Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
UM - Game-Playing Strength of MCTS Variants 11t...
Search
Ryushi
April 13, 2025
290
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
UM - Game-Playing Strength of MCTS Variants 11th. Place solution
Ryushi
April 13, 2025
More Decks by Ryushi
See All by Ryushi
なぜ俺は銀メダルなのか 25th solutionから⾦メダルへとの差分考える「BirdCLEF2025振り返り」
ryushi496
2
950
ざっくりTabMを知る
ryushi496
1
650
Data Science Osaka Autumn 2024 -16th Place solution-
ryushi496
2
400
Featured
See All Featured
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Bash Introduction
62gerente
615
220k
30 Presentation Tips
portentint
PRO
1
350
WCS-LA-2024
lcolladotor
0
680
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Facilitating Awesome Meetings
lara
57
7k
How to build a perfect <img>
jonoalderson
1
5.8k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
Done Done
chrislema
186
16k
Transcript
UM - Game-Playing Strength of MCTS Variants 11th Place solution
Kaggle Competitions Master Ryushi
本資料は2025.04.13に⾏われた湘南Kaggler会 の発表資料を⼀部改変したものです。
team:kansai-kaggler 2g Kaggle competitions Master RYUSHI Kaggle competitions Master ktm
Kaggle competitions Master
result : 11th. place (gold medal)
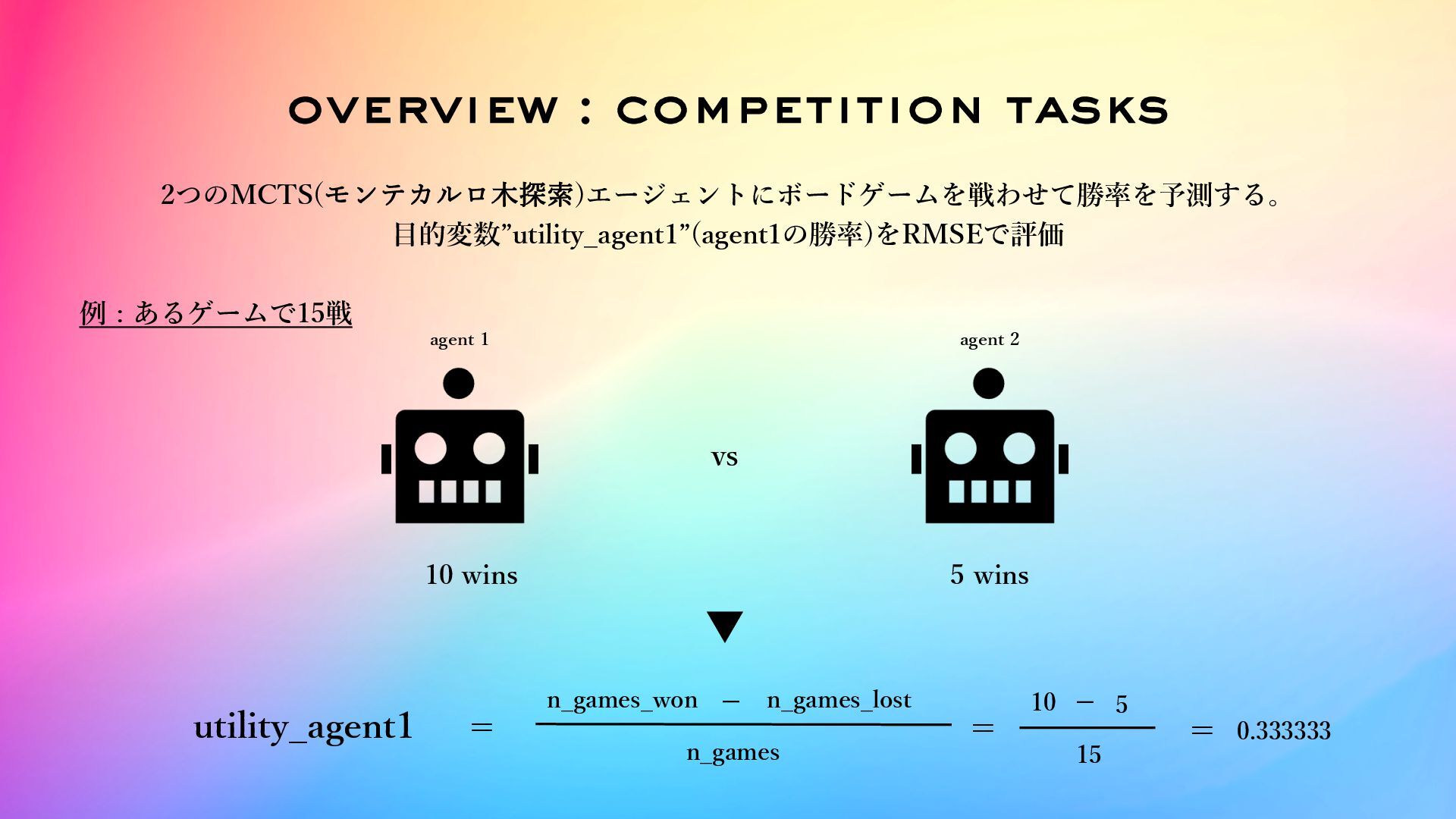
overview : competition tasks 2つのMCTS(モンテカルロ⽊探索)エージェントにボードゲームを戦わせて勝率を予測する。 ⽬的変数”utility_agent1”(agent1の勝率)をRMSEで評価 agent 1 agent 2
vs 例 : あるゲームで15戦 10 wins 5 wins utility_agent1 = n_games_won n_games_lost n_games = 10 5 15 = 0.333333
overview : dataset データ数 説明変数 エージェント Train.csv : 233,234 row
× 814 columns ゲーム名 ゲームルールに関する特徴量 ゲームの勝敗に関わる特徴量 本コンペの特徴量は以下に⼤別される MCTS(モンテカルロ⽊探索)アルゴリズム。選択戦略やパラメーターを変えた72種類 1377種類のボードゲーム ゲームのルールを定義する特徴量。詳しくは次ページ。 ⽬的変数(勝率)を含む、ゲームの勝利数と引き分け数など
