C L A Y E R × D R L 出発点 ― 認識を合わせるところから始めた データ基盤の役割が変わる 従来 人間が分析する場 ・人間が解釈できる品質、わからないことはData OwnerかGit blame で人づてに聞くことも ・メタデータやメトリクス定義は各種ドキュメントに分散、コンテキ ストを都度人が与えてAIが探しに行く ・利用はしているが、活用しきれていないデータ/dbt modelの散在 → これから AI が自律的に活用する場 ・AI が解釈できる品質、AIがアクセスできないなら無いのと同等 ・メタデータやメトリクス定義は基盤に統合 or Skillsに集約など、シ ステム境界を人間が設計し、AIが自律して探しやすく ・AI Readableの上で、不要なデータはノイズ。壊しやすく安全な modelが載せられる基盤を 既存基盤との主なギャップ ― 信頼できるメトリクス定義の散在 / メタデータ不足 / 利用状況が不明なモデルの蓄積。 このギャップを埋める活動として、プロジェクトを発足した。 18 / 36
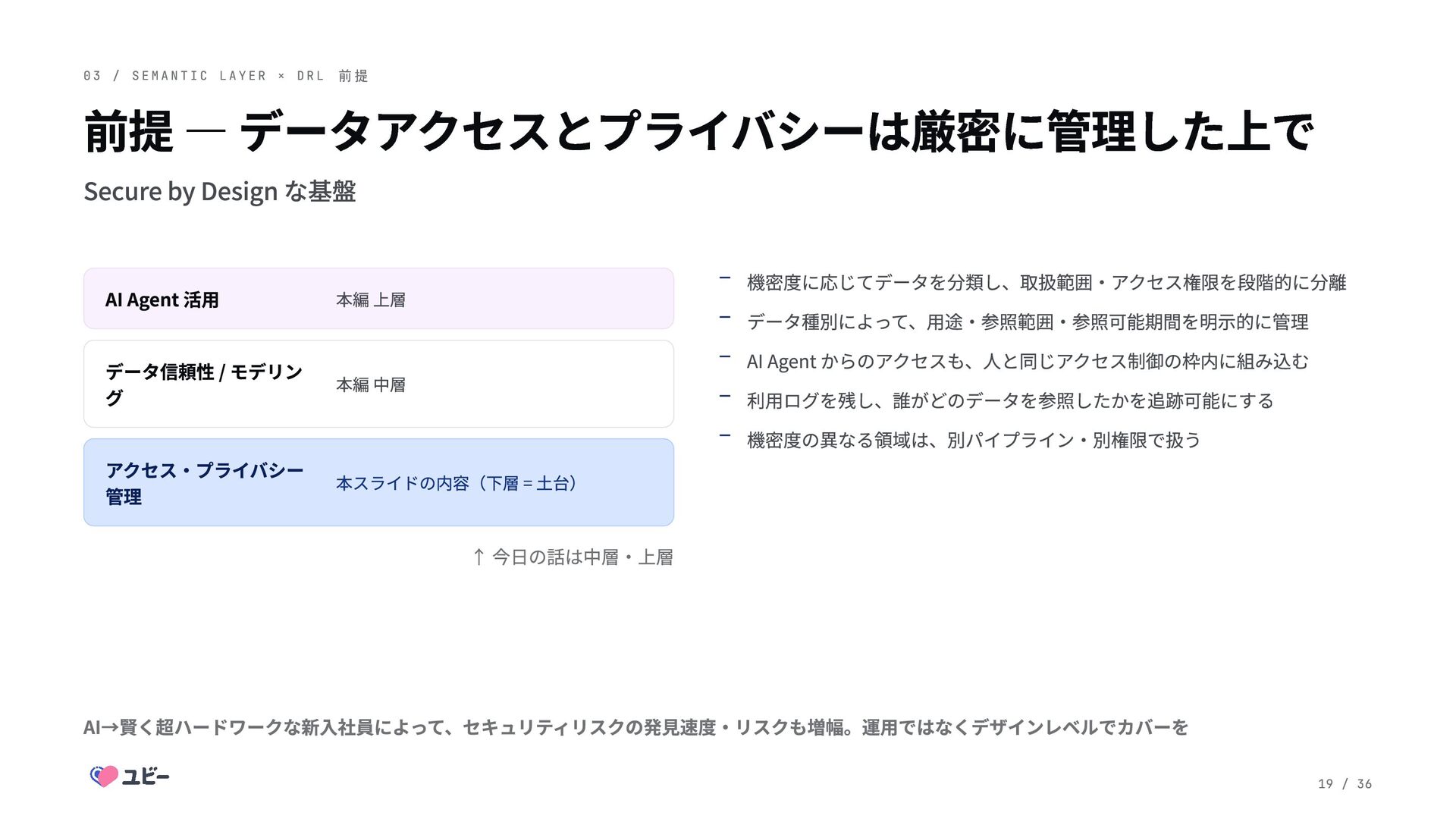
C L A Y E R × D R L 前 提 前提 ― データアクセスとプライバシーは厳密に管理した上で Secure by Design な基盤 AI Agent 活用 本編 上層 データ信頼性 / モデリン グ 本編 中層 アクセス・プライバシー 管理 本スライドの内容(下層 = 土台) ↑ 今日の話は中層・上層 AI→賢く超ハードワークな新入社員によって、セキュリティリスクの発見速度・リスクも増幅。