Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CADEDA #6 AWAにおけるデータ利活用の取り組みと今後の展望について
Search
Hiroki Mizukami
October 05, 2018
2.5k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CADEDA #6 AWAにおけるデータ利活用の取り組みと今後の展望について
サイバーエージェント社主催の下記のイベントの登壇資料です
https://cyberagent.connpass.com/event/101577/
Hiroki Mizukami
October 05, 2018
More Decks by Hiroki Mizukami
See All by Hiroki Mizukami
音楽配信サービスにおける 推薦システムの概要と 数理モデルについて
hiroki_mizukami
0
230
FukuokaR #7
hiroki_mizukami
0
340
オンライン広告の数理モデルと数学ソフトウェア MSFD#23
hiroki_mizukami
6
4.8k
Featured
See All Featured
The SEO identity crisis: Don't let AI make you average
varn
0
520
The agentic SEO stack - context over prompts
schlessera
0
850
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
390
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Transcript
Welcome to Data Engineering and Data Analytics Workshop #6 2018
/ 10 / 05
• ⽔水上 ひろき • サイバーエージェント 秋葉原ラボ • データアナリスト • 主にAWAのデータ利利活⽤用に従事
• 略略歴 • 家具屋さんで物流・販売管理理 • (中略略) • 現在に⾄至る • 数学を専攻してました. • 趣味:カレーと⾳音楽 ⾃自⼰己紹介
AWAにおけるデータ利利活⽤用の 取り組みと今後の展望について 株式会社サイバーエージェント 秋葉原ラボ ⽔水上 ひろき @pizukami
• AWAとラボの取り組みに関してご紹介 • 幅広く浅く • 類類似プレイリスト探索システムについて • 狭く深く • これまでとこれからの課題
• リアルタイムにユーザのフィードバック使いたい問題 • メタデータ問い合わせ遅い問題 • ABテスト始まらなかった問題 • 再利利⽤用可能なシステムのレイヤ分割 • アプリケーション構成のデザインパターンとして参考になれば • インフラのレイヤーにはあまり触れないかも 概要
⽬目次 ・AWAにおけるデータ利利活⽤用の取り組み ・類類似プレイリスト探索システムについて ・これまでとこれからの課題 ・AWAとは?
・AWAにおけるデータ利利活⽤用の取り組み ・類類似プレイリスト探索システムについて ・これまでとこれからの課題 ・AWAとは?
• 定額制⾳音楽配信サービス • エイベックスとサイバーエージェントが共同出資 • 5000万曲を超える楽曲を再⽣生可能(現在) • 特徴 • プレイリストの公開・共有が活発
• ユーザ間で送り合うフィードバック • 秋葉原ラボとの関わり • データ利利活⽤用基盤 • ⽣生ログのETLと可視化 • コンテンツ推薦 • プロモーション企画 • KPIダッシュボード AWAとは?
・AWAにおけるデータ利利活⽤用の取り組み ・類類似プレイリスト探索システムについて ・これまでとこれからの課題 ・AWAとは?
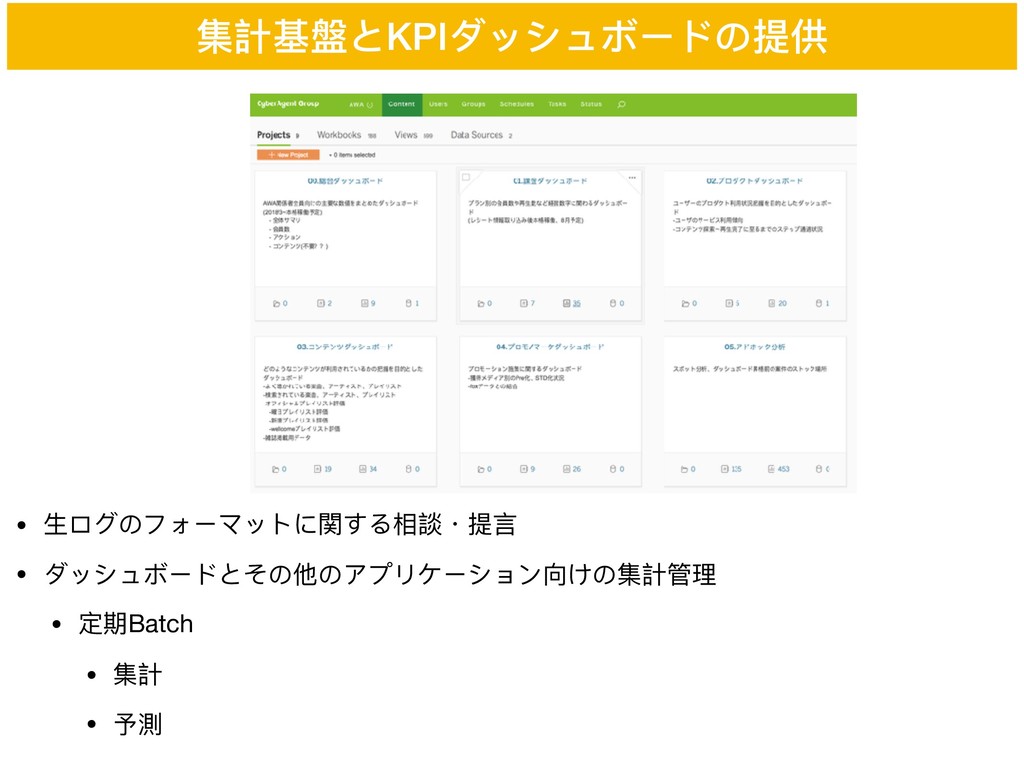
• ⽣生ログのフォーマットに関する相談・提⾔言 • ダッシュボードとその他のアプリケーション向けの集計管理理 • 定期Batch • 集計 • 予測
集計基盤とKPIダッシュボードの提供
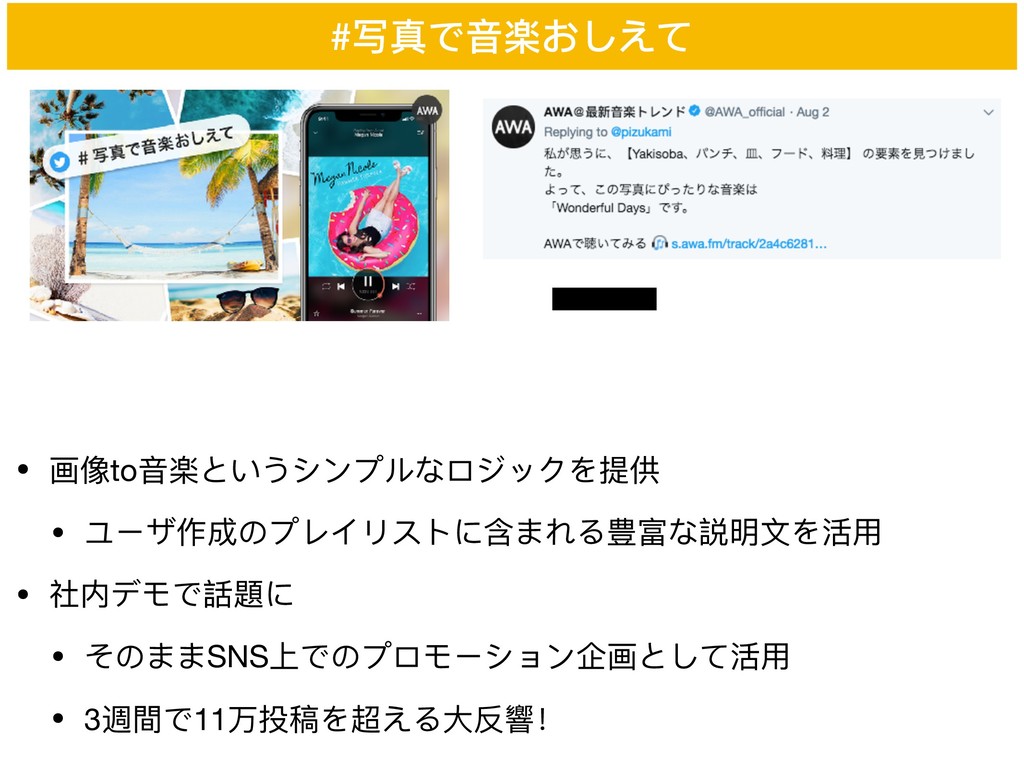
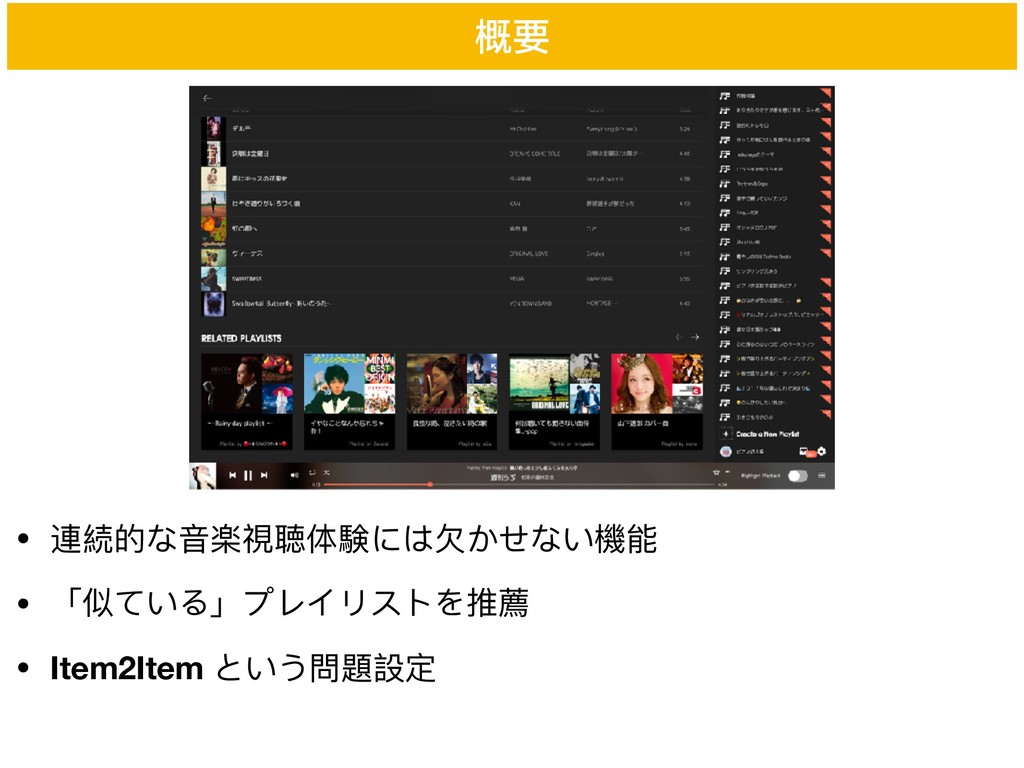
• 画像to⾳音楽というシンプルなロジックを提供 • ユーザ作成のプレイリストに含まれる豊富な説明⽂文を活⽤用 • 社内デモで話題に • そのままSNS上でのプロモーション企画として活⽤用 • 3週間で11万投稿を超える⼤大反響!