overview : feature(game rule) 本コンペのゲームは1,400以上のゲームが登録されているライブラリ Ludii portalで⾏われている。 Ludiiにおけるゲームは以下のように定義される。 「モンテカルロ⽊探索のパフォーマンスを予測する Kaggleコンペ解説
〜⽣成AIによる未知のゲーム⽣成〜」, https://speakerdeck.com/rist/solution-um-game-playing-strength-of-mcts-variants?slide=9, (参照2025-04-05)
preprocessing training inference agenda pipeline overview cv strategy multi target
feature engineering flip augmentation data generation stacking submittion selection
preprocessing : feature engineering(1/2) 特徴量としての情報が少ないものは学習から除いた。 具体的には以下のようなもの。 ユニークな値が1つしかない 95%以上⽋損しているもの ”_frequency”系特徴量と ”_components”系特徴量
相互相関が90%以上の特徴量はいずれかを残して、削除(RYUSHIのみ) 例えば、 [ʻScoreDifferenceVarianceʼ, ʻScoreDifferenceMedianʼ, ʻScoreDifferenceMaximumʼ, ʻScoreDifferenceChangeAverageʼ, ʻScoreDifferenceMaxDecreaseʼ, ʻScoreDifferenceAverageʼ, ʻScoreDifferenceMaxIncreaseʼ, ʻScoreDifferenceChangeLineBestFitʼ] の相互相関が90%超えていた場合、”ScoreDifferenceVariance” のみを残して他を削除
