Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
会社でMLモデルを作るとは @電気通信大学 データアントレプレナーフェロープログラム
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
yuto16
September 21, 2025
Science
760
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
会社でMLモデルを作るとは @電気通信大学 データアントレプレナーフェロープログラム
下記登壇時の発表資料です。
https://www.de.uec.ac.jp/
yuto16
September 21, 2025
More Decks by yuto16
See All by yuto16
Streamlit in Snowflakeで加速する 不動産テック企業のデータ活用@Tech業界ネットワーキングイベント
yuto16
0
180
Snowflakeで実現する広告画像評価の自動化と属人化解消 @Snowflake MEATup
yuto16
0
380
GA technologiesでのAI-Readyの取り組み@DataOps Night
yuto16
0
730
Cortexで加速する AI不動産投資 RENOSYのデータ活用 @Snowflake ACCELERATE
yuto16
0
550
Streamlit in Snowflakeで加速する不動産テック企業のデータ活用 @Snowflake WESTユーザー会
yuto16
1
780
Other Decks in Science
See All in Science
データベース03: 関係データモデル
trycycle
PRO
1
640
大黒市で発生した大規模インシデント の ポストモーテムから読み解く、 記憶媒体消去の大切さ
shucho0103
0
210
CVPR2026_VGGTとその仲間たち
mickey_0226
0
990
AI bij literatuuronderzoek in de wetenschap
voginip
0
220
Conversation is the New Dashboard: 属人性を排除する第4世代BIツールの勢力図
