more finite operations, and a set of laws those operations must obey. “ e.g Sum, Magma, Semigroup, Groups, Monoid, Abelian Group, Semi Lattices, Rings, Monads, etc.
<> (y <> z) identity <> x = x x <> identity = x x <> inverse x = identity inverse x <> x = identity trait Group[T] extends Monoid[T]{ def inverse (v : T) :T }
min c) with Int. - a max ( b max c) = (a max b) max c ** - a or (b or c) = (a or b) or c - a and (b and c) = (a and b) and c - int addition - set union - harmonic sum - Integer mean - Priority queue
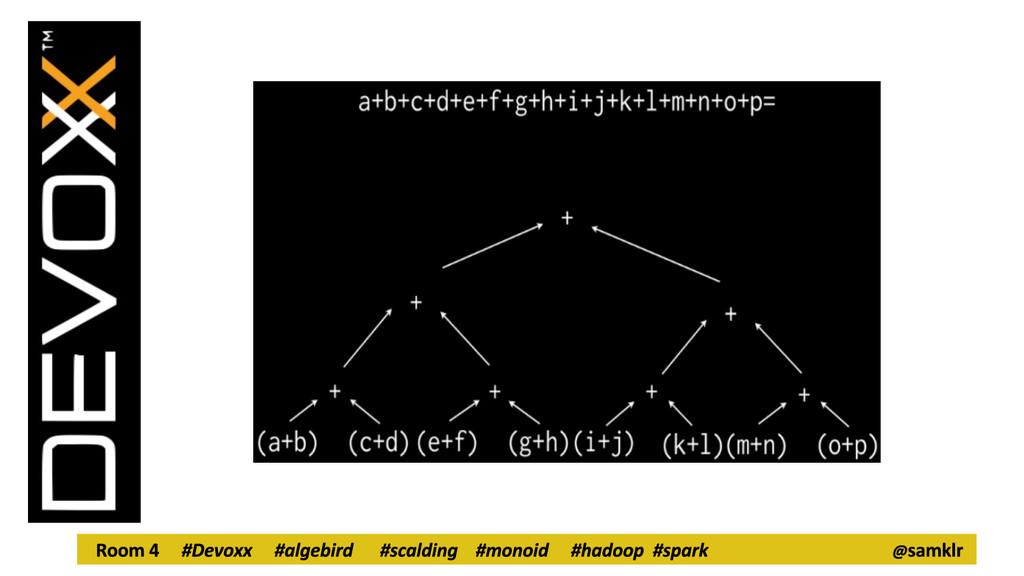
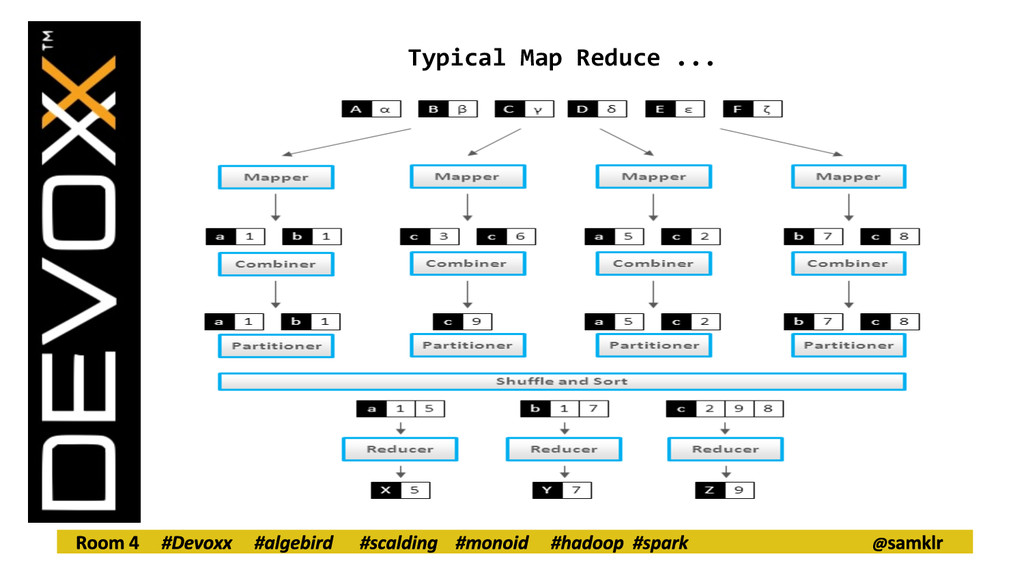
Leverage distributed computing to perform aggregation on really large data sets. - A lot of operations in analytics are just sorting and counting at the end of the day
extends Monoid[Priorityqueue[T] ] Let’s take a look : PQ1 : 55, 45, 21, 3 PQ2: 100, 80, 40, 3 top-4 (PQ1 U PQ2 ): 100, 80, 55, 45 Priority Queue : Can be empty Two Priority Queues can be “added” in any order Associative + Commutative
extends Monoid[Priorityqueue[T] ] Let’s take a look : PQ1 : 55, 45, 21, 3 PQ2: 100, 80, 40, 3 top-4 (PQ1 U PQ2 ): 100, 80, 55, 45 Priority Queue : Can be empty Two Priority Queues can be “added” in any order Associative + Commutative Makes Scalding go fast, by doing sorting, filtering and extracting in one single “map” step.