preprocessing : feature engineering(2/2) “LudRules”から以下のような特徴量を追加する “LudRules” 内に 'Draw'、'Win'、'Loss' が登場する回数を抽出 start、play、end
の各セクションに分割し、それぞれにTF-IDFを適⽤ セクション内のネストの深さ(() や {} の数を⽤いて計算) セクション内の "if" ステートメントの数。 セクション内の "place" の出現回数。 その他にも特徴量は作っていますが、⼀番効いたのは“LudRules”由来のもの
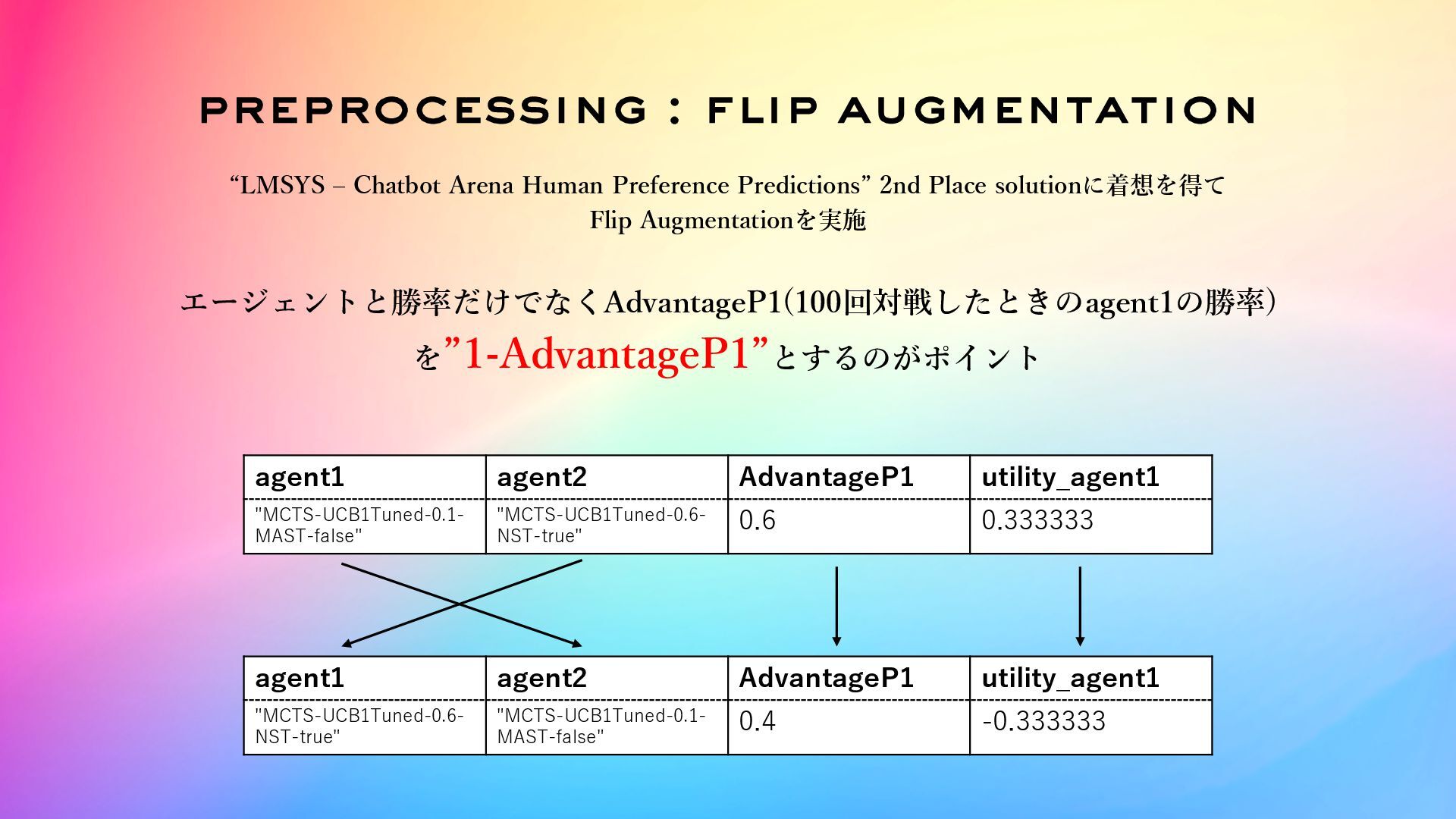
preprocessing : flip augmentation “LMSYS ‒ Chatbot Arena Human Preference
Predictions” 2nd Place solutionに着想を得て Flip Augmentationを実施 agent1 agent2 AdvantageP1 utility_agent1 "MCTS-UCB1Tuned-0.1- MAST-false" "MCTS-UCB1Tuned-0.6- NST-true" 0.6 0.333333 agent1 agent2 AdvantageP1 utility_agent1 "MCTS-UCB1Tuned-0.6- NST-true" "MCTS-UCB1Tuned-0.1- MAST-false" 0.4 -0.333333 エージェントと勝率だけでなくAdvantageP1(100回対戦したときのagent1の勝率) を”1-AdvantageP1”とするのがポイント
preprocessing : data generation ここでは、もしあなたがこのようなことをしたいのであれば、どのようにすればよいのか、 いくつかの詳細/ガイドラインを提供します。 ホストから追加データの作り⽅のガイドラインは提供されていた ただし、コードの実⾏に時間がかかりすぎるため、上位でも使っているチームは少なかった。 我々のチームは39,000件ほど作成し、⼀部のモデルでAugmentationとして使⽤した。
