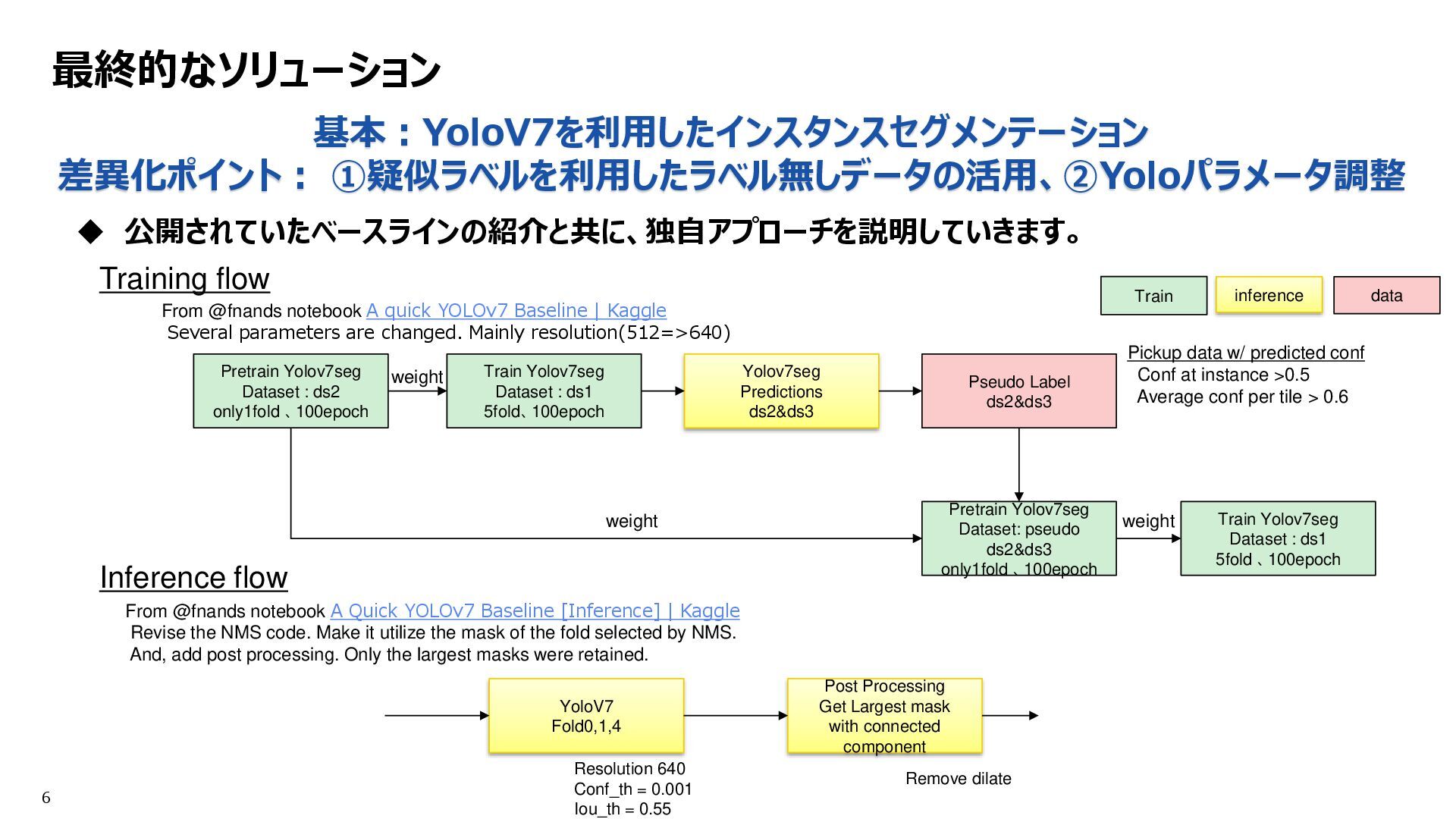
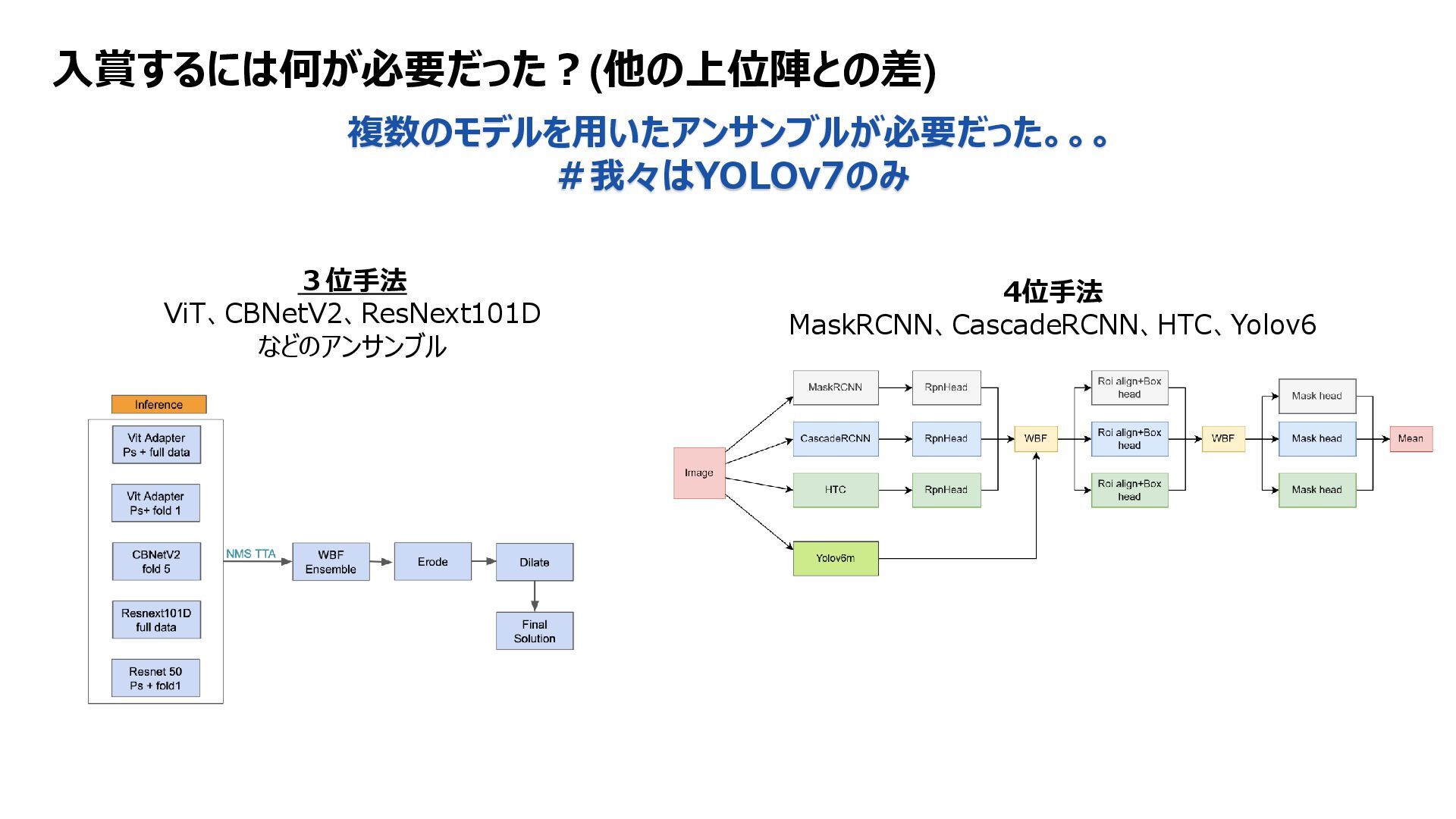
: ds2 only1fold 、100epoch Yolov7seg Predictions ds2&ds3 Pseudo Label ds2&ds3 Train Yolov7seg Dataset : ds1 5fold、100epoch Pretrain Yolov7seg Dataset: pseudo ds2&ds3 only1fold 、100epoch weight Train Yolov7seg Dataset : ds1 5fold 、100epoch Inference flow weight YoloV7 Fold0,1,4 Post Processing Get Largest mask with connected component From @fnands notebook A quick YOLOv7 Baseline | Kaggle Several parameters are changed. Mainly resolution(512=>640) From @fnands notebook A Quick YOLOv7 Baseline [Inference] | Kaggle Revise the NMS code. Make it utilize the mask of the fold selected by NMS. And, add post processing. Only the largest masks were retained. Resolution 640 Conf_th = 0.001 Iou_th = 0.55 weight Pickup data w/ predicted conf Conf at instance >0.5 Average conf per tile > 0.6 Remove dilate Training flow inference Train data
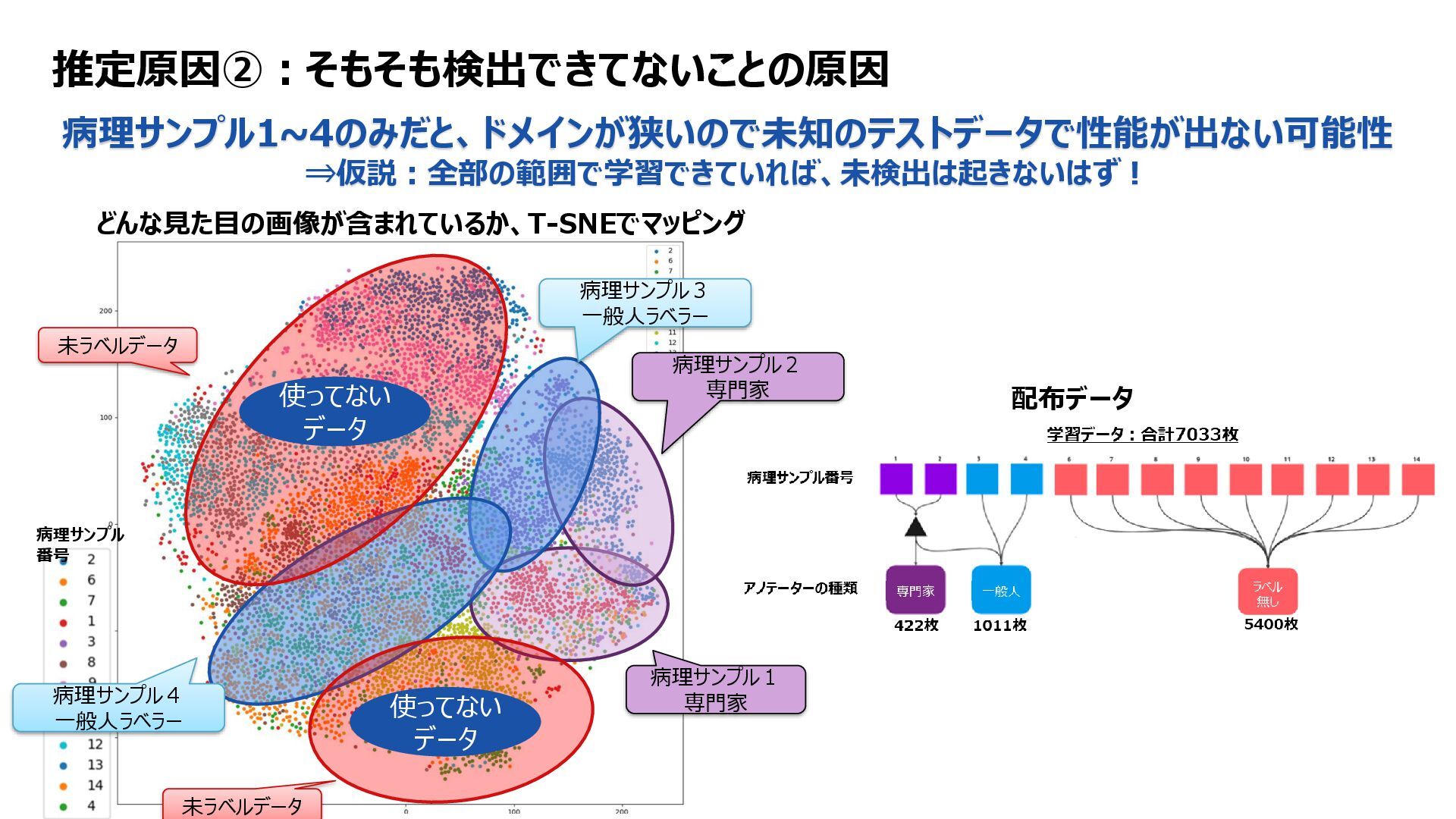
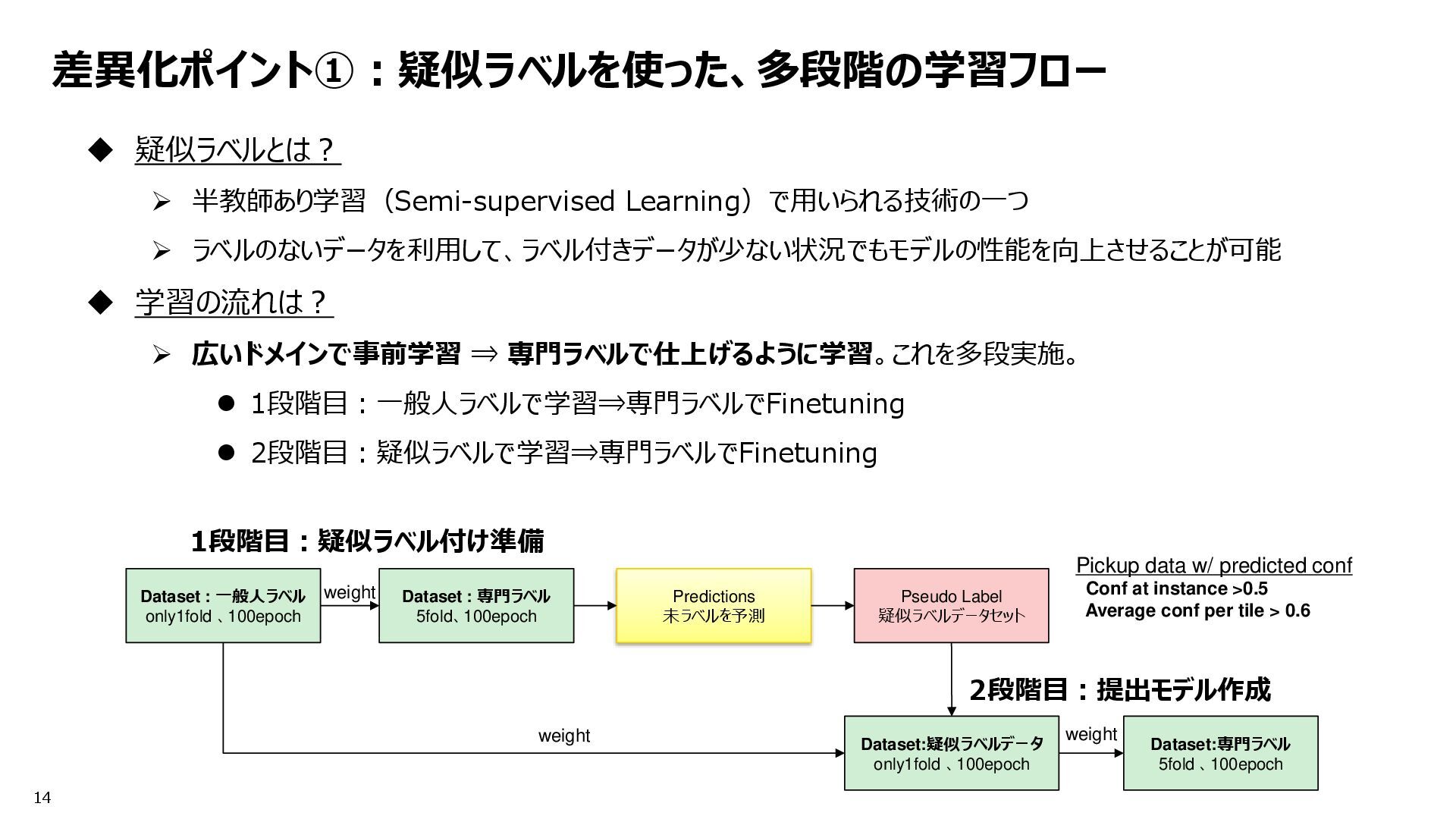
: ds2 only1fold 、100epoch Yolov7seg Predictions ds2&ds3 Pseudo Label ds2&ds3 Train Yolov7seg Dataset : ds1 5fold、100epoch Pretrain Yolov7seg Dataset: pseudo ds2&ds3 only1fold 、100epoch weight Train Yolov7seg Dataset : ds1 5fold 、100epoch Inference flow weight