Single pass : can’t read old data or replay the stream - Full size of the stream often unknown - Limited time for computation per observation - O(1) memory size
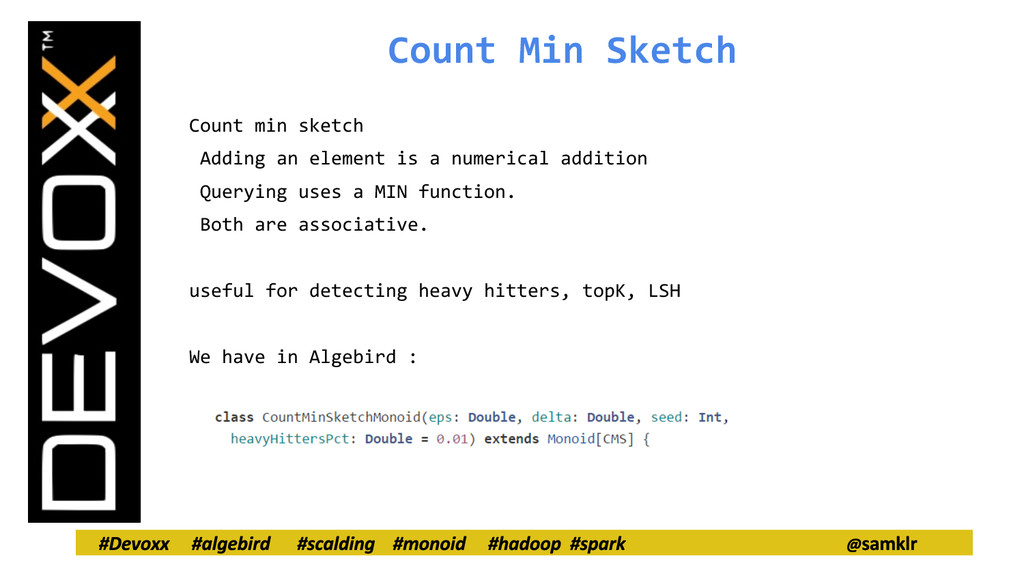
a data set that would be costly to store in its entirety, thus providing most of the time, sublinear algorithmic properties. E.g Bloom Filters, Counter Sketch, KMV counters, Count Min Sketch, HyperLogLog, Min Hashes
all element i, b[h(x,i)]=1 contains(x) : TRUE if b[h(x,i)] = = 1 for all i. (Boolean AND => associative) Both are associative => BF can be designed as a Monoid
val A = (1 to 300).toList // Generate a Bloomfilter val NUM_HASHES = 6 val WIDTH = 6000 // bits val SEED = 1 implicit val bfm = new BloomFilterMonoid(NUM_HASHES, WIDTH, SEED) // approximate set with bloomfilter val A_bf = A.map{i => bfm.create(i.toString)}.reduce(_ + _) val approxBool = A_bf.contains(“150”) ---> ApproximateBoolean(true, 0.9995…)
distribution of an error the number of distinct values in a data set. HLL.size = Approx[Number] Intuition Long runs of trailings 0 in a random bits chain are rare But the more bit chains you look at, the more likely you are to find a long one The longest run of trailing 0-bits seen can be an estimator of the number of unique bit chains observed.
