For years, the Java community has been told that Project Loom would kill reactive programming — that blocking and async were destined to be enemies. But what if that story was wrong?
In this talk, we’ll explore what happens when these two worlds actually fall in love.
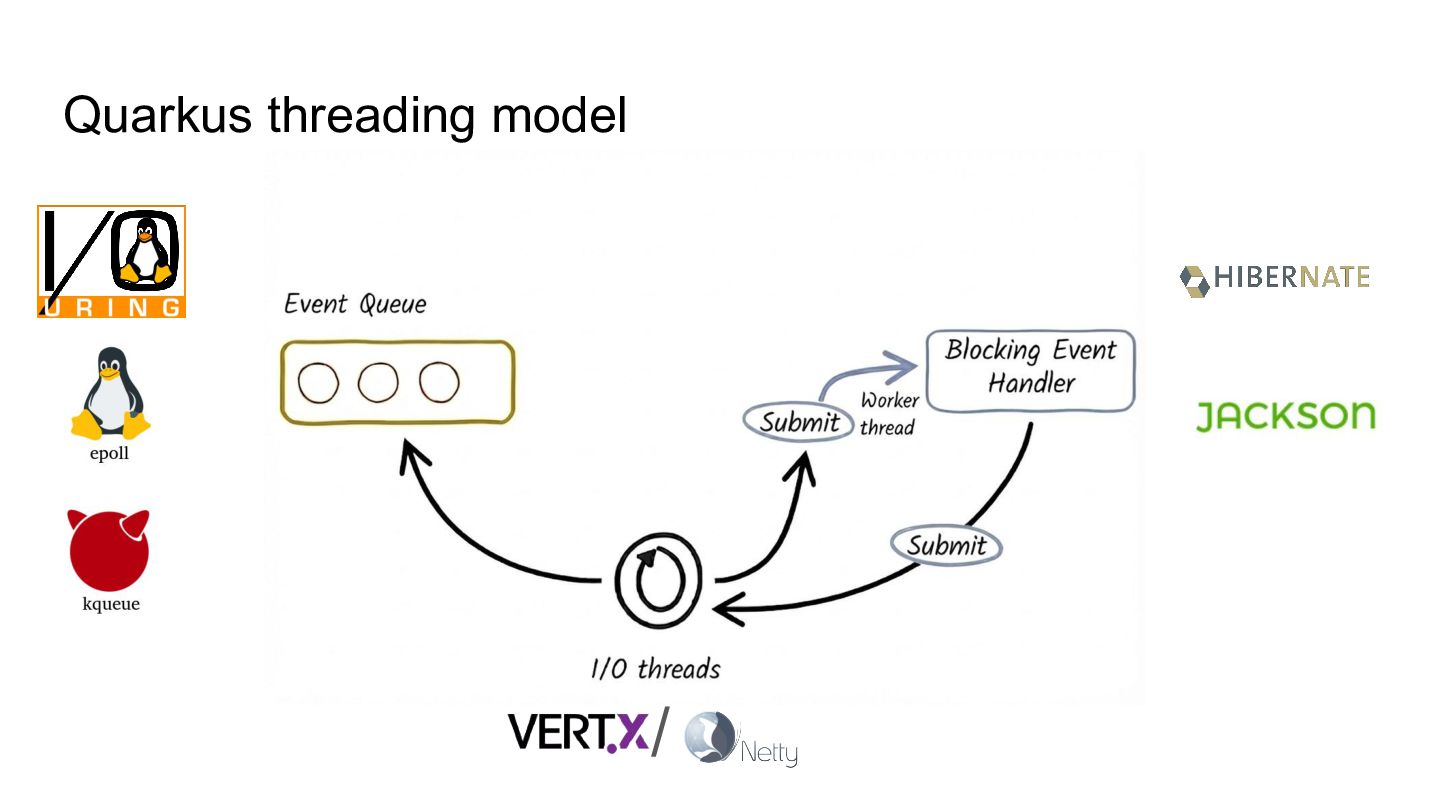
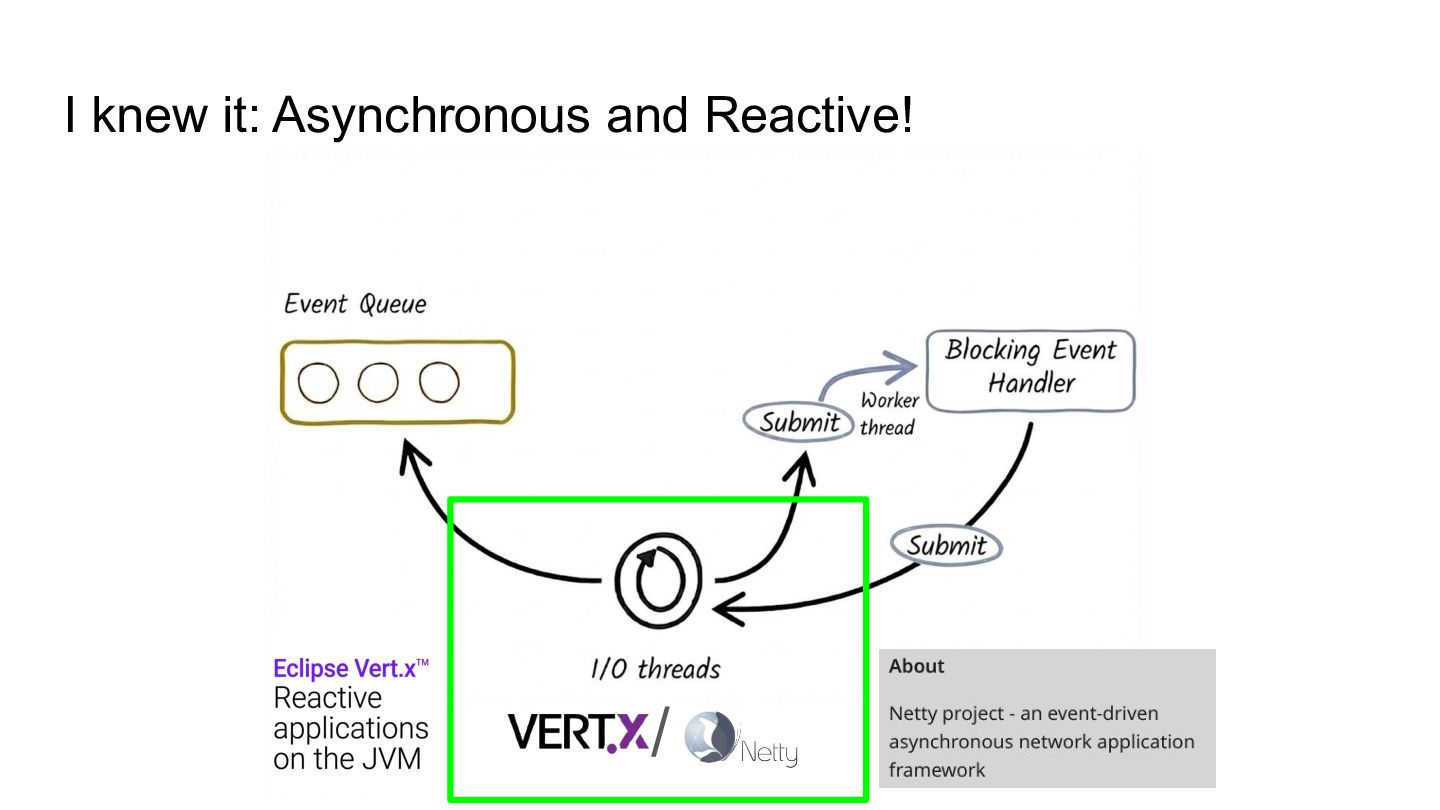
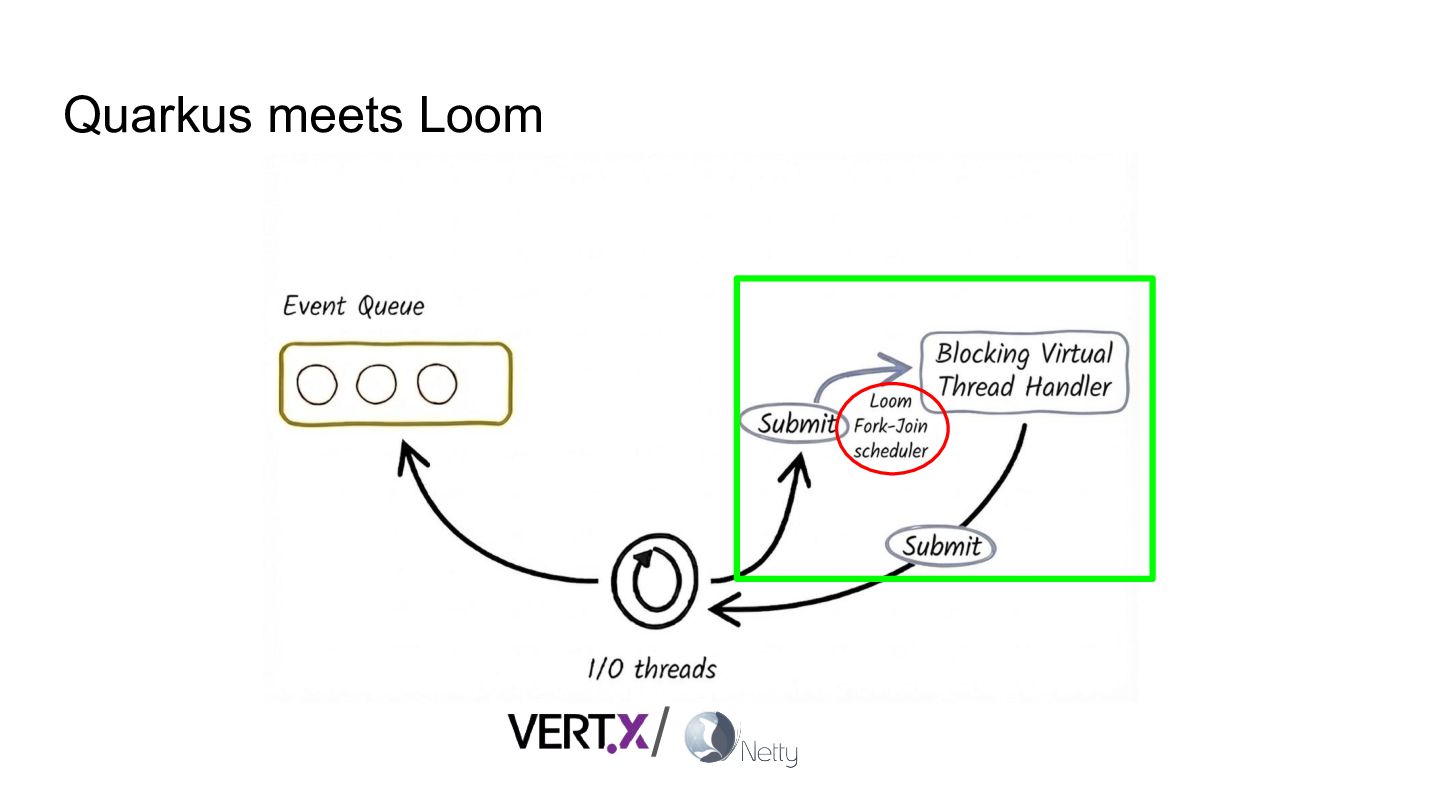