#写真で⾳音楽おしえて
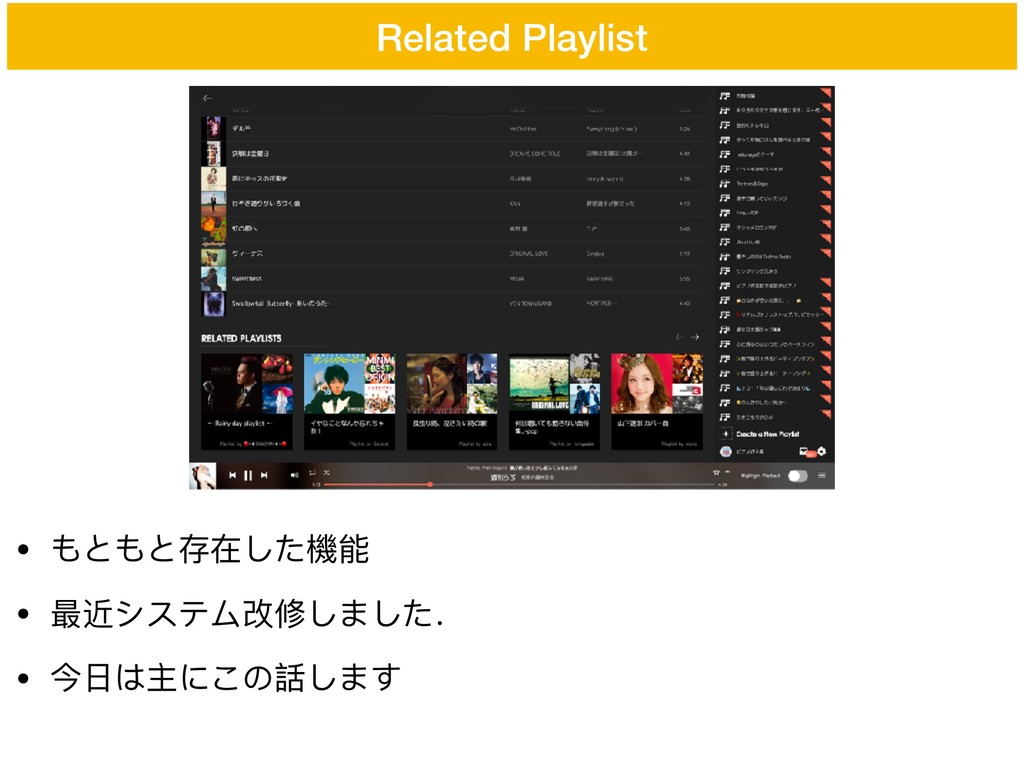
• もともと存在した機能 • 最近システム改修しました. • 今⽇日は主にこの話します Related Playlist
・AWAにおけるデータ利利活⽤用の取り組み ・類類似プレイリスト探索システムについて ・これまでとこれからの課題 ・AWAとは?
の前にちょっと予備知識 推薦システムとは?
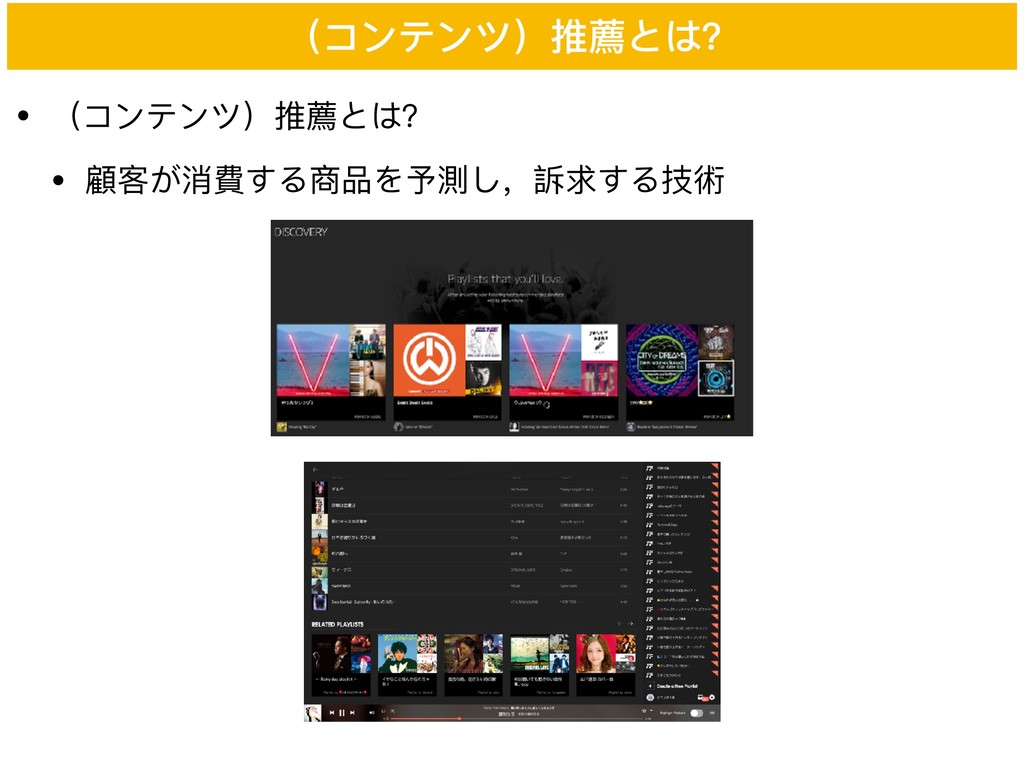
• (コンテンツ)推薦とは? • 顧客が消費する商品を予測し,訴求する技術 (コンテンツ)推薦とは?
• 推薦システムにおける主要な問題2つ • User to Item • 「あなたへのおすすめ」 • Userに対するCold
Start問題がある • Item to Item • 「この商品を買った⼈人はこんな商品も買っています」 • Userに対するCold Start問題がない • あらかじめ計算可能 (コンテンツ)推薦とは?
• 推薦システムにおける主要な⽅方針・根拠3つ • 協調フィルタリング(collaborative filtering) • ユーザからの過去のフィードバックを基にする • 計算に⼯工夫が必要なことがおおい •
内容ベースフィルタリング(content-based filtering) • 推薦したいアイテムのメタ情報を基にする • 意向ベースフィルタリング(intention-based filtering) • 例例:「新曲をPRしたい」 • 胴元が何を打ち出したいか • 実際には上記を組み合わせたシステムになる (コンテンツ)推薦とは?
