Have to include intermediary data in the output just for stats - Have to think about writing stats after writing production code Stats as Map-Reduce Jobs
Have to include intermediary data in the output just for stats - Have to think about writing stats after writing production code - Not updated at-least till next run (Not “realtime”) stats as map-reduce jobs
Realtime + Allows arbitrary functions as rollups - code as config - Not distributable - since it allows arbitrary functions - Stats emission and rollups are at separate places - making it difficult to test and keep them in sync
for stats - Have to think about writing stats after writing production code - Not updated at-least till next run (Not “realtime”) - Not distributable - since it allows arbitrary functions - Stats emission and rollups are at separate places - making it difficult to test and keep them in sync stats for map-reduce jobs stats for streaming workloads
are not - Approximate structures like HyperLogLog can find unique counts in constant memory (and a known error bound) - 2 more HLL can be merged and their merge is both associative and commutative - can be expressed as a monoid monoids - approximates
given they are associative (and some are also commutative), we can exploit them for massive parallel processing - We need our stats to be real time even if they’re approximate for some metrics as long as the error bounds are known learnings so far
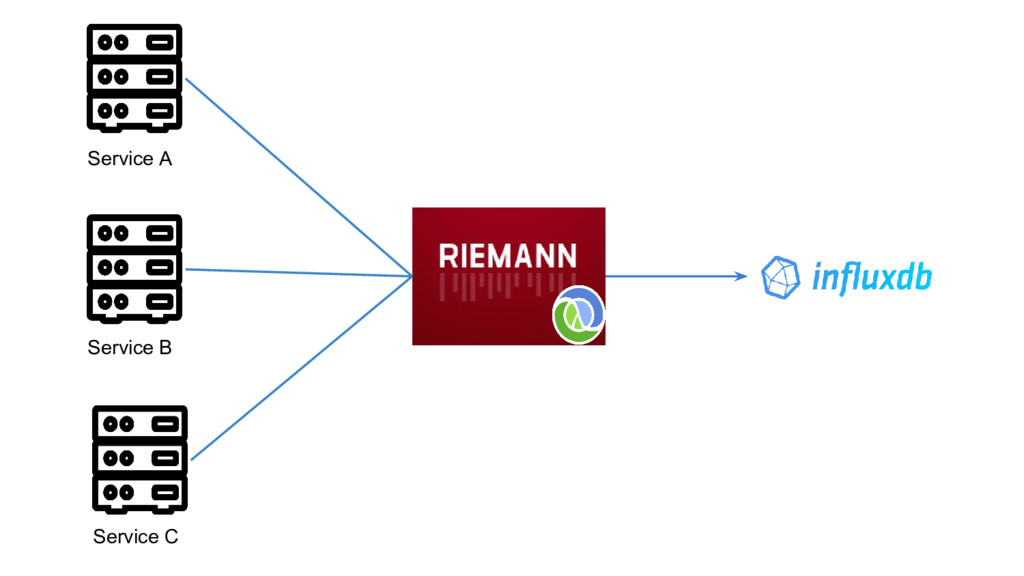
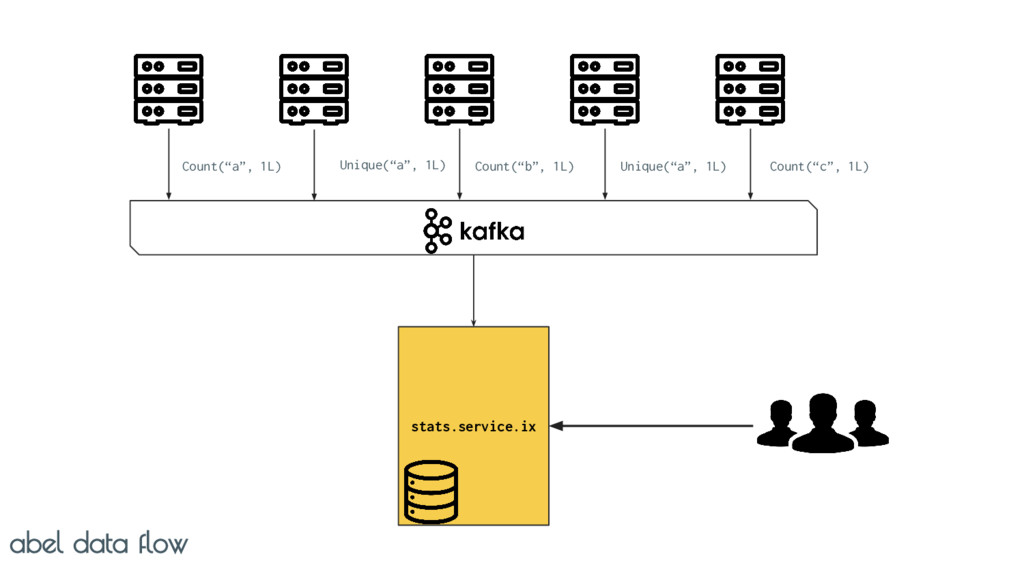
Uses Kafka for stats delivery abel Consumes stats in (near) Realtime Expose aggregations over HTTP Crunches 1M events in less than 15 seconds on 1 machine
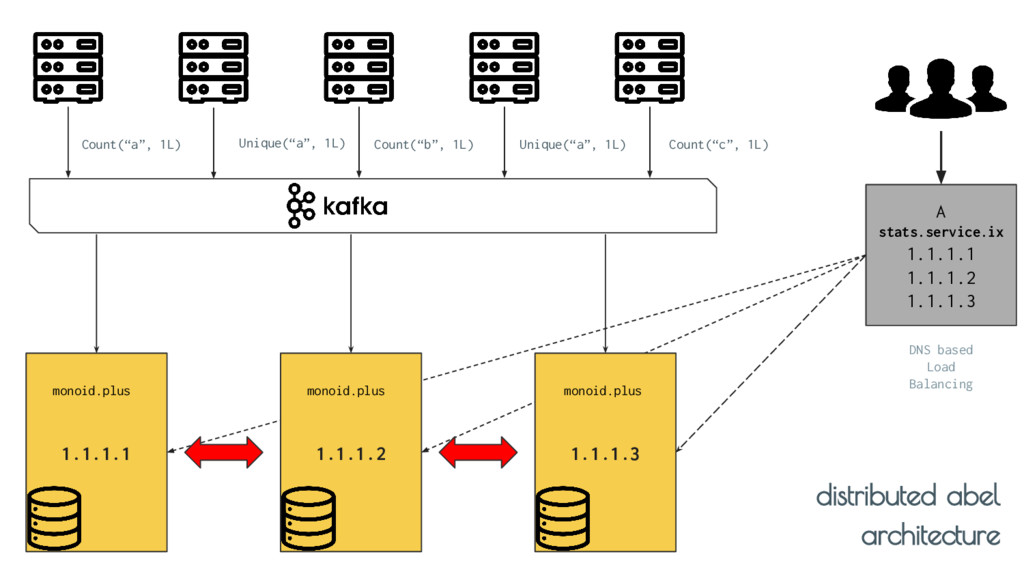
rebalances the partitions across instances - Uses scatter-gather primitive in Suuchi to perform query time reductions of the metrics before serving it to the users distributed abel
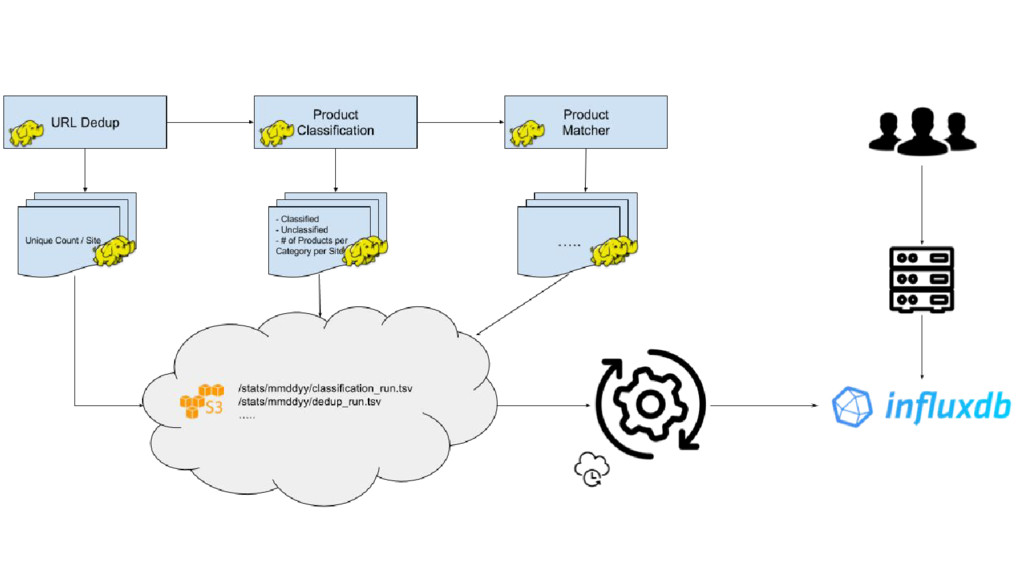
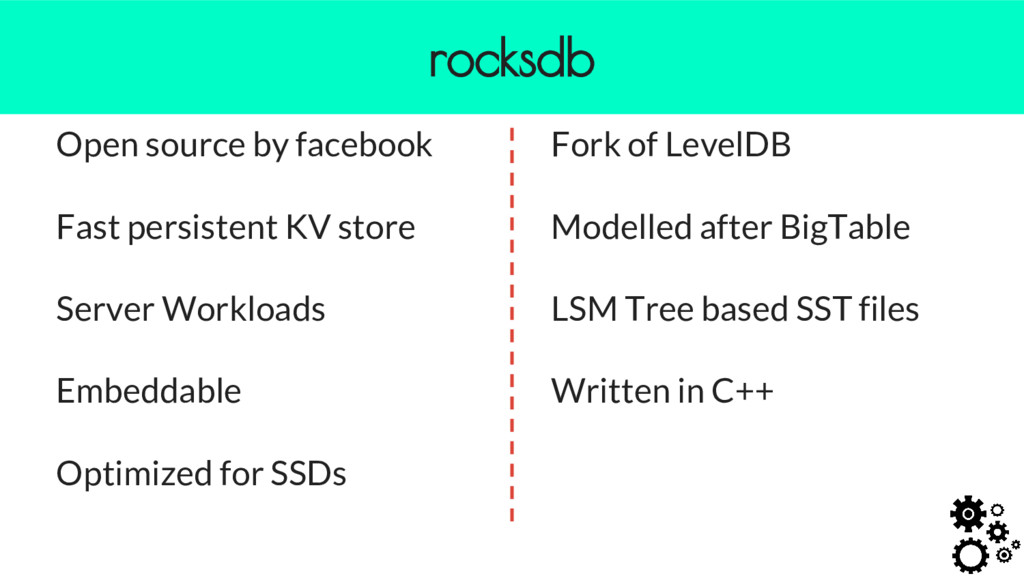
Search on hierarchical documents - Dynamic fields didn’t scale well on Solr - Brand / Store / Category Counts for a filter - Price History Service - More than a billion prices and serve online to REST queries rocksdb @indix
was approximate aggregates real-time - HTML Archive System - Stores ~120TB of url and timestamp indexed HTML pages - Real-time scheduler for our crawlers - Finds out which of the 20 urls to crawl now out of 3+ billion urls - Helps crawler crawl 20+ million urls everyday rocksdb @indix
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![case class Metric[T <: Aggregate[T]] (key: Key, value: T with](https://files.speakerdeck.com/presentations/0c3bf9f43a204c8aaaab26c6cb2216b4/slide_42.jpg){kind=link}
![trait Aggregate[T <: Aggregate[_]] { self: T => def plus(another:](https://files.speakerdeck.com/presentations/0c3bf9f43a204c8aaaab26c6cb2216b4/slide_43.jpg){kind=link}
![case class Time(time: Long, granularity: Long) case class Key(name:String, tags:SortedSet[String],](https://files.speakerdeck.com/presentations/0c3bf9f43a204c8aaaab26c6cb2216b4/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}