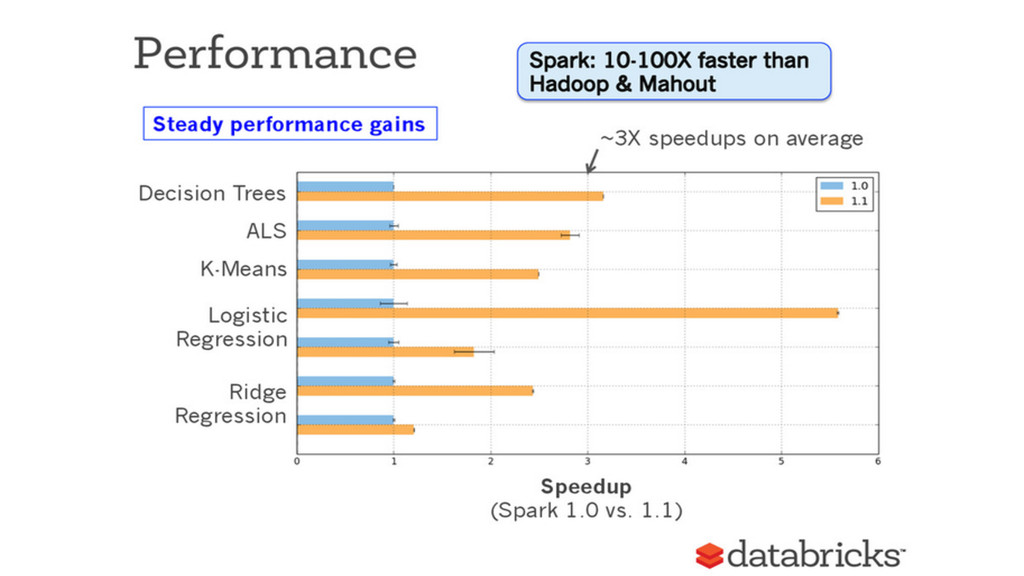
push towards faster execution platforms and real time predictions engines. • Traditional MapReduce on Hadoop is fading away, especially for Machine Learning • Apache Spark has become the darling of the Big Data world, thanks to its high level API and performances. • Rise of Machine Learning public APIs to easily integrate models into application and other data processing workflows.
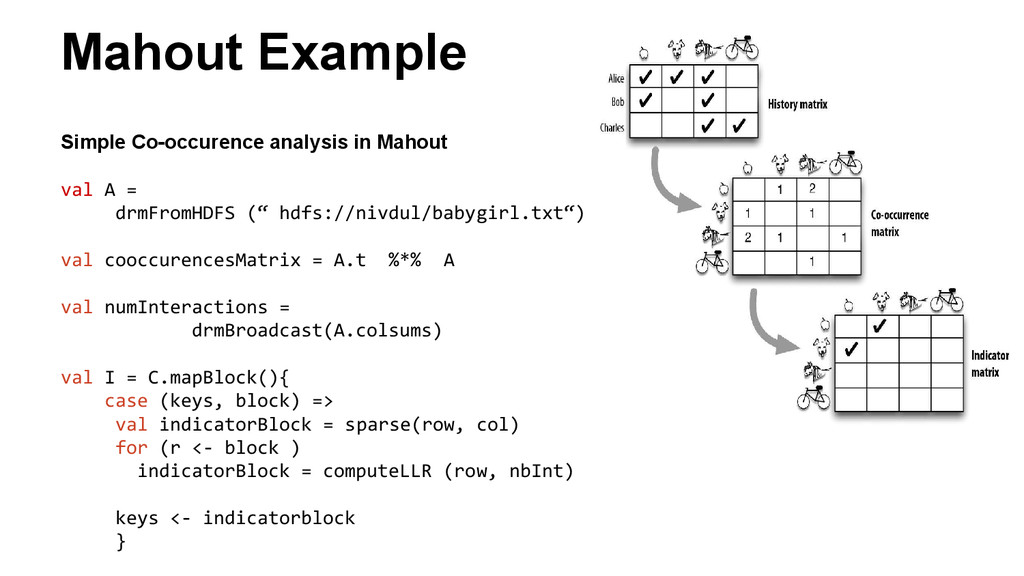
drmFromHDFS (“ hdfs://nivdul/babygirl.txt“) val cooccurencesMatrix = A.t %*% A val numInteractions = drmBroadcast(A.colsums) val I = C.mapBlock(){ case (keys, block) => val indicatorBlock = sparse(row, col) for (r <- block ) indicatorBlock = computeLLR (row, nbInt) keys <- indicatorblock }
