障害が発生したら全員が当事者になるということを教育する 2. 振り返りのクロージングに責任を持つ a. 全員を集めるからには最大限の効果を得たい b. 振り返りのアクションを放置するのはもったいなさすぎる 3. 何回でも繰り返す a. 新しい社員がどんどん増えてインシデントの記憶が薄れていく b. インシデントの辛さを知る社員の本気度を見て 新入社員が成長していく ダイニーには #remember_20220811 という Slack チャンネルがある
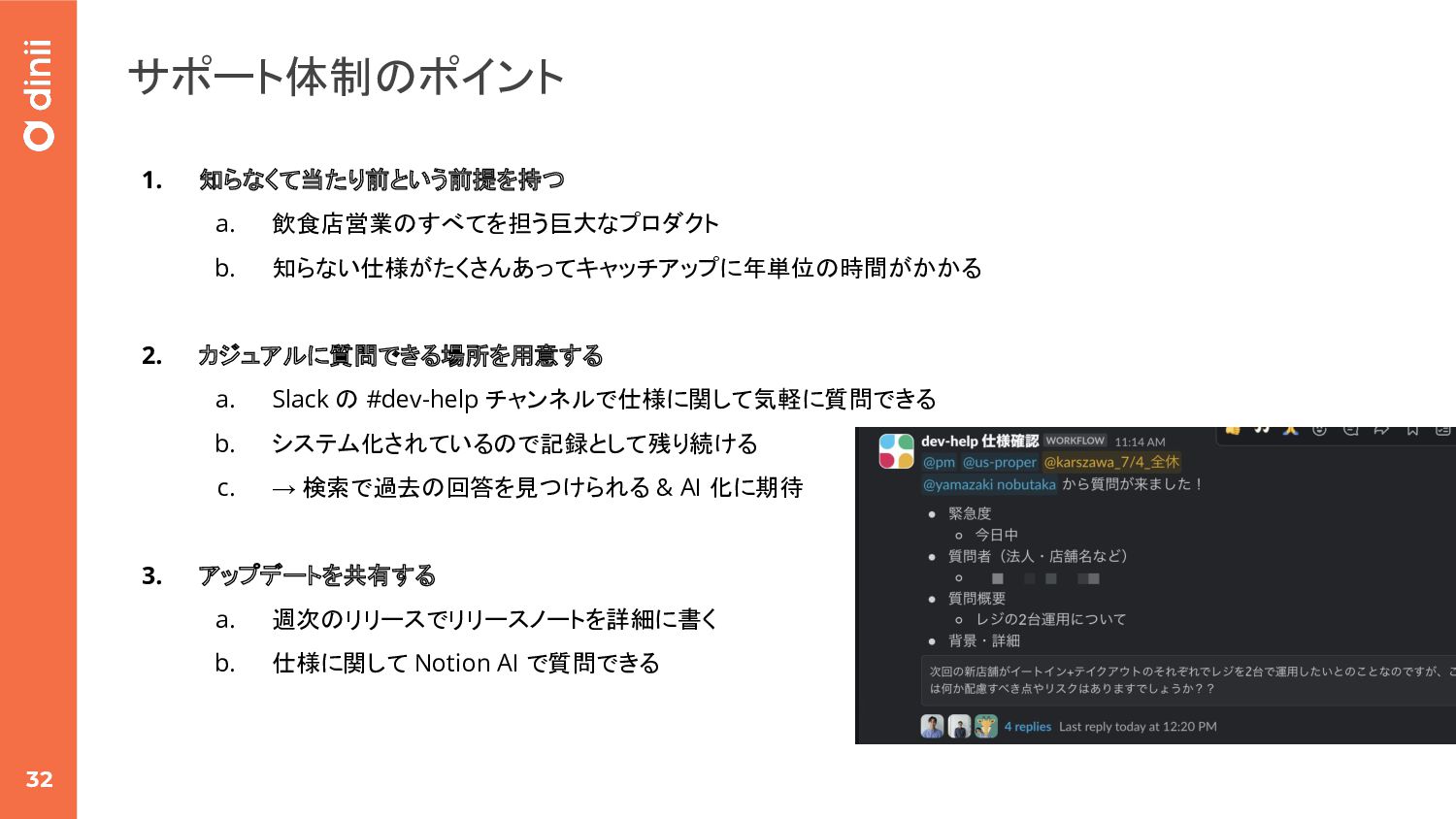
