Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20240119_KEDAでスパイク負荷を迎え撃つ。メトリクスとスケジュールドリブンなオートス...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
gonkun
January 19, 2024
1
410
20240119_KEDAでスパイク負荷を迎え撃つ。メトリクスとスケジュールドリブンなオートスケールでKubernetes上のプロダクトの信頼性を高めよう/lets_use_keda_for_reliability
gonkun
January 19, 2024
Tweet
Share
More Decks by gonkun
See All by gonkun
20250424_Reliable Communication Through Diagrams
gonkun
0
22
20250709_What is SRE, and Why Are We Here Together?
gonkun
0
40
20230929_SRE_NEXT_エラーバジェット運用までの取り組み-信頼性の低下に対するアクションを定義しよう / Let's define actions against unreliability
gonkun
2
3.6k
はじめの一歩を踏み出したい方へ~SREというロールを担うためにやったこと、学びや反省 / Let's start the first step to the SRE
gonkun
2
630
Featured
See All Featured
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
220
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Designing for Timeless Needs
cassininazir
0
160
Leading Effective Engineering Teams in the AI Era
addyosmani
9
1.7k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
67
37k
Designing for humans not robots
tammielis
254
26k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
150
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.1k
The Spectacular Lies of Maps
axbom
PRO
1
620
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.6k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