運用ではなくデザインレベルでカバーを 機密度に応じてデータを分類し、取扱範囲・アクセス権限を段階的に分離 データ種別によって、用途・参照範囲・参照可能期間を明示的に管理 AI Agent からのアクセスも、人と同じアクセス制御の枠内に組み込む 利用ログを残し、誰がどのデータを参照したかを追跡可能にする 機密度の異なる領域は、別パイプライン・別権限で扱う 19 / 36
C L A Y E R × D R L 整えてみて分かった難題 全てを整える続けるのは難しい モデリングガイドライン整備、活用事例の創出、不要モデルの片付けをする中、整えるだけでは届かない領域が見えてきた: 01 組織構造上、規律の徹底度にばらつきが 出る 事業の変化・チーミングの変化が激しく、ガイド ラインを敷いても完全には解消されない。中央のル ールが、各チームに同じ濃度で浸透しきらない。 02 全データを同じ濃度で品質づけしようと すると、持続不能 リソース有限な中、 すべてのテーブルに同じ投資をかけると結局どこも 届かない。 「全部を高品質に」が目的になることはない AIで全部なんとかする、もまだ遠い 03 データごとの品質・信頼性への要求が明 確でない 基盤的な「十分」の基準と、運用での「必要」の 基準のすり合わせ不足。 整備の到達点と実務での要求のミスマッチ。 → データに濃淡をつけて対応していく必要がありそう 22 / 36
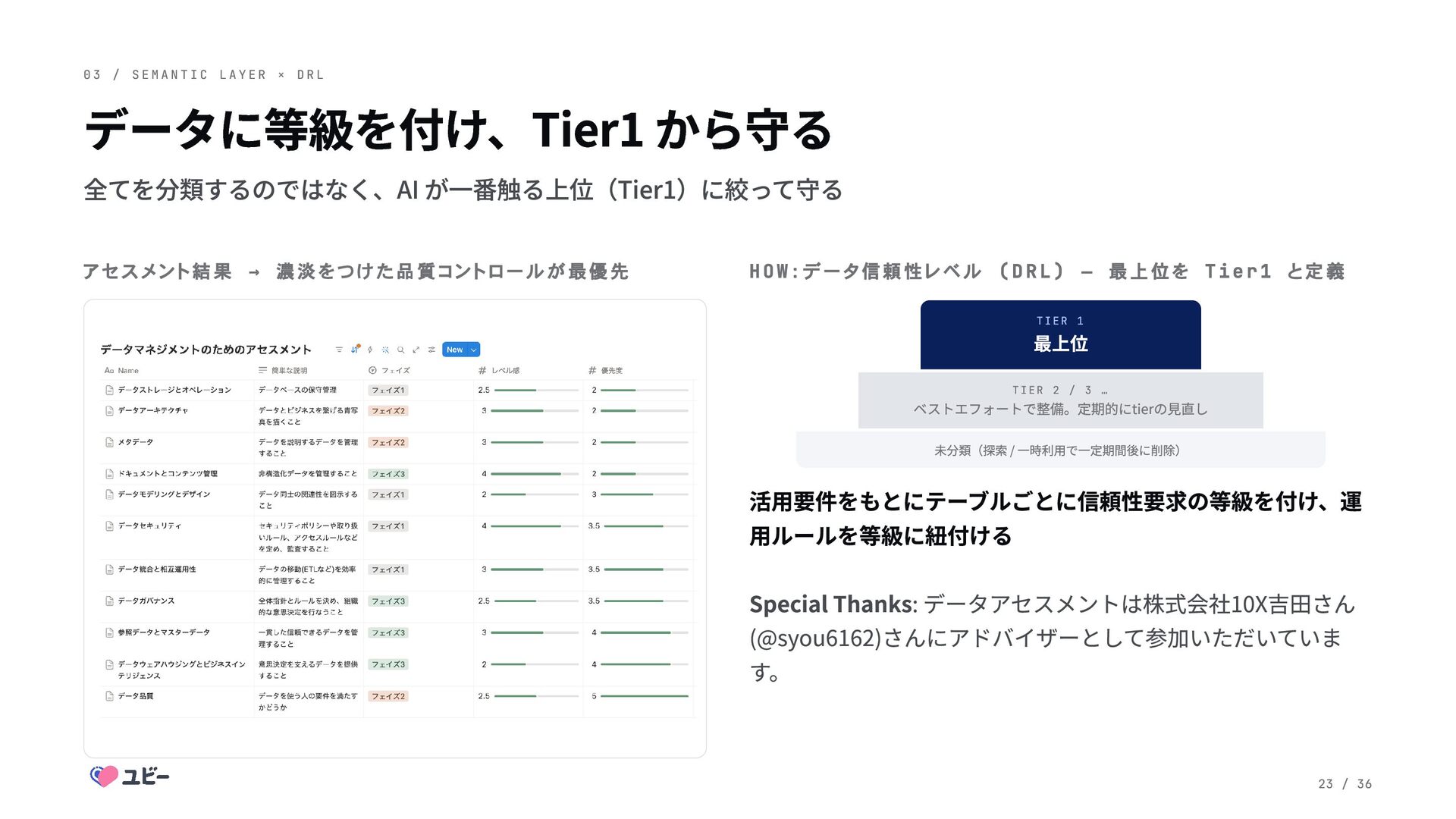
C L A Y E R × D R L データに等級を付け、Tier1 から守る 全てを分類するのではなく、AI が一番触る上位(Tier1)に絞って守る アセスメント結果 → 濃淡をつけた品質コントロールが最優先 HOW:データ信頼性レベル (DRL) ― 最上位を Tier1 と定義 TIER 1 最上位 TIER 2 / 3 … ベストエフォートで整備。