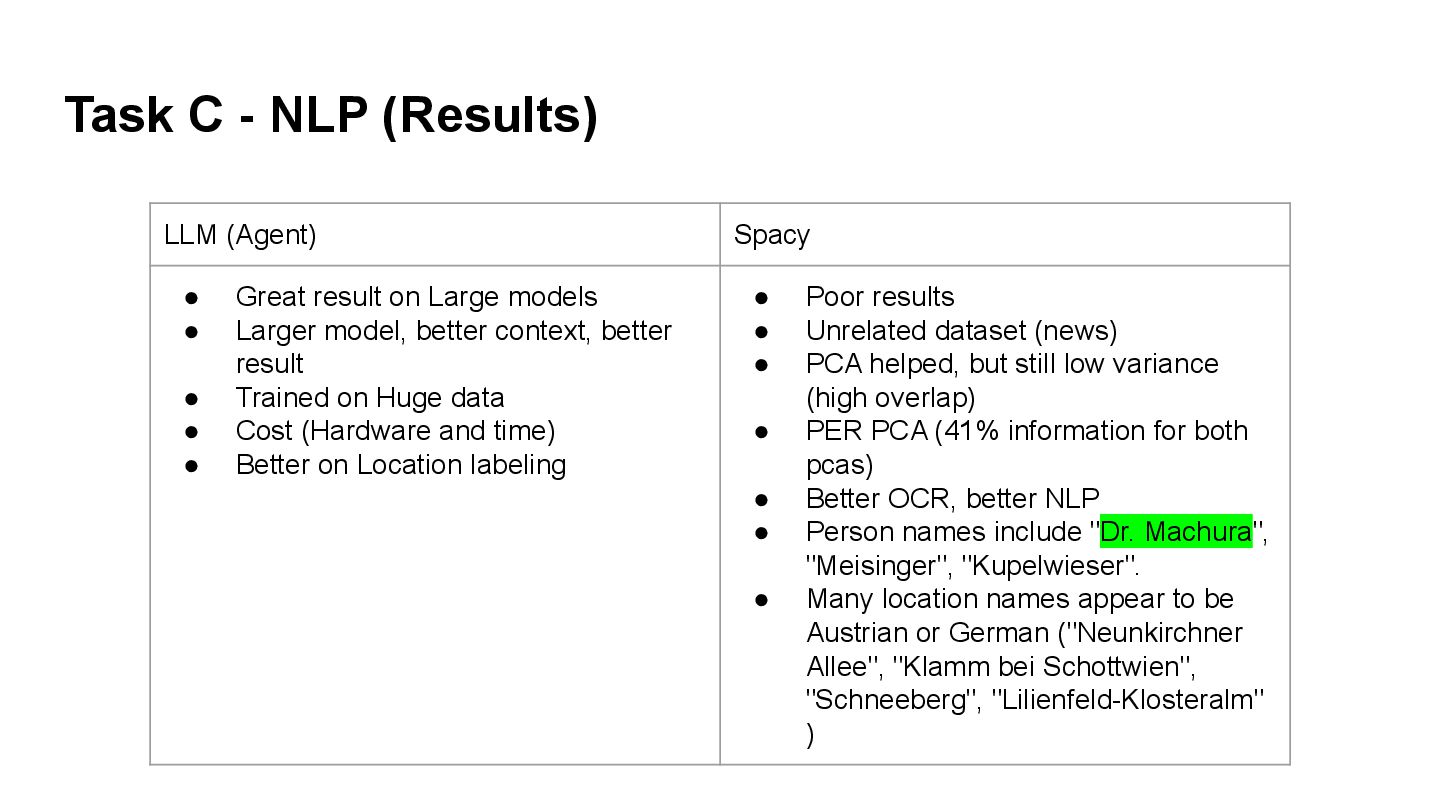
gemma-3-4b-it (Local Inference) you are an NER model, your task is to find following information on a german text: Location, Description, Date, Photographer, Film return the result as a JSON, use the following format: { "Location": "Helenental", "Description": "unerlaubte Rodung im Schutzgebiet", "Date": "April 1948", "Photographer": "Meisinger", "Film": "Neg.Nr. 