150
Transcript
KEDAでスパイク負荷を迎え撃つ メトリクスとスケジュールドリブンなオートスケールでKubernetes上のプロダクトの信頼性を高めよう 株式会社マネーフォワード MFBC-CTO室 SRE部 HRソリューショングループ 佐々木 優太 成長を続けるfreeeとマネーフォワードはサービスの信頼性をどう担保しているのか? #sre_fxm
#sre_fxm 自己紹介 佐々木 優太(ゴンくん) 株式会社マネーフォワード MFBC-CTO室 > SRE部 > HRソリューショングループ
@gogogonkun https://gonkunblog.com/
#sre_fxm メトリクスかつスケジュールドリブンなオートスケールで スケーラビリティを確保しつつKubernetes上の リソースコストを35%削減した話 本発表の概要
#sre_fxm こんな経験はありませんか? サービスの信頼性確保 大変じゃないですか?
#sre_fxm こんな経験はありませんか? 品質をお金で解決することも
#sre_fxm こんな経験はありませんか? プロダクトや組織が成長すると 品質とコストの両輪がより重要に
#sre_fxm コスト削減までの思考の過程を 経験談を踏まえてお伝えいたします
本発表の対象者 プロダクトの成長に応じて発生する 負荷の増加への対応に困っている人 これからサービスリソースのチューニングを 試みようとしている方
