data • Reduce cognitive load on users • Drive business revenue -Netflix : 2/3 of the movies watched are recommended -Amazon: 35% sales generated via recommendations -Google News : 38% more clicks (CTR) via recommender
the era of search and entering one of discovery. What's the difference? Search is what you do when you're looking for something. Discovery is when something wonderful that you didn't know existed, or didn't know how to ask for, finds you. ” CNN Money, “The race to create a 'smart' Google” 2007 http://money.cnn.com/magazines/fortune/fortune_archive/2006/11/27/8394347
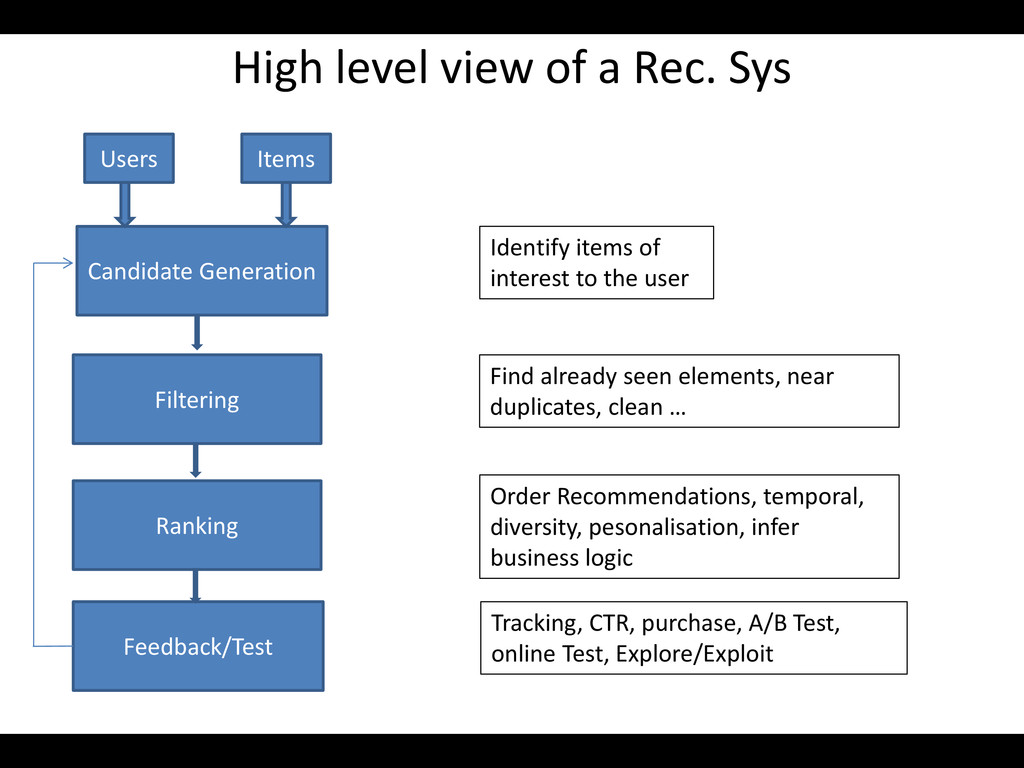
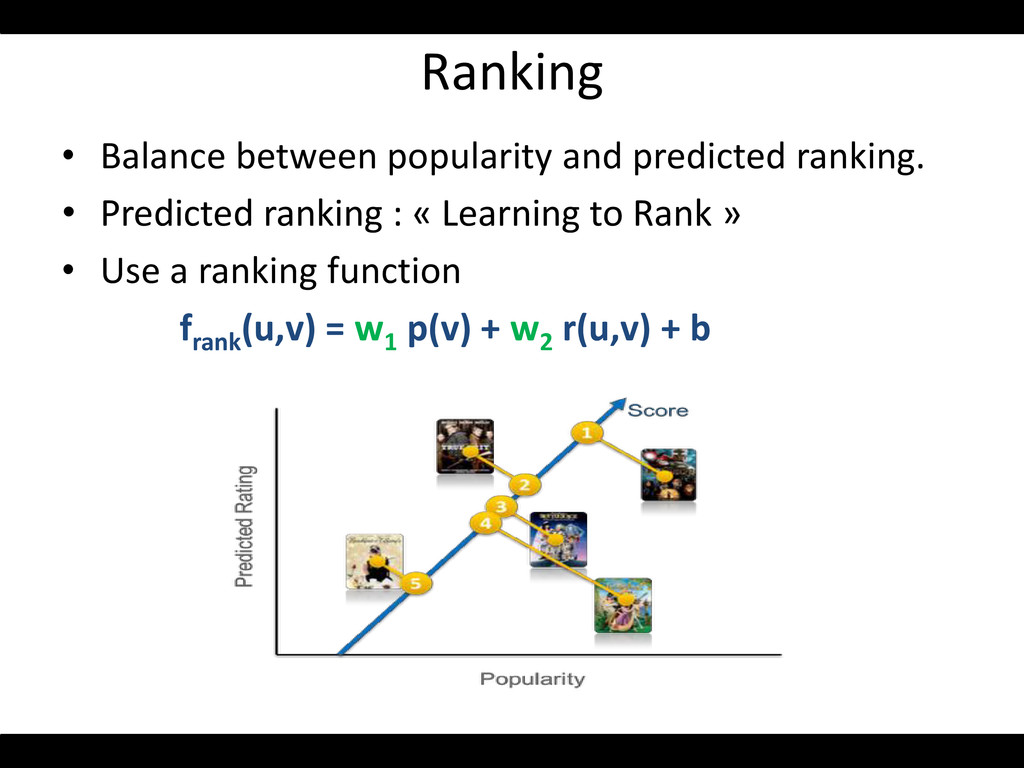
