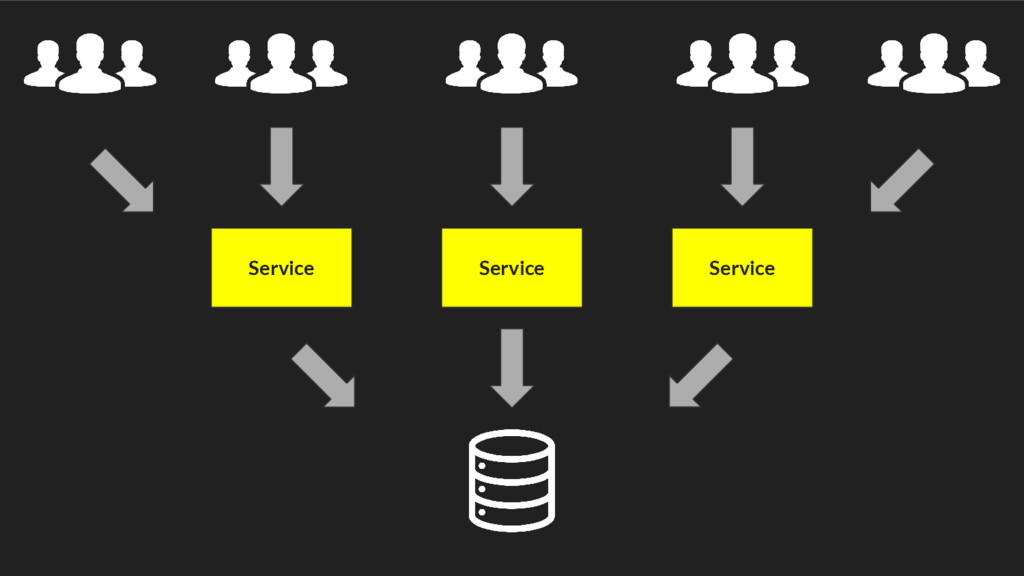
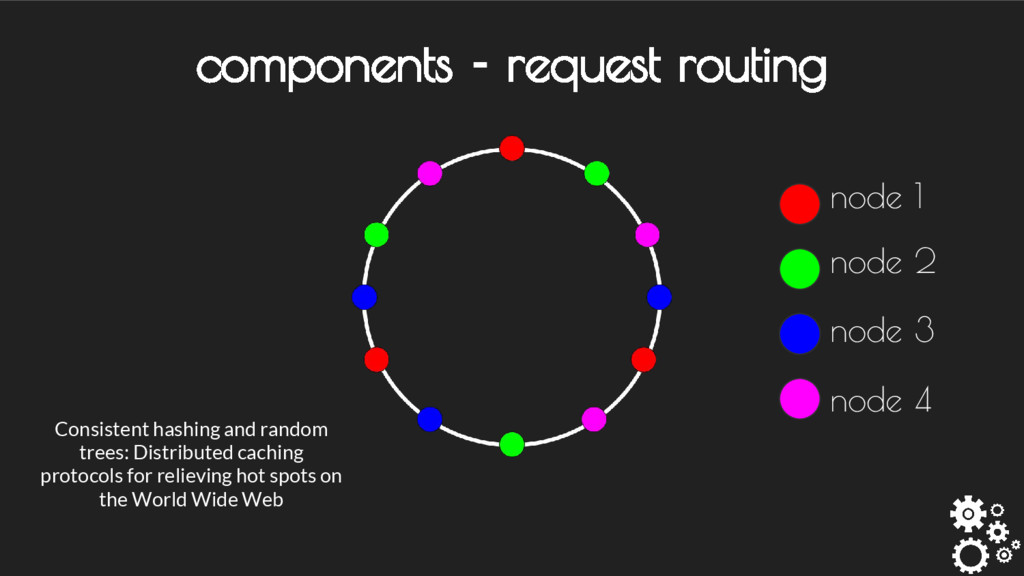
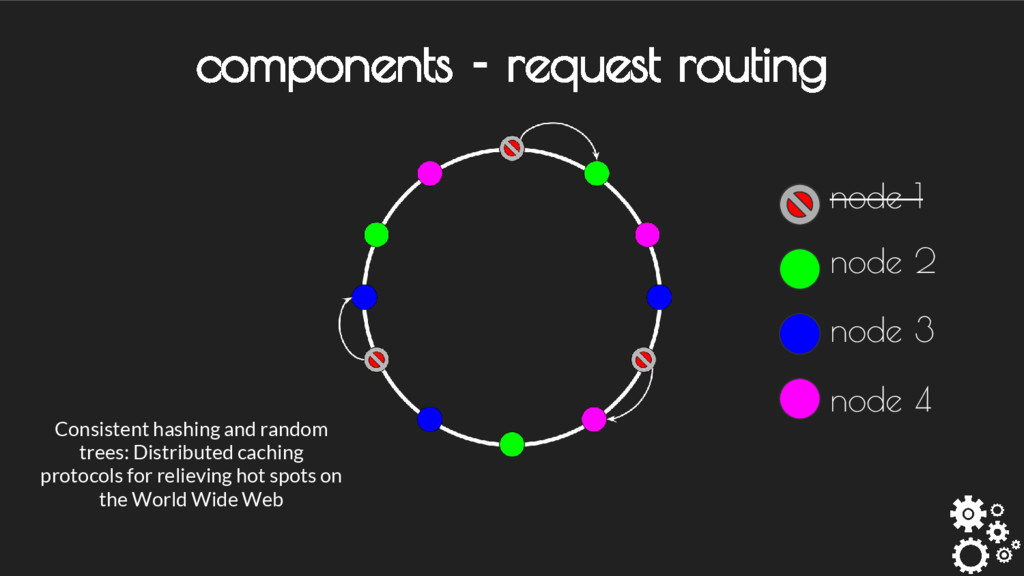
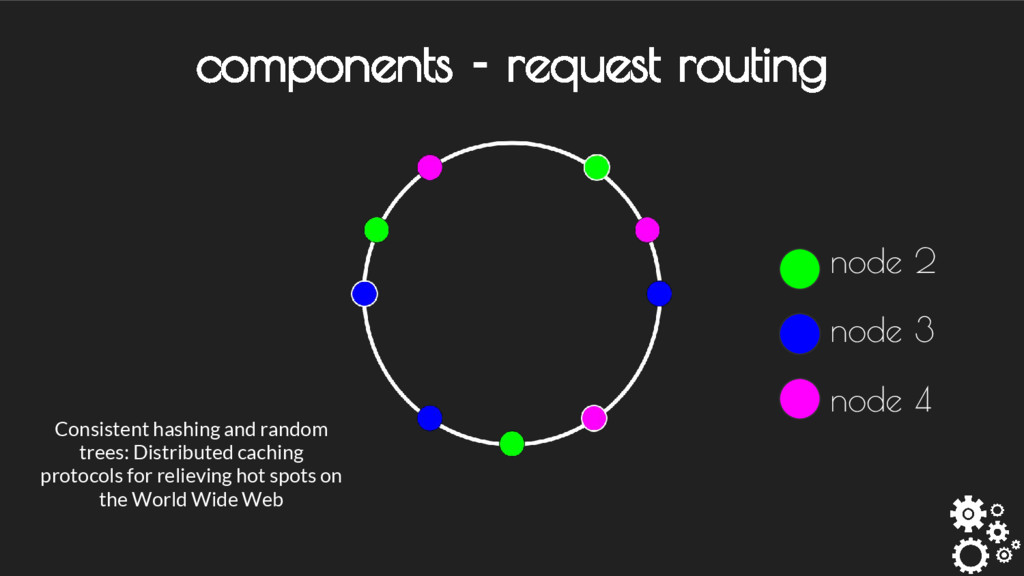
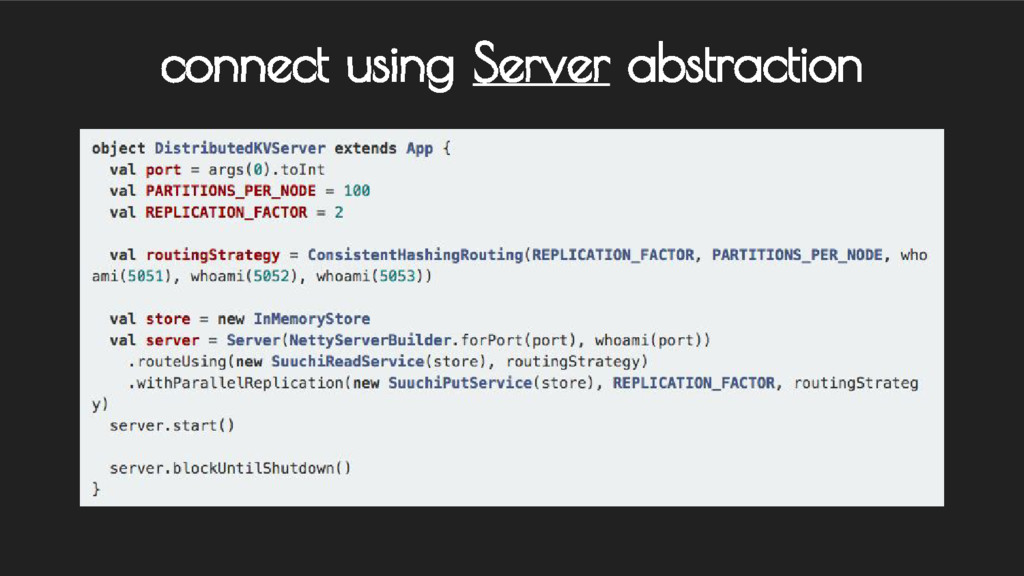
contact - Each node handles or forwards requests