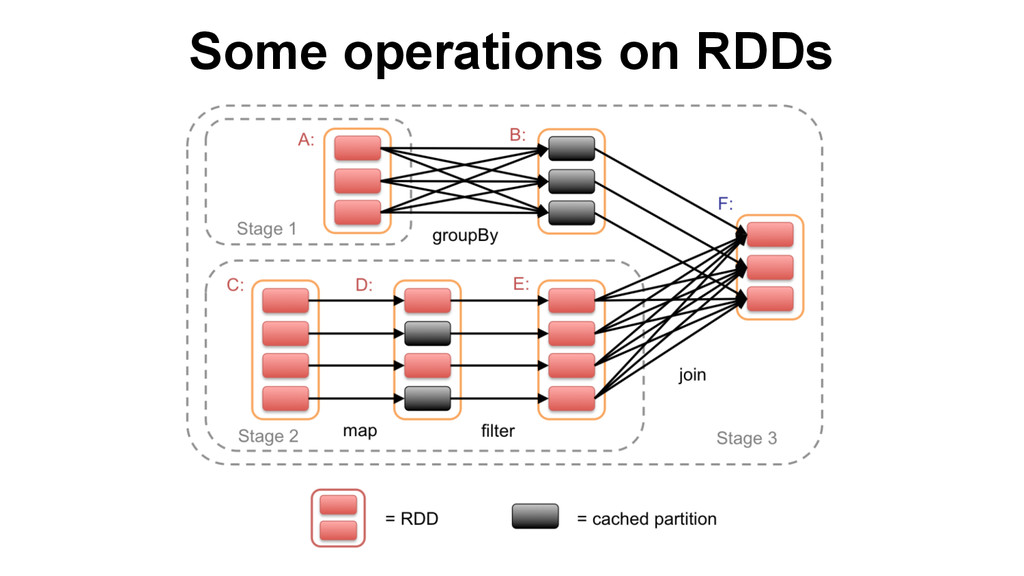
suited for iterative and complex transformations, like in most Machine Learning algorithms. Those in-memory collections are called Resilient Distributed Datasets (RDD) They provide : • Partitioned data • High level operations (map, filter, collect, reduce, zip, join, sample, etc …) • No side effects • Fault recovery via lineage
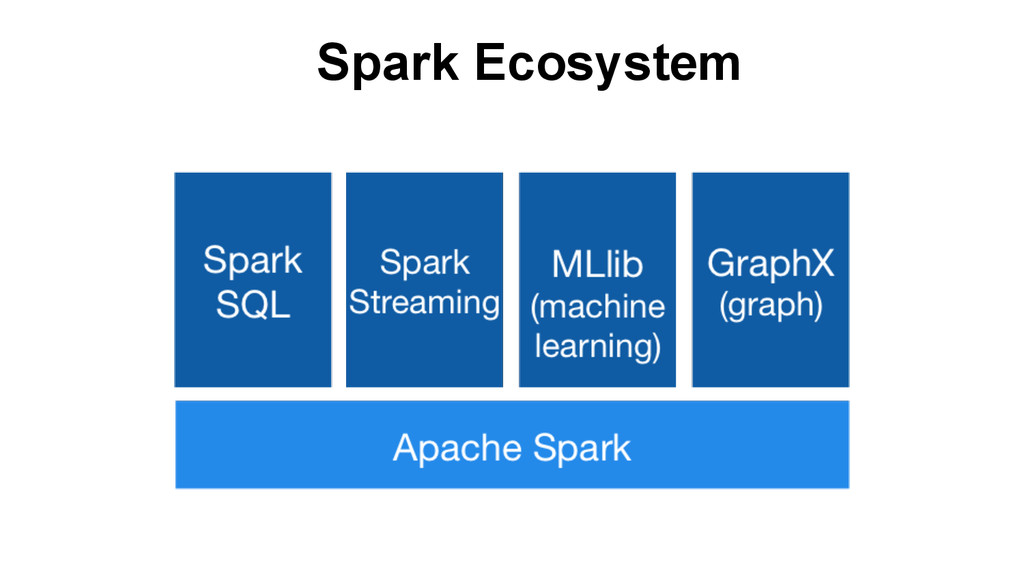
integrated predictive and data analysis workflow • Broad collections of algorithms and applications • Integrates with the whole Spark Ecosystem Three APIs in :