of interest to the user High level view of a Rec. Sys Candidate Generation Filtering Ranking Feedback/Test Users Items Find already seen elements, near duplicates, clean … Tracking, CTR, purchase, A/B Test, online Test, Explore/Exploit
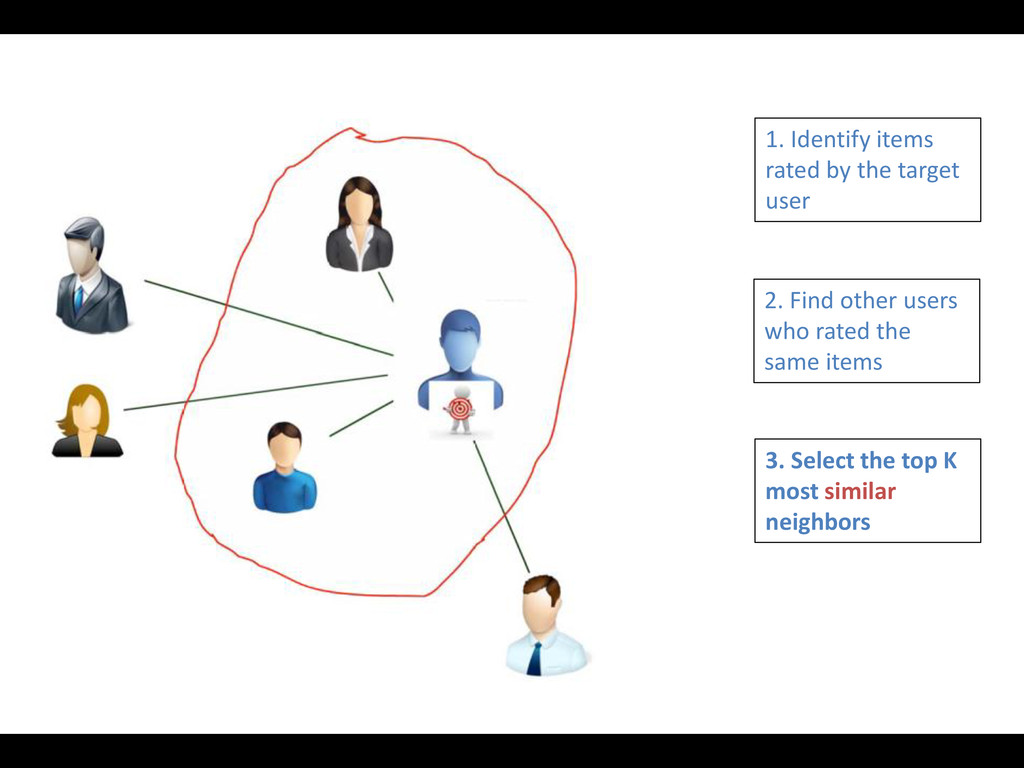
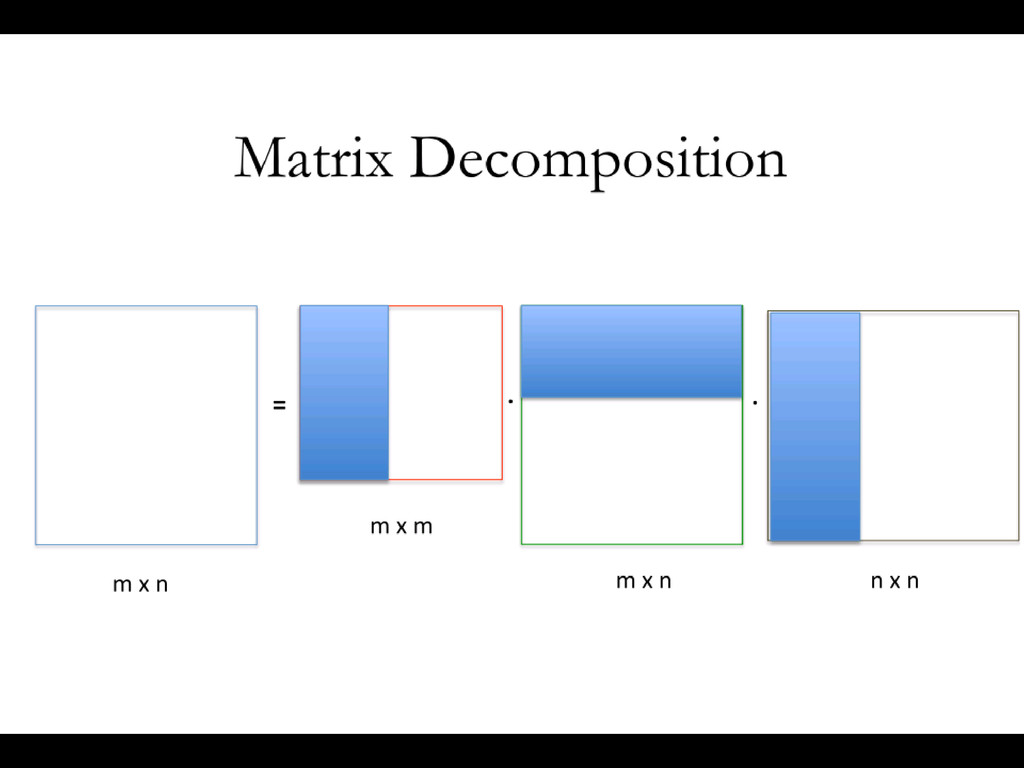
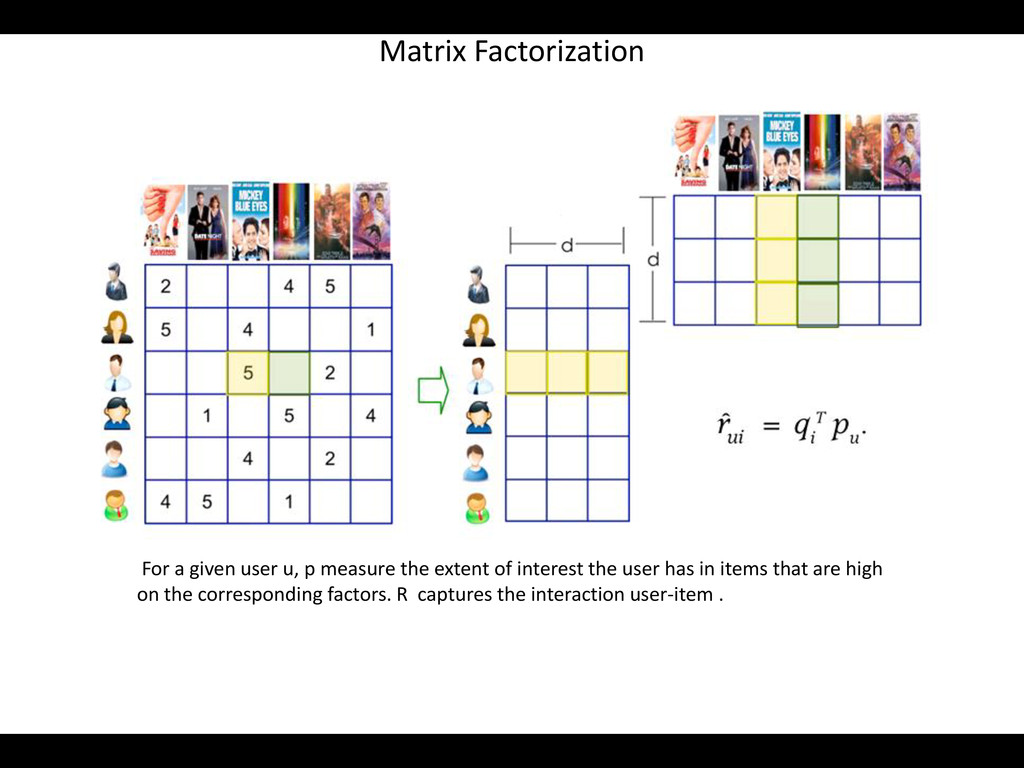
assuming that « Similar users tend to like similar items ». • Two appoaches : - Memory based CF * User based CF * Item based CF - Model based CF (Latent factors models) * Dimensionality Reduction(SVD o PCA) * Matrix Factorization
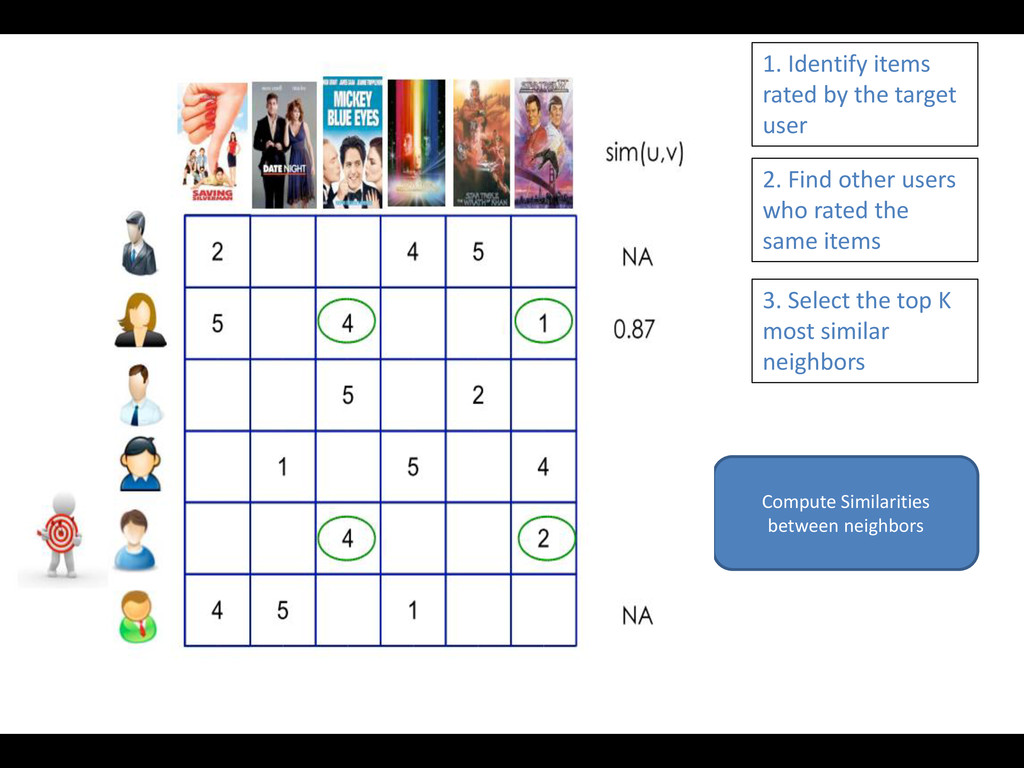
an item based on their ratings for other items 1. Identify the set of users who rated the target item 2. Find neighboring items 3. Compute similarities 4. Select top K similar items (Rank) 5. Predict rating for the target
