■AI×DevOps Study #9 の概要
2026年3月26日に開催した「AI×DevOps Study」第9回の勉強会資料です。
「AI×DevOps Study」は、AI駆動開発やそこに関係するマイクロサービスについて理解を深める場になります。
株式会社ScalarではAIを使ったチーム開発を進めており、参画しているメンバーや協力会社の方から、具体的なAI駆動開発を実施する方法、その中で生まれたマイクロサービスアーキテクチャを使用したAI駆動開発の事例や実際に使えるエージェントについてお話頂き、参加者の皆様と知識の共有や交換を目的としています。
(弊社製品であるScalarDBも絡んだお話も一部出てきますが、汎用的な内容となっておりますのでフラットにお楽しみいいただけます)
■今回のテーマ
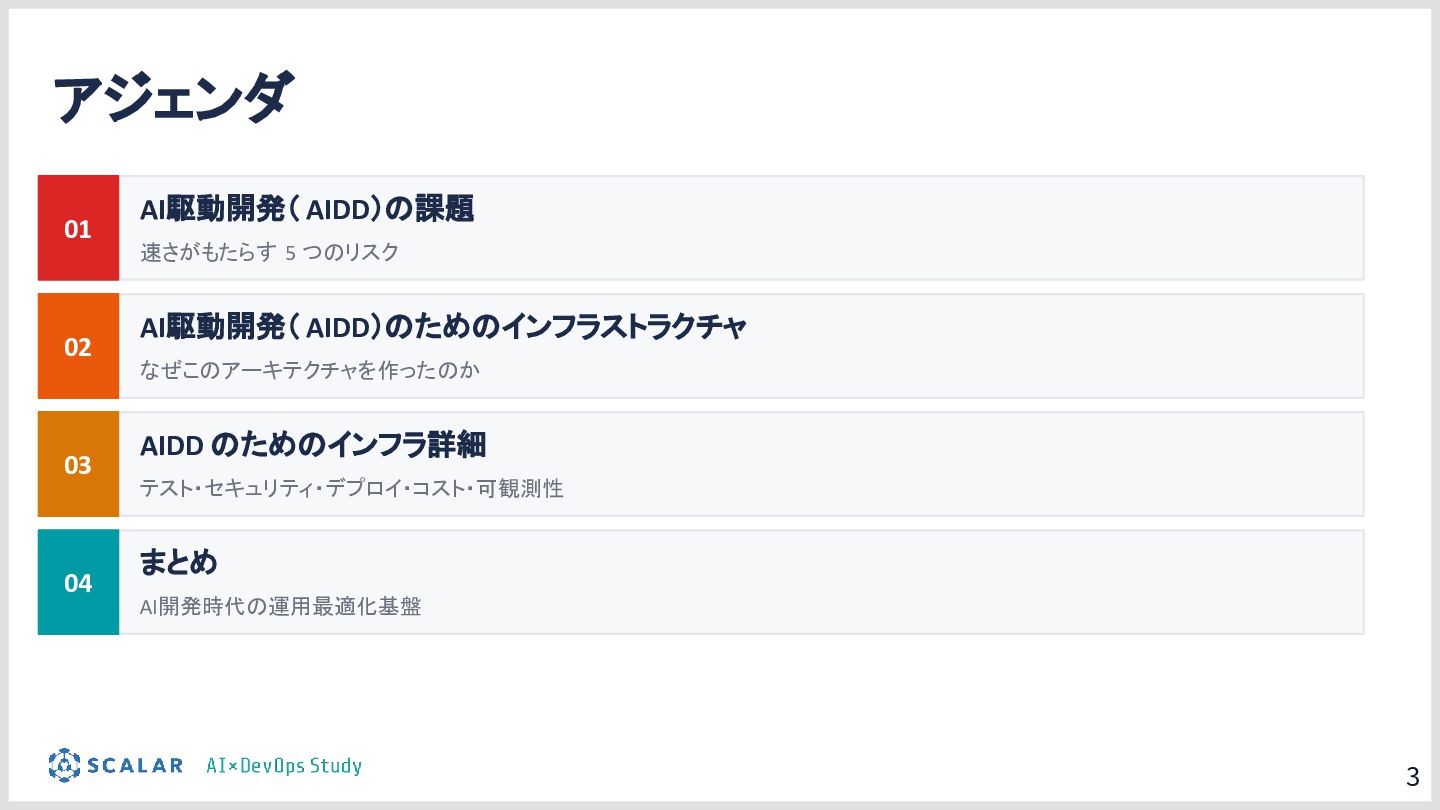
「AI駆動開発で作成したアプリを効率的にデプロイ・運用するインフラの仕組み」
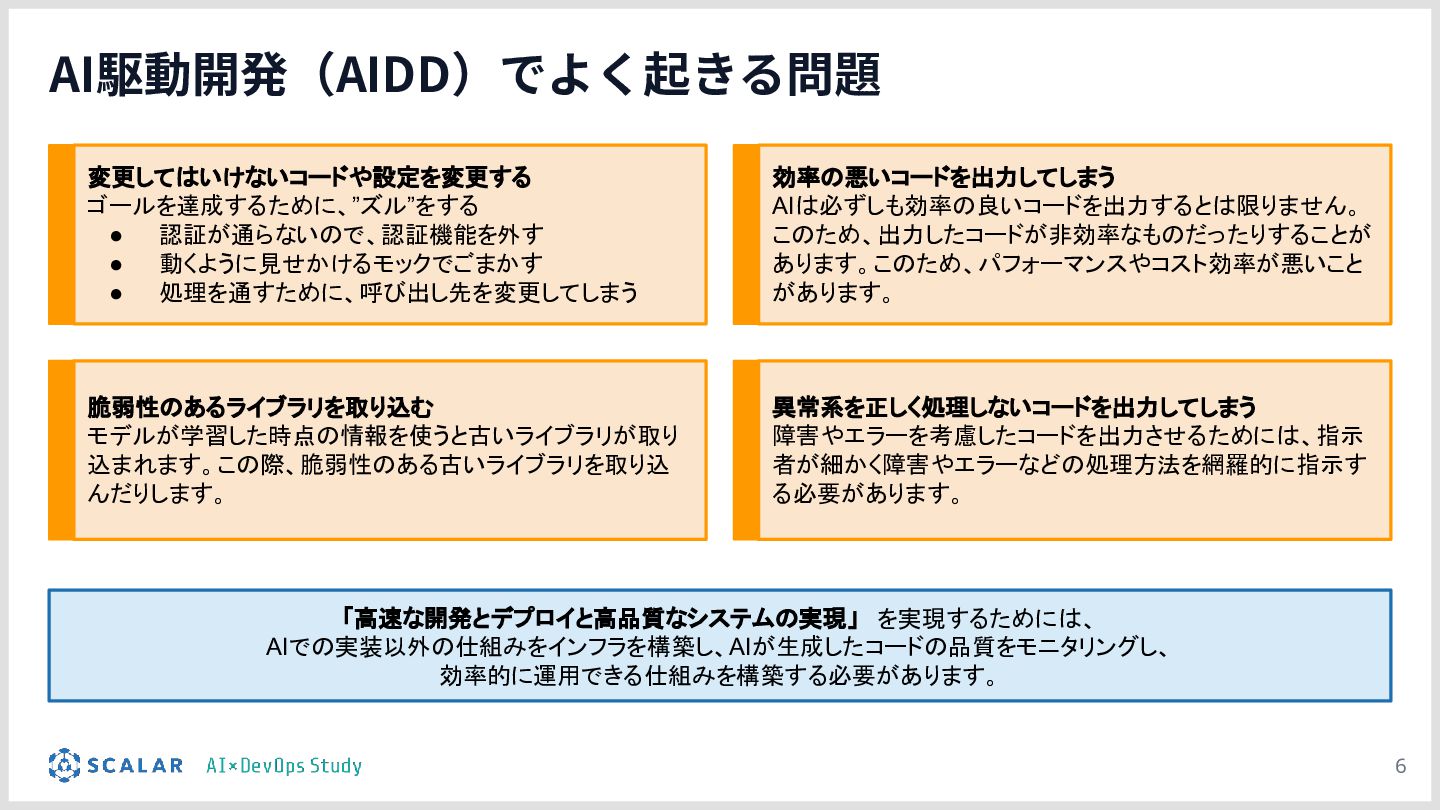
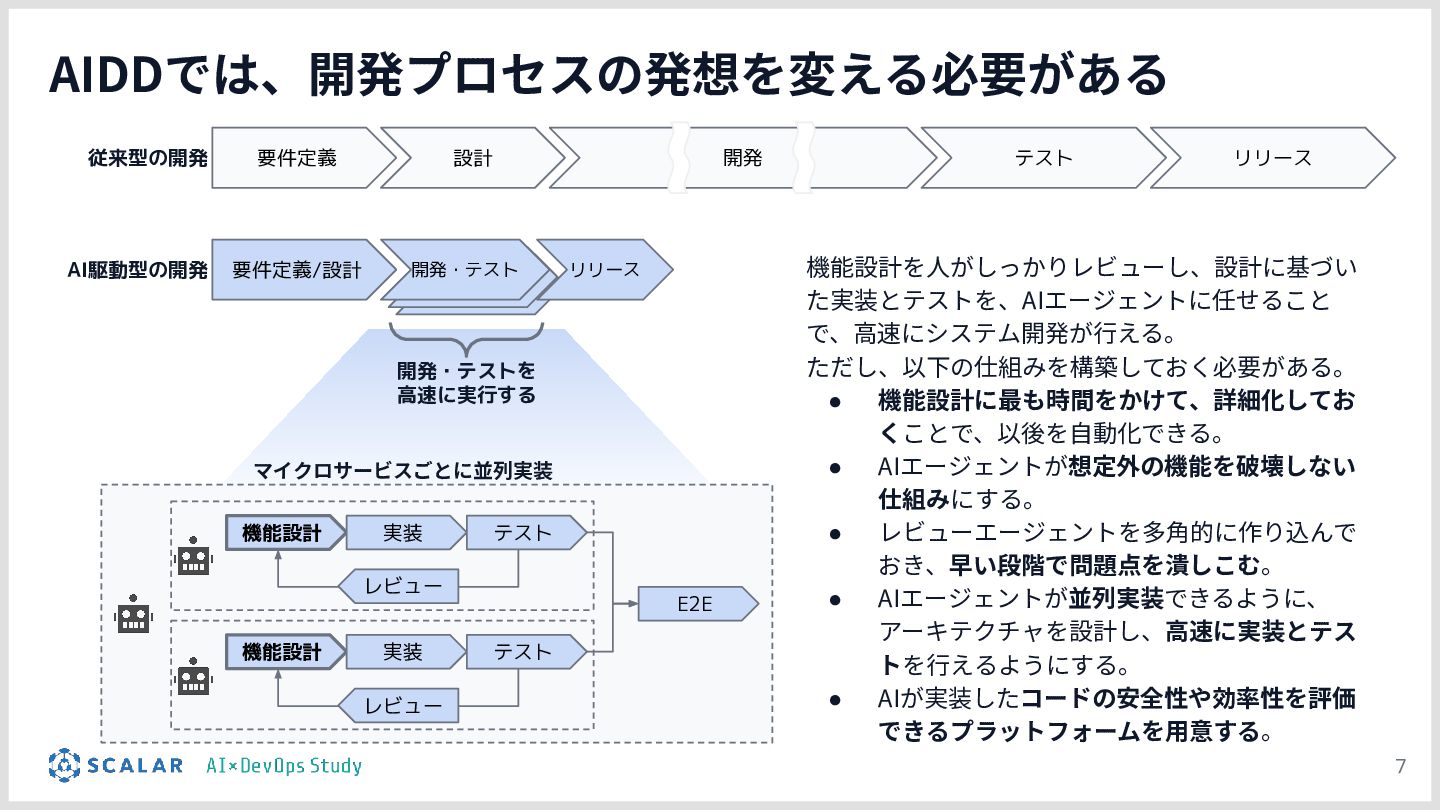
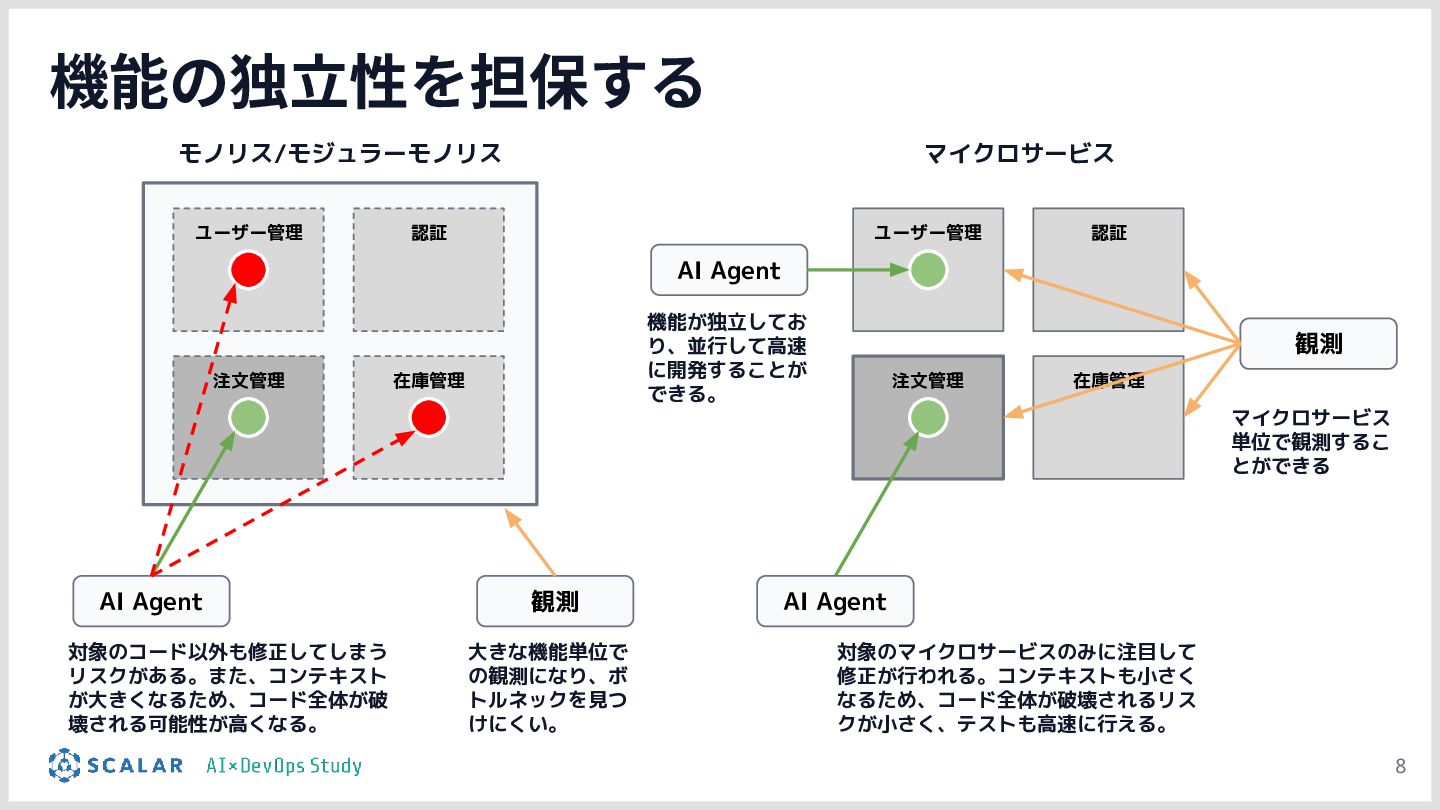
