configuration actively ◦ Single Instance type ◦ Single life cycle - Spot / OD • Auto Scaling Tightly coupled with only Cloudwatch • Alarms can be triggered (automatically) but only based on a single metric • Limited stat functions - avg, sum, min, max and # data samples
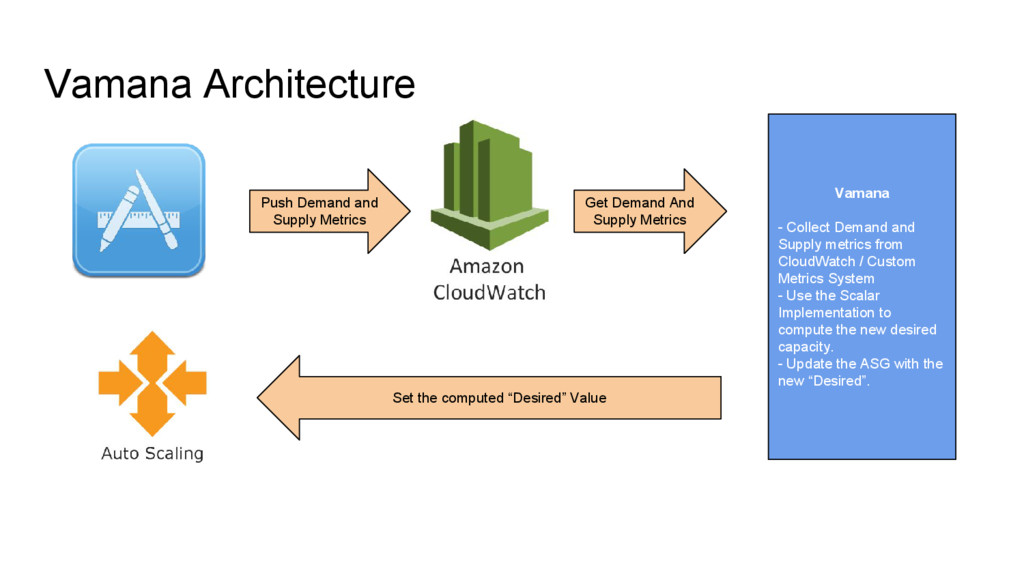
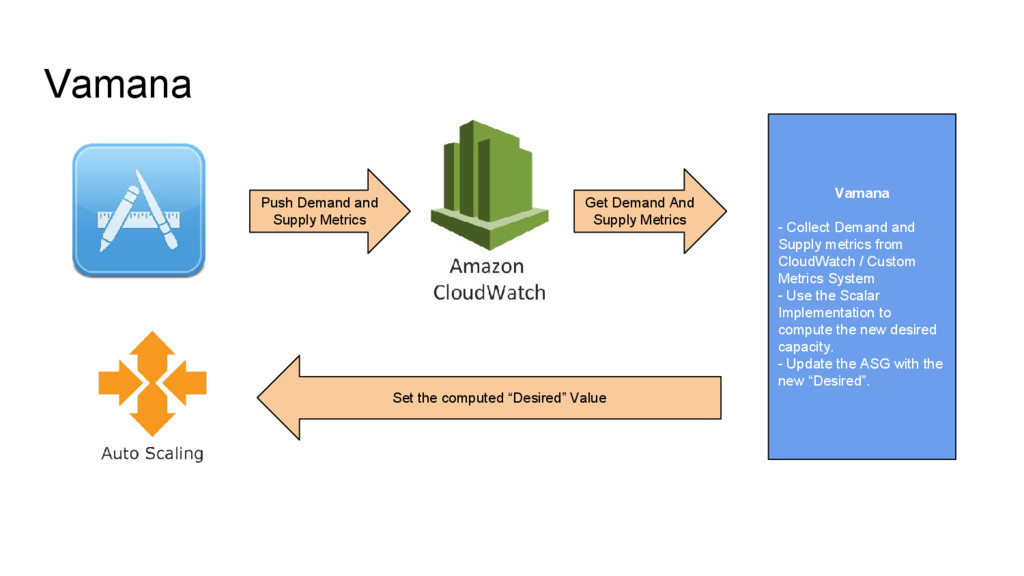
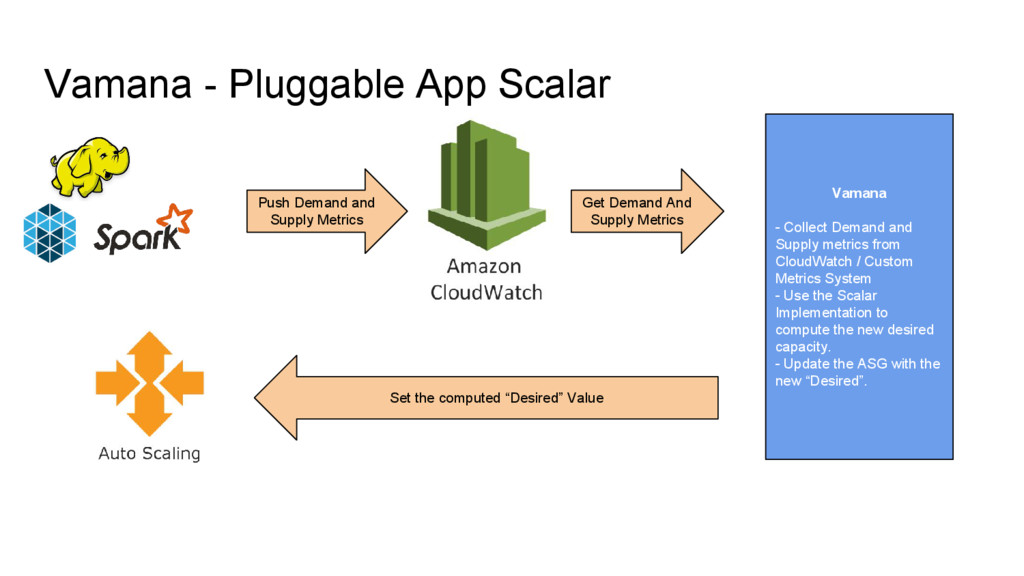
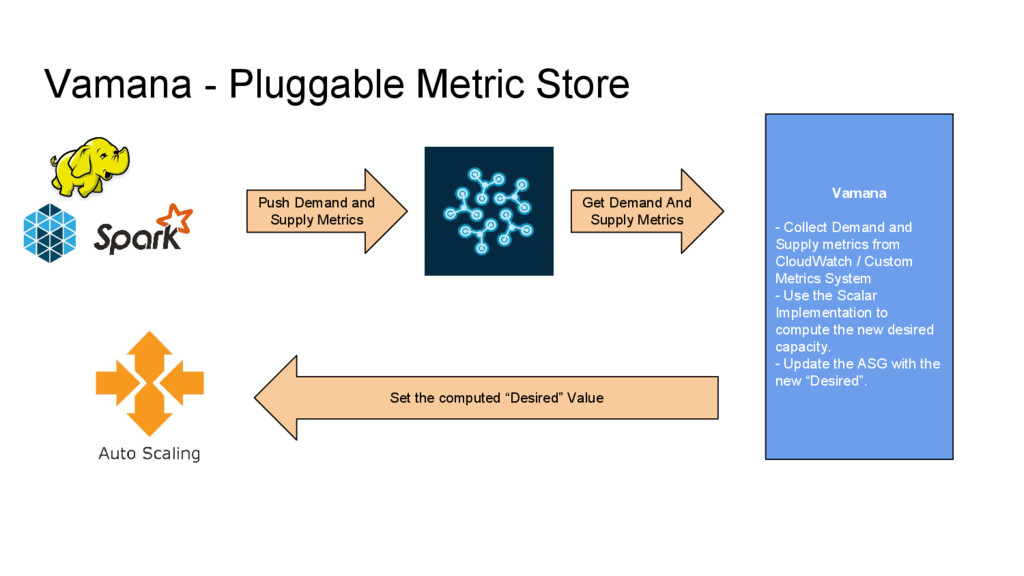
CloudWatch / Custom Metrics System - Use the Scalar Implementation to compute the new desired capacity. - Update the ASG with the new “Desired”. Push