Fernando Tadao Ito apresentou uma palestra fantástica no Devconf 2023, sobre Raspagem de Dados, segue a sinopse:
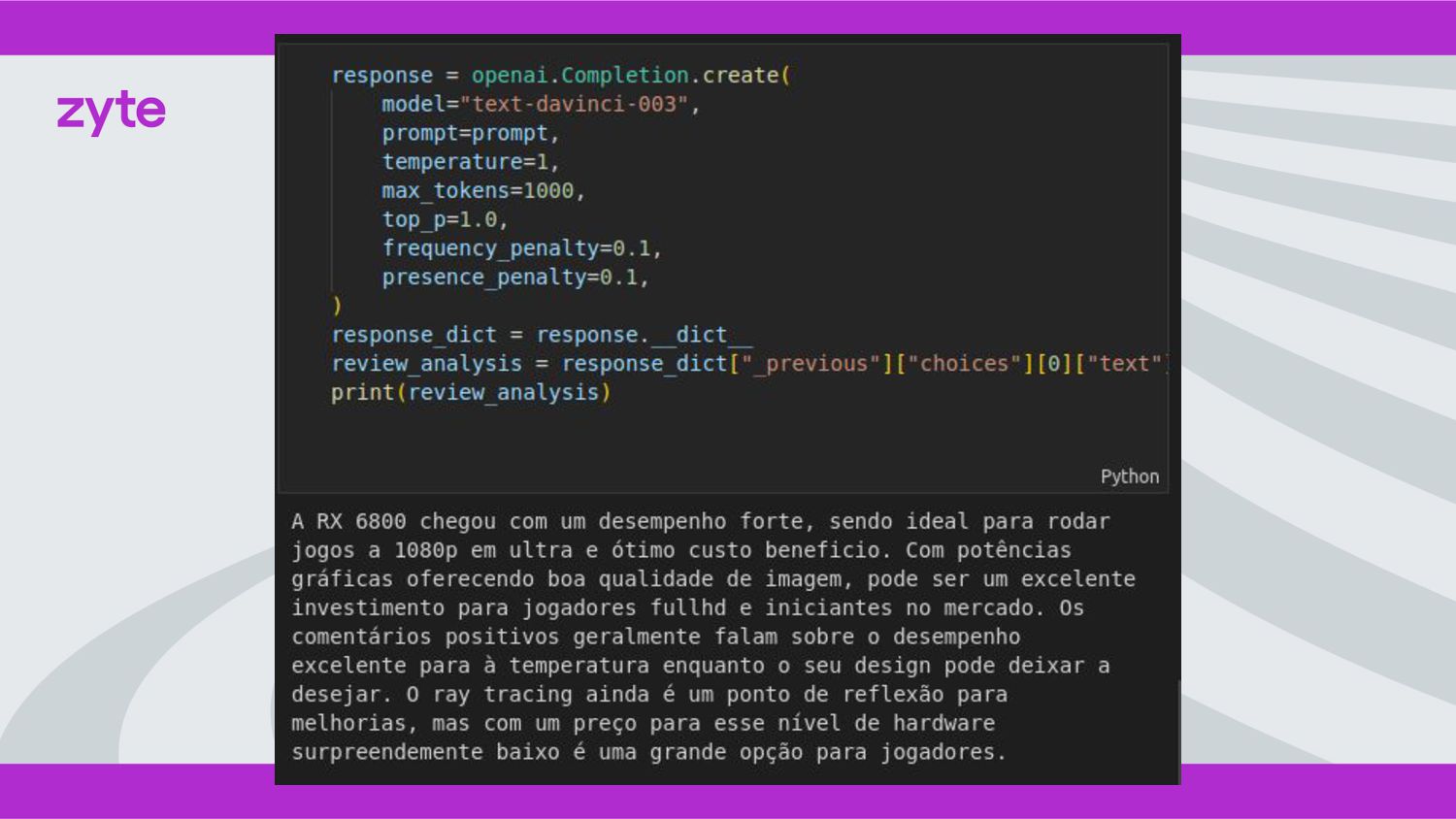