shomaekawa
1
610
俺たちは本当に分かり合えるのか? ~ PdMとスクラムチームの “ずれ” を科学する
bonotake
3
2.5k
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
Build your own LLM, Live, with MicroGPT
ianozsvald
0
110
TypeScript で WebAssembly を用いた 型安全なプラグイン設計
nagano
2
570
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
analokmaus
1
600
データベース14: B+木 & ハッシュ索引
trycycle
PRO
0
720
Distributional Regression
tackyas
0
550
Featured
See All Featured
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Building an army of robots
kneath
306
46k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
The SEO identity crisis: Don't let AI make you average
varn
0
520
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Rails Girls Zürich Keynote
gr2m
96
14k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Transcript
会社でMLモデルを作るとは? ~入社1ヶ月目でMLモデルを作成した話 ~ @電気通信大学 データアントレプレナーフェロープログラム GA technologies Data本部
Applied ML部 酒井悠斗 Data Scientist 2025/09/13
1. 登壇者紹介 / 会社紹介 2. 会社でMLモデルを作るとは? ~具体例ともに ~ 3. まとめ
アジェンダ
登壇者紹介 酒井 悠斗 / Yuto Sakai 学歴:慶應義塾大学大学院 数理科学専攻 職歴:新卒で外資保険会社
→ 2024年 GA technologies入社 所属:Data本部 Applied ML部 データサイエンティスト GA technologiesでの取り組み: ・デジタルマーケティング領域の出稿割合の最適化 ・セールス領域の行動とKPIの関連性可視化・分析 ・社内でのLLMアプリ作成ツール導入による LLMの民主化
会社紹介 / GA technologies ※コーポレートストーリー 2025年6月より(証券コード:3491)
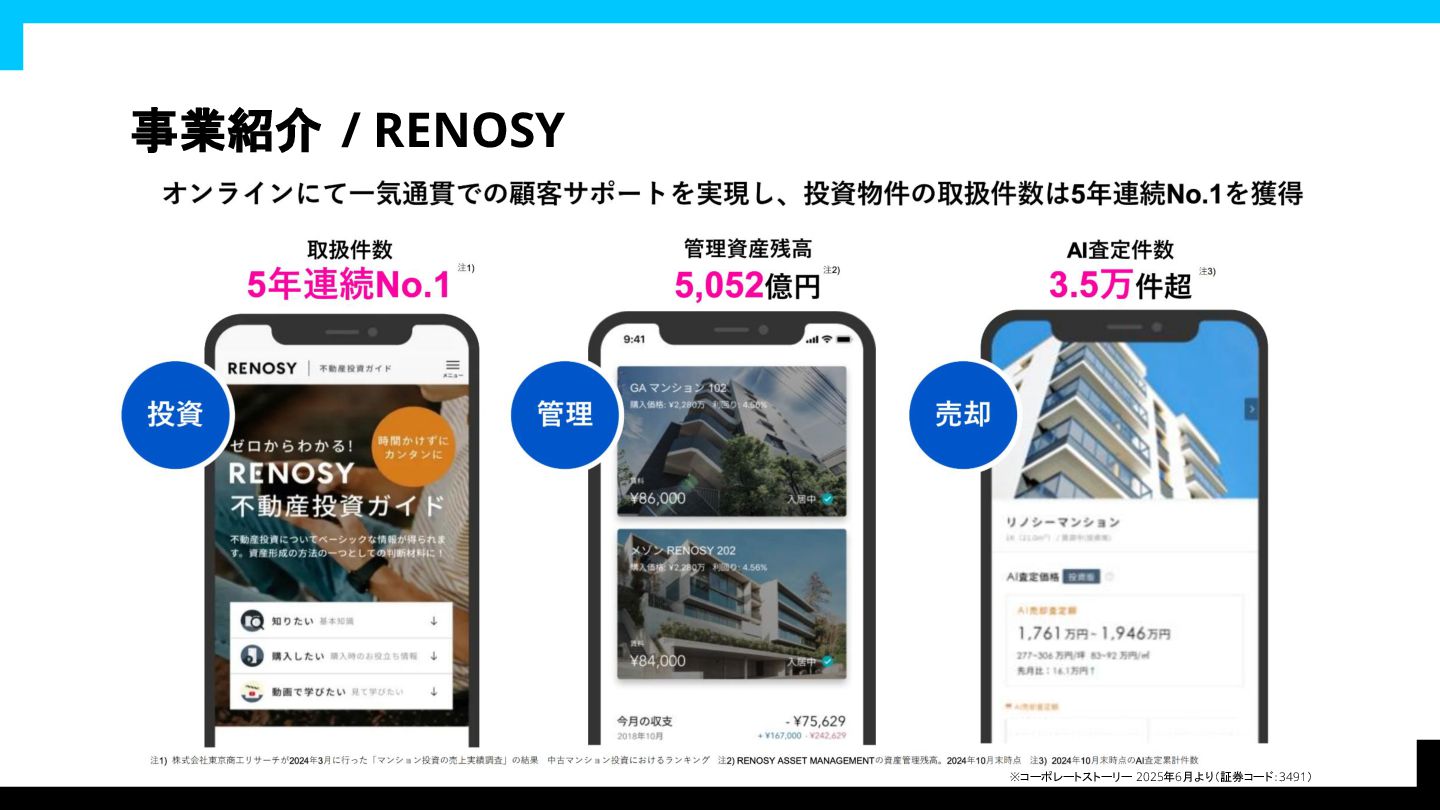
事業紹介 / RENOSY ※1 東京商工リサーチによる投資用不動産の売上実績(2025年3月調べ) ※2 東京商工リサーチによる投資用不動産会社の売上原価調査(2024年10月調べ)
事業紹介 / RENOSY ※コーポレートストーリー 2025年6月より(証券コード:3491)
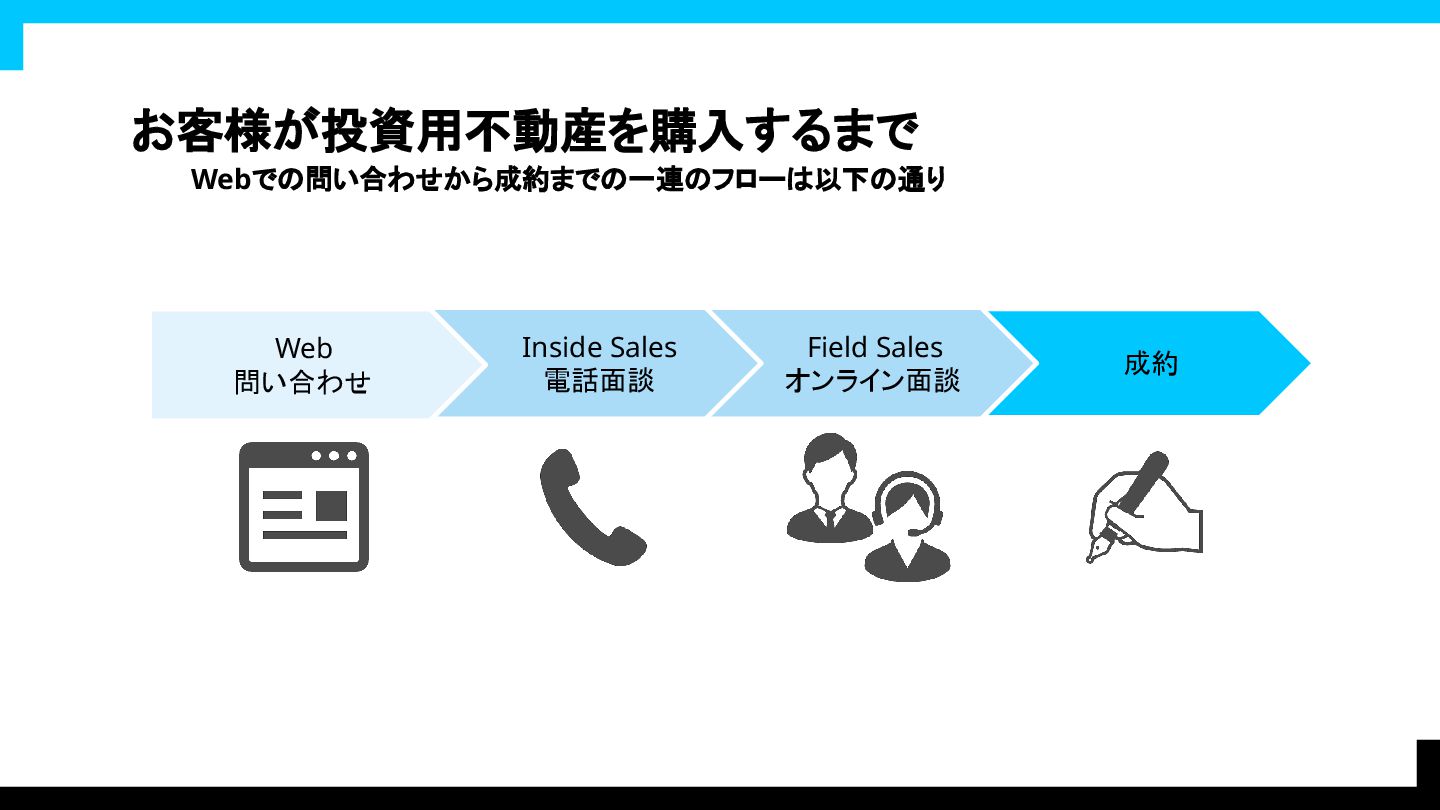
お客様が投資用不動産を購入するまで Webでの問い合わせから成約までの一連のフローは以下の通り 成約 Field Sales オンライン面談 Inside Sales
電話面談 Web 問い合わせ
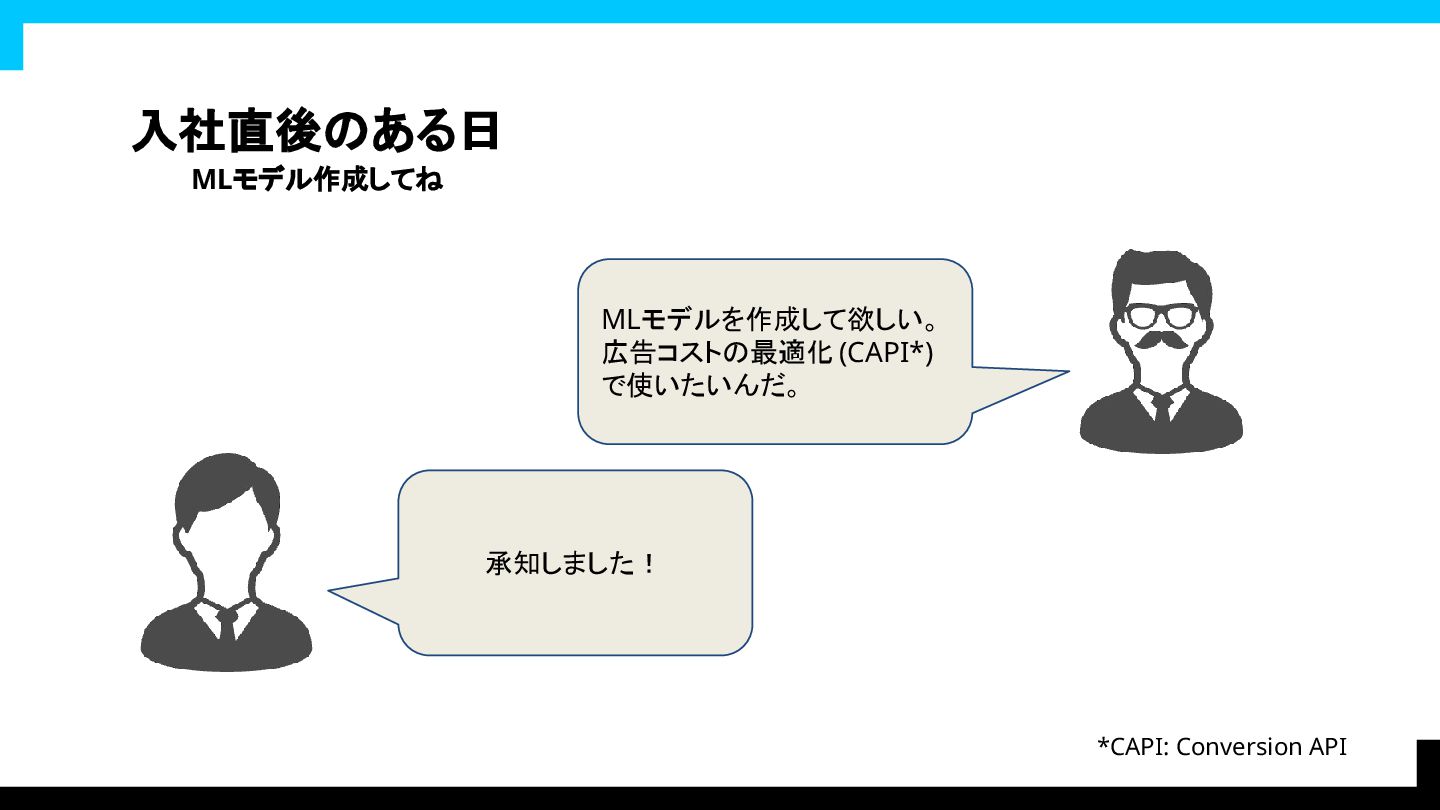
入社直後のある日 MLモデル作成してね 承知しました! MLモデルを作成して欲しい。 広告コストの最適化 (CAPI*) で使いたいんだ。 *CAPI:
Conversion API
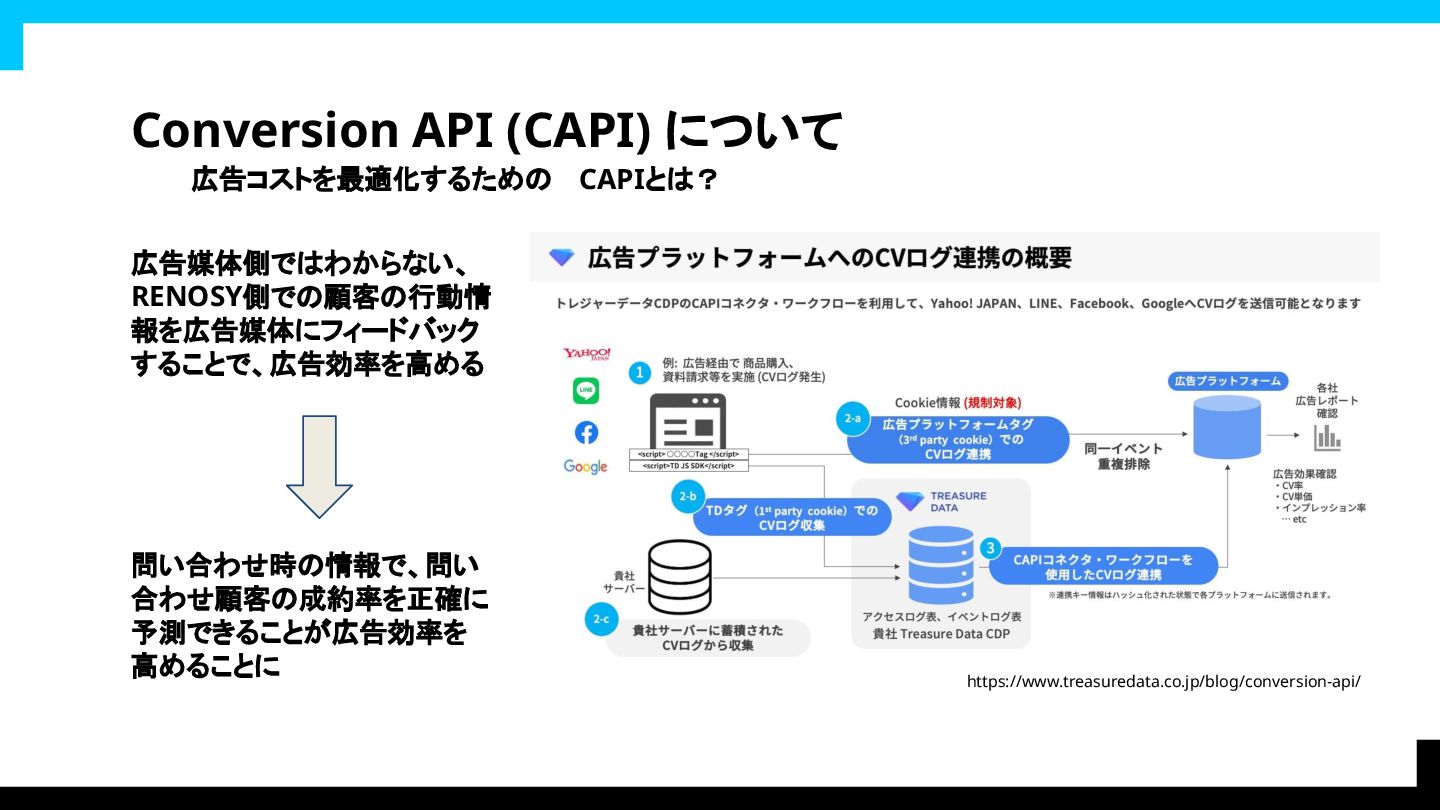
Conversion API (CAPI) について 広告コストを最適化するための CAPIとは? https://www.treasuredata.co.jp/blog/conversion-api/ 広告媒体側ではわからない、 RENOSY側での顧客の行動情 報を広告媒体にフィードバック
することで、広告効率を高める 問い合わせ時の情報で、問い 合わせ顧客の成約率を正確に 予測できることが広告効率を 高めることに
入社直後のある日 いざMLモデル作り よし!がんばるぞ!あれ・・・?