• 連続的な⾳音楽視聴体験には⽋欠かせない機能 • 「似ている」プレイリストを推薦 • Item2Item という問題設定 概要
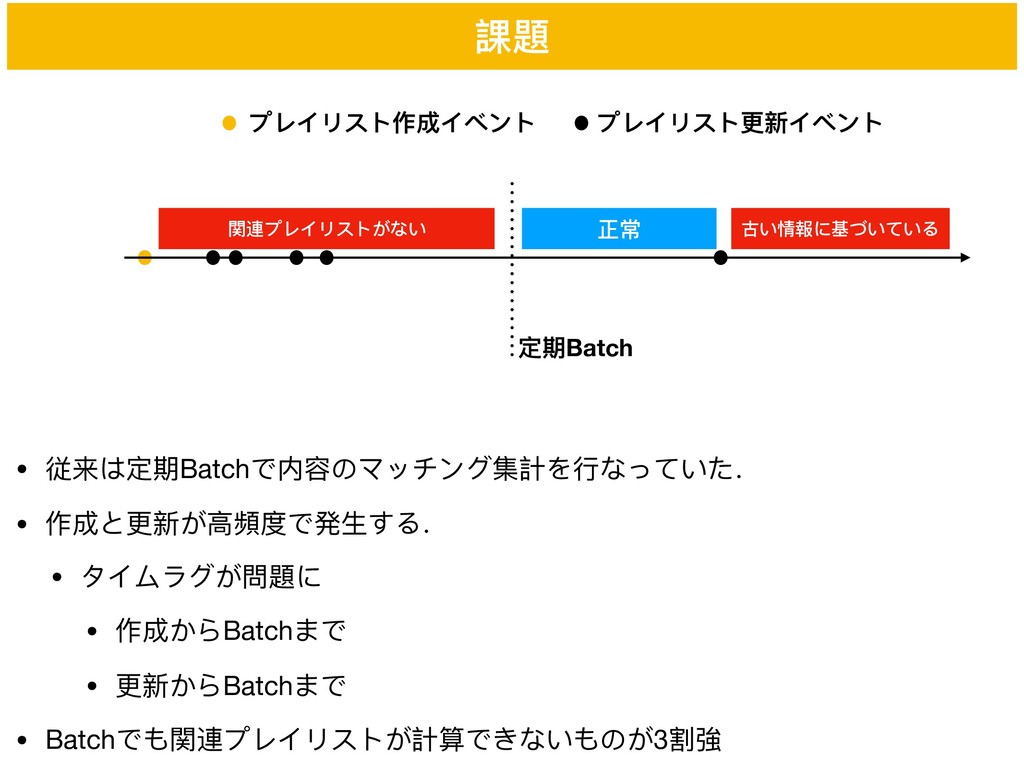
• 従来は定期Batchで内容のマッチング集計を⾏行行なっていた. • 作成と更更新が⾼高頻度で発⽣生する. • タイムラグが問題に • 作成からBatchまで • 更更新からBatchまで
• Batchでも関連プレイリストが計算できないものが3割強 課題 プレイリスト作成イベント プレイリスト更更新イベント 定期Batch 関連プレイリストがない 正常 古い情報に基づいている
• タイムラグの内約は上記の和(あたりまえ) • 作成待ち時間 • バッチ処理理→リアルタイムな作成リクエスト • 特徴量量の計算時間 • 内容ベース(トラックの情報を使う)
• 近傍探索 • 近似最近傍探索 (Approximately Nearest Neighbor) • 「事前計算」が基本戦略略 解決の⽅方針 作成(更更新)待ち 特徴量量の計算 近傍探索 + + + 通信
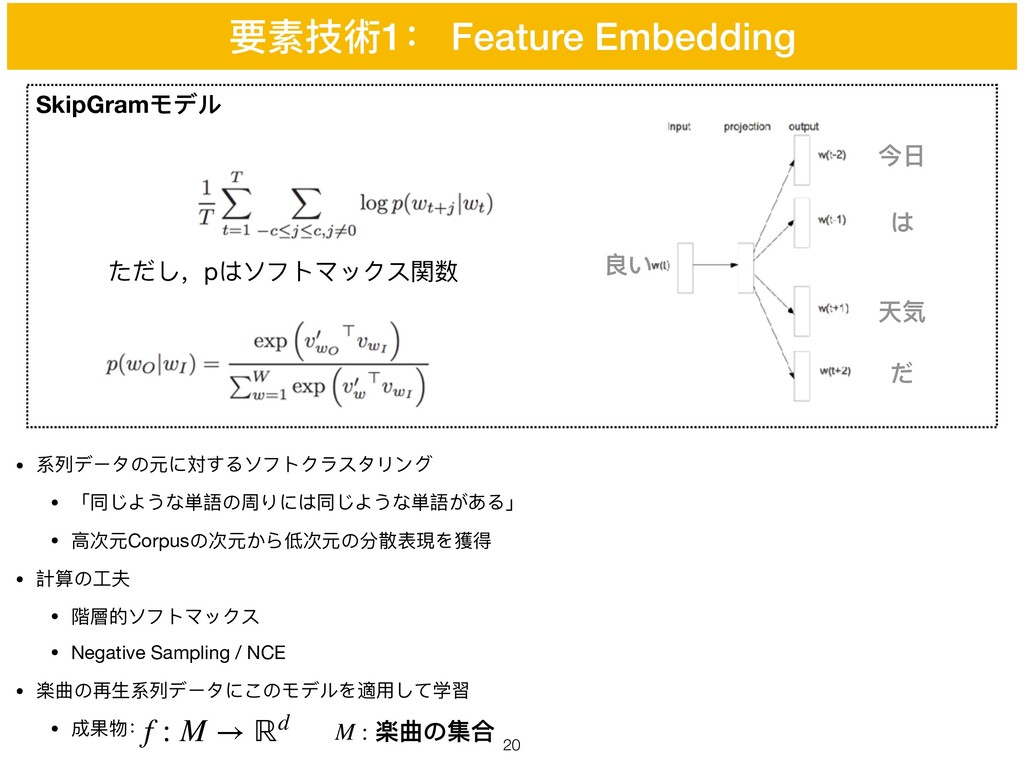
• 系列列データの元に対するソフトクラスタリング • 「同じような単語の周りには同じような単語がある」 • ⾼高次元Corpusの次元から低次元の分散表現を獲得 • 計算の⼯工夫 • 階層的ソフトマックス
• Negative Sampling / NCE • 楽曲の再⽣生系列列データにこのモデルを適⽤用して学習 • 成果物: 要素技術1: Feature Embedding SkipGramモデル ただし,pはソフトマックス関数 f : M → ℝd 今⽇日 は 良い 天気 だ M : 楽曲の集合 !20
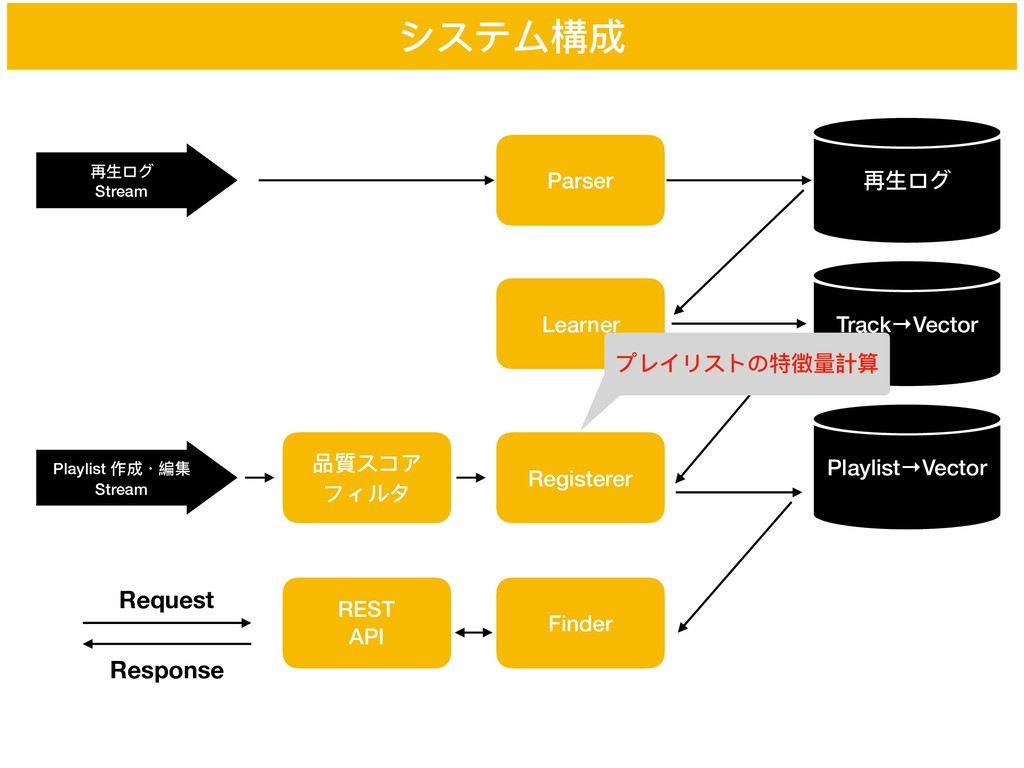
• 分散表現は計算が難しい • トラックの分散表現を事前に計算しておく • プレイリスト⾃自体の分散表現を学習しない • プレイリストの特徴量量を,紐づく楽曲のベクトルの重⼼心として得る • プレイリスト
→ トラックの列列 → 低次元ベクトル 要素技術2: プレイリストの特徴量量の定式化 プレイリスト の特徴量量 を以下で定義する ただし記号は以下の通り :トラックの集合 :プレイリストの集合 :分散表現への写像 f : M → ℝd m ∈ M8 m ∈ M g(m) := centroid(f(m1 ), f(m2 ), ⋯, f(m8 )) m !21 g(m)
要素技術3:近似最近傍探索 最近傍探索問題 有限個のアイテムの特徴量量の集合を とする,このとき任意のクエリベクトル に対して なる を探索する問題.(ちなみにNearest Neighborの意味) ここで はユークリッド距離とする.
