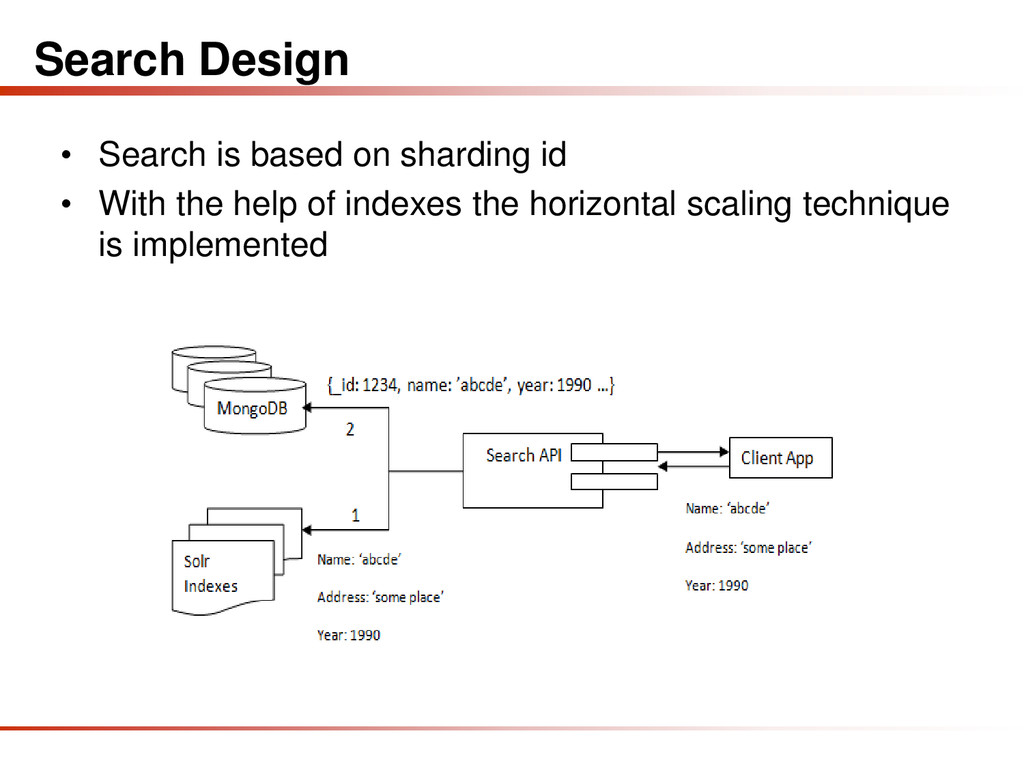
MongoDB is a part of NoSQL family with schema-less architecture, which has no constraints due to which retrieval and storing of data is faster and efficient. MongoDB helps in keeping the data simple by breaking up the workloads and in turn helps in tuning the workload which enhances performance and availability. In common, massive information is generated from interactive