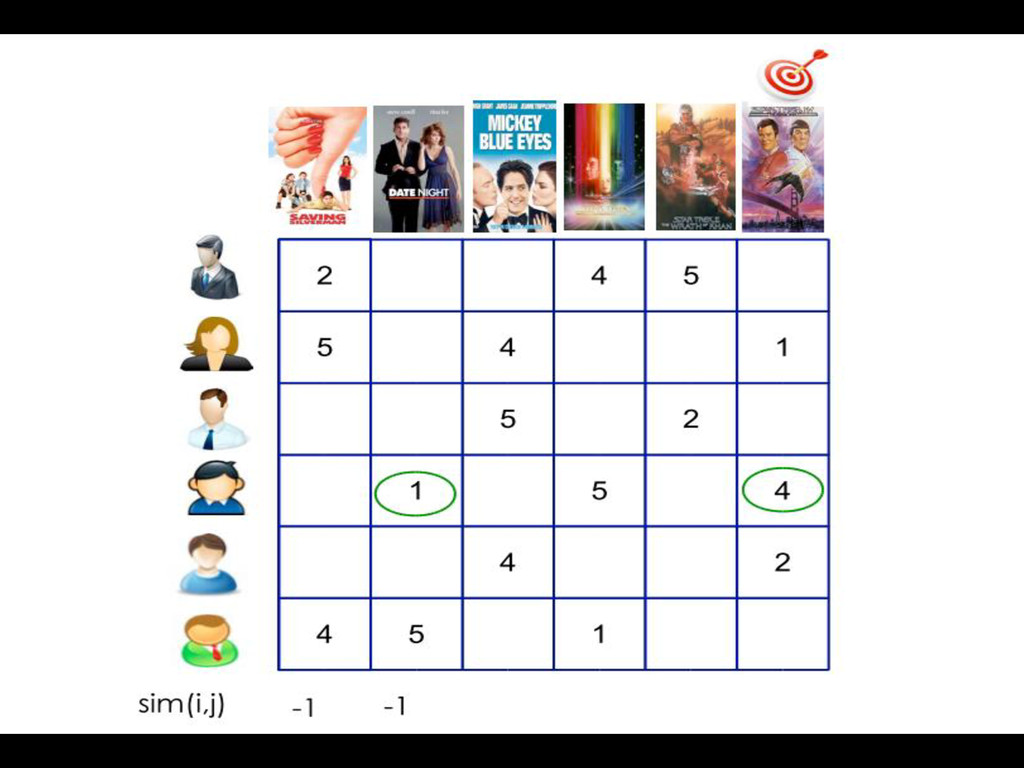
ratings bias • Cosine Similarity : Item are represeted vector ove user space. Similarity is the cosine of angle betwee two vectors : -1<=Sim(i,j) <=1 • Other similarities measures : Jaccard index, Magnitude aware measure …
poperties of data) rather from heuristics • Try to identify inter-relationships between between variables • Clustering • Dimensionality reduction (SVD) • Matrix Factorization
• Reduces dimensions and improve scalability • Reduce Data sparsity and improves prediction accuracy e.g User who likes « Star Trek» also likes « Star Gate » … Latent factor : Sci-fi, novel based …
