release (DR1) and steady data releases. • Impact will be huge (it already is). • We recognize and appreciate how much work these early releases are. ◦ (But can we also get trial data to, say, train new models? cf. Steinmetz)
project of your choosing. • Enforced policy of openness. • Already produced 12 refereed papers! ◦ (including all Gaia results in this talk) • Next one is the week of 2018 June 03 in New York City. ◦ We will pay travel expenses for Gaia team members. ◦ http://gaia.lol/
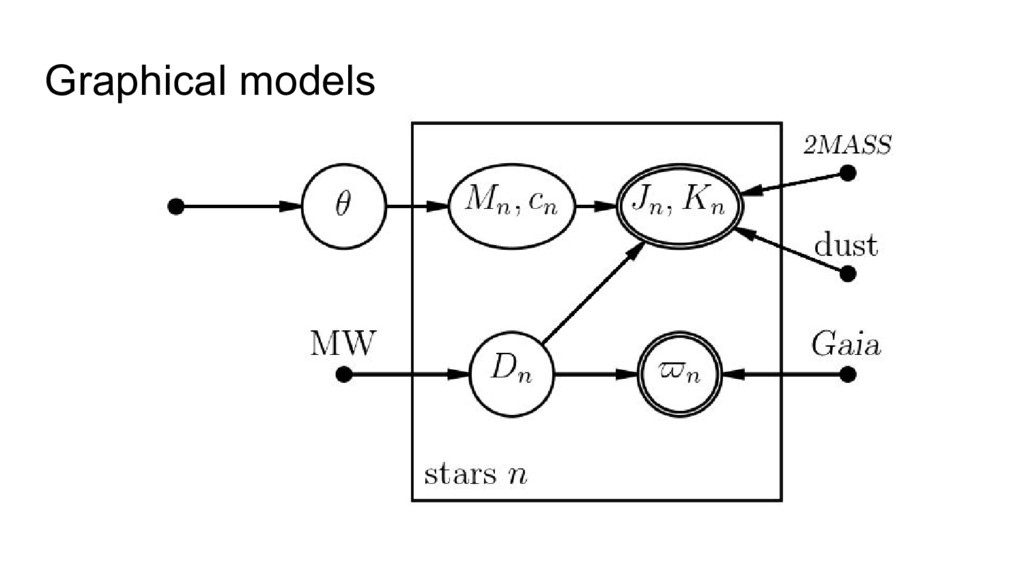
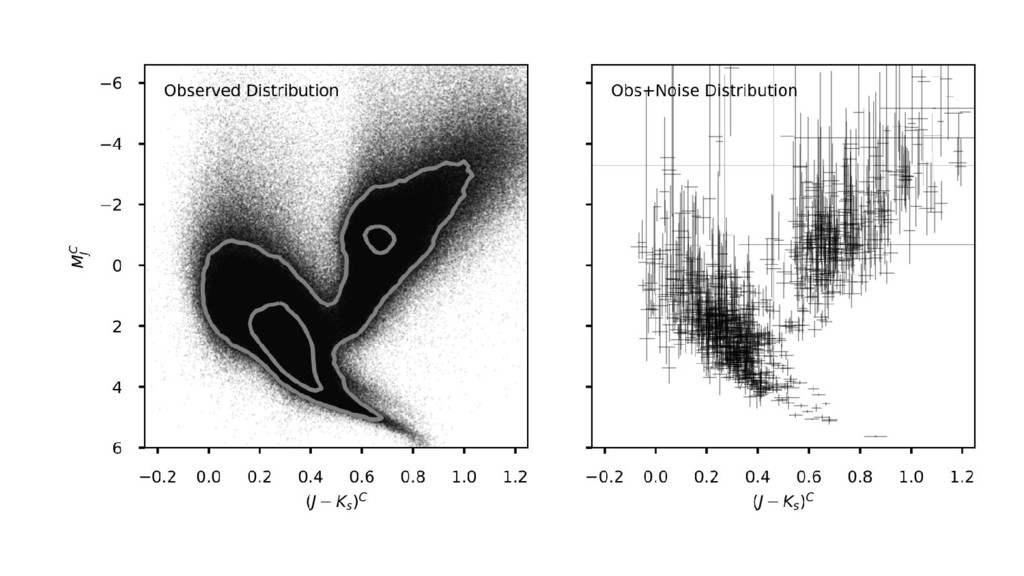
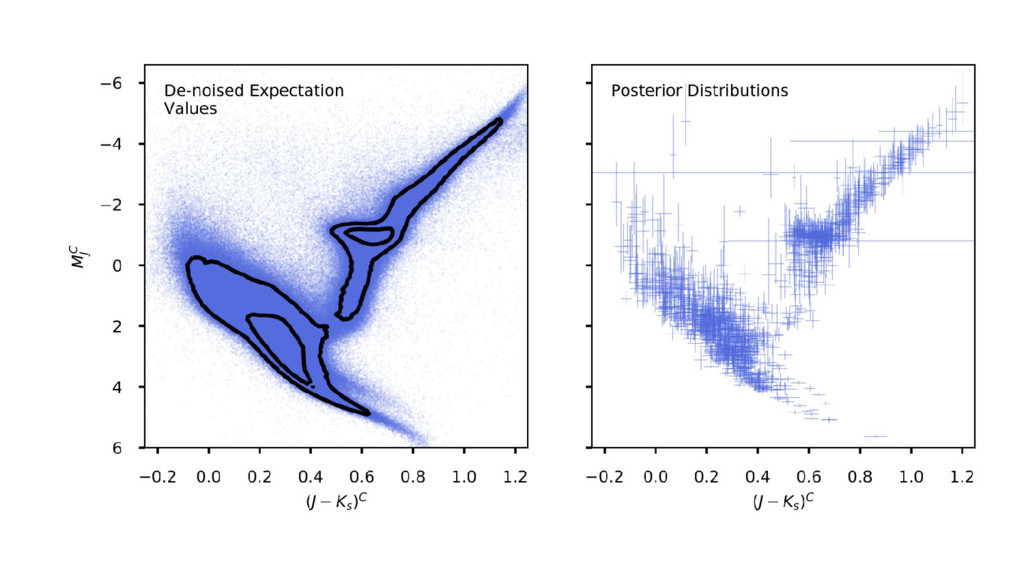
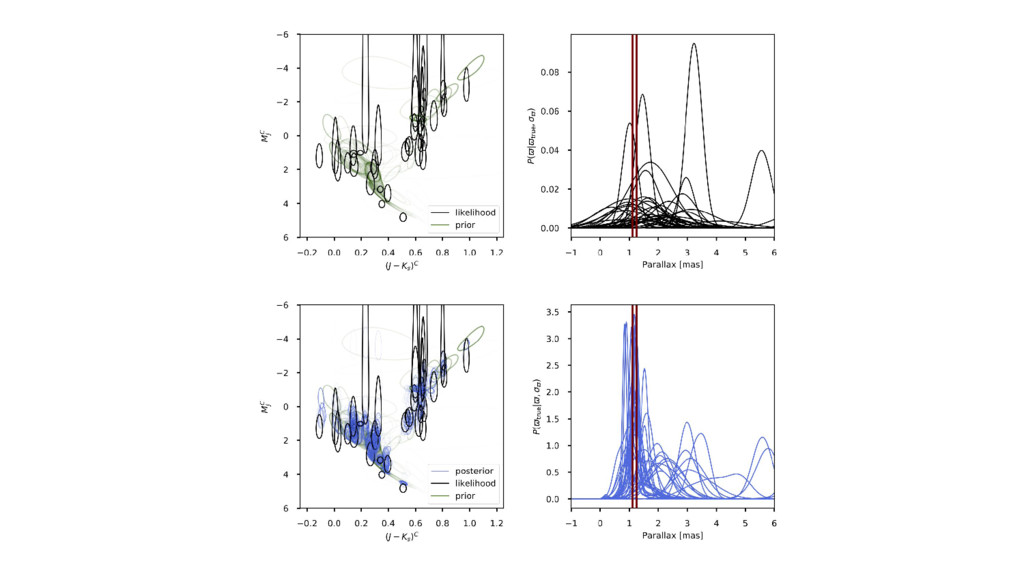