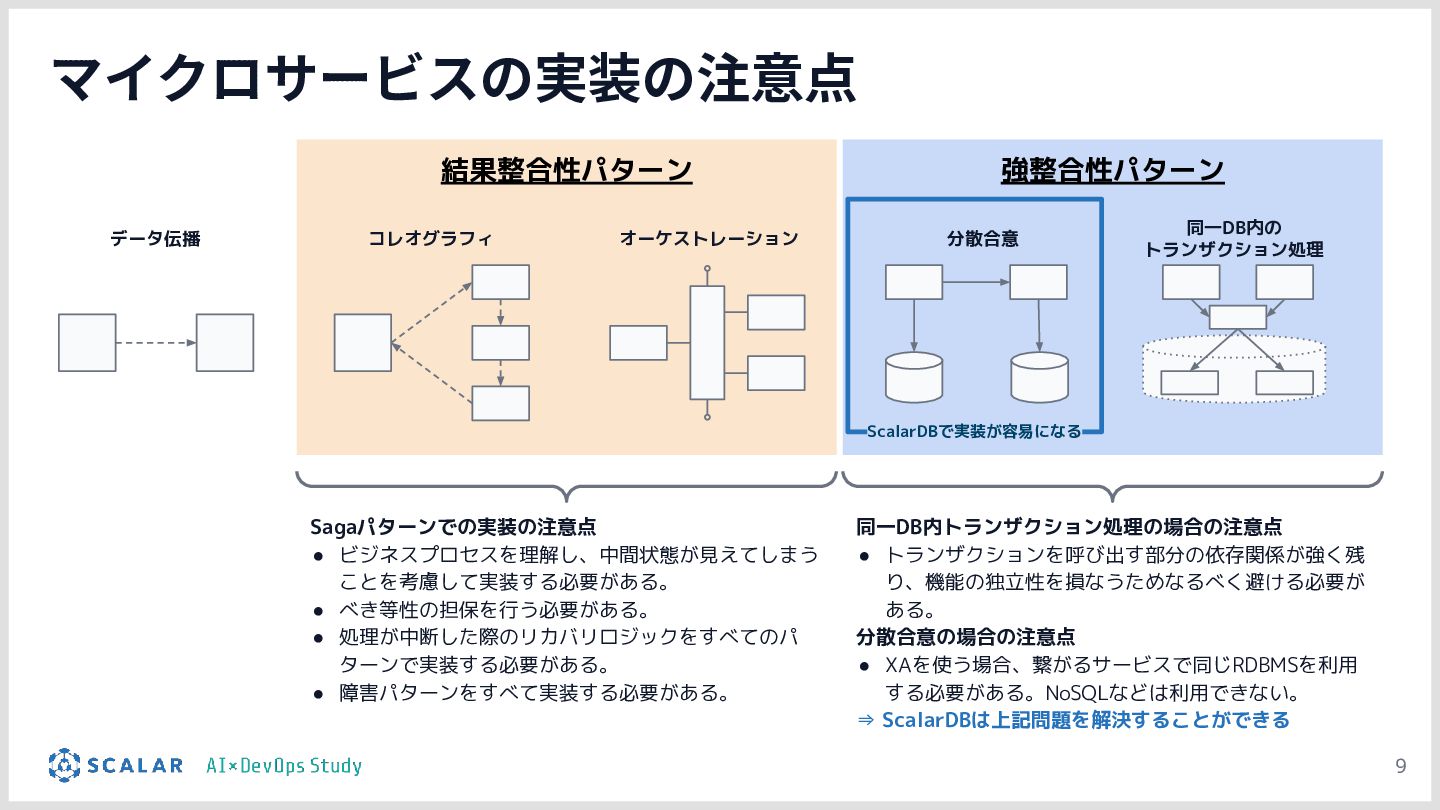
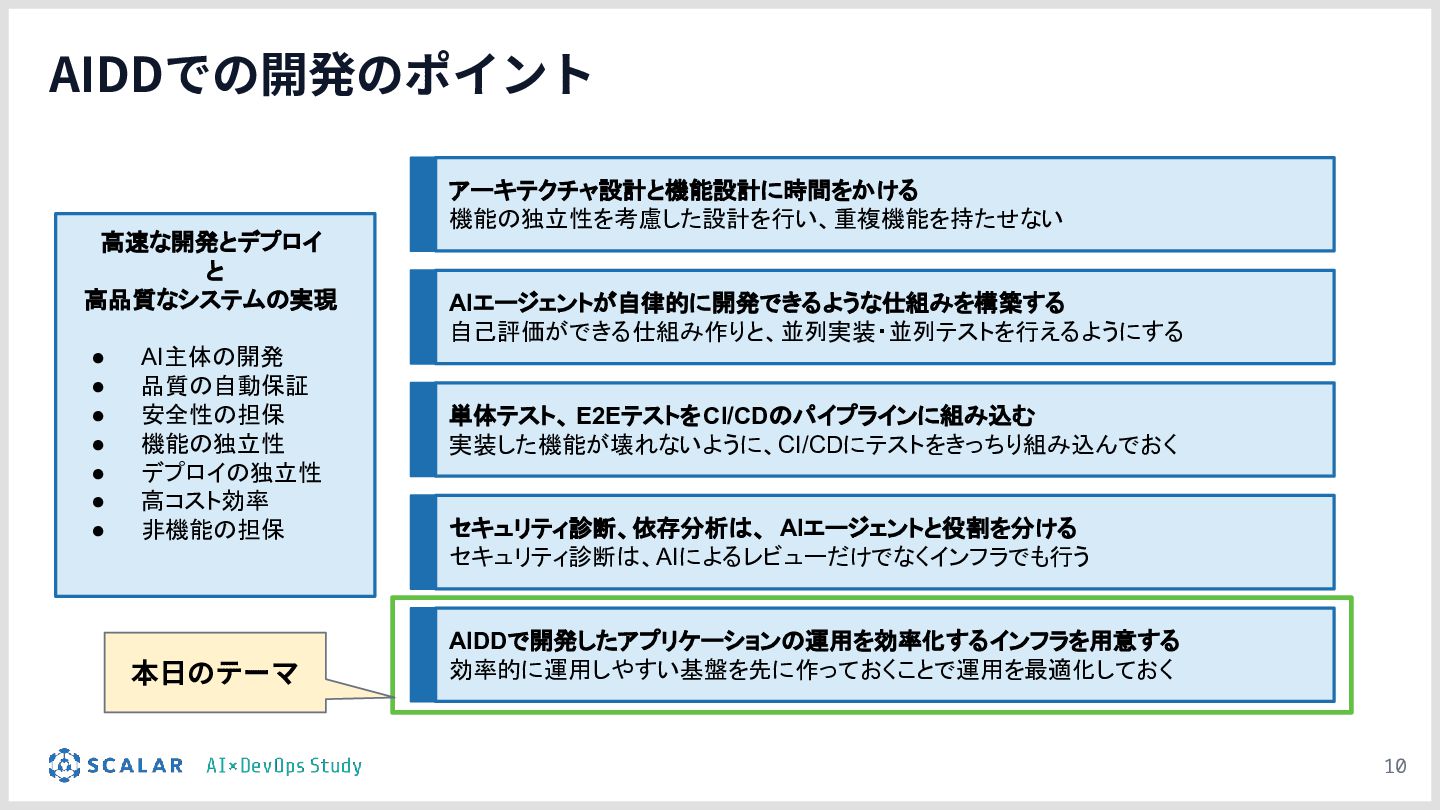
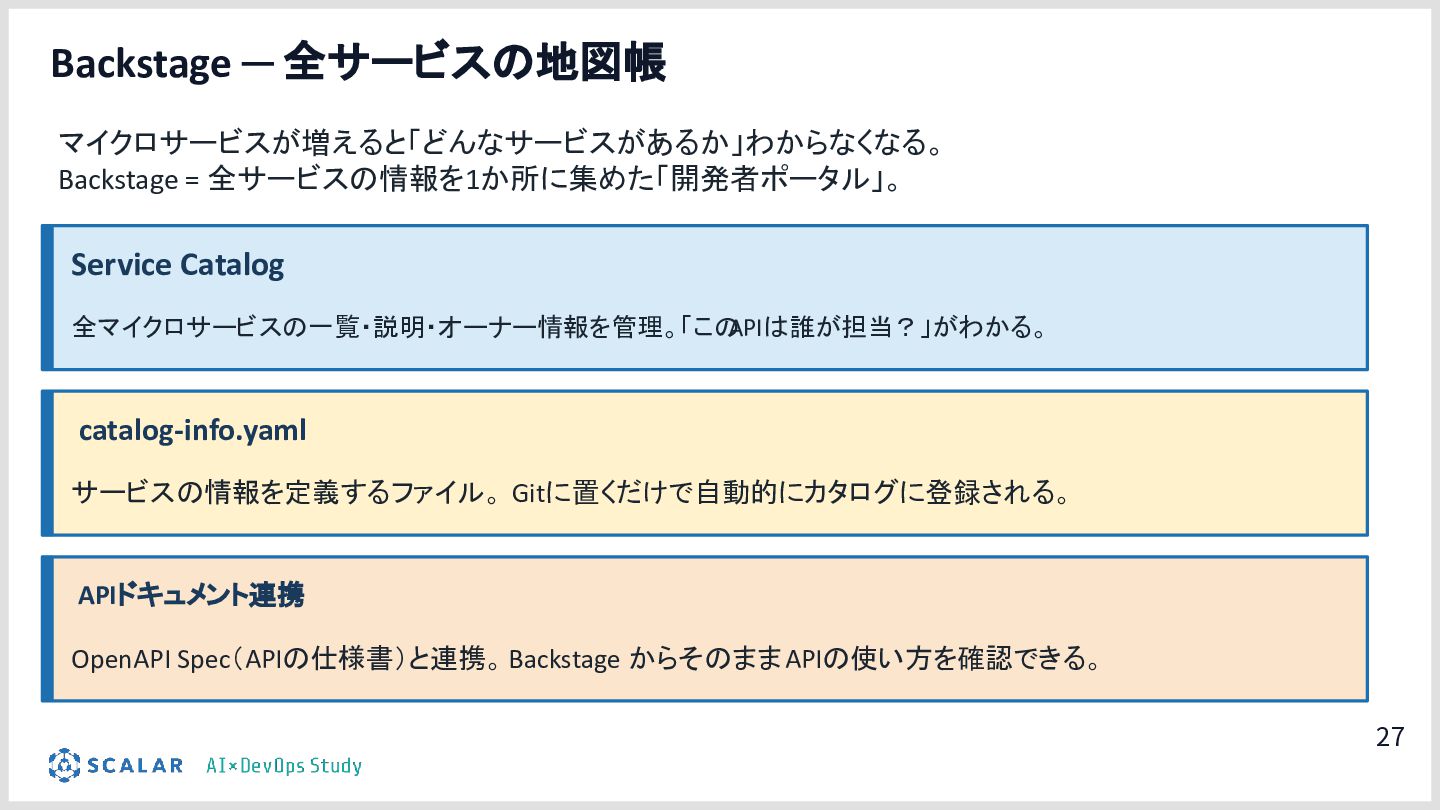
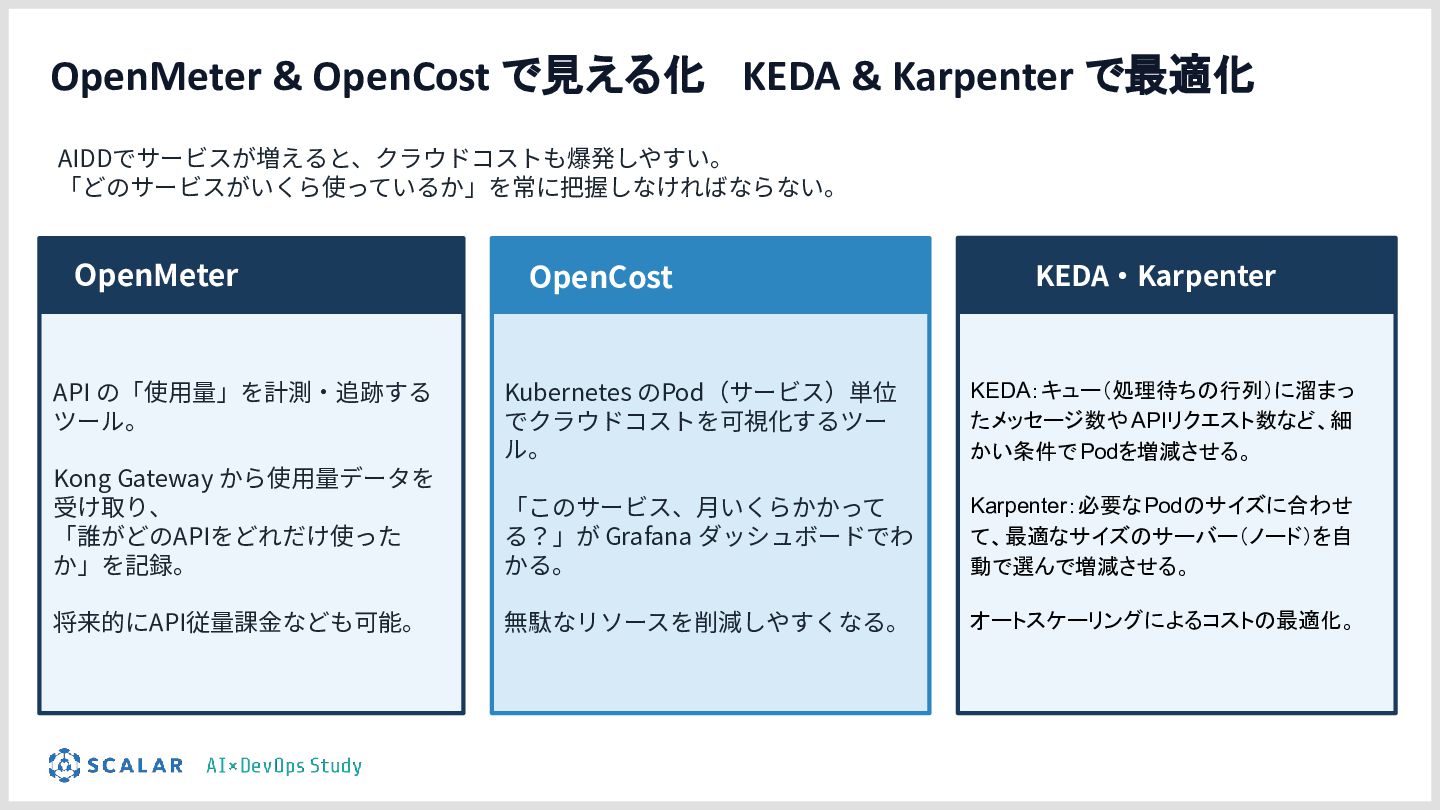
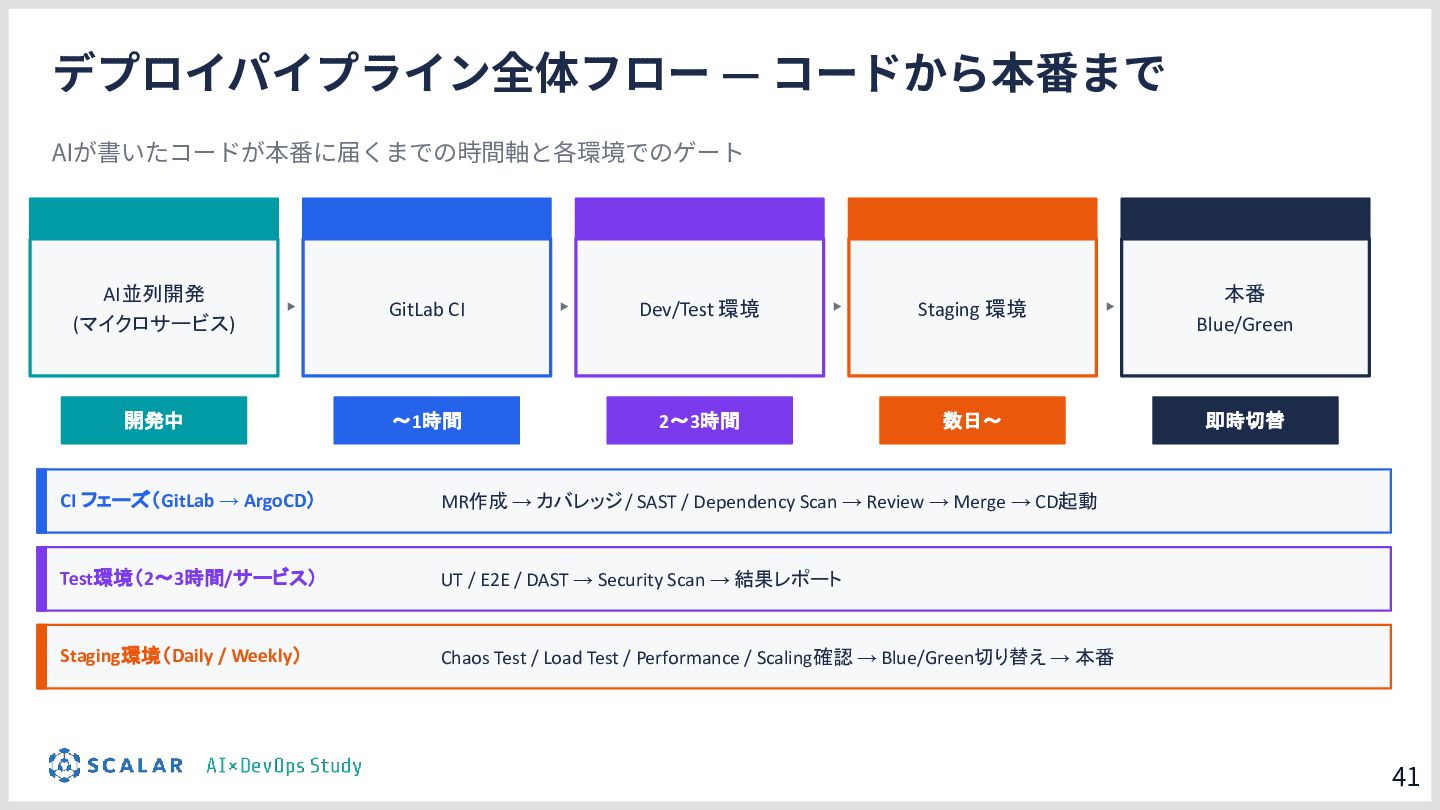
AI駆動開発(AIDD)の普及により、アプリ開発のスピードは飛躍的に向上しています。しかしその一方で、「マイクロサービスの爆発的な増加」「複数データベース間のデータ整合性」「手動では追いつかないデプロイ・運用」という新たな課題が生まれています。
