Philip H.S. Torr, Vladlen Koltun. Point Transformer. ICCV2021. • [Point Transformer V2] Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, Hengshuang Zhao. Point Transformer V2: Grouped Vector Attention and Partition-based Pooling. NeurIPS2022. • [Point Transformer V3] Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, Hengshuang Zhao. Point Transformer V3: Simpler, Faster, Stronger. CVPR2024. • [PointMLP] Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, Yun Fu. Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework. ICLR2022. • [PointNeXt] Guocheng Qian, Yuchen Li, Houwen Peng, Jinjie Mai, Hasan Hammoud, Mohamed Elhoseiny, Bernard Ghanem. PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies. NeurIPS2022. • [PCT] Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R. Martin, Shi-Min Hu. PCT: Point cloud transformer. Computational Visual Media(2021). • [Stratified Transformer] Xin Lai, Jianhui Liu, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, Jiaya Jia. Stratified Transformer for 3D Point Cloud Segmentation. CVPR2022. • [Swin3D] Yu-Qi Yang, Yu-Xiao Guo, Jian-Yu Xiong, Yang Liu, Hao Pan, Peng-Shuai Wang, Xin Tong, Baining Guo. Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding. arXiv:2304.06906. • [SPoTr] Jinyoung Park, Sanghyeok Lee, Sihyeon Kim, Yunyang Xiong, Hyunwoo J. Kim. Self-Positioning Point-Based Transformer for Point Cloud Understanding. CVPR2023. • [OctFormer] Peng-Shuai Wang. OctFormer: Octree-based Transformers for 3D Point Clouds. SIGGRAPH2023. • [OA-CNN] Bohao Peng, Xiaoyang Wu, Li Jiang, Yukang Chen, Hengshuang Zhao, Zhuotao Tian, Jiaya Jia. OA-CNNs: Omni-Adaptive Sparse CNNs for 3D Semantic Segmentation. CVPR2024. • [PointContrast] Saining Xie, Jiatao Gu, Demi Guo, Charles R. Qi, Leonidas J. Guibas, Or Litany. PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding. ECCV2020. • [OcCo] Hanchen Wang, Qi Liu, Xiangyu Yue, Joan Lasenby, Matthew J. Kusner. Unsupervised Point Cloud Pre-Training via Occlusion Completion. ICCV2021. • [Mix3D] Alexey Nekrasov, Jonas Schult, Or Litany, Bastian Leibe, Francis Engelmann. Mix3D: Out-of-Context Data Augmentation for 3D Scenes. 3DV2021. • [CSC] Ji Hou, Benjamin Graham, Matthias Nießner, Saining Xie. Exploring Data-Efficient 3D Scene Understanding with Contrastive Scene Contexts. CVPR2021. • [Point-BERT] Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, Jiwen Lu. Point-BERT: Pre-Training 3D Point Cloud Transformers With Masked Point Modeling. CVPR2022. • [Point-MAE] Yatian Pang, Wenxiao Wang, Francis E.H. Tay, Wei Liu, Yonghong Tian, Li Yuan. Masked Autoencoders for Point Cloud Self-supervised Learning. ECCV2022. • [Point-M2AE] Renrui Zhang, Ziyu Guo, Peng Gao, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, Hongsheng Li. Point-M2AE: Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training. NeurIPS2022. • [MSC] Xiaoyang Wu, Xin Wen, Xihui Liu, Hengshuang Zhao. Masked Scene Contrast: A Scalable Framework for Unsupervised 3D Representation Learning. CVPR2023. • [ReCon] Zekun Qi, Runpei Dong, Guofan Fan, Zheng Ge, Xiangyu Zhang, Kaisheng Ma and Li Yi. Contrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining. ICML2023. • [IAE] Siming Yan, Zhenpei Yang, Haoxiang Li, Chen Song, Li Guan, Hao Kang, Gang Hua, Qixing Huang. Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning. ICCV2023. • [Point-FEMAE] Yaohua Zha, Huizhen Ji, Jinmin Li, Rongsheng Li, Tao Dai, Bin Chen, Zhi Wang, Shu-Tao Xia. Towards Compact 3D Representations via Point Feature Enhancement Masked Autoencoders. AAAI2024. • [PointGPT] Guangyan Chen, Meiling Wang, Yi Yang, Kai Yu, Li Yuan, Yufeng Yue. PointGPT: Auto-regressively Generative Pre-training from Point Clouds. NeurIPS2024. • [PPT] Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, Hengshuang Zhao. Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training. CVPR2024. • [Sonata] Xiaoyang Wu, Daniel DeTone, Duncan Frost, Tianwei Shen, Chris Xie, Nan Yang, Jakob Engel, Richard Newcombe, Hengshuang Zhao, Julian Straub. Sonata: Self-Supervised Learning of Reliable Point Representations. CVPR2025. • [IDPT] Yaohua Zha, Jinpeng Wang, Tao Dai, Bin Chen, Zhi Wang, Shu-Tao Xia. Instance-aware Dynamic Prompt Tuning for Pre-trained Point Cloud Models. ICCV2023. • [Point-PEFT] Yiwen Tang, Ray Zhang, Zoey Guo, Dong Wang, Zhigang Wang, Bin Zhao, Xuelong Li. Point-PEFT: Parameter-Efficient Fine-Tuning for 3D Pre-trained Models. AAAI2024. • [DAPT] Xin Zhou, Dingkang Liang, Wei Xu, Xingkui Zhu, Yihan Xu, Zhikang Zou, Xiang Bai. Dynamic Adapter Meets Prompt Tuning: Parameter-Efficient Transfer Learning for Point Cloud Analysis. CVPR2024. • [PointGST] Dingkang Liang, Tianrui Feng, Xin Zhou, Yumeng Zhang, Zhikang Zou, Xiang Bai. Parameter-Efficient Fine-Tuning in Spectral Domain for Point Cloud Learning. arXiv:2410.08114. • [LION] Zhe Liu, Jinghua Hou, Xinyu Wang, Xiaoqing Ye, Jingdong Wang, Hengshuang Zhao, Xiang Bai. LION: Linear Group RNN for 3D Object Detection in Point Clouds. NeurIPS2024. • [PointMamba] Dingkang Liang, Xin Zhou, Wei Xu, Xingkui Zhu, Zhikang Zou, Xiaoqing Ye, Xiao Tan, Xiang Bai. A Simple State Space Model for Point Cloud Analysis. NeurIPS2024. • [PoinTramba] Zicheng Wang, Zhenghao Chen, Yiming Wu, Zhen Zhao, Luping Zhou, Dong Xu. PoinTramba: A Hybrid Transformer-Mamba Framework for Point Cloud Analysis. arXiv:2405.15463. • [Mamba3D] Xu Han, Yuan Tang, Zhaoxuan Wang, Xianzhi Li. Mamba3D: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model. ACMMM2024. • [PointABM] Jia-wei Chen, Yu-jie Xiong, Yong-bin Gao. PointABM: Integrating Bidirectional State Space Model with Multi-Head Self-Attention for Point Cloud Analysis. International Conference on Intelligent Technology and Embedded Systems (ICITES) 2024. • [PCM] Tao Zhang, Haobo Yuan, Lu Qi, Jiangning Zhang, Qianyu Zhou, Shunping Ji, Shuicheng Yan, Xiangtai Li. Point Cloud Mamba: Point Cloud Learning via State Space Model. AAAI2025. • [SI-Mamba] Ali Bahri, Moslem Yazdanpanah, Mehrdad Noori, Sahar Dastani, Milad Cheraghalikhani, Gustavo Adolfo Vargas Hakim, David Osowiechi, Farzad Beizaee, Ismail Ben Ayed, Christian Desrosiers. Spectral Informed Mamba for Robust Point Cloud Processing. CVPR2025. • [StruMamba3D] Chuxin ang, Yixin Zha, Wenfei Yang, Tianzhu Zhang. StruMam3D: Exploring Structural Mamba for Self-supervised Point Cloud Representation Learning. ICCV2025. 154
{kind=link}
{kind=link}
{kind=link}
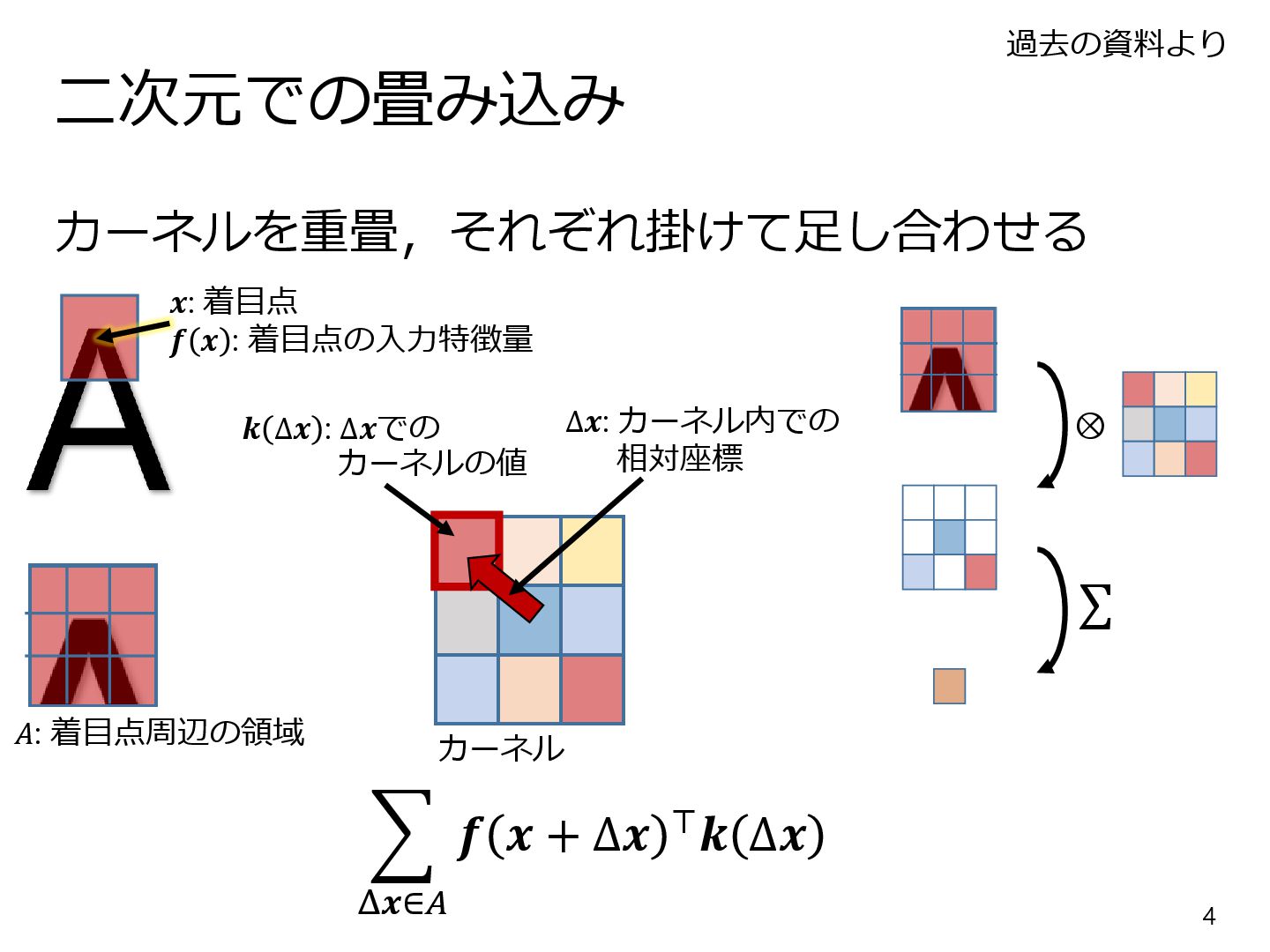{kind=link}
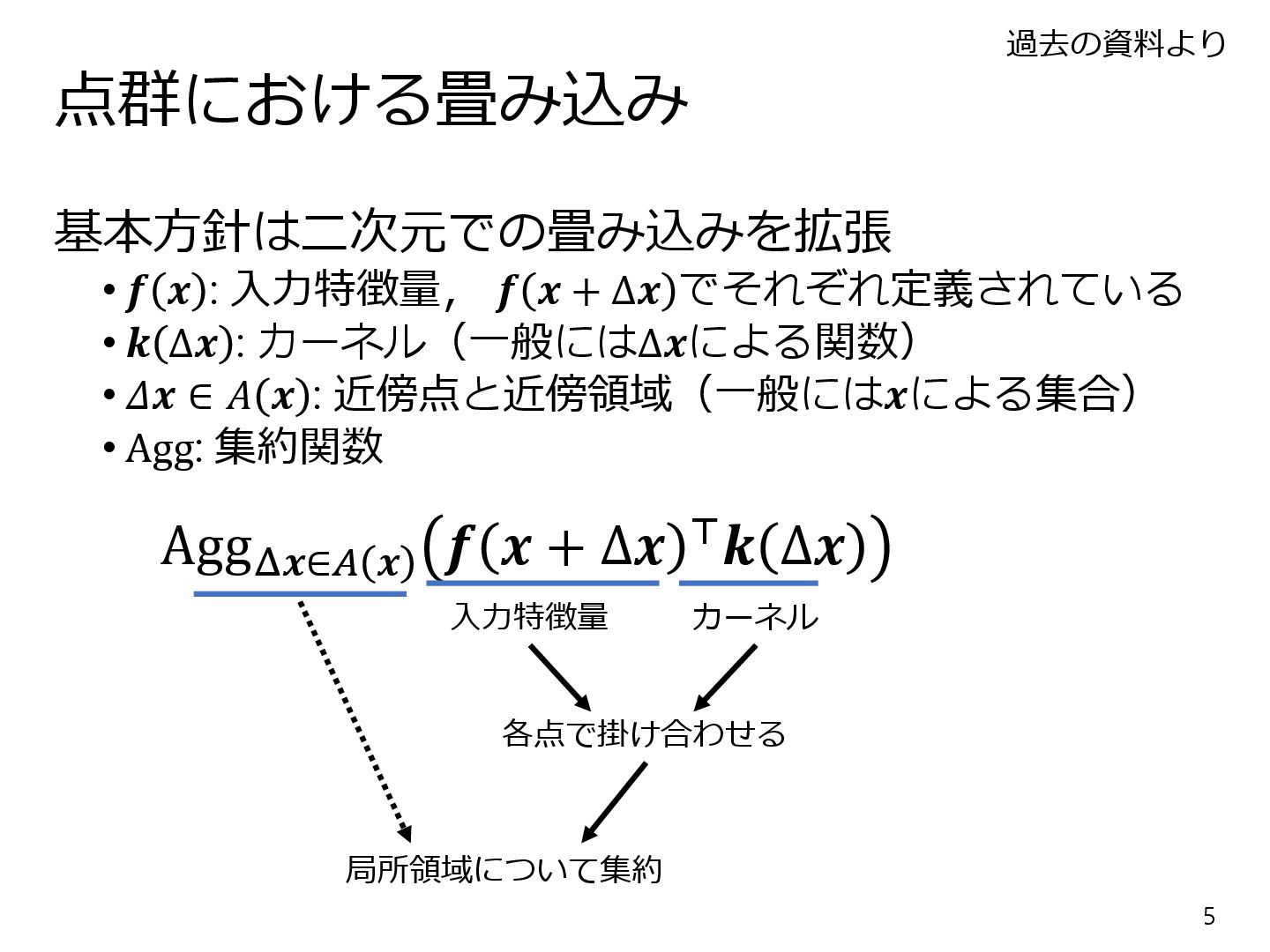{kind=link}
{kind=link}
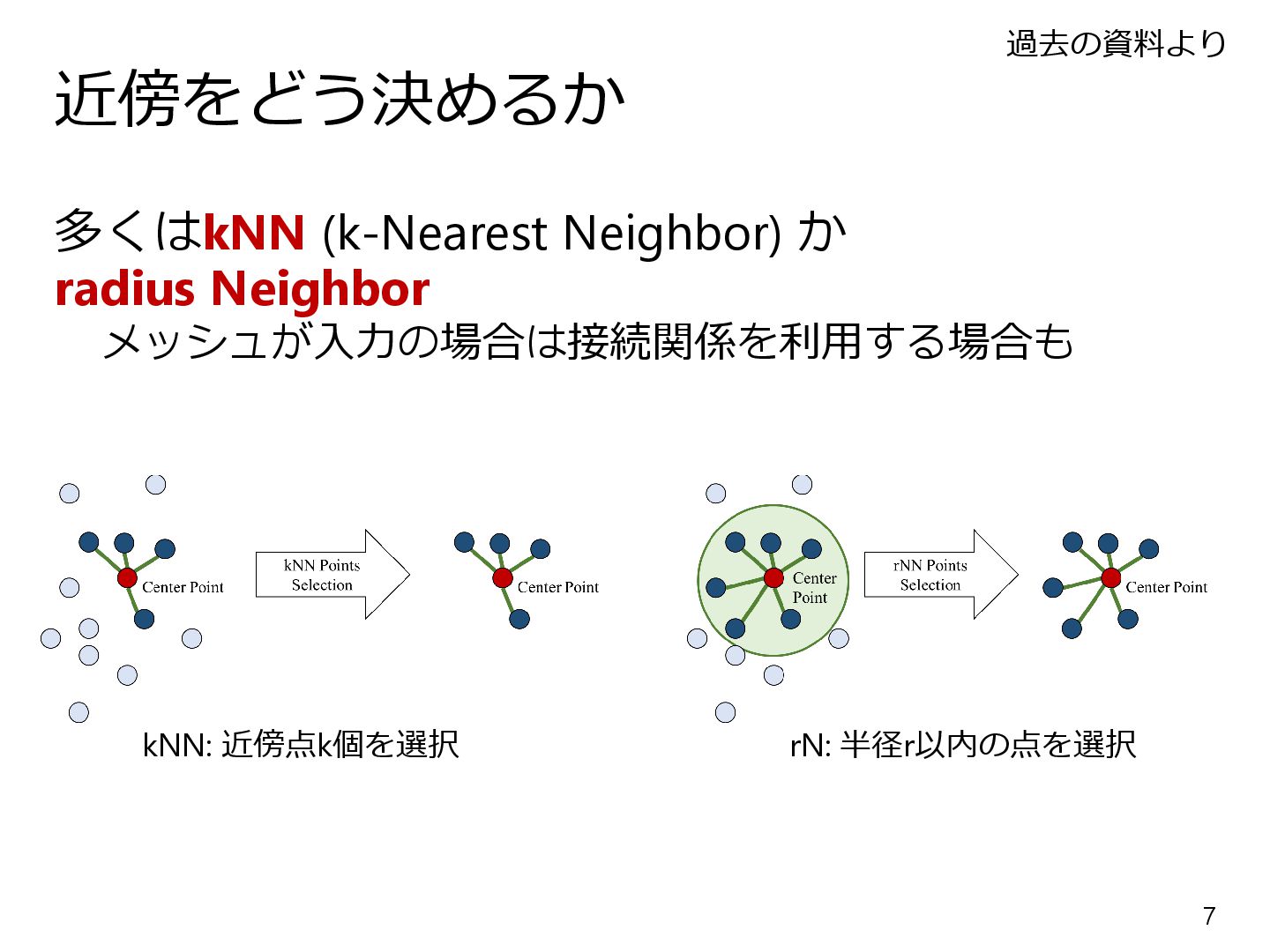{kind=link}
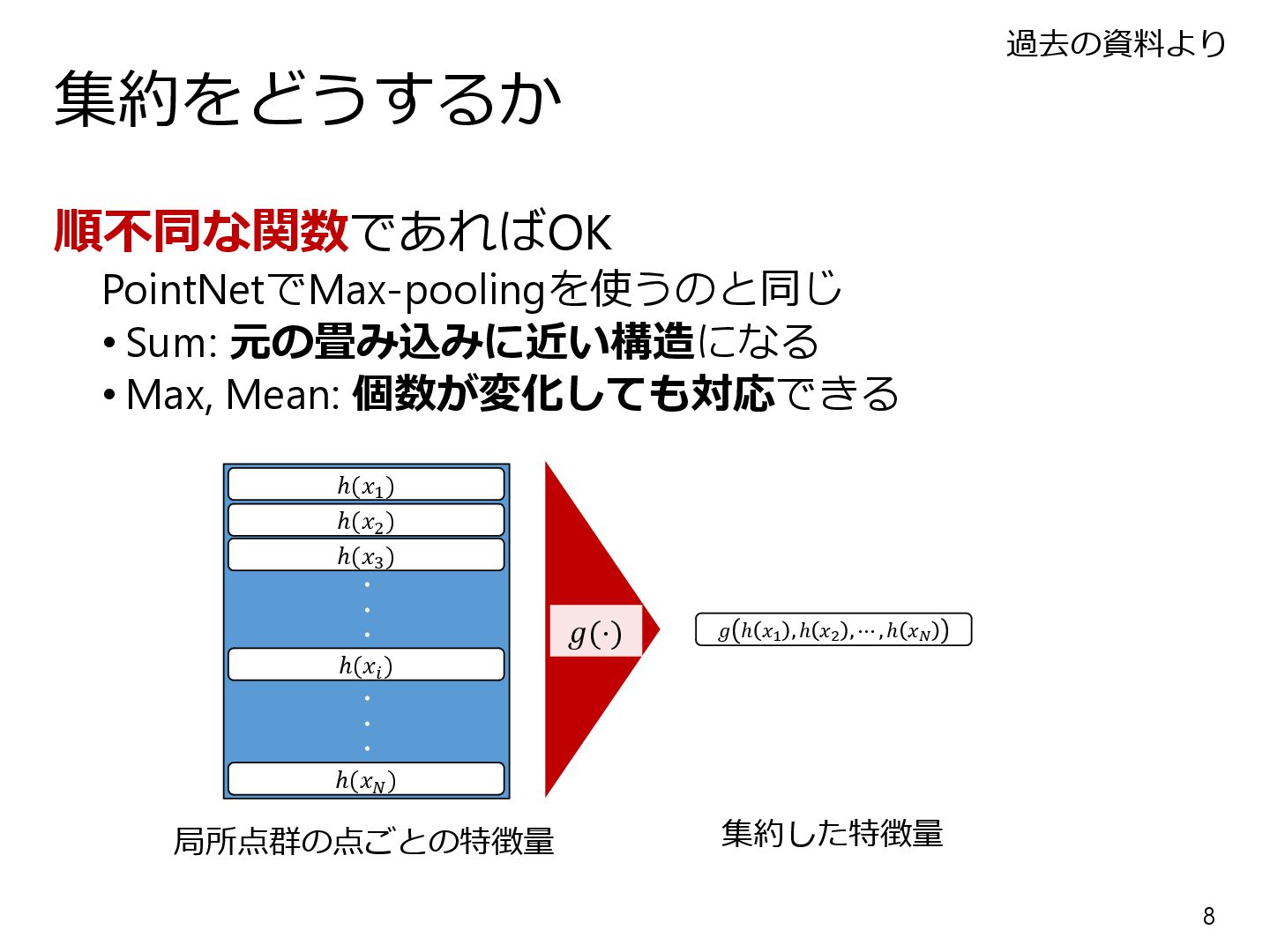{kind=link}
{kind=link}
{kind=link}
![Point Transformer [H. Zhao+, ICCV2021] 点群をTransformerで処理する初期の論文 Transformerを導入する枠組み • kNNグラフ上でAttention •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_10.jpg){kind=link}
![Point Transformer [H. Zhao+, ICCV2021] Vector (Self-)Attention • 同著者がCVPR2020で提案 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_11.jpg){kind=link}
![Point Transformer [H. Zhao+, ICCV2021] ネットワーク構造 Transformerを挿入したU-Net構造 13](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_12.jpg){kind=link}
![Point Transformer [H. Zhao+, ICCV2021] kNNが遅い • ヒープソートで高速化し一応の解決 • 近傍点数kの選び方が性能に重要であることも示唆](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_13.jpg){kind=link}
