Share
ACL2023 Student Research Workshop Best Paperの紹介。 京大黒橋研D4児玉 貴志 (Takashi KODAMA)さんの論文です。 外部知識を使った発話において、どんな発話が魅力的なのか、現在のシステムはそれができているかを分析する話です。
{kind=link}
{kind=link}
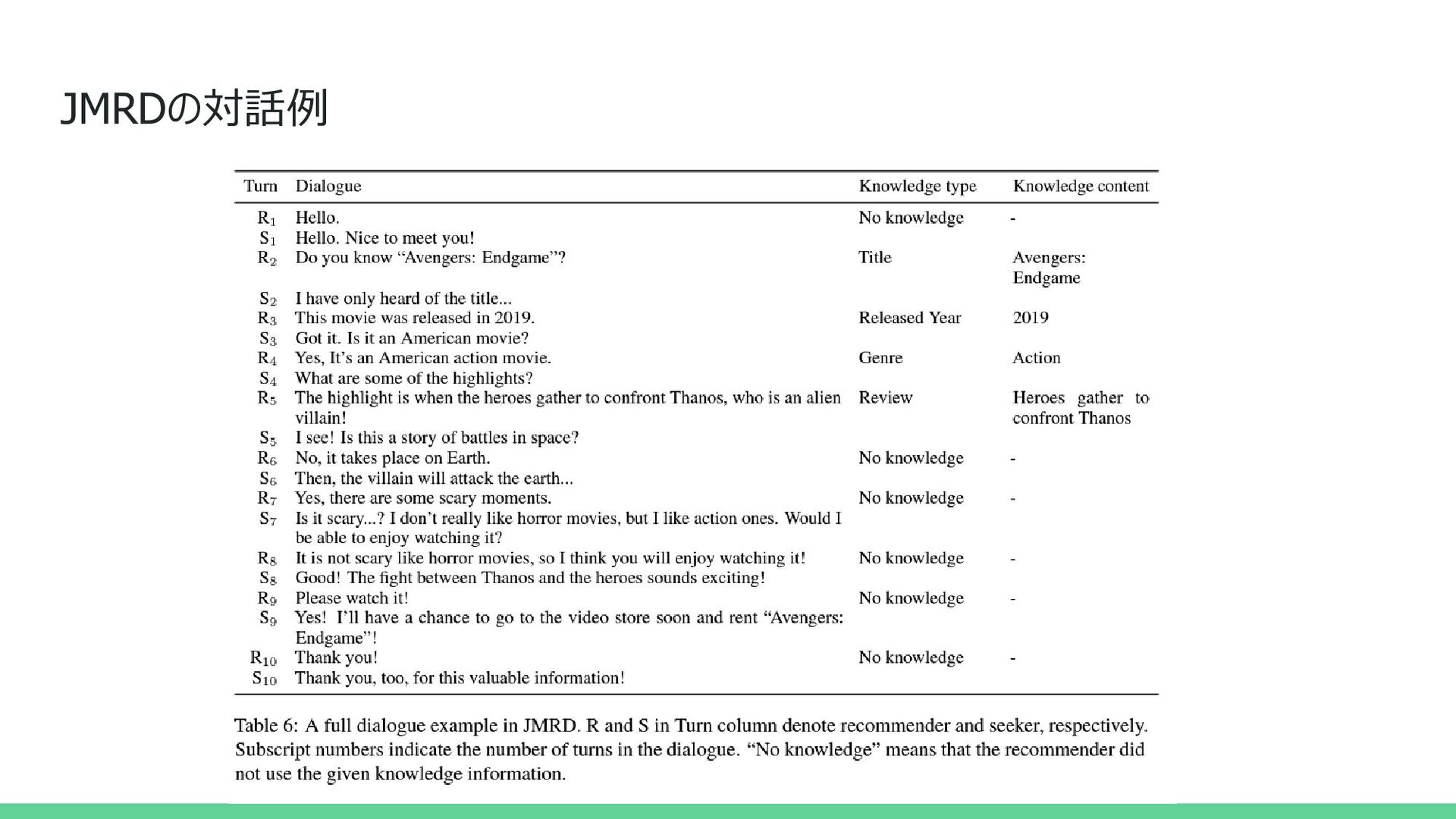
![背景 • 対話型推薦システム(CRS)など多くの研究で外部知識を導入 [Ghazvininejadetal.,2018;Zhouetal.,2018;Mogheetal.,2018; Dinanetal.,2019;Zhaoetal.,2020] ◦ 