x ∈ ℝn = {yi ∈ ℝn |i ∈ I} NN(x) = argmin d(x, y) NN(x) d( ⋅ , ⋅ ) • これは計算量量が膨⼤大 • 近似的な近傍探索アルゴリズムが考案されている. • 距離計算の近似 • 計算対象のスクリーニング y ∈
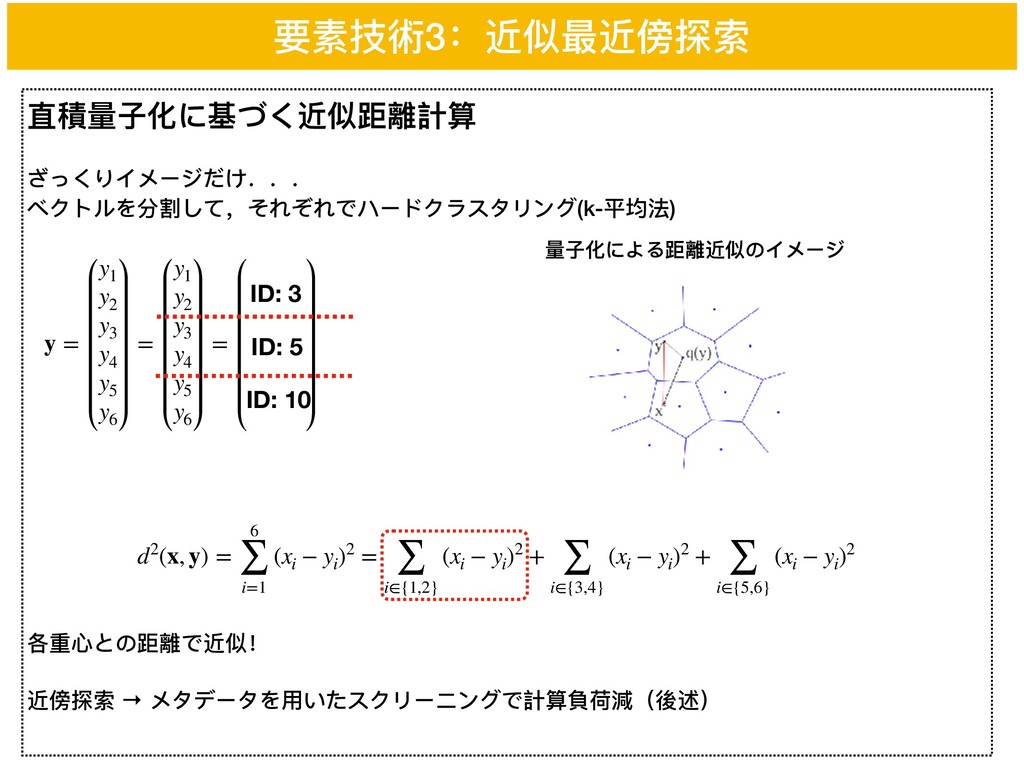
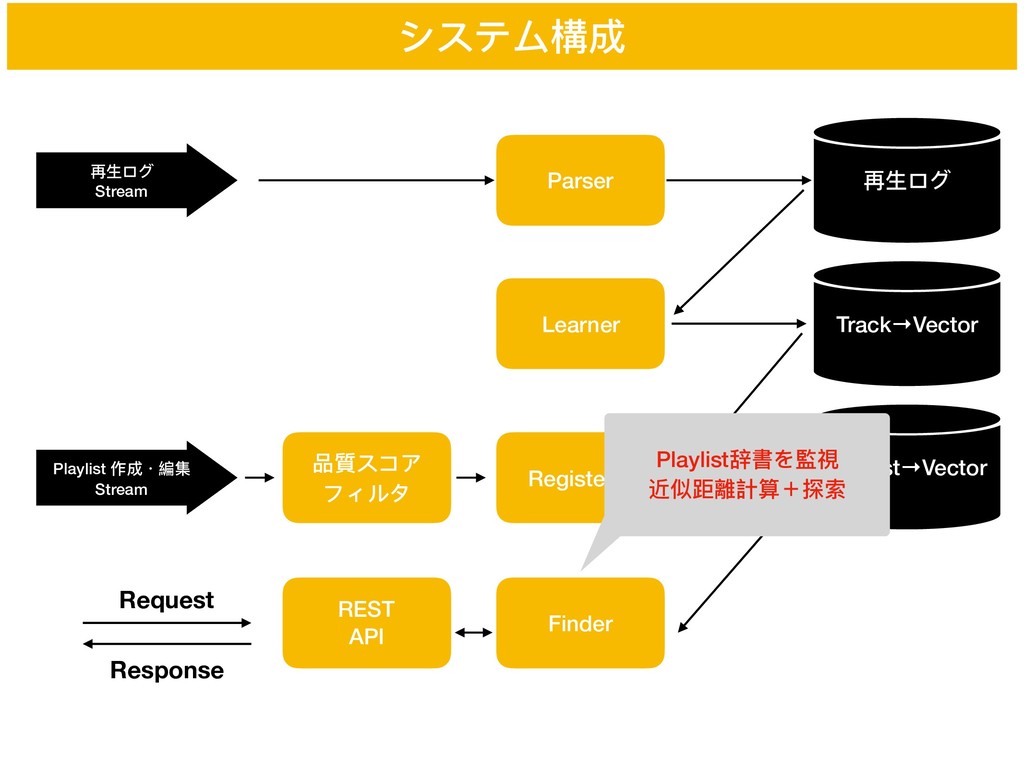
直積量量⼦子化に基づく近似距離計算 ざっくりイメージだけ... ベクトルを分割して,それぞれでハードクラスタリング(k-平均法) 各重⼼心との距離で近似! 近傍探索 → メタデータを⽤用いたスクリーニングで計算負荷減(後述) y = y1
y2 y3 y4 y5 y6 = y1 y2 y3 y4 y5 y6 = y1 y2 y3 y4 y5 y6 要素技術3:近似最近傍探索 量量⼦子化による距離近似のイメージ ID: 3 ID: 5 ID: 10 d2(x, y) = 6 ∑ i=1 (xi − yi )2 = ∑ i∈{1,2} (xi − yi )2 + ∑ i∈{3,4} (xi − yi )2 + ∑ i∈{5,6} (xi − yi )2
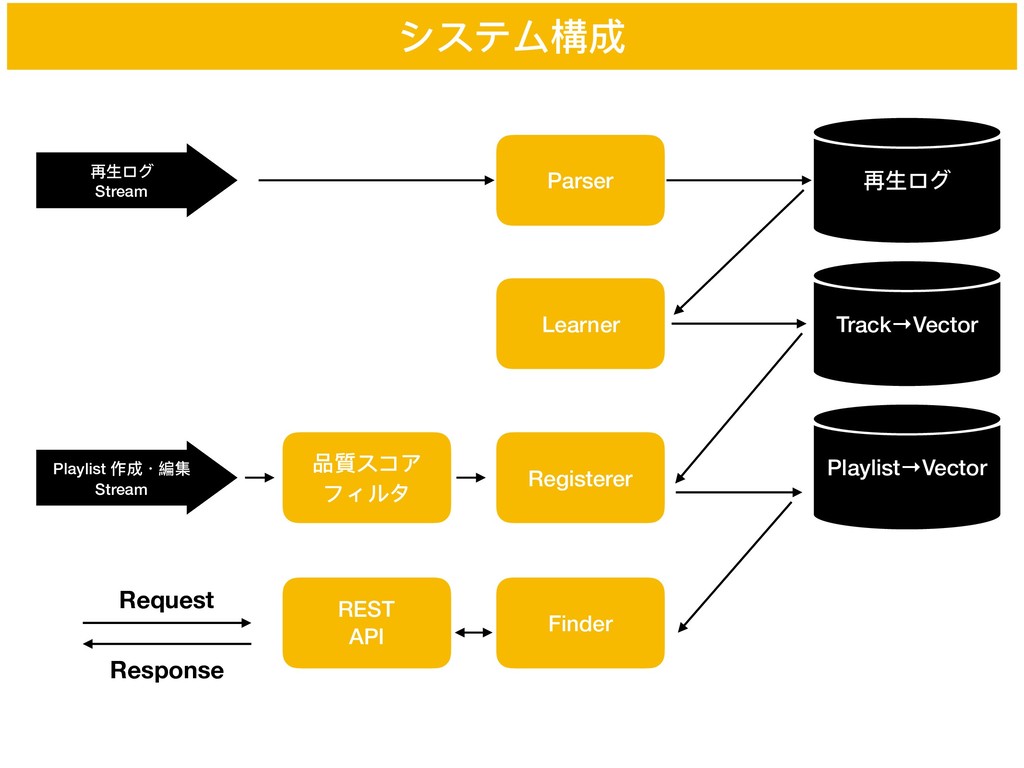
システム構成 再⽣生ログ Stream Parser Playlist 作成・編集 Stream 再⽣生ログ Learner Track→Vector
Registerer Playlist→Vector Finder 品質スコア フィルタ REST API Request Response
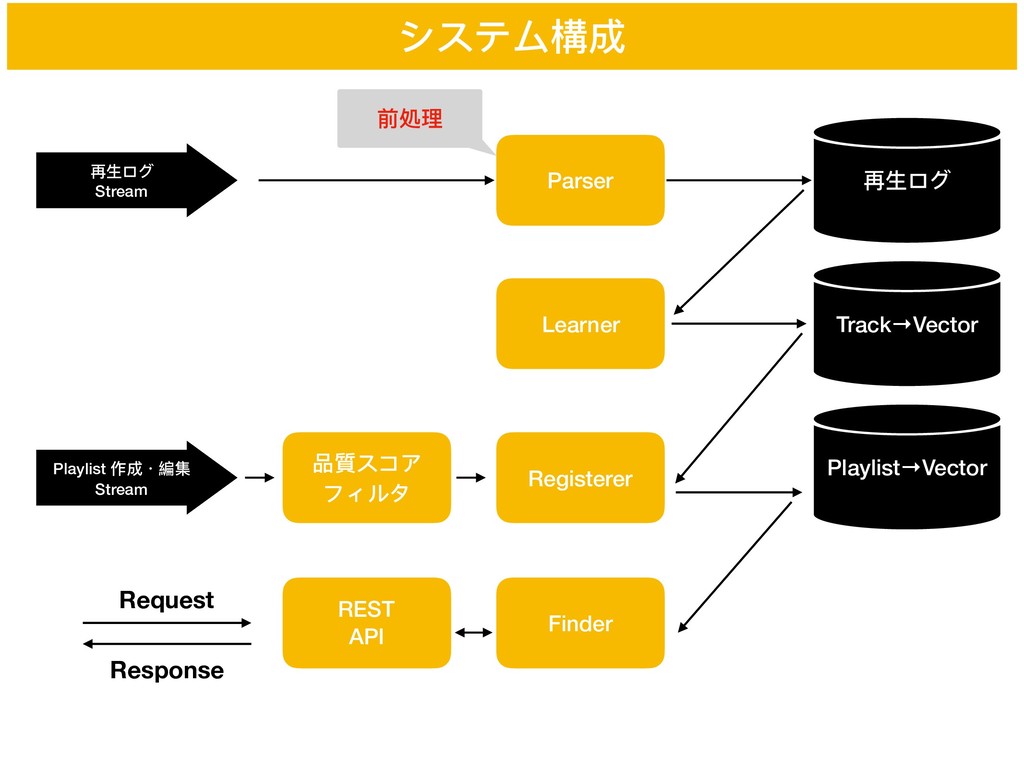
システム構成 再⽣生ログ Stream Parser Playlist 作成・編集 Stream 再⽣生ログ Learner Track→Vector
