Vaswani et al. (2017), “Attention Is All You Need”, arxiv: 1706.03762 [41] Noam Shazeer (2019), “Fast Transformer Decoding: One Write-Head is All You Need”, arxiv: 1911.02150 [42] shubham ashok gandhi, “Multi-Head vs Multi-Query vs Grouped Query Attention”, アクセス日:2025/10/21 [43] Joshua Ainslie et al. (2023), “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”, arxiv: 2305.13245 [44] Aixin Liu et al. (2024), “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model”, arxiv: 2405.04434 [45] Iz Beltagy et al. (2020), “Longformer: The Long-Document Transformer”, arxiv: 2004.05150 [46] Sebastian Raschka, “Gemma 3 270M From Scratch”, アクセス日:2025/10/21 [47] DeepSeek-AI (2025), “DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention”,アクセス日:2025/10/21 [48] Aaron Blakeman et al. (2025), “Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models”, arxiv: 2504.03624 [49] Omkaar Kamath, “The Illustrated LFM-2 (by Liquid AI)”, アクセス日:2025/10/21 [50] Qwen Team, “Qwen3-Next: Towards Ultimate Training & Inference Efficiency”, アクセス日:2025/10/21 [51] Weilin Cai et al. (2024), “A Survey on Mixture of Experts in Large Language Models”, arxiv: 2407.06204 [52] Hugging Face, “meta-llama/Llama-4-Scout-17B-16E”, アクセス日:2025/10/23 [53] Aixin Liu et al. (2024), “DeepSeek-V3 Technical Report”, arxiv: 2412.19437 [54] Felix Abecassis et al. (2025), “Pretraining Large Language Models with NVFP4”, arxiv: 2509.25149 [55] Zeyu Han et al. (2024), “Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey”, arxiv: 2403.14608 [56] Edward J. Hu et al. (2021), “LoRA: Low-Rank Adaptation of Large Language Models”, arxiv: 2106.09685 [57] Tim Dettmers et al. (2023), “QLoRA: Efficient Finetuning of Quantized LLMs”, arxiv: 2305.14314 [58] Yixiao Li et al. (2023), “LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models”, arxiv: 2310.08659 [59] Damjan Kalajdzievski (2023), “A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA”, arxiv: 2312.03732
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
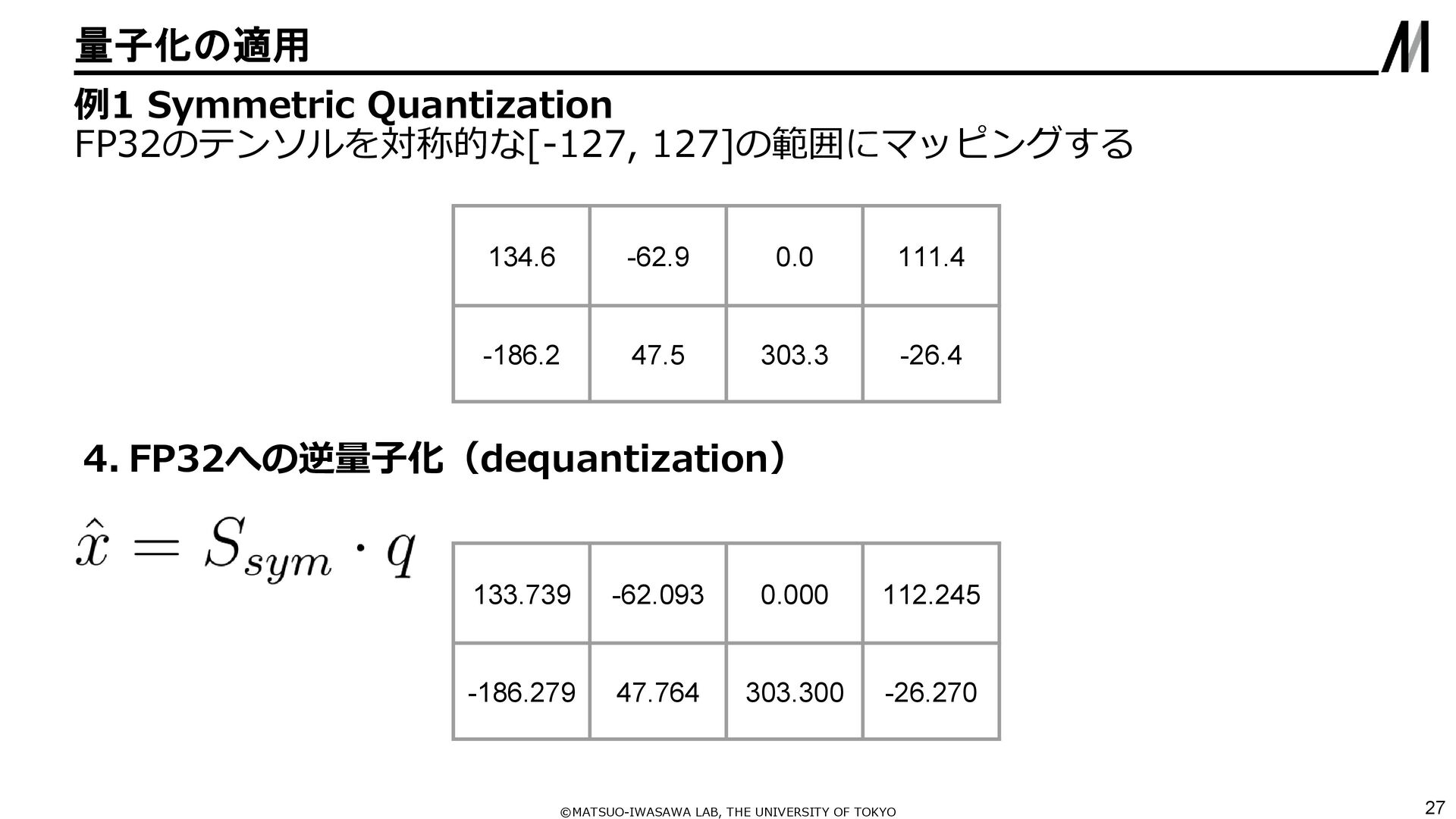{kind=link}
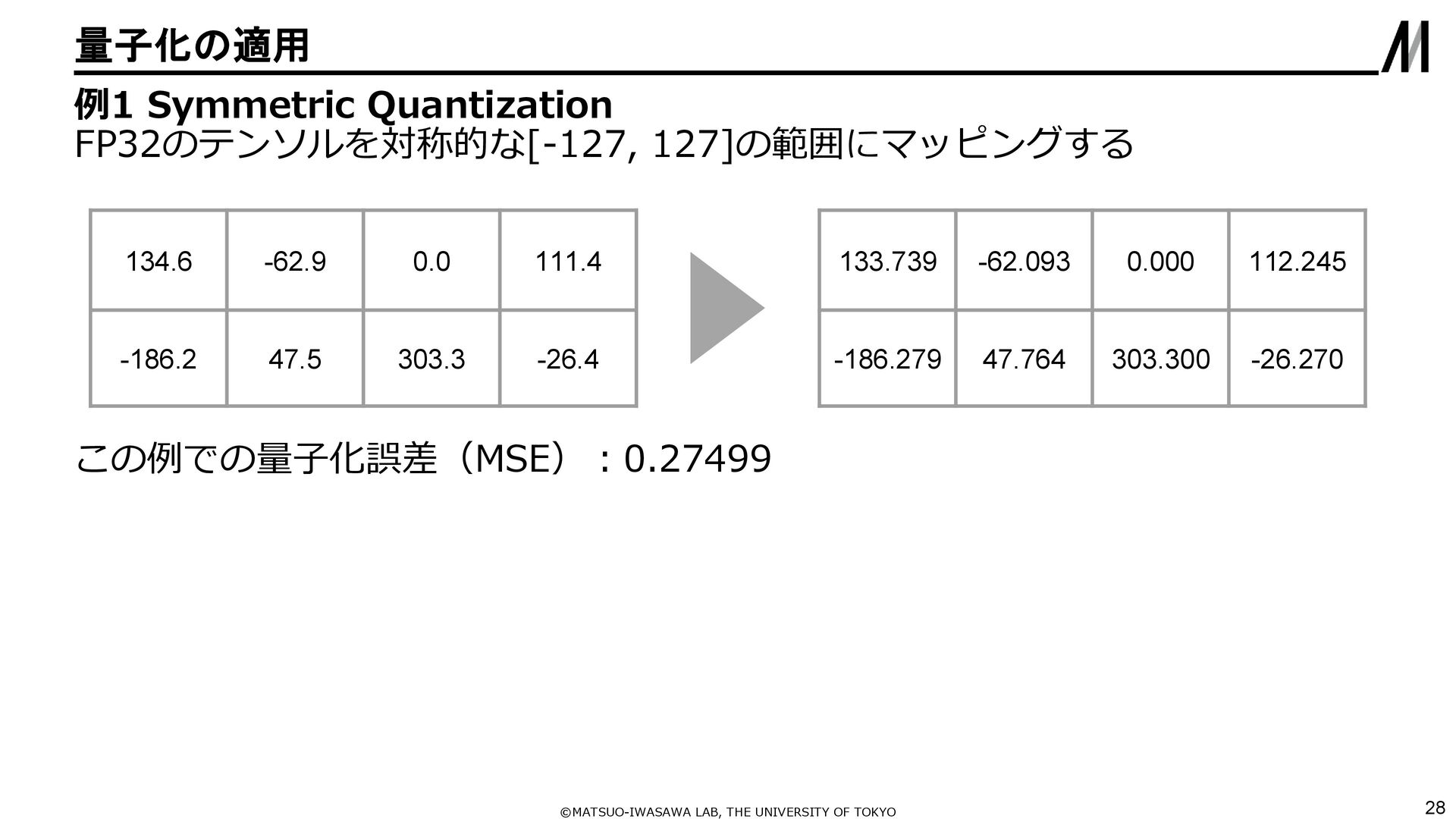{kind=link}
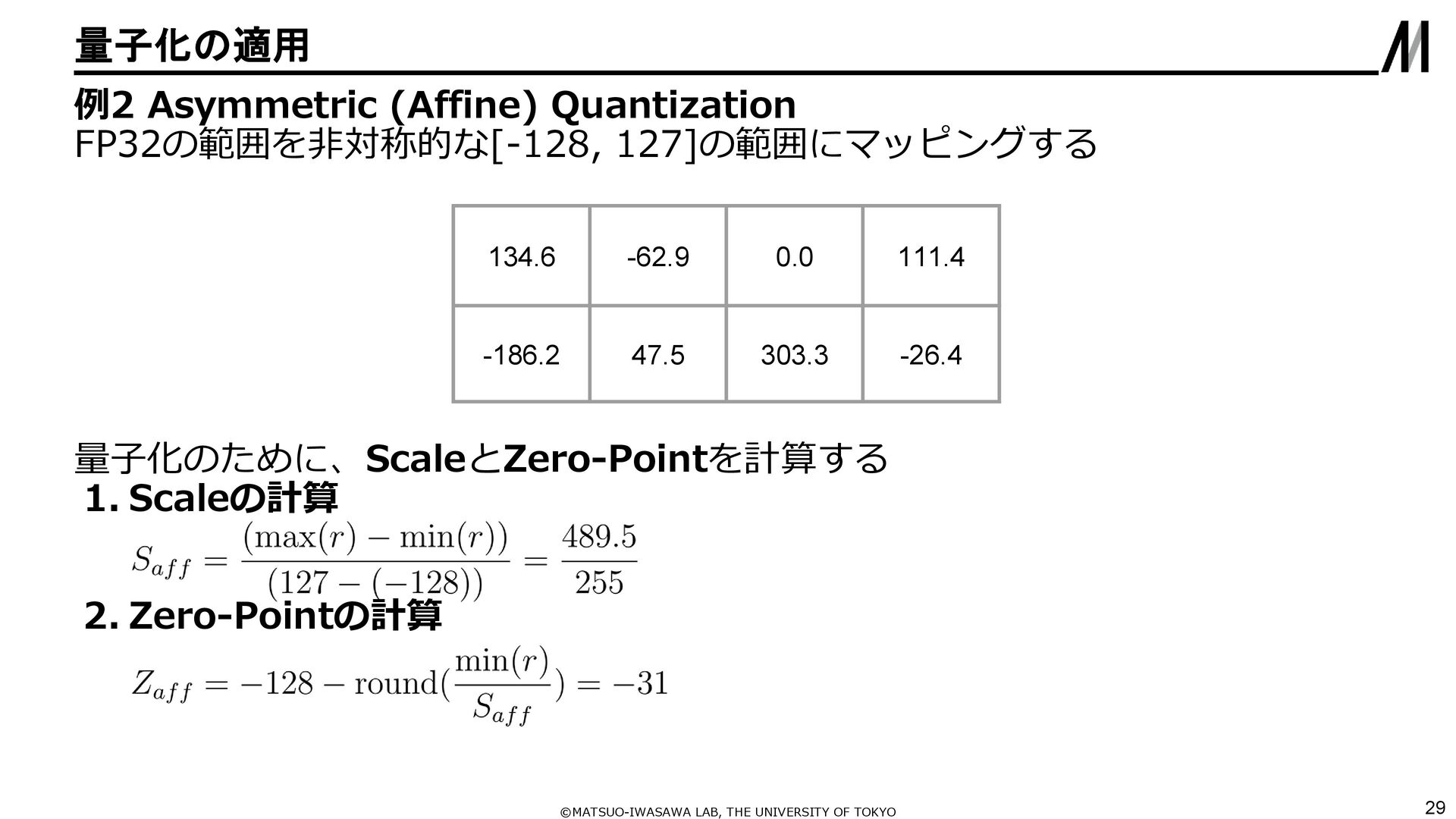{kind=link}
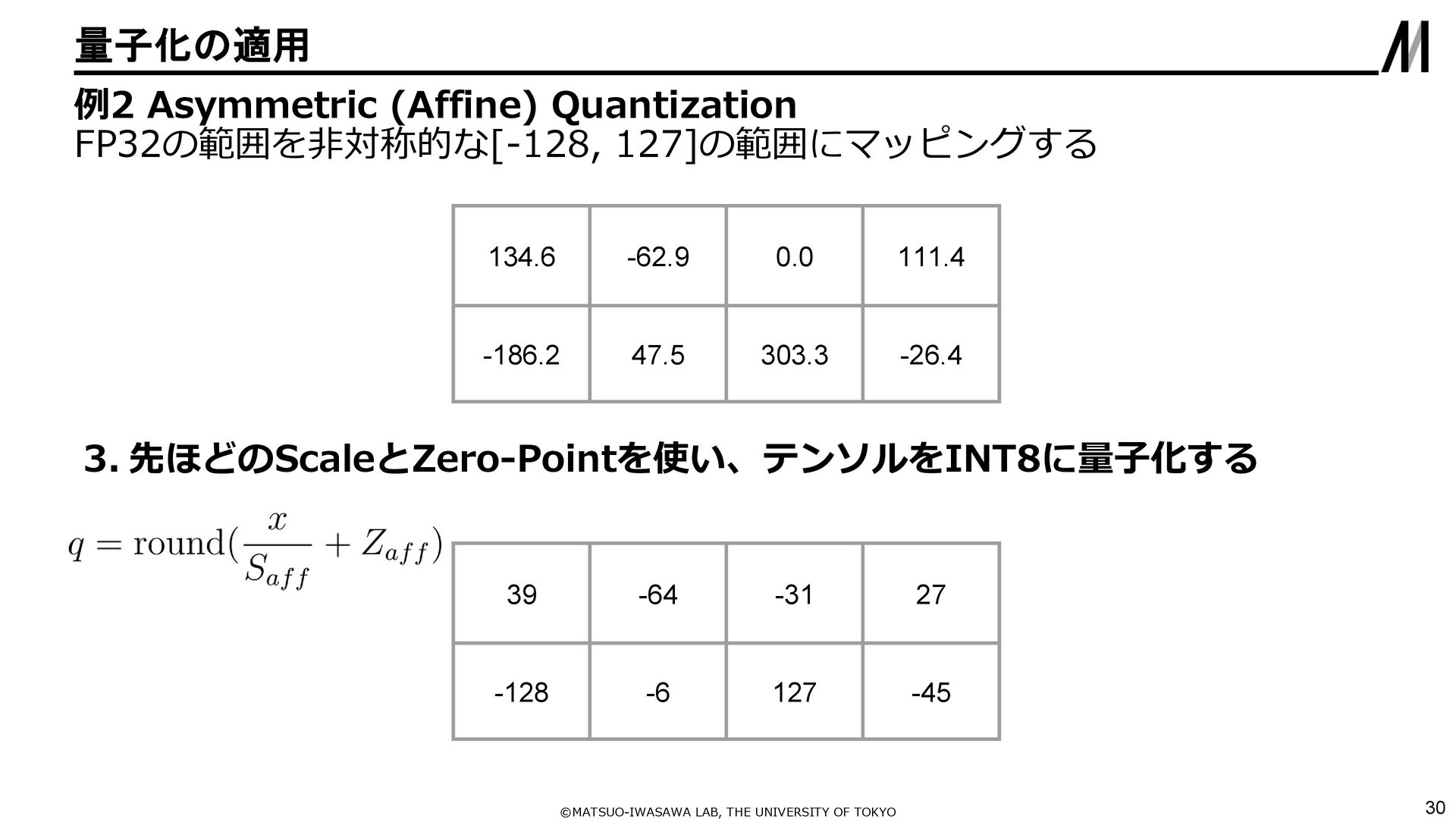{kind=link}
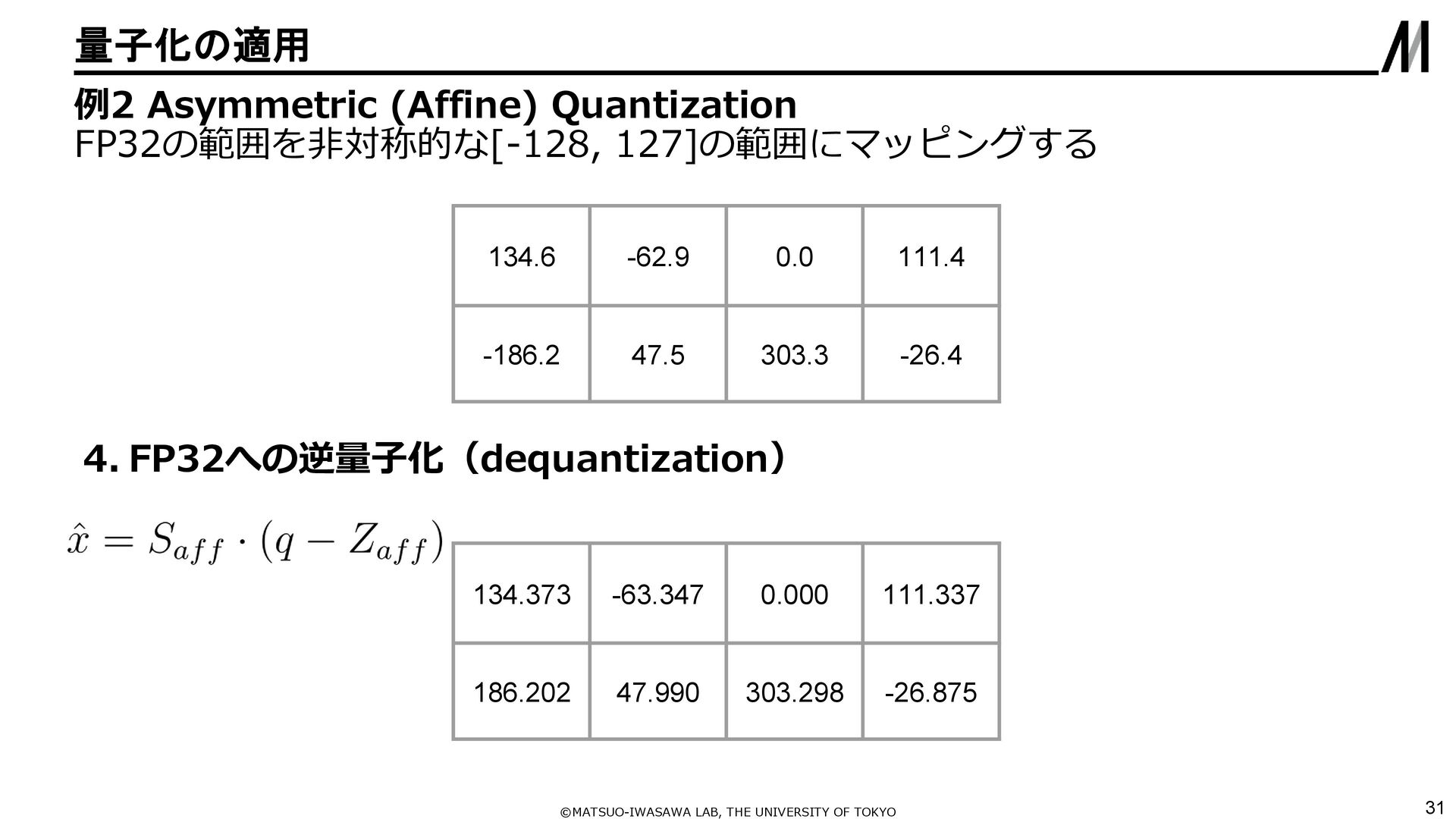{kind=link}
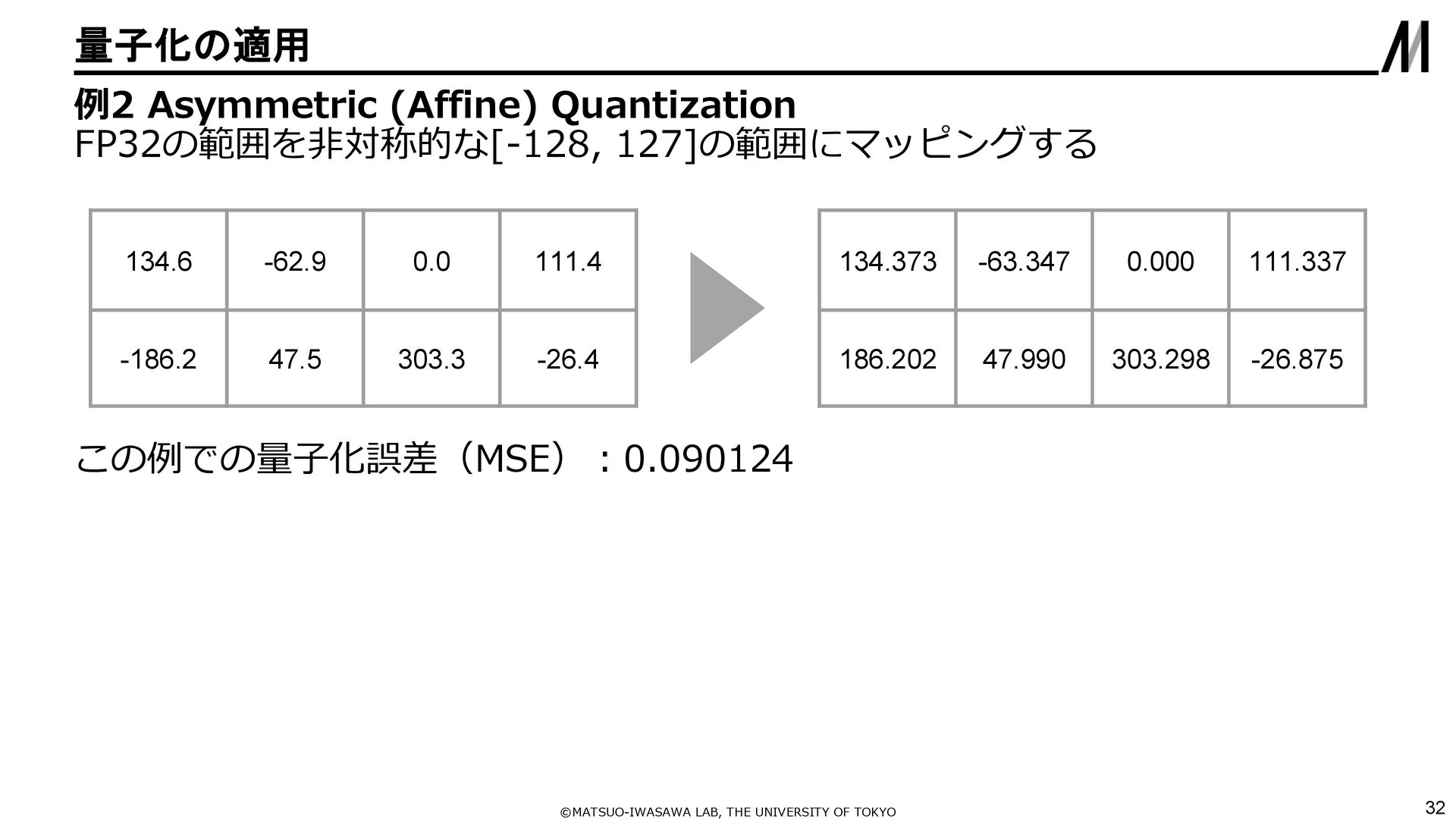{kind=link}
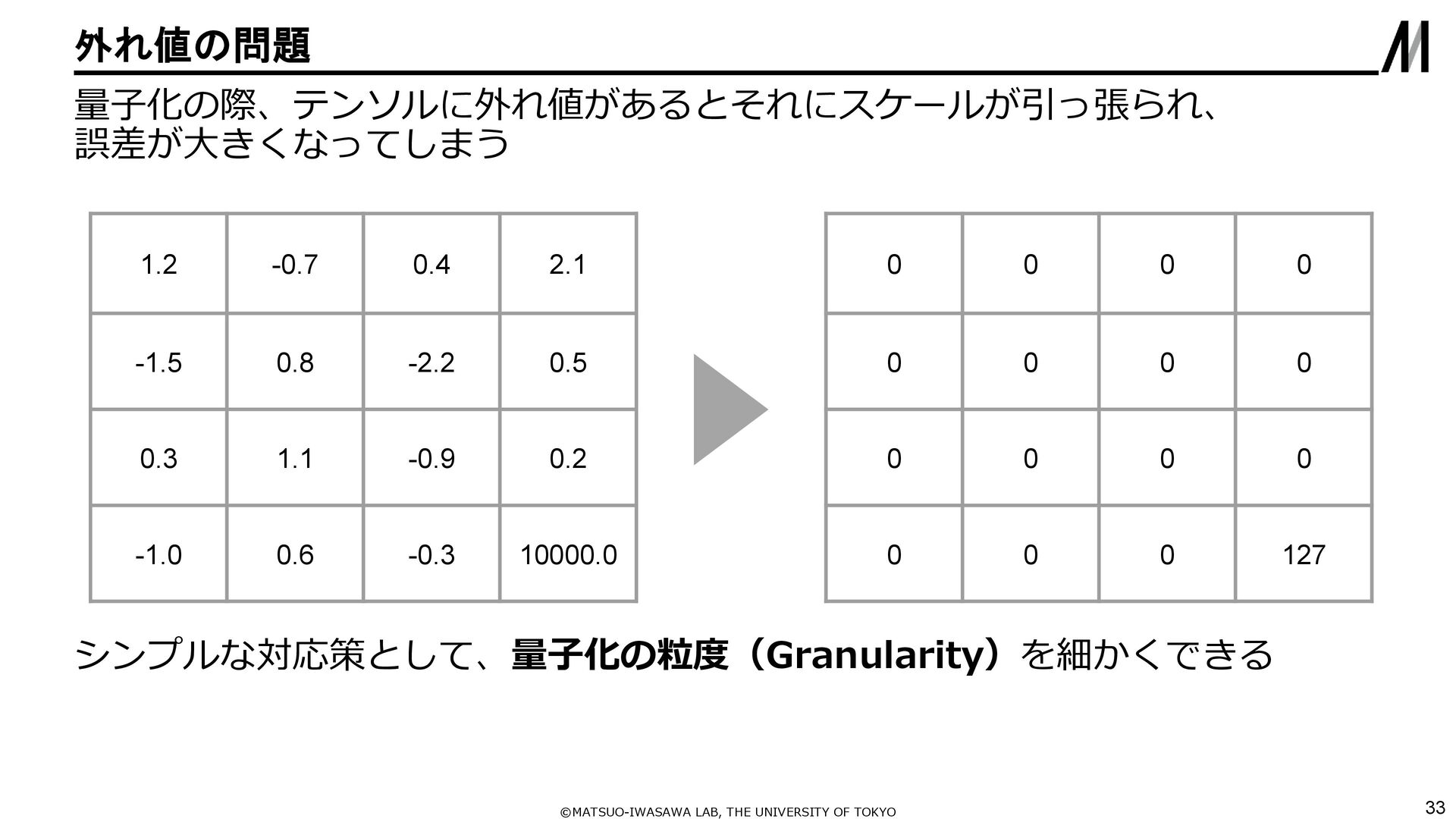{kind=link}
{kind=link}
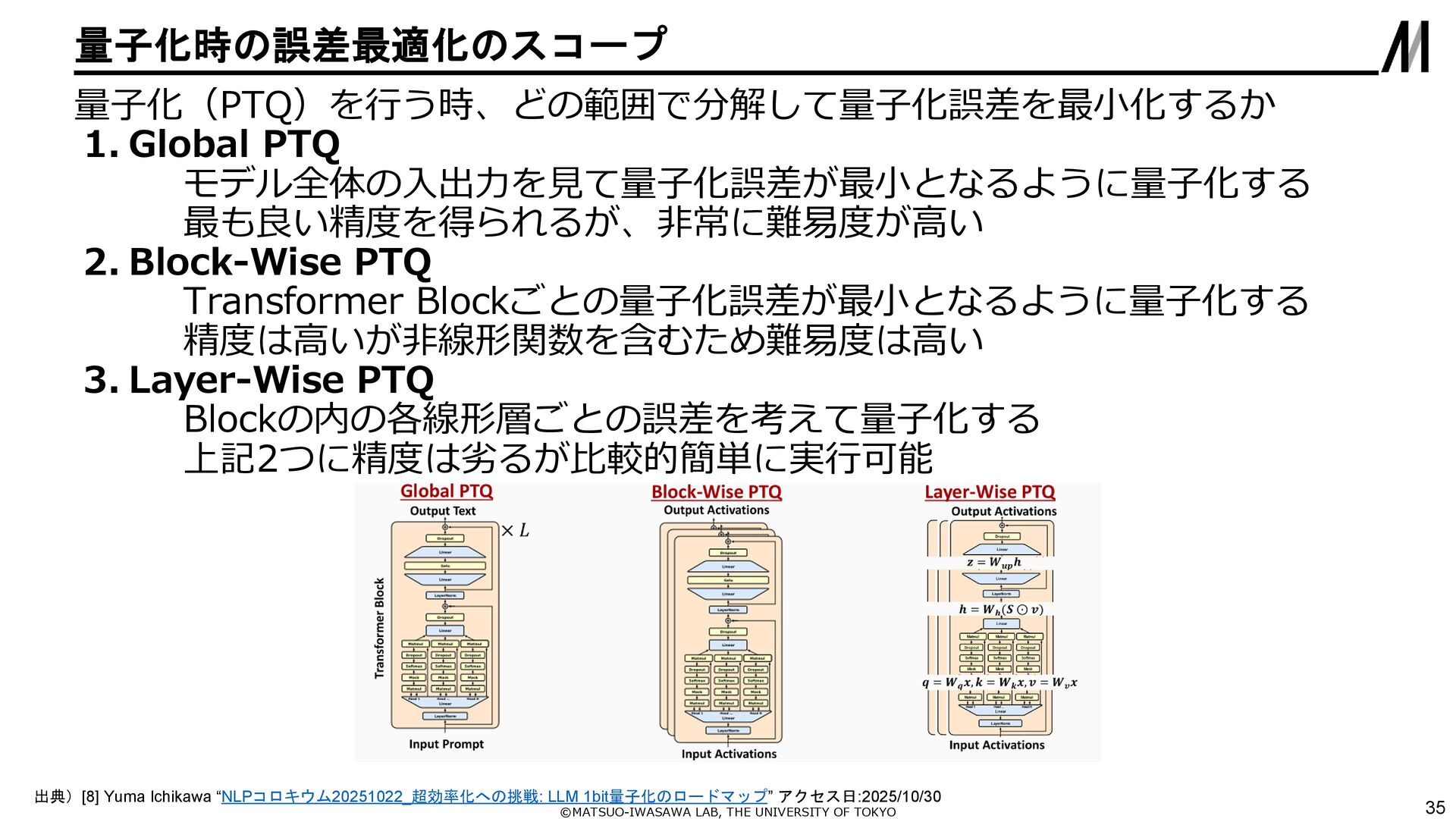{kind=link}
{kind=link}
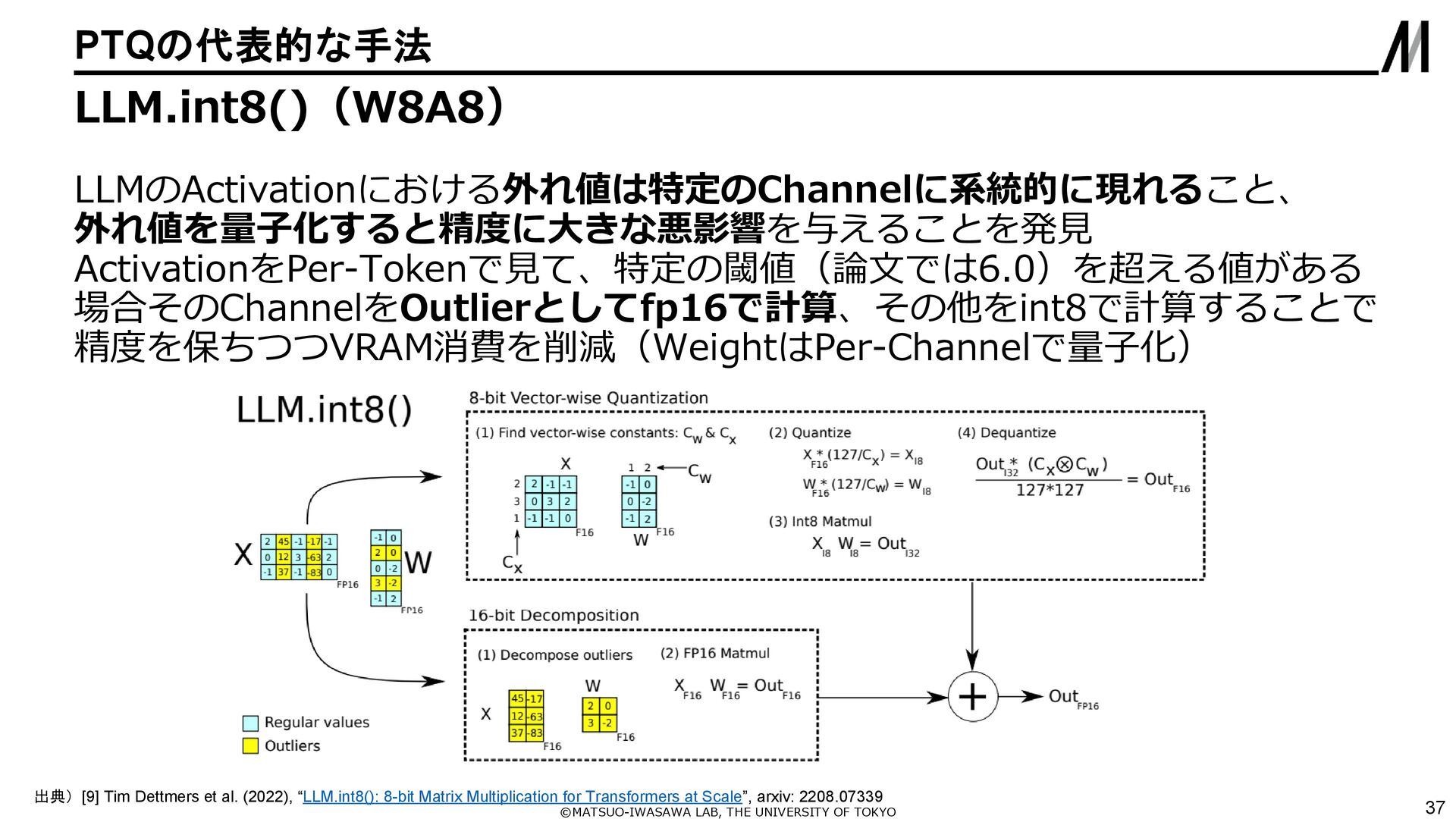{kind=link}
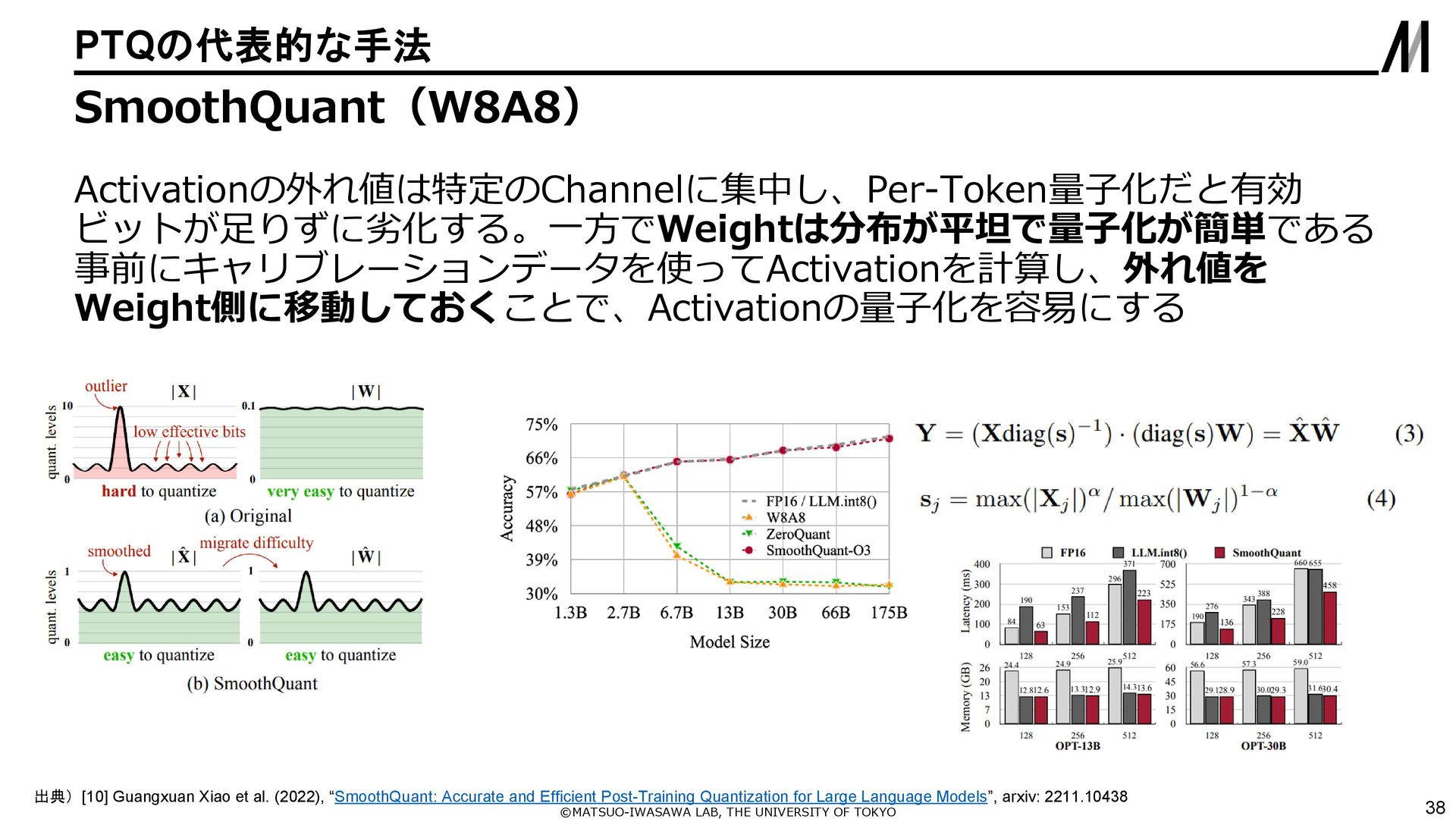{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
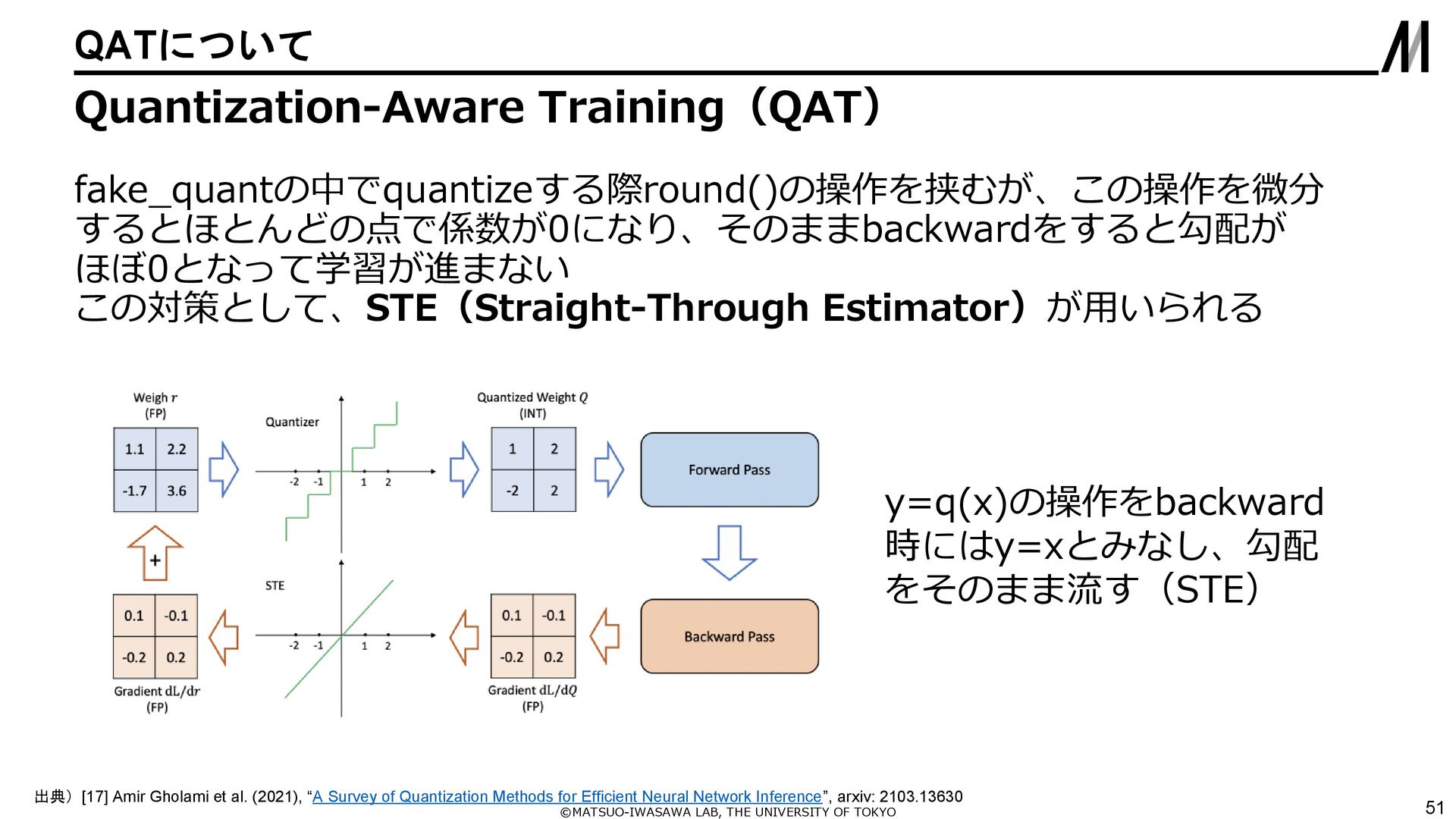{kind=link}