Demand and Supply Metrics Get Demand And Supply Metrics Set the computed “Desired” Value
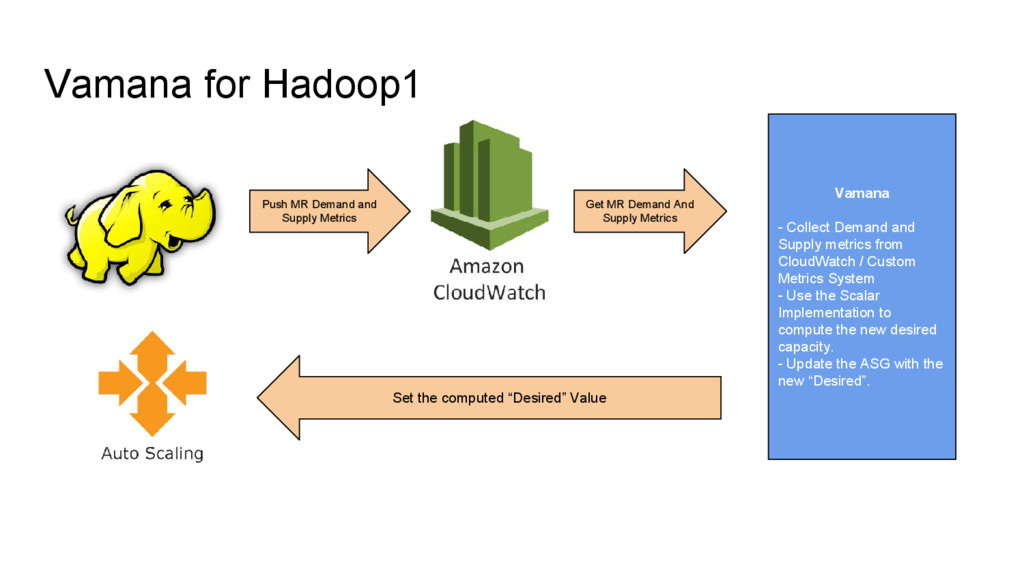
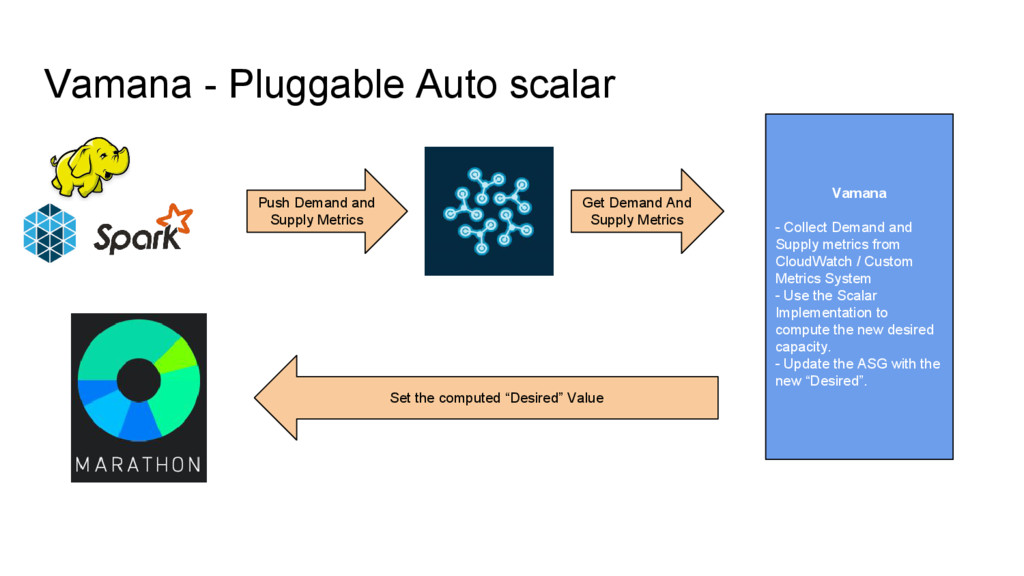
from CloudWatch / Custom Metrics System - Use the Scalar Implementation to compute the new desired capacity. - Update the ASG with the new “Desired”. Push MR Demand and Supply Metrics Get MR Demand And Supply Metrics Set the computed “Desired” Value
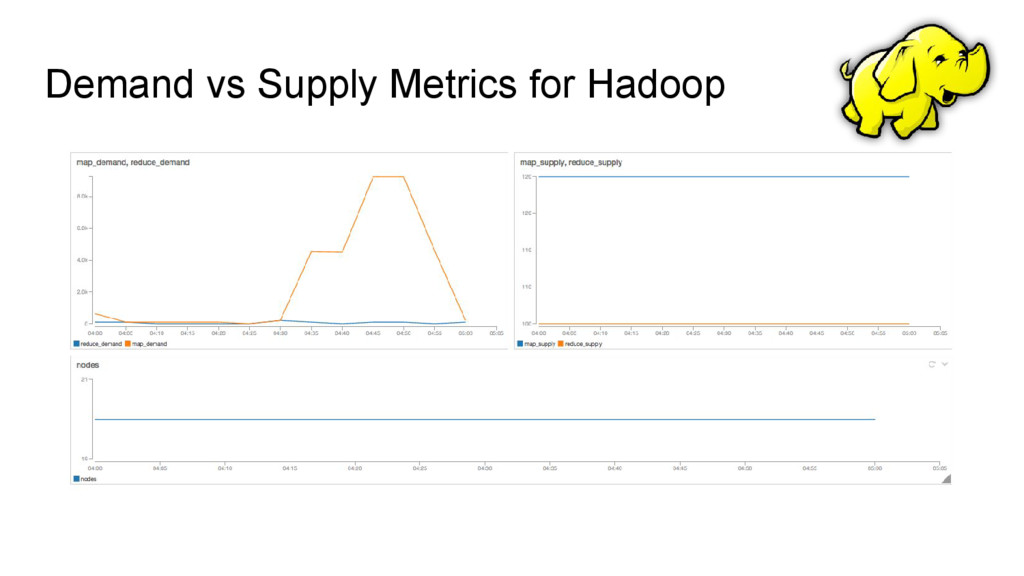
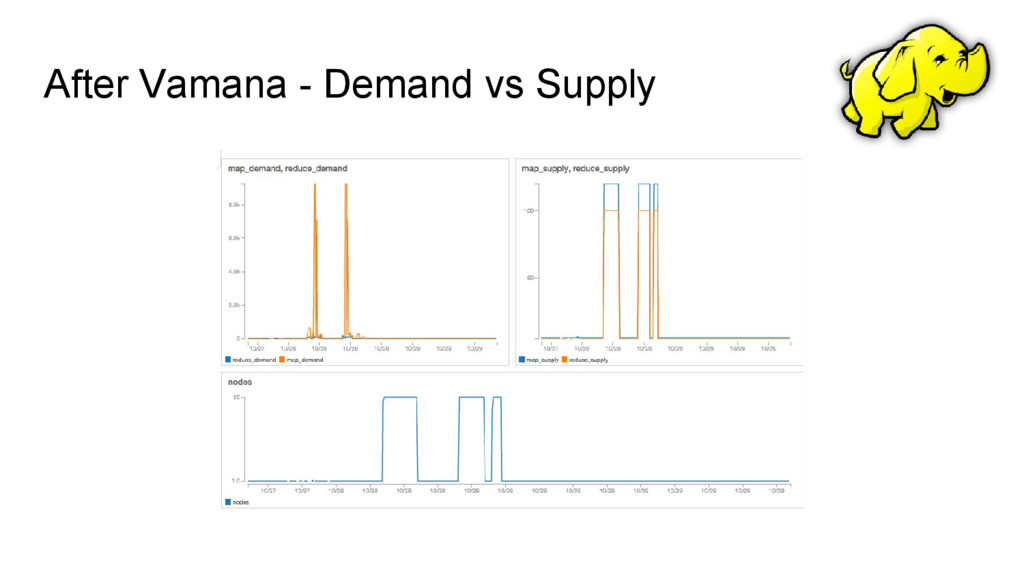