preprocessing training inference agenda pipeline overview cv strategy multi target
feature engineering flip augmentation data generation stacking submittion selection
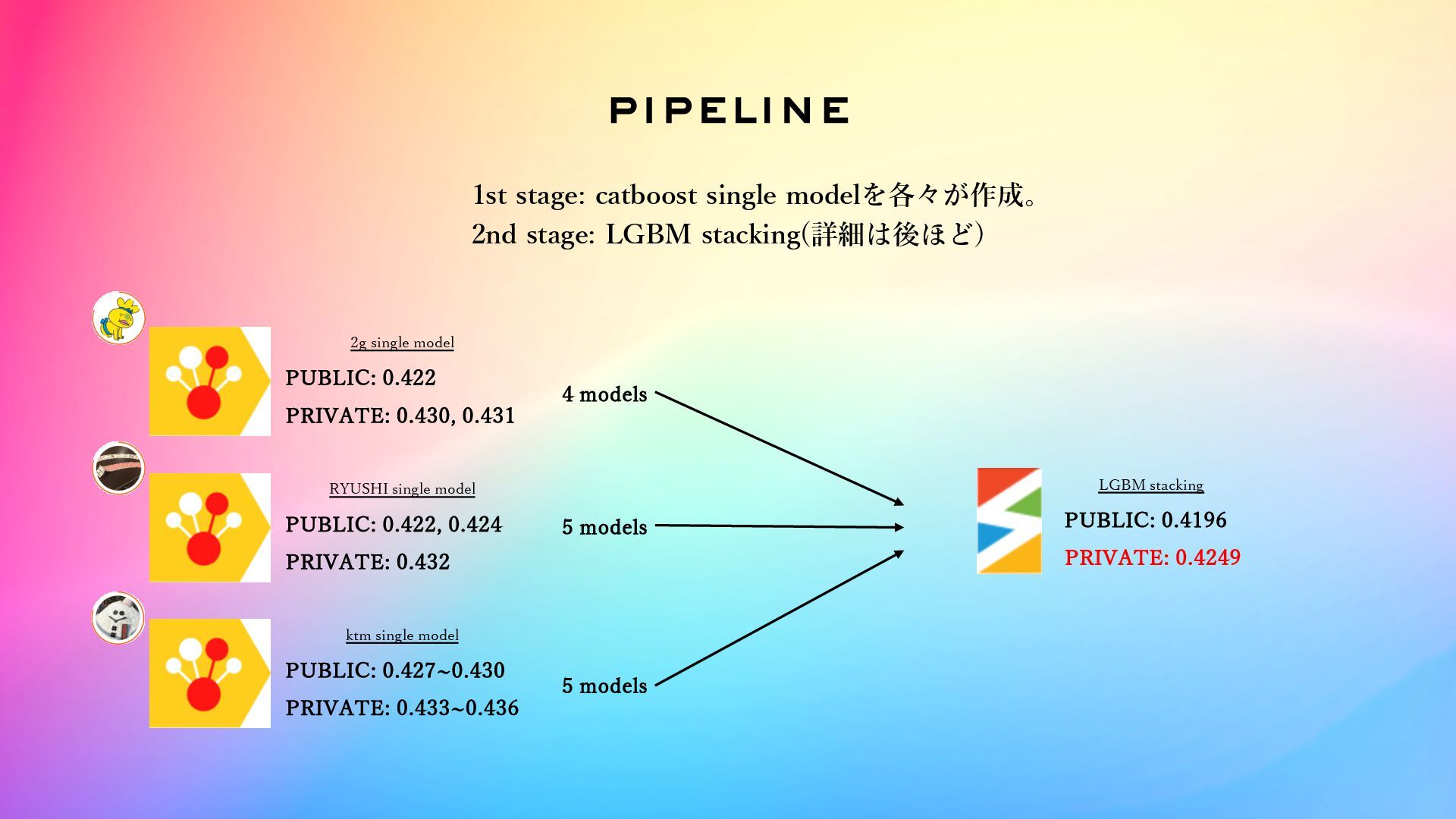
pipeline 2g single model PUBLIC: 0.422 PRIVATE: 0.430, 0.431 RYUSHI
single model PUBLIC: 0.422, 0.424 PRIVATE: 0.432 ktm single model PUBLIC: 0.427~0.430 PRIVATE: 0.433~0.436 LGBM stacking PUBLIC: 0.4196 PRIVATE: 0.4249 1st stage: catboost single modelを各々が作成。 2nd stage: LGBM stacking(詳細は後ほど) 5 models 4 models 5 models
training : cv strategy 難しさ Seedでスコアがにばらつきがある上に、各fold間でcvが異なる https://www.kaggle.com/competitions/um-game-playing-strength-of-mcts- variants/discussion/532617 コンペ序盤から活発に動いていた c-number⽒によるCV-LBスレッド
https://www.kaggle.com/competitions/um-game-playing-strength-of-mcts- variants/discussion/532617 コンペ中にLBトラストできるかの議論は散⾒ yunsuxiaozi⽒によるスレッド