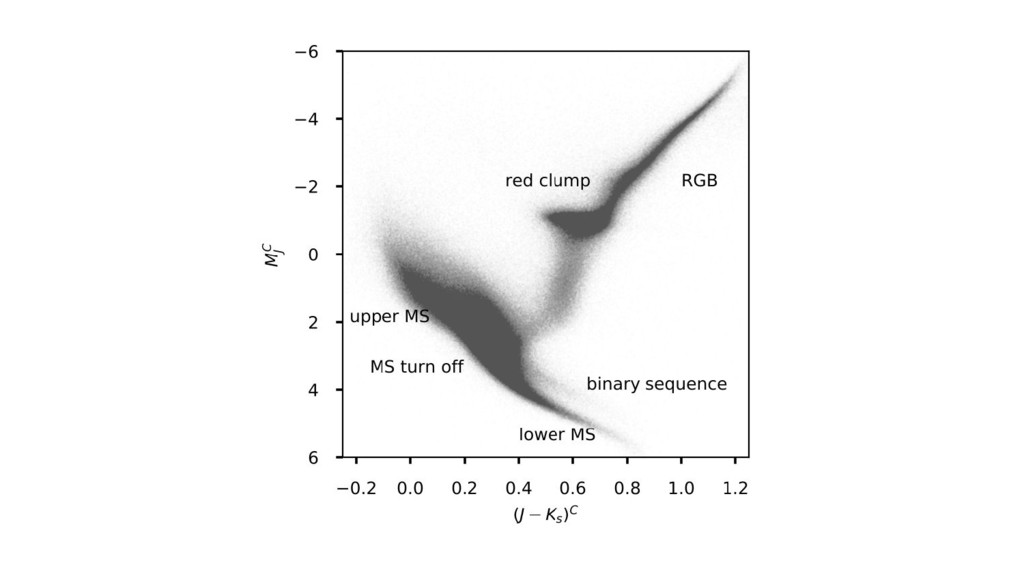
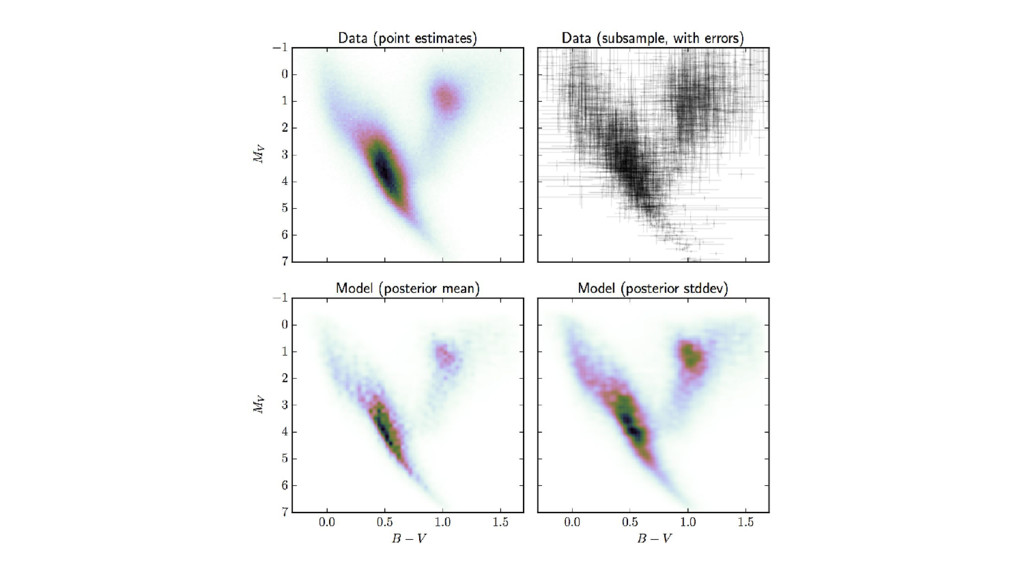
the noise-deconvolved color–magnitude diagram. • Using Gaia TGAS parallax and 2MASS photometric noise (uncertainties) responsibly. • Using rigid dust model (from Green et al). • ...Then use the CMD model to get improved parallaxes.
