Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
How to do regexp analysis
Search
Iskander (Alex) Sharipov
April 25, 2020
Programming
320
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
How to do regexp analysis
Iskander (Alex) Sharipov
April 25, 2020
More Decks by Iskander (Alex) Sharipov
See All by Iskander (Alex) Sharipov
quasigo
quasilyte
0
100
Go gamedev: XM music
quasilyte
0
150
Zero alloc pathfinding
quasilyte
0
780
Mycelium
quasilyte
0
100
Roboden game pitch
quasilyte
0
290
Ebitengine Ecosystem Overview
quasilyte
1
1k
Go gamedev patterns
quasilyte
0
550
profile-guided code analysis
quasilyte
0
390
Go inlining
quasilyte
0
170
Other Decks in Programming
See All in Programming
フィードバックで育てるAI開発
kotaminato
1
120
技術記事、 専門家としてのプログラマ、 言語化
mizchi
14
7.5k
地域 SRE コミュニティ最前線 - ホンマでっかSRE勉強会
tk3fftk
0
260
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
340
FDEが実現するAI駆動経営の現在地
gonta
1
110
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
200
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
460
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
150
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.9k
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
140
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
140
Featured
See All Featured
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
GitHub's CSS Performance
jonrohan
1033
470k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
400
Docker and Python
trallard
47
4k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Optimizing for Happiness
mojombo
378
71k
Site-Speed That Sticks
csswizardry
13
1.3k
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Transcript
How to do regexp analysis @quasilyte / GolangKazan 2020
Not why, but how Implementation advice and potential issues overview.
go-critic NoVerify Open-Source analyzers
Discussion plan • Handling regexp syntax • Analyzing regexp flow
• Finding bugs in regular expressions • Regexp rewriting
Handling regexp syntax
Why making own parser? Most regexp libraries use parsers that
give up on the first error. For analysis, we need rich AST (parse tree even) and error-tolerant parser.
Writing a parser Useful resources: • Regexp syntax docs (BNF,
re2-syntax) • Pratt parsers tutorial (RU, EN) • Regexp corpus for tests (gist) • Dialect-specific documentation
Composition operators Only two: • Concatenation: xy (“x” followed by
“y”) • Alternation: x|y (“x” or “y”) Concatenation is implicit. And we want it to be explicit in AST.
Concat operation `0|xy[a-z]` ⬇ 0 | x ⋅ y ⋅
[a-z]
Parsing concatenation • Insert concat tokens • Parse regexp like
it has explicit concat xy? ⬇ “x” “⋅” “y” “?”
Char classes (are hard) • Different escaping rules • Char-ranges
can be tricky This is char range: [\n-\r] 4 chars This is not: [\d-\r] \d, “-” and “\r”
Char classes syntax `[][]` What is it?
Char classes syntax `[][]` A char class of “]” and
“[“! `[\]\[]`
Char classes syntax `[^]*|\[[^\]]` What is it?
Char classes syntax `[^]*|\[[^\]]` A single char class! `[^\]*|\[\[^\]]`
Char classes syntax `[+=-_]` What will be matched?
Char classes syntax `[+=-_]` “F” matched
Char classes syntax `[+=\-_]` “F” not matched
Chars and literals • Consecutive “chars” can be merged •
Single char should not be converted Both forms (with and without merge) are useful. Merged chars simplify literal substring analysis.
Concat operation `foox?y` ⬇ lit(foo) ⋅ ?(char(x)) ⋅ char(y)
AST types There are at least two approaches: • One
type + enum tags • Many types + shared interface/base Both have pros and cons.