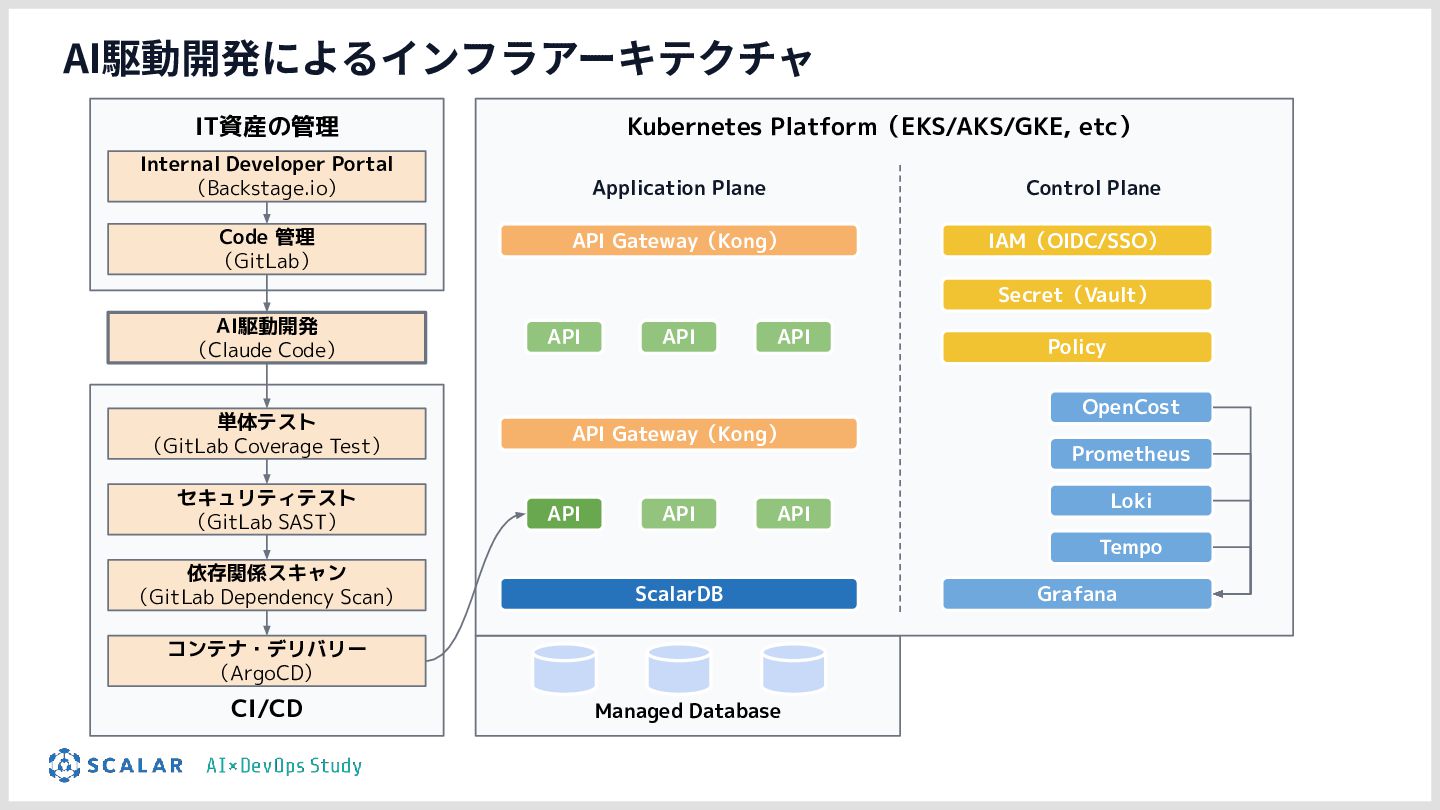
本勉強会では、こうした課題を解決するために構築したインフラ基盤を解説します。
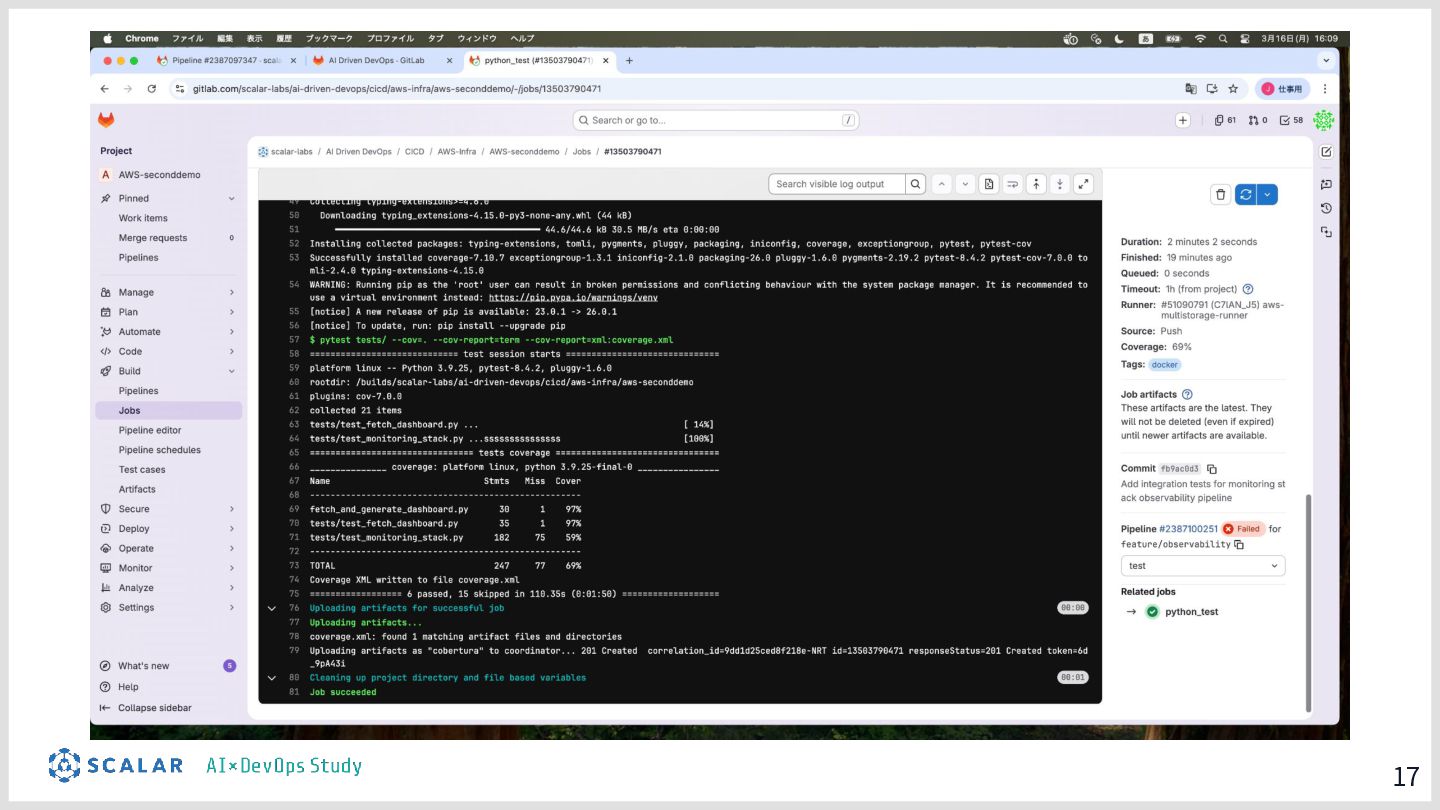
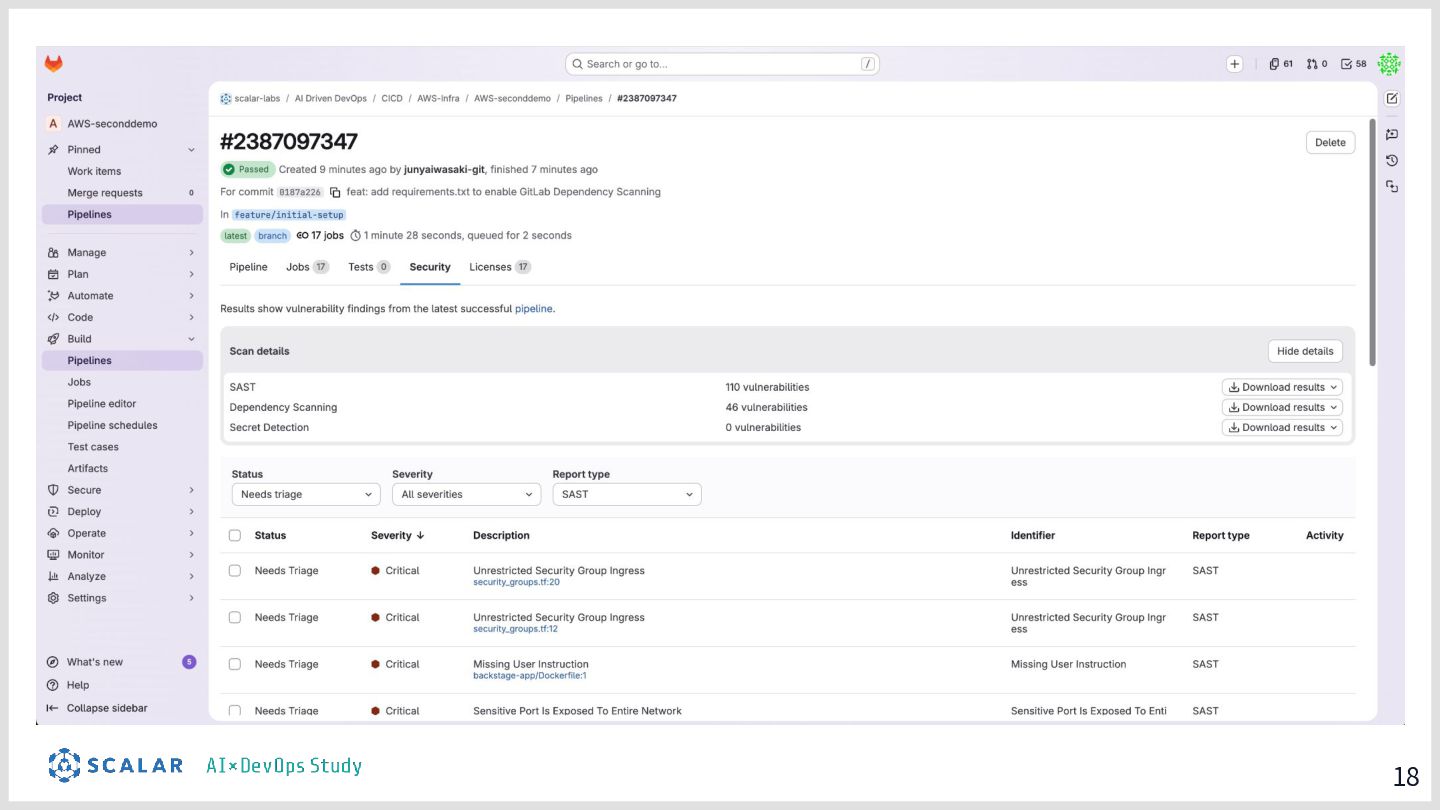
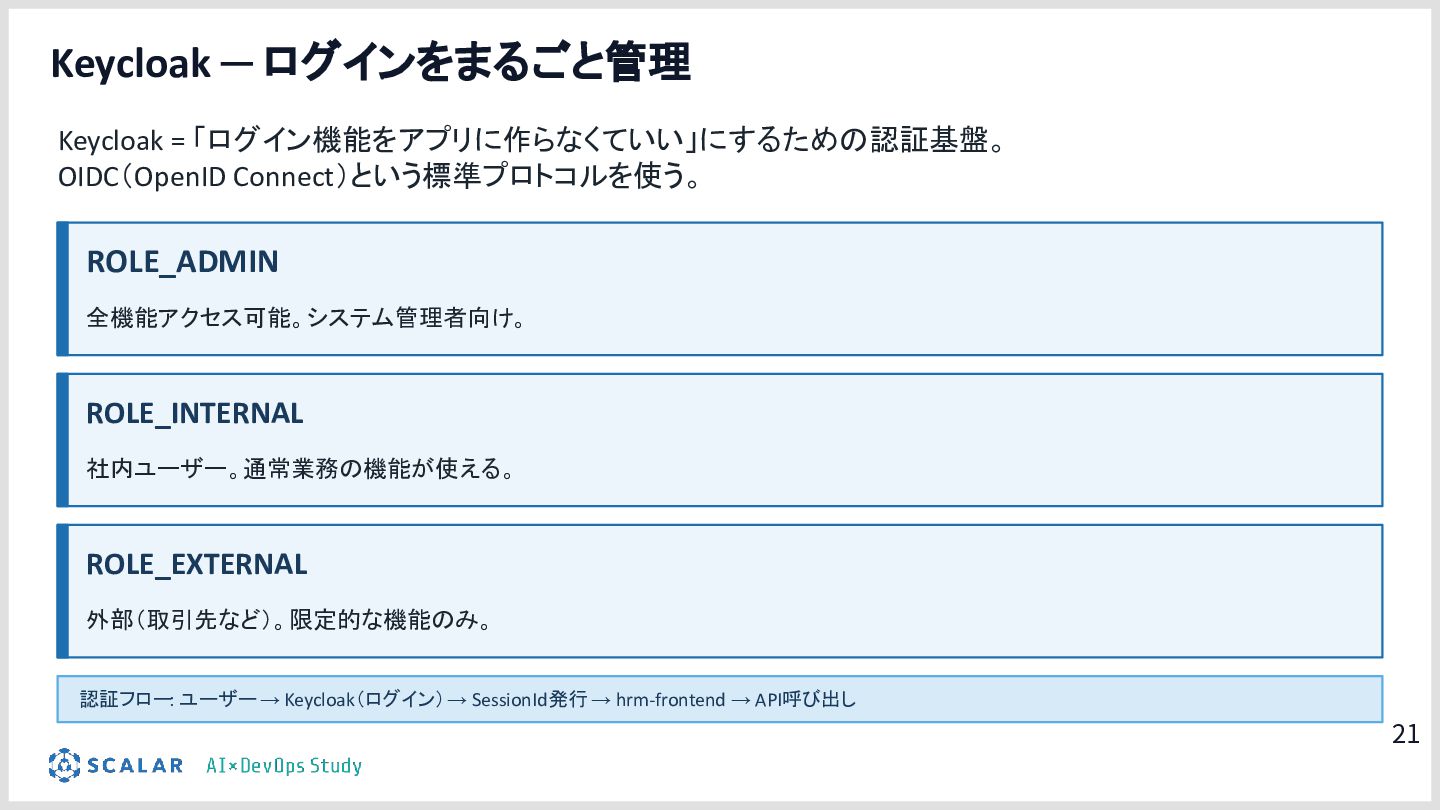
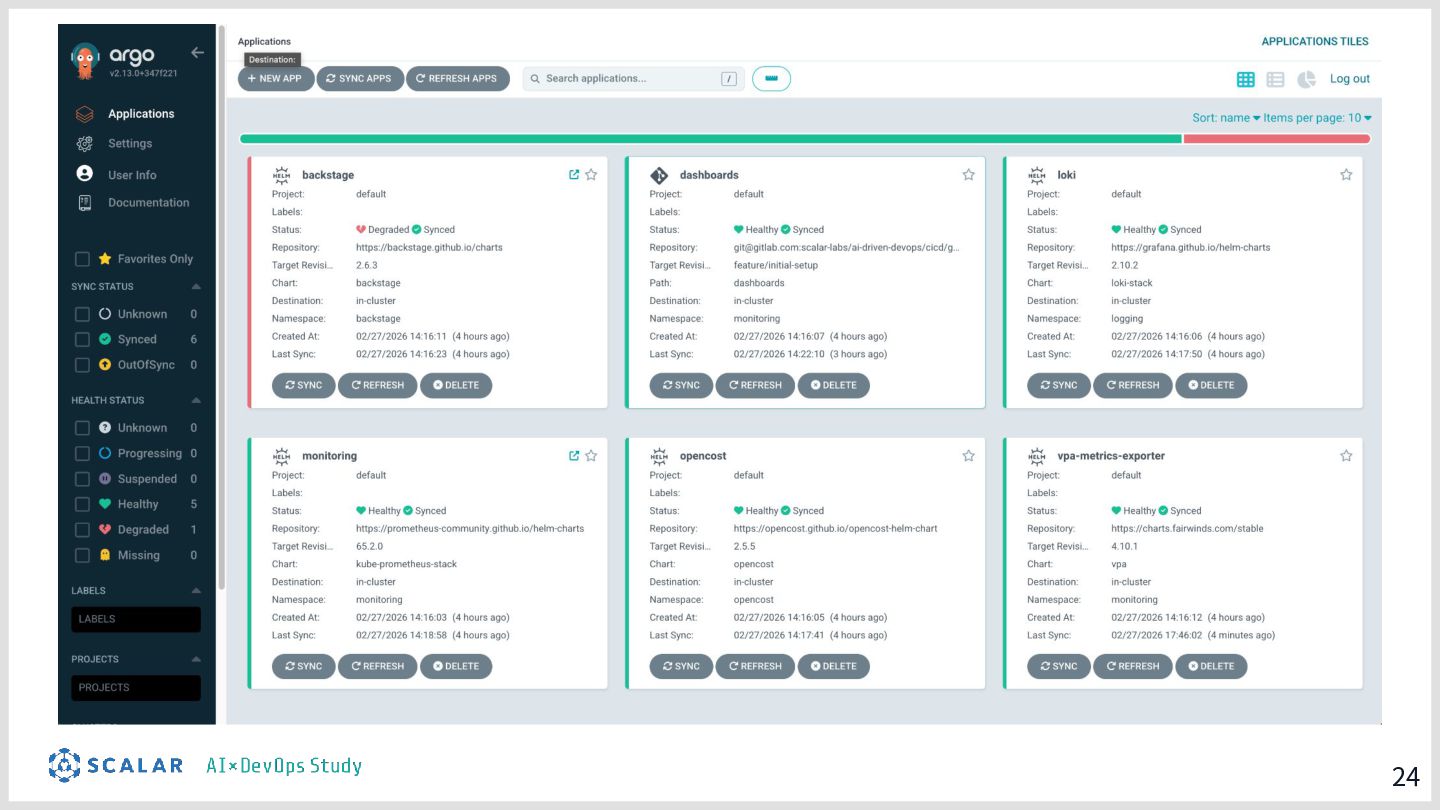