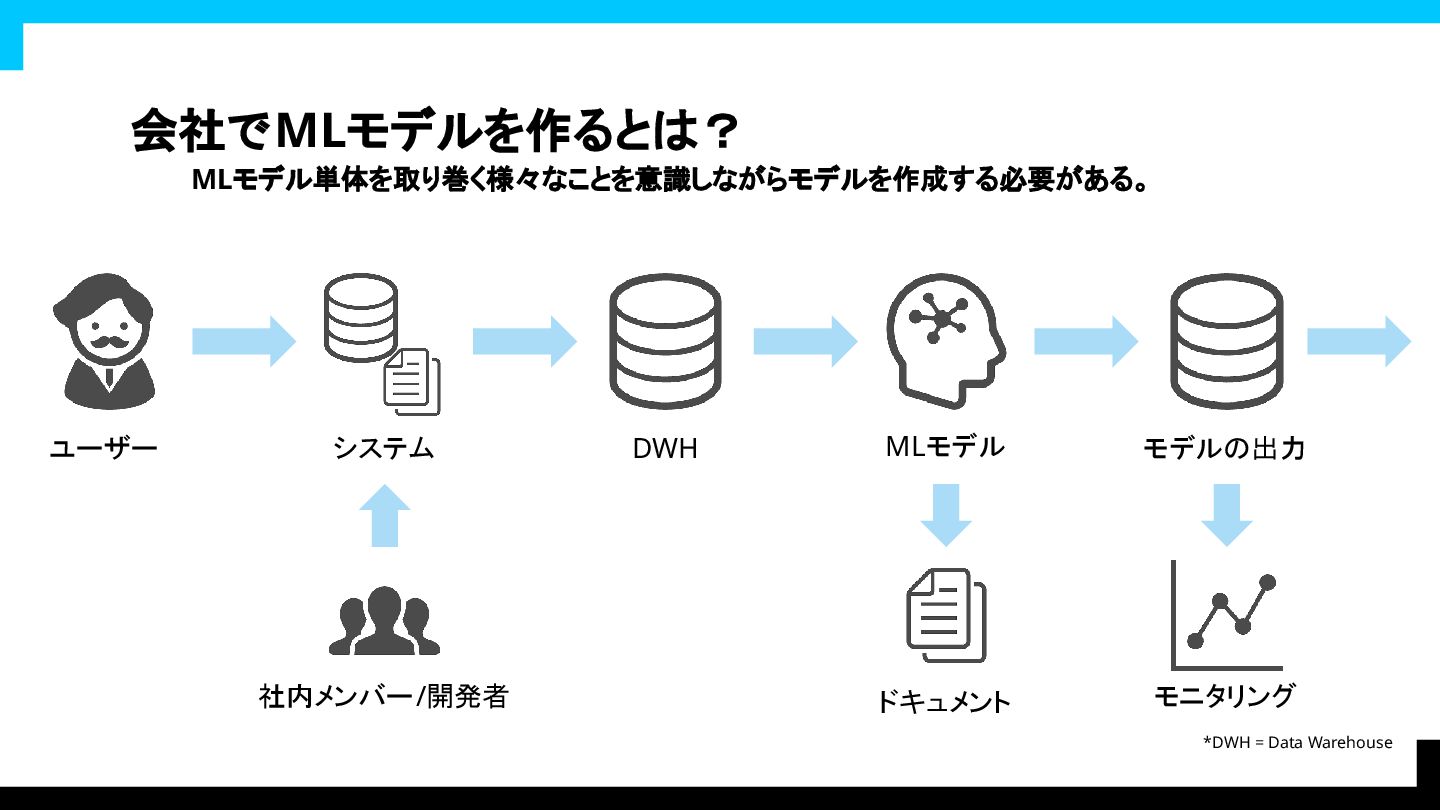
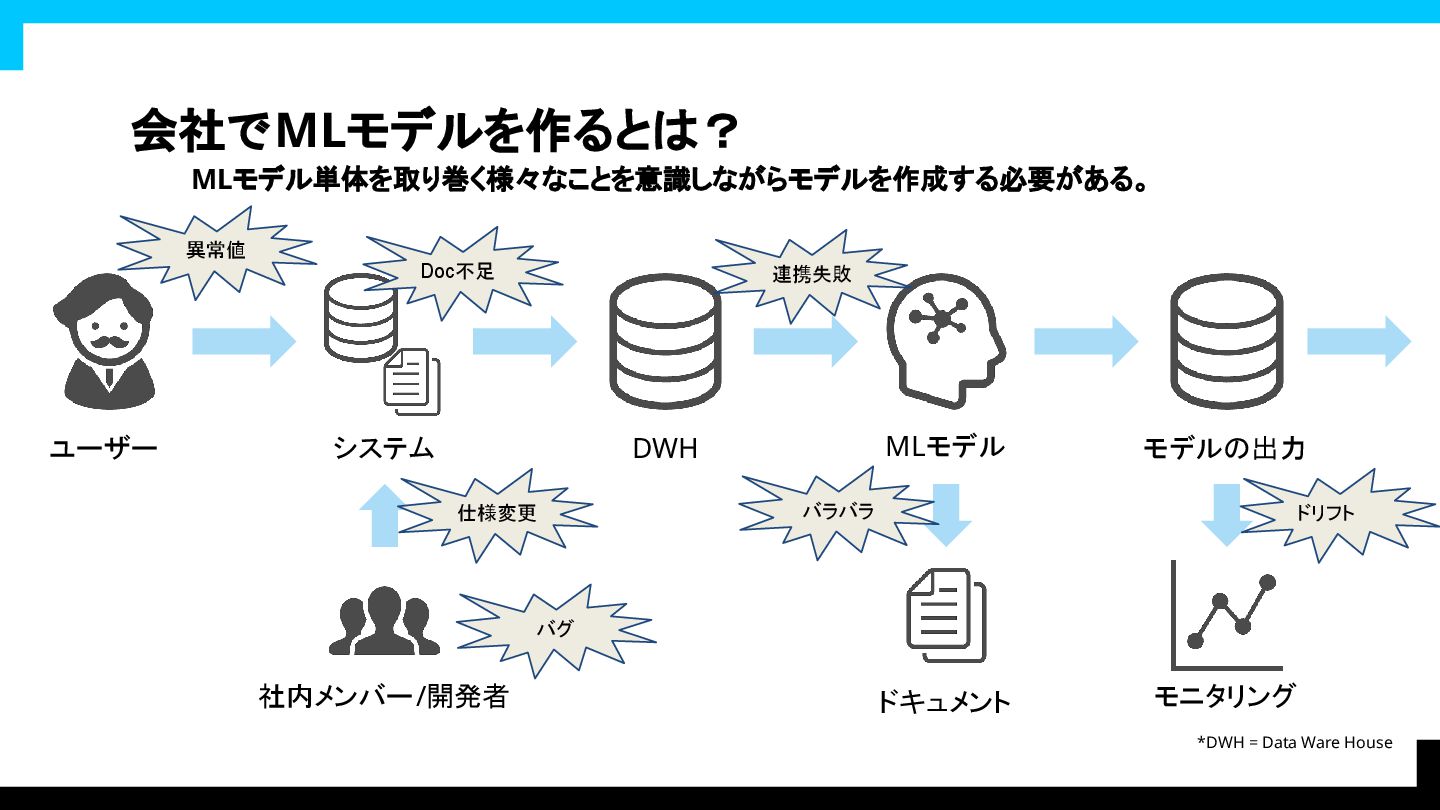
会社でMLモデルを作るとは? MLモデル単体を取り巻く様々なことを意識しながらモデルを作成する必要がある。 ユーザー 社内メンバー/開発者 システム DWH *DWH =
Data Warehouse MLモデル ドキュメント モデルの出力 モニタリング
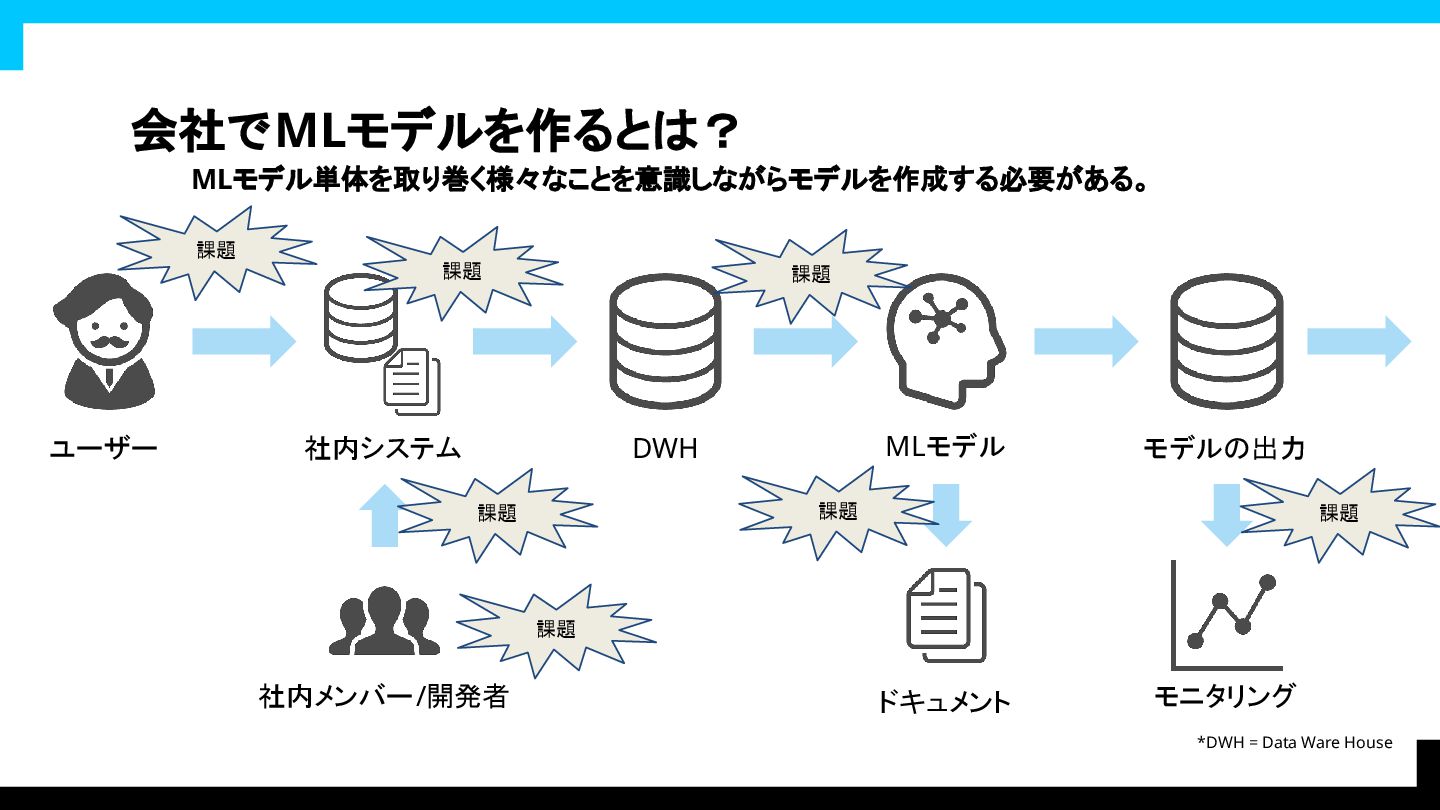
会社でMLモデルを作るとは? MLモデル単体を取り巻く様々なことを意識しながらモデルを作成する必要がある。 ユーザー 社内メンバー/開発者 社内システム DWH *DWH =
Data Ware House MLモデル ドキュメント モデルの出力 モニタリング 課題 課題 課題 課題 課題 課題 課題
どんな変数使えそうかな? 変数の意味調べてみよう! モデル作成段階
データカタログの情報が不十分 データの説明が 100%整備されていることはまずないです しっかり説明が記載されているプロダクトもあった り、そうではないものも・・・ 社内のドキュメント +
人に聞く (長期的にはデータガバナンスの強化が大切) 用語:SchemaSpy, OpenMetadata 課題 解決策
