/OpenPipe/ART/blob/f872cc33fb670f92677dece8a84eb5fe6751b281/src/art/rewards/ruler.py How it works メリット
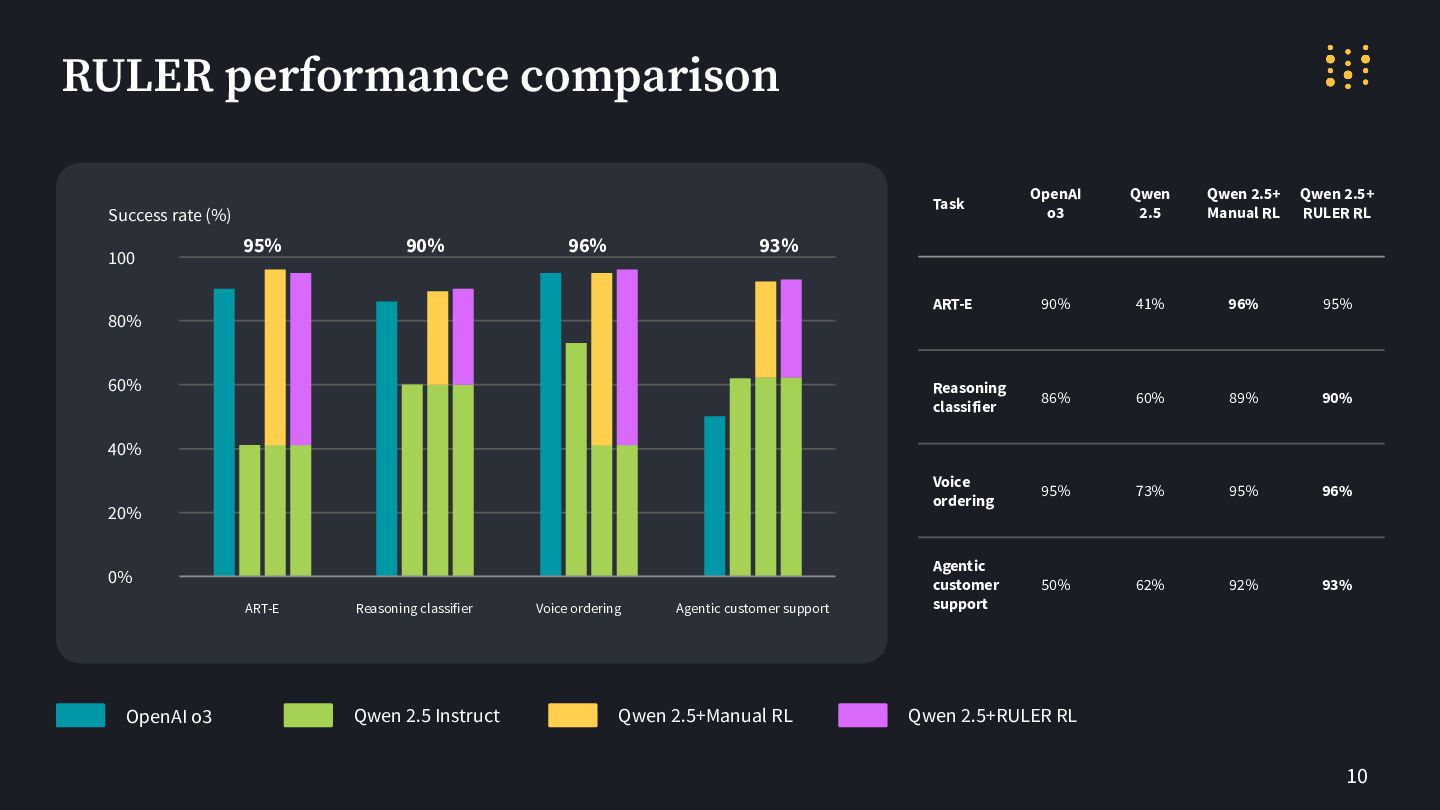
10 RULER performance comparison OpenAI o3 Qwen 2.5 Instruct Qwen
2.5+Manual RL Qwen 2.5+RULER RL Task OpenAI o3 Qwen 2.5 Qwen 2.5+ Manual RL Qwen 2.5+ RULER RL ART-E 90% 41% 96% 95% Reasoning classifier 86% 60% 89% 90% Voice ordering 95% 73% 95% 96% Agentic customer support 50% 62% 92% 93% ART-E Success rate (%) 95% Reasoning classifier Voice ordering Agentic customer support 100 0% 20% 40% 60% 80% 90% 96% 93%
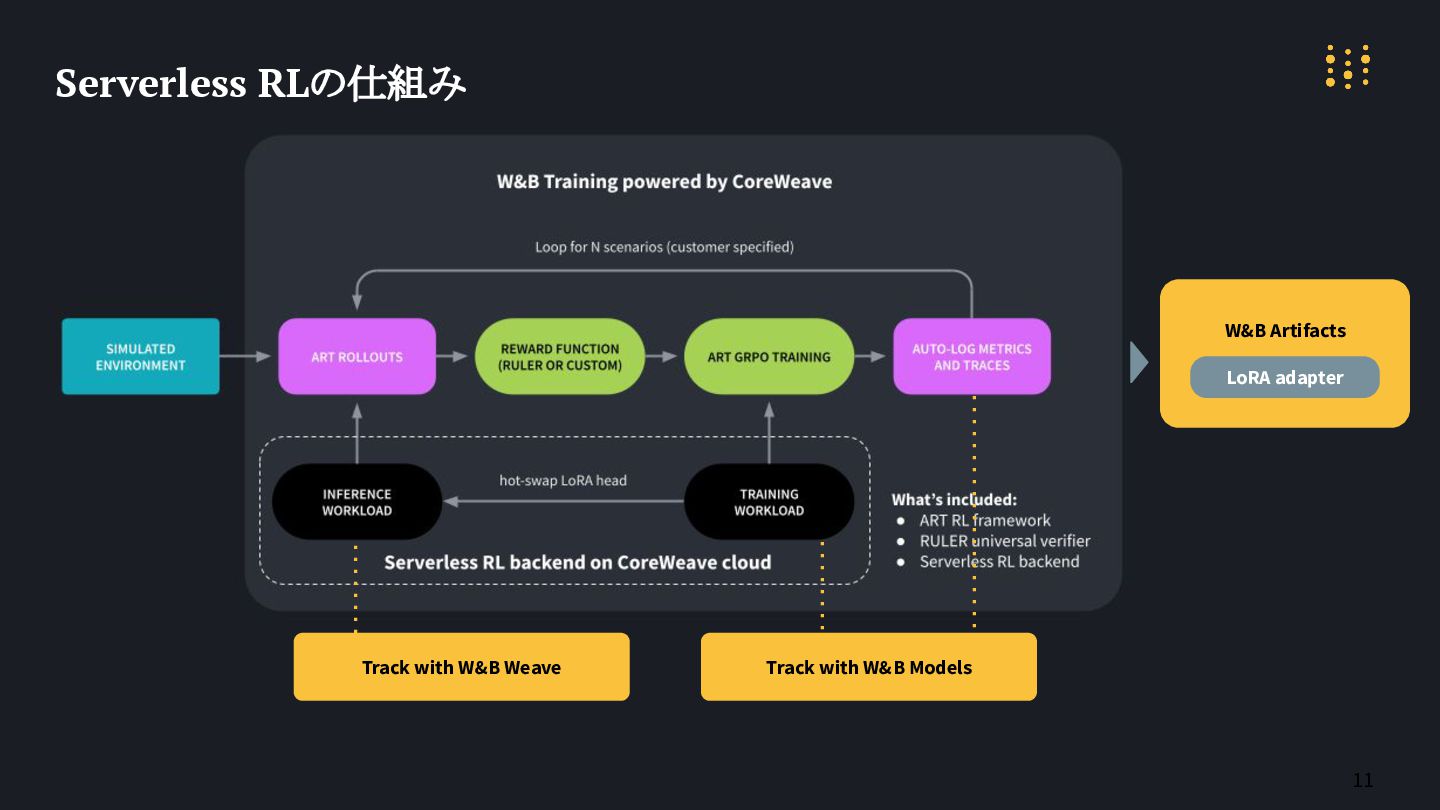