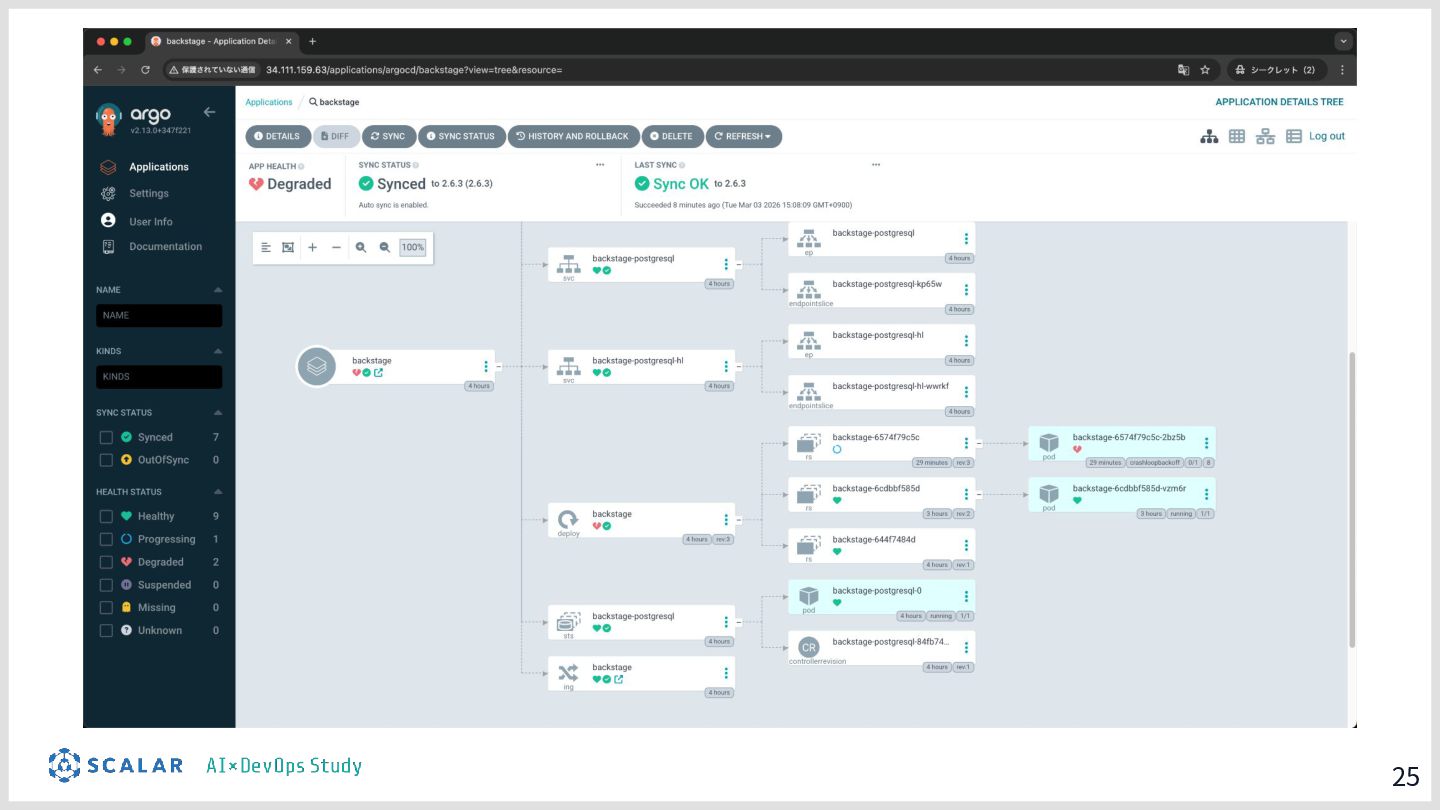
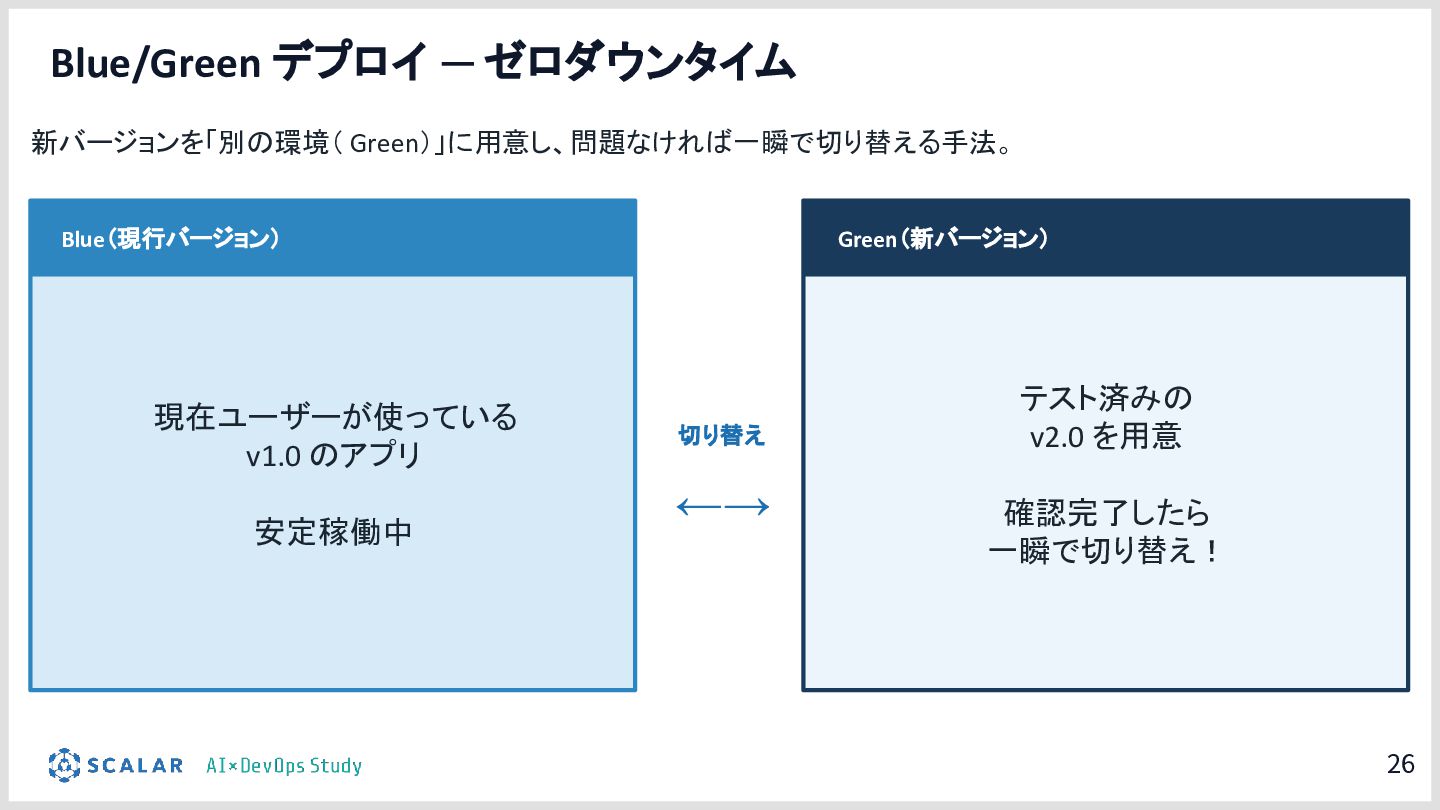
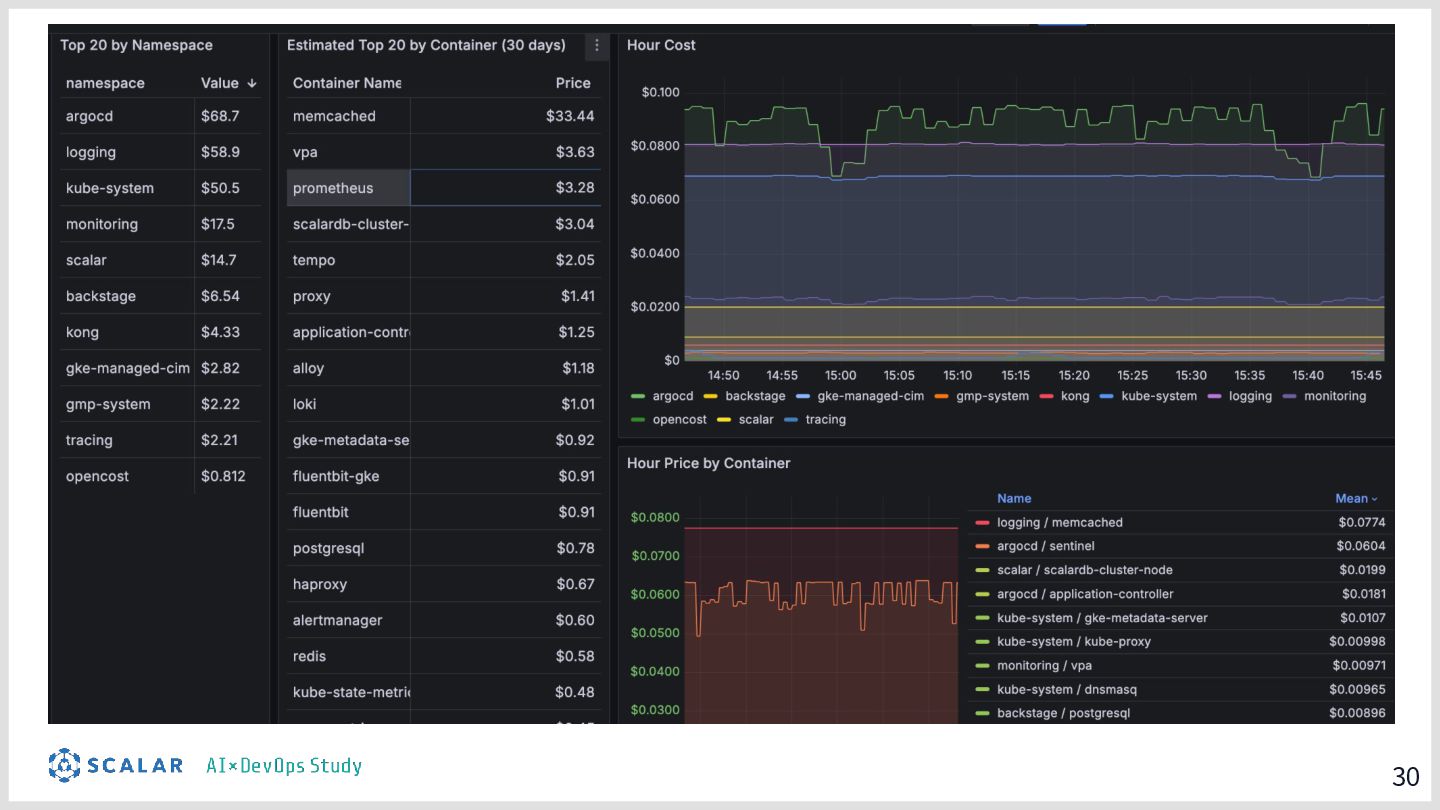
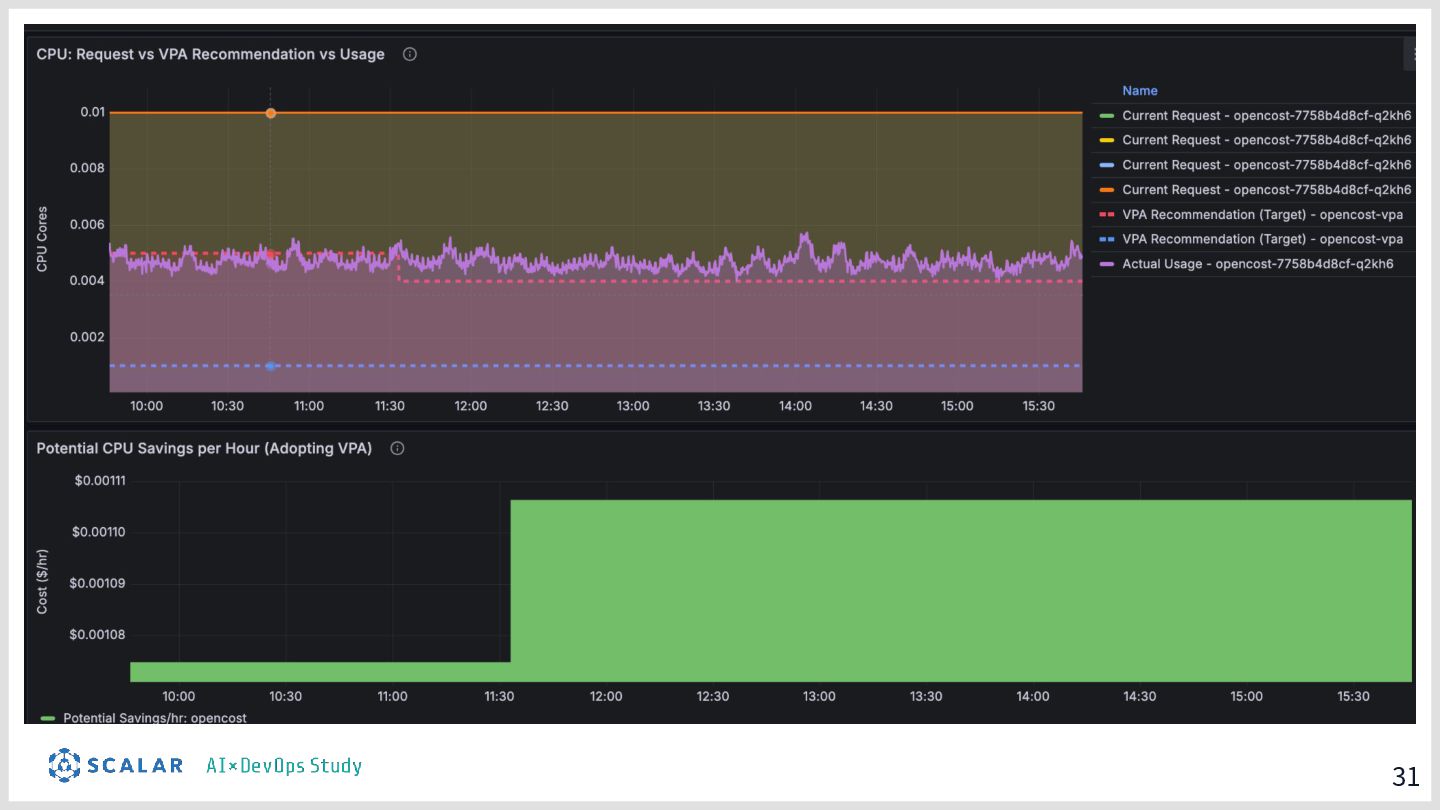
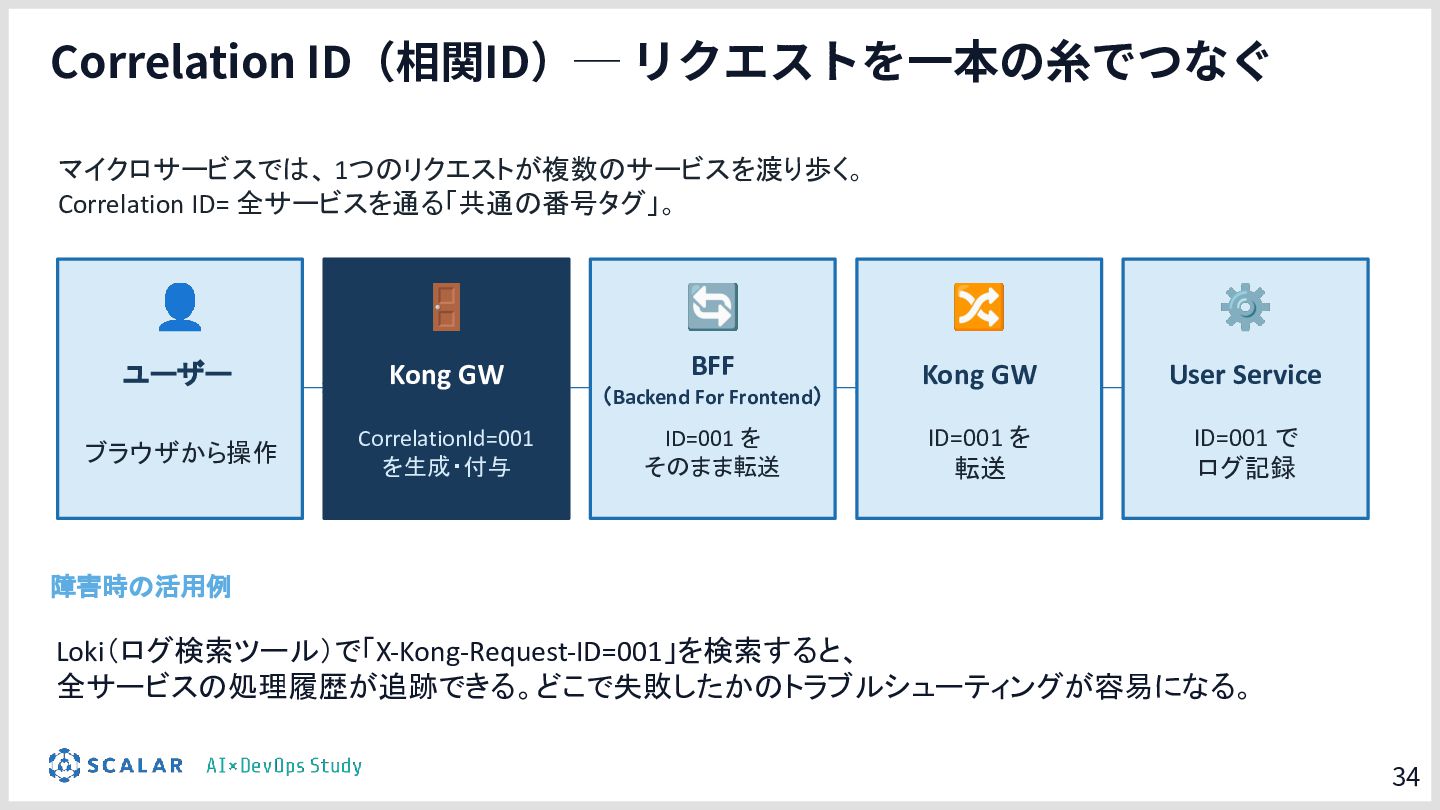
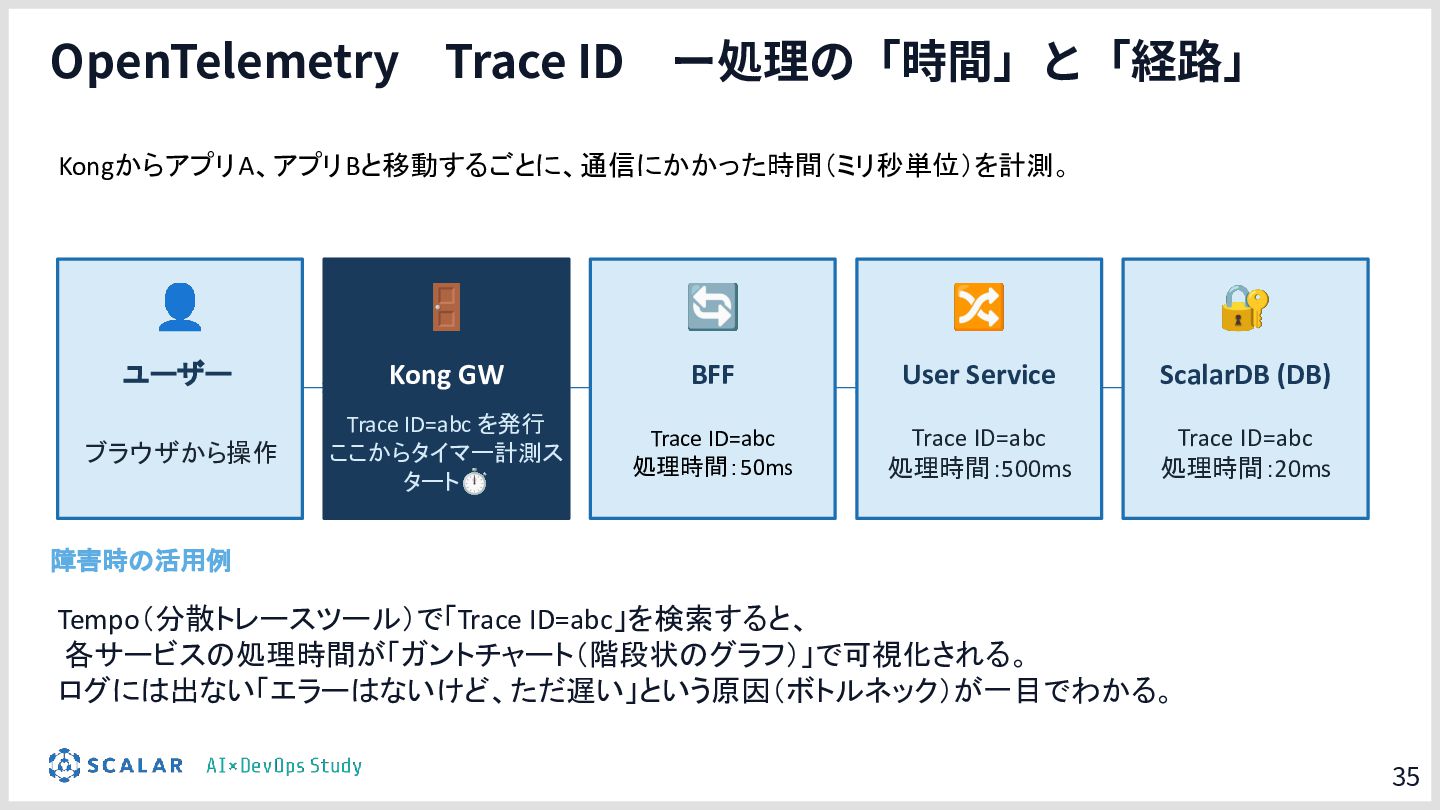
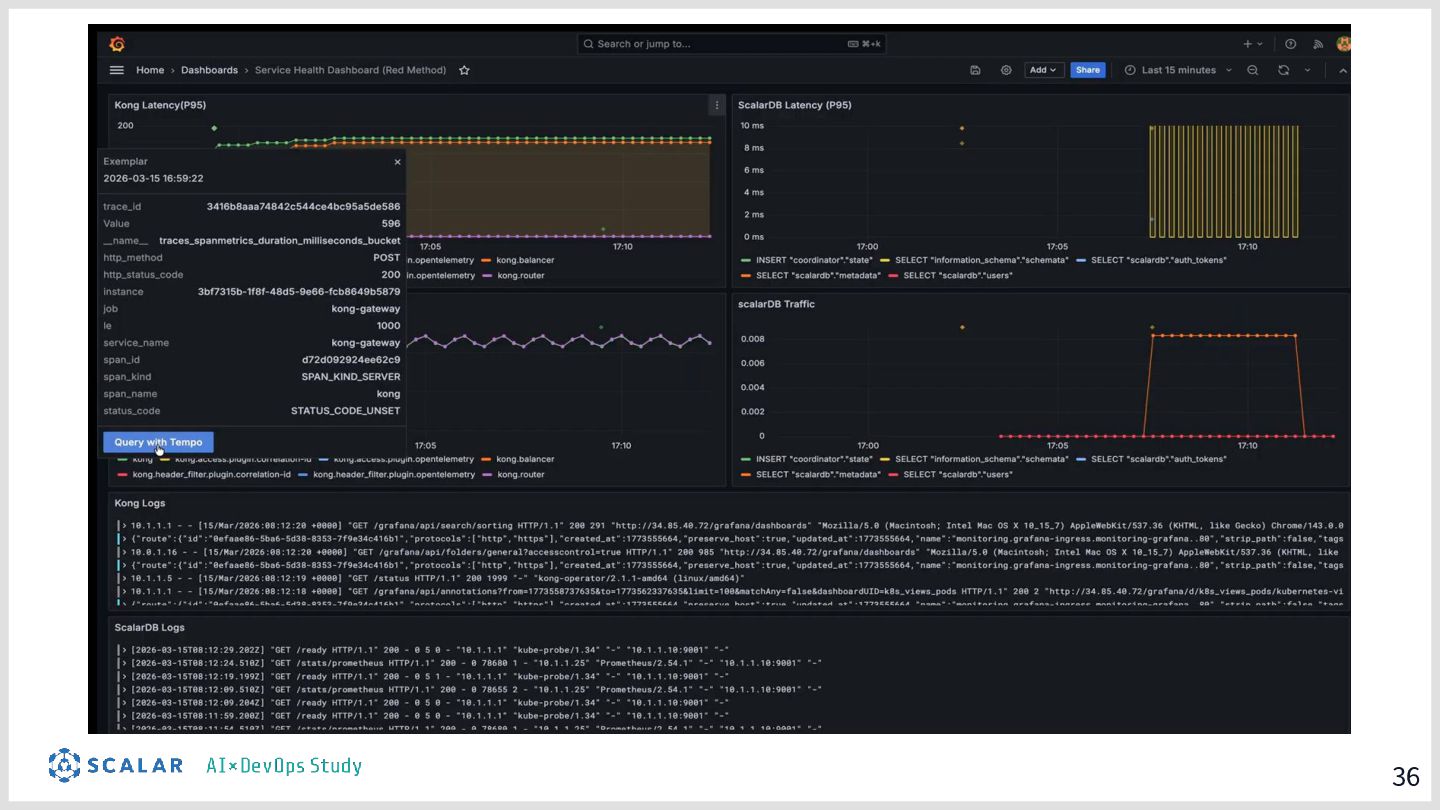