![Point Transformer V2 [X. Wu+, NeurIPS2022] PTv1の限界 • FPS +](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_14.jpg){kind=link}
![Point Transformer V2 [X. Wu+, NeurIPS2022] Grouped Vector Attention (GVA)](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_15.jpg){kind=link}
![Point Transformer V2 [X. Wu+, NeurIPS2022] ネットワーク構造はあまり変化なし Grid PoolingとGVA Blockに置き換え](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_16.jpg){kind=link}
![Point Transformer V3 [X. Wu+, CVPR2024] PTv2からさらに省メモリ・高速に 少数データでも高性能 データセットを跨いで事前学習できる Point](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_17.jpg){kind=link}
![Point Transformer V3 [X. Wu+, CVPR2024] ストーリー • 点群Transformerでは,近傍を計算させる kNNやRelative](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_18.jpg){kind=link}
![Point Transformer V3 [X. Wu+, CVPR2024] Serialization-based method • Z-orderやHilbert曲線による](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_19.jpg){kind=link}
![Point Transformer V3 [X. Wu+, CVPR2024] 空間充足曲線の例 複数組み合わせて, シャッフルして使うと 性能向上](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_20.jpg){kind=link}
![Point Transformer V3 [X. Wu+, CVPR2024] Positional Encodingの工夫:xCPE • ペアワイズの距離を計算するRPEは計算コストが高い](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_21.jpg){kind=link}
![Point Transformer V3 [X. Wu+, CVPR2024] ネットワークアーキテクチャ FPSがなくなり,PTv2よりもシンプルに 23](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
![PointMLP [X. Ma+, ICLR2022] 精度・推論/学習速度ともに 優れた点群Backbone • 局所点群をアフィン変換する 軽量なモジュール •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_25.jpg){kind=link}
![PointNeXt [G. Qian+, NeurIPS2022] PointNet++の正統進化 単に深くしても性能向上しないことを指摘 高速で高精度,モデルサイズでバランス調整可能 主な工夫 • 訓練戦略](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_26.jpg){kind=link}
![PointNeXt [G. Qian+, NeurIPS2022] アーキテクチャの改善 • クエリする半径の拡大 • 相対座標の正規化 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_27.jpg){kind=link}
![PCT [M.-H. Guo+, CVA, 2021] Transformerを点群に利用した初期の論文 FPS + kNNでパッチ化,近傍に対してAttention Offset](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_28.jpg){kind=link}
![PCT [M.-H. Guo+, CVA, 2021] FPS + kNNでパッチ化,近傍に対してAttention Offset Attention](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_29.jpg){kind=link}
![PCT [M.-H. Guo+, CVA, 2021] MA-Pool • MaxとAverageによる特徴量のPooling • バリエーション](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_30.jpg){kind=link}
![PCT [M.-H. Guo+, CVA, 2021] Attention Mapの可視化 意味的に近いことを捉えていると解釈できる 32](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_31.jpg){kind=link}
![Stratified Transformer [X. Lai+, CVPR2022] 点群Transformerで離れた領域のコンテキストを 利用できるよう拡張 工夫 • Stratified](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_32.jpg){kind=link}
![Stratified Transformer [X. Lai+, CVPR2022] Stratified Key-sampling Strategy • 密な近傍点と疎な遠隔点で](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_33.jpg){kind=link}
![Swin3D [Y.-Q. Yang+, arXiv:2304.06906] Swin Transformerを三次元点群に利用 • シフトしたパッチでSelf-Attentionを適用 • 事前学習としての利用を想定](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_34.jpg){kind=link}
![Swin3D [Y.-Q. Yang+, arXiv:2304.06906] 手法の設計 • スパース畳み込みでFeature Embeddingsに変換 計算順序を変えてSoftmaxを外に出すことで スパースなSelf-Attentionをメモリ効率よく計算](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_35.jpg){kind=link}
![SPoTr [J. Park+, CVPR2023] Self-Positioning point-based Transformer (SPoTr) 点群のTransformerに,データに合わせた キーポイントの自動設定を導入](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_36.jpg){kind=link}
![SPoTr [J. Park+, CVPR2023] SPA (Self-Positioning Point-based Attention) キーポイントを点群から生成しグルーピング Local](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_37.jpg){kind=link}