プロダクトの負荷特性を考慮しつつ、 リソースのチューニングができるように - 具体的に何をすべきかが分かる - 気を付けるポイントが分かる ※ KEDAの導入方法には触れません 持ち帰れること
#sre_fxm 今回は勤怠管理システムを例に一緒に考えてみましょう
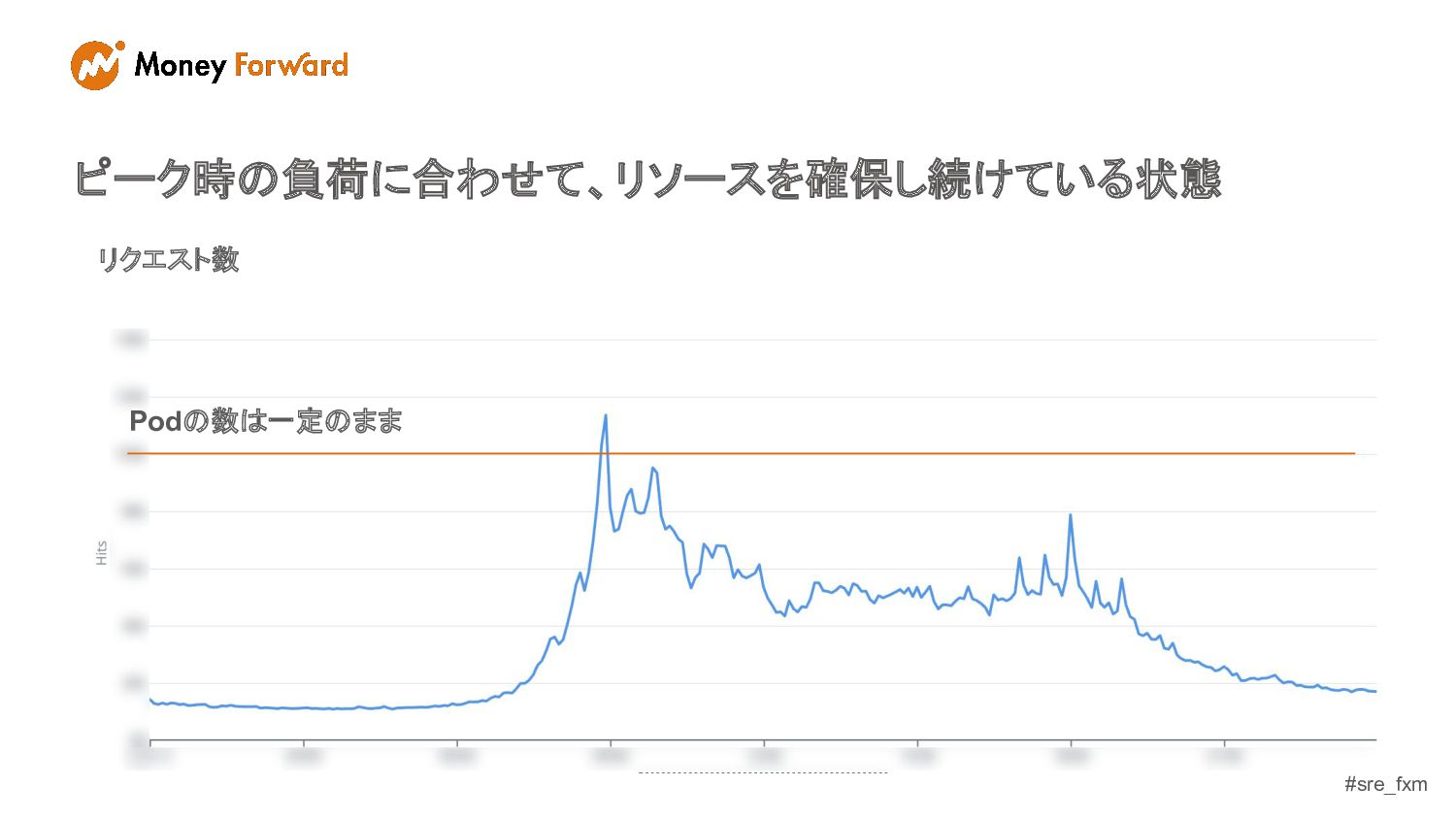
#sre_fxm 置かれている状況 - 想像以上のユーザ数の増加 1年前と比較してn倍になっている。という状況 - ヤバそうだったらインフラ側のリソース増強 - 気付けばk8sのリソース使用率が社内でもトップクラスに
#sre_fxm リクエスト数 ピーク時の負荷に合わせて、リソースを確保し続けている状態 Podの数は一定のまま
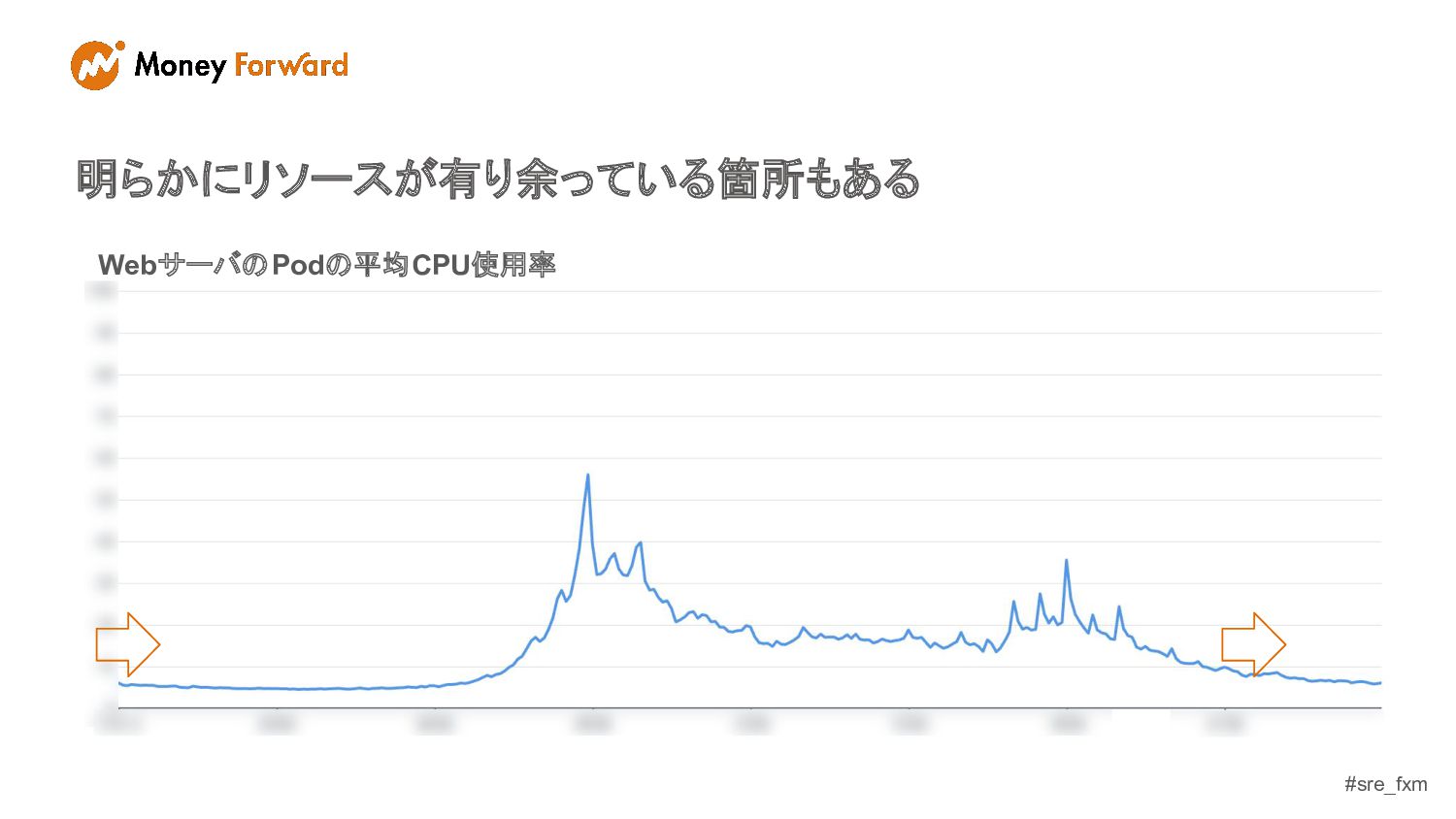
#sre_fxm 明らかにリソースが有り余っている箇所もある WebサーバのPodの平均CPU使用率
#sre_fxm 理想を言うならば... - リソースを使わない時間帯Podを減らす - でも1日の負荷には耐えられること
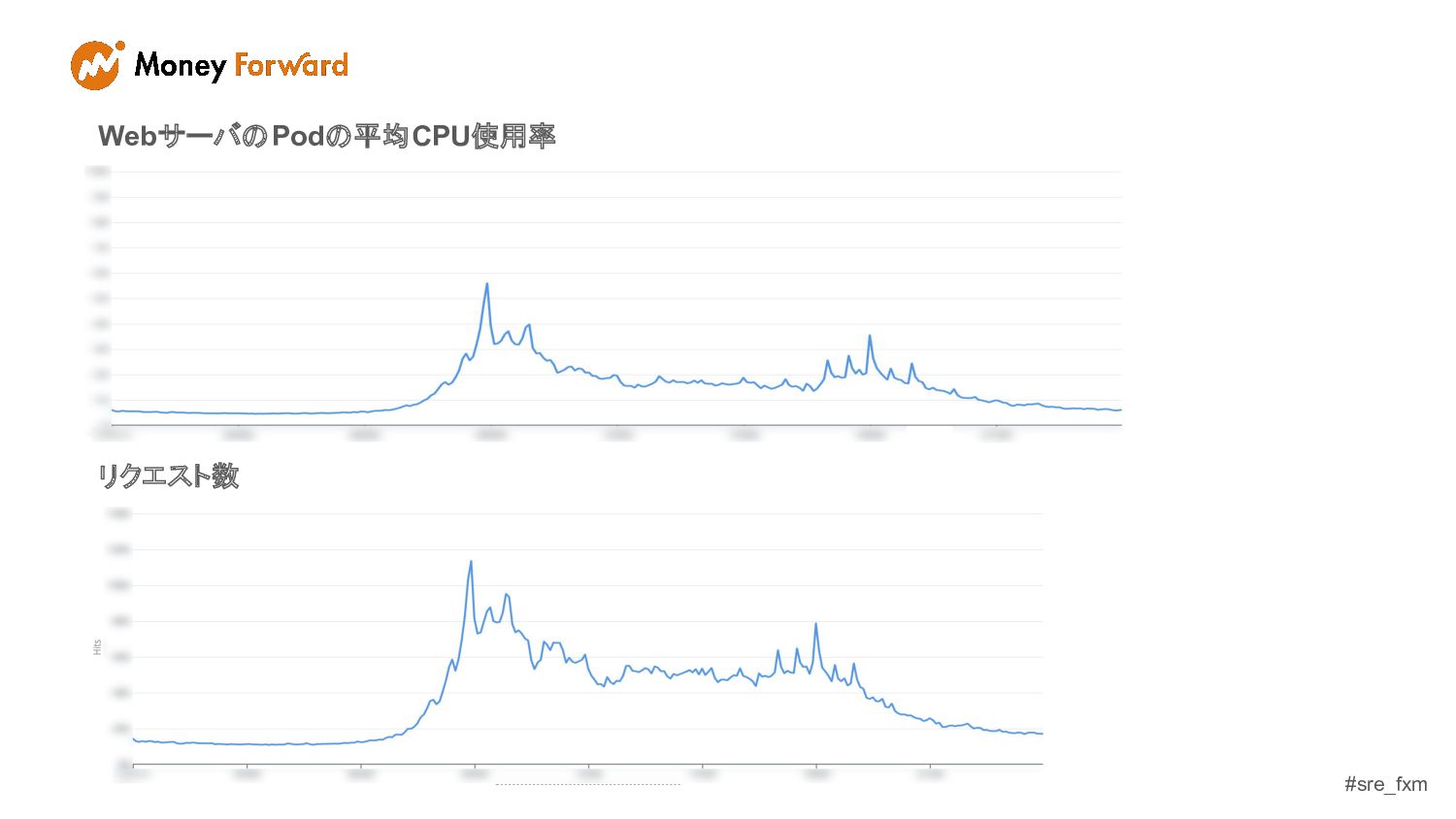
#sre_fxm まずは1日のCPU使用率やリクエスト数の推移を見てみる
#sre_fxm WebサーバのPodの平均CPU使用率 リクエスト数
#sre_fxm リクエスト数 Q. HPA(Horizontal Pod Autoscaler)に任せれば...? こういうイメージ リクエスト数 Pod数(理想)