Registerer Playlist→Vector Finder 品質スコア フィルタ REST API Request Response 前処理理
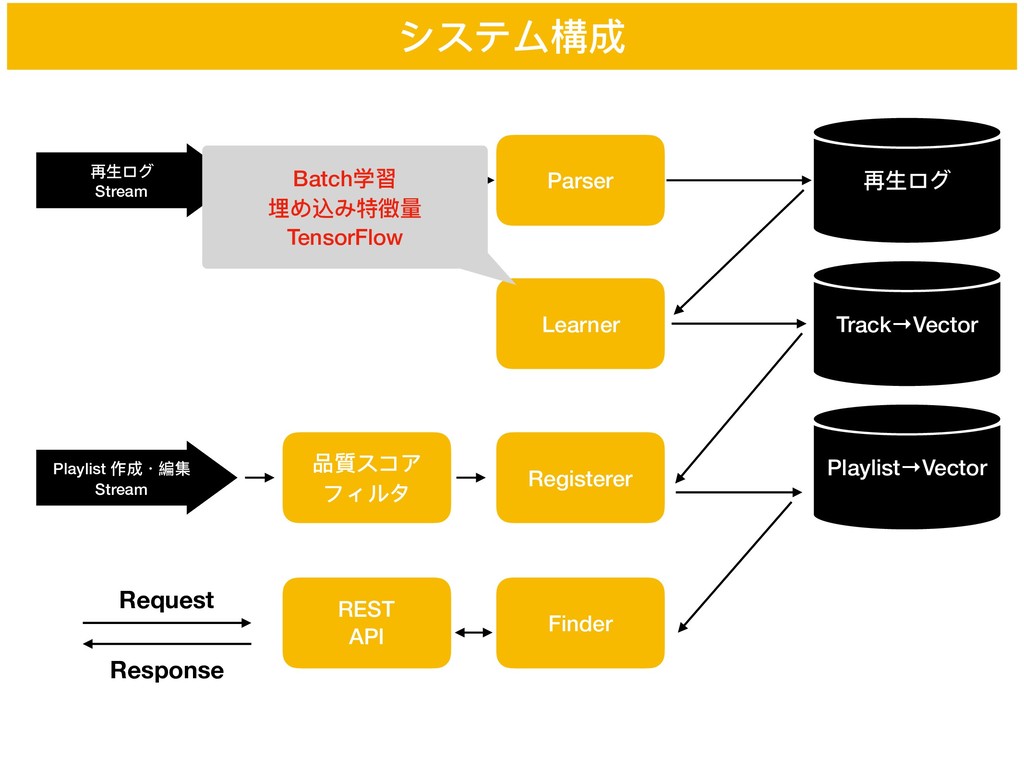
システム構成 再⽣生ログ Stream Parser Playlist 作成・編集 Stream 再⽣生ログ Learner Track→Vector
Registerer Playlist→Vector Finder 品質スコア フィルタ REST API Request Response Batch学習 埋め込み特徴量量 TensorFlow
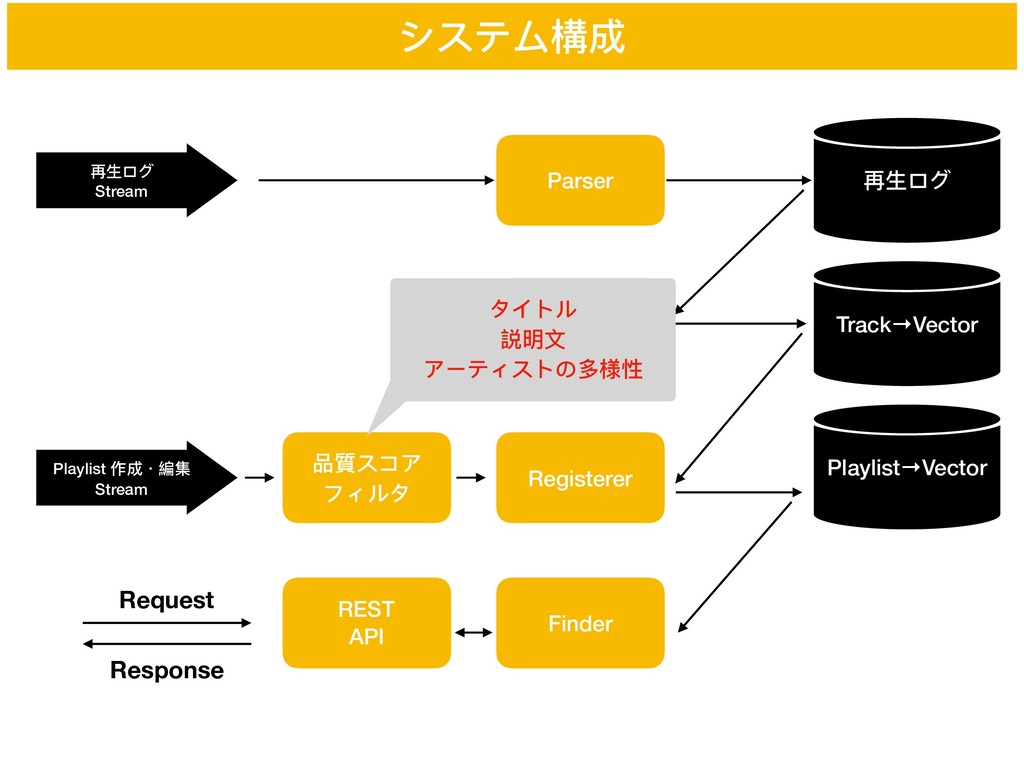
システム構成 再⽣生ログ Stream Parser Playlist 作成・編集 Stream 再⽣生ログ Learner Track→Vector
Registerer Playlist→Vector Finder 品質スコア フィルタ REST API Request Response タイトル 説明⽂文 アーティストの多様性
システム構成 再⽣生ログ Stream Parser Playlist 作成・編集 Stream 再⽣生ログ Learner Track→Vector
Registerer Playlist→Vector Finder 品質スコア フィルタ REST API Request Response プレイリストの特徴量量計算
システム構成 再⽣生ログ Stream Parser Playlist 作成・編集 Stream 再⽣生ログ Learner Track→Vector
Registerer Playlist→Vector Finder 品質スコア フィルタ REST API Request Response Playlist辞書を監視 近似距離計算+探索
システム構成 再⽣生ログ Stream Parser Playlist 作成・編集 Stream 再⽣生ログ Learner Track→Vector