![SPoTr [J. Park+, CVPR2023] ネットワーク構造 • クラス分類には階層的なネットワーク • セグメンテーションには階層的なU-Net構造 39](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_38.jpg){kind=link}
![SPoTr [J. Park+, CVPR2023] キーポイントとAttentionの可視化 • それらしい点にキーポイントが配置されている • 空間局所的にAttentionが貼られている 40](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_39.jpg){kind=link}
![OctFormer [P.-S. Wang, SIGGRAPH2023] Octreeを使い局所領域を設定することで Transformerを点群に適用する • グリッドベースだと点数が不均衡になり, GPU計算と相性が悪い.Octreeで不均衡を解決 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_40.jpg){kind=link}
![OctFormer [P.-S. Wang, SIGGRAPH2023] OctreeがZ-orderで配置されることを利用 • Reshapeだけで自然に固定で区切ることができる • 個々の領域の形状はまちまち(ボクセル領域とは限らない) •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_41.jpg){kind=link}
![OA-CNN [B. Peng+, CVPR2024] スパースボクセル上の3D CNNに, Adaptive Relationというアイデアを入れる Self-Attentionなしで省メモリ・高速・高精度 43](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_42.jpg){kind=link}
![OA-CNN [B. Peng+, CVPR2024] Adaptive Relation Convolution (ARConv) カーネルの重みは特徴量の差分から計算しSoftmax Adaptive](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_43.jpg){kind=link}
![OA-CNN [B. Peng+, CVPR2024] ネットワーク構造 ARConvとAggregatorを組み込んだSparse CNN 45](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_44.jpg){kind=link}
![OA-CNN [B. Peng+, CVPR2024] Multi-One-Multi構造なので軽量,kNNも不要 畳み込みにおける特徴量の集約と再配置に Gridを用いるため,近傍探索が不要になる 46](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
![PointContrast [S. Xie+, ECCV2020] 点群における事前学習の枠組みを構成した エポックメイキングな論文 • 線形プロービングでの検証 • 物体認識](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_48.jpg){kind=link}
![PointContrast [S. Xie+, ECCV2020] 点群におけるシーン位置合わせによる対照学習 ストーリー • ShapeNet事前学習が性能を下げることを指摘 • 後のPPTとも同じ着眼点](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_49.jpg){kind=link}
![PointContrast [S. Xie+, ECCV2020] 点群における対照学習 • 変換された点群間の対応で学習 • 剛体変換を考慮 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_50.jpg){kind=link}
![PointContrast [S. Xie+, ECCV2020] ネットワーク構造 Sparse Residual U-Net:スパース畳み込みを入れたU-Net 52](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_51.jpg){kind=link}
![OcCo [H. Wang+, ICCV2021] 隠れを利用したデータ拡張による 点群の事前学習手法 • カメラ視線から隠れる点をマスク • Encoder-Decoder](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_52.jpg){kind=link}
![OcCo [H. Wang+, ICCV2021] ネットワーク • エンコーダー:PointNet, PCN, DGCNNで検証 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_53.jpg){kind=link}
![OcCo [H. Wang+, ICCV2021] OcCoファインチューニング後のモデルが 平坦な局所解であることを確認 • ランダムな摂動ベクトルに対して評価 • 間接的に,獲得された表現が優れることを示唆](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_54.jpg){kind=link}
![Mix3D [A. Nekrasov+, 3DV2021] セグメンテーションのためのデータ拡張手法 種々のネットワークで利用可能 アイデア • 学習データをランダムに空間的に重畳 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_55.jpg){kind=link}
![Mix3D [A. Nekrasov+, 3DV2021] 手法の流れ • シーン2つランダムに選択 • それぞれにランダムな幾何変換・カラーの変換を適用 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_56.jpg){kind=link}
![Mix3D [A. Nekrasov+, 3DV2021] Ablation Study • ノイズやCutOutよりもMixingが優れることを検証 • Mix時に空間的に重畳することが有効](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_57.jpg){kind=link}
![CSC [J. Hou+, CVPR2021] ShapeContextから着想した点群に対する対照学習 Contrastive Scene Context (CSC) •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_58.jpg){kind=link}
![CSC [J. Hou+, CVPR2021] Scene Contexts • PointConstrastでは点の対応だけに着目 • CSCではどのビンに入っているかを利用し,](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_59.jpg){kind=link}
![CSC [J. Hou+, CVPR2021] 評価シナリオ • 自己教師あり事前学習 • データ数が限定 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_60.jpg){kind=link}
![CSC [J. Hou+, CVPR2021] 想定している利用シナリオの一つ: Limited Annotations (LA) • アノテーションが限定](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_61.jpg){kind=link}