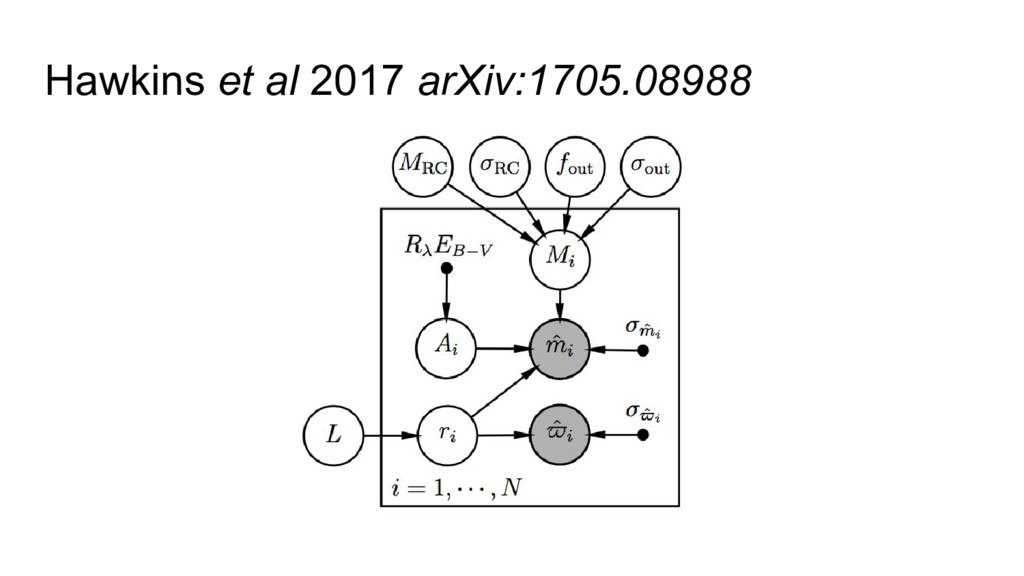
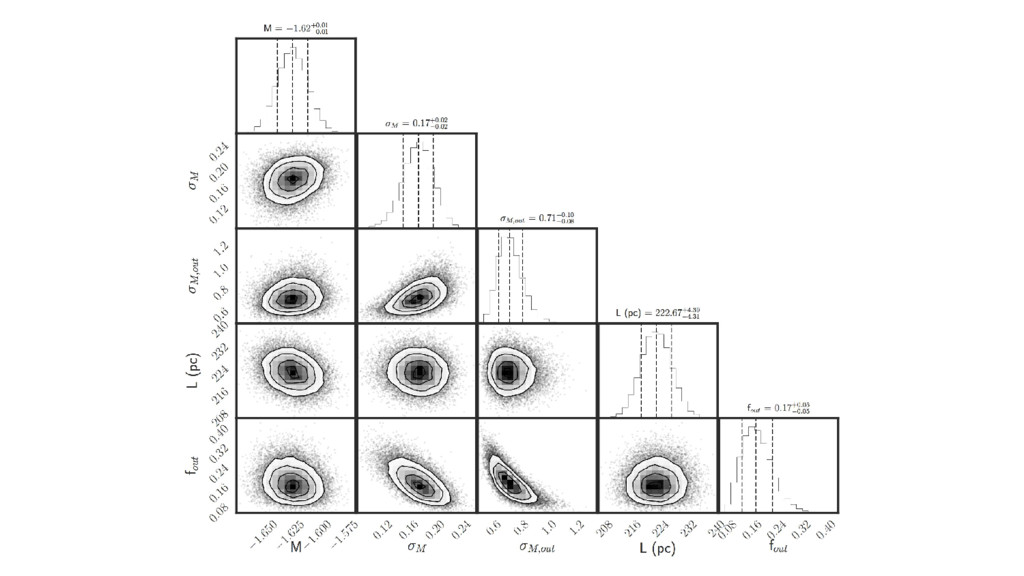
stars as standard candles? • Build a mixture model for RC stars and contaminants. • Fit for mean and dispersion of RC absolute magnitudes, taking account of the TGAS and photometric uncertainties. • ...Find 0.17 mag dispersion.