11 Serverless RLの仕組み W&B Artifacts LoRA adapter Track with W&B
Models Track with W&B Weave
12 Demo ART-E • ART·E は「メール検索エージェント」を強化学習で 最適化 • ユーザー質問に対し、メール検索 →
読み込み → 回答生成を自動化 • Enron メールを用いた合成データで学習 • GRPO による最適化(正答かどうか、ターン数、関 連性など) • ユーザー質問を受け取る • search_emails で関連メールを検索 • read_email で候補メール本文を取得 • 必要に応じて検索・読込を繰り返す(最大10ターン) • return_final_answer で回答と根拠メールを返す https://openpipe.ai/blog/art-e-mail-agent 概要 流れ
13 Tips ▪ 1. 報酬の“標準偏差”を監視する • GRPO は複数の軌跡を比較して学習するため、報酬 が似通いすぎると学習信号が消える。 •
停滞したら:軌跡数を増やす/報酬を少し密にする/ 学習率を下げる。 ▪ 2. メトリクスを多角的に追跡する • 正答率だけで判断すると“ごまかし”を見逃す。 • 例:ターン数・失敗率・幻覚率・検索成功率などを併せ て見る。 ▪ 3. 出力を“必ず”人間の目で確認する • RLモデルは報酬ハックの天才。 • 報酬が増えていても、意図しない行動をしている可能 性がある。 • 例:部分点を与えたら同じツール呼び出しを無限リピー ト。 ▪ 4. 部分的な報酬は慎重に設計する • 中間目標を与えると、それを“最適に悪用”されるリスク がある。 • 最終目的だけで学習させた方が早い場合も多い。 ▪ 5. ハイパーパラメータは小刻みに試す • GRPO は敏感なため、LR や rollout 数の微調整で大 きく変わる。 • 1回の学習に固執せず、短時間ジョブを何度も回して 効率化する。
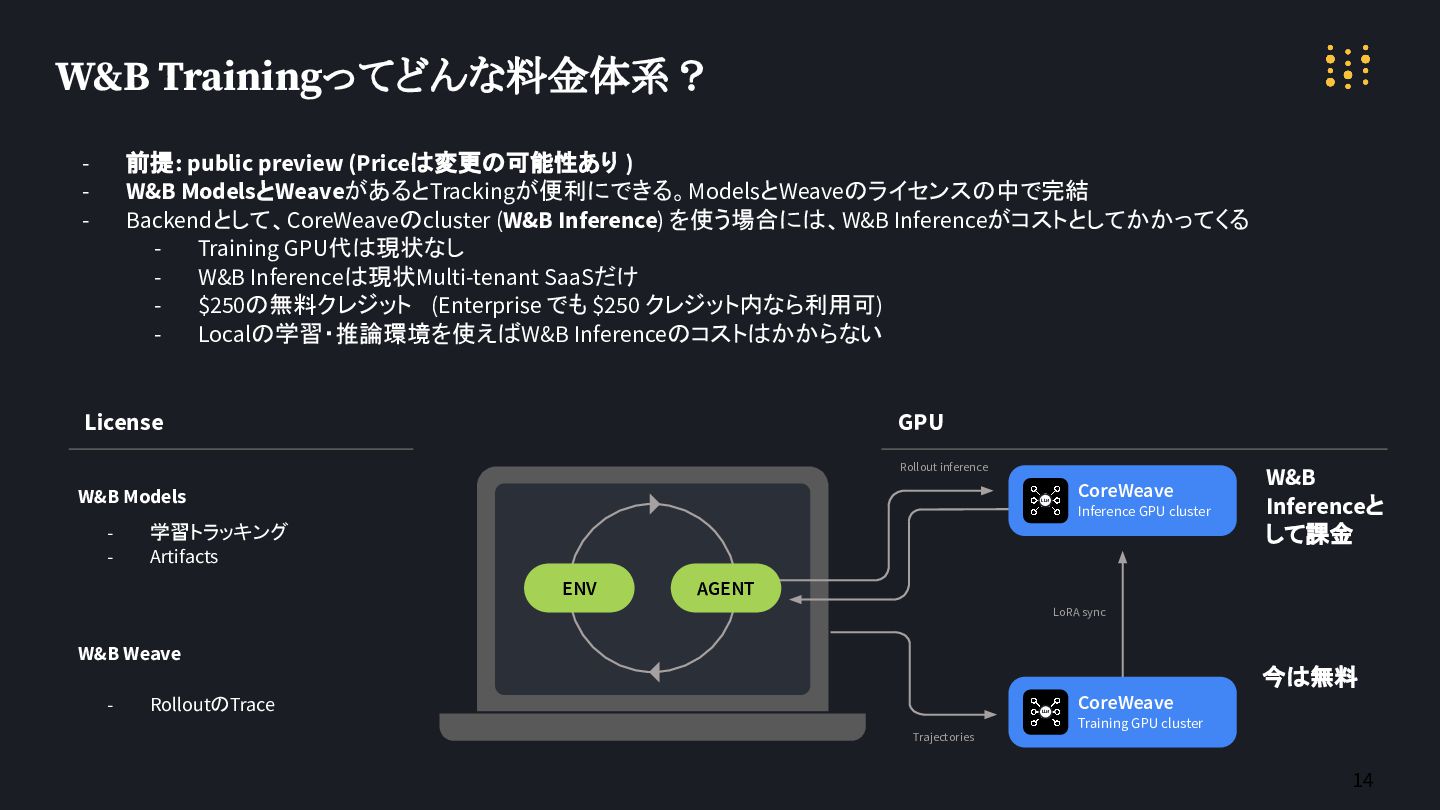
14 W&B Trainingってどんな料金体系? CoreWeave Inference GPU cluster CoreWeave Training GPU
cluster Rollout inference Trajectories ENV LoRA sync AGENT LLM LLM W&B Models W&B Weave - 学習トラッキング - Artifacts - RolloutのTrace License 今は無料 W&B Inferenceと して課金 GPU - 前提: public preview (Priceは変更の可能性あり ) - W&B ModelsとWeaveがあるとTrackingが便利にできる。