![Point-BERT [X. Yu+, CVPR2022] 点群を事前学習付きのTransformerで処理 • 点群のトークナイザーの導入 • 相対位置によるPositional Encoding](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_62.jpg){kind=link}
![Point-BERT [X. Yu+, CVPR2022] 点群のトークナイザー • dVAE (discrete VAE) ベースのトークナイザー](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_63.jpg){kind=link}
![Point-BERT [X. Yu+, CVPR2022] Masked Point Modeling (MPM) • BERTインスパイヤの自己教師あり学習](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_64.jpg){kind=link}
![Point-BERT [X. Yu+, CVPR2022] 事前学習タスクの結果 マスクの下部分の推定が出来ていることを確認 66](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_65.jpg){kind=link}
![Point-MAE [Y. Pang+, ECCV2022] 点群TransformerにMasked Auto-Encoderを 適用し,自己教師あり学習を行う • Point-BERTではトークン化の ためにDGCNNによる](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_66.jpg){kind=link}
![Point-MAE [Y. Pang+, ECCV2022] FPS + kNNでパッチ化 • 座標はパッチ中心で正規化 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_67.jpg){kind=link}
![Point-MAE [Y. Pang+, ECCV2022] 事前学習タスク マスクした後の再構成の可視化 69](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_68.jpg){kind=link}
![Point-M2AE [R. Zhang+, NeurIPS2022] Multi-scale Masked Autoencoders (M2AE) • 点群にMAEを適用するにあたり,階層的なモデルに](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_69.jpg){kind=link}
![Point-M2AE [R. Zhang+, NeurIPS2022] Multi-scale Masking Strategy • Transformerベースで,FPS +](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_70.jpg){kind=link}
![Point-M2AE [R. Zhang+, NeurIPS2022] Local Spatial Self-Attention • エンコーダーにおいて,Fine-Tuning時に 担当する局所領域以外のトークンをマスクする](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_71.jpg){kind=link}
![Point-M2AE [R. Zhang+, NeurIPS2022] 可視化 マルチスケールで再構成がなされていることを検証 73](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_72.jpg){kind=link}
![MSC [X. Wu+, CVPR2023] シーン分割による教師なし点群表現学習 • PointContrastのFrame MatchingはRGB-Dに依存, オーバーラップのあるフレームを利用している •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_73.jpg){kind=link}
![MSC [X. Wu+, CVPR2023] Scene augmentation • シーン点群をランダムに分割して利用 • 幾何・カラー両方にランダムなデータ拡張](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_74.jpg){kind=link}
![MSC [X. Wu+, CVPR2023] 対称学習としての設計 • 同じ点を共有しないように クエリービューとキービューをマスク • マスクした部分は学習可能なマスクトークンを割り当て](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_75.jpg){kind=link}
![MSC [X. Wu+, CVPR2023] View Mixing • クエリビューのみをランダムに混ぜ合わせてから Backboneに入力,特徴抽出後分離する InfoNCEロスでボキャブラリーを形成するキービューが](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_76.jpg){kind=link}
![ReCon [Z. Qi+, ICML2023] 点群の表現学習で, 対照学習と生成モデルを 組み合わせる Student-Teacher with Student-Student](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_77.jpg){kind=link}
![ReCon [Z. Qi+, ICML2023] Student-Teacher with Student-Student Assistance • Teacher](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_78.jpg){kind=link}
![IAE [S. Yan+, ICCV2023] 点群エンコーダーの事前学習として, パッチ単位でのImplicit Decoderを導入 • 対応付けを必要とする再構成ロス(CD, EMDなど)を](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_79.jpg){kind=link}
![IAE [S. Yan+, ICCV2023] ストーリー • 表面形状に対して表面点群のサンプリング方法は 無数にある • 点群をそのまま使うと](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_80.jpg){kind=link}
![Point-FEMAE [Y. Zha+, AAAI2024] MAEによる点群の表現学習 • Linear Headで点群を再構成してロスを計算 • クロスモーダルでも検証](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_81.jpg){kind=link}
![Point-FEMAE [Y. Zha+, AAAI2024] Local Enhancement Module (LEM) • ローカルブランチのみで適用し局所特徴量を取り出す](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_82.jpg){kind=link}
![Point-FEMAE [Y. Zha+, AAAI2024] 処理の流れ • FPS + kNNでパッチに分割,Shared MLP](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_83.jpg){kind=link}