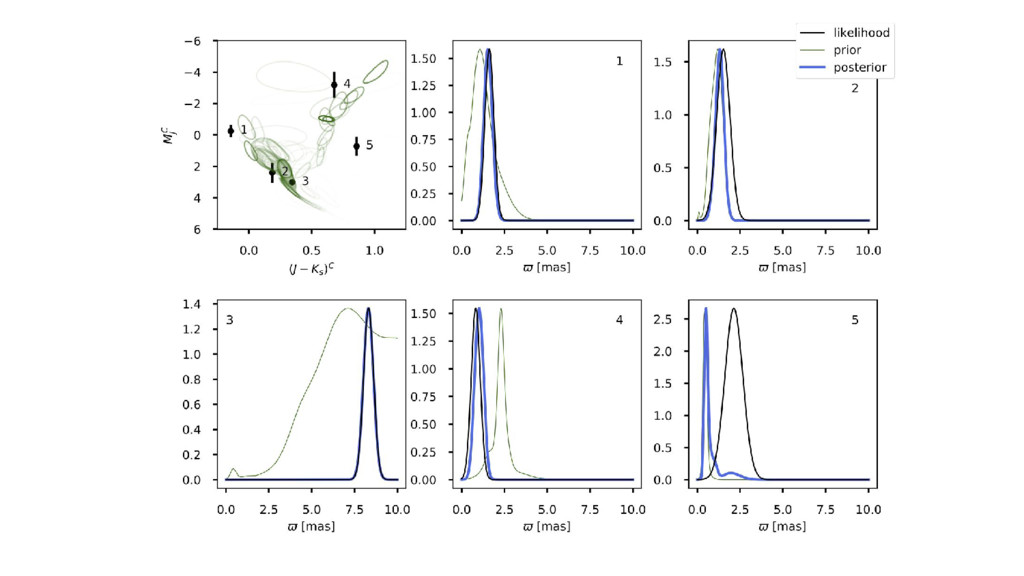
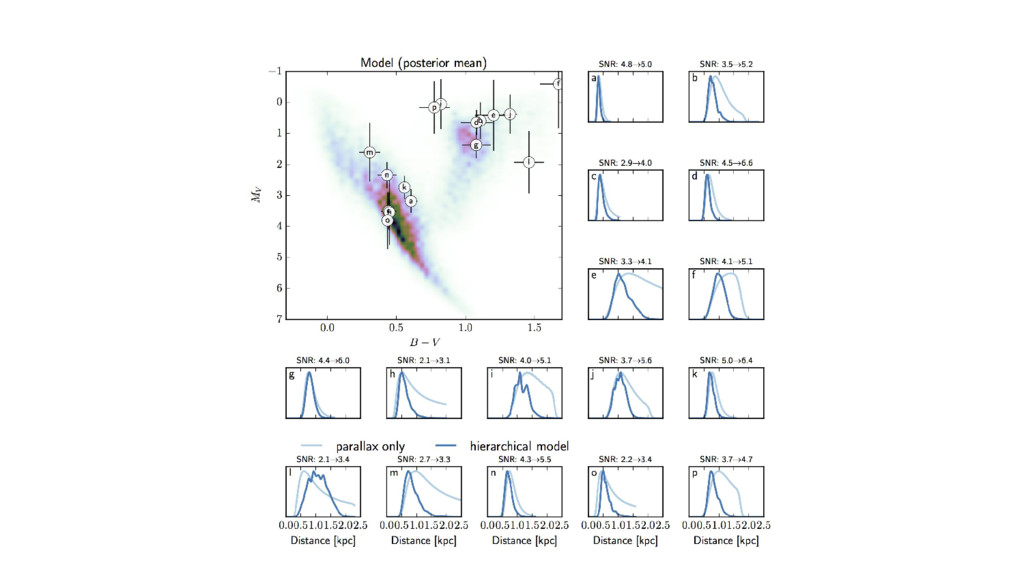
al, but fully Bayesian. • Model is less flexible, but it is tractable as a sampling problem. • ...Now distance posteriors are fully marginalized with respect to CMD models!
et al). ◦ Maximum marginalized likelihood (eg, Anderson et al). ◦ Maximum likelihood (eg, Ness et al). • The important thing is the causal structure, not the statistical philosophy.