Obter dados textuais de qualidade é essencial para o treinamento de modelos de Inteligência Artificial, e a maior fonte deste tipo de informação está na Internet. Nesta palestra, discutiremos o papel importante da raspagem de dados dentro de um projeto de IA, juntamente com um exemplo prático de como facilitar esse processo usando a Zyte API em conjunto com o ChatGPT.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
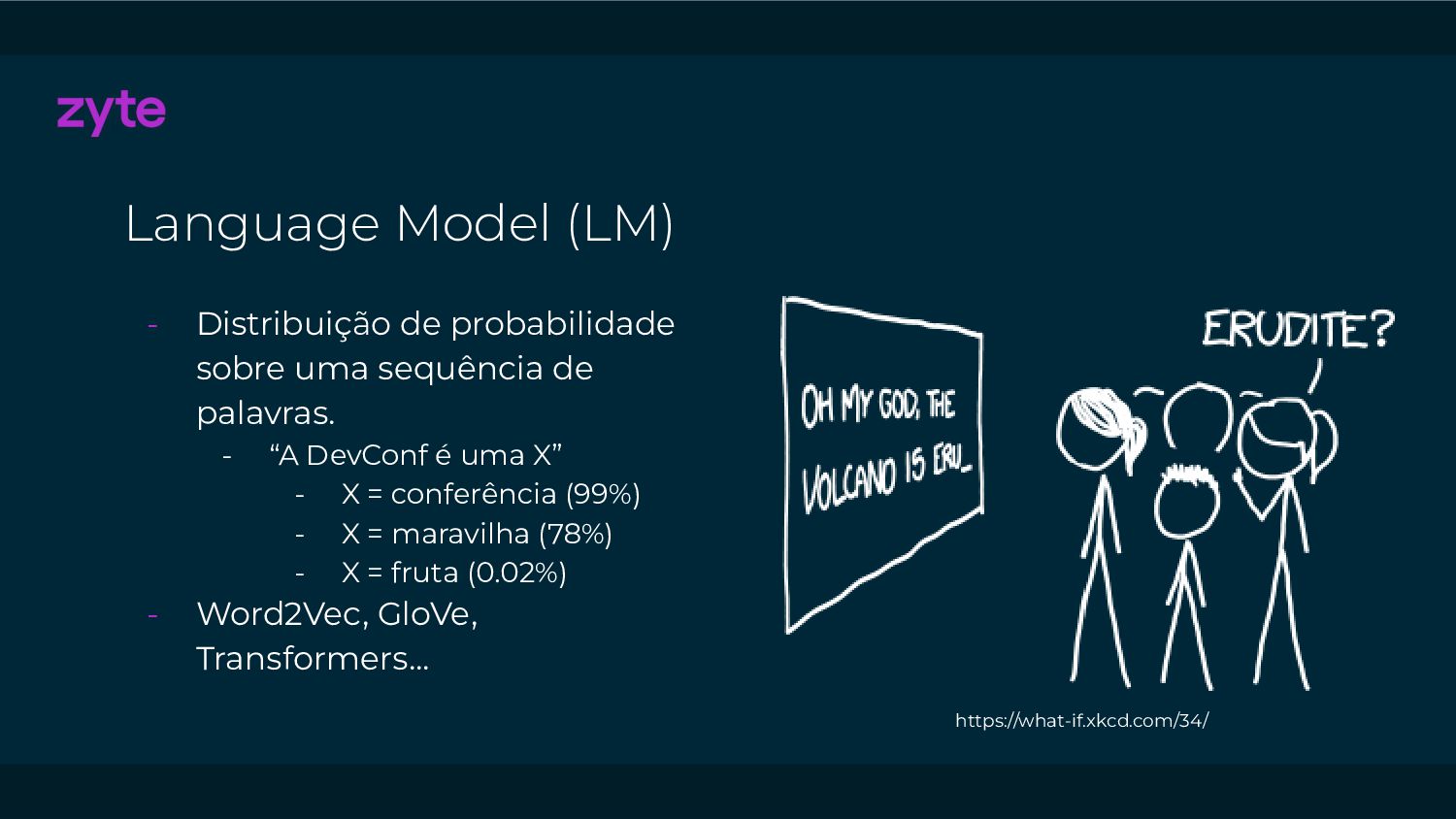{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
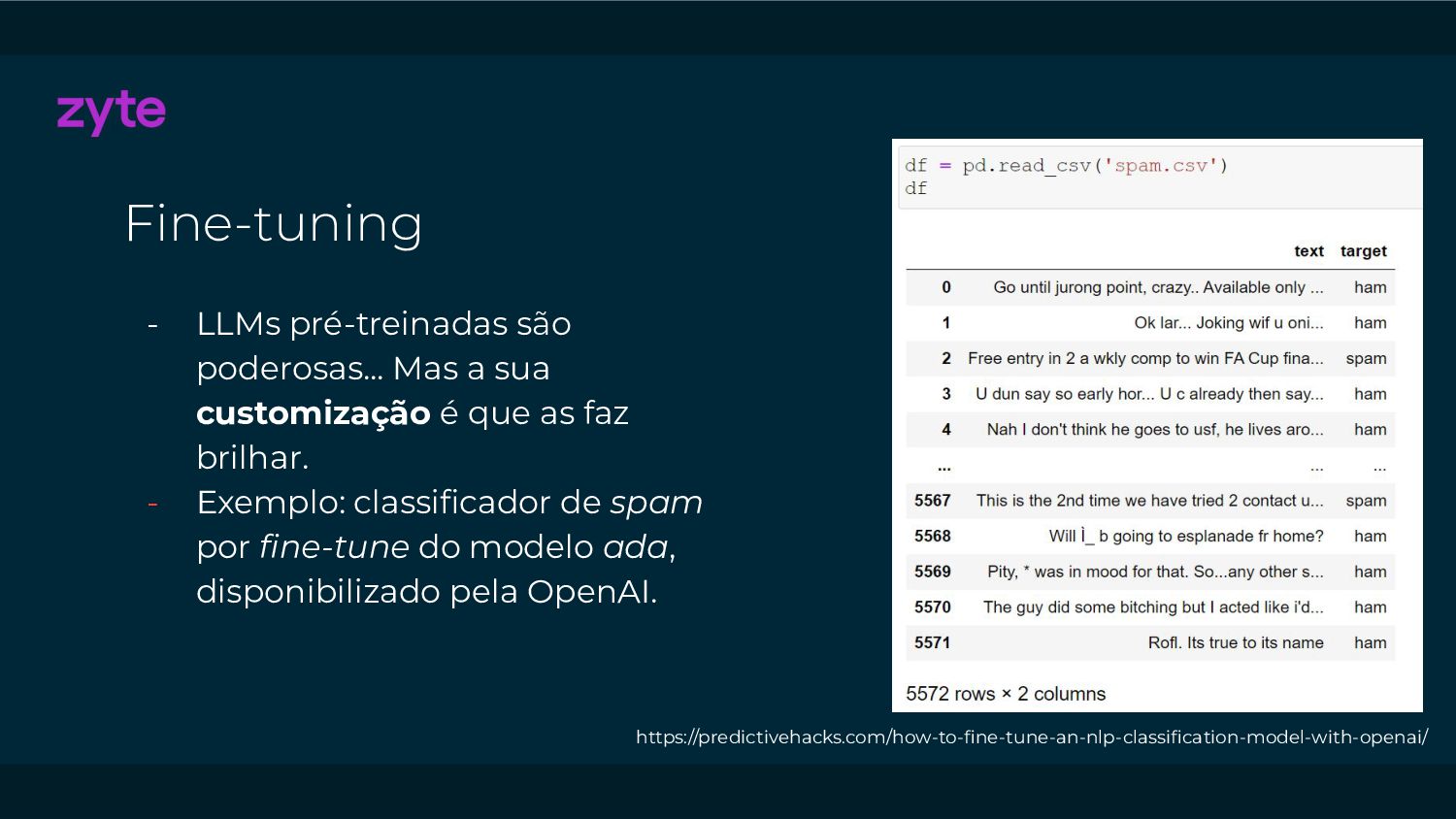{kind=link}