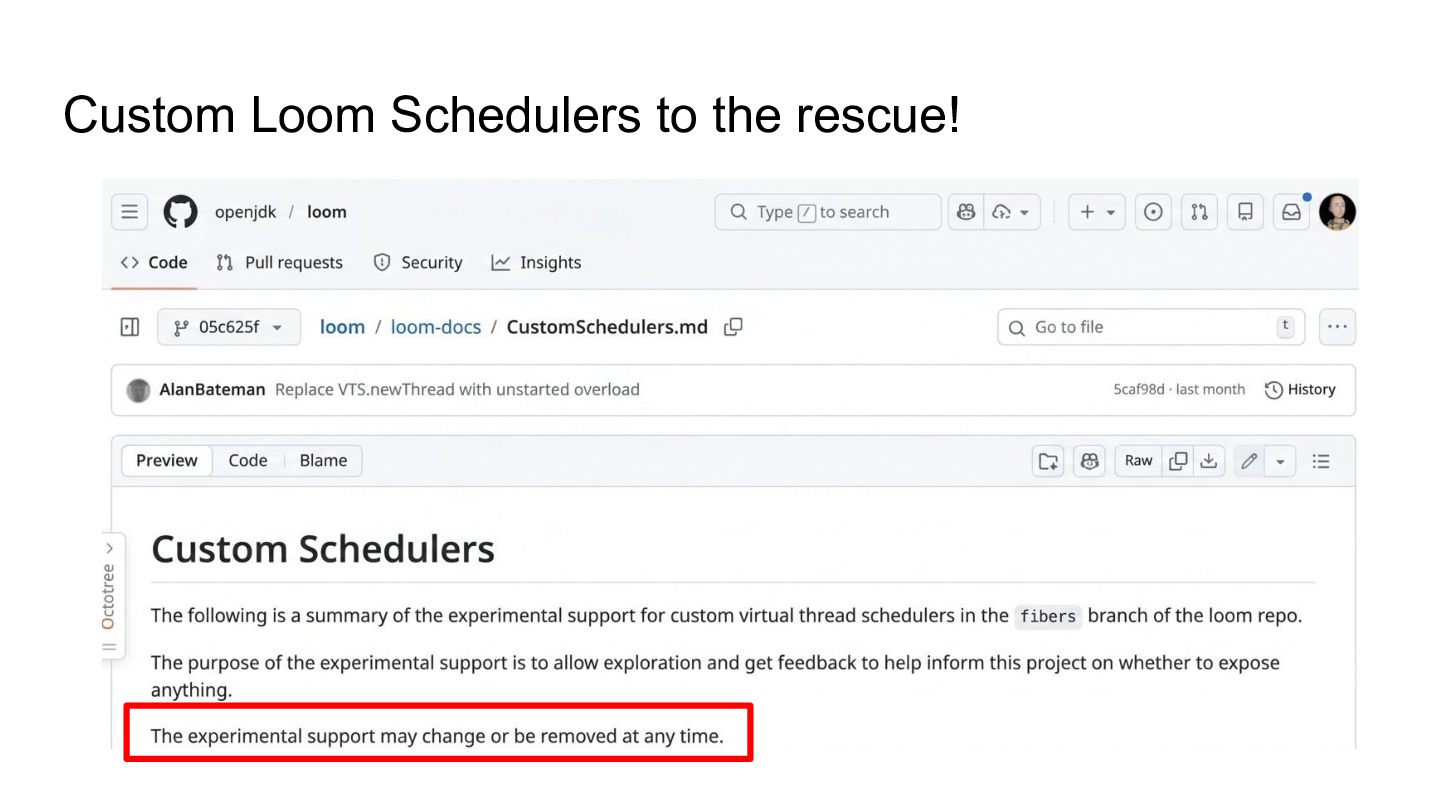
Drawing from real-world work inside the Quarkus, Vert.x, Netty, and HotSpot teams, we’ll see how a custom Loom scheduler built on top of Netty brings together the performance of event-driven I/O and the simplicity of virtual-thread-friendly blocking APIs.
This isn’t a theoretical “what if”: it’s a data-driven exploration born from experiments and collaborations between IBM, Oracle Labs, Oracle and Apple engineering teams.
You’ll see how this approach reshapes how we think about async, concurrency, and scheduling — and why some of the long-held assumptions about “reactive vs blocking” simply don’t hold up when measured scientifically.
Along the way, we’ll dissect:
- How the Loom scheduler and virtual threads work under the hood.
- What happens when you run them over a Netty core
- Performance implications and trade-offs measured empirically
This talk is a technical love story, but also a call to reason: Measure, Don’t Guess.
Because sometimes, the forbidden relationships are the ones that can move the platform forward.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}