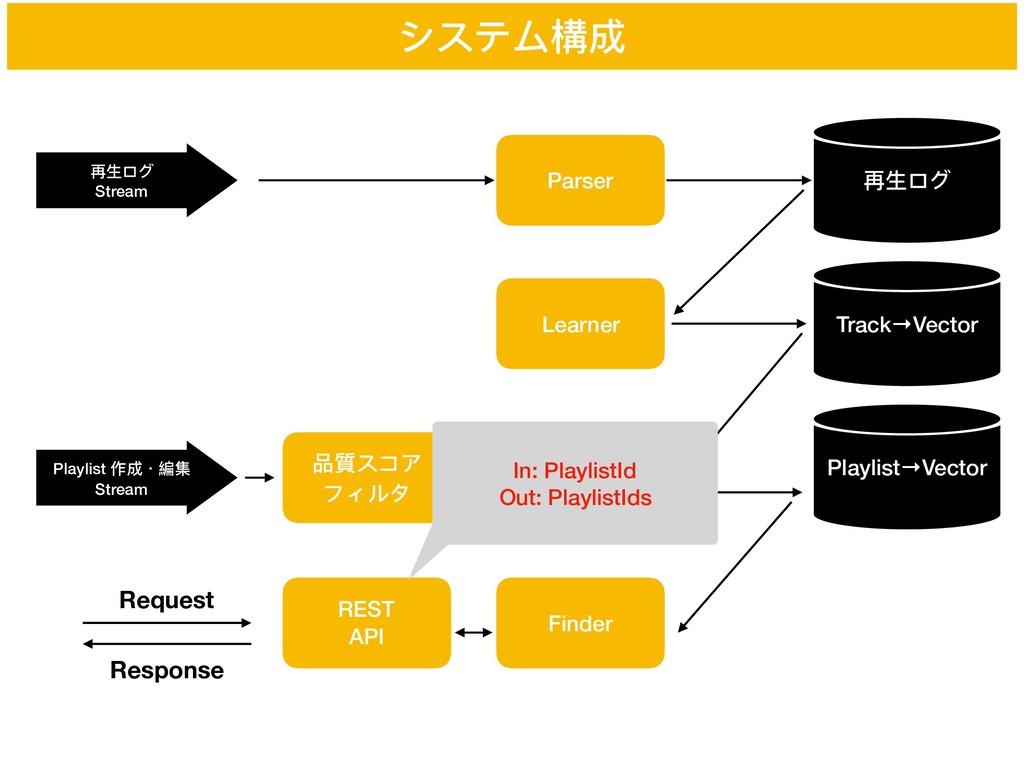
Registerer Playlist→Vector Finder 品質スコア フィルタ REST API Request Response In: PlaylistId Out: PlaylistIds
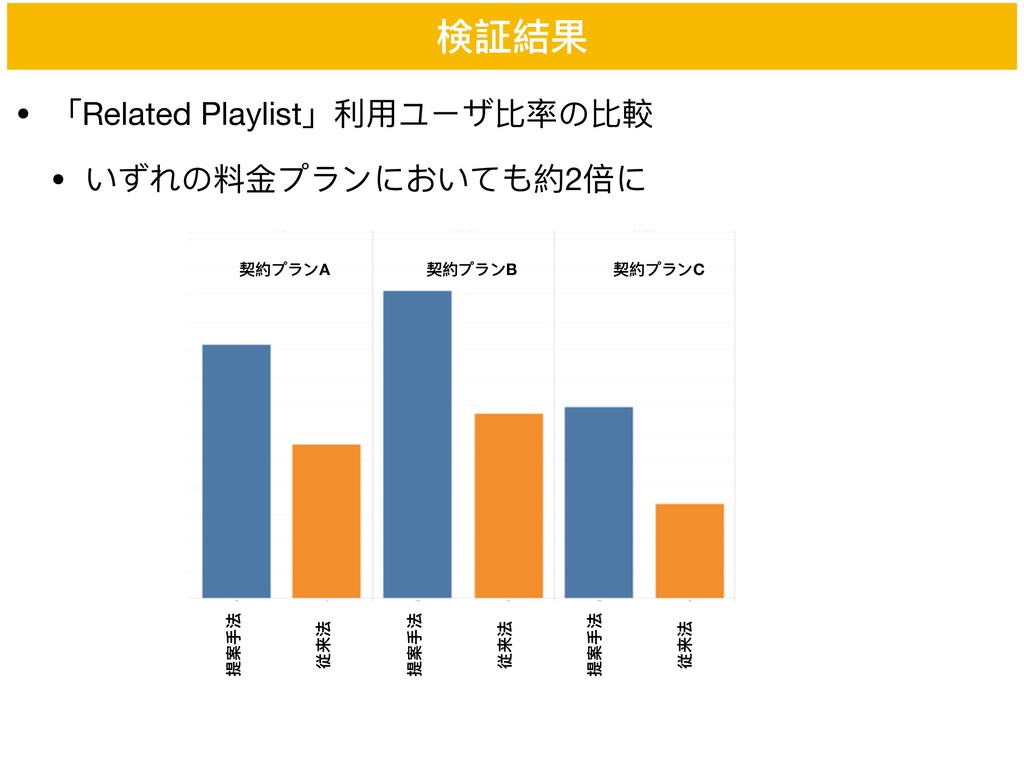
• 「Related Playlist」利利⽤用ユーザ⽐比率の⽐比較 • いずれの料料⾦金金プランにおいても約2倍に 検証結果 契約プランA 契約プランB 契約プランC 提案⼿手法
従来法 提案⼿手法 従来法 提案⼿手法 従来法
・AWAにおけるデータ利利活⽤用の取り組み ・類類似プレイリスト探索システムについて ・これまでとこれからの課題 ・AWAとは?
リアルタイムにユーザの フィードバック使いたい問題
• フィードバックデータ • 主にユーザが発⽣生させるデータ • いわゆる「ログ」 • 更更新処理理が発⽣生しない⼤大きなデータ • どんなデータ?
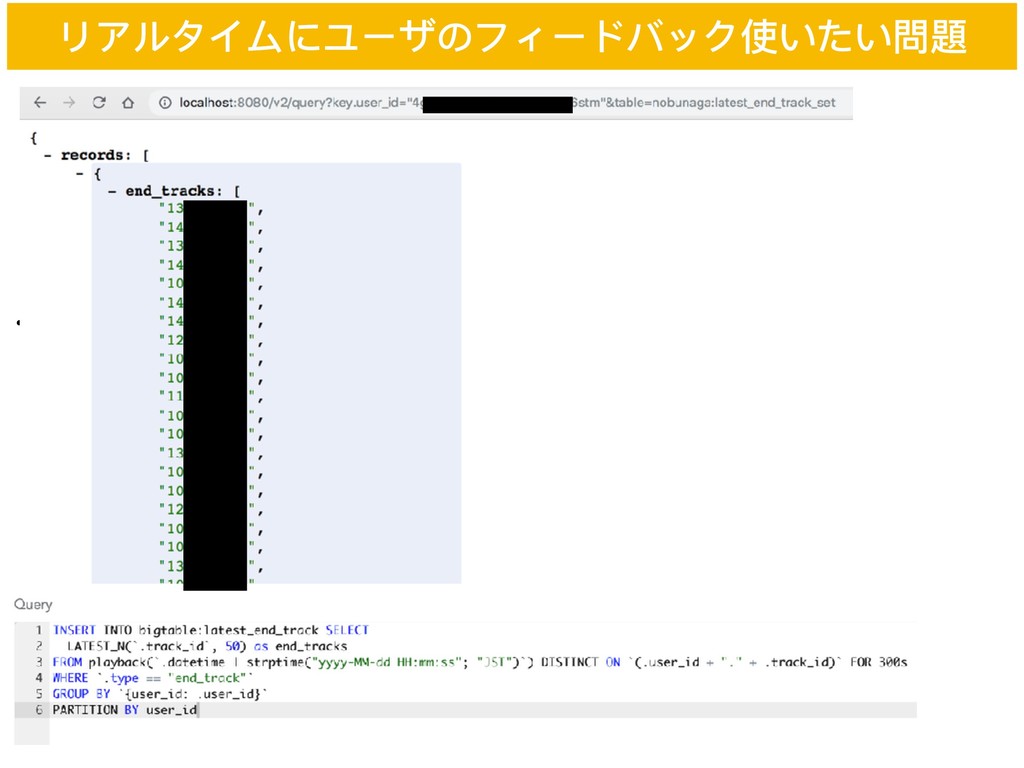
• ユーザの⾏行行動ログ誰が いつ 何を なにした • 「Aさんが 2018/10/5 10:00:00 に楽曲tを再⽣生開始した」 • バッチ処理理+列列志向データベースは⼤大規模集計向き • ストリーミング処理理+KVS使い分ける • 難しい → 遅延するし重複する リアルタイムにユーザのフィードバック使いたい問題 これまで:システムに⽤用いるデータはバッチ処理理+列列志向データベース →少数⾏行行の処理理・低遅延な処理理に不不向き 現在:内製ストリーミング処理理基盤Zeroの導⼊入: ストリーミング処理理+KVS →需要に合わせて選択できるように Query: Aさんが最後に聞いたアーティスト5⼈人教えて
• フィードバックデータ? • フィードバックデータ=主にユーザが発⽣生させるデータ • いわゆる「ログ」 • 更更新処理理が発⽣生しない • どんなデータ?
