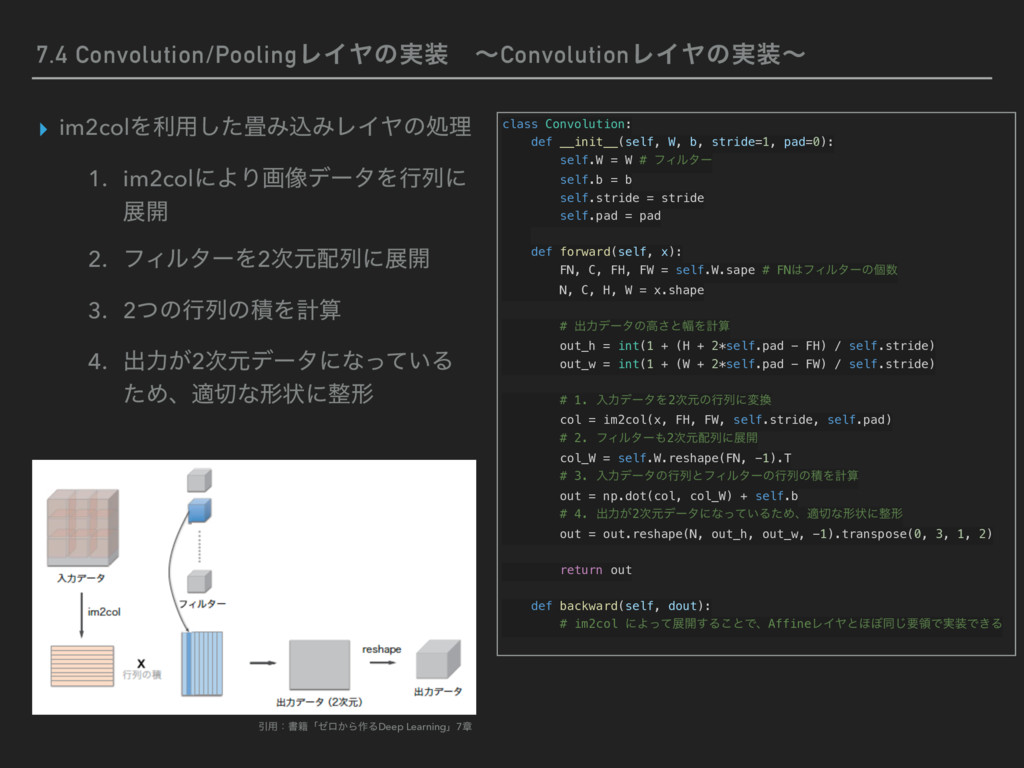
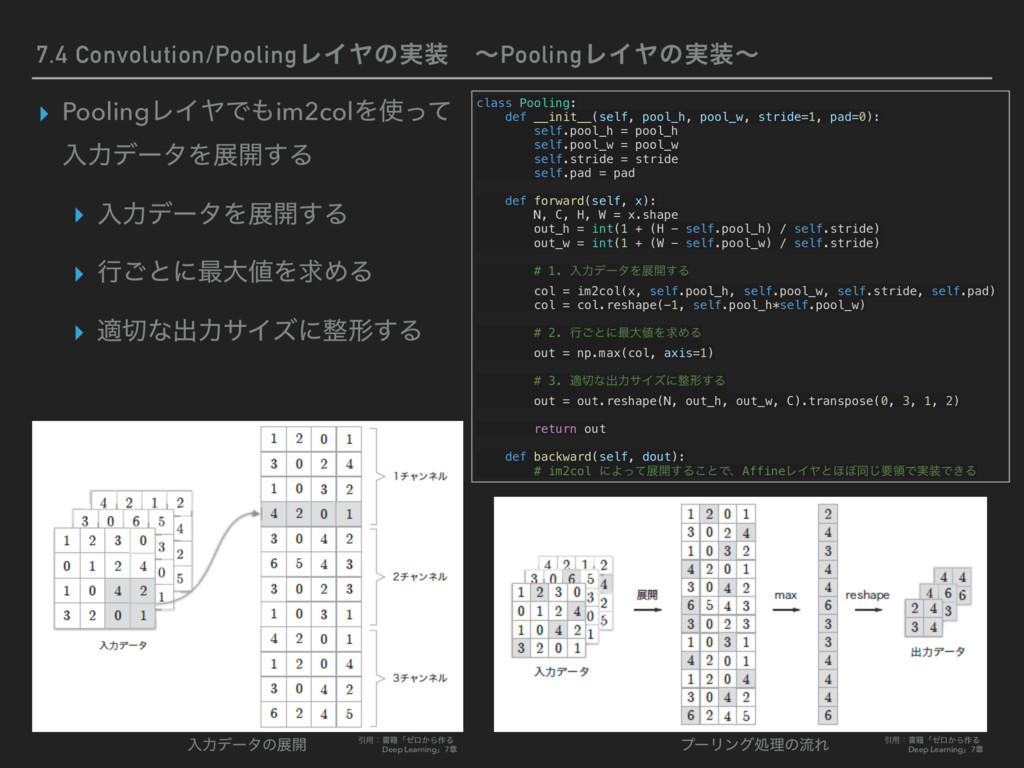
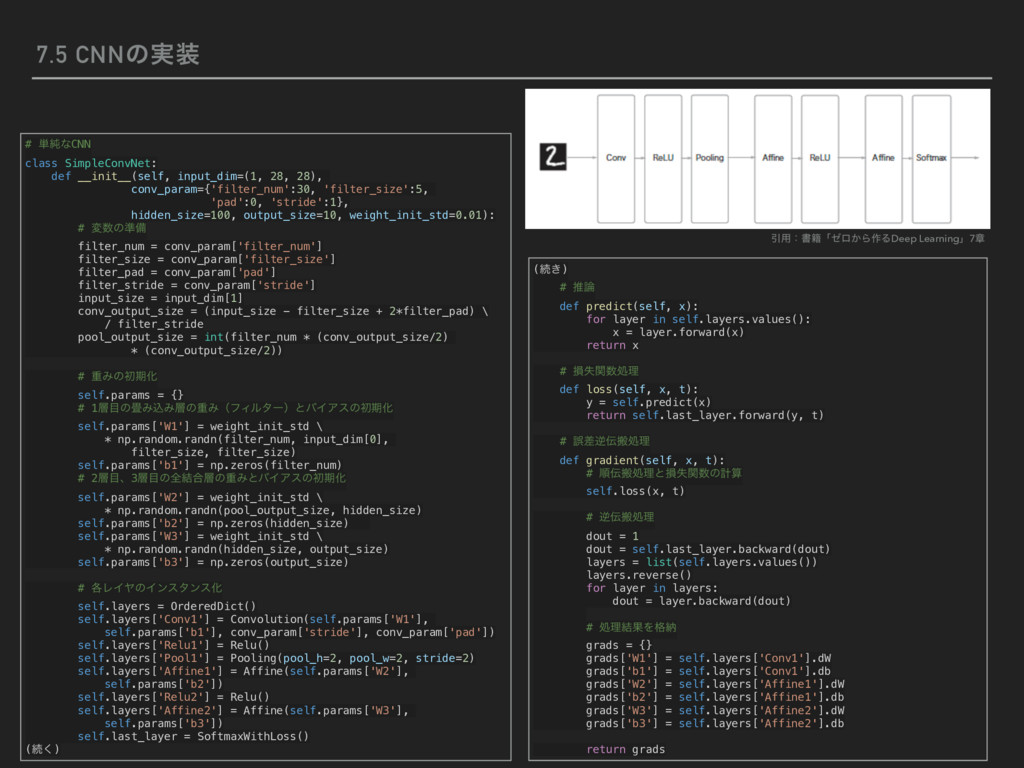
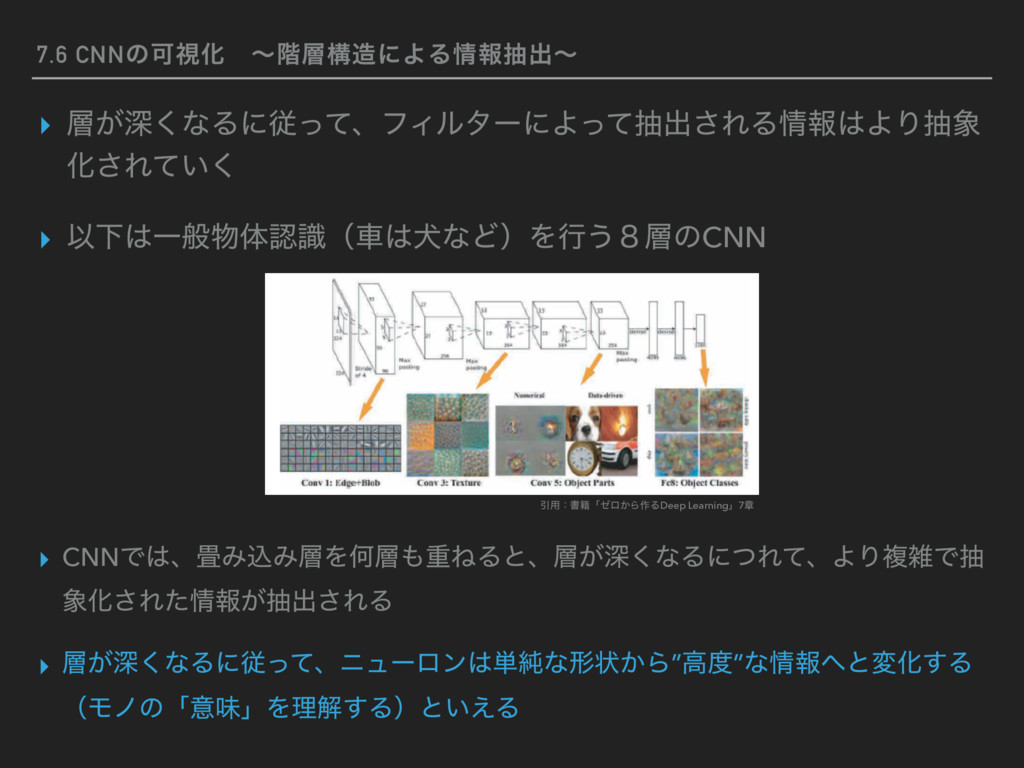
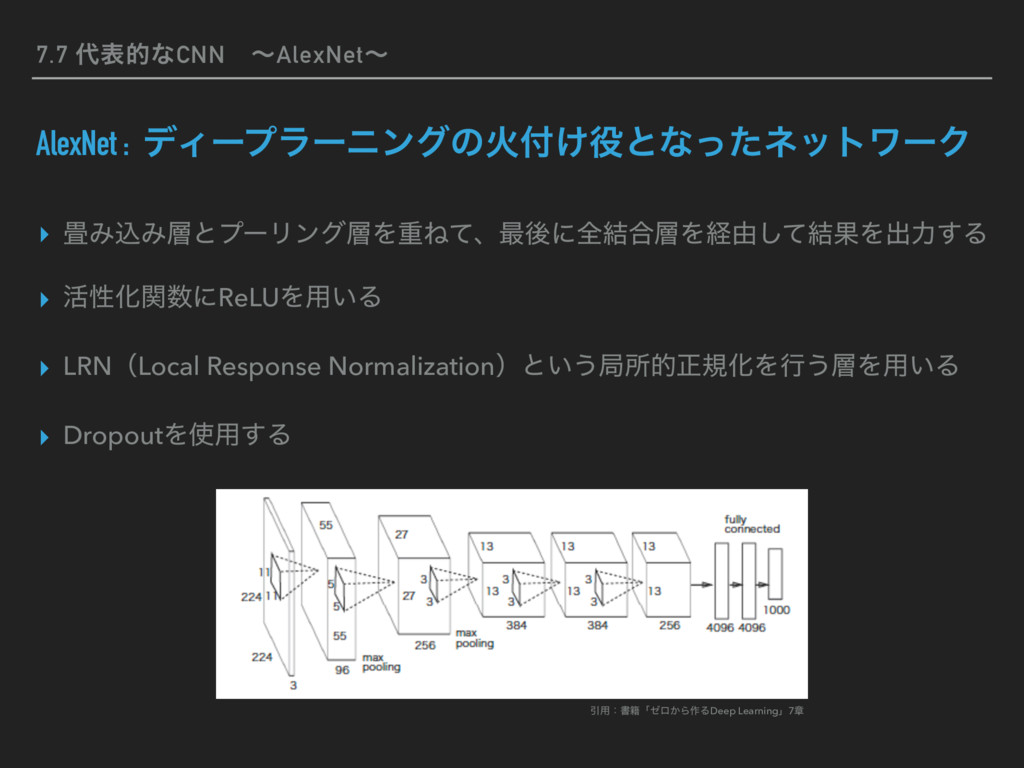
28), conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1}, hidden_size=100, output_size=10, weight_init_std=0.01): # มͷ४උ filter_num = conv_param['filter_num'] filter_size = conv_param['filter_size'] filter_pad = conv_param['pad'] filter_stride = conv_param['stride'] input_size = input_dim[1] conv_output_size = (input_size - filter_size + 2*filter_pad) \ / filter_stride pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2)) # ॏΈͷॳظԽ self.params = {} # 1ͷΈࠐΈͷॏΈʢϑΟϧλʔʣͱόΠΞεͷॳظԽ self.params['W1'] = weight_init_std \ * np.random.randn(filter_num, input_dim[0], filter_size, filter_size) self.params['b1'] = np.zeros(filter_num) # 2ɺ3ͷશ݁߹ͷॏΈͱόΠΞεͷॳظԽ self.params['W2'] = weight_init_std \ * np.random.randn(pool_output_size, hidden_size) self.params['b2'] = np.zeros(hidden_size) self.params['W3'] = weight_init_std \ * np.random.randn(hidden_size, output_size) self.params['b3'] = np.zeros(output_size) # ֤ϨΠϠͷΠϯελϯεԽ self.layers = OrderedDict() self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad']) self.layers['Relu1'] = Relu() self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2) self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2']) self.layers['Relu2'] = Relu() self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3']) self.last_layer = SoftmaxWithLoss() (ଓ͘) (ଓ͖) # ਪ def predict(self, x): for layer in self.layers.values(): x = layer.forward(x) return x # ଛࣦؔॲཧ def loss(self, x, t): y = self.predict(x) return self.last_layer.forward(y, t) # ޡࠩٯൖॲཧ def gradient(self, x, t): # ॱൖॲཧͱଛࣦؔͷܭࢉ self.loss(x, t) # ٯൖॲཧ dout = 1 dout = self.last_layer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # ॲཧ݁ՌΛ֨ೲ grads = {} grads['W1'] = self.layers['Conv1'].dW grads['b1'] = self.layers['Conv1'].db grads['W2'] = self.layers['Affine1'].dW grads['b2'] = self.layers['Affine1'].db grads['W3'] = self.layers['Affine2'].dW grads['b3'] = self.layers['Affine2'].db return grads Ҿ༻ɿॻ੶ʮθϩ͔Β࡞ΔDeep Learningʯ7ষ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}