{kind=link}
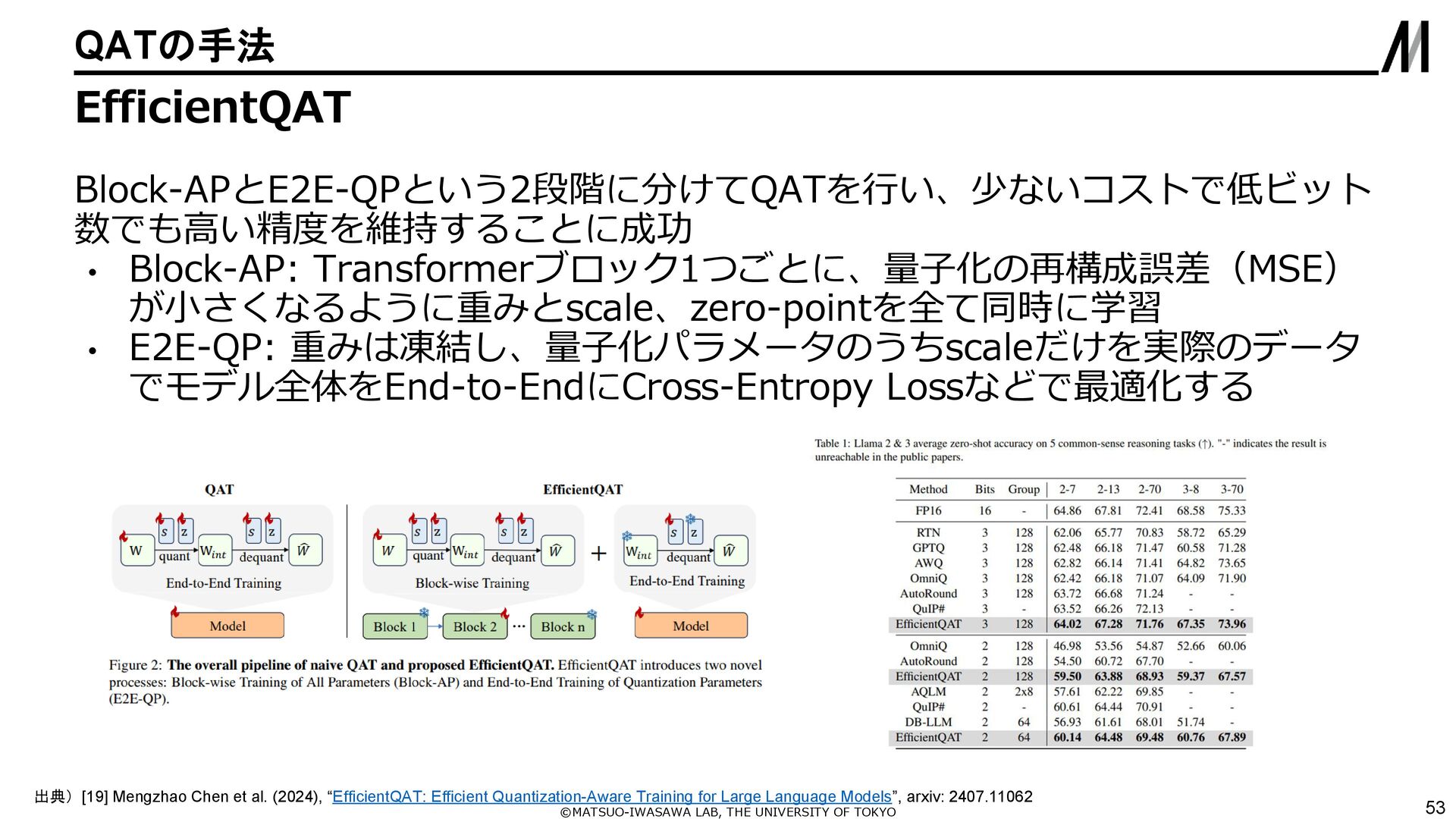{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
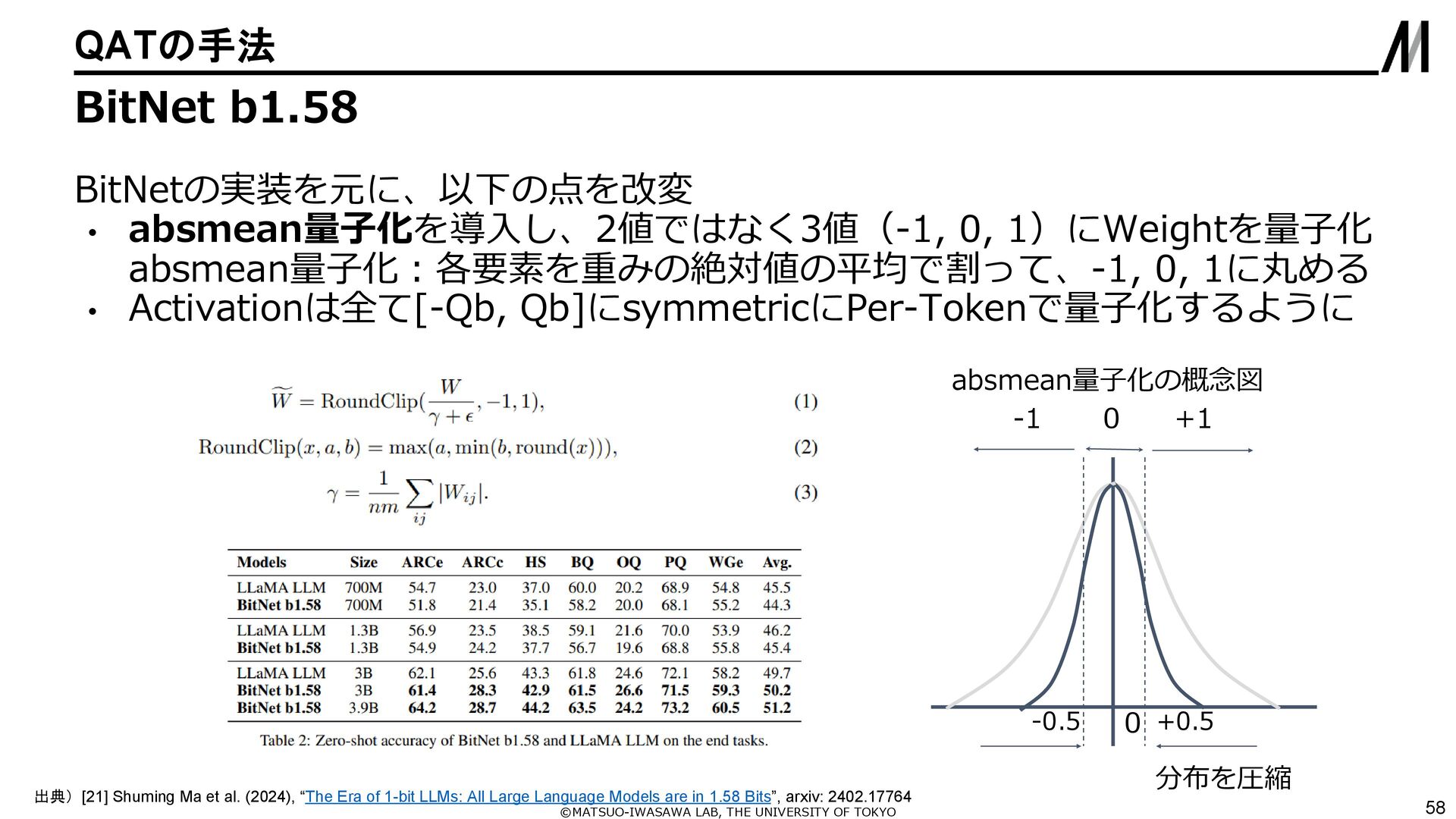{kind=link}
{kind=link}
{kind=link}
{kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 62 出典)[24] https://github.com/ggml-org/llama.cpp/wiki/Tensor-Encoding-Schemes, アクセス日:2025/10/15](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
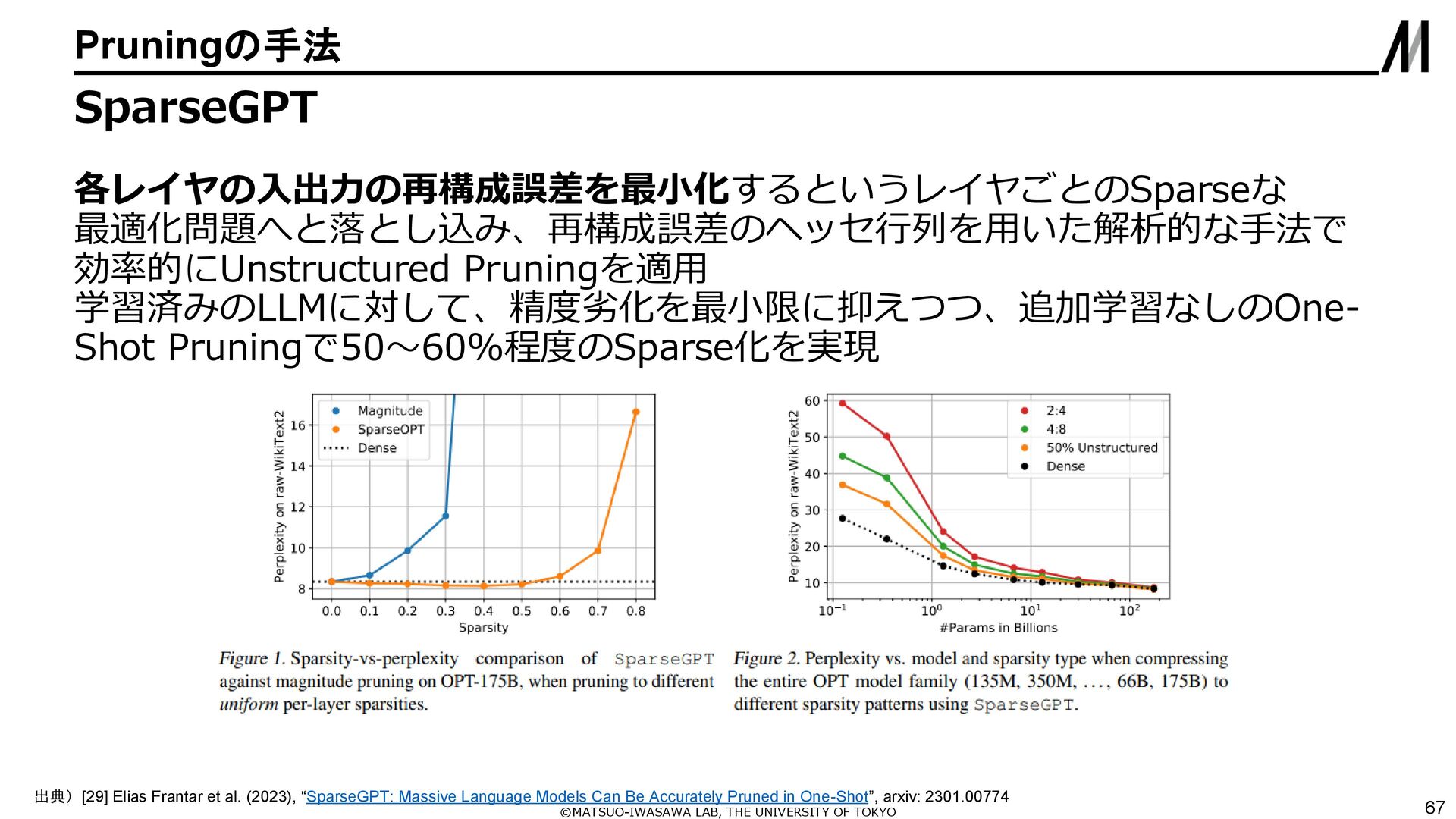{kind=link}
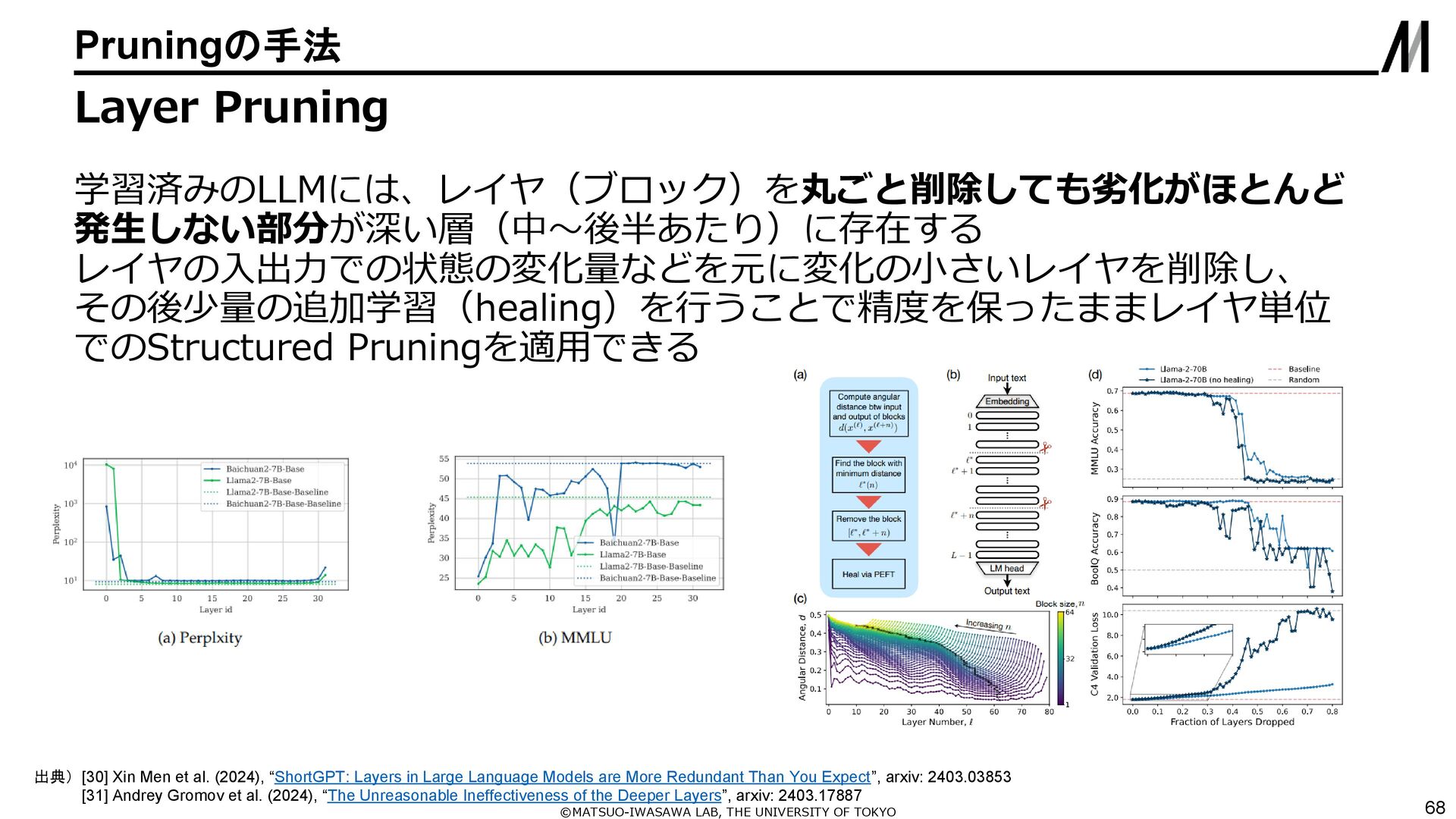{kind=link}
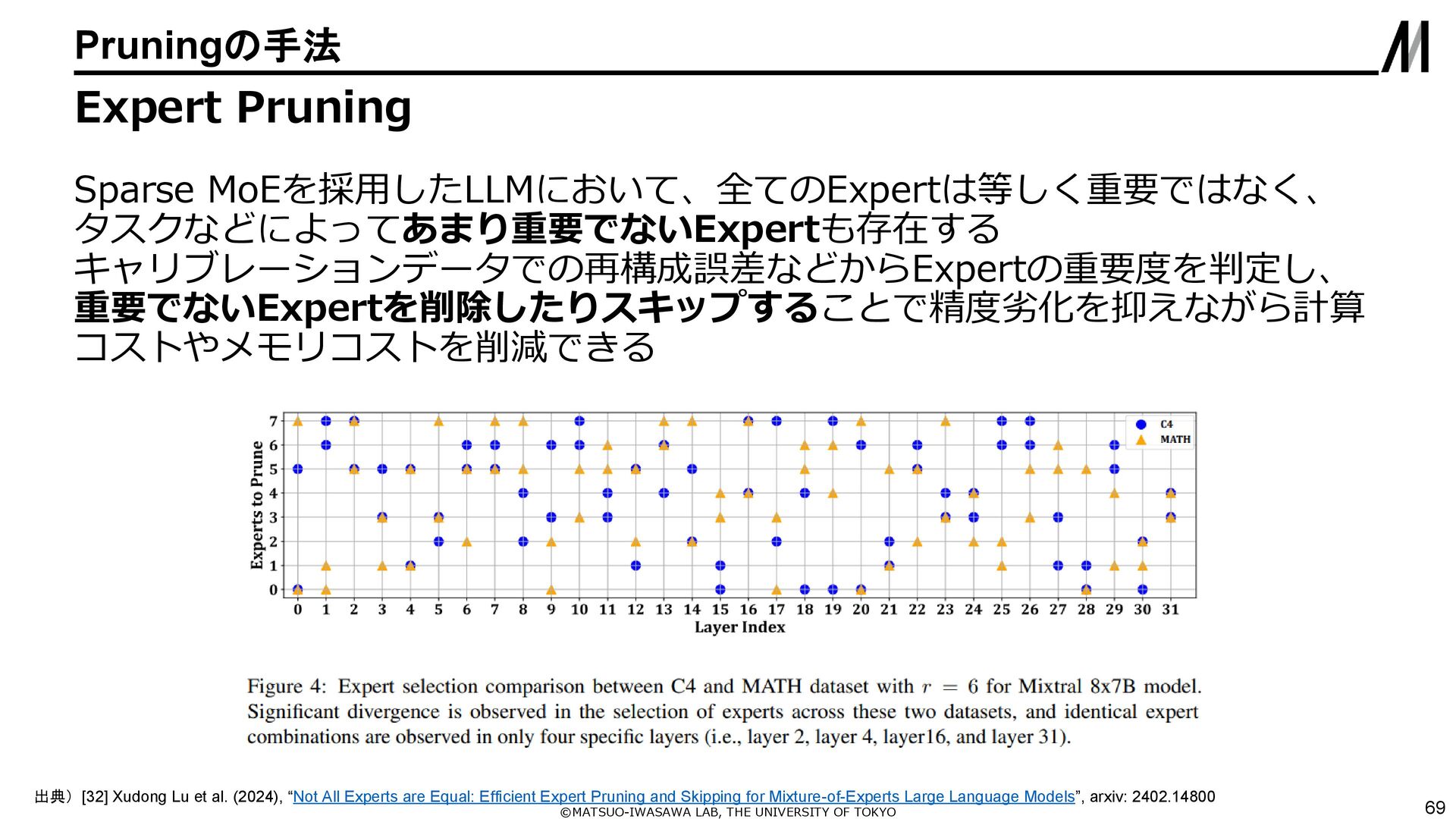{kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 70 出典)[33] Sharath Sreenivas](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_69.