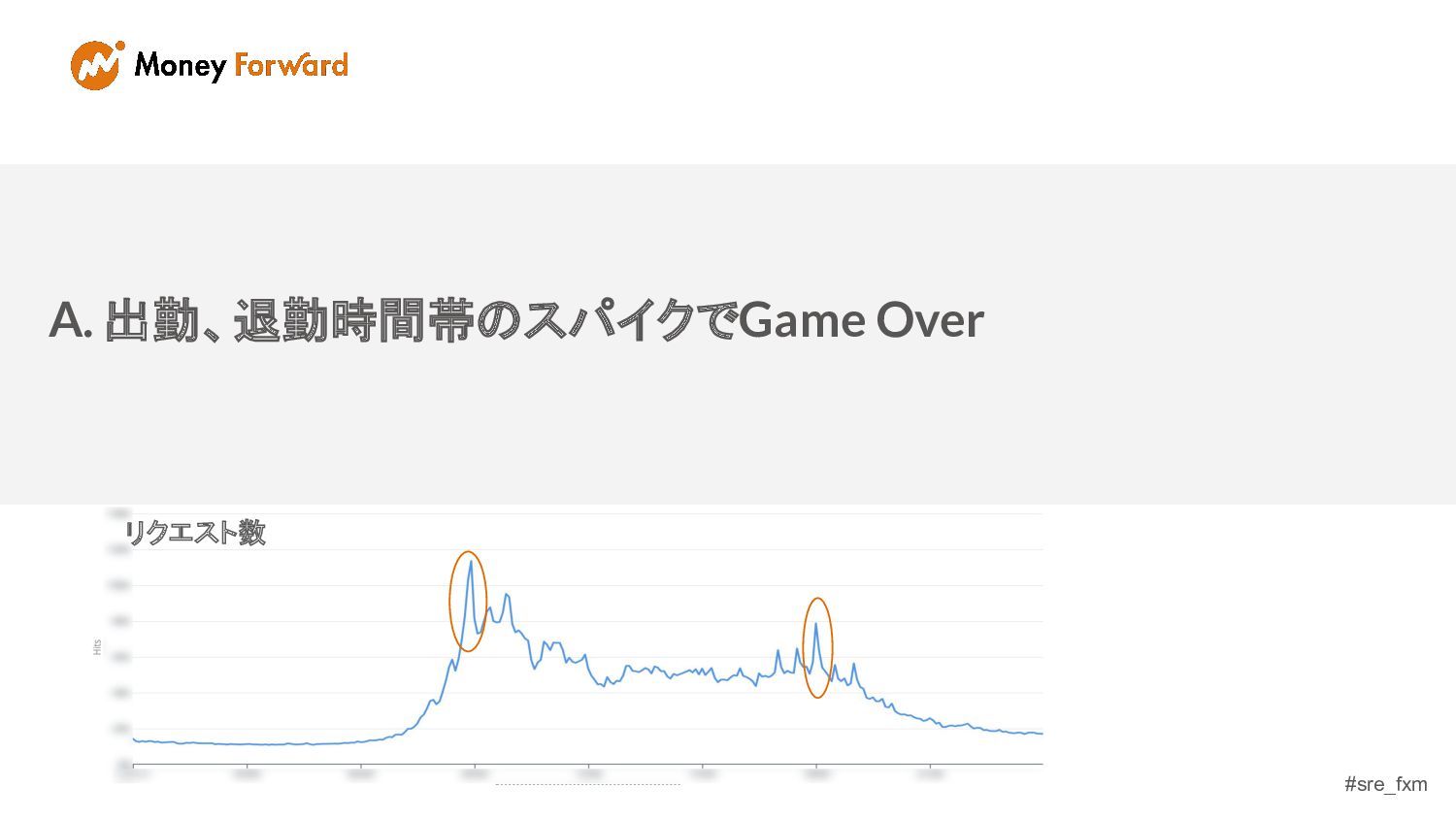
#sre_fxm リクエスト数 A. 出勤、退勤時間帯のスパイクでGame Over リクエスト数
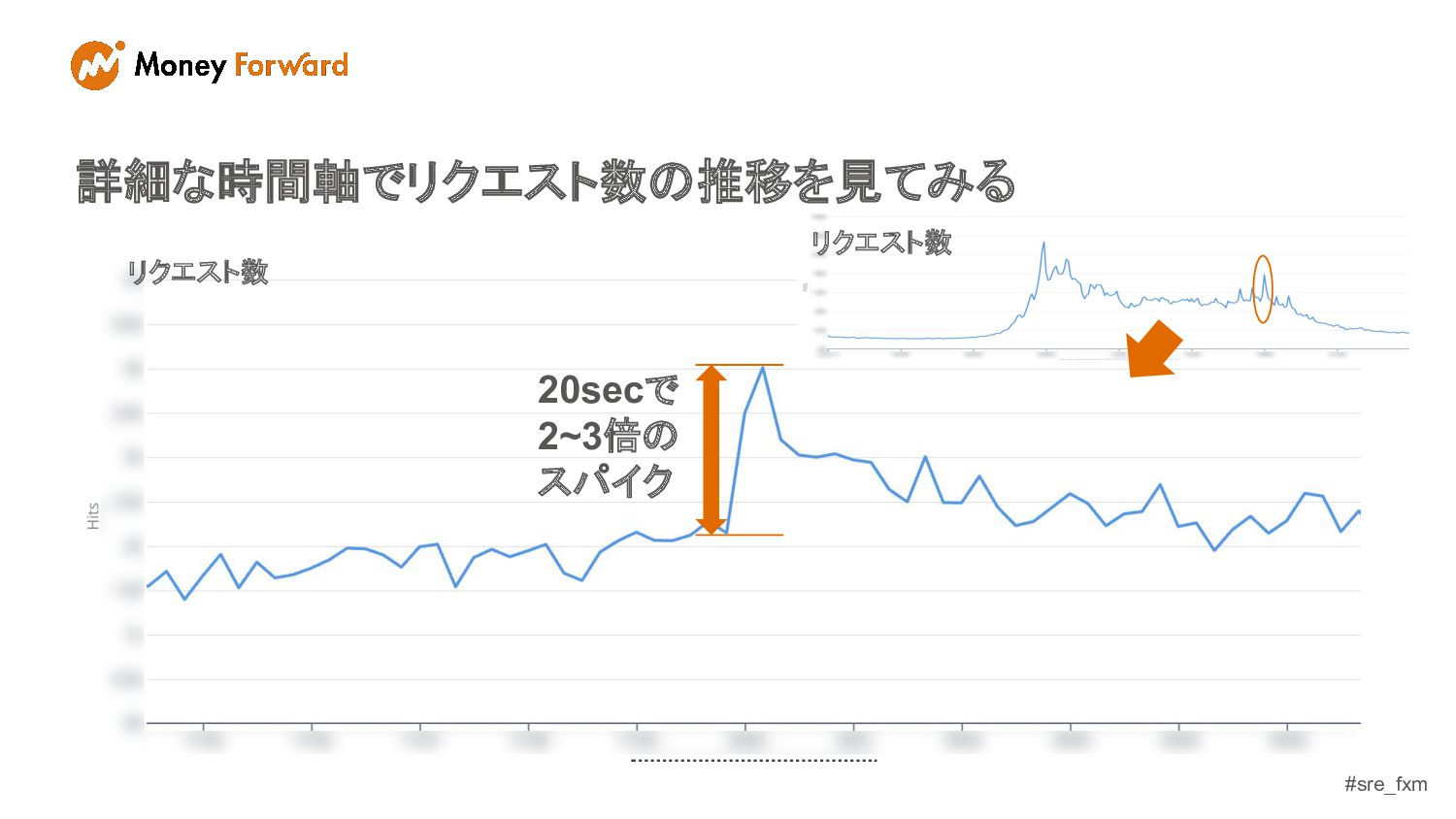
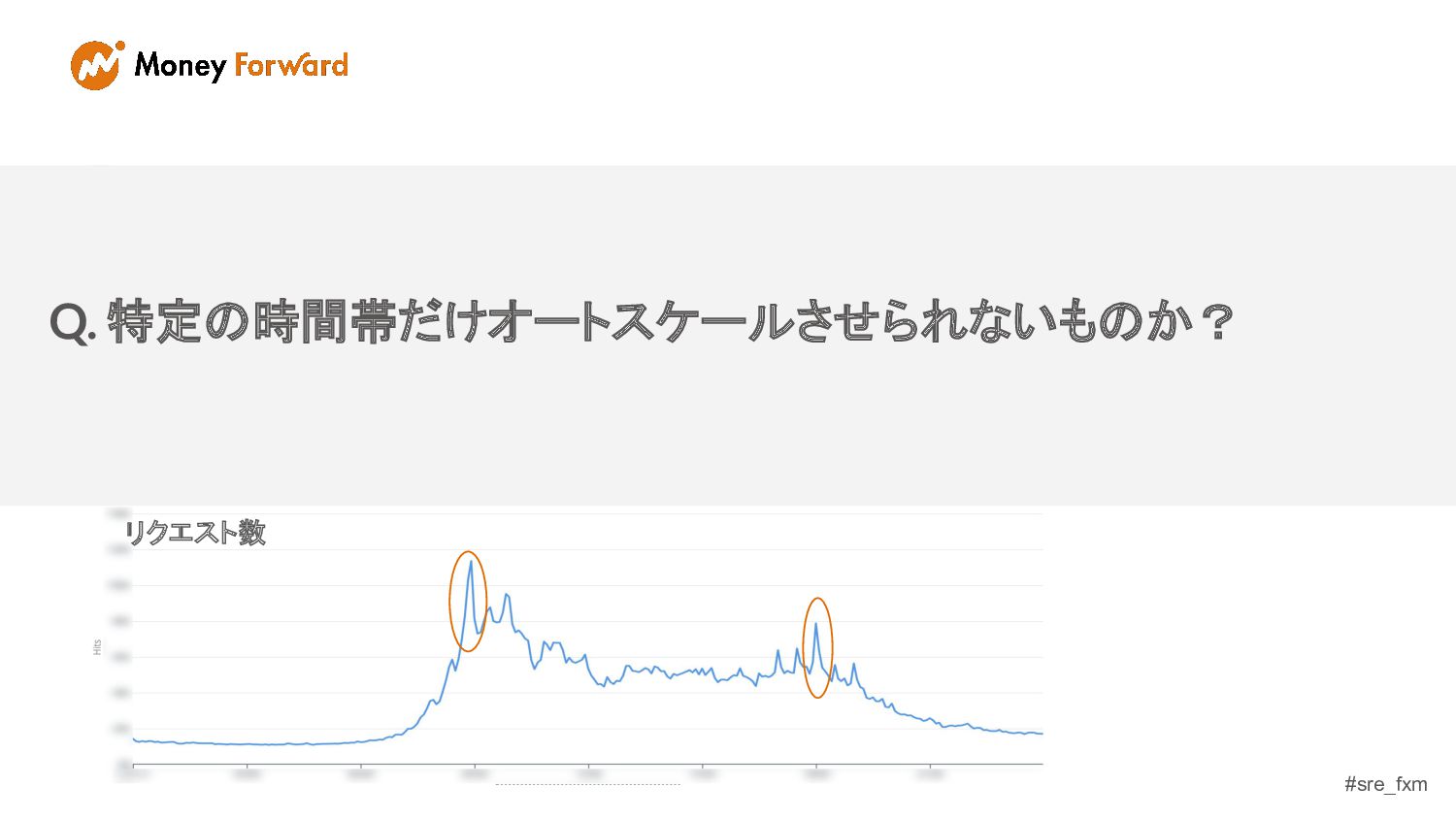
#sre_fxm 詳細な時間軸でリクエスト数の推移を見てみる 20secで 2~3倍の スパイク リクエスト数 リクエスト数
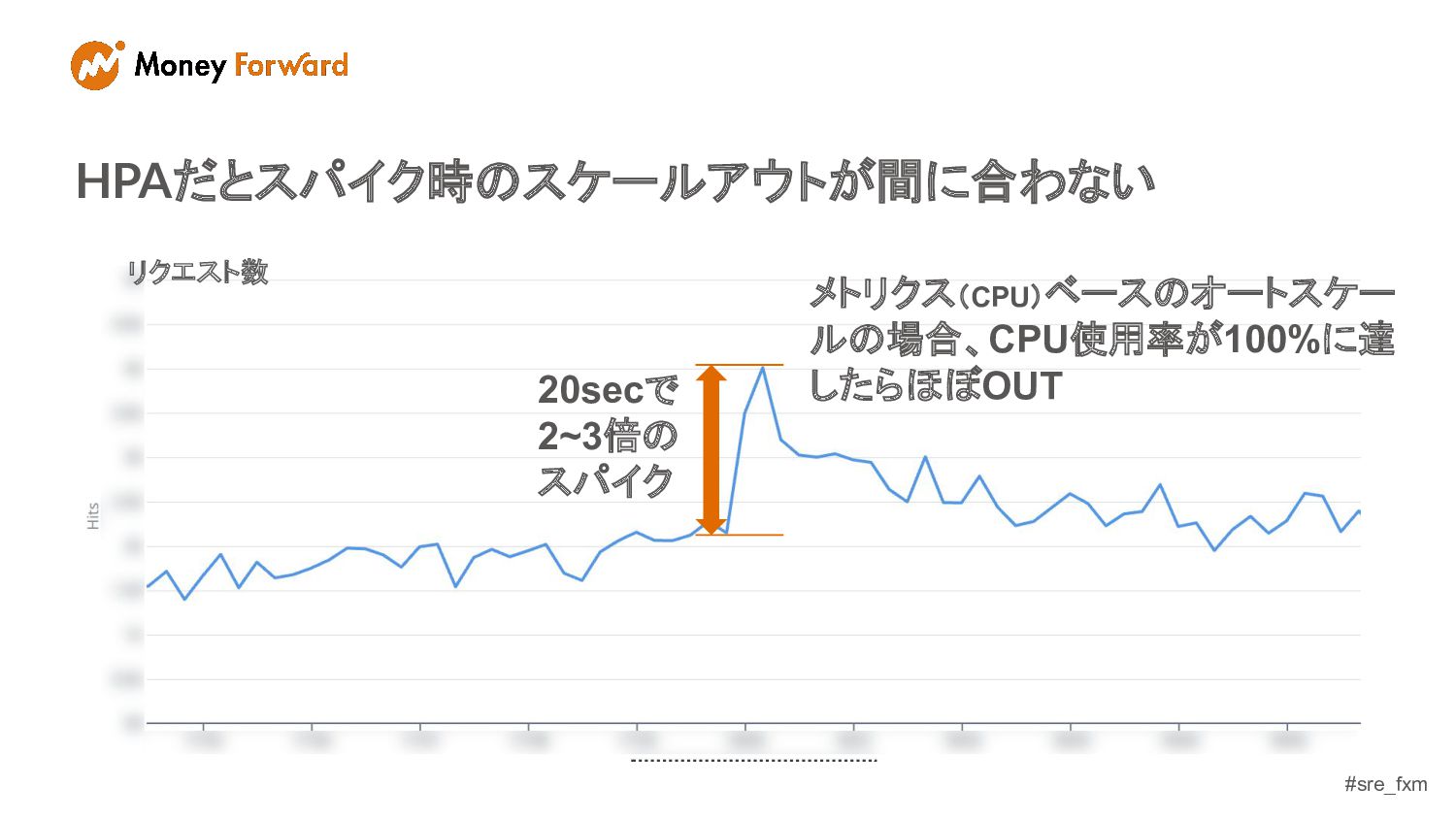
#sre_fxm 20secで 2~3倍の スパイク メトリクス(CPU)ベースのオートスケー ルの場合、CPU使用率が100%に達 したらほぼOUT HPAだとスパイク時のスケールアウトが間に合わない リクエスト数
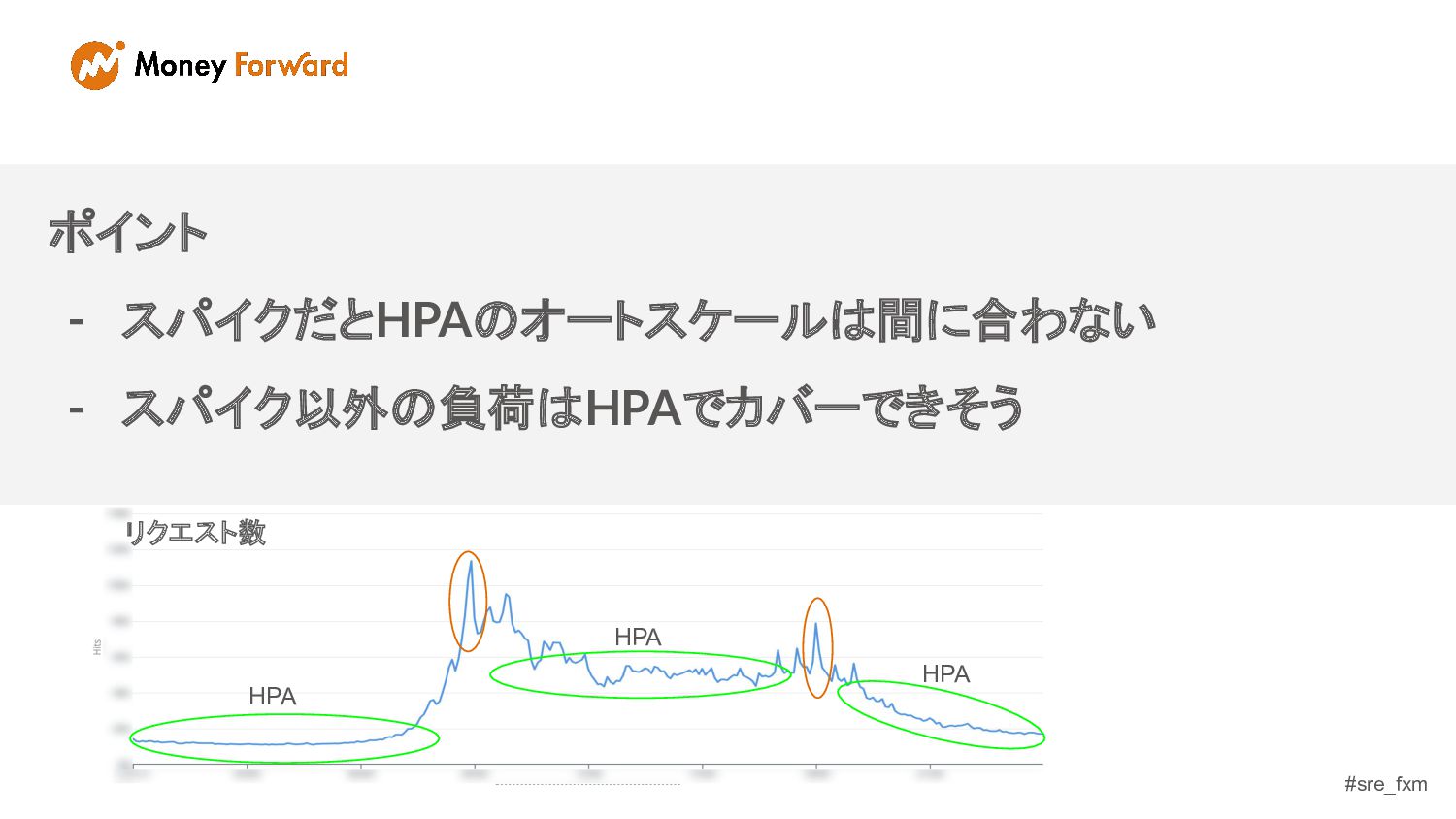
#sre_fxm リクエスト数 ポイント - スパイクだとHPAのオートスケールは間に合わない - スパイク以外の負荷はHPAでカバーできそう リクエスト数 HPA HPA
HPA
#sre_fxm KEDAの導入を考える
#sre_fxm リクエスト数 Q. 特定の時間帯だけオートスケールさせられないものか? リクエスト数
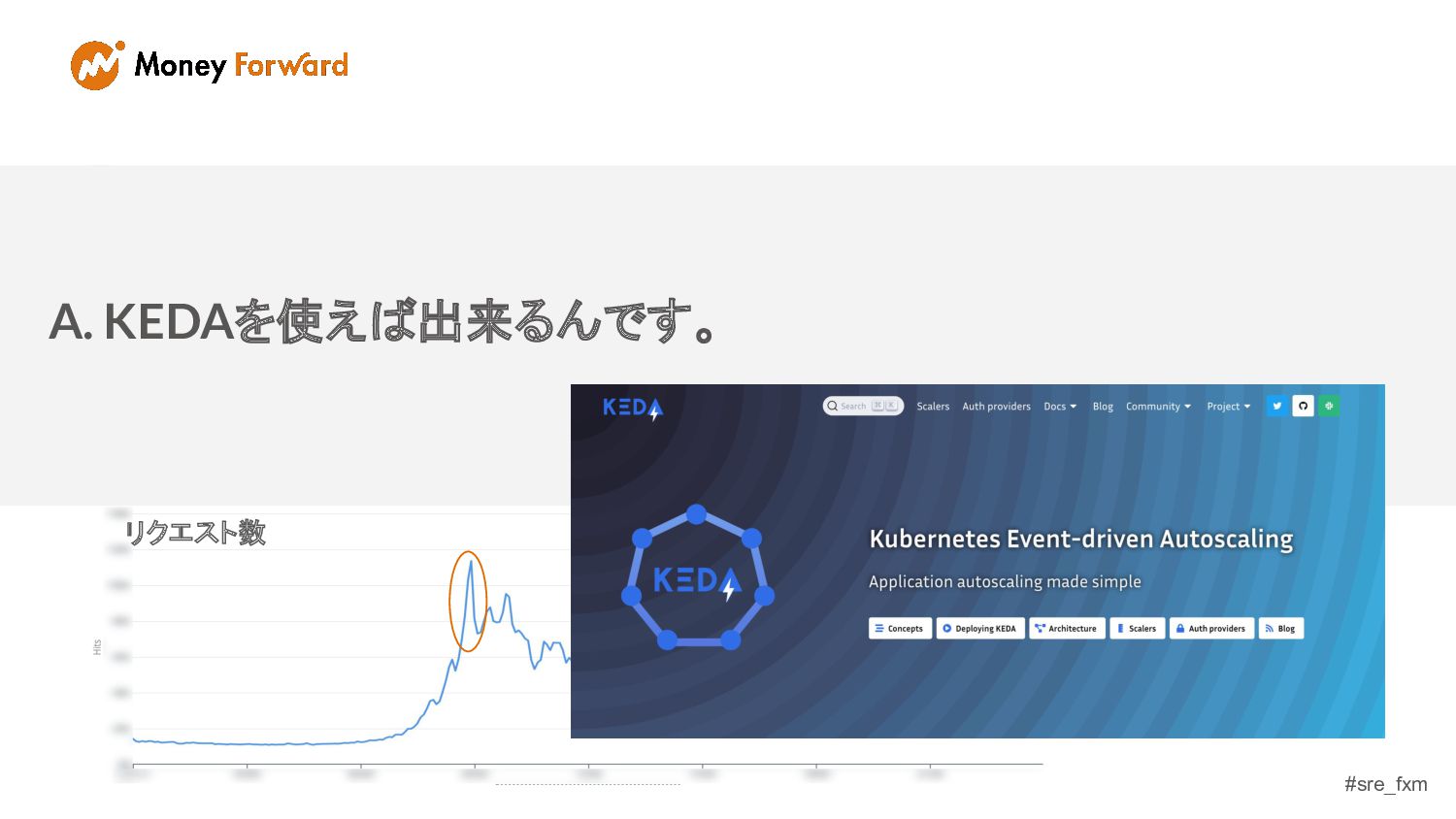
#sre_fxm リクエスト数 A. KEDAを使えば出来るんです。 リクエスト数
