本スライドでは、AIエージェント評価の課題を解決するアプローチを提案しています。
・現状、評価が難しい理由として「何を測定するか」の選択肢が多様で解釈も多様な点があります。
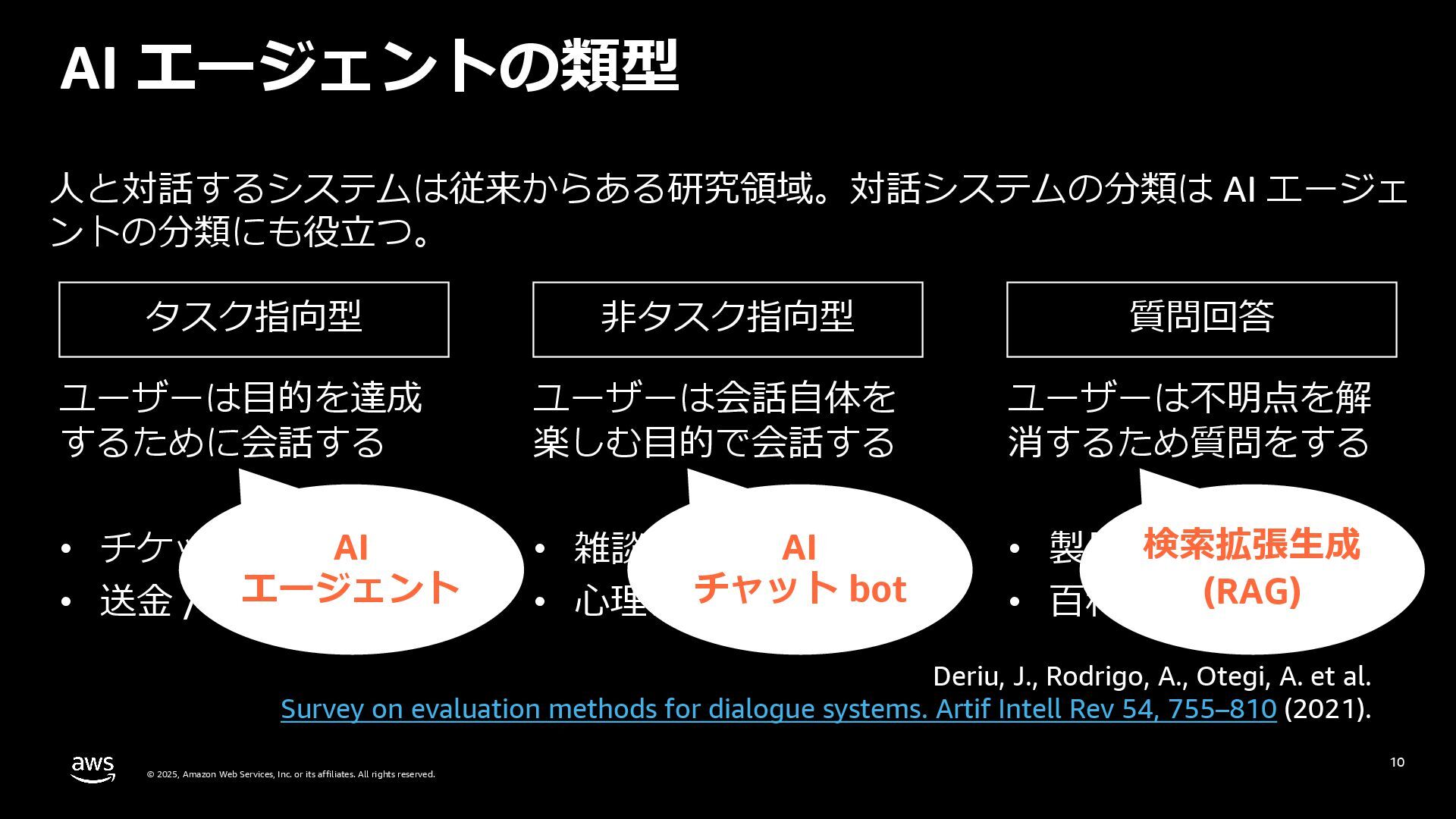
・これについて、従来の自然言語処理研究の知見を活かし実績がある体系的なフレームワークで AI エージェントとその評価観点を整理する方法を紹介します。
・その上で、評価を進めるに際し欠かせない「あるべき体験についての合意形成」に必要な対話例やシミュレーターを Spec Driven で効率的に進める方法を紹介し、病院向けのエージェント評価で適用した時に得られた結果を共有します
詳細記事 : https://qiita.com/icoxfog417/items/7078561064ef21226927
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}