a. Slack の #dev-help チャンネルで仕様に関して気軽に質問できる b. システム化されているので記録として残り続ける c. → 検索で過去の回答を見つけられる & AI 化に期待 3. アップデートを共有する a. 週次のリリースでリリースノートを詳細に書く b. 仕様に関して Notion AI で質問できる
{kind=link}
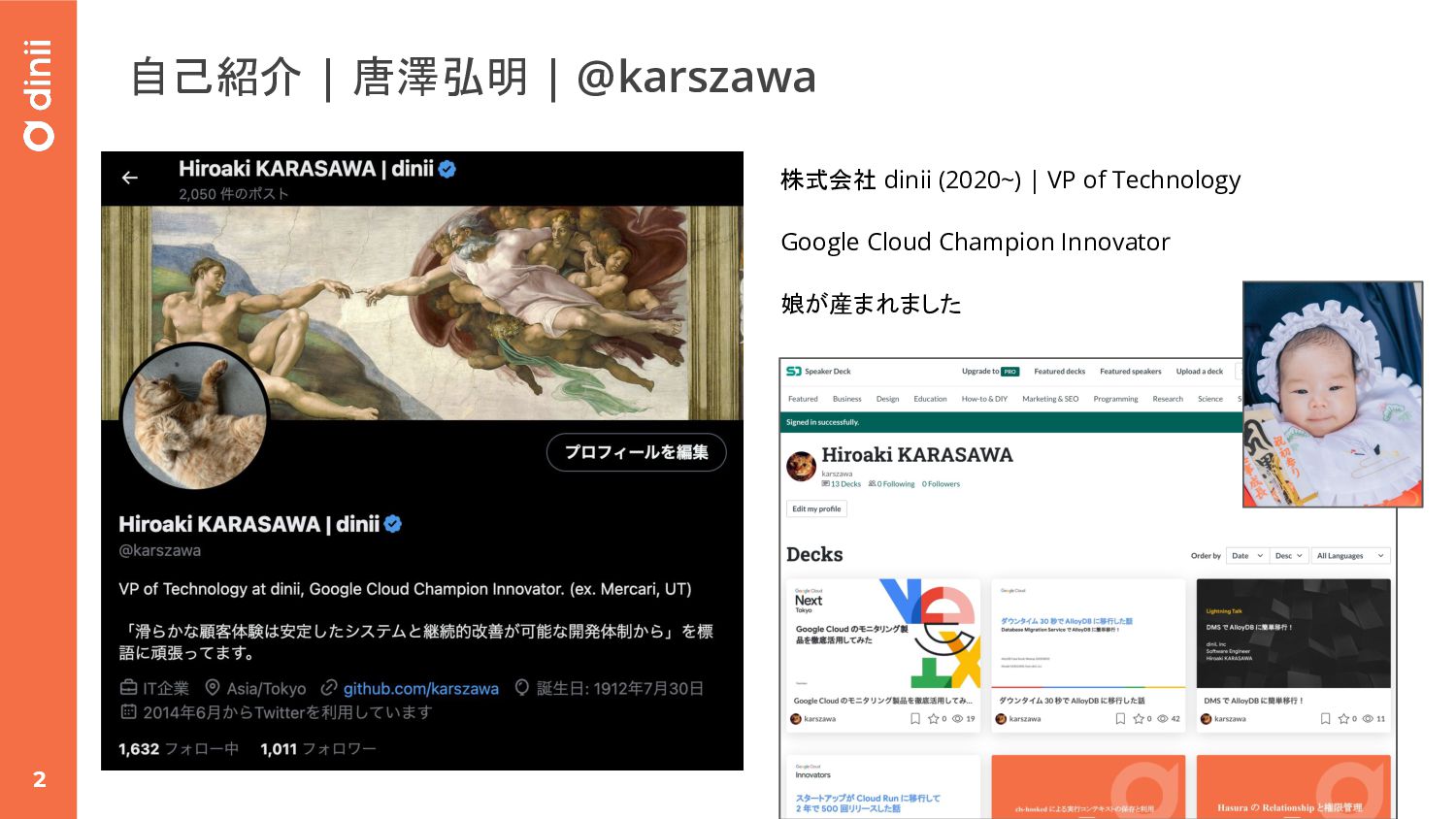{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}