data = sc.textFile(“hdfs://bbgrl/dataset.txt”) val parsedData = data.map { x => Vectors.dense(x.split(“ “).map.(_.toDouble )) }. cache() //Cluster data into 5 classes using K-means val clusters = Kmeans.train(parsedData, k=5, numIterations=20 ) //Evaluate model error val cost = clusters.computeCost(parsedData)
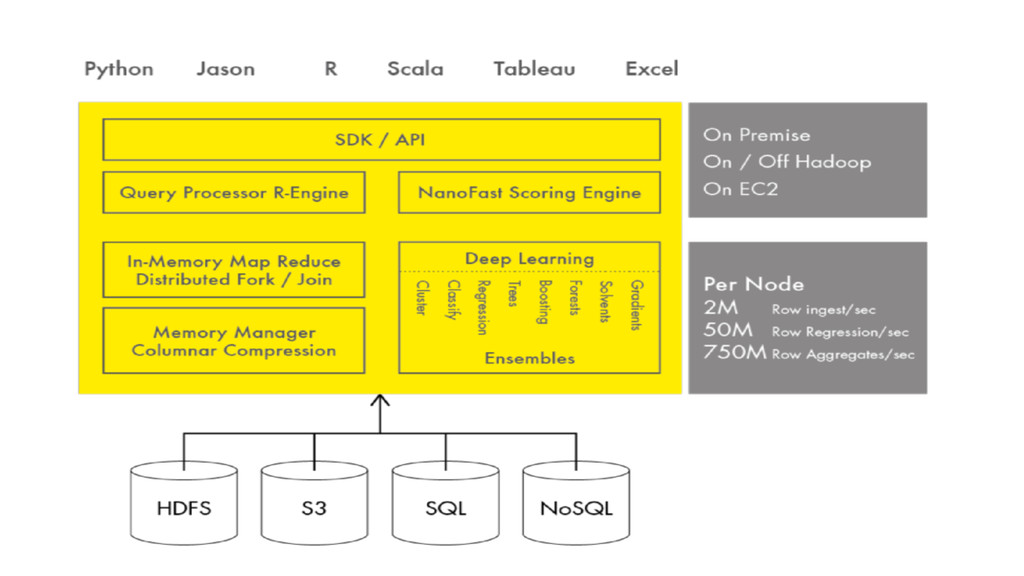
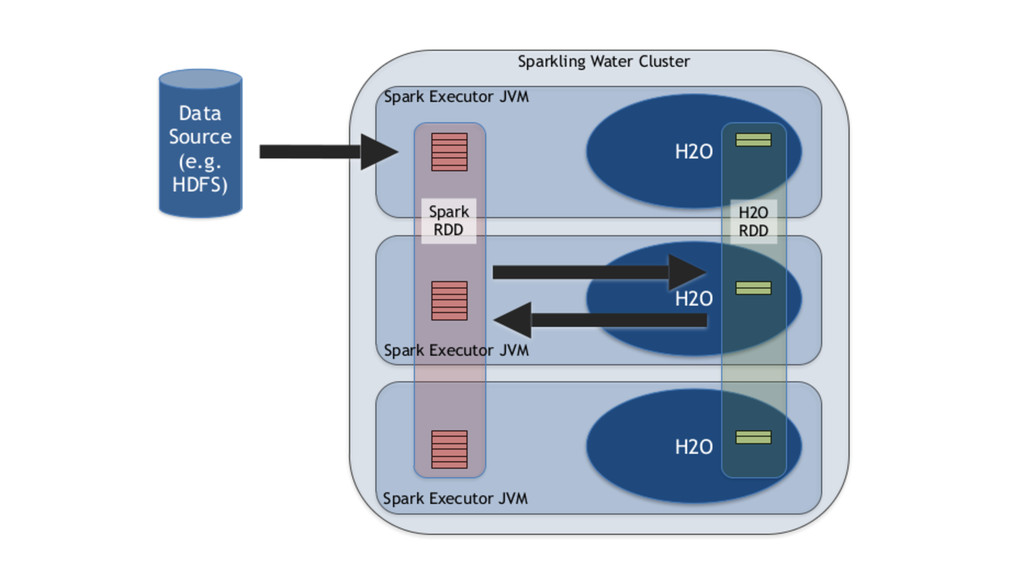
Machine Learning and maths engine on the JVM. • Edited by 0xdata (commercial entity) and focus on bringing robust and highly performant machine learning algorithms to popular Big Data workloads. • Has APIs in R, Java, Scala and Python and integrates to third parties tools like Tableau and Excel.