AST types type Expr struct { Kind ExprKind // enum
tag Value string // source text Args []Expr // sub-expr list } type ExprKind int
AST types const ( ExprNone ExprKind = iota ExprChar ExprLiteral
// list of chars ExprConcat // xy ExprAlt // x|y // etc. )
Helper for the next slide func charExpr(val string) Expr {
return Expr{ Kind: ExprChar, Value: val, } }
AST of `x|yz` Expr{ Kind: ExprAlt, Value: "x|yz", Args: []Expr{
charExpr("x"), { Kind: ExprConcat, Value: "yz", Args: []Expr{ charExpr("y"), charExpr("z"), }, }, }, }
Go regexp parsing library https://github.com/quasilyte/regex contains a `regex/syntax` package that
is used in both NoVerify and go-critic. It can parse both re2 and pcre patterns.
Analyzing regexp flow
Regexp flags A regular expression can have an initial set
of flags, then it can add or remove any of them inside the expression. The effect is localized to the current (potentially capturing) group.
Concat operation `/((?i)a(?m)b(?-m)c)d/s` ^--------- flags: si Entered a group with
“i” flag
Concat operation `/((?i)a(?m)b(?-m)c)d/s` -^ flags: sim Mid-group flags: add “m”
Concat operation `/((?i)a(?m)b(?-m)c)d/s` -------------^ flags: si Mid-group flags: clear “m”
Concat operation `/((?i)a(?m)b(?-m)c)d/s` -----------------^ flags: s Left a group with
“i” flag
Flags flow • Flags are lexically scoped • Groups are
a scoping unit • Leaving a group drops a scope • Entering a group adds a scope
Back references • Rules vary among engines/dialects • Syntax may
clash with octal literals • Can also be relative/named: \g{-1}, etc We’ll use PHP rules as an example.
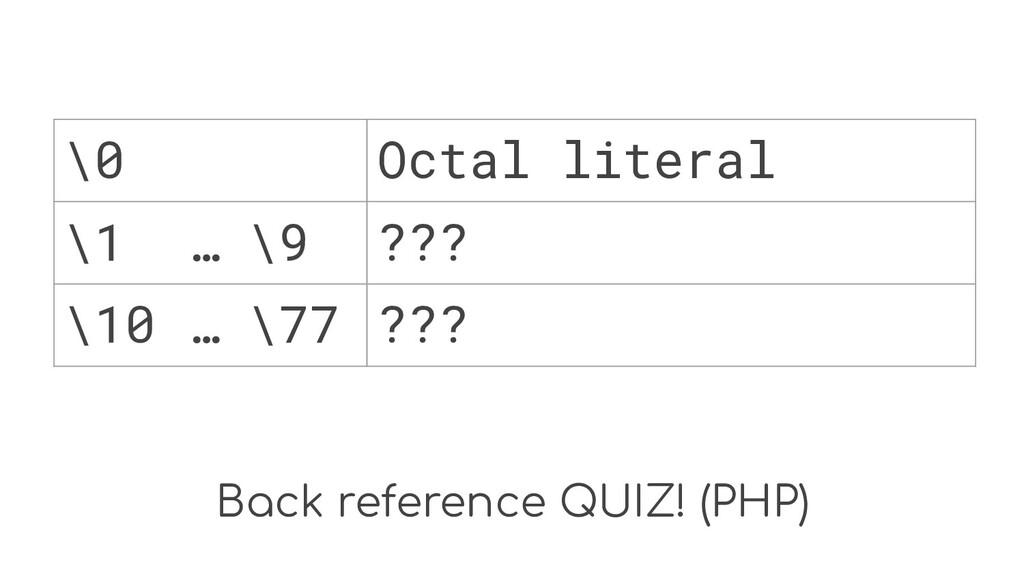
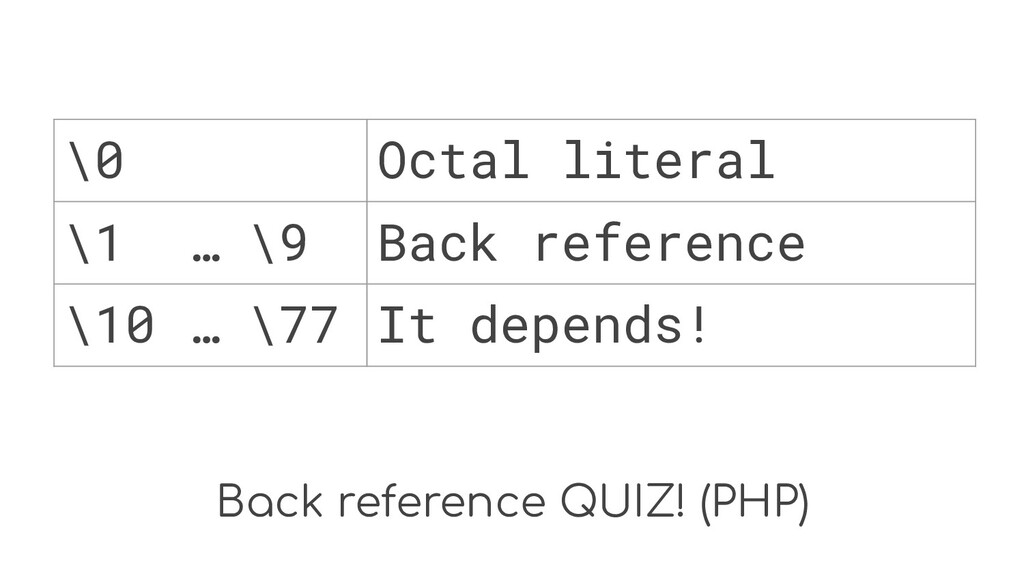
Back reference QUIZ! (PHP) \0 ??? \1 … \9 ???
\10 … \77 ???
Back reference QUIZ! (PHP) \0 Octal literal \1 … \9
??? \10 … \77 ???
Back reference QUIZ! (PHP) \0 Octal literal \1 … \9
Back reference \10 … \77 ???
Back reference QUIZ! (PHP) \0 Octal literal \1 … \9
Back reference \10 … \77 It depends!
Groups flow • Capturing groups are numbered from left to