変数の時系列での分布がおかしいぞ? モデル作成段階
不正確なデータ 過去のデータの値・説明が正しい保証はないです。 エンジニアの実装ミスで一定期間の値のマッピン グが間違っていたことも 該当期間のデータを正しく修復できそうなら修復。 難しそうなら削除
課題 解決策
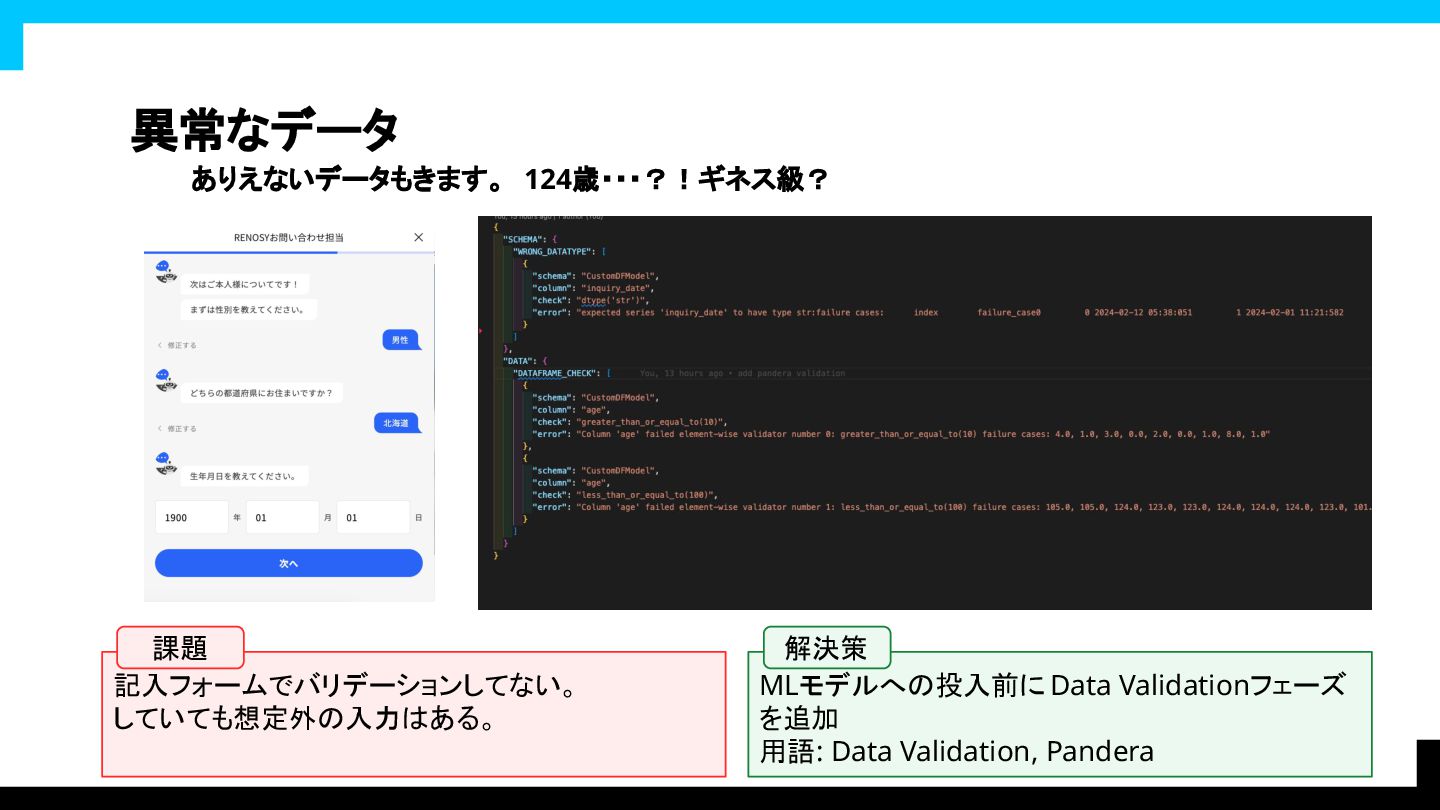
あれ、ありえないデータが? モデル作成段階
異常なデータ ありえないデータもきます。 124歳・・・?!ギネス級? 記入フォームでバリデーションしてない。 していても想定外の入力はある。 MLモデルへの投入前に
Data Validationフェーズ を追加 用語: Data Validation, Pandera 課題 解決策
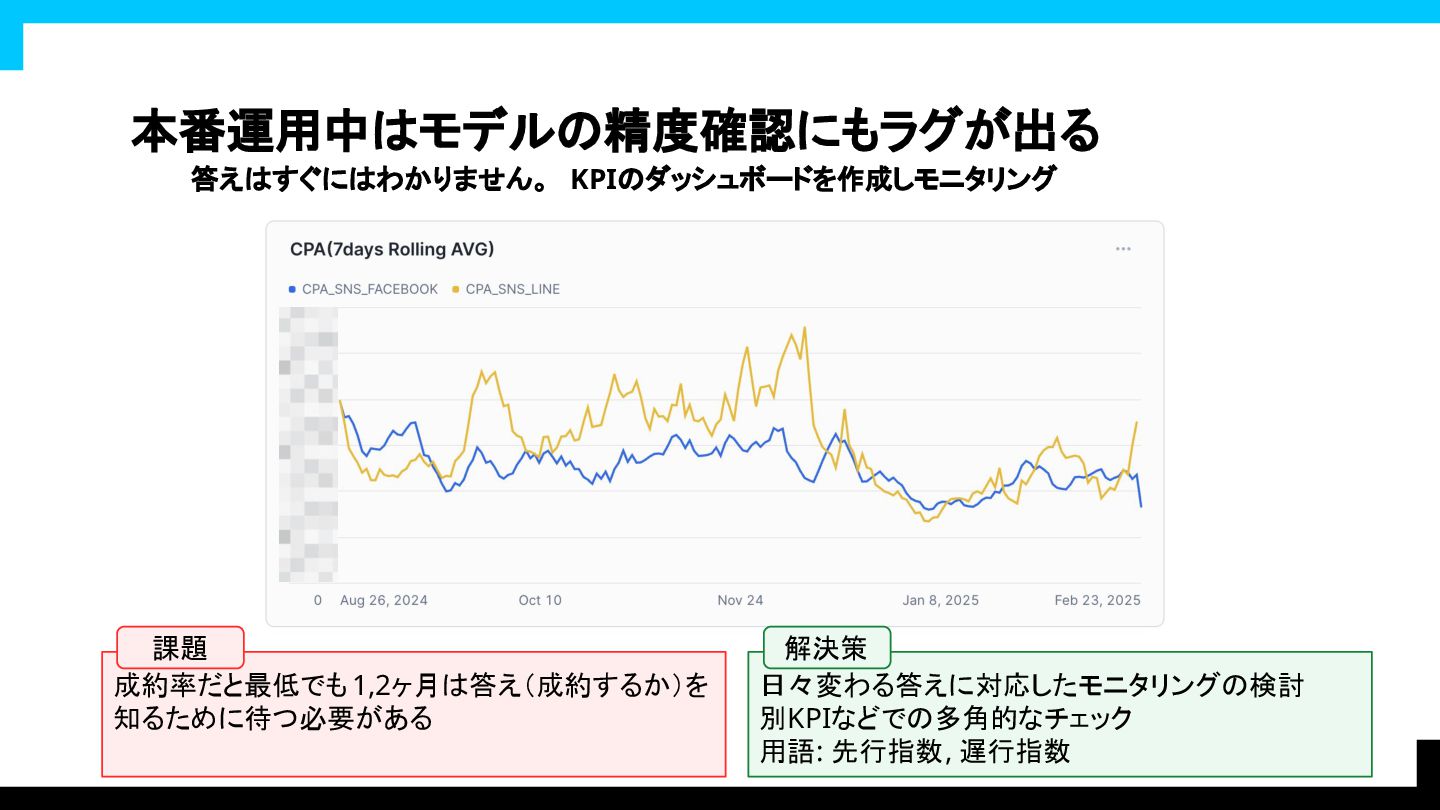
リリース直後: モデルうまく動いているかな・・・ ドキドキ・・・ モデルリリース
本番運用中はモデルの精度確認にもラグが出る 答えはすぐにはわかりません。 KPIのダッシュボードを作成しモニタリング 成約率だと最低でも 1,2ヶ月は答え(成約するか)を 知るために待つ必要がある 日々変わる答えに対応したモニタリングの検討
別KPIなどでの多角的なチェック 用語: 先行指数, 遅行指数 課題 解決策
リリース後のある日: あれ、今日の分のMLモデルの出力が 無い?! リリース後
