is strictly prohibited Agenda What is the percolator? What do people use it for? How does it work? Why did it need a redesign? What was changed exactly?
is strictly prohibited Agenda What is the percolator? What do people use it for? How does it work? Why did it need a redesign? What was changed exactly?
is strictly prohibited Agenda What is the percolator? What do people use it for? How does it work? Why did it need a redesign? What was changed exactly?
is strictly prohibited Agenda What is the percolator? What do people use it for? How does it work? Why did it need a redesign? What was changed exactly?
is strictly prohibited Let’s index a query... PUT /_percolator/twitter/es-tweets -d ' { "query": { "match": { "tweet": "elasticsearch" } } } ' the query
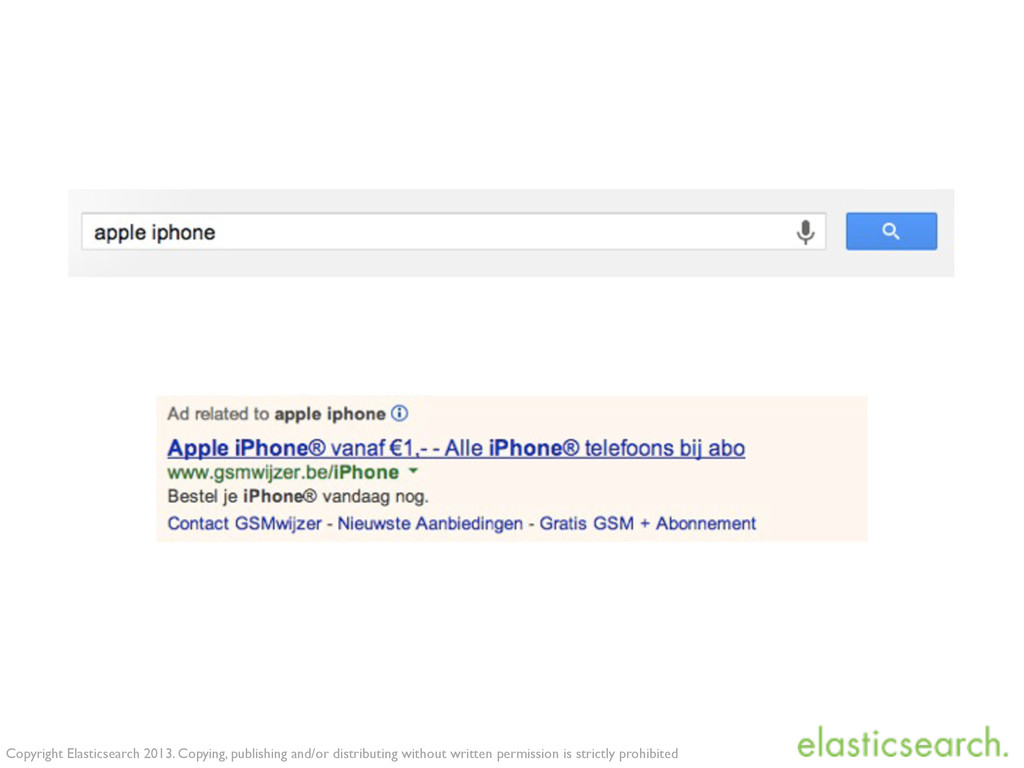
publishing and/or distributing without written permission is strictly prohibited # 200 OK How many people would the updated ad reach? ...and get feedback back
is strictly prohibited percolate a new article GET /article/tech/_percolate -d ' { “doc” : { "title": "iOS 7 released", "content": “iOS 7, the seventh major iteration of the mobile platform, includes more than 200 new features, including a brand new bright and colorful user interface.” } } '
is strictly prohibited percolate a new article { "ok": "true", "matches": ["apple"] } GET /article/tech/_percolate -d ' { “doc” : { "title": "iOS 7 released", "content": “iOS 7, the seventh major iteration of the mobile platform, includes more than 200 new features, including a brand new bright and colorful user interface.” } } '
is strictly prohibited index the enriched article PUT /article/tech/1 -d ' { "title": "iOS 7 released", "content": “iOS 7, the seventh major iteration of the mobile platform, includes more than 200 new features, including a brand new bright and colorful user interface.”, “tag” : “apple” } '
is strictly prohibited How does it work? All queries are loaded in memory Each doc is indexed in memory All queries get executed against it Execution time linear (# of queries) The memory index gets cleaned up
is strictly prohibited How does it work? All queries are loaded in memory Each doc is indexed in memory All queries get executed against it Execution time linear (# of queries) The memory index gets cleaned up
is strictly prohibited How does it work? All queries are loaded in memory Each doc is indexed in memory All queries get executed against it Execution time linear (# of queries) The memory index gets cleaned up