right. • Non-capturing groups are ignored. • Groups can have a name.
Finding bugs in regular expressions
“^” anchor diagnostic Let’s check that “^” is used only
in the beginning position of the pattern. Because if it follows a non-empty match, it’ll never succeed.
Correct “^” usages `^foo` `^a|^b` `a|(b|^c)`
Incorrect “^” usages `foo^` `a^b` `(a|b)^c`
Algorithm • Traverse all starting branches • Mark all reached
“^” as “good” Then traverse a pattern AST normally and report any “^” that was not marked.
The starting branches? • For every “concat” met, it’s the
first element (applied recursively). • If root regexp element is not “concat”, consider it to be a concat of 1 element.
URL matching `google.com`
URL matching `google.com` http://googleocom.ru
URL matching `google.com` http://googleocom.ru http://a.github.io/google.com
URL matching `google\.com` http://googleocom.ru http://a.github.io/google.com
URL matching `^https?://google\.com/` http://googleocom.ru http://a.github.io/google.com
URL matching When “.” is used before common domain name
like “com”, it’s probably a mistake. If we have char sequences represented as a single AST node, this analysis is trivial.
Handling unescaped dot `google.com` lit(google) ⋅ . ⋅ lit(com) Warn
if “.” is followed by a lit with domain name value.
Regexp rewriting
Regexp input generation It’s quite simple to generate a string
that will be matched by a regular expression if you have that regexp AST.
Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $
Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $
aa N matches of \w
Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $
aa7 1 match of [0-9]
Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $
aa7 May do nothing for $
Regexp input generation Generating a non-matching strings can be useful
for catastrophic backtracking evaluation.
Regexp simplification Instead of writing a matching characters we can
write the pattern syntax itself. By replacing recognized AST node sequences with something simpler, we can perform a regexp simplification.