#sre_fxm KEDAとは? - イベントドリブンでの オートスケールを可能とする - 多様なイベントに対応 - 今回はCron(スケジュール) イベントをトリガーにスケールア
ウトさせる
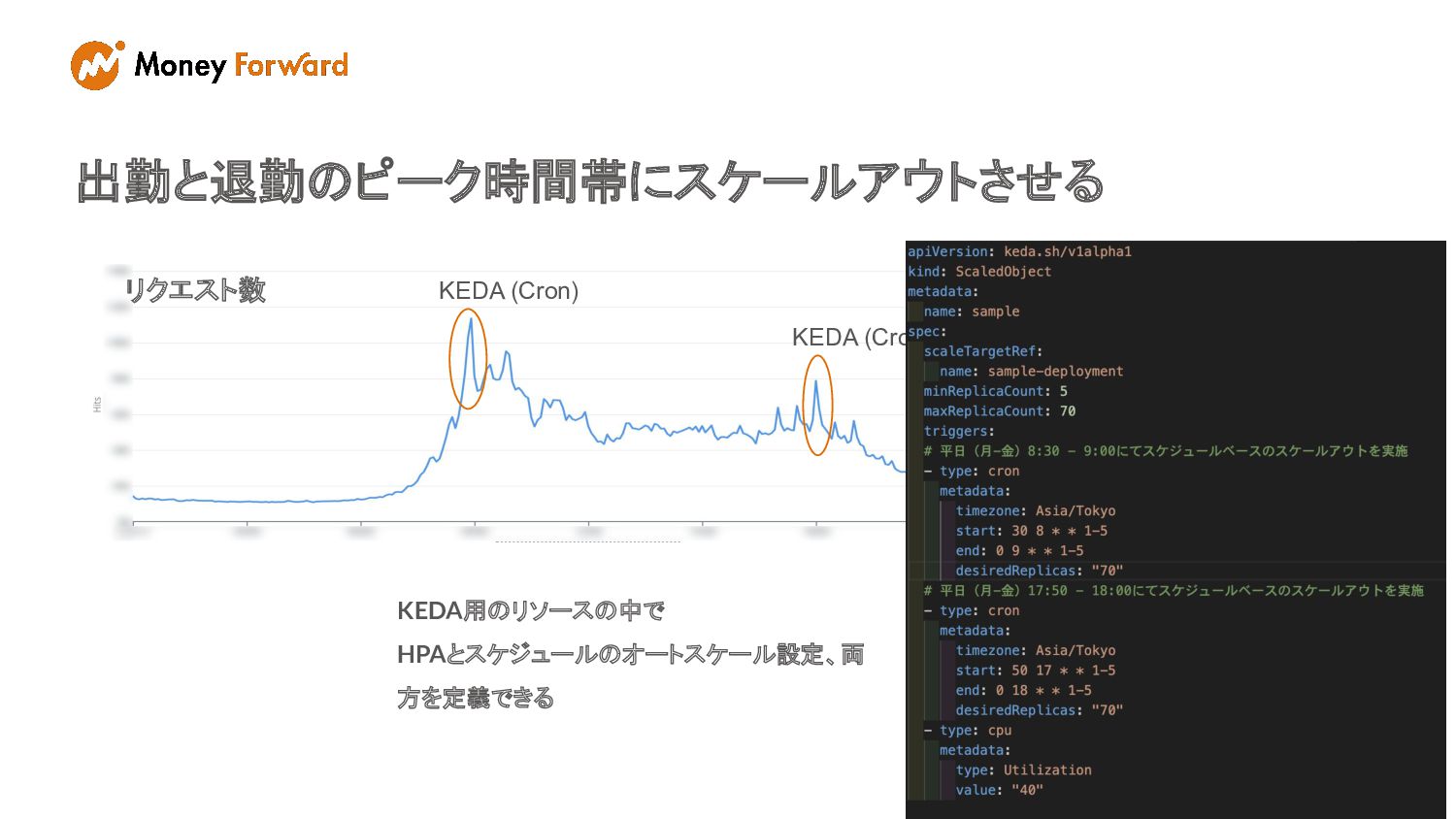
#sre_fxm リクエスト数 KEDA (Cron) KEDA (Cron) 出勤と退勤のピーク時間帯にスケールアウトさせる KEDA用のリソースの中で HPAとスケジュールのオートスケール設定、両 方を定義できる
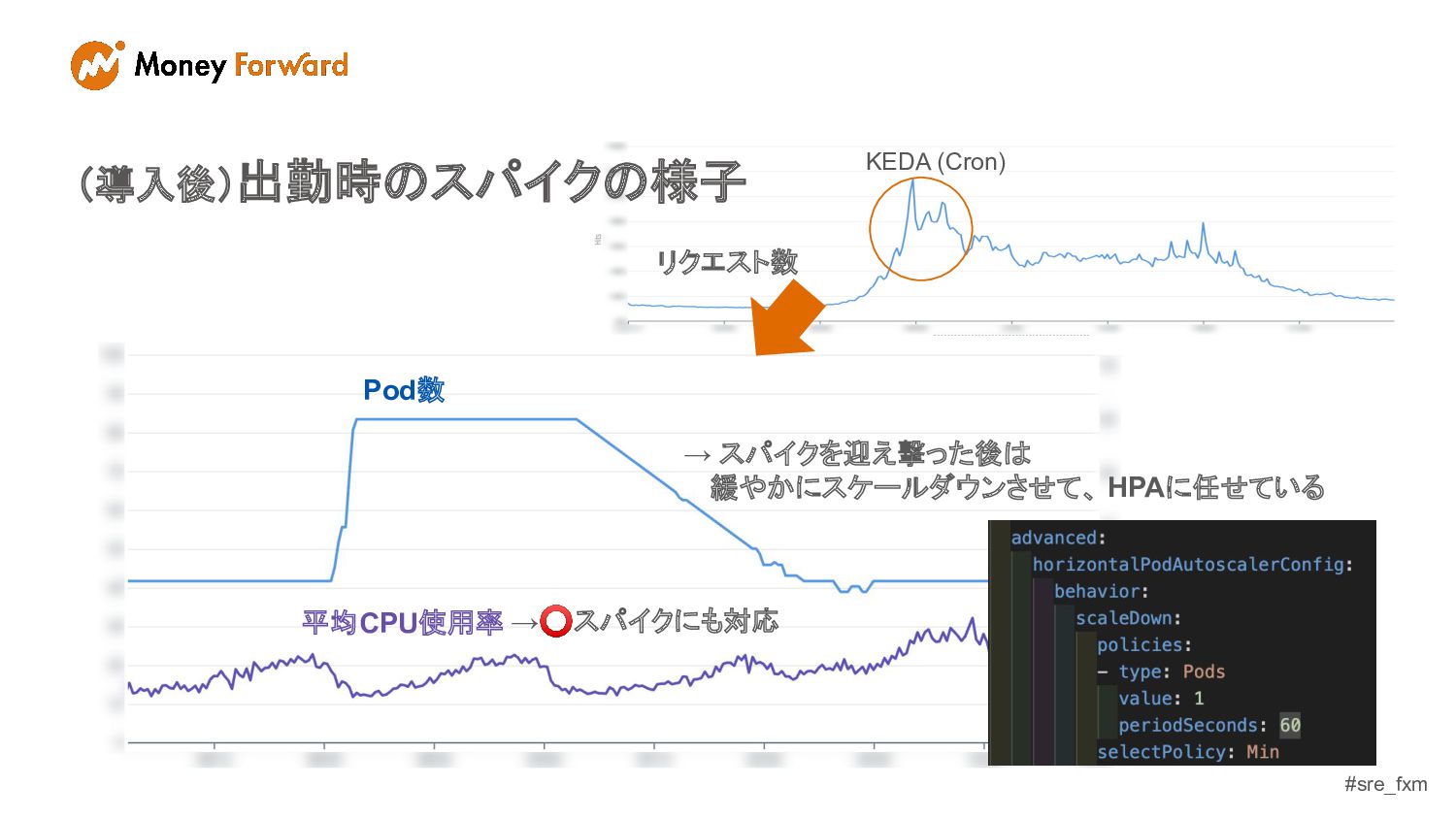
#sre_fxm KEDA (Cron) (導入後)出勤時のスパイクの様子 → スパイクを迎え撃った後は 緩やかにスケールダウンさせて、 HPAに任せている →⭕スパイクにも対応
リクエスト数 Pod数 平均CPU使用率
#sre_fxm KEDAとHPAのチューニングの失敗
#sre_fxm 残るは最低Pod数のラインを下げてコストを減らすだけ...
#sre_fxm その時事件は起こるのでした...
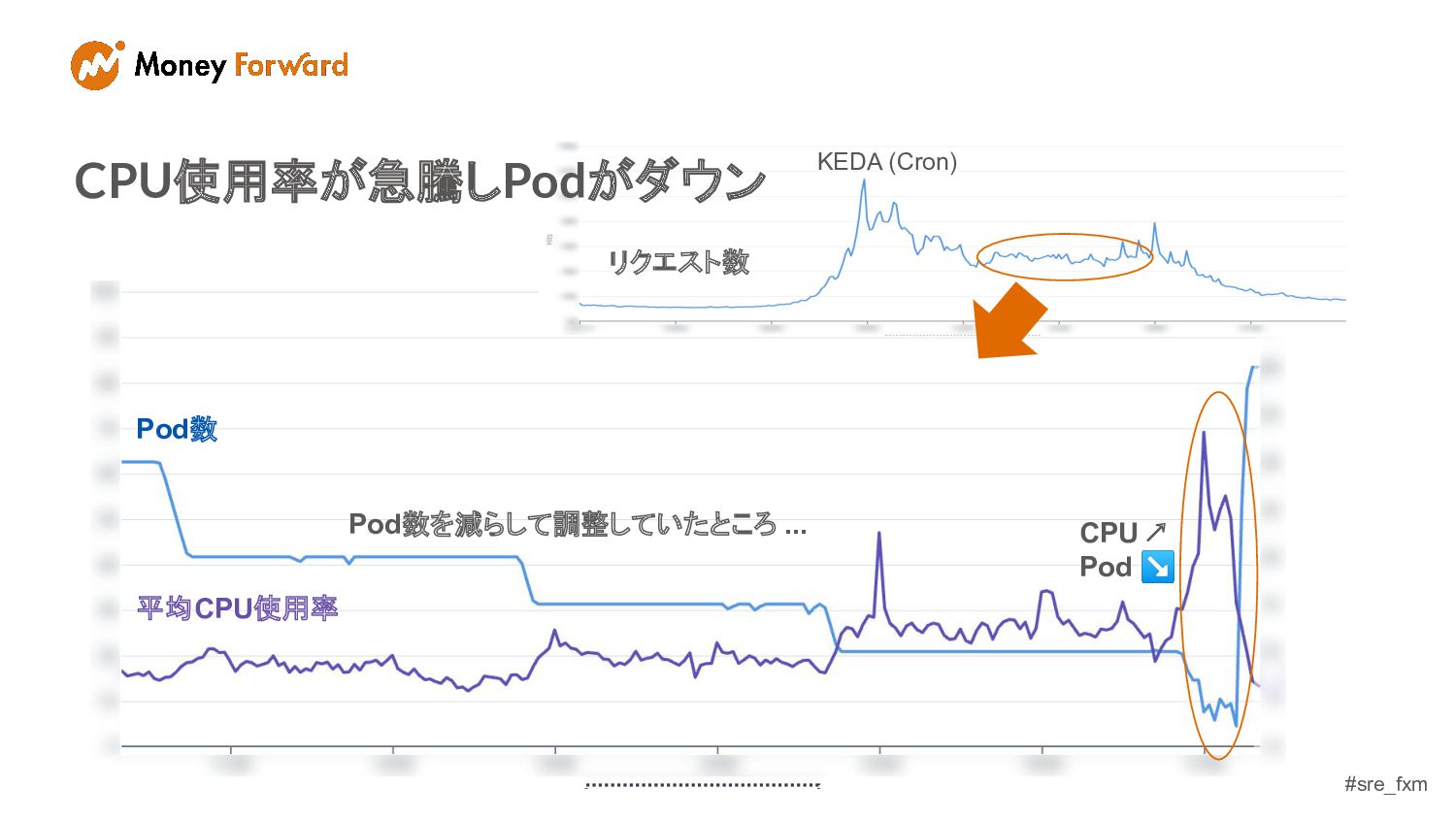
#sre_fxm KEDA (Cron) CPU使用率が急騰しPodがダウン リクエスト数 Pod数を減らして調整していたところ ... CPU ↗ Pod
↘ Pod数 平均CPU使用率
#sre_fxm まだ退勤ピークではないはず... なぜ起きた???