metrics from the Cluster Summary table ◦ map_supply ◦ reduce_supply • Demand metrics are collected as cumulative sum of map & reduce tasks of all Running jobs ◦ map_demand ◦ reduce_demand https://github.com/ashwanthkumar/hadoop-as-publisher
/ Custom Metrics System - Use the Scalar Implementation to compute the new desired capacity. - Update the ASG with the new “Desired”. Push Demand and Supply Metrics Get Demand And Supply Metrics Set the computed “Desired” Value
Supply metrics from CloudWatch / Custom Metrics System - Use the Scalar Implementation to compute the new desired capacity. - Update the ASG with the new “Desired”. Push Demand and Supply Metrics Get Demand And Supply Metrics Set the computed “Desired” Value
Supply metrics from CloudWatch / Custom Metrics System - Use the Scalar Implementation to compute the new desired capacity. - Update the ASG with the new “Desired”. Push Demand and Supply Metrics Get Demand And Supply Metrics Set the computed “Desired” Value
Supply metrics from CloudWatch / Custom Metrics System - Use the Scalar Implementation to compute the new desired capacity. - Update the ASG with the new “Desired”. Push Demand and Supply Metrics Get Demand And Supply Metrics Set the computed “Desired” Value
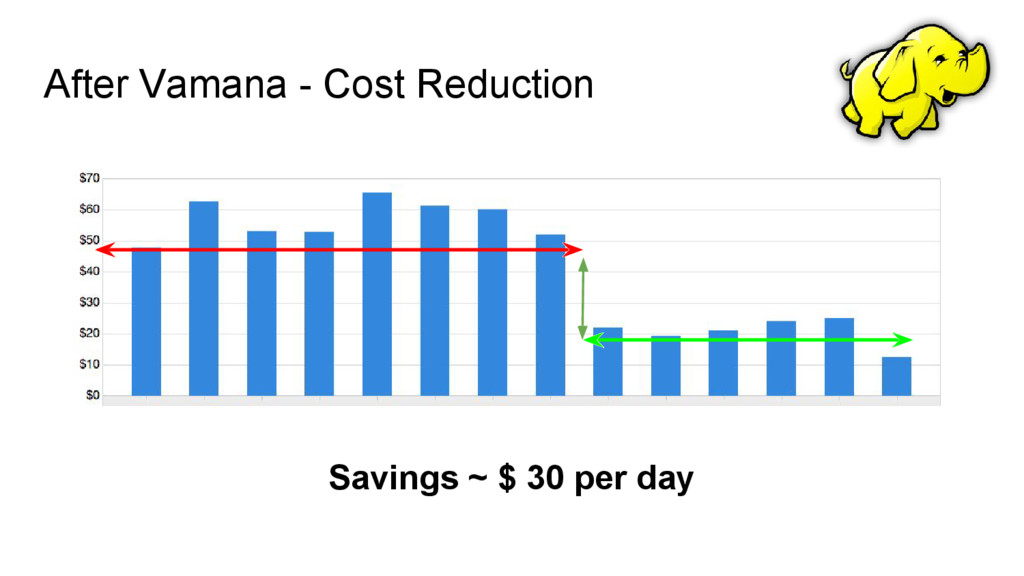
Hadoop • Each of them have their own usage pattern ◦ A Staging cluster has only workloads for 3-4 hours a day ◦ Production cluster has workloads 24x7 • We started having Scale Up and Scale Down stages in our Datapipelines • Initially it helped but started breaking when ◦ Pipeline fails before completion and the cluster is not scaled down ◦ Every new pipeline created had to have a scale up and scale down stage ◦ More than 1 pipeline started sharing the cluster Hadoop @ Indix
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}