are associative and Monoids. (Max is an ordered semigroup in Algebird really) Querying for an element uses an harmonic mean which is a Monoid. In Algebird :
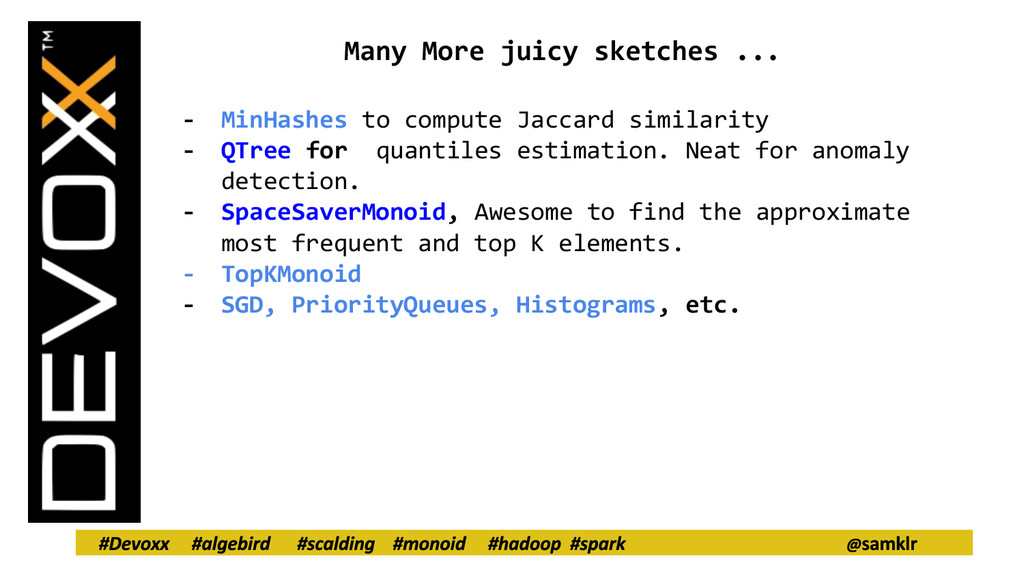
similarity - QTree for quantiles estimation. Neat for anomaly detection. - SpaceSaverMonoid, Awesome to find the approximate most frequent and top K elements. - TopKMonoid - SGD, PriorityQueues, Histograms, etc.
- Take a look into HLearn https://github.com/mikeizbicki/HLearn - Great intro into Algebird by Michael Noll http://www.michael-noll.com/blog/2013/12/02/twitter-algebird-monoid- monad-for-large-scala-data-analytics/ -Aggregate Knowledge http://research.neustar.biz/2012/10/25/sketch-of- the-day-hyperloglog-cornerstone-of-a-big-data-infrastructure - Probabilistic data structures for web analytics. http://highlyscalable.wordpress.com/2012/05/01/probabilistic- structures-web-analytics-data-mining/ - http://debasishg.blogspot.fr/2014/01/count-min-sketch-data- structure-for.html - http://infolab.stanford.edu/~ullman/mmds/ch3.pdf Links
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![class PiorityQueueMonoid[T] (max : Int) (implicit order : Ordering[T] )](https://files.speakerdeck.com/presentations/870487004b1d013241400a4dd3cf94f0/slide_27.jpg){kind=link}
![class PiorityQueueMonoid[T] (max : Int) (implicit order : Ordering[T] )](https://files.speakerdeck.com/presentations/870487004b1d013241400a4dd3cf94f0/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}