データ連携の失敗 パイプラインは失敗するもの Cloudサービス・実装ミス・予期しない負荷などの 影響でデータフローは失敗する フローの各地点でうまく動いているかどうか記録・ エラーの検知を設定しておく
用語: Logging, Webhook 課題 解決策
リリース後のある日: あれ、MLモデルの出力おかしいぞ * *フィクションです。実際この時は事前に 社内で情報共有がありました。 リリース後
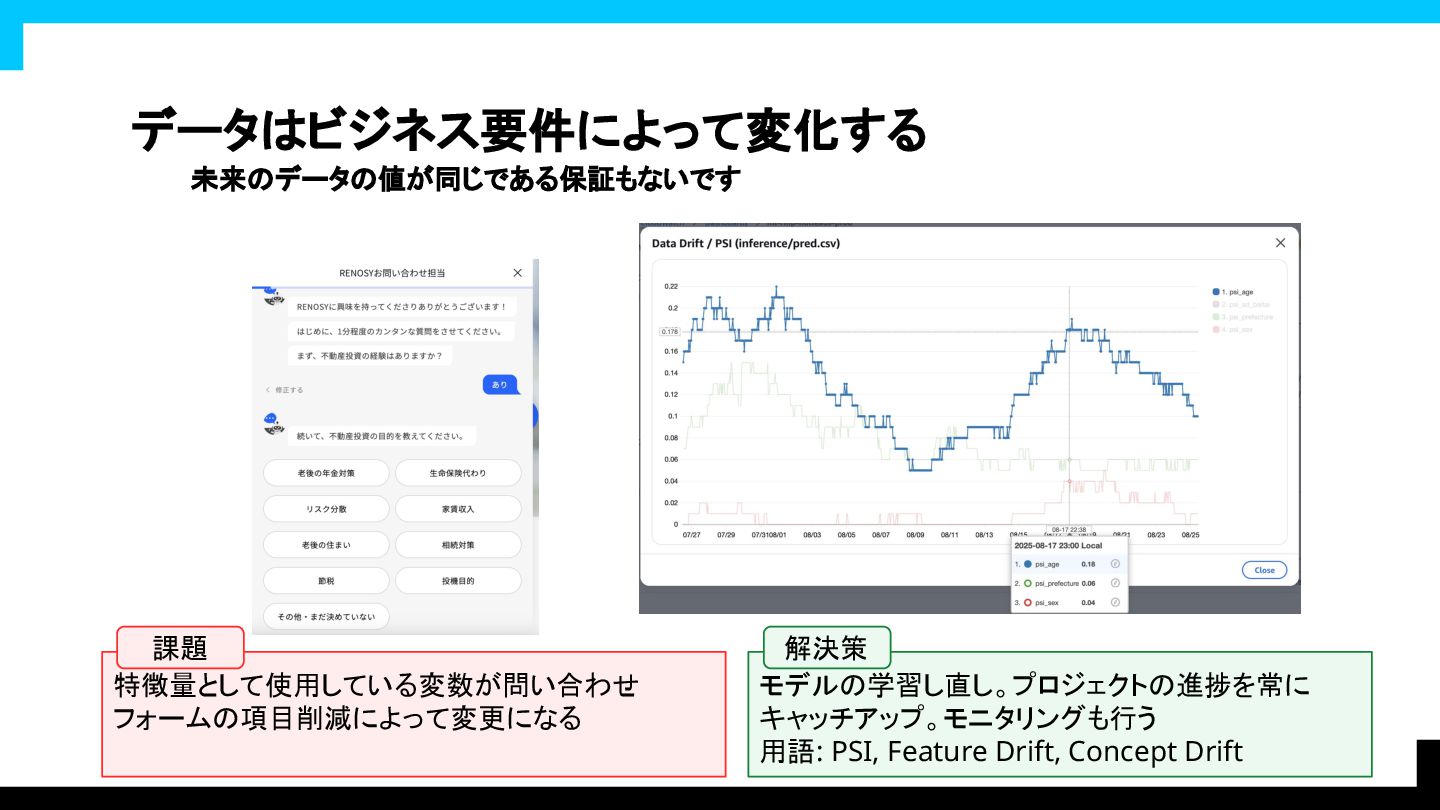
データはビジネス要件によって変化する 未来のデータの値が同じである保証もないです 特徴量として使用している変数が問い合わせ フォームの項目削減によって変更になる モデルの学習し直し。プロジェクトの進捗を常に キャッチアップ。モニタリングも行う
用語: PSI, Feature Drift, Concept Drift 課題 解決策
他にも気にする点あります
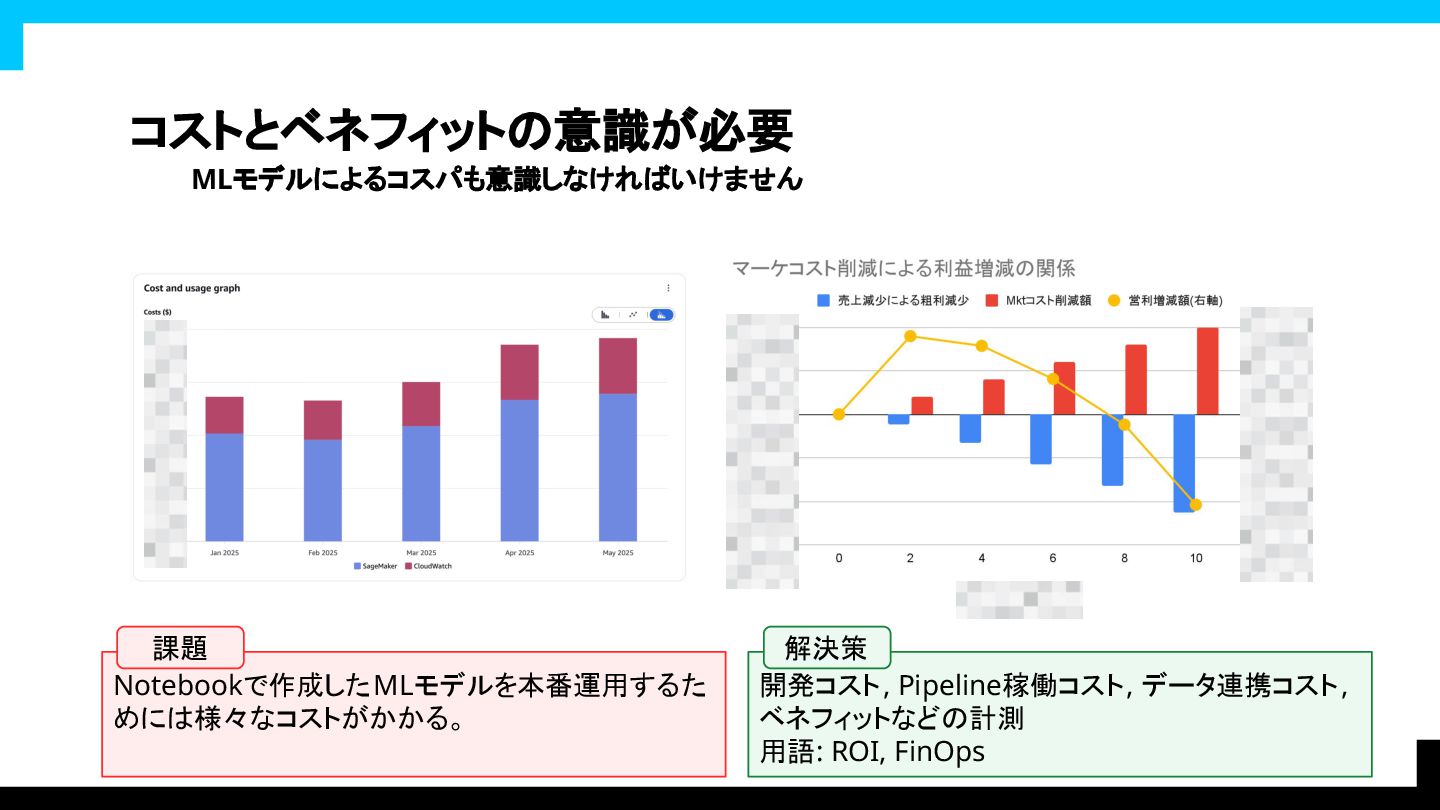
コストとベネフィットの意識が必要 MLモデルによるコスパも意識しなければいけません Notebookで作成したMLモデルを本番運用するた めには様々なコストがかかる。 開発コスト, Pipeline稼働コスト, データ連携コスト,