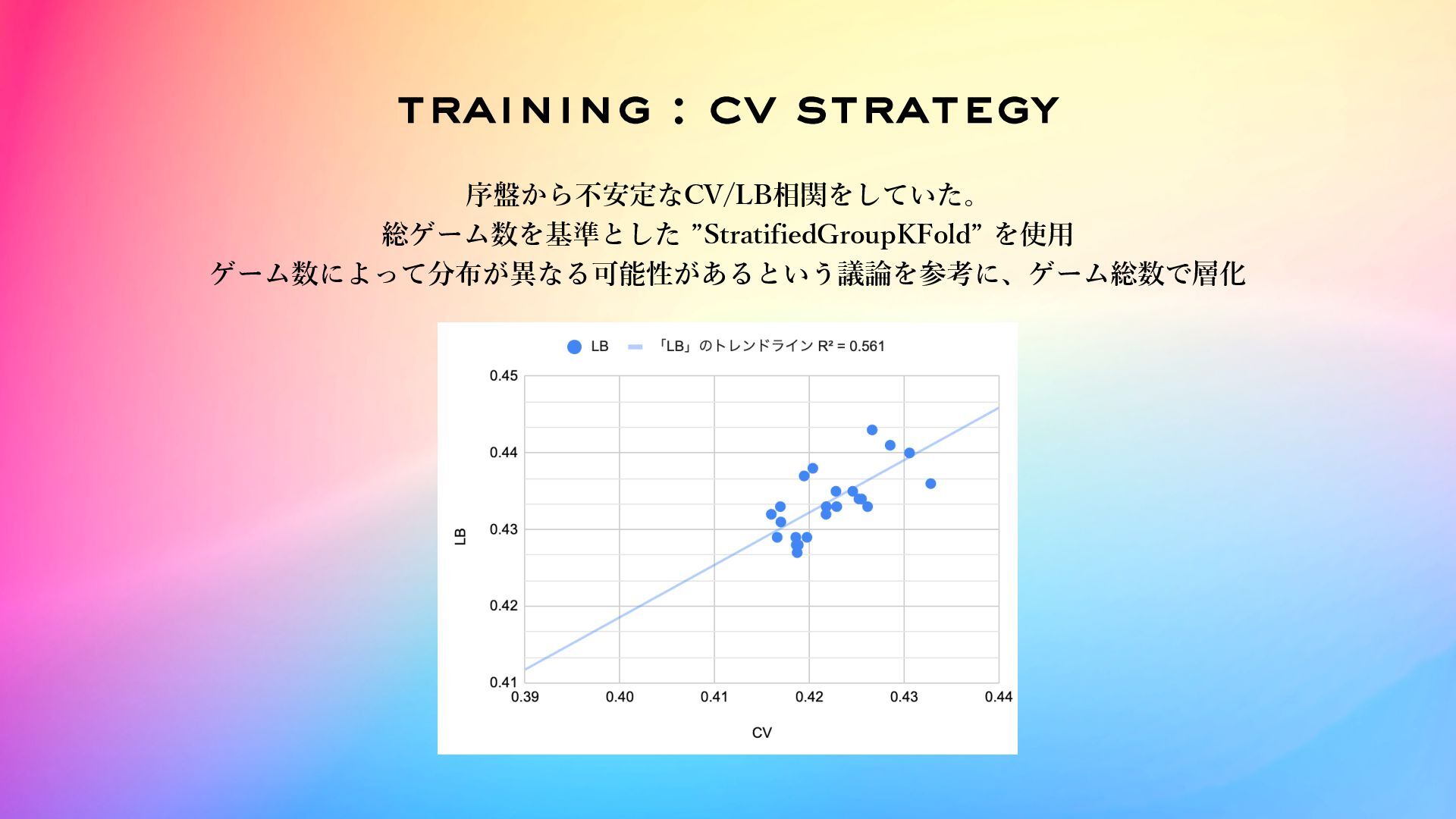
training : cv strategy 序盤から不安定なCV/LB相関をしていた。 総ゲーム数を基準とした ”StratifiedGroupKFold” を使⽤ ゲーム数によって分布が異なる可能性があるという議論を参考に、ゲーム総数で層化
training : multi target “utility_agent1”(⽬的変数)は勝率であるため 引き分け率を表す”draw_ratio”を考慮できると予測に寄与するのではないかと考え、 Catboostの”MultiRMSE loss”を⽤いて学習 「Multiregression: objectives
and metrics」, https://catboost.ai/docs/en/concepts/loss-functions-multiregression, (参照2025-04-05)
preprocessing training inference agenda pipeline overview cv strategy multi target
feature engineering flip augmentation data generation stacking submittion selection
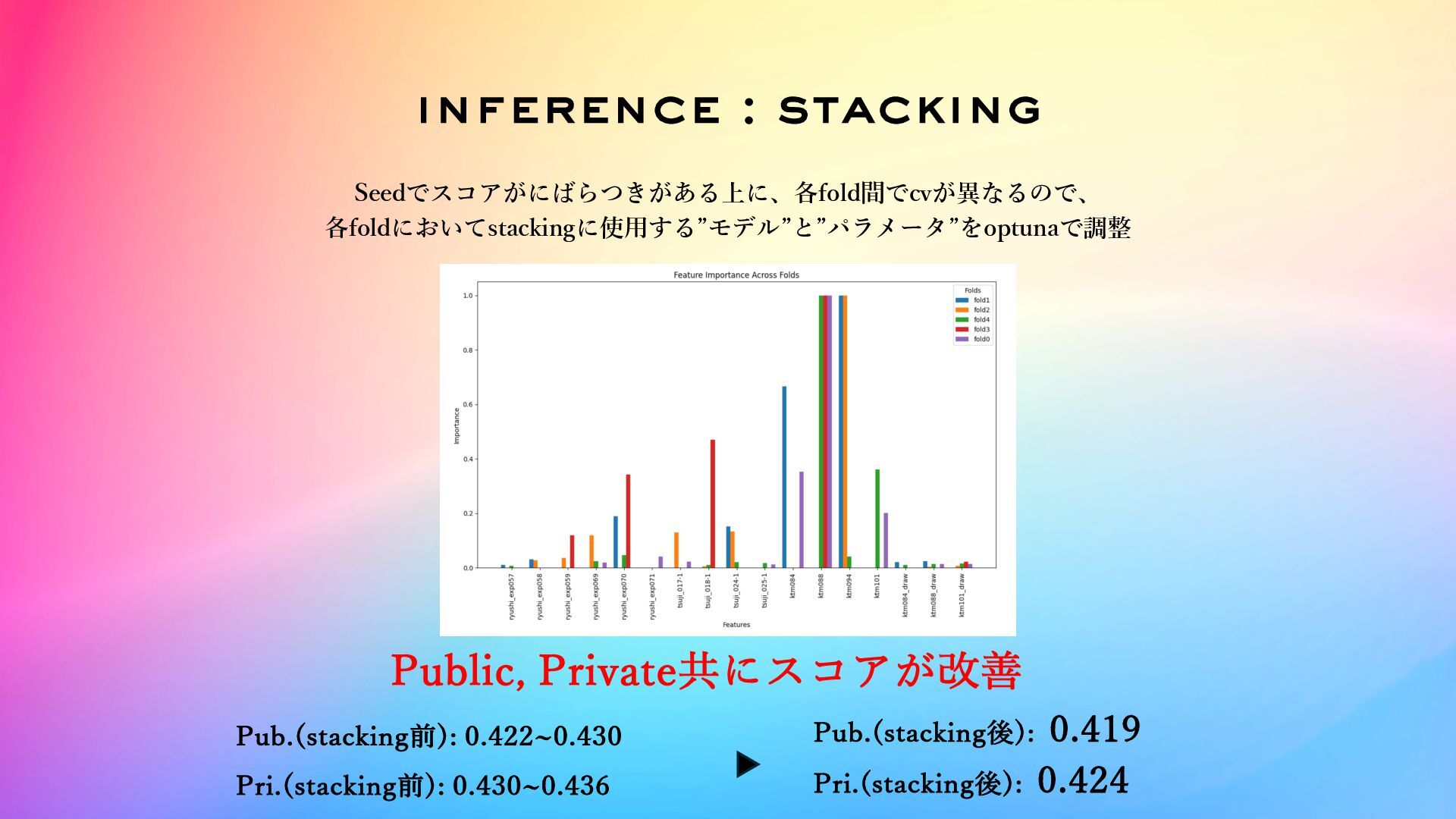
inference : stacking Seedでスコアがにばらつきがある上に、各fold間でcvが異なるので、 各foldにおいてstackingに使⽤する”モデル”と”パラメータ”をoptunaで調整 Public, Private共にスコアが改善 Pub.(stacking前): 0.422~0.430 Pub.(stacking後):
0.419 Pri.(stacking前): 0.430~0.436 Pri.(stacking後): 0.424
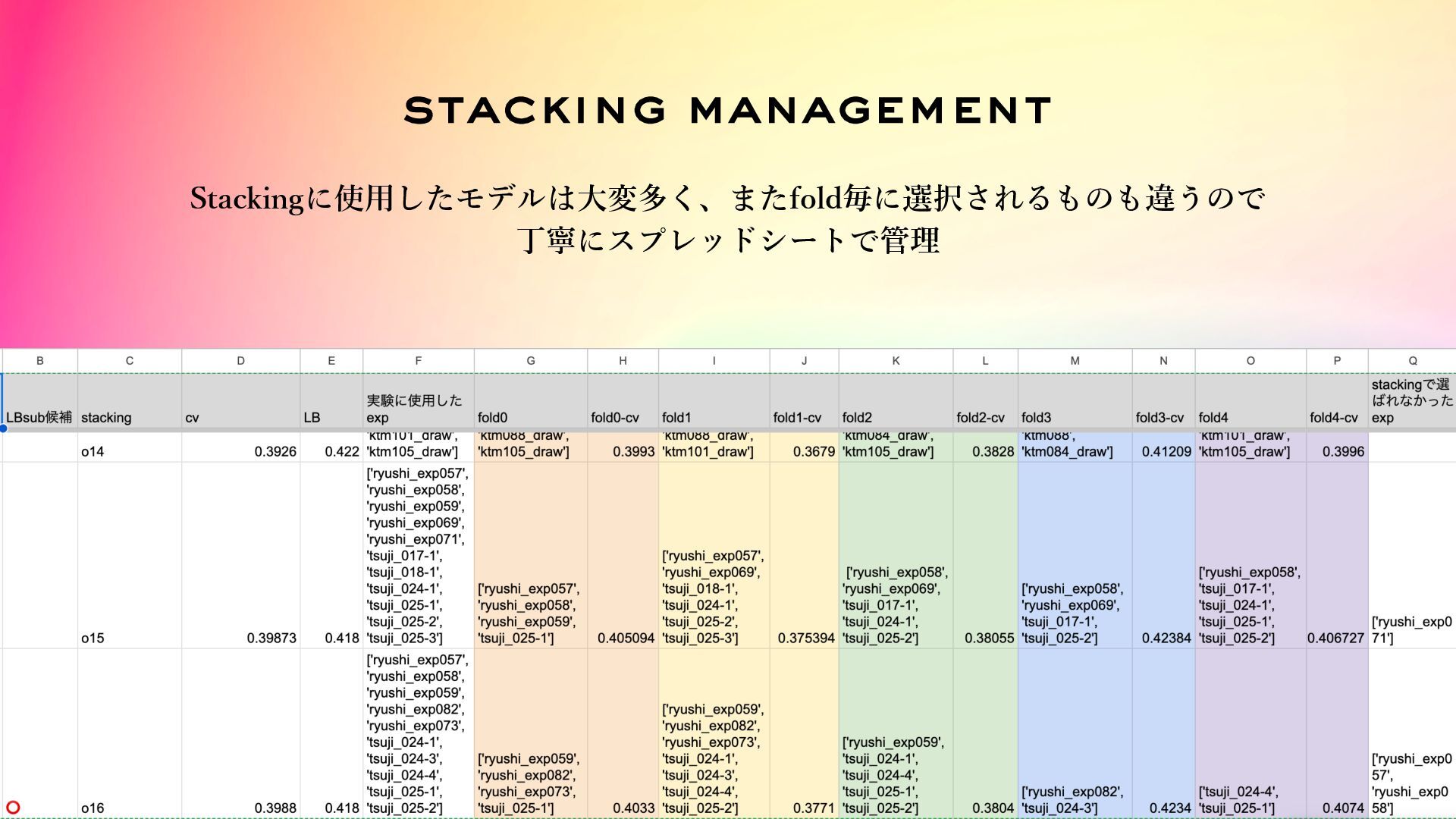
