Encoding: 系列内のトークンの相対的/絶対的な位置情報を与える。 sin関数とcos関数を用いた固定的な値を、入力Embeddingに加算。 Residual Connection & Layer Normalization: 各サブレイヤー (Attention, FFN) の後に追加。勾配伝播を助け、学習を安定化。 Attention Is All You Need 論文解説 7
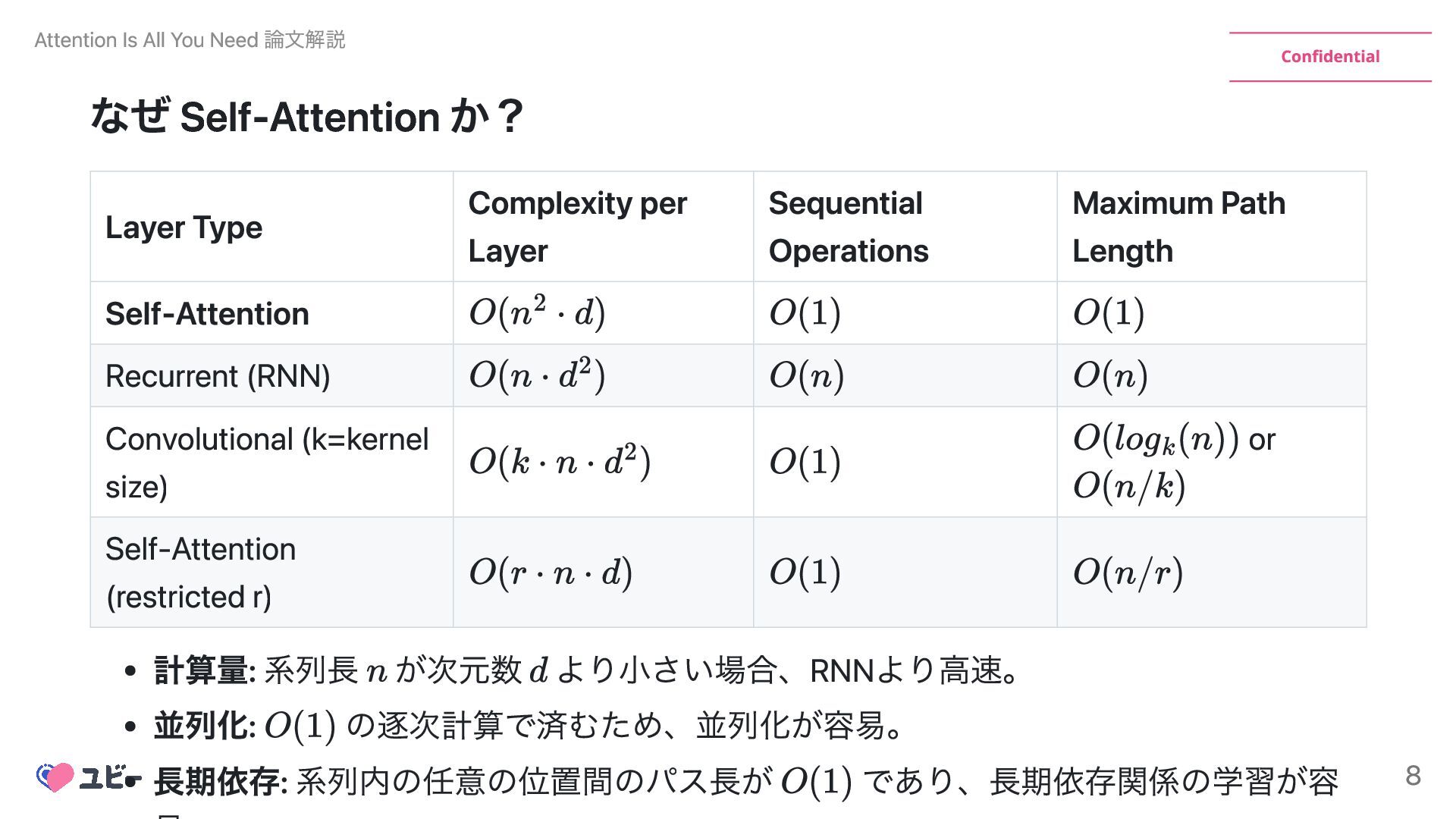
Maximum Path Length Self-Attention Recurrent (RNN) Convolutional (k=kernel size) or Self-Attention (restricted r) 計算量: 系列長 が次元数 より小さい場合、RNNより高速。 並列化: の逐次計算で済むため、並列化が容易。 長期依存: 系列内の任意の位置間のパス長が であり、長期依存関係の学習が容 Attention Is All You Need 論文解説 8
Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems 30 (NIPS 2017). (https://arxiv.org/abs/1706.03762) Attention Is All You Need 論文解説 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}