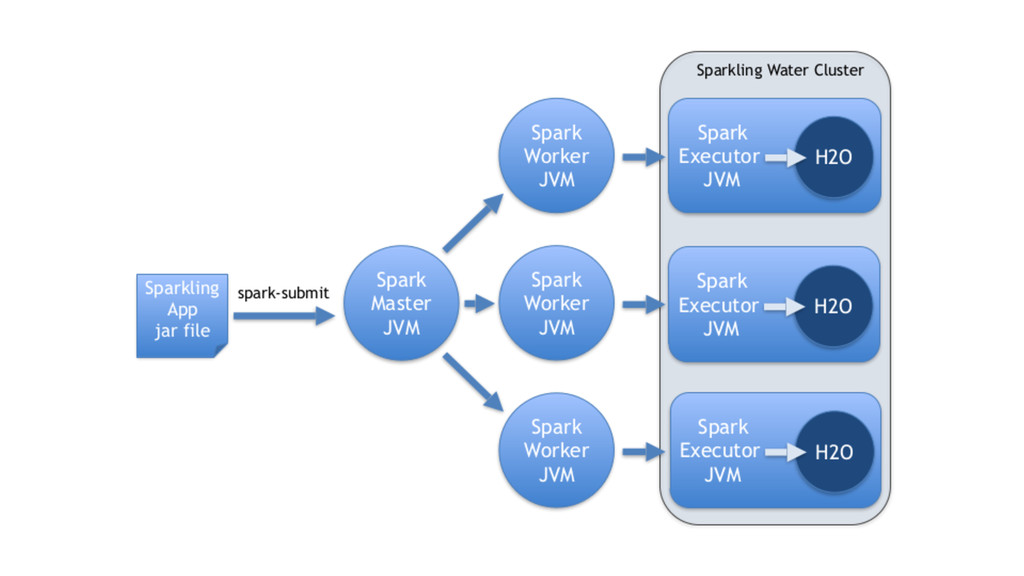
implicits for conversions val h2oContext = new H2OContext(sc) import h2oContext._ // Create RDD wrapper around DataFrame val airlinesTable : RDD[Airlines] = toRDD[Airlines](airlinesData) airlinesTable.count // And use Spark RDD API directly val flightsOnlyToSF = airlinesTable.filter(f => f.Dest==Some("SFO") || f.Dest==Some("SJC") || f.Dest==Some("OAK") ) flightsOnlyToSF.count
new DeepLearningParameters() dlParams._training_frame = result( 'Year, 'Month, 'DayofMonth, DayOfWeek, 'CRSDepTime, 'CRSArrTime,'UniqueCarrier, FlightNum, 'TailNum, 'CRSElapsedTime, 'Origin, 'Dest,'Distance,‘IsDepDelayed) dlParams.response_column = 'IsDepDelayed.name // Create a new model builder val dl = new DeepLearning(dlParams) val dlModel = dl.train.get
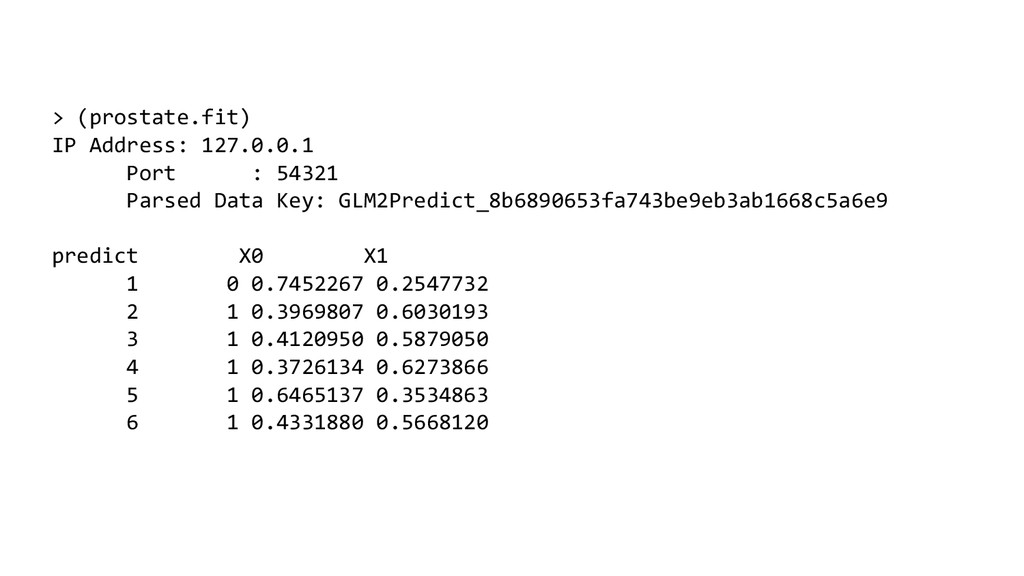
dlModel.score(result)(‘predict) // Collect predicted values via the RDD API val predictionValues = toRDD[DoubleHolder](prediction) .collect .map ( _.result.getOrElse("NaN") )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}