![PointGPT [G. Chen+, NeurIPS2024] 点群の自己回帰生成による事前学習 GPT: Generative Pre-trained Transformer Morton-order](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_84.jpg){kind=link}
![PointGPT [G. Chen+, NeurIPS2024] Extractor-generator based Transformer Extractorで特徴抽出,Generatorは生成で学習し 事前学習のみで用いる 86](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_85.jpg){kind=link}
![PointGPT [G. Chen+, NeurIPS2024] Extractor-generator based Transformer Extractorで特徴抽出,Generatorは生成で学習し 事前学習のみで用いる •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_86.jpg){kind=link}
![PointGPT [G. Chen+, NeurIPS2024] ロス関数の工夫 下流タスクでも補助的に生成タスクを組み込む Post-Pre-Training • データセットを超えた自己教師あり学習が難しい •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_87.jpg){kind=link}
![PPT [X. Wu+, CVPR2024] 点群データセットの不足 ドメインギャップが大きく,単純にデータセットを 結合しても性能が向上しない → Point Prompt](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_88.jpg){kind=link}
![PPT [X. Wu+, CVPR2024] Domain Prompt Adapter (PDNorm) • Normalizationとして実装](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_89.jpg){kind=link}
![PPT [X. Wu+, CVPR2024] 性能評価 • 単にデータを混ぜるだけだと性能悪化 • PPTにより性能向上,Fine-Tuningでより優れた性能 91](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_90.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] PTv3ベースの点群の自己教師あり表現学習 同じ点は同じ特徴量で表現される,を体現 “In essence, (point) self-supervised](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_91.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] ストーリー • 既存のSSL手法は線形プロービングで性能が出ない • 「Geometric shortcut」を生じるのが原因](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_92.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] デコーダーフリーな設計 • 幾何学的ショートカットへの対策 • U-Net構造を用いると,Skip-connection経由で 局所形状を重視](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_93.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] 自己蒸留の設計 • 点群に対して複数のビューを生成 → 後述 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_94.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] ビューの作り方 • Global View: 教師モデルで特徴抽出 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_95.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] Self-Distillation Loss • 教師モデルと生徒モデルの間で特徴量を一致させる • 複数のLocal](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_96.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] 学習した特徴量の性質 • DINOv2と比較・組み合わせを検証 • 相補的な特徴量を獲得 98](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_97.jpg){kind=link}
![Sonata [X. Wu+, CVPR2025] 可視化:高いゼロショット性能を達成 99](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_98.jpg){kind=link}
{kind=link}
{kind=link}
![IDPT [Y. Zha+, ICCV2023] 動的なプロンプトチューニング • Transformerによる事前学習済モデルをfine-tuning • 単にPromptを最適化(Static)するのではなく, データに合わせてプロンプトを調整する(Dynamic)](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_101.jpg){kind=link}
![IDPT [Y. Zha+, ICCV2023] 全体のパイプライン • FPS + kNNでトークン化してTransformerに入力 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_102.jpg){kind=link}
![IDPT [Y. Zha+, ICCV2023] t-SNEによる可視化からの観察 • Point-MAEの事前学習済みモデルの特徴量 • 合成データセット(ModelNet40やShapeNetPart)では クラスごとに密なクラスタを形成](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_103.jpg){kind=link}
![Point-PEFT [Y. Tang+, AAAI2024] 点群の事前学習済モデルの 少数パラメータでのFine-Tuning • 事前学習済みのTransformerを固定 • Point-PEFTモジュールとタスク固有のHead,](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_104.jpg){kind=link}
![Point-PEFT [Y. Tang+, AAAI2024] Point-prior Prompt • 点群の事前バンクの構築:Key-Value • 入力点群をクエリとする](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_105.jpg){kind=link}
![Point-PEFT [Y. Tang+, AAAI2024] Geometry-aware Adapter • 局所形状を点群に合わせて抽出することを意図 • 処理の流れ](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_106.jpg){kind=link}