ModelsとWeaveのライセンスの中で完結 - Backendとして、CoreWeaveのcluster (W&B Inference) を使う場合には、W&B Inferenceがコストとしてかかってくる - Training GPU代は現状なし - W&B Inferenceは現状Multi-tenant SaaSだけ - $250の無料クレジット (Enterprise でも $250 クレジット内なら利用可) - Localの学習・推論環境を使えばW&B Inferenceのコストはかからない
15 W&B Trainingを試してみてください! https://docs.wandb.ai/training 19:40 start
Appendix
17 Weights & Biases AI Agent Suite Training Train agents
with serverless RL Inference Deploy agents at scale Models Build models to power agents Weave Observe + evaluate agents
W&B Inference powered by CoreWeave
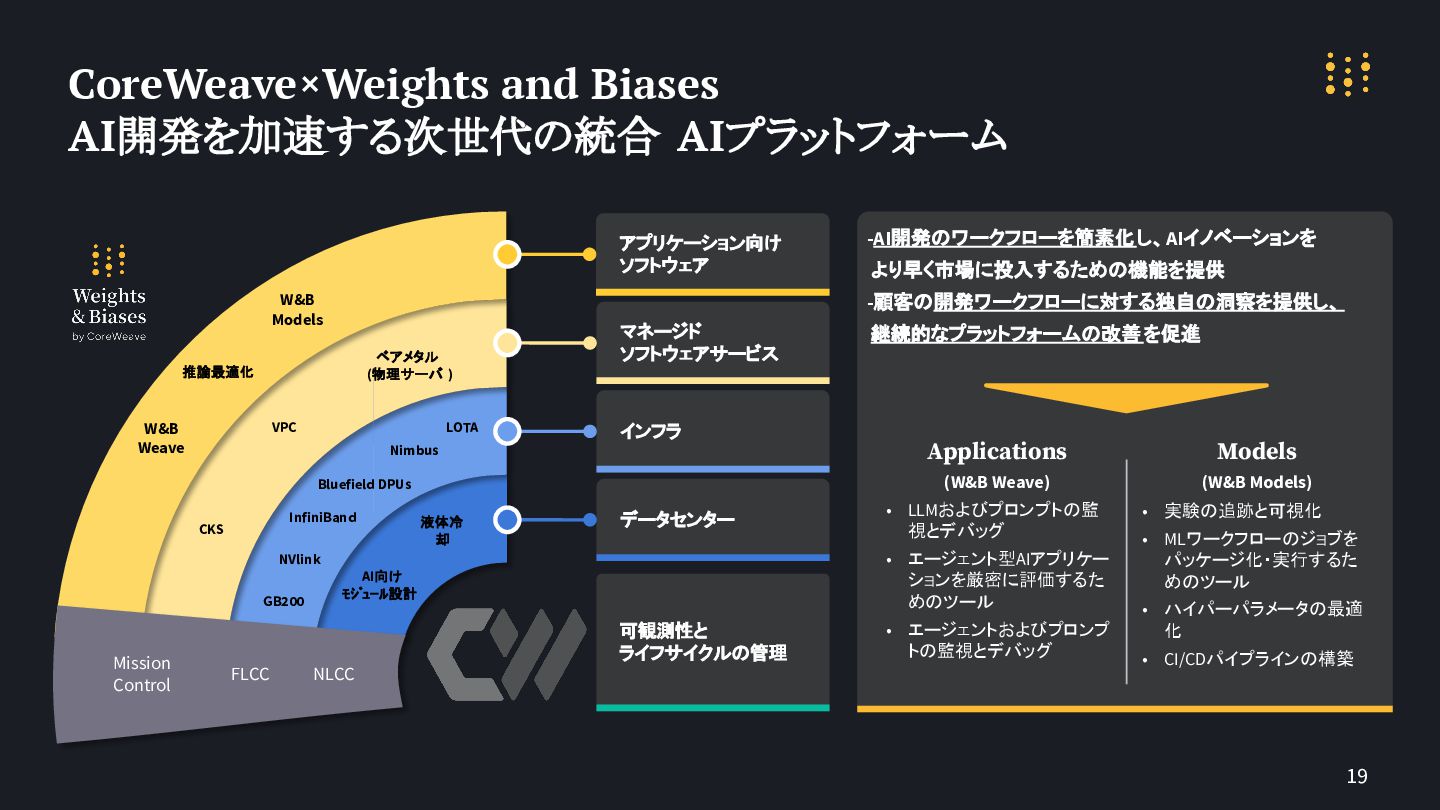