3254/KIX/16, Film", } I will send text, are you ready? you are an NER model, your task is to find following information on a german text: Location, Description, Date, Photographer, Film return the result as a JSON, use the following format: { "Location": "Helenental", "Description": "unerlaubte Rodung im Schutzgebiet", "Date": "April 1948", "Photographer": "Meisinger", "Film": "Neg.Nr. 3254/KIX/16, Film", } I will send text, are you ready? can you act as NER and find information about this keys in the following text, the language of the text id german: 1. Location 2. Description 3. Date 4. Photographer 5. Film text: Regelsorunner Au.S.A.A. Aufn. Dr. Machura 1948 Film Nr. 19, Neg, Nr. 21. u. 22. your output should be a json like this: { "Location": "", "Description": "", "Date": "", "Photographer": "", "Film": "", } { "Location": "Neunkirchner Allee", "Description": "", "Date": "1948", "Photographer": "Dr. Machura", "Film": "Film Nr. 17, Neg. 17 /" } { "Location": "Neunkirchner Allee", "Description": "", "Date": "1948", "Photographer": "Dr. Machura", "Film": "Film Nr. 17, Neg. 17" } { "Location": "Aufn. Dr. Machura", "Description": "Regelsorunner Au.S.A.A.", "Date": "1948", "Photographer": null, "Film": "Film Nr. 19, Neg, Nr. 21. u. 22." }
{kind=link}
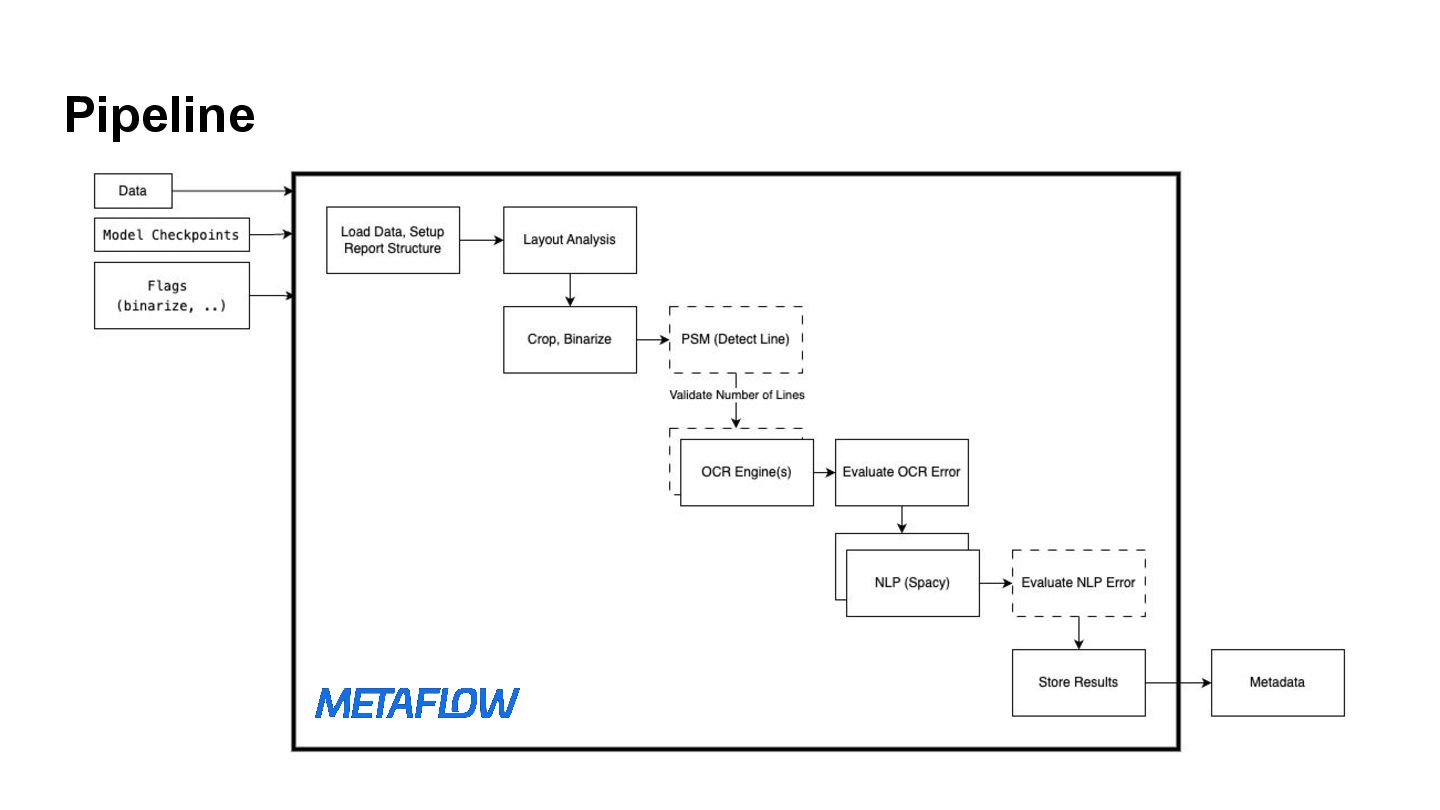{kind=link}
{kind=link}
{kind=link}
{kind=link}
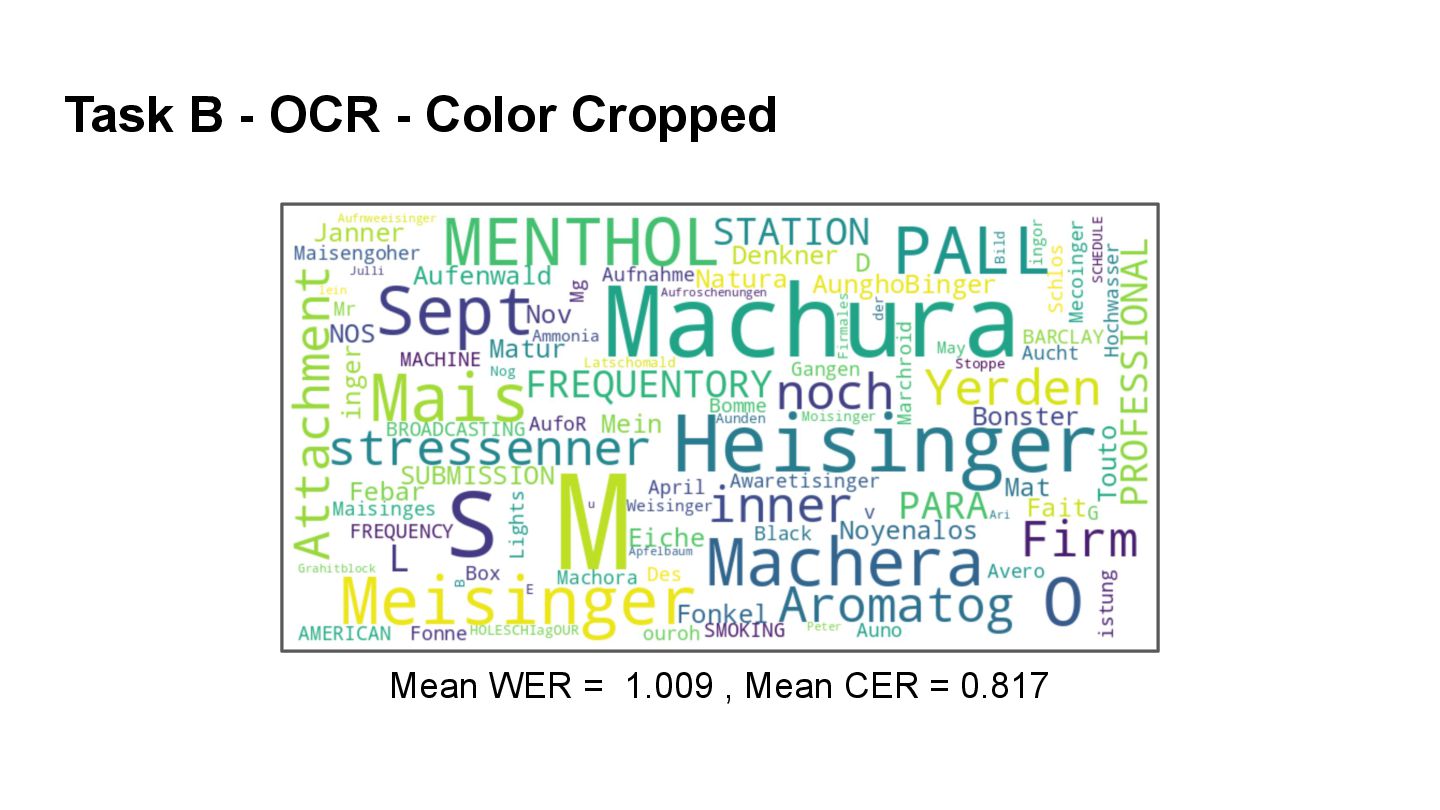{kind=link}
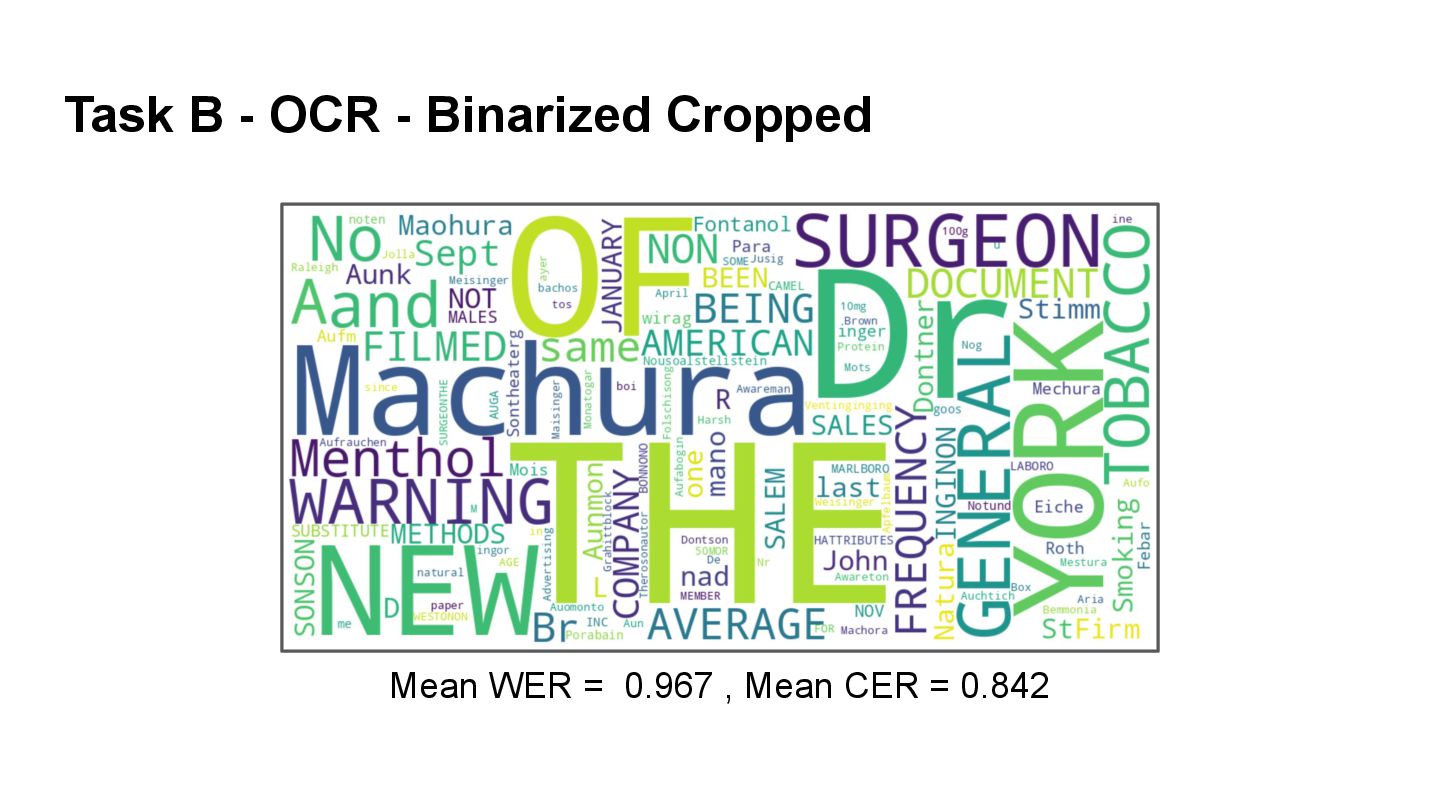{kind=link}
{kind=link}
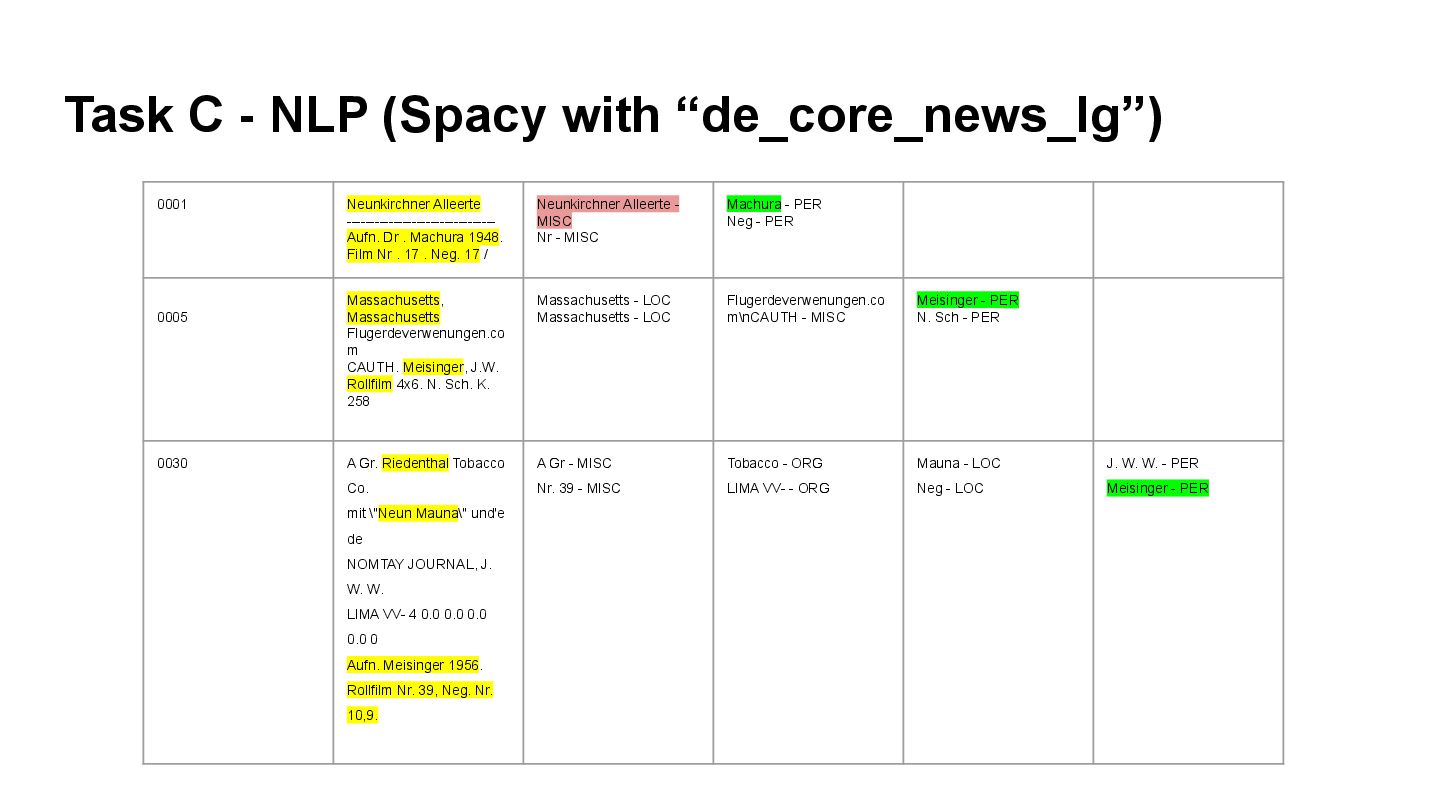{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}