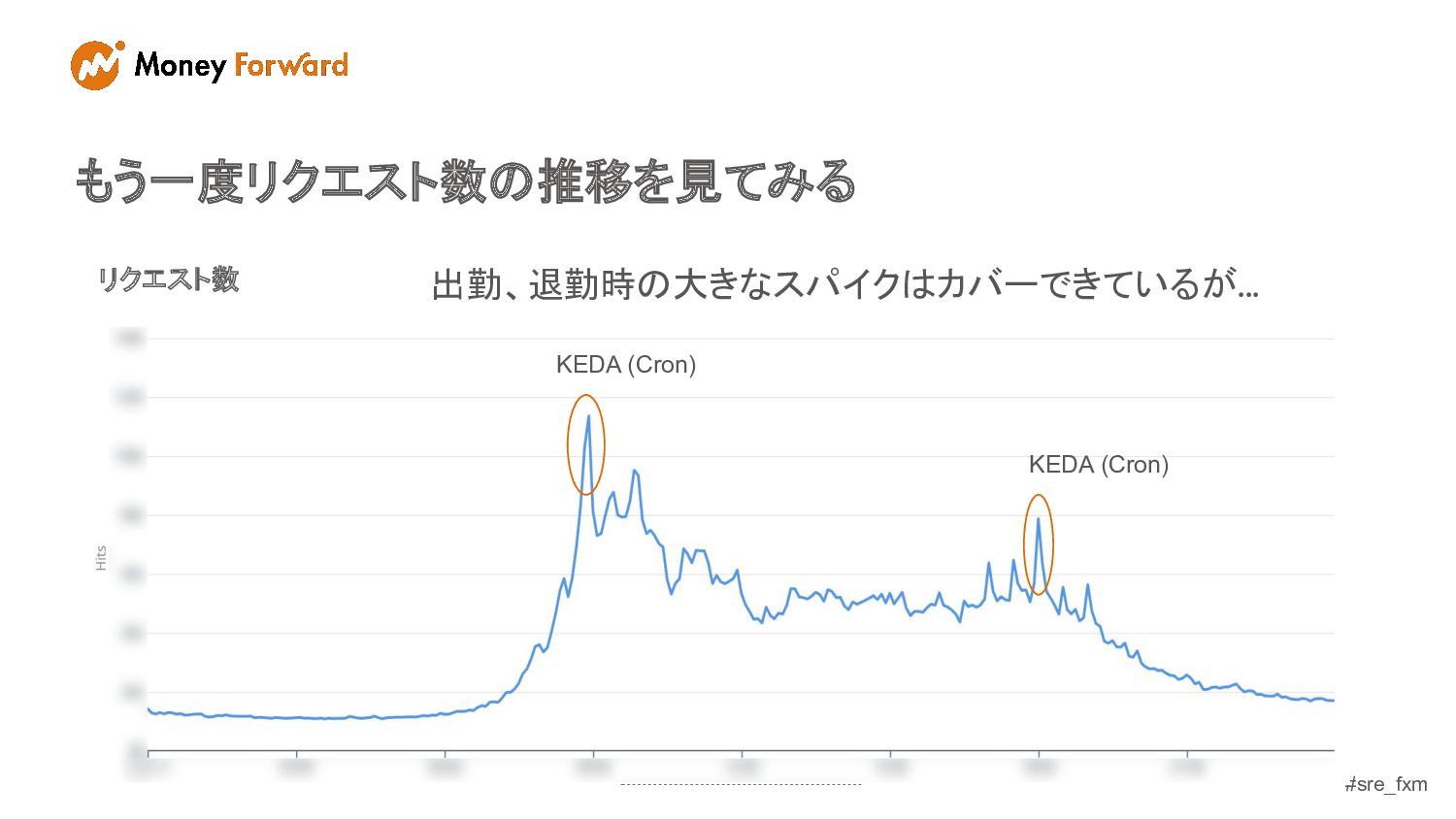
#sre_fxm もう一度リクエスト数の推移を見てみる リクエスト数 KEDA (Cron) KEDA (Cron) 出勤、退勤時の大きなスパイクはカバーできているが...
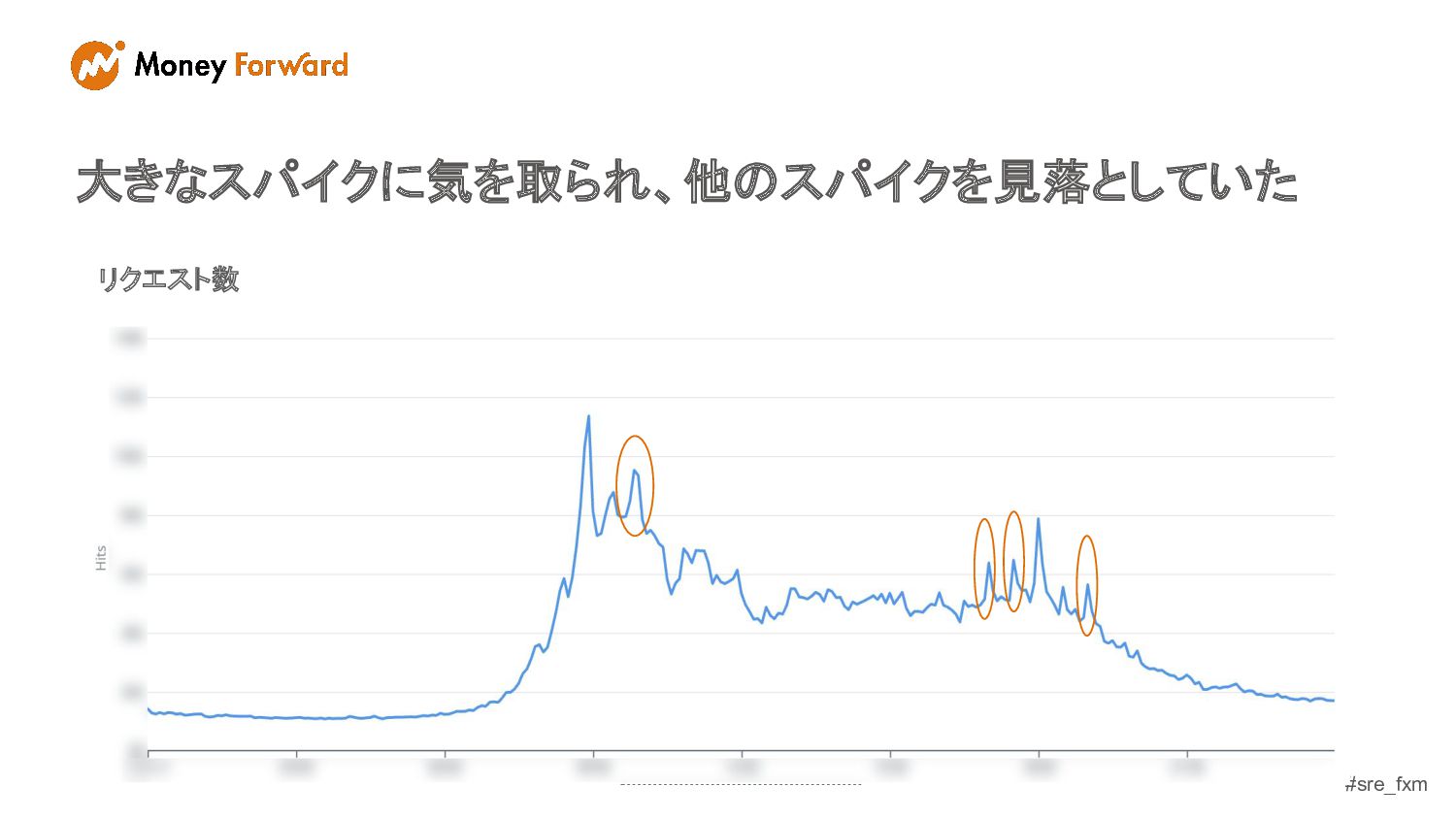
#sre_fxm 大きなスパイクに気を取られ、他のスパイクを見落としていた リクエスト数
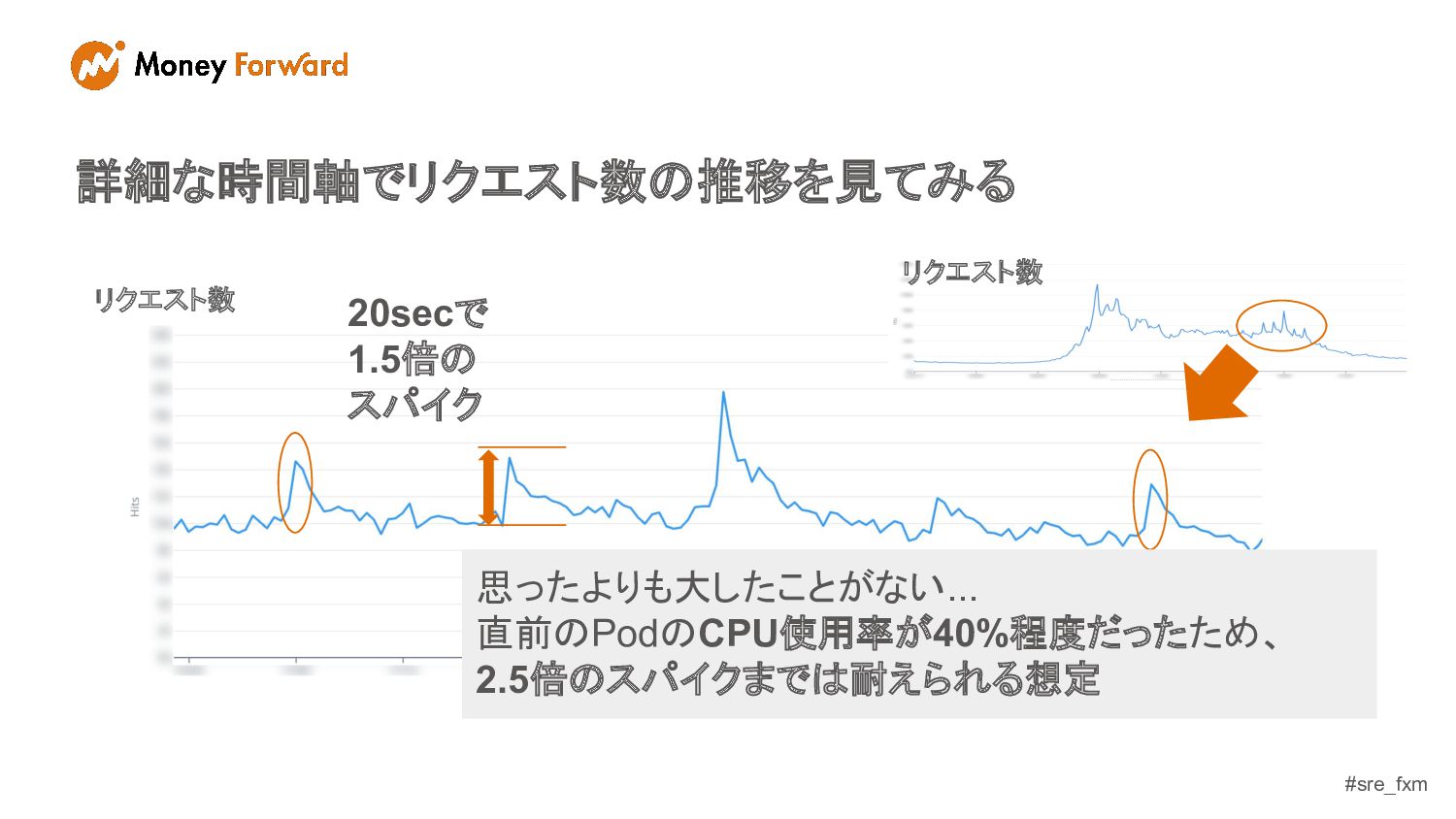
#sre_fxm 詳細な時間軸でリクエスト数の推移を見てみる リクエスト数 20secで 1.5倍の スパイク リクエスト数 思ったよりも大したことがない... 直前のPodのCPU使用率が40%程度だったため、 2.5倍のスパイクまでは耐えられる想定
#sre_fxm なんだか腑に落ちない... もう少しアプリケーションの特性に踏み込んでみる
#sre_fxm 退勤時に叩かれる かつ 重めのAPIに絞って抽出してみる 20secで 3倍の スパイク リクエスト数(退勤時に叩かれる重めの API) これならPod側も耐えられそうにない...
ようやく納得
#sre_fxm 20secで 3倍の スパイク リクエスト数(退勤時に叩かれる重めの API) 学び - スパイクは大きな山だけ見るのではなく、変化率を注視 -
マクロとミクロの両方の観点で負荷を分析すること 反省点 - もっと慎重に、1日に少しずつチューニングしていく (負荷特性を分析しきれていないなら尚更慎重に)
#sre_fxm 改善: スパイクはスケジュールで丸ごと迎え撃つ リクエスト数(退勤時に叩かれる重めの API) KEDA (Cron) リクエスト数