主な焦点は、いかに適切な外部知識を選択し、それを応答に正確に反映させるか • しかし、話し手は外部知識だけでなく、自分自身の知識、経験、意見 を効果的に取り入れることで、対話をより魅力的](https://files.speakerdeck.com/presentations/b26f96642a39406380829c11749b1111/slide_2.jpg){kind=link}
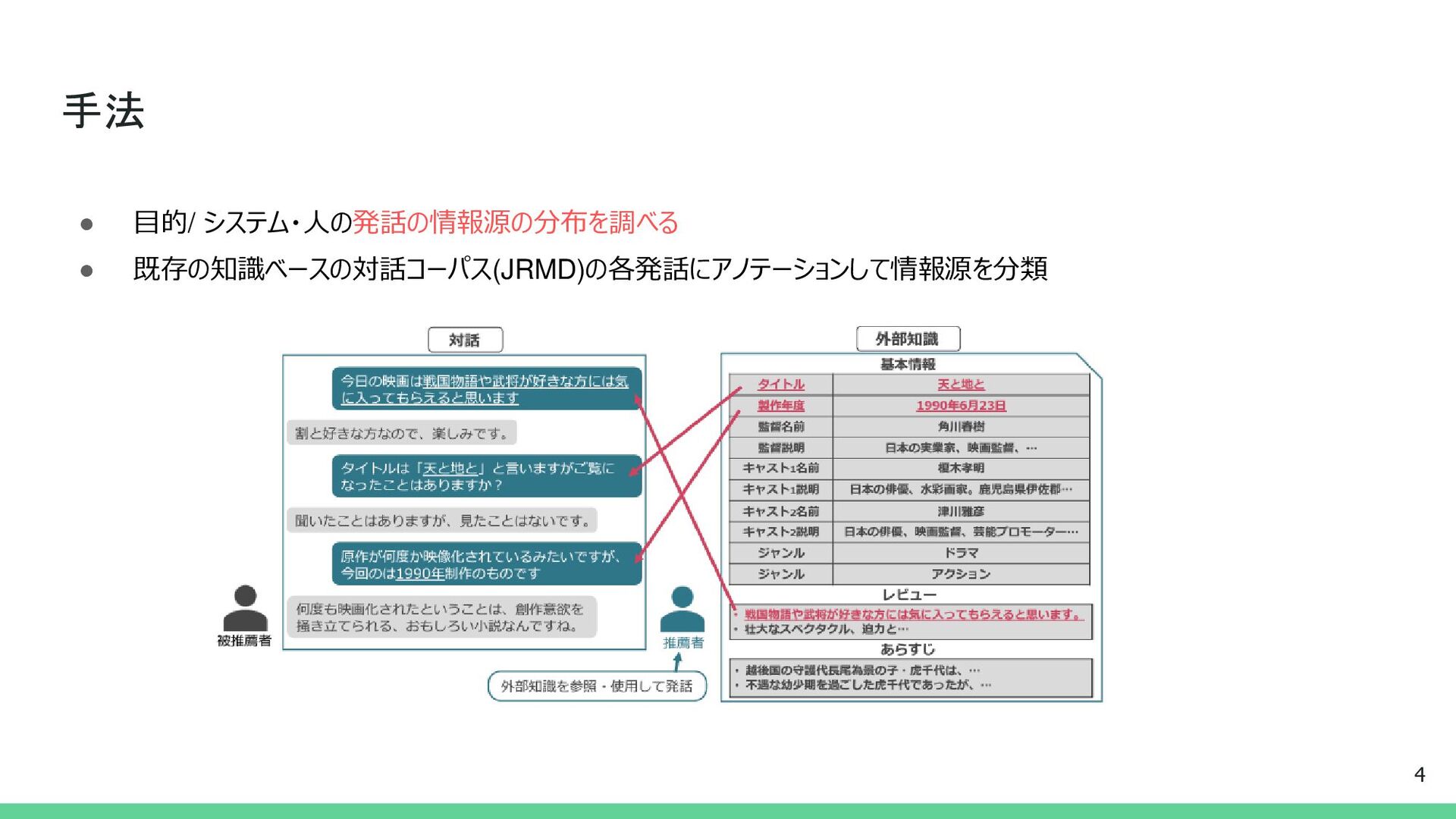{kind=link}
{kind=link}
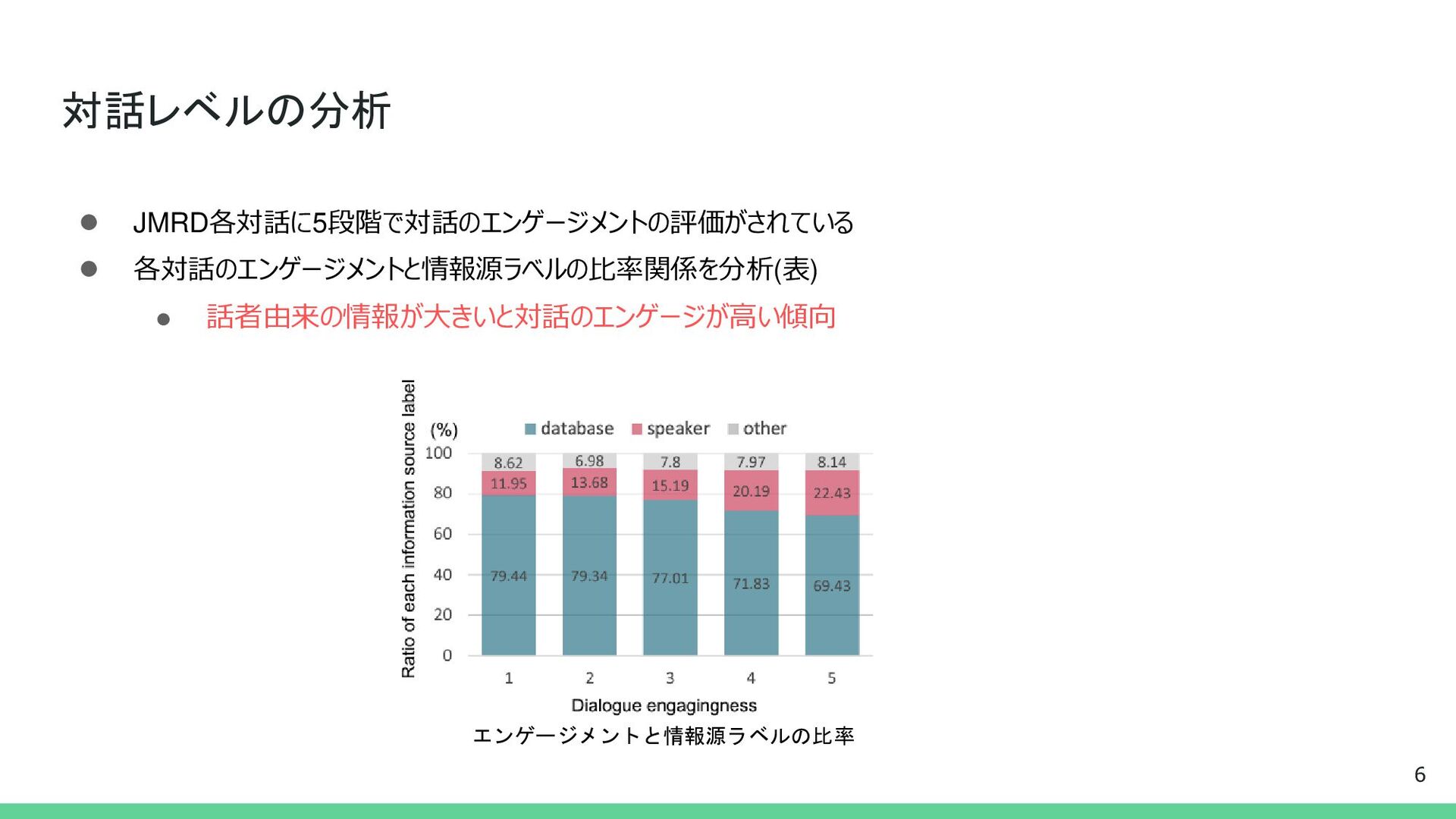{kind=link}