transparently - Uses pluggable partitioner scheme - Can be customized as weighted distribution / Rendezvous Hash etc. components - request routing
heavy system - Stores ~120TB of url and timestamp indexed HTML pages - Stats (as Monoids) Storage System* - All we want was approximate aggregates real-time - Real-time scheduler for our crawlers* - Finds out which of the 20 urls to crawl now out of 3+ billion urls - Helps crawler crawl 20+ million urls everyday suuchi @indix
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
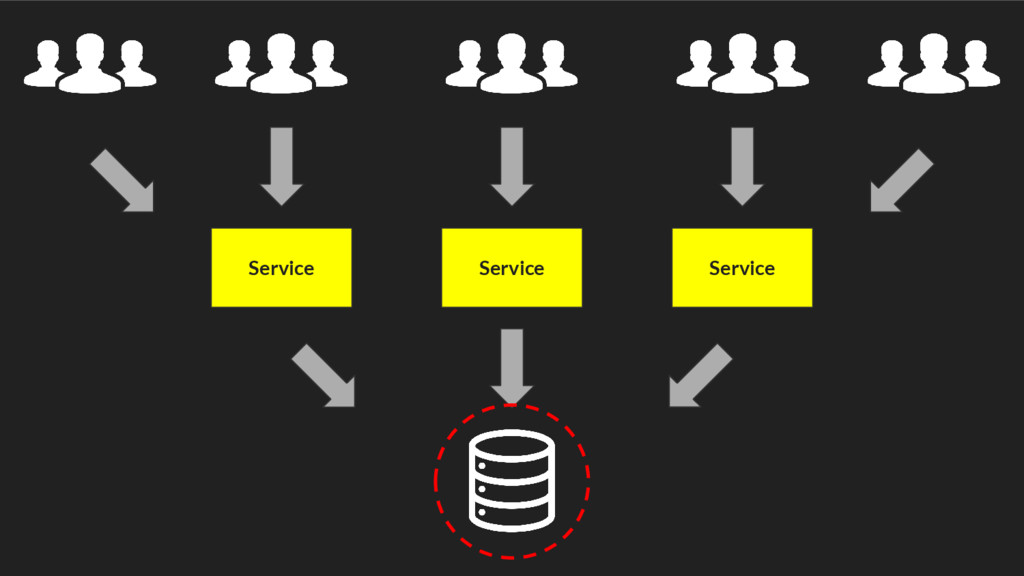{kind=link}
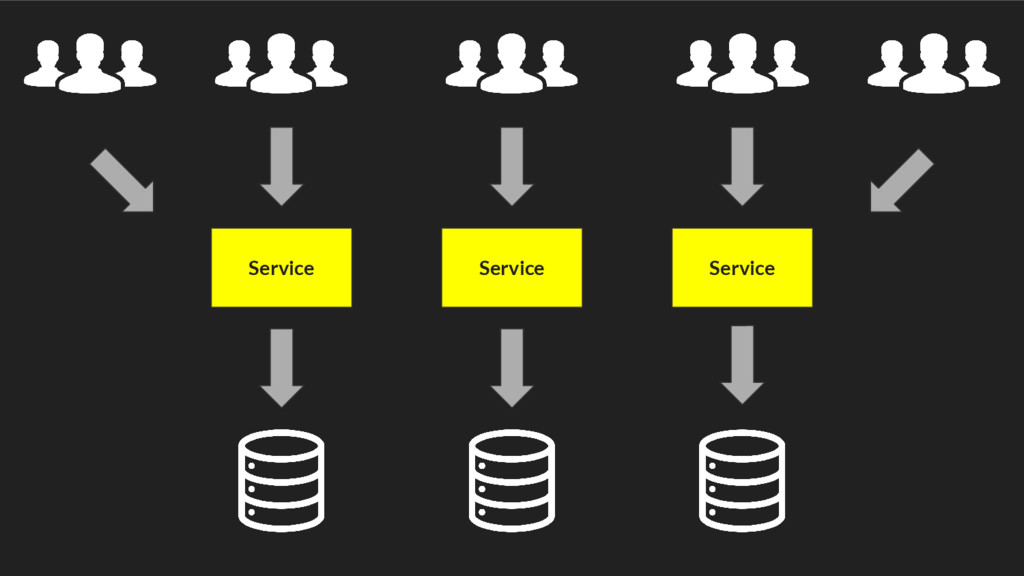{kind=link}
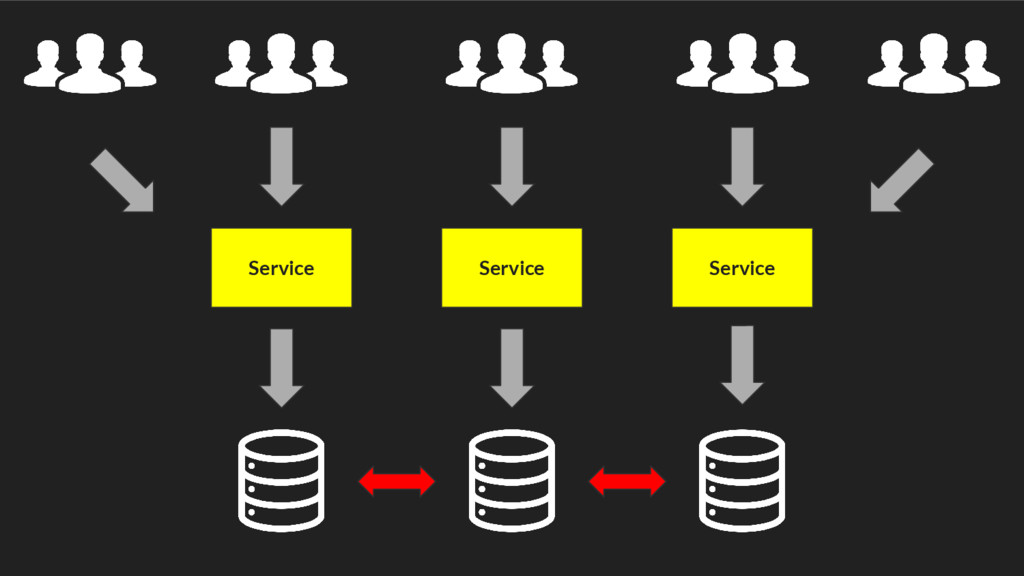{kind=link}
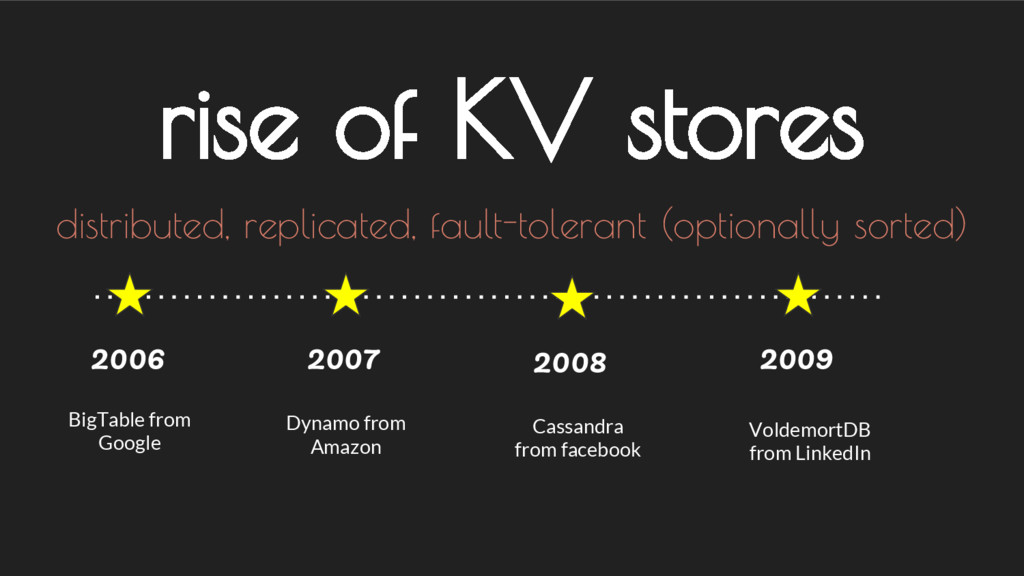{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}