is strictly prohibited How does it work? All queries are loaded in memory Each doc is indexed in memory All queries get executed against it Execution time linear to # of queries The memory index gets cleaned up
is strictly prohibited How does it work? All queries are loaded in memory Each doc is indexed in memory All queries get executed against it Execution time linear to # of queries The memory index gets cleaned up
is strictly prohibited GET /twitter/tweet/_percolate -d ' { “doc” : { "tweet": "#elasticsearch is AWESOME", "nick": "@lucacavanna" }, “query” : { “term” : {“user.nick” : “lucacavanna”} } } ' Drill down restricts the # of queries to run
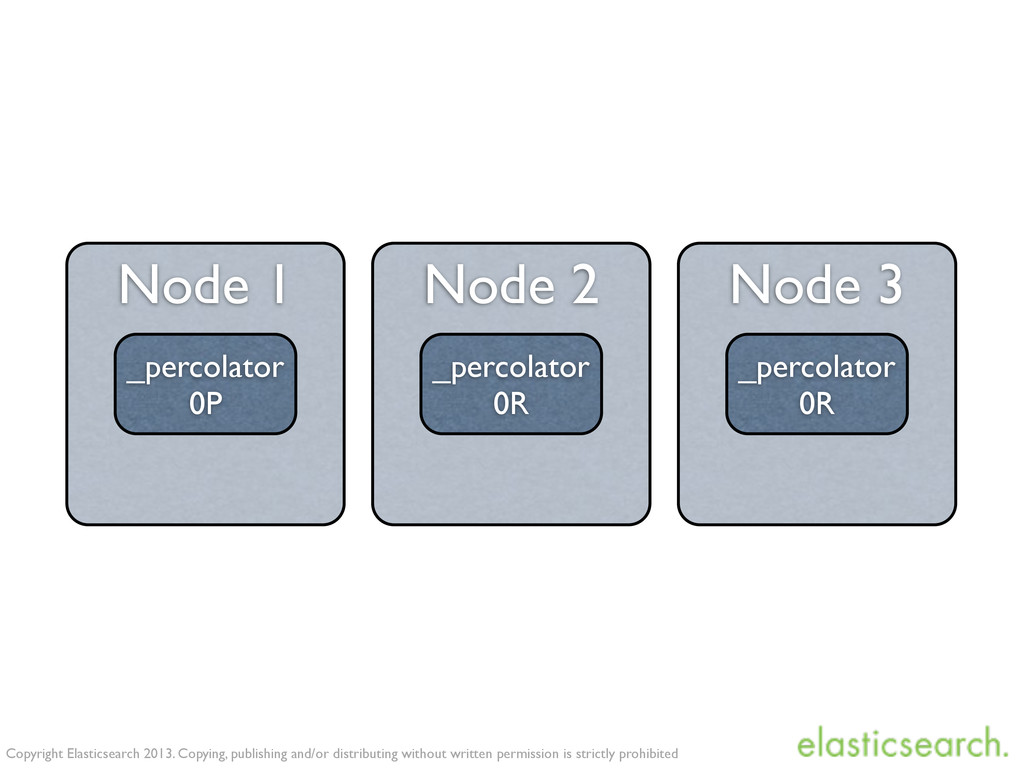
is strictly prohibited Let’s index a query... PUT /anyindex/twitter/es-tweets -d ' { "query": { "match": { "tweet": "elasticsearch" } } } ' any index can contain queries to percolate against
is strictly prohibited Let’s index a query... PUT /anyindex/_percolator/es-tweets -d ' { "query": { "match": { "tweet": "elasticsearch" } } } ' reserved type for queries to percolate against
is strictly prohibited GET /twitter/tweet/1/_percolate Percolate existing doc 1) index that contains the document 2) and the queries (_percolator type)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ "ok": "true", "matches": ["es-tweets"] } Copyright Elasticsearch 2013. Copying,](https://files.speakerdeck.com/presentations/48a42bb00dd90131f03e62baa3f41b0c/slide_23.jpg){kind=link}
![{ "ok": "true", "matches": ["es-tweets"] } Copyright Elasticsearch 2013. Copying,](https://files.speakerdeck.com/presentations/48a42bb00dd90131f03e62baa3f41b0c/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ "ok": "true", "matches": ["summer"] } Copyright Elasticsearch 2013. Copying,](https://files.speakerdeck.com/presentations/48a42bb00dd90131f03e62baa3f41b0c/slide_30.jpg){kind=link}
![{ "ok": "true", "matches": ["summer"] } Copyright Elasticsearch 2013. Copying,](https://files.speakerdeck.com/presentations/48a42bb00dd90131f03e62baa3f41b0c/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ "ok": "true", "matches": [] } Copyright Elasticsearch 2013. Copying,](https://files.speakerdeck.com/presentations/48a42bb00dd90131f03e62baa3f41b0c/slide_44.jpg){kind=link}
{kind=link}
![{ "ok": "true", "matches": ["user1"] } Copyright Elasticsearch 2013. Copying,](https://files.speakerdeck.com/presentations/48a42bb00dd90131f03e62baa3f41b0c/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}