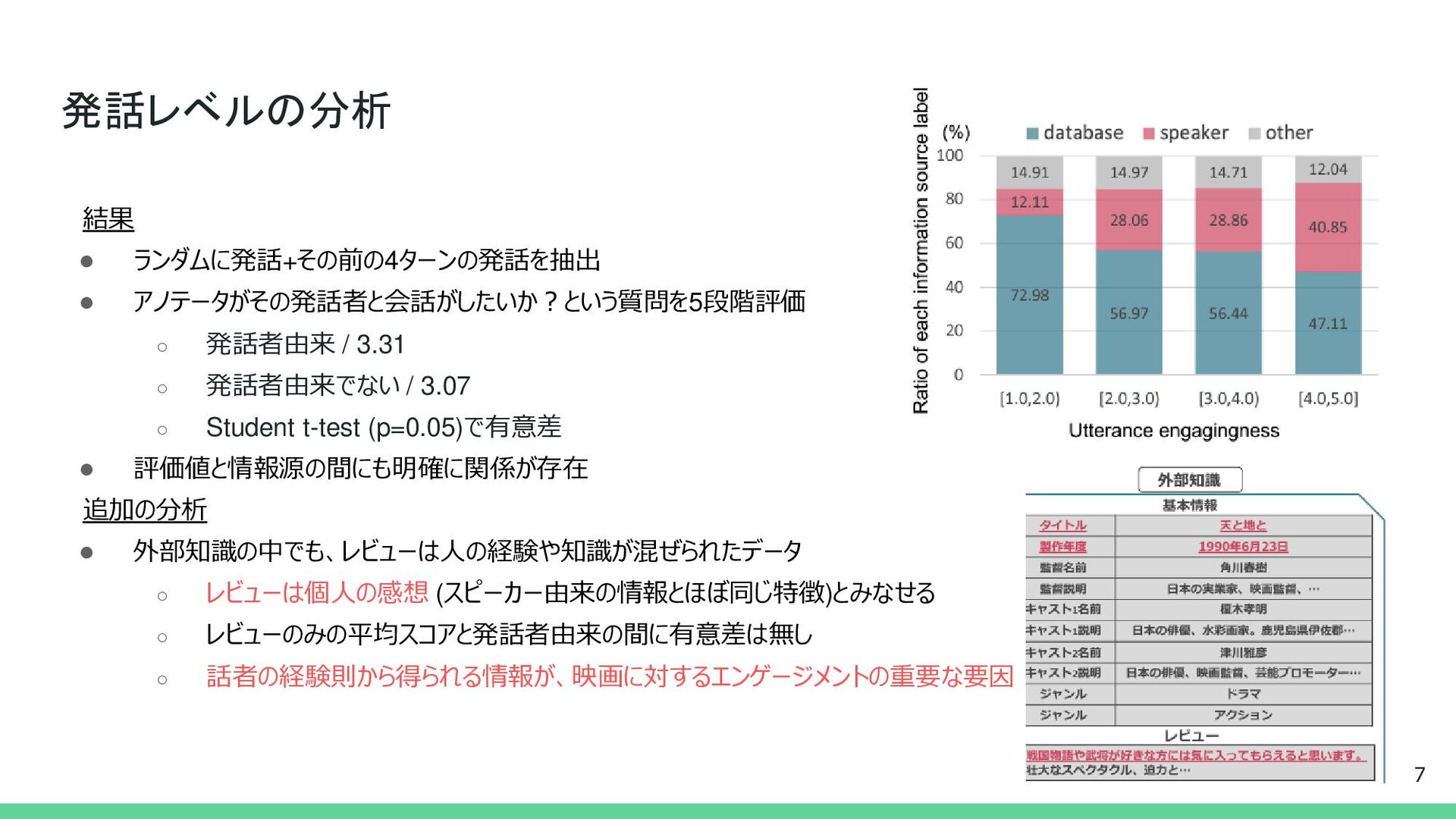{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
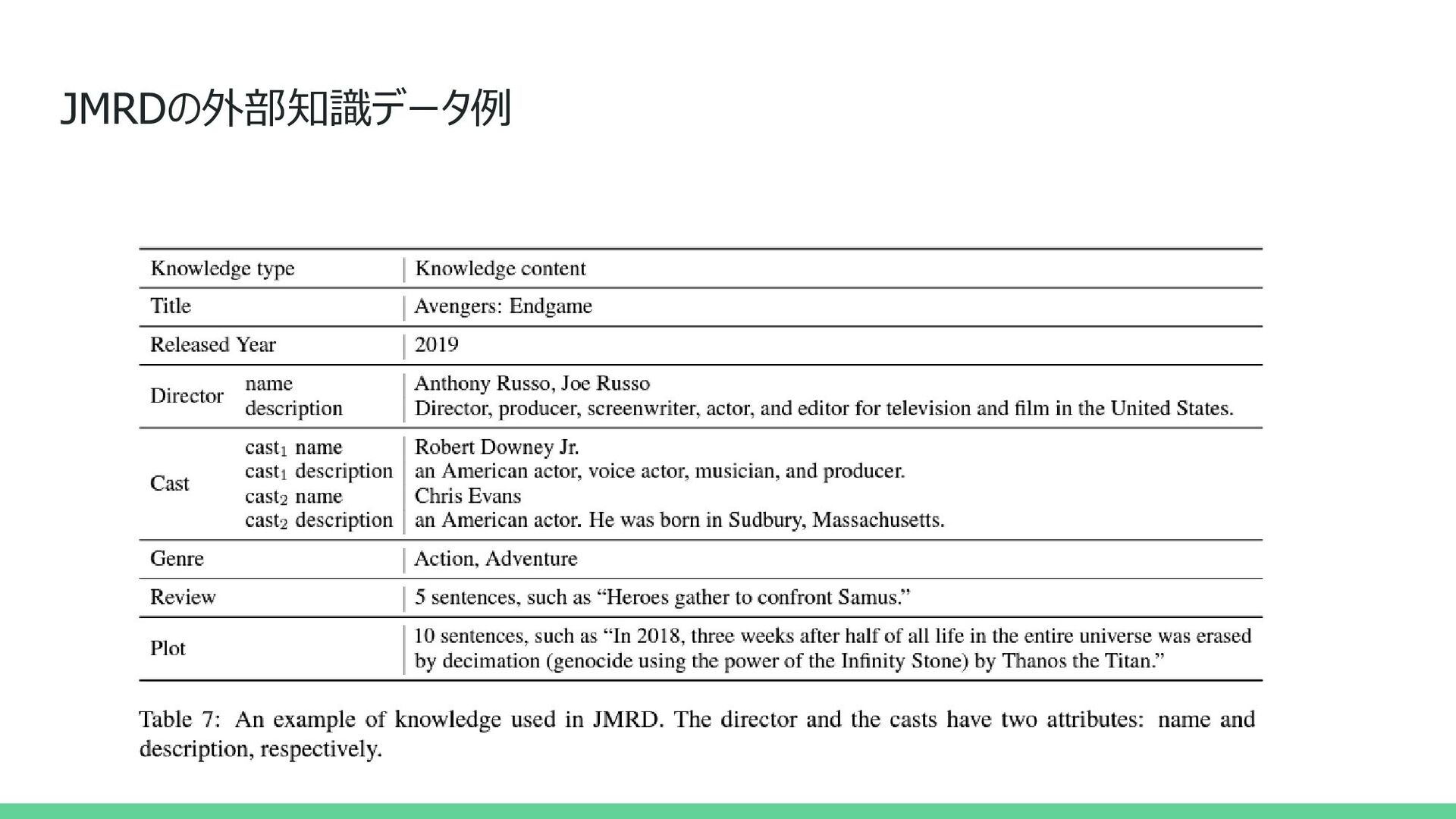{kind=link}
{kind=link}