YoloV7 Fold0,1,4 Post Processing Get Largest mask with connected component From @fnands notebook A quick YOLOv7 Baseline | Kaggle Several parameters are changed. Mainly resolution(512=>640) From @fnands notebook A Quick YOLOv7 Baseline [Inference] | Kaggle Revise the NMS code. Make it utilize the mask of the fold selected by NMS. And, add post processing. Only the largest masks were retained. Resolution 640 Conf_th = 0.001 Iou_th = 0.55 weight Pickup data w/ predicted conf Conf at instance >0.5 Average conf per tile > 0.6 Remove dilate Training flow inference Train data 差異化ポイント①:疑似ラベルを使った、多段階の学習フロー 目的:データ品質バラつきへの対応、ドメイン拡大への対応 差異化ポイント②:パラメータ調整 目的:小さいサイズへの対応
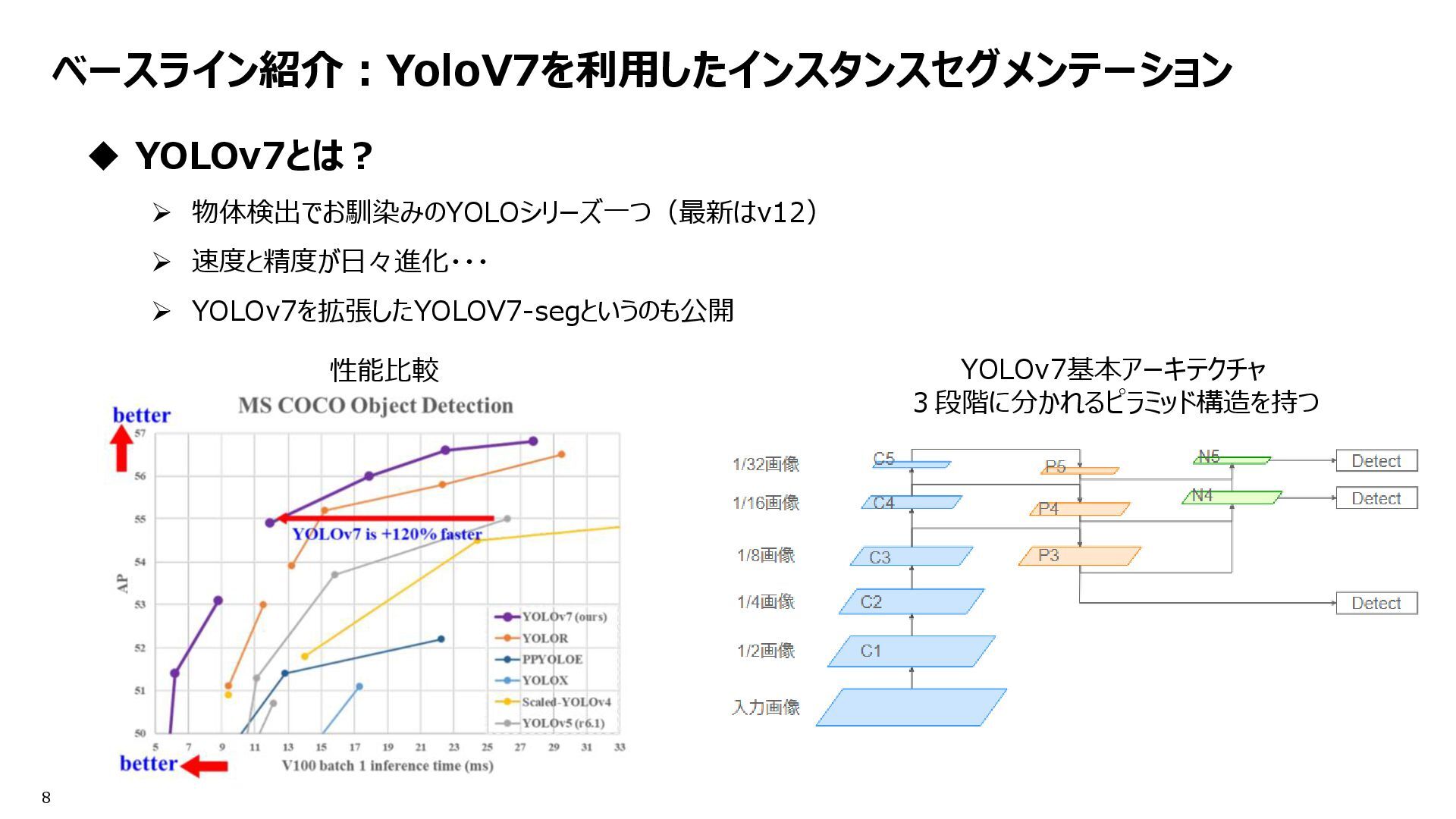
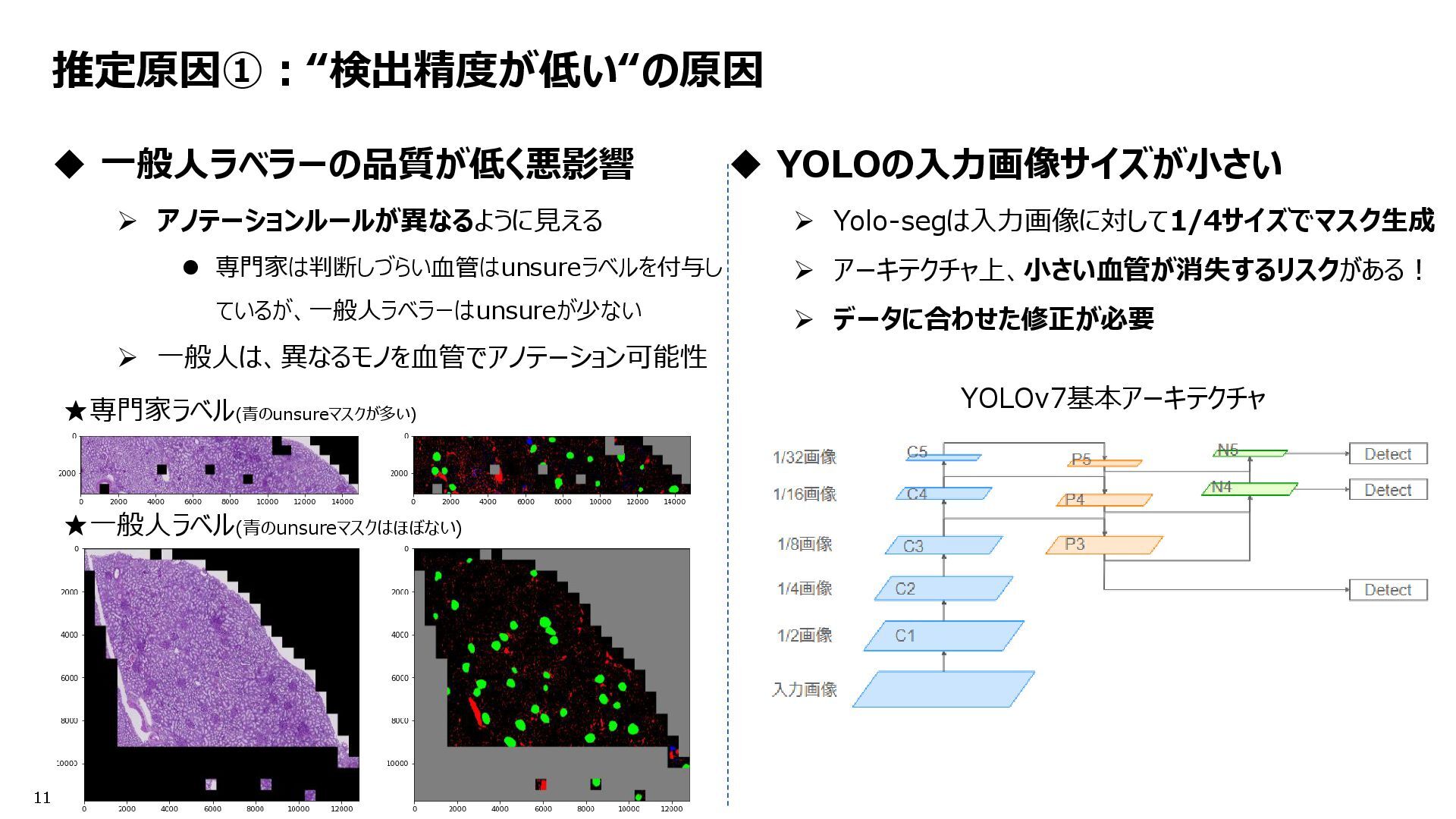
※ 配布画像は512x512だが、640x640にリサイズして推論。一見意味無さそうだけどある。 ➢ 目的:ネットワークアーキテクチャ的に消失リスクのある小さい物体への対応 Inference flow YoloV7 Fold0,1,4 Post Processing Get Largest mask with connected component From @fnands notebook A Quick YOLOv7 Baseline [Inference] | Kaggle Revise the NMS code. Make it utilize the mask of the fold selected by NMS. And, add post processing. Only the largest masks were retained. Resolution 640 Conf_th = 0.001 Iou_th = 0.55 Remove dilate YOLOv7基本アーキテクチャ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}