{kind=link}
{kind=link}
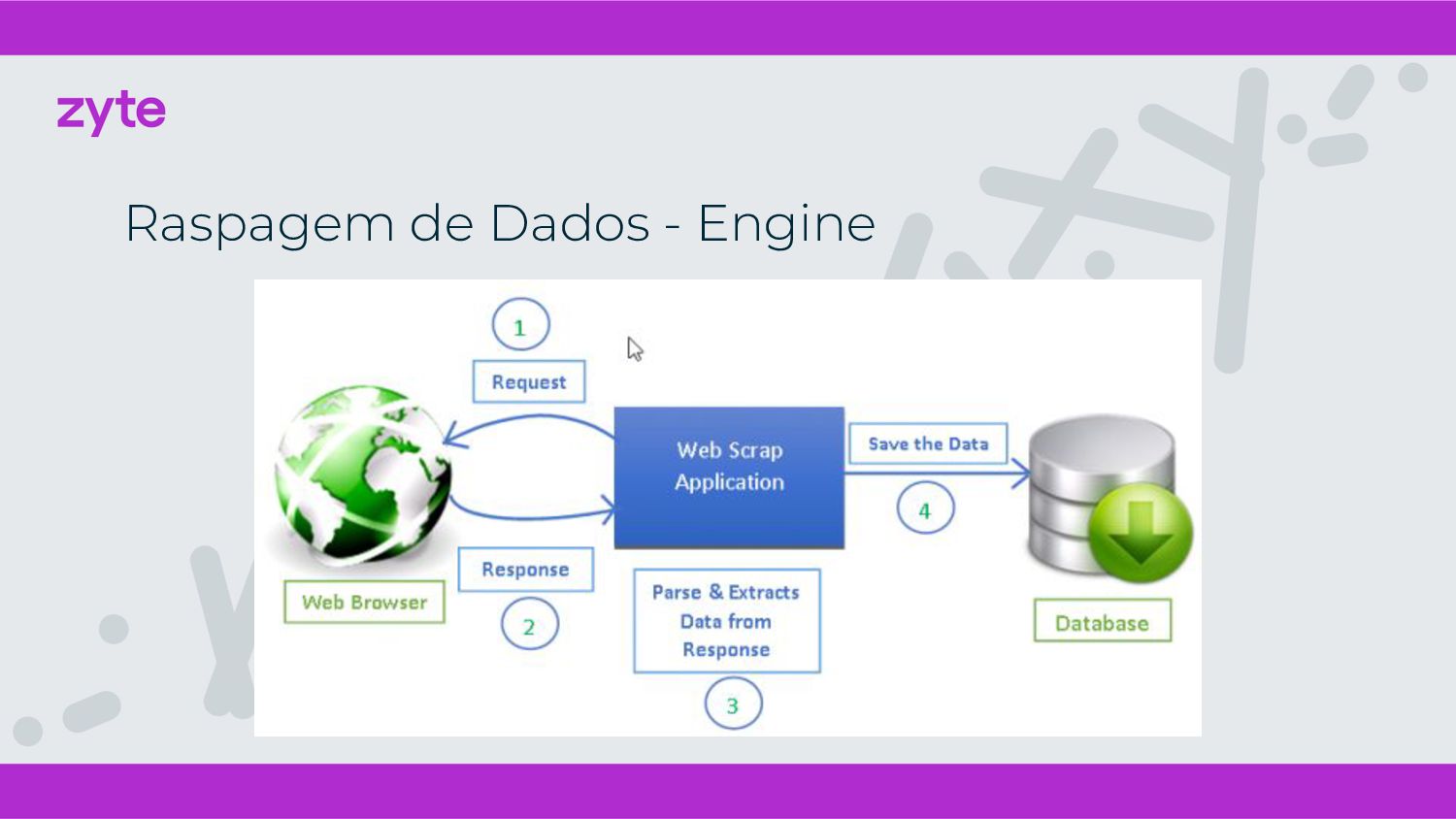{kind=link}
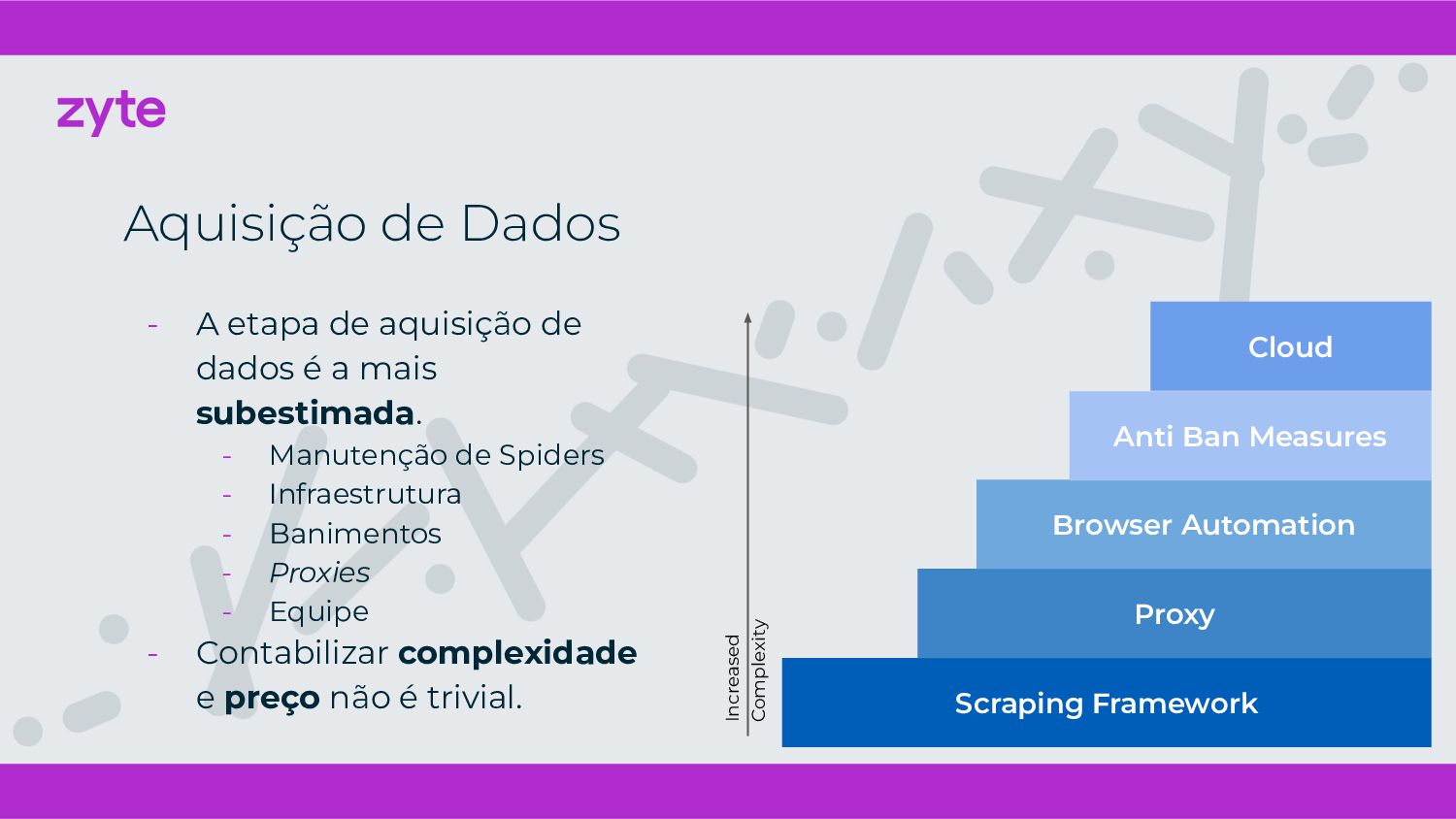{kind=link}
{kind=link}
{kind=link}