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
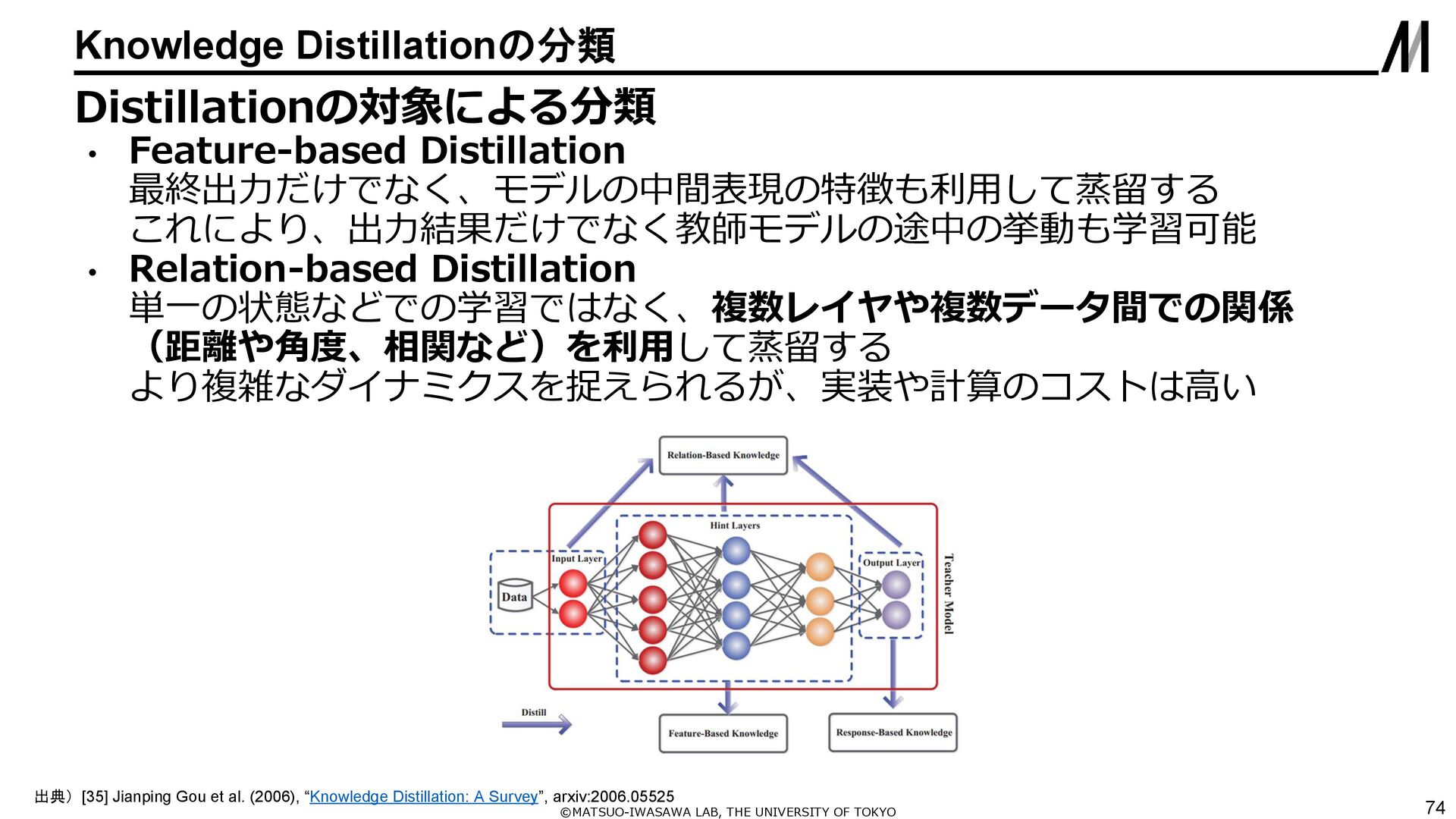{kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 75 出典)[36] Kevin Lu](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_74.jpg){kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 76 出典)[33] Sharath Sreenivas](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
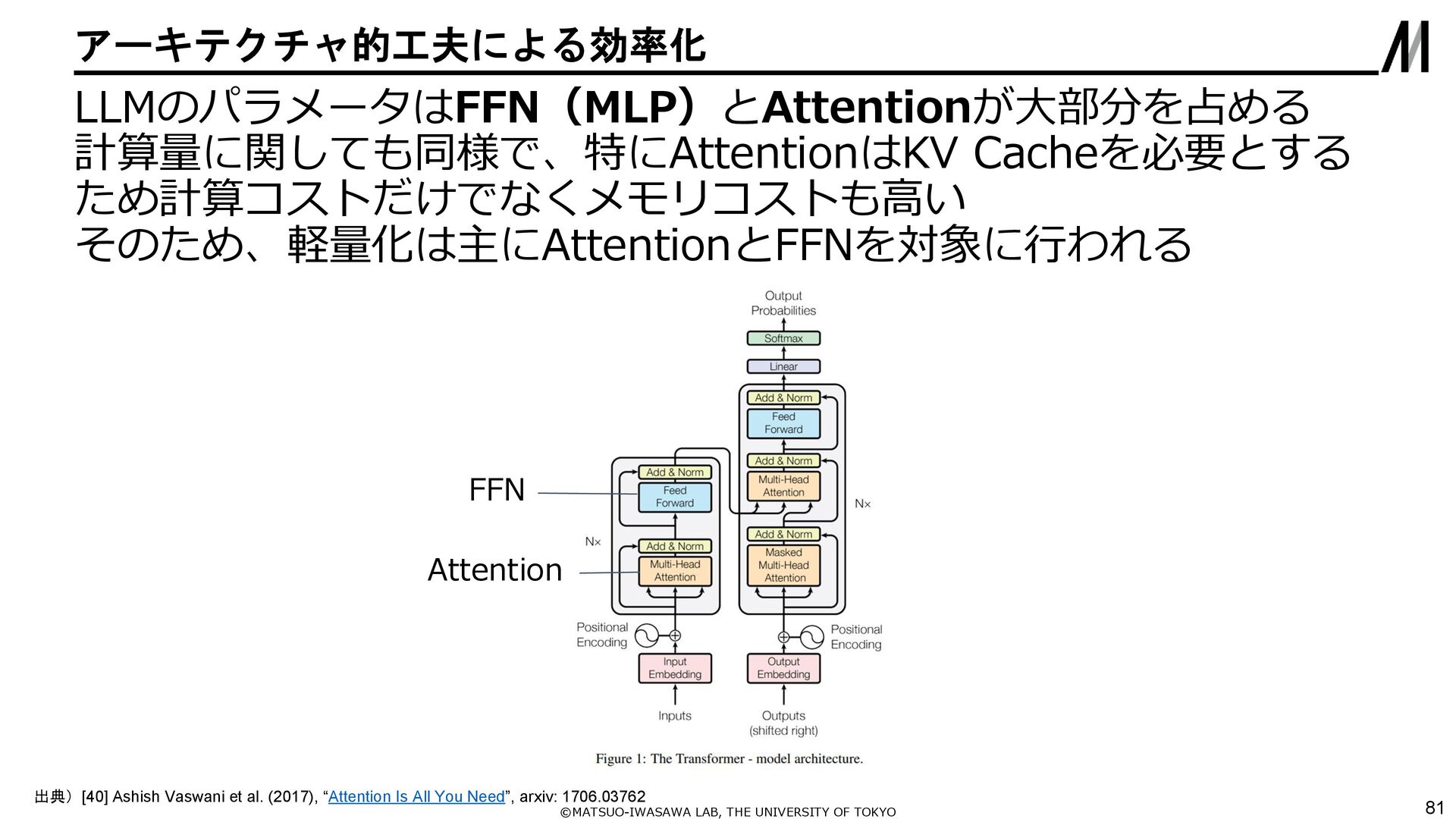{kind=link}
{kind=link}
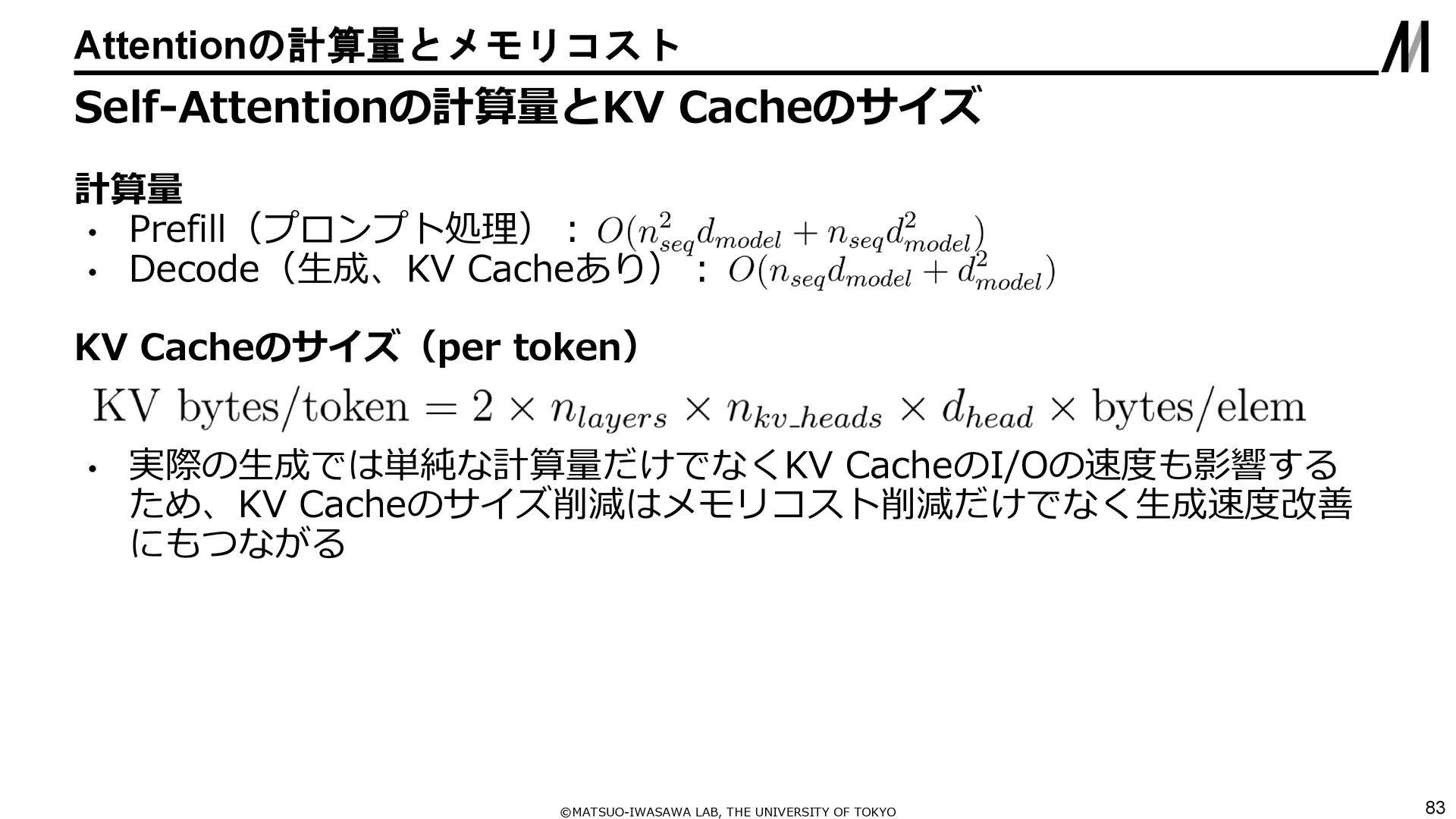{kind=link}
{kind=link}
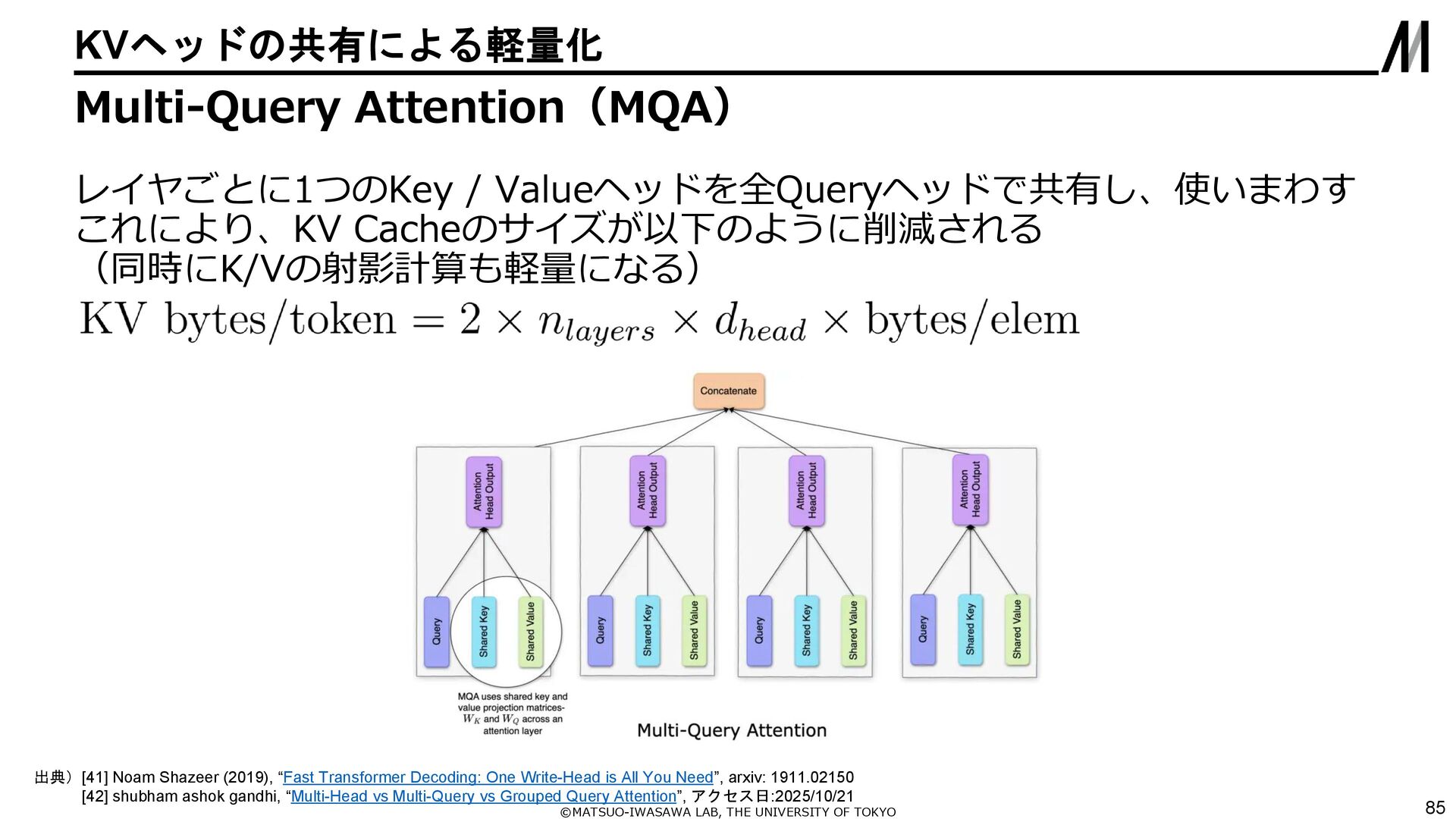{kind=link}
{kind=link}