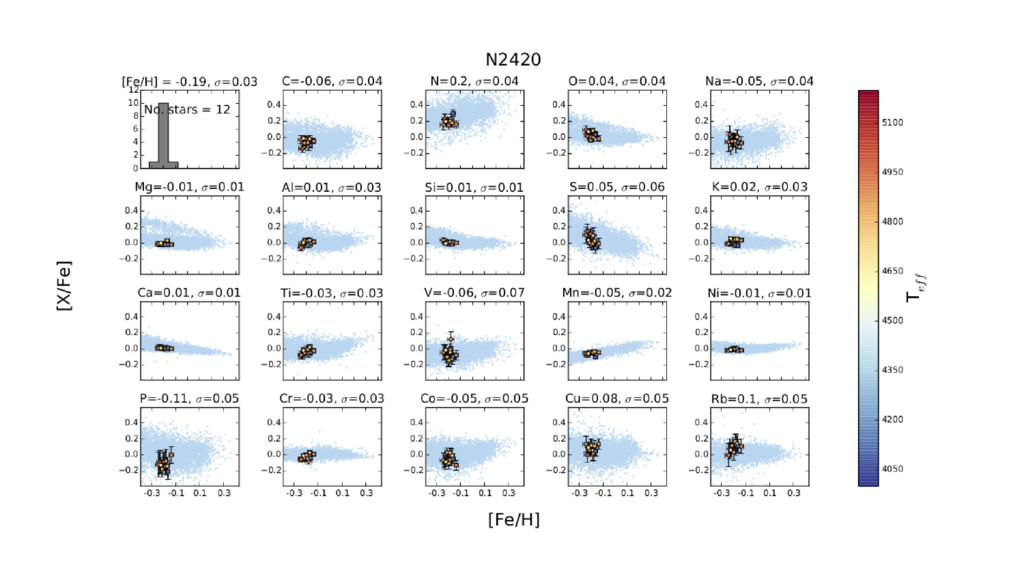
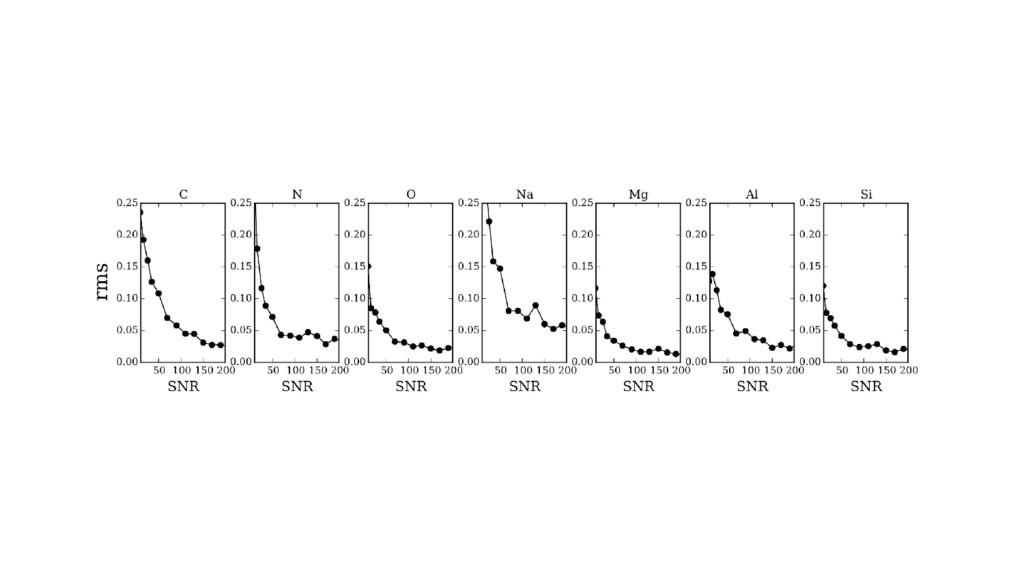
as training set. • Train The Cannon (Ness et al 2015) to get detailed chemical abundances. • Apply to low-SNR APOGEE spectra. • ...Find far more precise chemical homogeneity among cluster stars than in the training data. ◦ (also: better results at lower SNR)
with distance like parallaxes. • With a position–velocity model for the MW, they can be combined. ◦ cf. Floor’s talk; cf. “reduced proper motion” ◦ At large distances (and 10-year mission) we expect proper motions might dominate information.
distributions of metallicity -> different color–magnitude diagrams. • Solution: Add kinematics and Galactocentric distance into the graphical model, and permit the model to discover this.
numerical stellar models to generate photometric parallaxes. • The billion-star catalog plus statistical shrinkage will deliver enormous precision (and accuracy), better than any physics models. • Data > Numerical models of stars.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}