{kind=link}
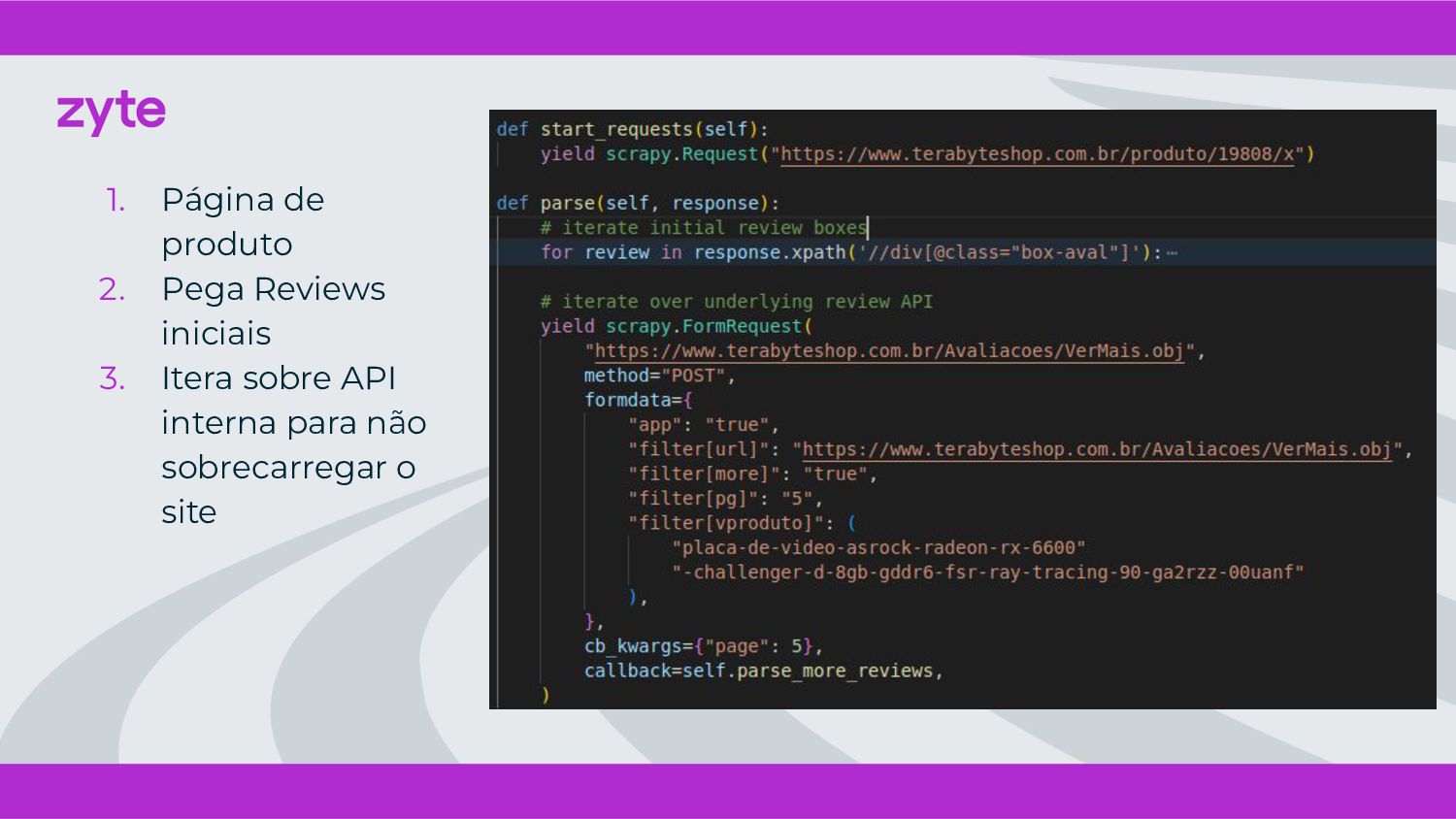{kind=link}
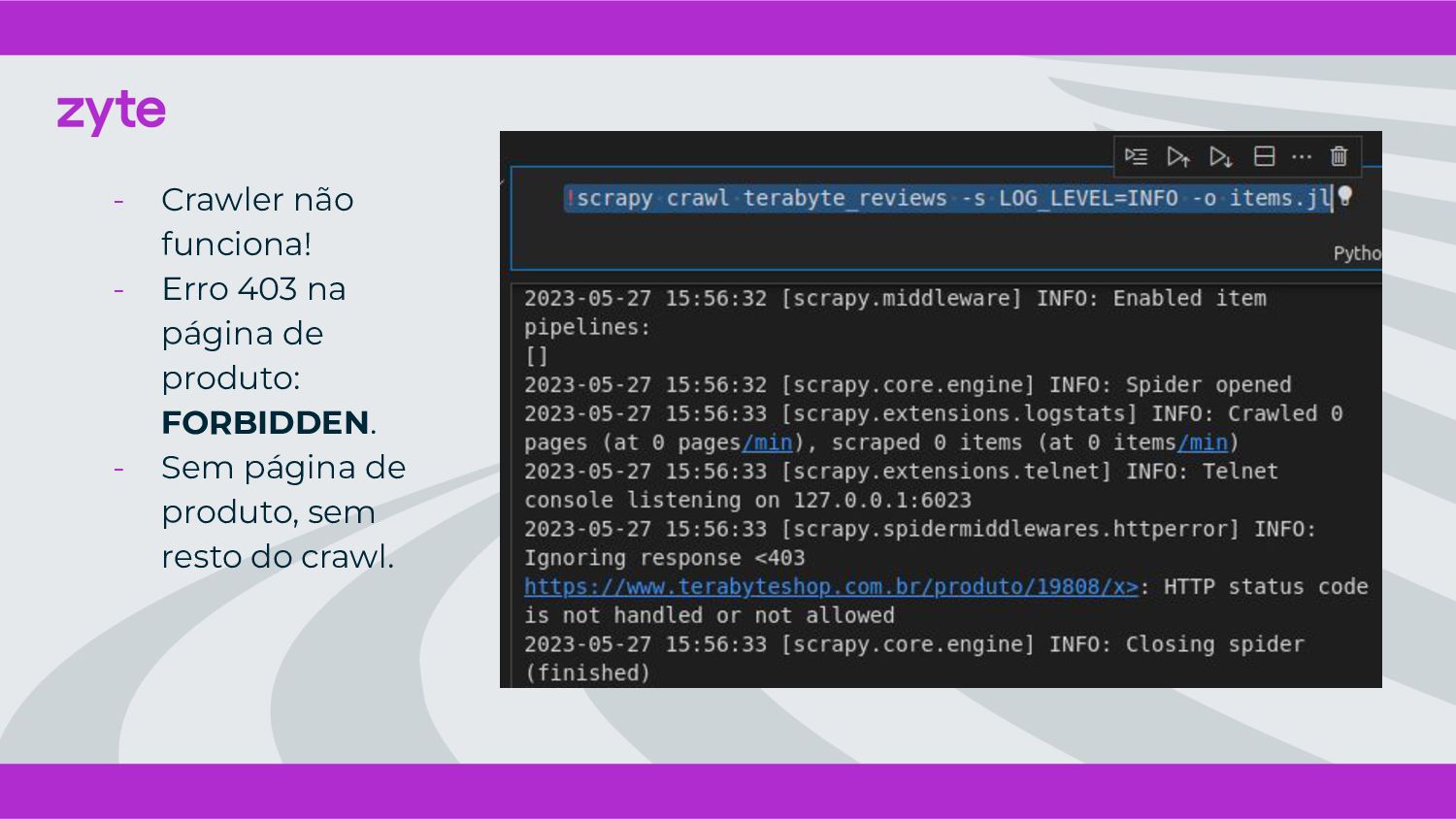{kind=link}
{kind=link}