![Point-PEFT [Y. Tang+, AAAI2024] Attentionの可視化 • 判別性の高い部分にAttentionされていることがわかる • 単に[CLS]トークンでは情報を捉えていない •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_107.jpg){kind=link}
![DAPT [X. Zhou+, CVPR2024] 事前学習済みTransformerモデルの転移学習で, インスタンス固有の特徴を捉える Point-BERT,Point-MAE,ReConで検証 構成要素 • Dynamic](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_108.jpg){kind=link}
![DAPT [X. Zhou+, CVPR2024] Task-agnostic Feature Transform Strategy (TFTS) •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_109.jpg){kind=link}
![DAPT [X. Zhou+, CVPR2024] 推定されたトークンのスケールの可視化 インスタンスに応じて動的に調整されている 111](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_110.jpg){kind=link}
![DAPT [X. Zhou+, CVPR2024] Internal Prompt Tuning • 前層の出力トークンにDynamic Adapterを適用](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_111.jpg){kind=link}
![PointGST [D. Liang+, arXiv:2410.08114] Transformerによる事前学習済み点群の Parameter Efficient Fine-Tuning (PEFT) •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_112.jpg){kind=link}
![PointGST [D. Liang+, arXiv:2410.08114] Point cloud Graph Spectral Tuning (PGST)](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_113.jpg){kind=link}
![PointGST [D. Liang+, arXiv:2410.08114] 各コンポーネントの実装 • Transformerとしての設計 • FPS +](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_114.jpg){kind=link}
{kind=link}
{kind=link}
![LION [Z. Liu+, NeurIPS2024] Linear RNN (Mambaなど)による3Dデータ処理 • 3Dバックボーン +](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_117.jpg){kind=link}
![LION [Z. Liu+, NeurIPS2024] LION: LInear grOup RNN • 3DボクセルをX軸主,Y軸主で並び替えてRNNで処理](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_118.jpg){kind=link}
![LION [Z. Liu+, NeurIPS2024] スパースボクセルの値があるボクセル周囲にも トークンを配置 出力特徴量が大きい場合は値を保持 ゼロ初期化で初めから余計なボクセルが現れないように 120](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_119.jpg){kind=link}
![PointMamba [D. Liang+, NeurIPS2024] 点群にMambaを適用し線形計算量で点群処理 点群に利用するには順序付けが必要 → パッチ化してから空間充足曲線に沿って順序付け 121](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_120.jpg){kind=link}
![PointMamba [D. Liang+, NeurIPS2024] kNN + FPSでキーポイント・局所領域選択, 相対座標化 + Shared](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_121.jpg){kind=link}
![PointMamba [D. Liang+, NeurIPS2024] Order Indicator どの順序で並べられたかを示すトークンを結合 123](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_122.jpg){kind=link}
![PointMamba [D. Liang+, NeurIPS2024] グローバルモデリング 異なる順序で集約されたグローバルな特徴量を 両方とも利用することで, それぞれのシーケンスが捉えた情報を共有 124](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_123.jpg){kind=link}
![PointMamba [D. Liang+, NeurIPS2024] 基本的にはMAEで事前学習することを前提 • マスクして再構成することで事前学習 • 線形なヘッドでの出力とChamfer Distanceで学習](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_124.jpg){kind=link}
![PoinTramba [Z. Wang+, arXiv:2405.15463] TransformerとMambaのハイブリッド手法 • FPS + kNNでパッチに切り分ける •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_125.jpg){kind=link}
![PoinTramba [Z. Wang+, arXiv:2405.15463] Bi-directional Importance-aware Ordering (BIO) • Mambaに入力する際の順序を決定するために使用](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_126.jpg){kind=link}
![PoinTramba [Z. Wang+, arXiv:2405.15463] Importance-Aware Pooling • 重要度≒グローバル特徴量とのコサイン類似度の予測が 負のパッチを棄却 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_127.jpg){kind=link}
![PoinTramba [Z. Wang+, arXiv:2405.15463] 129 Ablation Study • 既存の順序付け手法よりも提案する順序付け(BIO)が 優れた性能を達成](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_128.jpg){kind=link}
![Mamba3D [X. Han+, ACMMM2024] Mambaを用いて点群を処理するネットワーク 順序依存性への対策として, チャンネル方向に順序を 反転させるC-SSMを 組み合わせる 130](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_129.jpg){kind=link}