Regexp simplification `\dxx*` \d ⋅ x ⋅ *(x)
Regexp simplification `\dxx*` \d ⋅ x ⋅ *(x) \d Can’t
simplify \d, write as is
Regexp simplification `\dxx*` \d ⋅ x ⋅ *(x) \dx+ xx*
-> x+
Oh, the possibilities! x{1,} -> x+ [a-z\d][a-z\d] -> [a-z\d]{2} [^\d]
-> \D a|b|c -> [abc]
https://quasilyte.dev/regexp-lint/ Online Demo
Submit your ideas! :) If you have a particular regexp
simplification or bug pattern that is not detected by regexp-lint, let me know.
Thank you.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Concat operation `0|xy[a-z]` ⬇ 0 | x ⋅ y ⋅](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![Char classes syntax `[][]` What is it?](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_11.jpg){kind=link}
![Char classes syntax `[][]` A char class of “]” and](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_12.jpg){kind=link}
![Char classes syntax `[^]*|\[[^\]]` What is it?](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_13.jpg){kind=link}
![Char classes syntax `[^]*|\[[^\]]` A single char class! `[^\]*|\[\[^\]]`](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_14.jpg){kind=link}
![Char classes syntax `[+=-_]` What will be matched?](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_15.jpg){kind=link}
![Char classes syntax `[+=-_]` “F” matched](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_16.jpg){kind=link}
![Char classes syntax `[+=\-_]` “F” not matched](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AST of `x|yz` Expr{ Kind: ExprAlt, Value: "x|yz", Args: []Expr{](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_54.jpg){kind=link}
![Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_55.jpg){kind=link}
![Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_56.jpg){kind=link}
![Generating matching string (N=2) `\w*[0-9]?$` *(\w) ⋅ ?([0-9]) ⋅ $](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
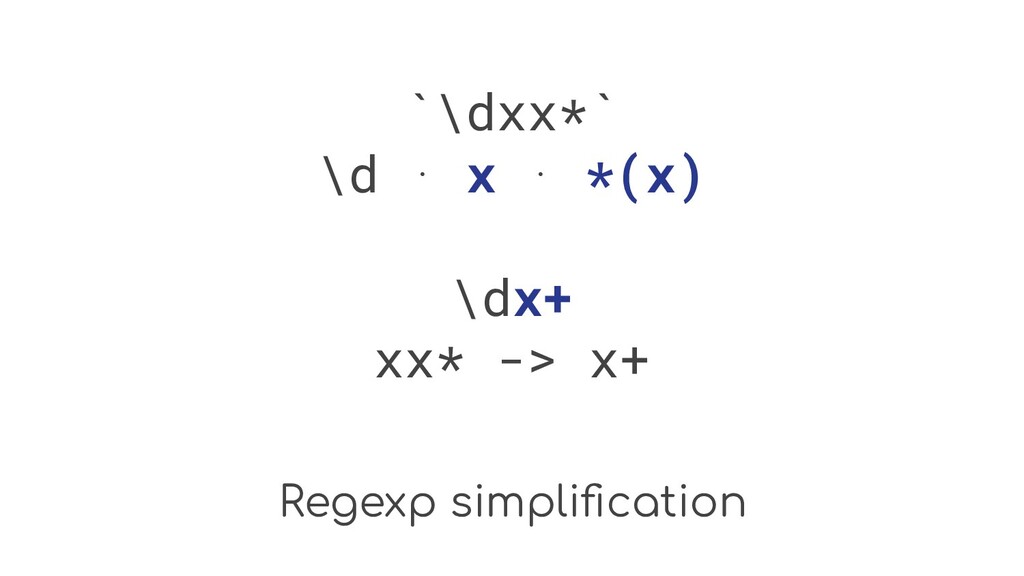{kind=link}
![Oh, the possibilities! x{1,} -> x+ [a-z\d][a-z\d] -> [a-z\d]{2} [^\d]](https://files.speakerdeck.com/presentations/80b2d4f016f84985a2e4aff96dbbccbd/slide_63.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}