• 誰が いつ 何を なにした • Aさんが 2018/10/5 10:00:00 に楽曲tを再⽣生開始した • Bさんが 2018/10/5 10:00:00 に楽曲sをお気に⼊入り登録した • バッチ処理理+列列志向データベースは⼤大規模集計向き • ストリーミング処理理使い分ける • 難しい • 遅延する • 重複する(cf: least at once戦略略) リアルタイムにユーザのフィードバック使いたい問題 これまで:システムに⽤用いるデータはバッチ処理理+列列志向データベース →少数⾏行行の処理理・低遅延な処理理に不不向き 現在:ストリーミング処理理基盤Zeroの導⼊入: ストリーミング処理理+KVS → Query: Aさんが最後に聞いたアーティスト5⼈人教えて
• Use Case • Frequency Control • 「5回表示して再⽣生しなかったプレイリストを⾮非表示に」 • 機械学習などによるリアルタイム予測
• 「直近の再⽣生10曲を元に次の曲を推薦」 • 「最後に聴いたアーティストの新曲を推薦したい」 リアルタイムにユーザのフィードバック使いたい問題
メタデータ問い合わせ 遅い問題
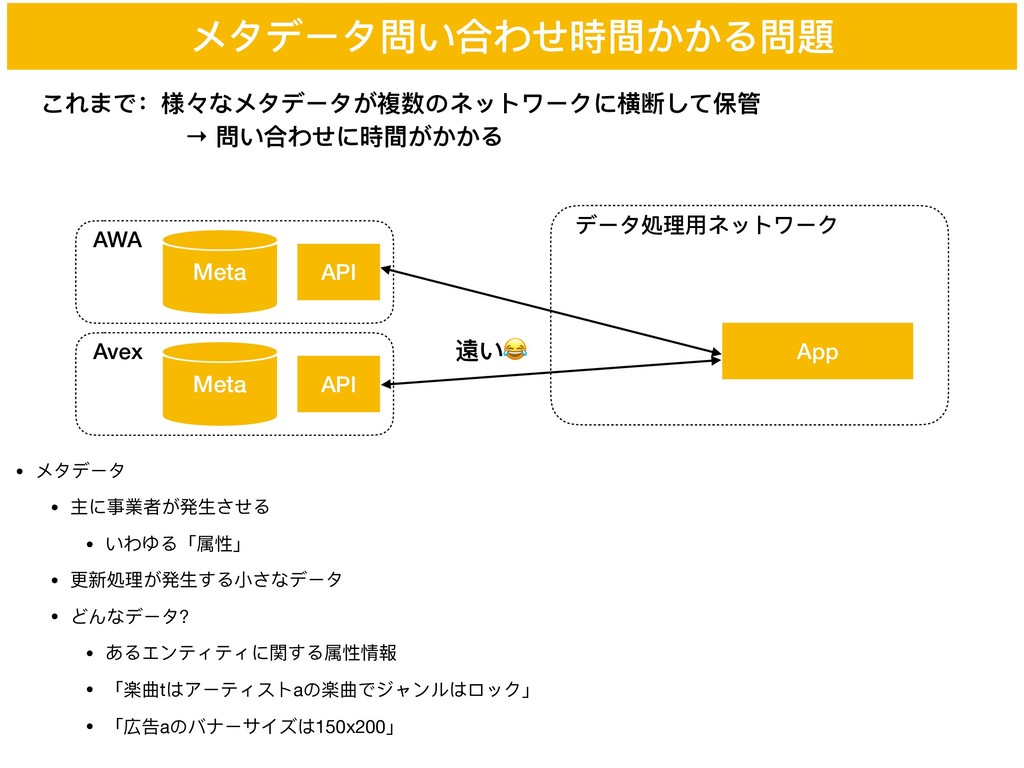
メタデータ問い合わせ時間かかる問題 データ処理理⽤用ネットワーク App これまで:様々なメタデータが複数のネットワークに横断して保管 → 問い合わせに時間がかかる AWA Meta • メタデータ
• 主に事業者が発⽣生させる • いわゆる「属性」 • 更更新処理理が発⽣生する⼩小さなデータ • どんなデータ? • あるエンティティに関する属性情報 • 「楽曲tはアーティストaの楽曲でジャンルはロック」 • 「広告aのバナーサイズは150x200」 Avex Meta API API 遠い
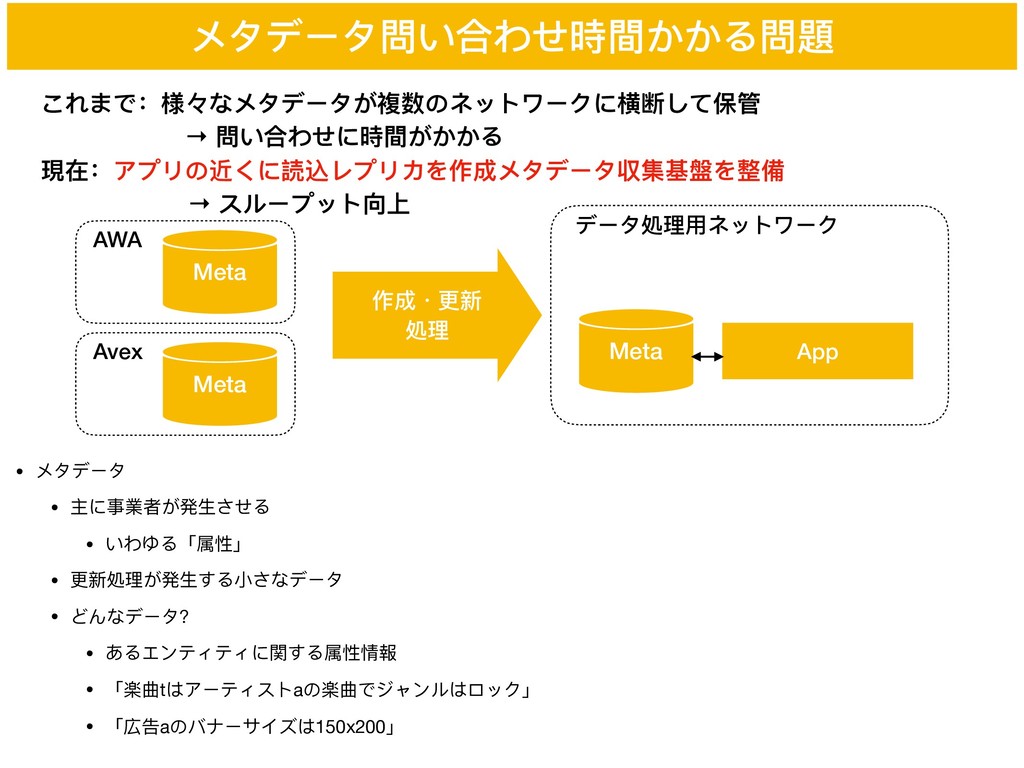
メタデータ問い合わせ時間かかる問題 データ処理理⽤用ネットワーク App これまで:様々なメタデータが複数のネットワークに横断して保管 → 問い合わせに時間がかかる 現在:アプリの近くに読込レプリカを作成メタデータ収集基盤を整備 → スループット向上 Meta
作成・更更新 処理理 AWA Meta • メタデータ • 主に事業者が発⽣生させる • いわゆる「属性」 • 更更新処理理が発⽣生する⼩小さなデータ • どんなデータ? • あるエンティティに関する属性情報 • 「楽曲tはアーティストaの楽曲でジャンルはロック」 • 「広告aのバナーサイズは150x200」 Avex Meta
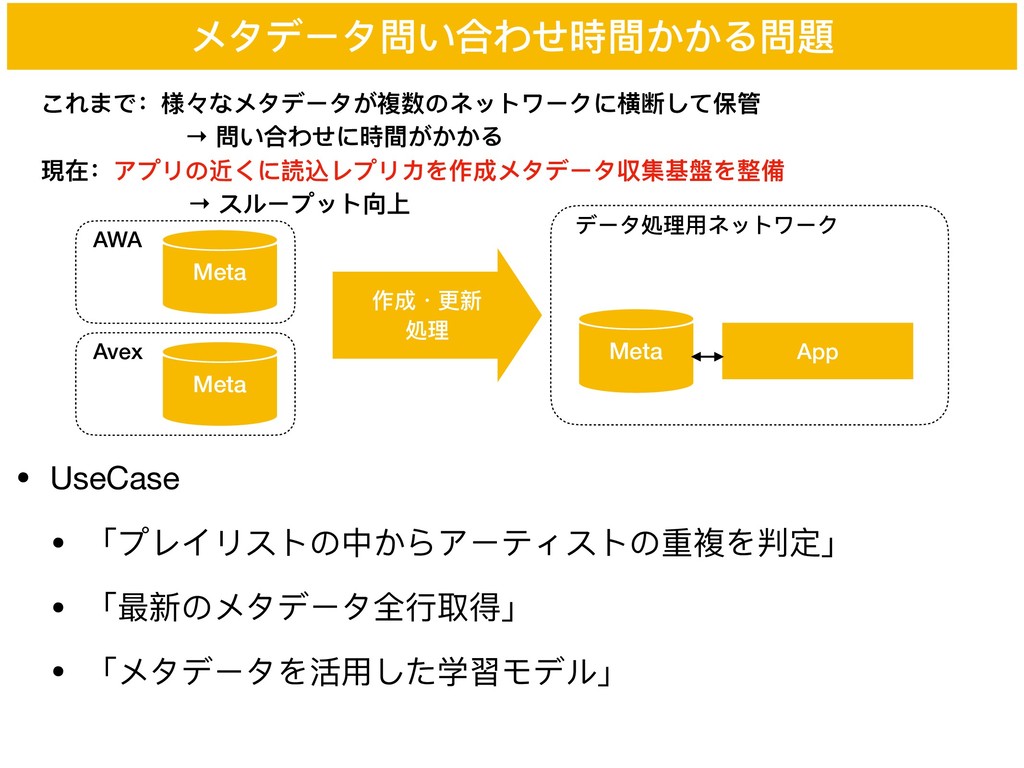
メタデータ問い合わせ時間かかる問題 データ処理理⽤用ネットワーク App これまで:様々なメタデータが複数のネットワークに横断して保管 → 問い合わせに時間がかかる 現在:アプリの近くに読込レプリカを作成メタデータ収集基盤を整備 → スループット向上 Meta
作成・更更新 処理理 AWA Meta • UseCase • 「プレイリストの中からアーティストの重複を判定」 • 「最新のメタデータ全⾏行行取得」 • 「メタデータを活⽤用した学習モデル」 Avex Meta
A / Bテスト 始まらなかった問題
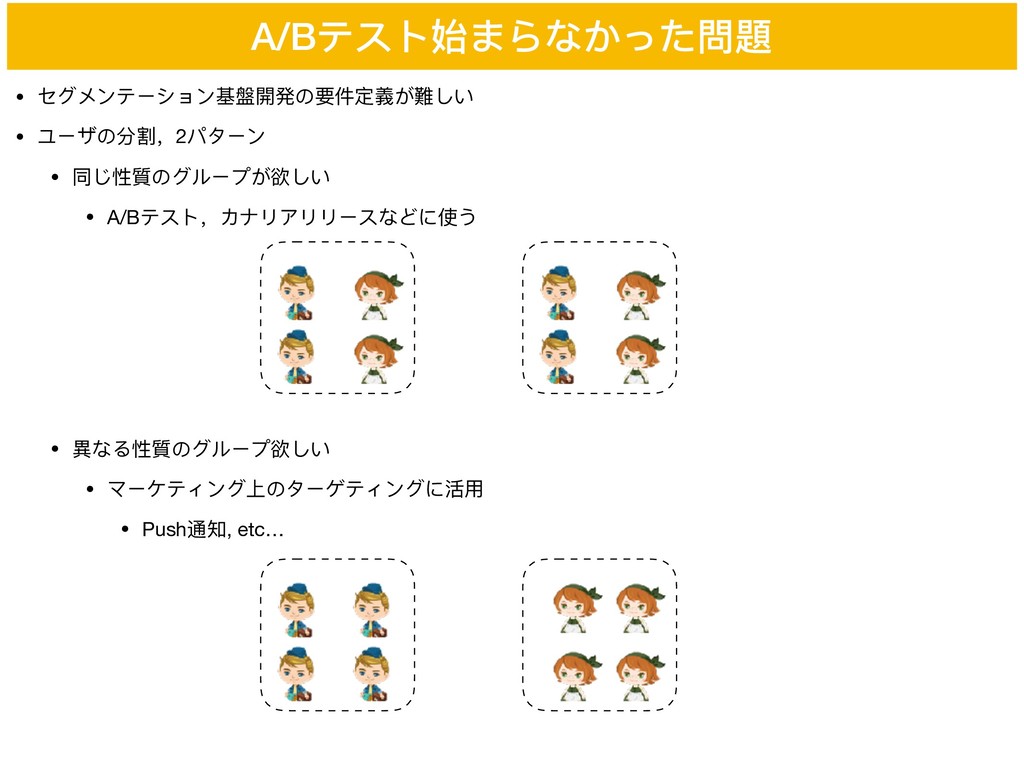
