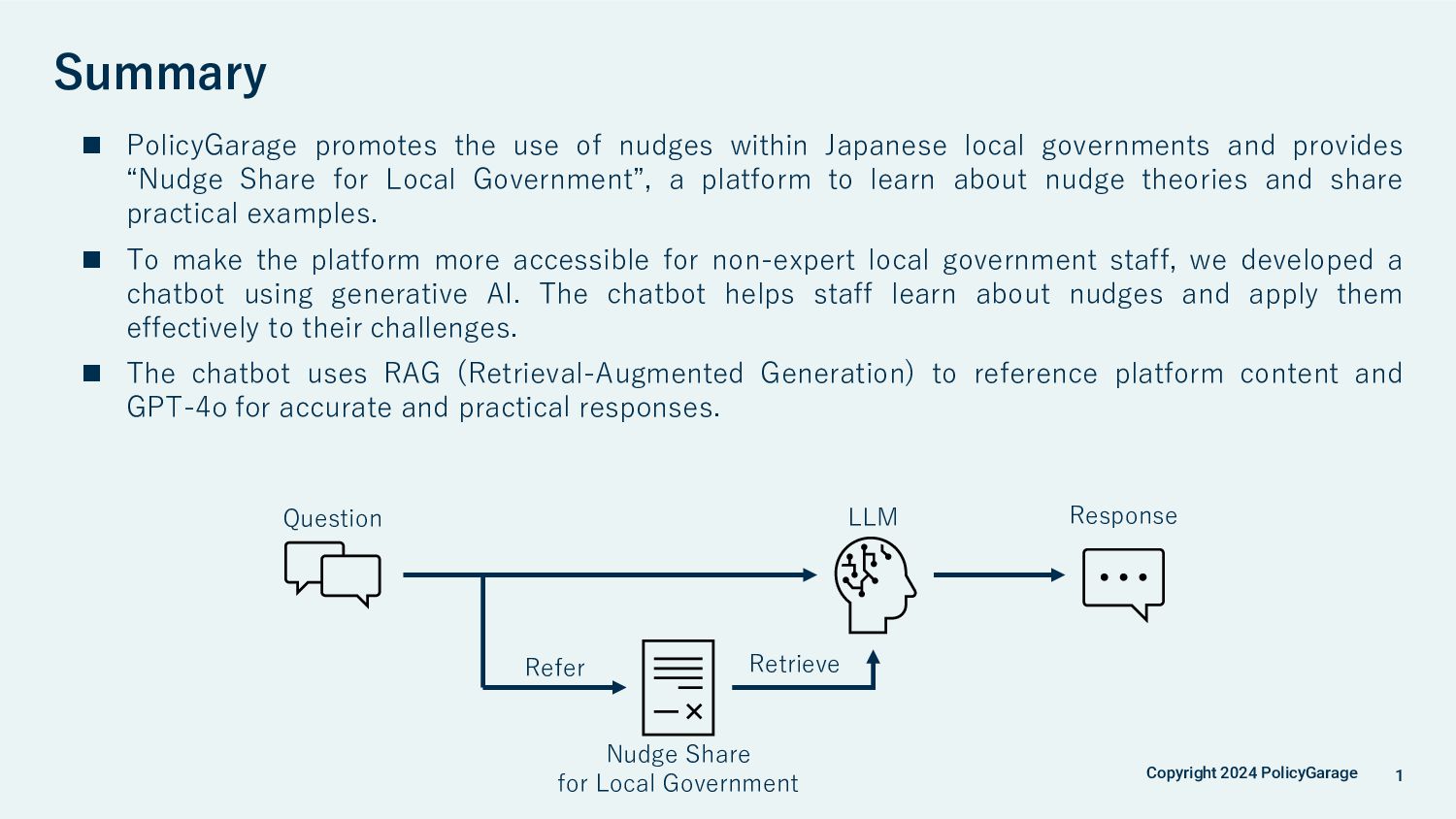
nudges within Japanese local governments and provides “Nudge Share for Local Government”, a platform to learn about nudge theories and share practical examples. ◼ To make the platform more accessible for non-expert local government staff, we developed a chatbot using generative AI. The chatbot helps staff learn about nudges and apply them effectively to their challenges. ◼ The chatbot uses RAG (Retrieval-Augmented Generation) to reference platform content and GPT-4o for accurate and practical responses. Question LLM Response Nudge Share for Local Government Refer Retrieve Summary
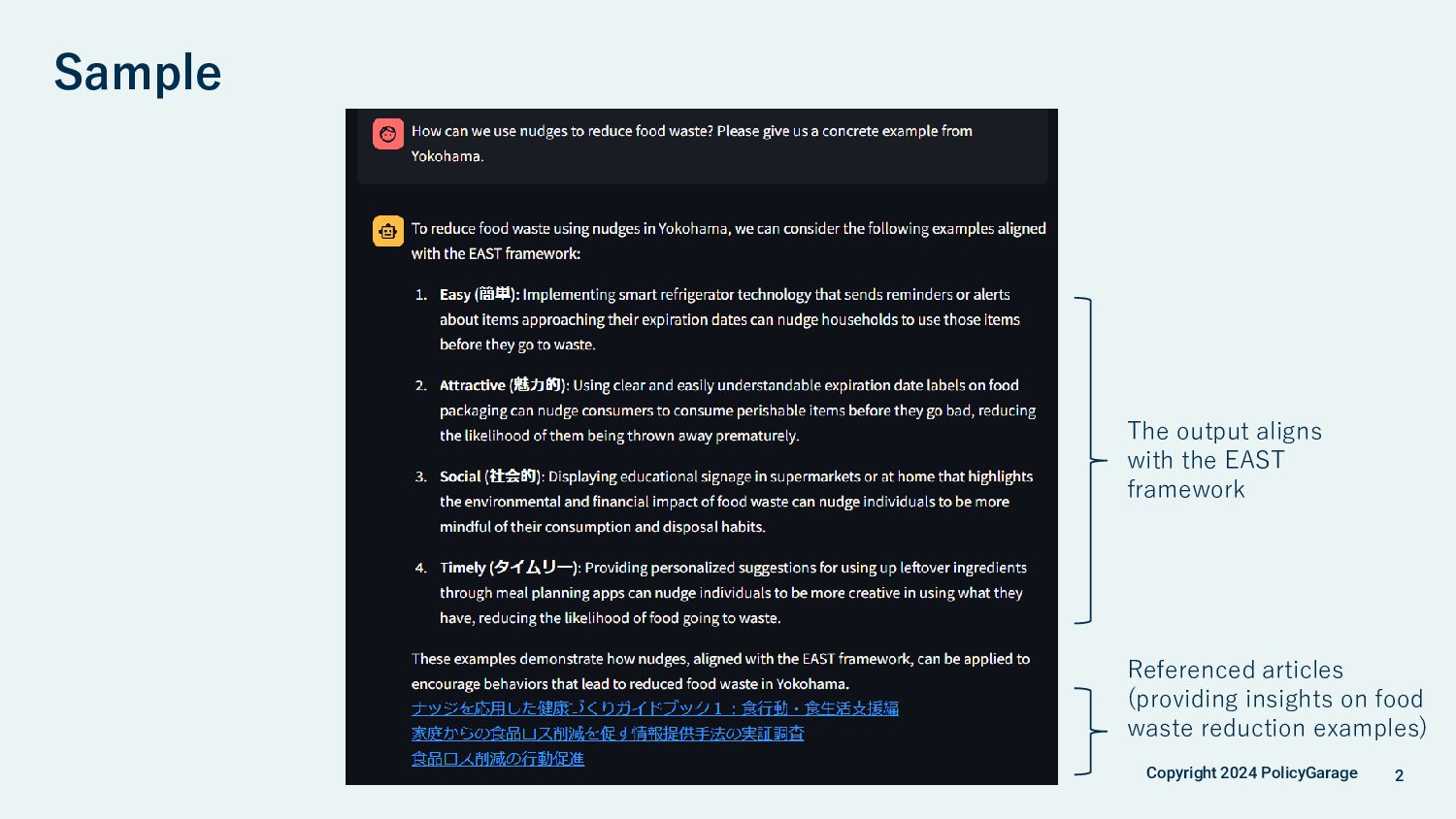
government staff to evaluate its usefulness. ◼ Outcomes • The chatbot effectively supports learning about nudges theories and generating ideas for measures • Using RAG significantly improved response accuracy compared to ChatGPT. Hallucinations were largely suppressed with prompt tuning. • For established frameworks like EAST, generative AI shows strong potential for application. • The platform and prompts are in Japanese, but the chatbot can provide responses in English with slightly lower accuracy. ◼ Challenges • Developing an all-purpose chatbot is difficult; its purpose needs to be clearly defined. • Evaluating responses requires expert verification, which is resource-intensive. Tools for RAG evaluation, such as Ragas and LLM-as-a-Judge, remain underdeveloped. • Developing a simple chatbot leads to low usage; additional strategies are needed to encourage engagement. Outcomes and Challenges
{kind=link}
{kind=link}
{kind=link}
{kind=link}