stacking management Stackingに使⽤したモデルは⼤変多く、またfold毎に選択されるものも違うので 丁寧にスプレッドシートで管理
submission selection Seed間のLBのズレや、fold間のCVのズレなどLBに多くの不安があったため 最終提出はPublicLBを捨てて、CVスコアを起点に以下の2つとした。 CV + LB ベストモデル CV ベストモデル
結果的に本コンペはPublicLBを起点に選んでもあまり揺れなかったのだが、 (我々のsubmissionの中では)CVを起点にprivate bestを選択できた。 やはり信頼できるCVに基づいた、Trust CVは⼤切 2nd stageで、Stackingを⽤いたもので、CVとLBを総合的に判断して⼀番良かったもの 2nd stageで、nelder-meadを⽤いたもので、CVが⼀番良かったもの
introspection 他のモデルの精度が低かった。上位のシングルより弱かった TabMやDeepTableなどのtabularNNを使いスコアを 出しているチームが上位でもチラホラいた。 tabularNNの勘所は全くわからない。 GBDTに関しては”balance”という特徴量をひっくり 返すことで更に上るチームもあったそう。もっと でーたの考察がひつようだったか。
reference 本資料の元となった、我々のチーム(Kansai-kaggler)のソリューションです。 11th Place solution / RYUSHI(Team:Kansai-kaggler) https://qiita.com/DataRobot_PR/items/7e8195d1bcd11394ccaa Kaggleコンペ「UM -