ベネフィットなどの計測 用語: ROI, FinOps 課題 解決策
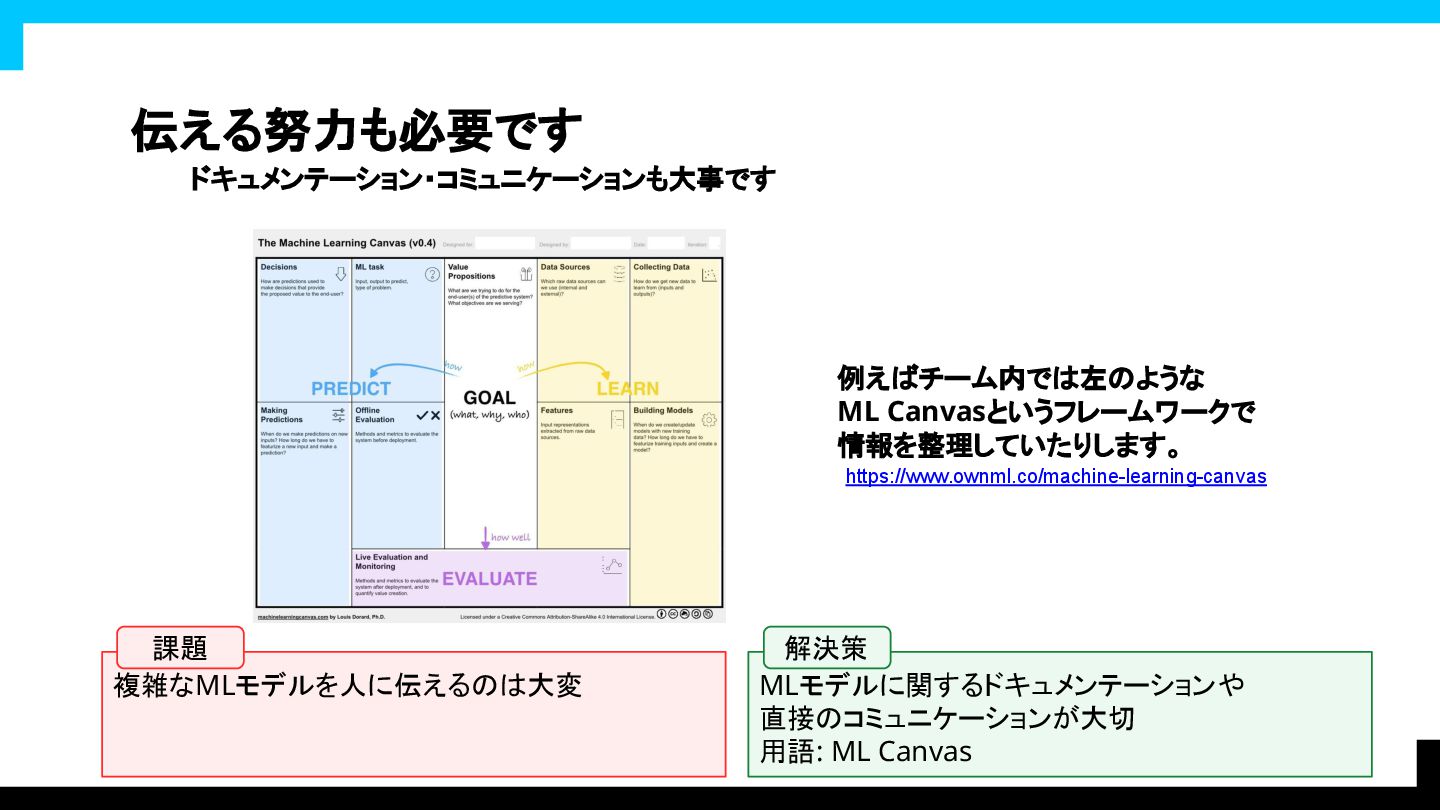
伝える努力も必要です ドキュメンテーション・コミュニケーションも大事です https://www.ownml.co/machine-learning-canvas 例えばチーム内では左のような ML Canvasというフレームワークで 情報を整理していたりします。
複雑なMLモデルを人に伝えるのは大変 MLモデルに関するドキュメンテーションや 直接のコミュニケーションが大切 用語: ML Canvas 課題 解決策
会社でMLモデルを作るとは? MLモデル単体を取り巻く様々なことを意識しながらモデルを作成する必要がある。 ユーザー 社内メンバー/開発者 システム DWH *DWH =
Data Ware House MLモデル ドキュメント モデルの出力 モニタリング 仕様変更 異常値 バグ 連携失敗 Doc不足 ドリフト バラバラ
会社でMLモデルを作るとは? MLモデル単体を取り巻く様々なことを意識しながらモデルを作成する必要がある。 • データカタログが完璧ではない中で、 • 過去のデータの不整合もカバーして、
• 日々流れてくる異常値にも頑健で、 • たまにデータ連携が失敗することもある中で、 • 未来のschema変更にも注意を払ってモデルをメンテナンスして、 • モデルの精度に気をかけながら、 • コストとベネフィットのバランスを考え、 • それらを正確に正しくコミュニケーションしながら、 MLモデルを作るということ いろいろ考えることは多いがそれが楽しい!
MLモデルを作成するだけでも ... 前述のような前後のこと、 • データがどのように集められてくるか • MLモデルの出力をどのように活用するか
にも思いをめぐらせることで、より良い分析・モデリングができ ると思います!
最近のはなし LLMアプリ作成してね 承知しました! LLMでアプリケーションを 作って欲しい。営業社員 の効率化のために使いた いんだ。
最近のはなし いろいろ取り組んでいるのでご興味あればご覧ください 社内のAI/ML活用のための取り 組みについて紹介します! @ナウキャストさん (九段下) @09/29(月)
LLMや統計を用いた社内の便 利アプリをいろいろ作ったり (*1) 営業の商談トークを LLMを用い て分析したり (*1) 新しいデータ活用基盤について 考えたり (*2) *1: https://speakerdeck.com/yuto16 *2: https://finatext.connpass.com/event/365995/
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}