文字集合 + 符号化方式(エンコーディング) のように、2つの概念の組み合わせ 文字集合 = どの文字を扱えるか(ASCII, JIS X 0201, JIS X 0208, JIS X 0221 など) 例) ASCIIでは「1」「A」は含まれるが「カ」「カ」「漢」は含まれない JIS X 0201 というJIS規格では「1」「A」「カ」は含まれるが「カ」「漢」は含まれない (→Shift_JISで言う1Byte文字の集合) JIS X 0208 というJIS規格では「漢」という字が含まれており、コードポイントは20-33 符号化方式 = どうビット列に変換するか(Shift_JIS, EUC-JP, UTF-8, UTF-16など) 例) コードポイント20-33の文字(「漢」)はShift_JIS では16進数で8A BFに変換されるが、 UTF-8ではE6 BC A2、UTF-16では 6F 22に変換される Shift_JISなどの文字コードは複数の文字集合(JIS X 0201 と JIS X 0208など)を組み合わせ て符号化しています。
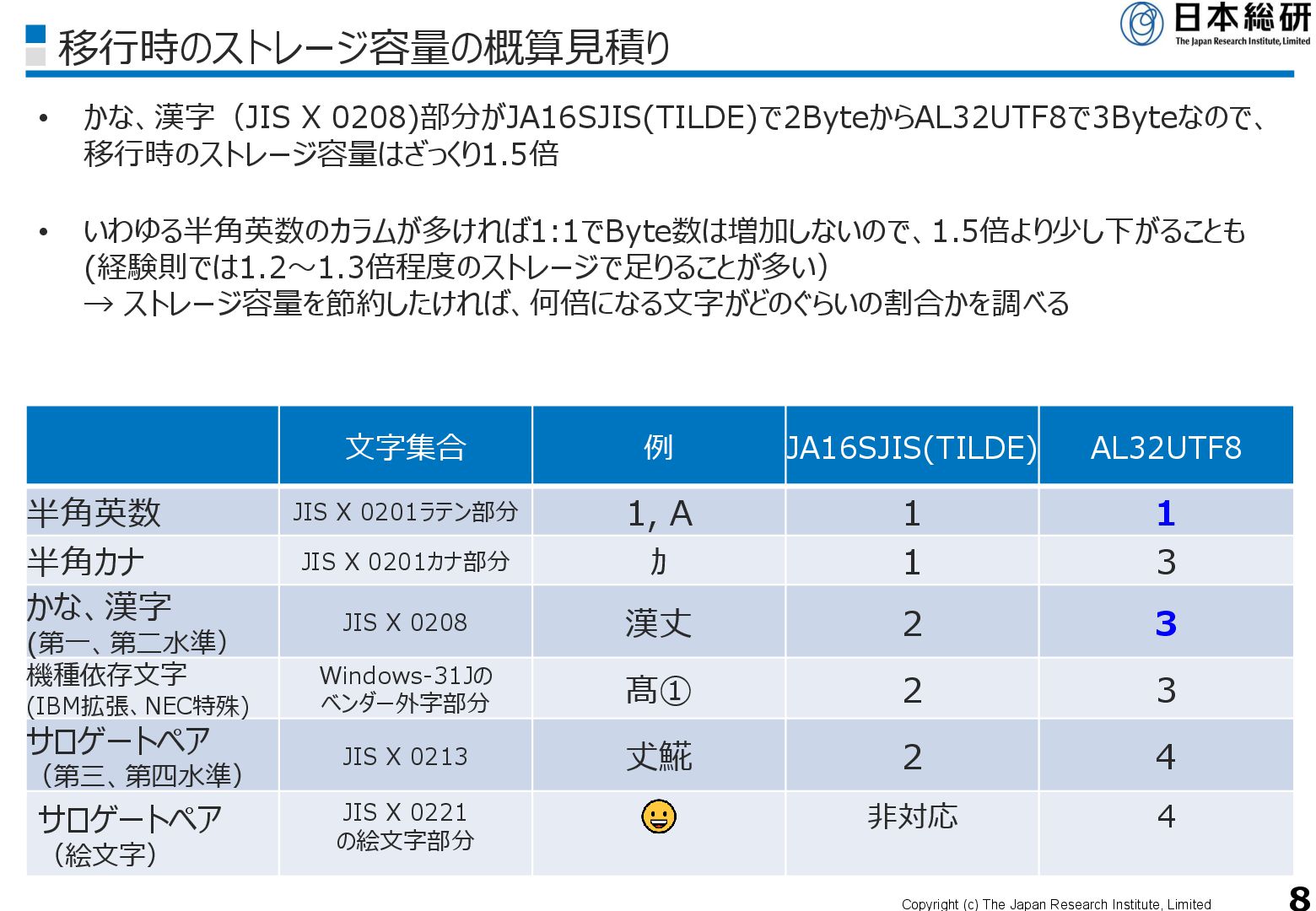
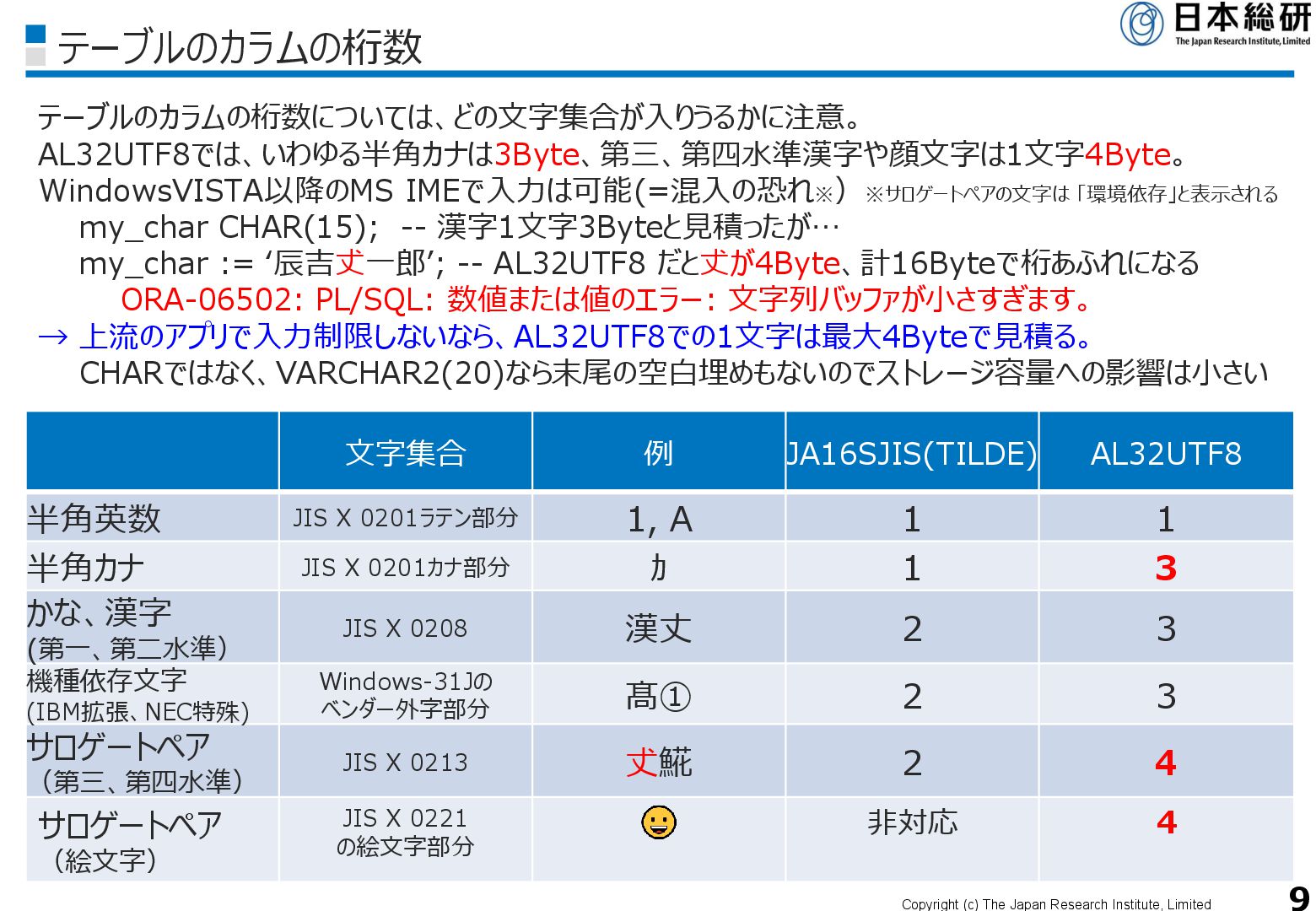
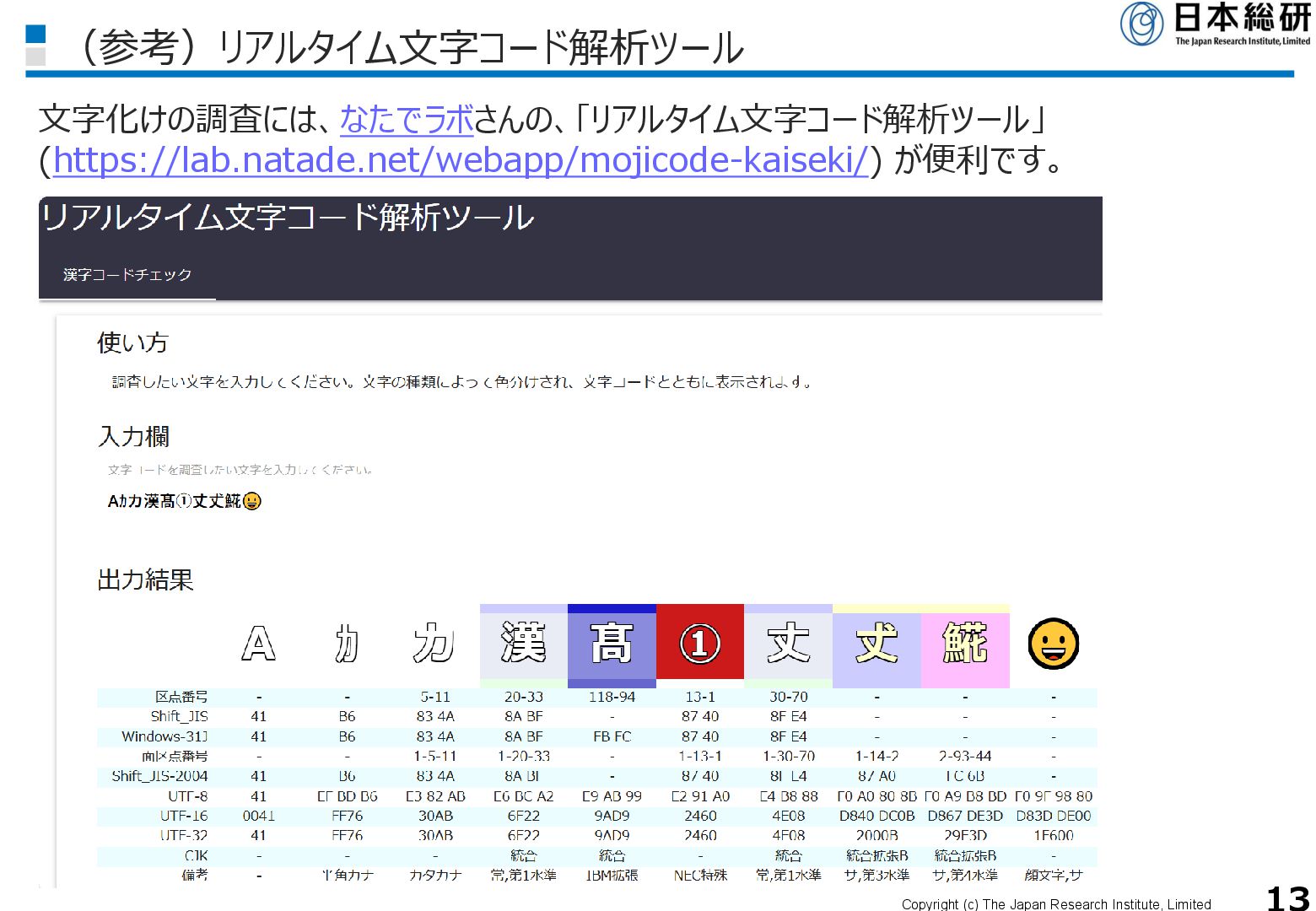
X 0208)部分がJA16SJIS(TILDE)で2ByteからAL32UTF8で3Byteなので、 移行時のストレージ容量はざっくり1.5倍 • いわゆる半角英数のカラムが多ければ1:1でByte数は増加しないので、1.5倍より少し下がることも (経験則では1.2~1.3倍程度のストレージで足りることが多い) → ストレージ容量を節約したければ、何倍になる文字がどのぐらいの割合かを調べる 文字集合 例 JA16SJIS(TILDE) AL32UTF8 半角英数 JIS X 0201ラテン部分 1, A 1 1 半角カナ JIS X 0201カナ部分 カ 1 3 かな、漢字 (第一、第二水準) JIS X 0208 漢丈 2 3 機種依存文字 (IBM拡張、NEC特殊) Windows-31Jの ベンダー外字部分 髙① 2 3 サロゲートペア (第三、第四水準) JIS X 0213 𠀋𩸽 2 4 サロゲートペア (絵文字) JIS X 0221 の絵文字部分 非対応 4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}