Game-Playing Strength of MCTS Variants 」3位⼊賞解法徹底解説 / Senkin https://speakerdeck.com/rist/solution-um-game-playing-strength-of-mcts-variants モンテカルロ⽊探索のパフォーマンスを予測する Kaggleコンペ解説 〜⽣成AIによる未知のゲーム⽣成〜 / smly https://www.kaggle.com/competitions/um-game-playing-strength-of-mcts-variants/discussion/549708 Soloで3位⼊賞されたSenkin⽒の解説記事です。本コンペに限らず、テーブルコンペで⼤切な考え⽅を述べてくれています。 Rist Inc.による解説記事です。優勝解法が採⽤していたアプローチと⽣成AIによる未知のゲーム⽣成について詳しく説明しています。
reference 23位で銀メダルを獲られたmirandora⽒の振り返り記事です。solutionに加えて、⾦メダルとの差分を丁寧に分析しています。 Kaggle UMコンペ振り返り(Silver / 23th) / mirandora https://www.mirandora.com/?p=5076 https://zenn.dev/ryushi496/articles/ddd480808f6a86
kaggle(UM-MCTSコンペ)振り返り(11th Place) &上位解法 / RYUSHI ⼿前味噌ですが、私の記事です。参考になれば幸いです。 https://catboost.ai/docs/en/concepts/loss-functions-multiregression Multiregression: objectives and metrics Catboostのmultiregressionに関する公式ドキュメントです。
UM - Game-Playing Strength of MCTS Variants 11th. Place solution
Kaggle Competitions Master Ryushi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}