![Mamba3D [X. Han+, ACMMM2024] 構成要素 • FPS + kNNとShared MLP](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_130.jpg){kind=link}
![PointABM [J.-W, Chen+, ICITES2024] MambaとTransformerを統合したモデル FPS + kNNでパッチ分割 bidirectional SSM](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_131.jpg){kind=link}
![PCM [T. Zhang+, AAAI2025] Point Cloud Mamba (PCM) 概要 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_132.jpg){kind=link}
![PCM [T. Zhang+, AAAI2025] Consistent Traverse Serialization (CTS) • 隣接点が連続するように](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_133.jpg){kind=link}
![PCM [T. Zhang+, AAAI2025] Positional Encoding • RoPEや学習可能なEmbeddingは点群に向かない • 線形な座標のマッピング](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_134.jpg){kind=link}
![SI-Mamba [A. Bahri+, CVPR2025] Spectral Informed Mamba (SI-Mamba) • Mambaを点群に応用](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_135.jpg){kind=link}
![SI-Mamba [A. Bahri+, CVPR2025] SAST: Surface-Aware Spectral Traversing • FPS](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_136.jpg){kind=link}
![SI-Mamba [A. Bahri+, CVPR2025] HLT: Hierarchical Local Traversing • グラフスペクトルを考慮し,SASTの順序を](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_137.jpg){kind=link}
![StruMamba3D [C. Wang+, ICCV2025] StruMamba3D • 空間的な依存関係の維持 • 空間的局所な関係を捉えるためのSpatial States](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_138.jpg){kind=link}
![StruMamba3D [C. Wang+, ICCV2025] Structural SSM Block • 状態の初期化にFPS +](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_139.jpg){kind=link}
![StruMamba3D [C. Wang+, ICCV2025] シーケンス長適応 • 状態更新のためのサンプリング間隔Δを点数に応じて調整 • Stateを共有したTeacher-StudentモデルをEMA更新 •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_140.jpg){kind=link}
{kind=link}
{kind=link}
![44. MortonNet [A. Thabet+, CVPR2020WS, arXiv:1904.00230, 2019-03-30] 点群に対する三次元特徴量を教師無しで学習する ネットワーク MortonNetの提案](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_143.jpg){kind=link}
![44. MortonNet [A. Thabet+, CVPR2020WS, arXiv:1904.00230, 2019-03-30] Sparse Filtering Curves](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_144.jpg){kind=link}
![44. MortonNet [A. Thabet+, CVPR2020WS, arXiv:1904.00230, 2019-03-30] 処理の流れ 1. Z-orderに従う点のシーケンスをShared](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_145.jpg){kind=link}
![8. RSNet (Ver. 1収録) [Q. Huang+, CVPR2018, arXiv:1802.04402, 2018-02-13] 点群を順序付きのボクセルに変換し入力する](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_146.jpg){kind=link}
![8. RSNet (Ver. 1収録) [Q. Huang+, CVPR2018, arXiv:1802.04402, 2018-02-13] 処理の流れ](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_147.jpg){kind=link}
![8. RSNet (Ver. 1収録) [Q. Huang+, CVPR2018, arXiv:1802.04402, 2018-02-13] ネットワークの構造](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_148.jpg){kind=link}
![49. 3P-RNN [X. Ye+, ECCV2018, 2018-10-08] Pointwise Pyramid Pooling (3P)と軸に沿ったRNNで](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_149.jpg){kind=link}
![49. 3P-RNN [X. Ye+, ECCV2018, 2018-10-08] Pointwise Pyramid Pooling (3P)](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_150.jpg){kind=link}
![49. 3P-RNN [X. Ye+, ECCV2018, 2018-10-08] RNNによる広い範囲での形状特徴の抽出 上方向(z方向)は既知とし,x, y方向にRNNを走らせる x軸に沿って](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_151.jpg){kind=link}
![49. 3P-RNN [X. Ye+, ECCV2018, 2018-10-08] ネットワークの構造 • 前半はPointNetに3Pを導入したネットワーク •](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_152.jpg){kind=link}
![参考文献 • [Point Transformer] Hengshuang Zhao, Li Jiang, Jiaya Jia,](https://files.speakerdeck.com/presentations/dd7cd9e74b2146da9c590982355c3c48/slide_153.jpg){kind=link}
{kind=link}
{kind=link}