9010. Strength of the preference: 8.699270 • Recommened Item Id 9012. Strength of the preference: 8.659677 • Recommened Item Id 9011. Strength of the preference: 8.377571 • Recommened Item Id 9004. Strength of the preference: 1.000000 • User Id: 1002 • Recommened Item Id 9012. Strength of the preference: 8.721395 • Recommened Item Id 9010. Strength of the preference: 8.523443 • Recommened Item Id 9011. Strength of the preference: 8.211071 • User Id: 1003 • Recommened Item Id 9012. Strength of the preference: 8.692321 • Recommened Item Id 9010. Strength of the preference: 8.613442 • Recommened Item Id 9011. Strength of the preference: 8.303847 • User Id: 1004 • No recommendations for this user. • User Id: 1005 • No recommendations for this user. • User Id: 1006 • No recommendations for this user.
is good? -Compare implementations, play with similarity measures - Test your recommenders : A/B Testing, Multi Armed Bandits • Business metrics - Does your recommender leads to increase value (CTR, sales, ..) • Leave one out - Remove one preferences, rebuild the model, see if recommended - Cross validation, … • Precision / Recall - Precision : Ratio of recommended items that are relevant - Recall : Ratio of relevant items actually recommended
items comes in remove the ones too similar to prior recommendation - Play with ranking to randomize Top K • Increase Serendipity - Downgrade too popular items …
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}