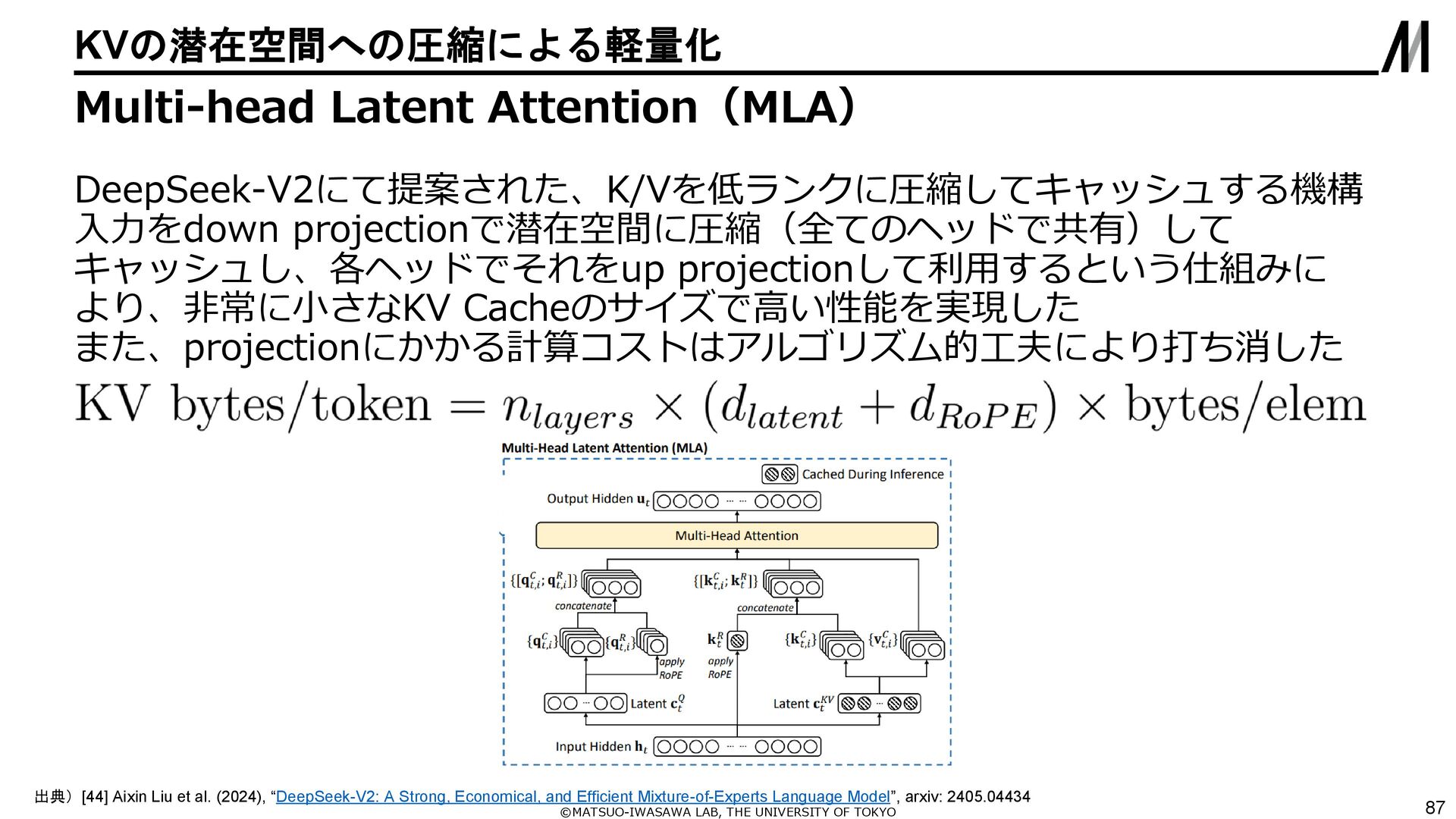{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
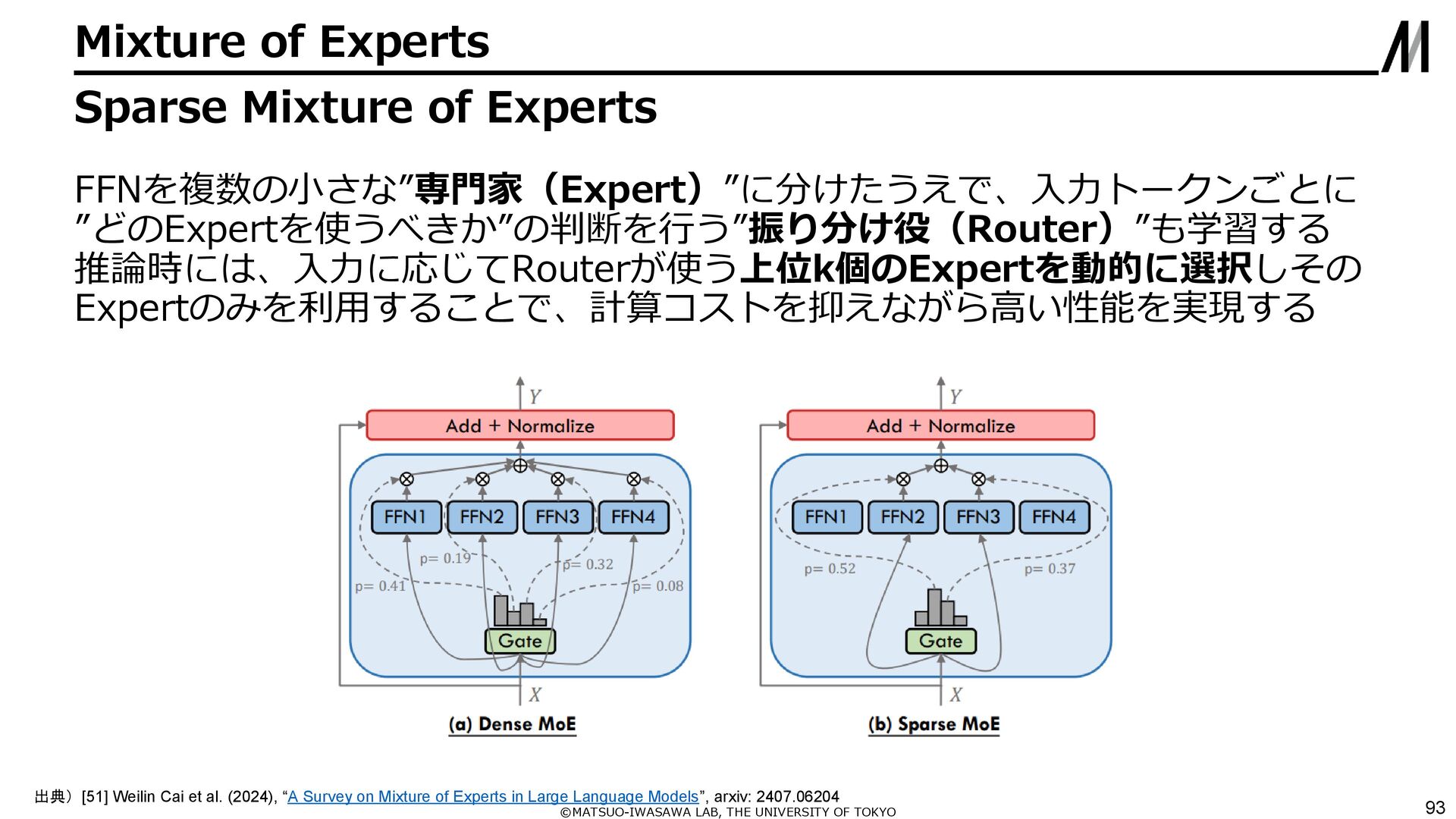{kind=link}
{kind=link}
{kind=link}
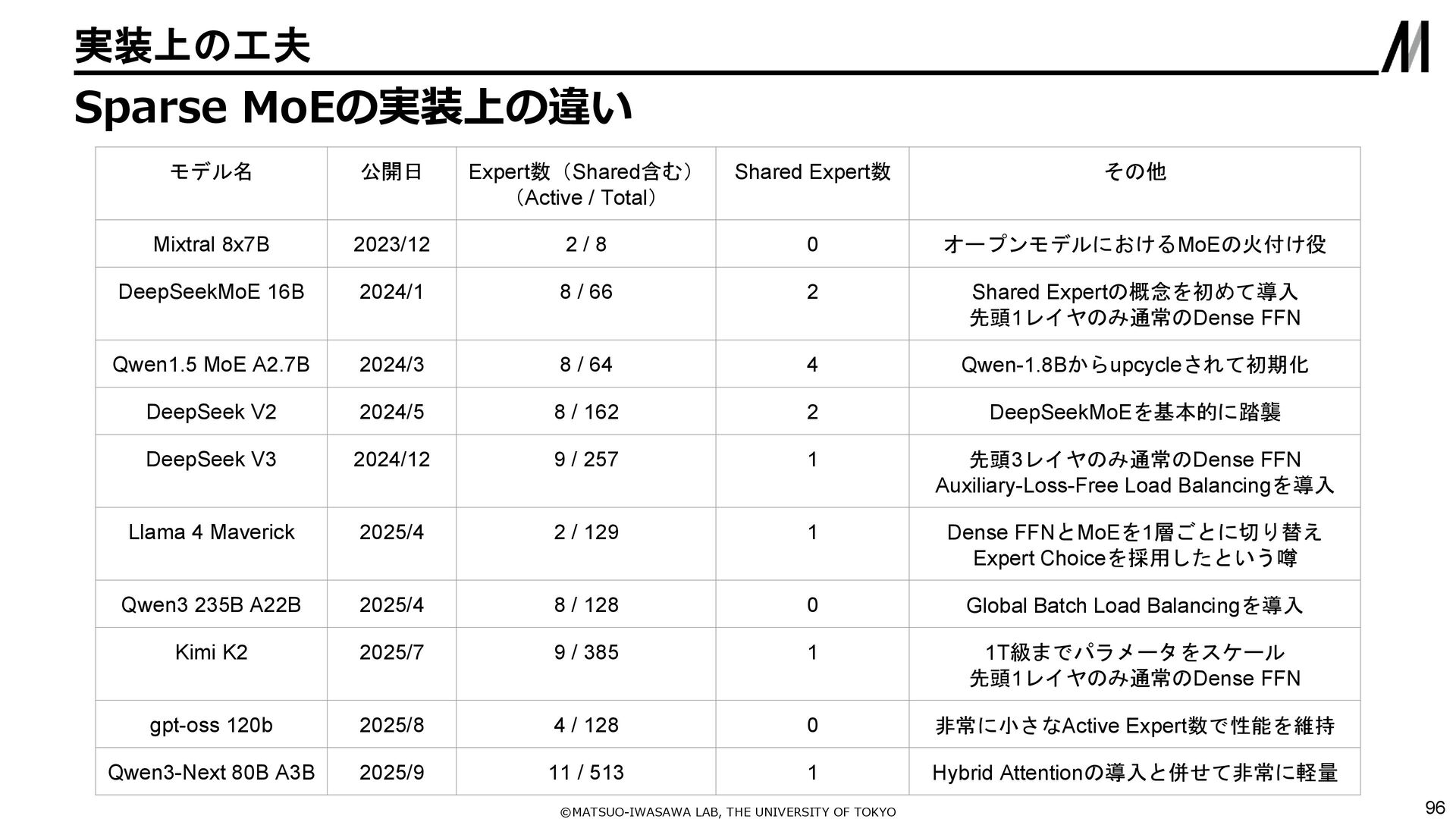{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
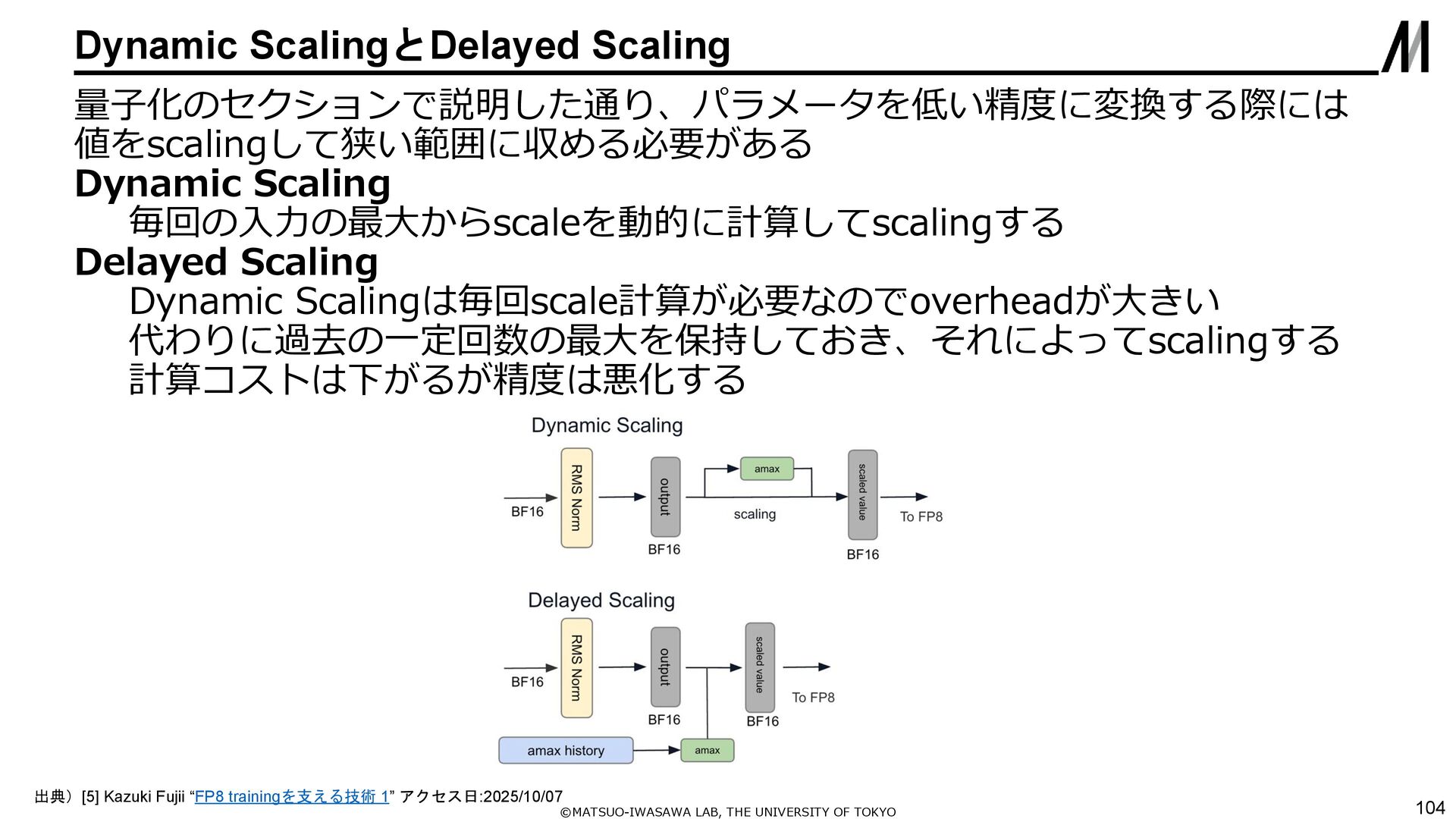{kind=link}
{kind=link}
{kind=link}
{kind=link}
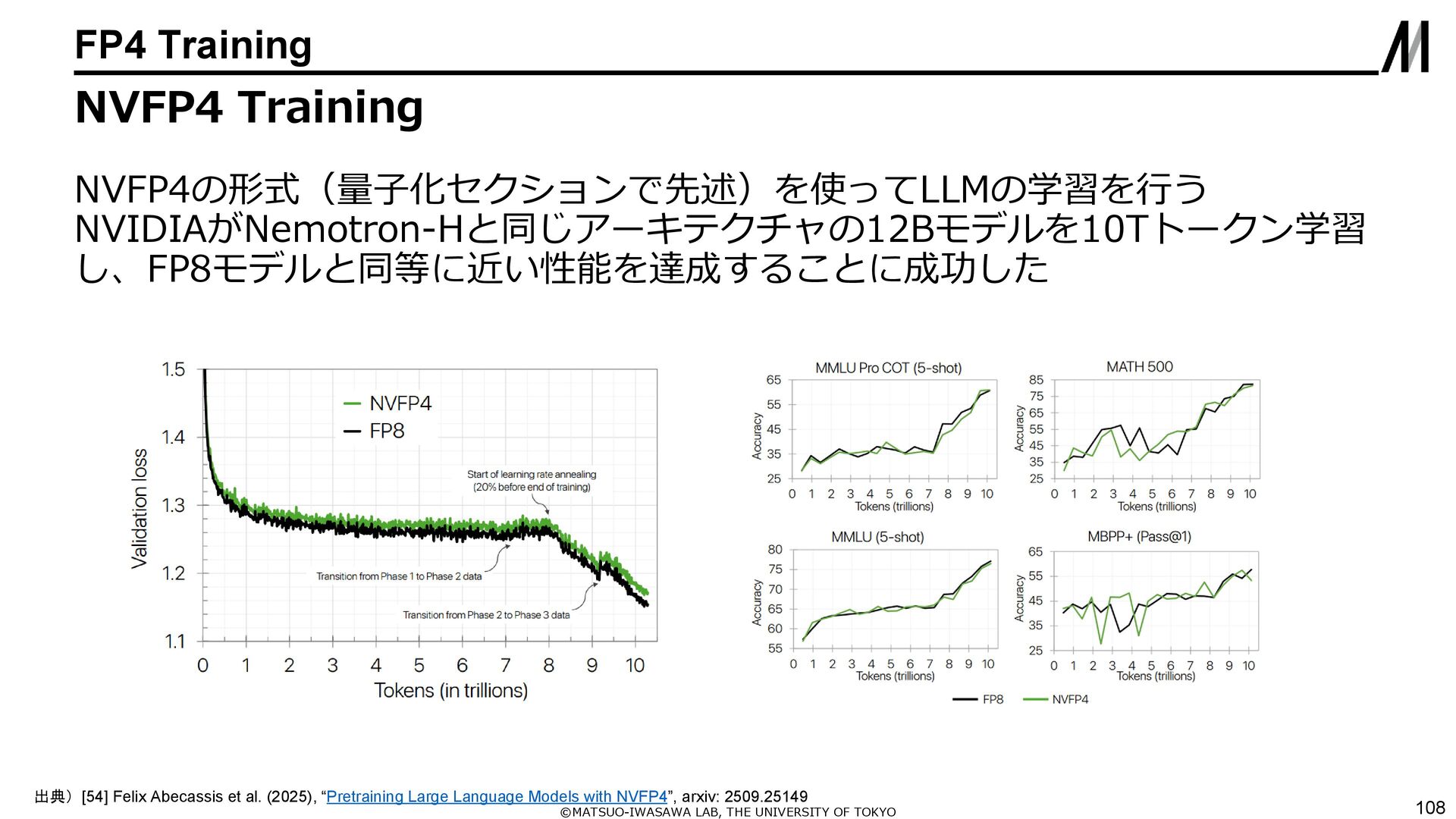{kind=link}
{kind=link}
{kind=link}
{kind=link}
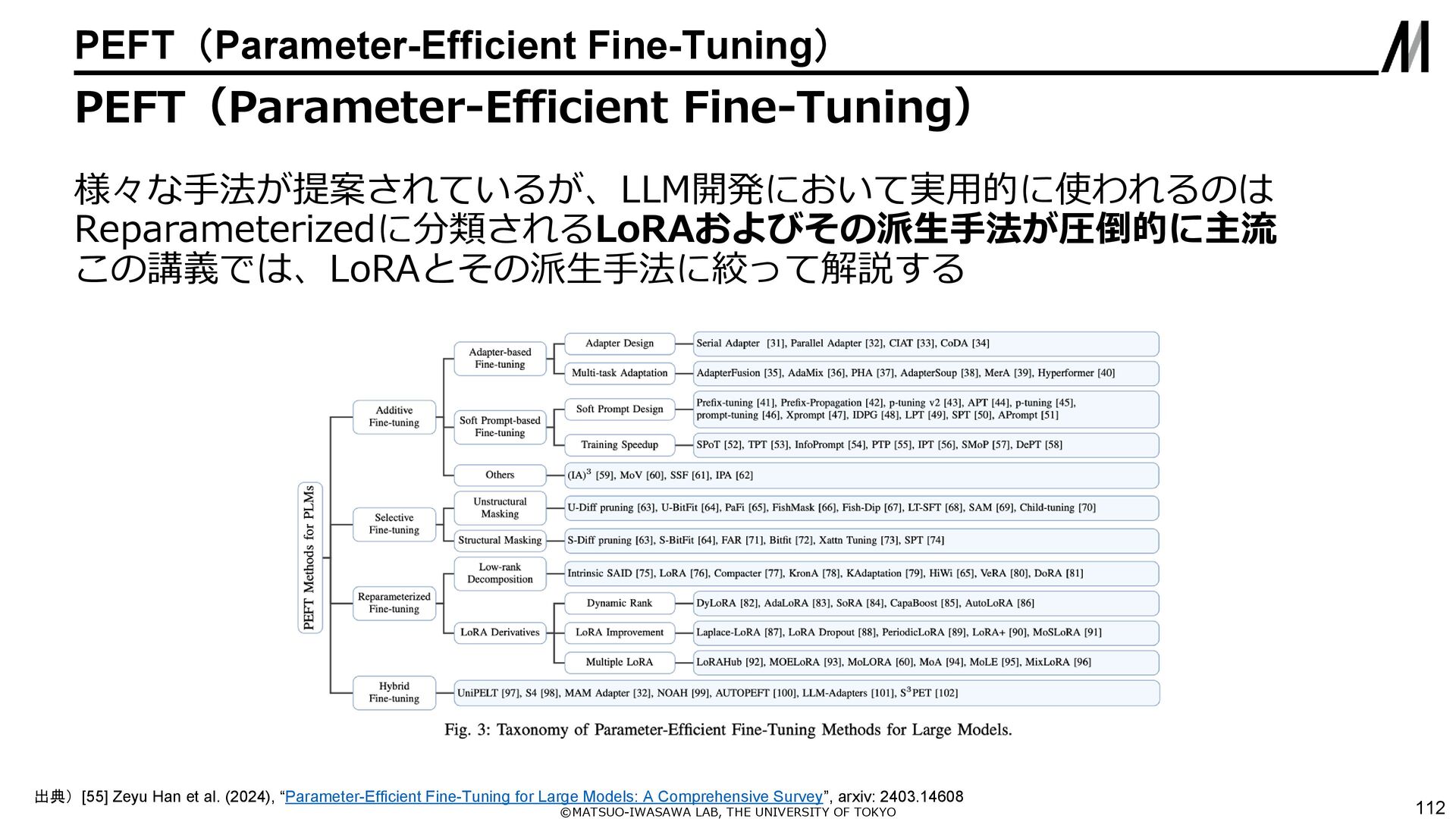{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
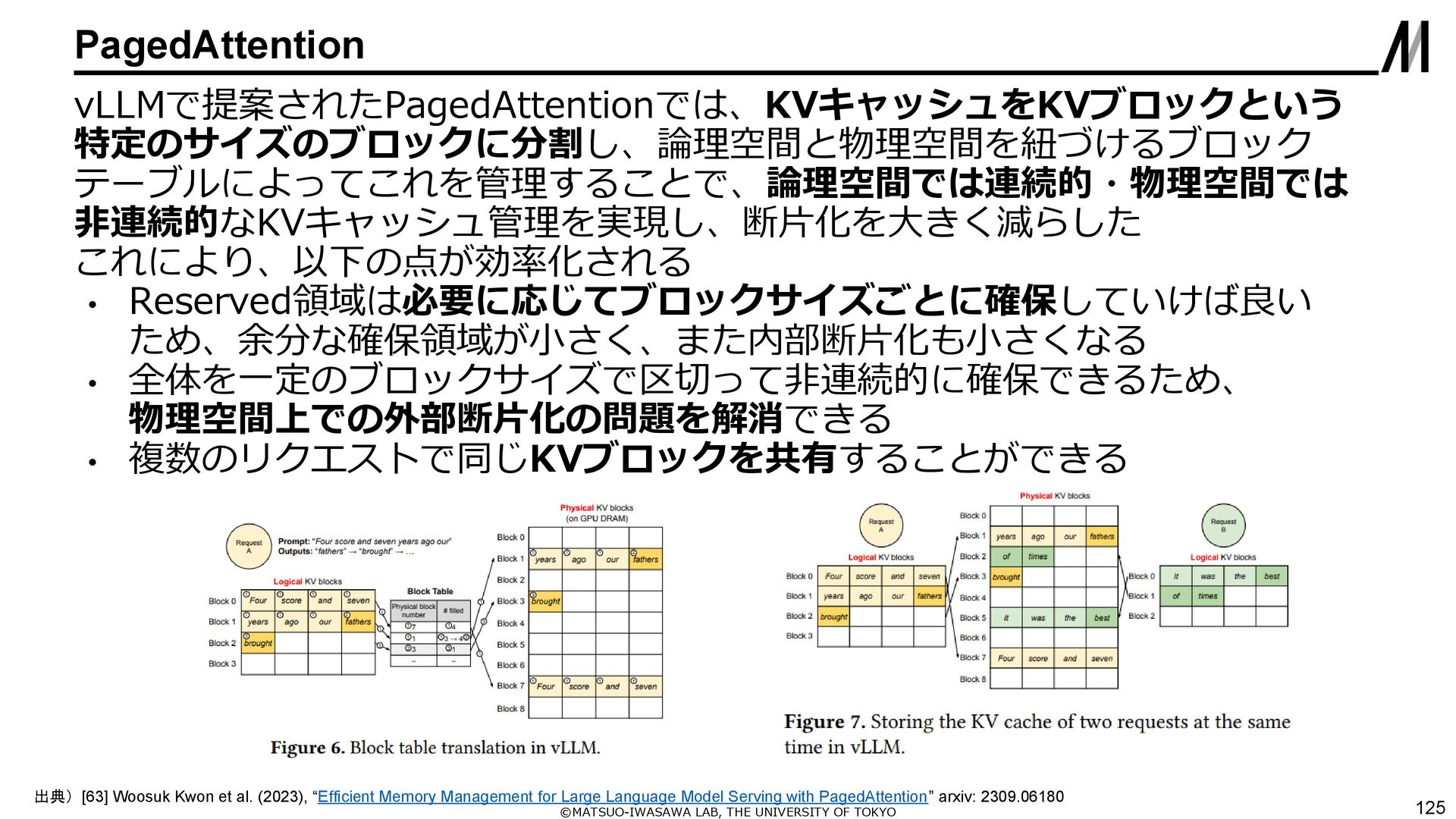{kind=link}
{kind=link}
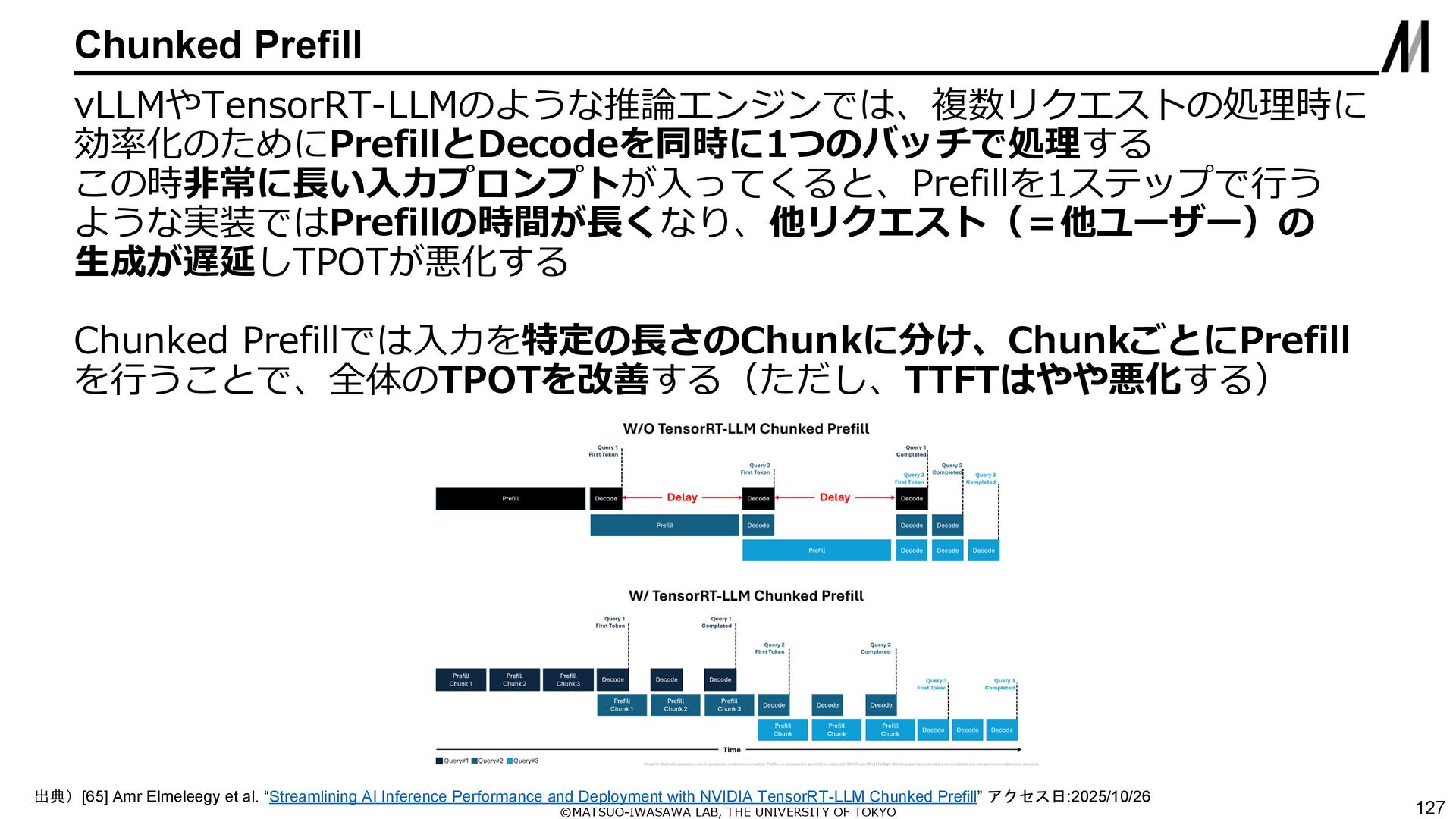{kind=link}
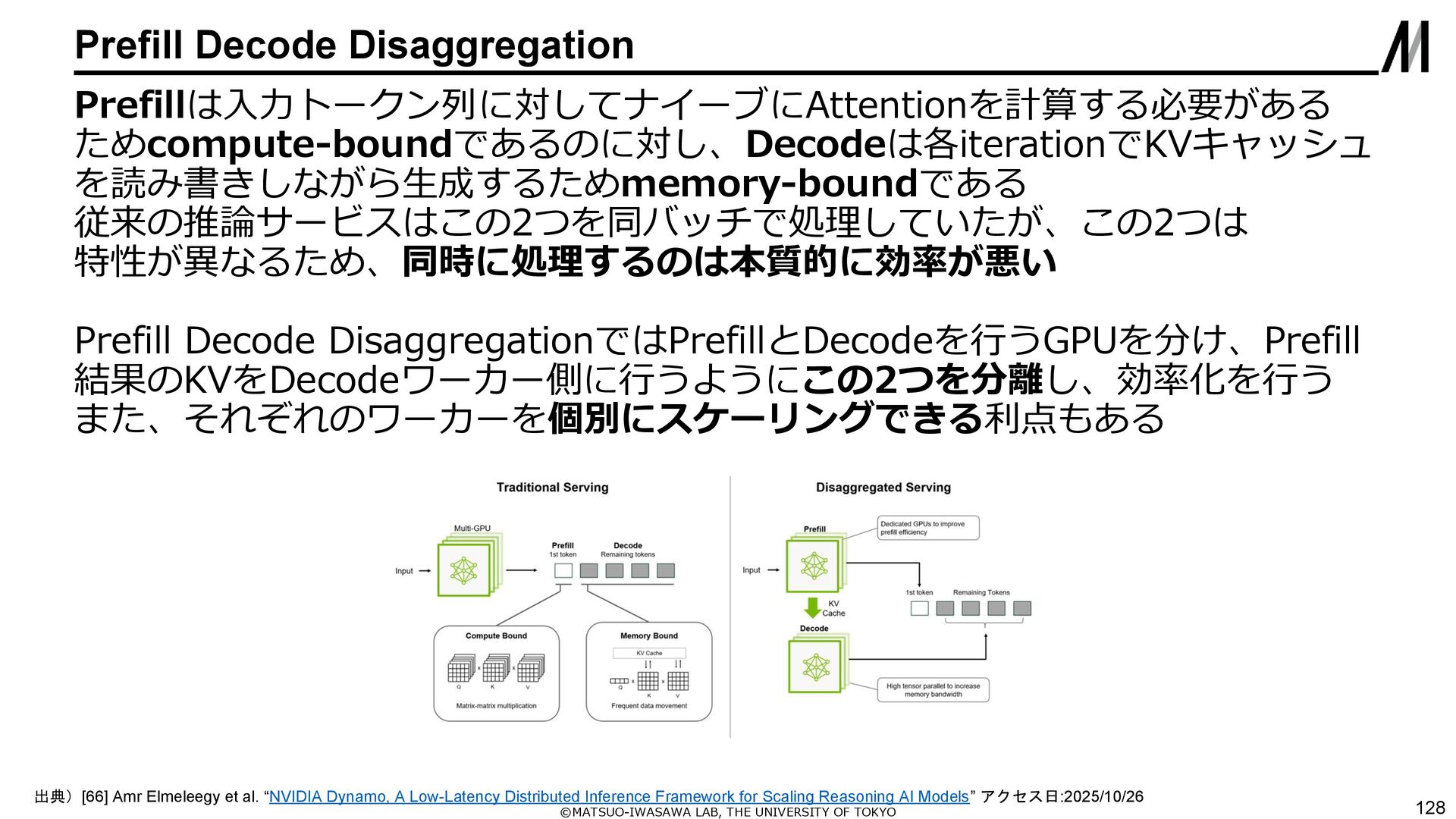{kind=link}
{kind=link}
{kind=link}
{kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 132 Reference [1] Nouamane](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_131.jpg){kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 133 Reference [21] Shuming](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_132.jpg){kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 134 Reference [40] Ashish](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_133.jpg){kind=link}
![©︎MATSUO-IWASAWA LAB, THE UNIVERSITY OF TOKYO 135 Reference [60] Soufiane](https://files.speakerdeck.com/presentations/b790ec492188415e8b174ea29f4c182e/slide_134.jpg){kind=link}