• セグメンテーション基盤開発の要件定義が難しい • ユーザの分割,2パターン • 同じ性質のグループが欲しい • A/Bテスト,カナリアリリースなどに使う • 異異なる性質のグループ欲しい
• マーケティング上のターゲティングに活⽤用 • Push通知, etc… A/Bテスト始まらなかった問題
A/Bテスト始まらなかった問題 こちら側の要件を切り捨てて シンプルなシステムに!! • セグメンテーション基盤開発の要件定義が難しい • ユーザの分割,2パターン • 同じ性質のグループが欲しい •
A/Bテスト,カナリアリリースなどに使う • 異異なる性質のグループ欲しい • マーケティング上のターゲティングに活⽤用 • Push通知, etc…
・・・みたいな問題を 何回も解きたくない!
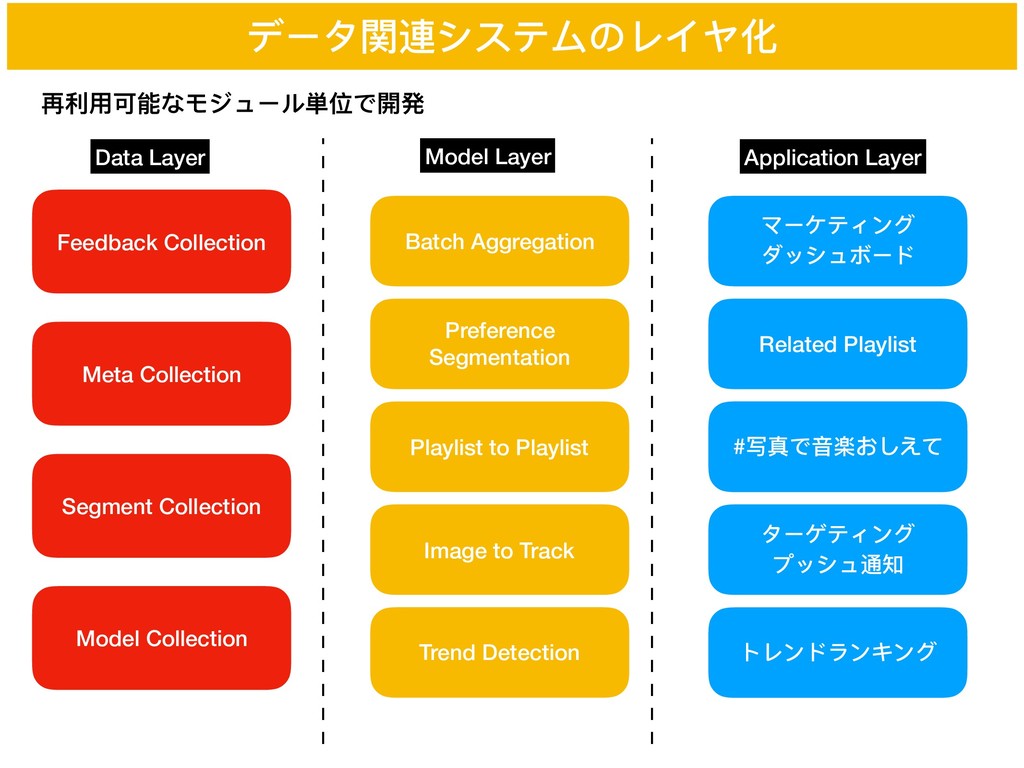
データ関連システムのレイヤ化 再利利⽤用可能なモジュール単位で開発 Data Layer Model Layer Application Layer Feedback Collection
Meta Collection Segment Collection Model Collection Batch Aggregation Preference Segmentation Playlist to Playlist Image to Track マーケティング ダッシュボード Related Playlist #写真で⾳音楽おしえて ターゲティング プッシュ通知 Trend Detection トレンドランキング
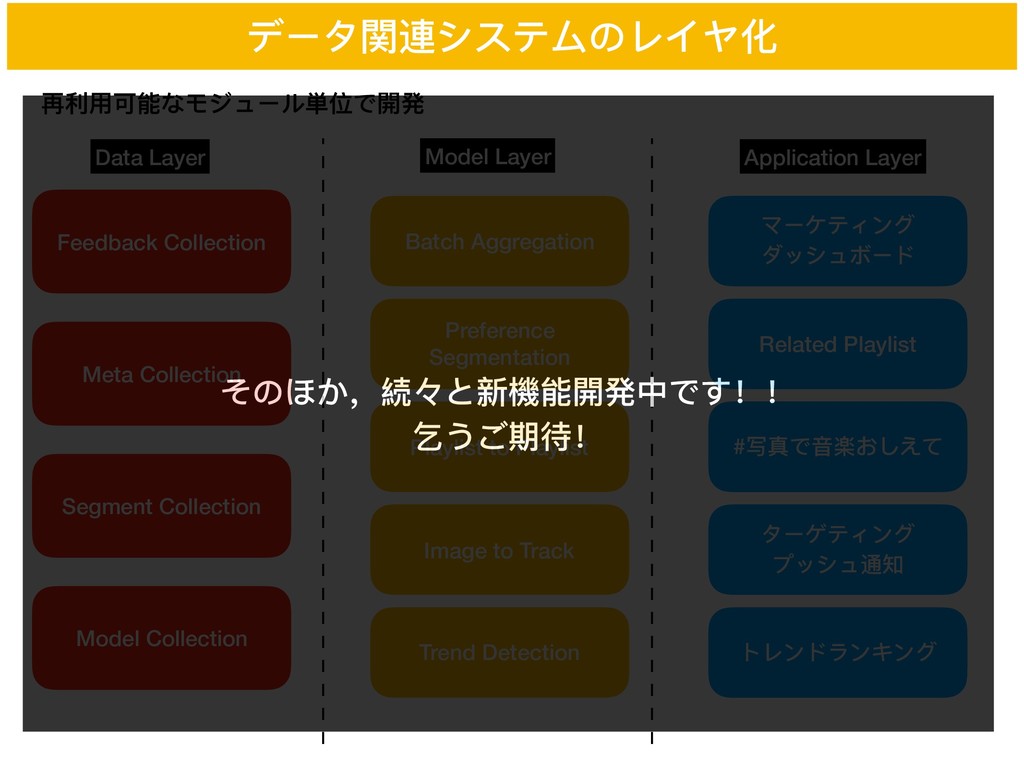
データ関連システムのレイヤ化 再利利⽤用可能なモジュール単位で開発 Data Layer Model Layer Application Layer Feedback Collection
Meta Collection Segment Collection Model Collection Batch Aggregation Preference Segmentation Playlist to Playlist Image to Track マーケティング ダッシュボード Related Playlist #写真で⾳音楽おしえて ターゲティング プッシュ通知 Trend Detection トレンドランキング そのほか,続々と新機能開発中です!! 乞うご期待!
• ストリーム処理理エンジン「Zero」の開発と運⽤用 • https://www.slideshare.net/EiichiSato/zero-80237397 • A.J.A Recommend Engineにおける⽂文書推薦について • https://www.slideshare.net/cyberagent/20170627-workshop-
ajatextrecommend-77364019 • Product Quantization for Nearest Neighbor Search, H. Jegou, et al, ’11 • Distributed Representations of Words and Phrases and their Compositionality, T. Mikolov, et al, ‘13 参考資料料
AWA データ周りでつかってるもの使いそうなもの雑に !48
ご静聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}