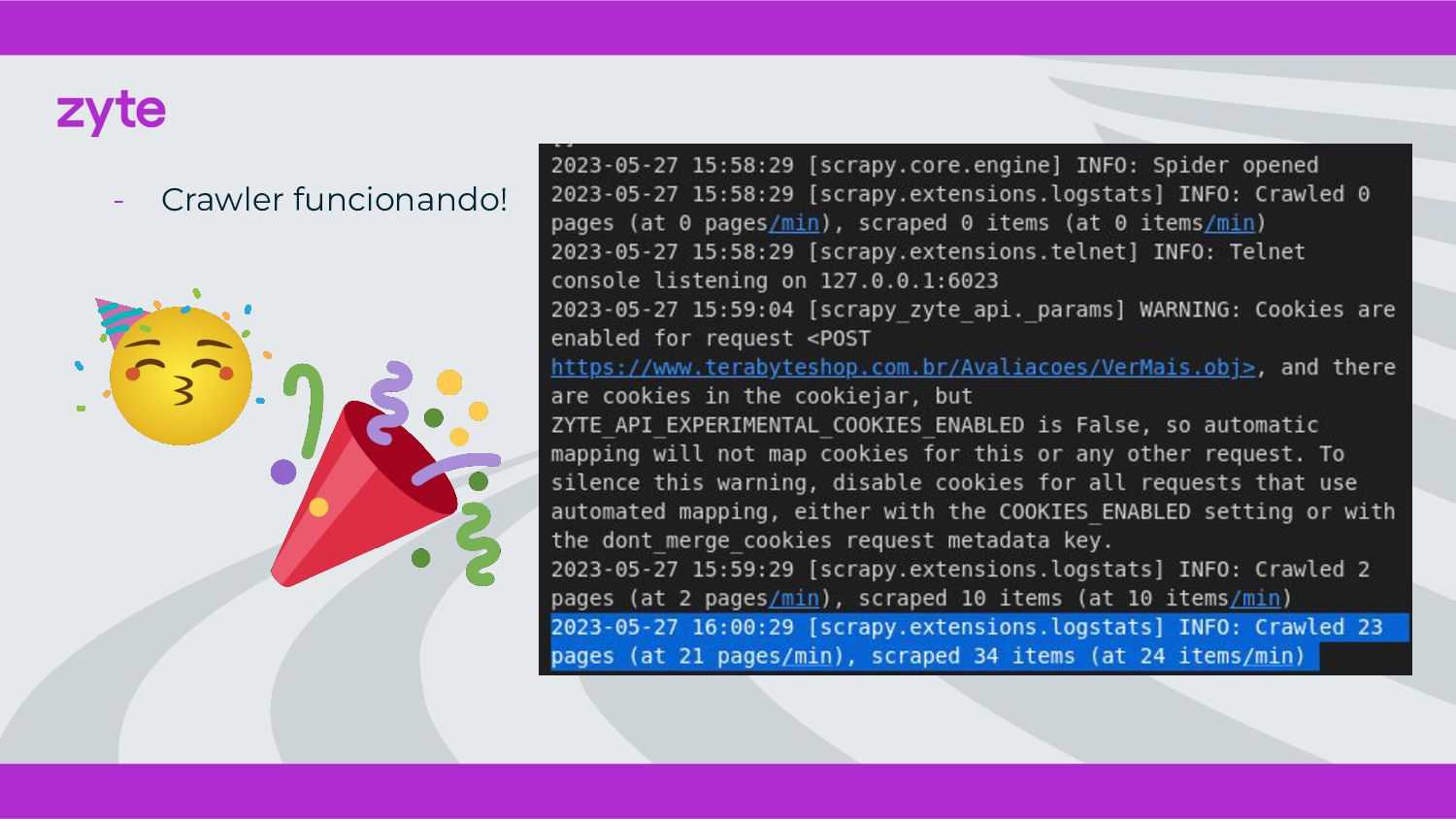{kind=link}
{kind=link}
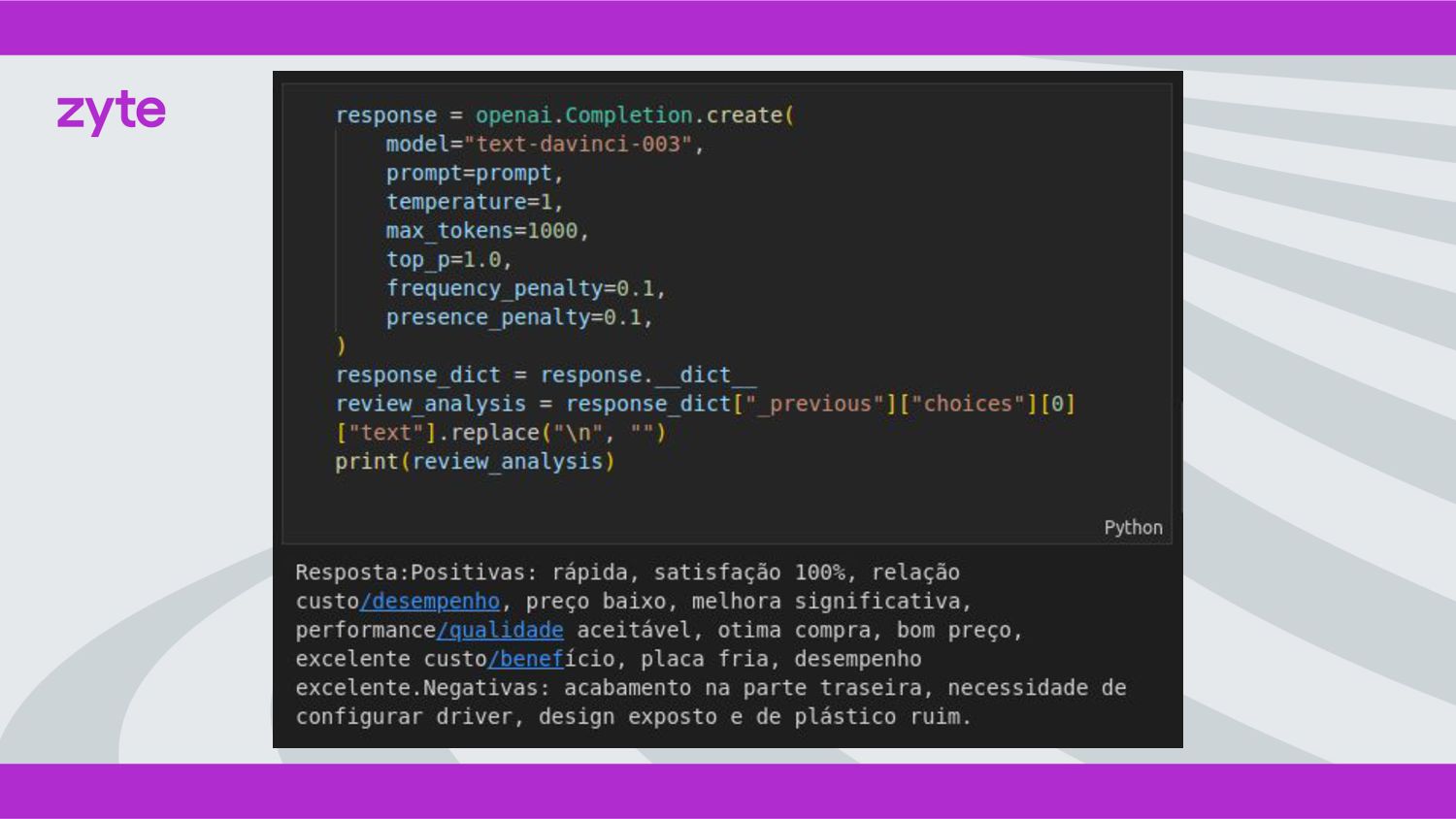{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}