#sre_fxm リクエスト数 メトリクスベース(HPA)とスケジュールベース(Cron)を 組み合わせて負荷の増減とスパイクに対処することに成功 リクエスト数 HPA HPA HPA KEDA (Cron)
KEDA (Cron)
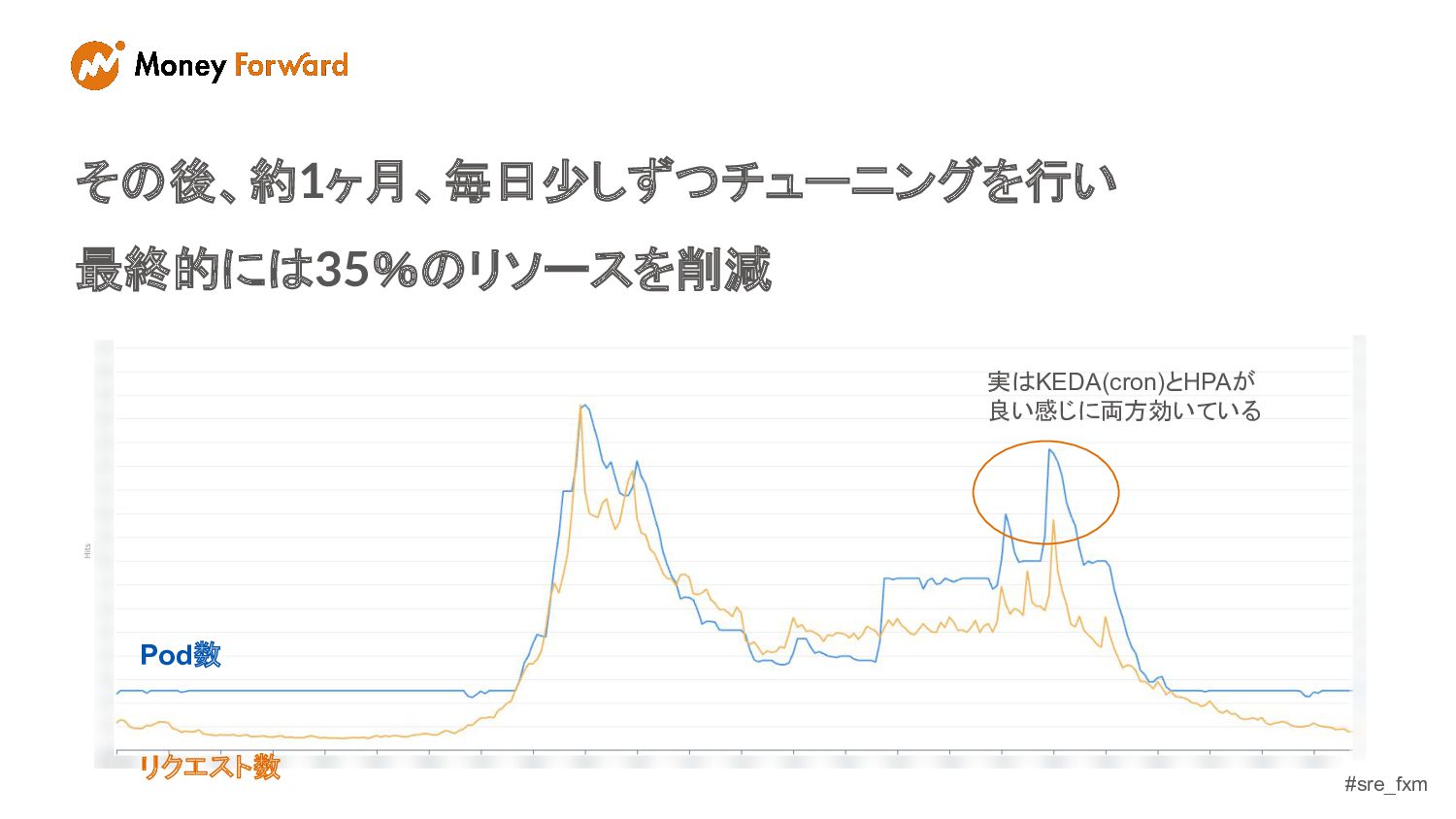
#sre_fxm Pod数 リクエスト数 その後、約1ヶ月、毎日少しずつチューニングを行い 最終的には35%のリソースを削減 実はKEDA(cron)とHPAが 良い感じに両方効いている
#sre_fxm Pod数 平均CPU使用率 平均CPU使用率も無理の無い範囲に収まっている (まだまだ見直せそう...)
#sre_fxm まとめ - メトリクスベースのオートスケール時にはスパイクに注意! - スパイクにはスケジュールベースのオートスケールが有効!! KEDAを活用すべし! - アプリケーションの特性の理解しつつ、慎重にチューニング
#sre_fxm まとめ その他補足 - HPAの感度を調整することで、更に柔軟に負荷に対応できる 参考: k8s - HPAを設定してチューニングする上で気をつけていること -
KEDAのマニフェスト(scaledObject)適用時には、deploymentのreplicaが1(デ フォルト値)を経由しないように注意 - 障害に発展する可能性がある - 詳しくは以下の記事が大変参考になりました Kubernetesの既存DeploymentにHPAを導入する際の注意点
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}