19 CoreWeave×Weights and Biases AI開発を加速する次世代の統合 AIプラットフォーム -AI開発のワークフローを簡素化し、AIイノベーションを より早く市場に投入するための機能を提供 -顧客の開発ワークフローに対する独自の洞察を提供し、 継続的なプラットフォームの改善を促進
アプリケーション向け ソフトウェア 推論最適化 ベアメタル (物理サーバ ) VPC CKS LOTA Nimbus Bluefield DPUs InfiniBand NVlink GB200 液体冷 却 Mission Control FLCC NLCC AI向け モジュール設計 Models (W&B Models) • 実験の追跡と可視化 • MLワークフローのジョブを パッケージ化・実行するた めのツール • ハイパーパラメータの最適 化 • CI/CDパイプラインの構築 Applications (W&B Weave) • LLMおよびプロンプトの監 視とデバッグ • エージェント型AIアプリケー ションを厳密に評価するた めのツール • エージェントおよびプロンプ トの監視とデバッグ W&B Models W&B Weave マネージド ソフトウェアサービス インフラ データセンター 可観測性と ライフサイクルの管理
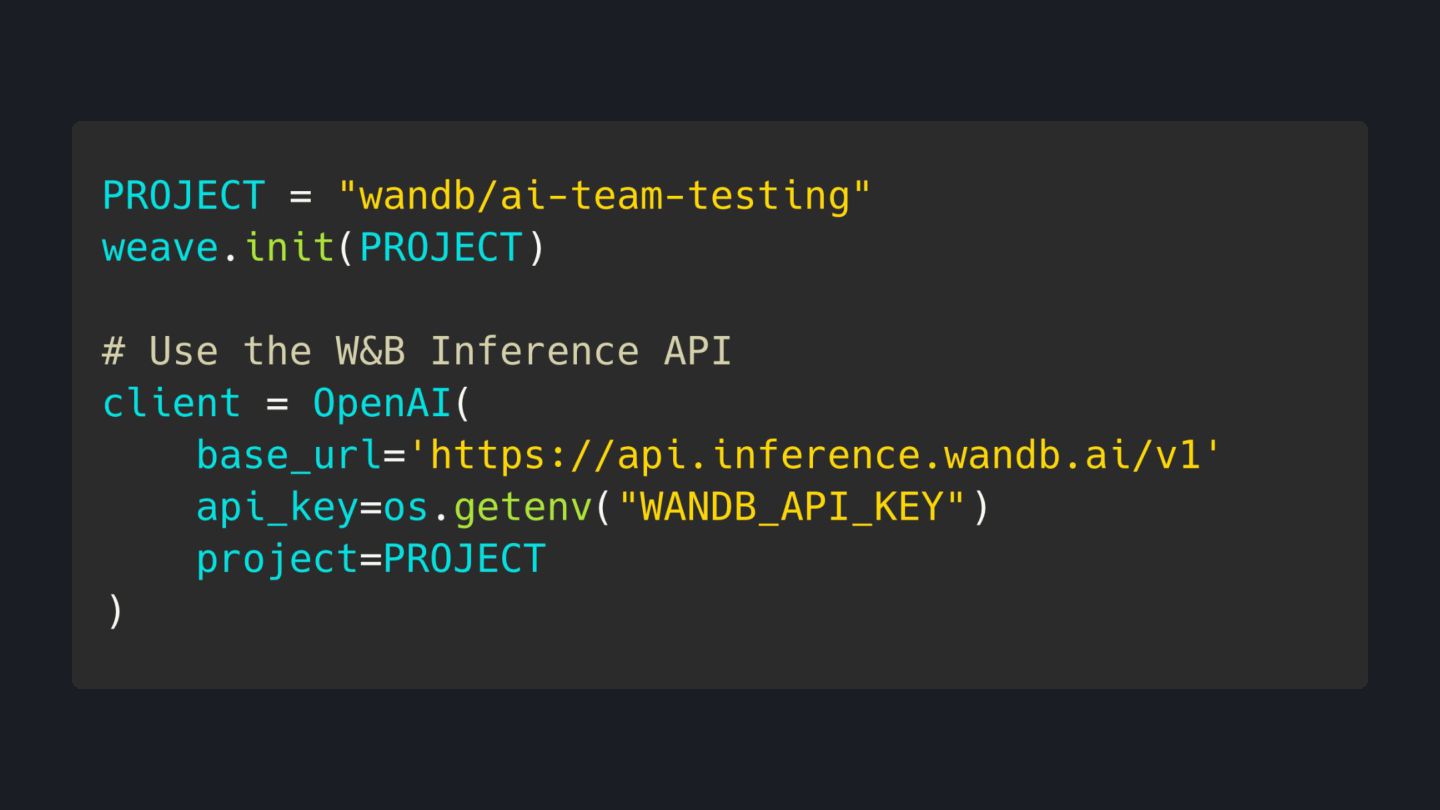
Powered by CoreWeave W&B Inference: Instantly access leading open-source LLMs