processing and visualizations. Centric architecture has been recently proposed to efficiently support information transmission over the Internet which provides communication services to big data. The goal of this presentation is to focus on large scale data which will be massive adoption of scaling technique
This paper was presented in the 5th National Conference On Emerging Trends In IT on 26th February , 2014 at Christ University, Hosur Road, Bangalore - 560 029, India
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
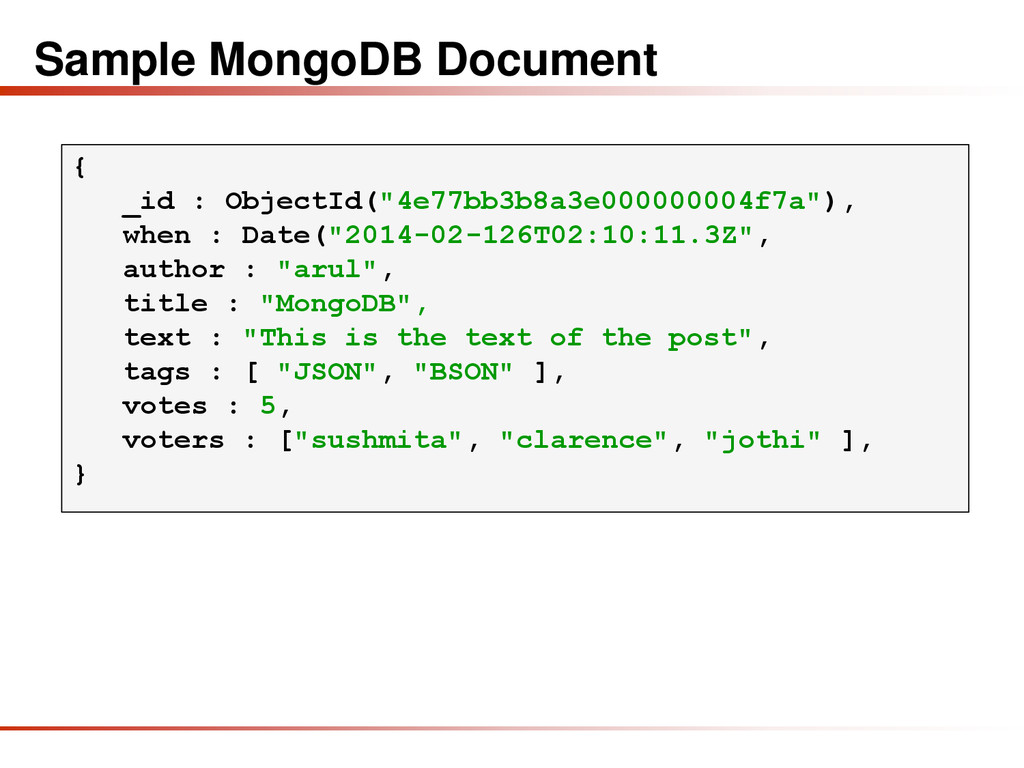{kind=link}
{kind=link}
{kind=link}
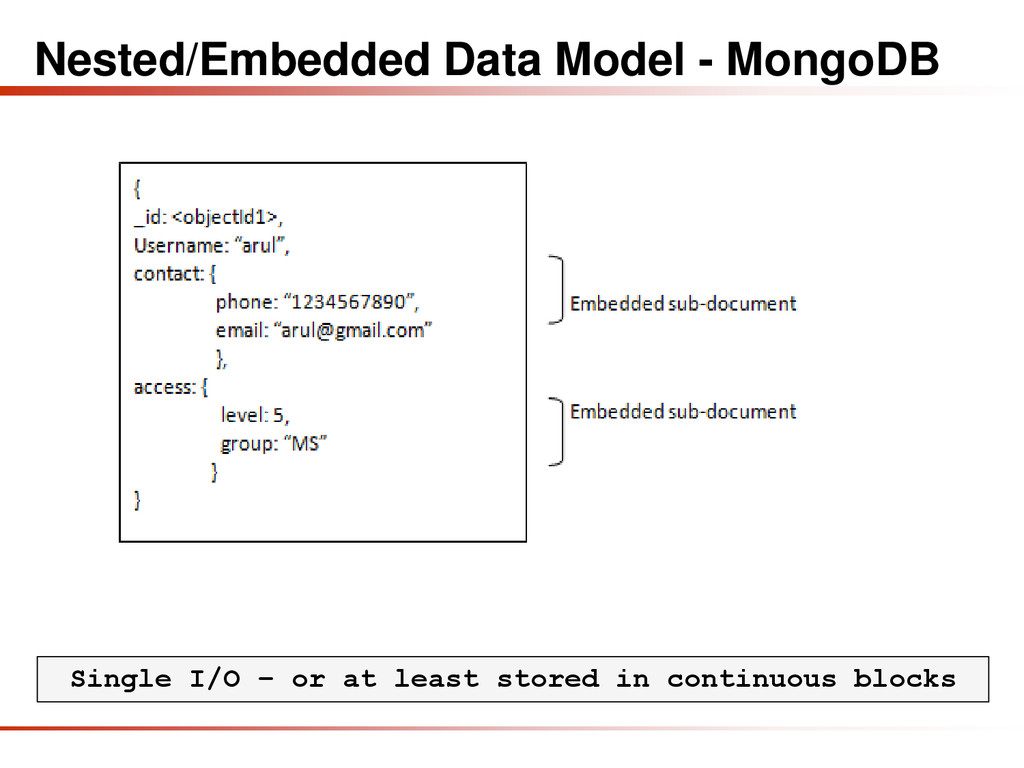{kind=link}
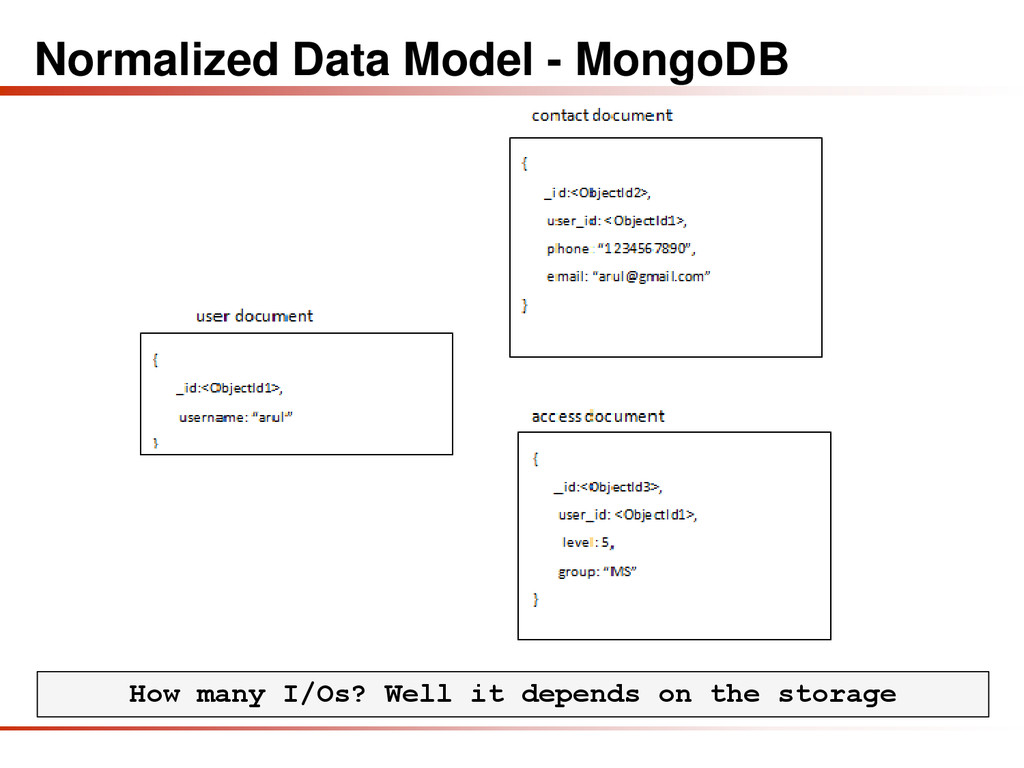{kind=link}
{kind=link}
{kind=link}
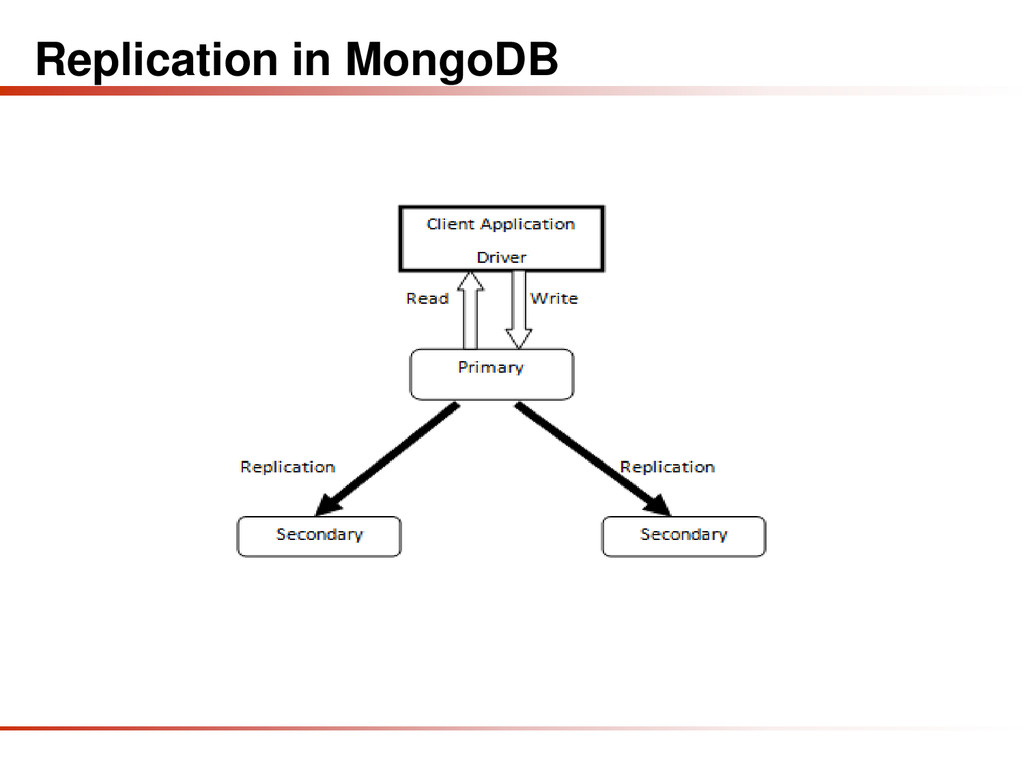{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}