定期的にtierの見直し 未分類(探索 / 一時利用で一定期間後に削除) 活用要件をもとにテーブルごとに信頼性要求の等級を付け、運 用ルールを等級に紐付ける Special Thanks: データアセスメントは株式会社10X吉田さん (@syou6162)さんにアドバイザーとして参加いただいていま す。 23 / 36
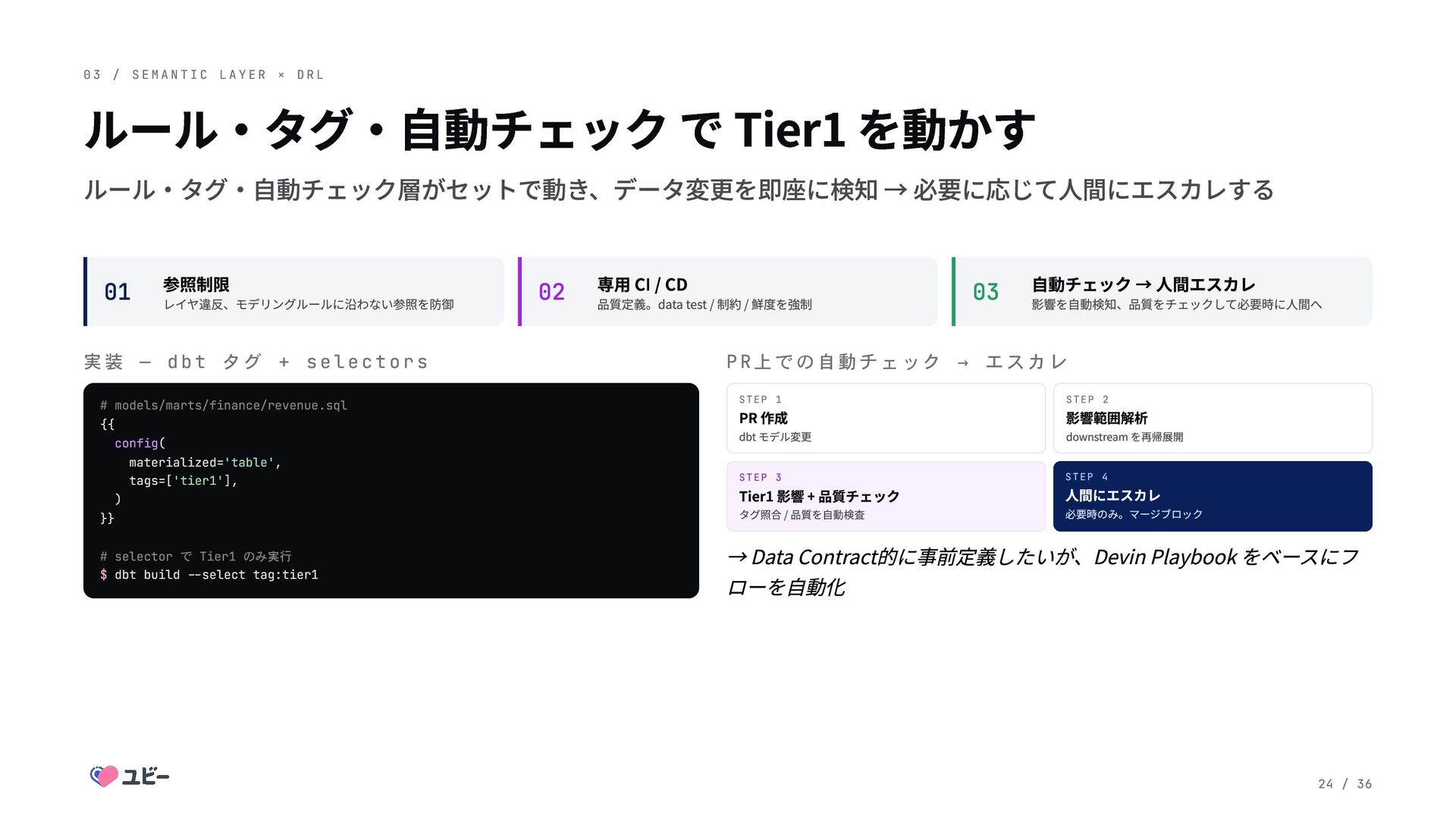
C L A Y E R × D R L PR レビューを AI Agent に任せる ― Devin Playbook 自動化を任せながらも、信頼性が必要な領域は AI Agent 側でガードする 背 景 Tier1データが依存先にあるような変更を、壊れる前に検知したい 課 題 Tier1データが依存先にあるような変更が、クエリの問題かデータの 問題か、どのくらい重大かわからない 解 決 Playbook に Tier1 タグの認識ルールを記述し リスクと重要度をコメ ントしてレビュアーに伝える。 dbtコードベースを読むだけでなく、 - "tags:tier1" で絞ったdbt lsコマンドの結果 - Application側のRepositoryの実装や、App DBの定義スクリプト も読ませ、精度を高める 25 / 36
C L A Y E R × D R L BI 層の棚卸しを AI Agent に任せる ― Lightdash Autopilot データ層と同じ思想を BI 層にも適用 ― 壊れ・古さ・修正を AI Agent が担う Autopilot が や っ て い る こ と Ubie で の 活 用 壊れたチャート / 古いチャートの自動検出 stale 検知(一定期間アクセスなし) スキーマ変更への修正提案 未使用ダッシュボードの棚卸し カラムリネームなど追従提案を確認 → 適用 BI 側でも「触らせるもの / 触らせないもの」を分離 参考 Lightdash Autopilot 公式 — docs.lightdash.com/guides/ai-agents/autopilot 26 / 36
C L A Y E R × D R L 進捗を継続的に可視化する データアセスメントを一回やって完成、ではない。変わりゆくボトルネックを解消し続ける 現 状 ✓ Data Reliablity Levelの定義とTier1ガードレール ✓ 品質影響検知・棚卸し自動化の開始 ✓ AI Agent設計プラクティスの創出 道 半 ば … dbt modelとMaster Data Managementの境界分割 … Tier定義対象拡大(複数ドメイン / 横断指標) … Semantic Layerの拡大 27 / 36
“That’s where discipline in modeling, validation, and ownership becomes a requirement, not a best practice.” modeling, validation, ownershipがmustな時代へ そのデザインをし続けるのがデータエンジニア / アナリティクスエンジニアの仕事 参考 https://www.getdbt.com/blog/new-dbt-labs-report-finds-ai-driven-acceleration-is-outpacing-trust-and-governance 36 / 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}