20 • LLM を手軽に切り替えて試せる環境 • API キー登録やモデルのデプロイは不要 • オープンソース LLM をゼロ設定で利用できる プレイグラウンド • アプリの挙動を可視化するWeaveとのインテグレー ション DeepSeek R1-0528 LLaMa 3.3 70B LLaMA 4 Scout 17Bx16E Phi 4 Mini 3.8B LLaMA 3.1 8B DeepSeek V3-0324 Kimi K2 Instruct ∂ Qwen3 Coder ∂ Qwen3 Thinking ∂ Qwen3 Instruct GPT OSS 120B ∂ GPT OSS 20B GLM 4.5 DeepSeek V3.1
None
None
23
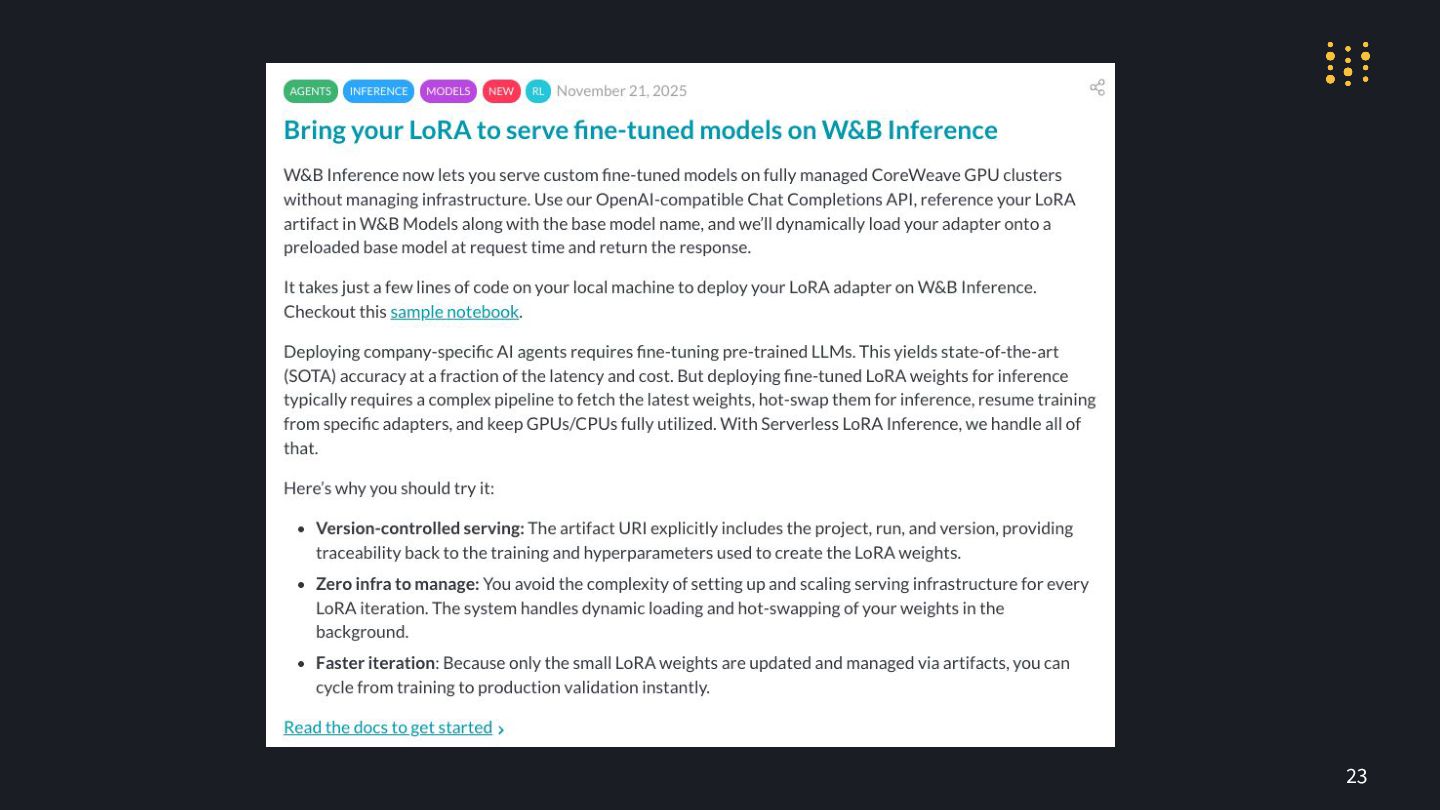
Serverless RL powered by OpenPipe & CoreWeave
25 LLM開発における強化学習 (RL)の進化とオンザジョブ RLの重要性 • RLの手法は急速に発展し、LLMの人間の意図に沿った振る舞いの調整(PPO, DPOなど)から、高度な推論能力の獲得 (GRPOなど)を実現してきた • それでも「汎用モデル」と、企業が求める「実務要件」の間にはギャップがある。
• 企業固有のタスクに合わせてモデルを再調整するためにSFTをしたいが十分なデータがないケースが多いそのギャップを 埋める期待をされているのが「オンザジョブRL」
26 OpenPipe 2023: USのNYで創業 LLM を効率的に使うための モデル最適化 プラットフォームを提供 (SFT) 2025:CoreWeave
が買収 エージェント訓練基盤として強化 -> RLに注力
強化学習のハードルを下げる • Agent Reinforcement Trainer(ART)フレーム ワーク・RULER Universal Verifierとの統合 GPUインフラの抽象化・高速化 •
CoreWeave 上で稼働するサーバーレス強化 学習バックエンド • 高速化を実現 実験管理ツールとのインテグレーション • 学習状況の管理・Roll outの可視化 • LoRA チェックポイントは W&B のアーティファ クトとして保存(必要であればダウンロード・ 推論利用可能 β機能) Serverless RL (W&B Training) CoreWeave Inference GPU cluster CoreWeave Training GPU cluster Rollout inference Trajectories ENV LoRA sync AGENT LLM LLM
28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}