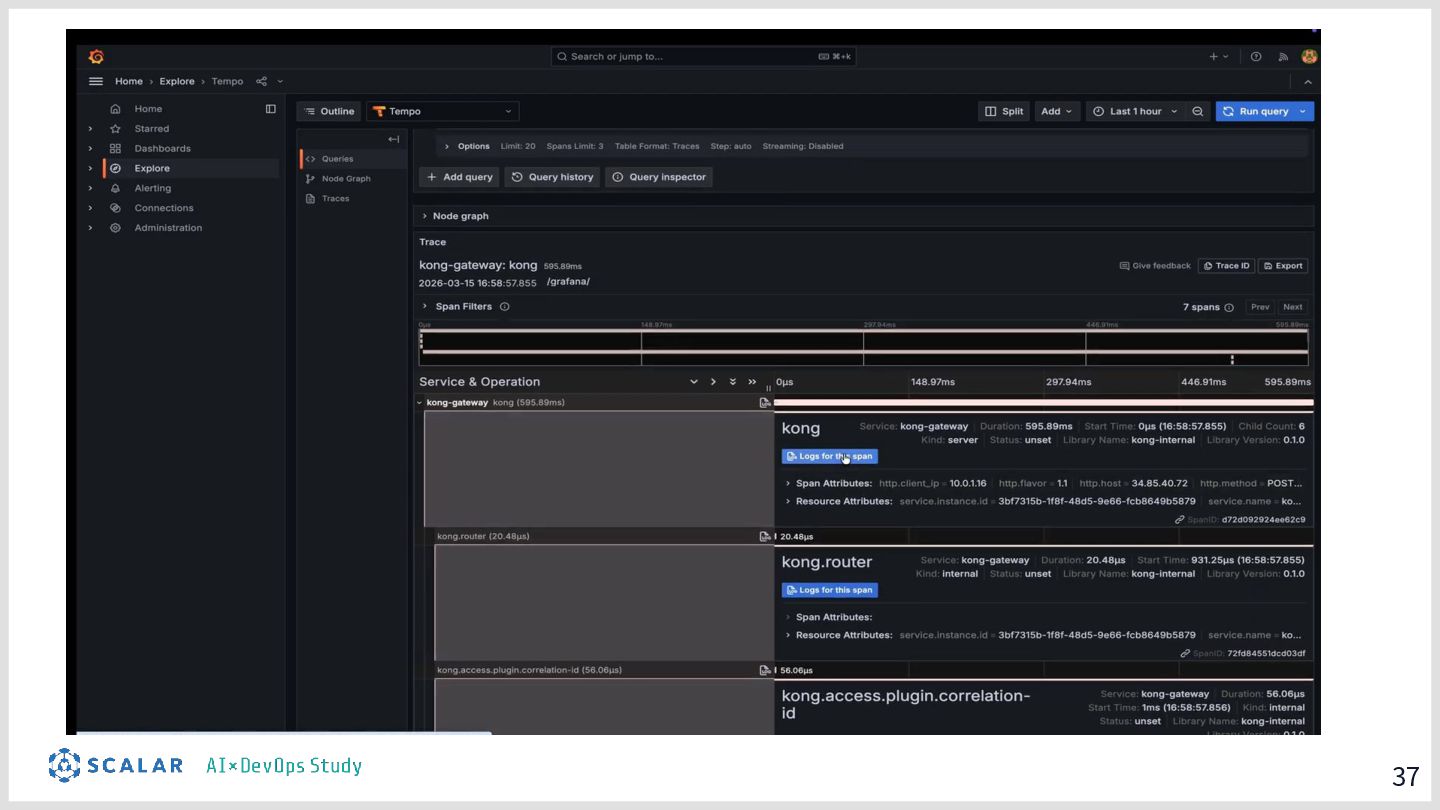
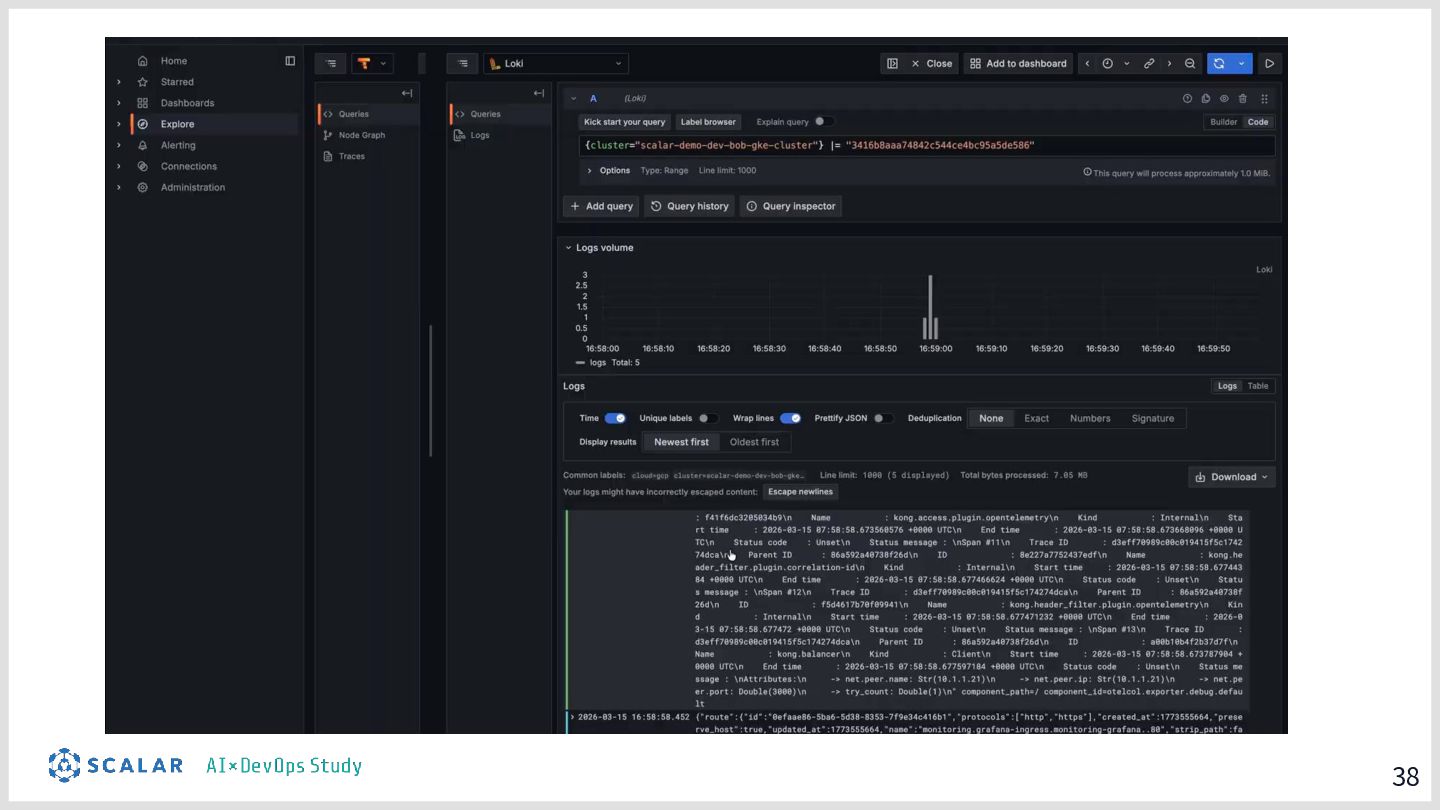
具体的には、GitLab CI/ArgoCD による全自動デプロイ、Blue/Green デプロイによるゼロダウンタイムリリース、Kong Gateway・Keycloak・HashiCorp Vault によるセキュリティ基盤、そして Loki・Tempo・Grafana を活用した可観測性スタックを取り上げます。
■登壇者情報(敬称略)
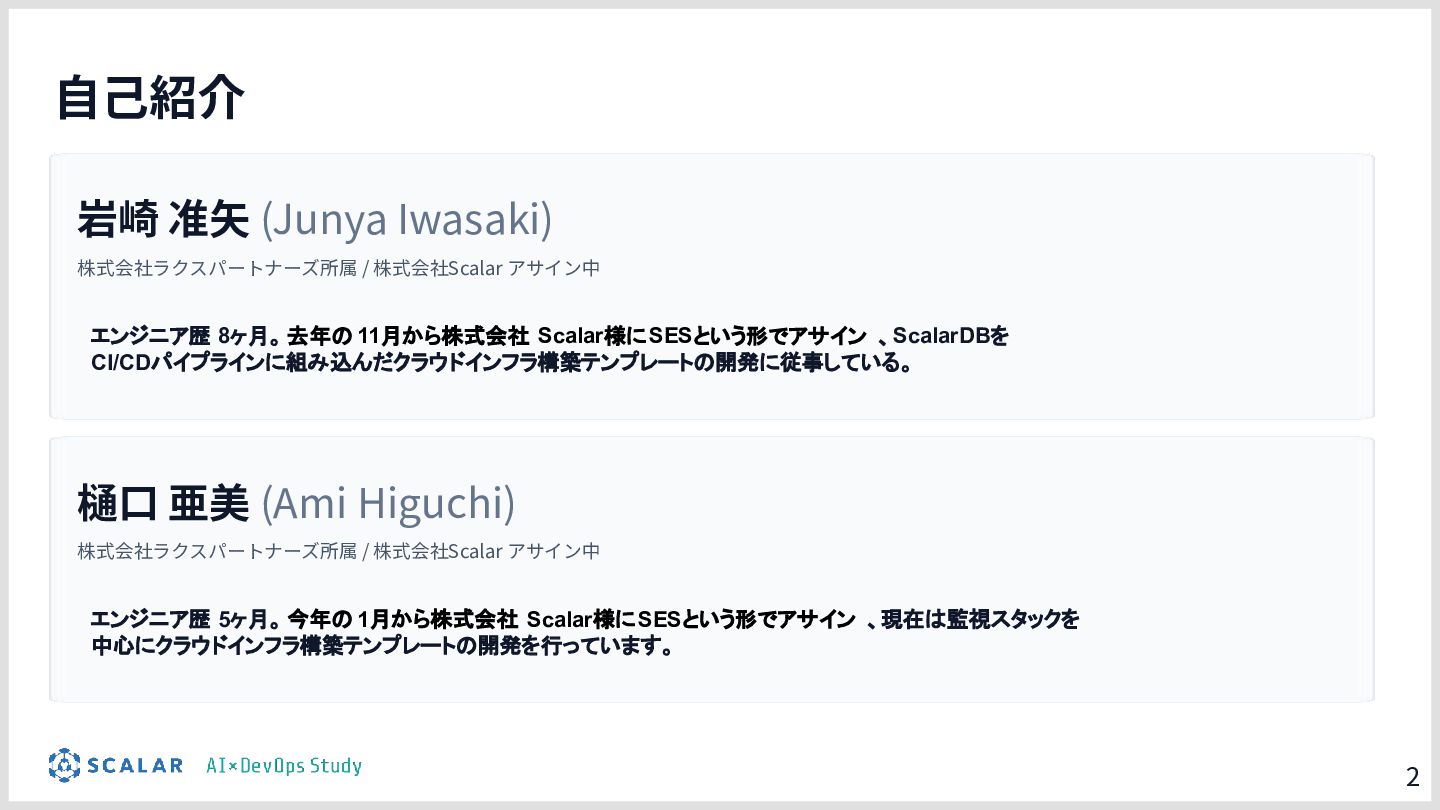
岩崎
株式会社ラクスパートナーズ クラウドエンジニア。異業界の営業職を経て、2025年7月よりエンジニアとしてのキャリアをスタートし、エンジニア歴8ヶ月。現在は株式会社Scalarにて、ScalarDBをCI/CDパイプラインに組み込んだクラウドインフラ構築テンプレートの開発に従事している。GitLabを活用した自動化の実践を通じ、ScalarDBの導入をより円滑にするための最適なアーキテクチャ設計と運用の効率化を探求中。
樋口
株式会社ラクスパートナーズ クラウドエンジニア。株式会社ラクスパートナーズ クラウドエンジニア。異業界の看護師を経て、AIの可能性に惹かれてこの世界に飛び込みました。2025年10月よりエンジニアとしてのキャリアをスタートし、エンジニア歴5ヶ月。現在は監視スタックを中心にクラウドインフラ構築テンプレートの開発を行っています。わからないことだらけの中でも、「なぜこの仕組みが必要なのか」を大切にしながら日々探求しています。
■関連コンテンツ
Youtube
www.youtube.com/@scalar-labs
Zenn ブログ
https://zenn.dev/p/scalar_sol_blog
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}