Share
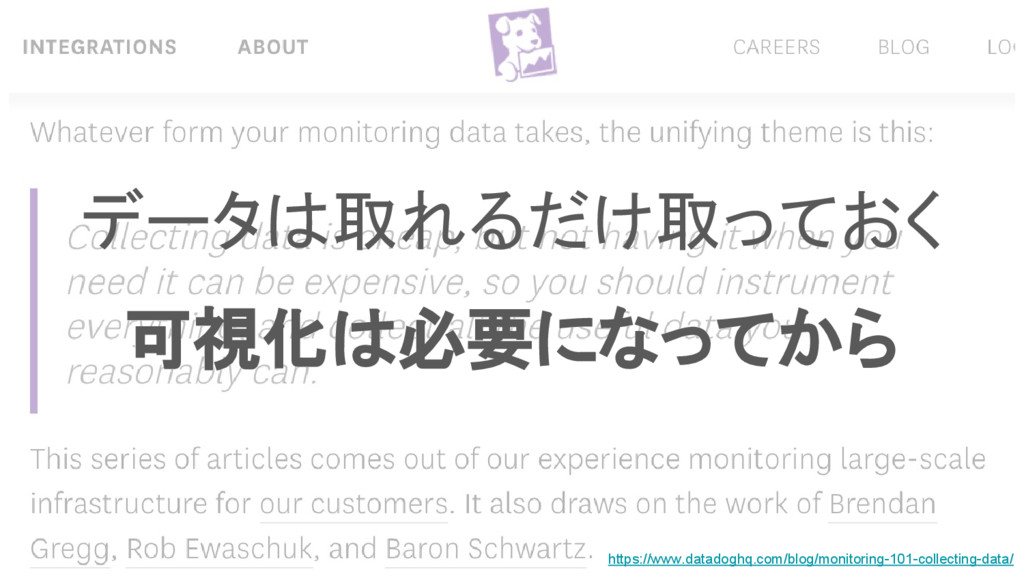
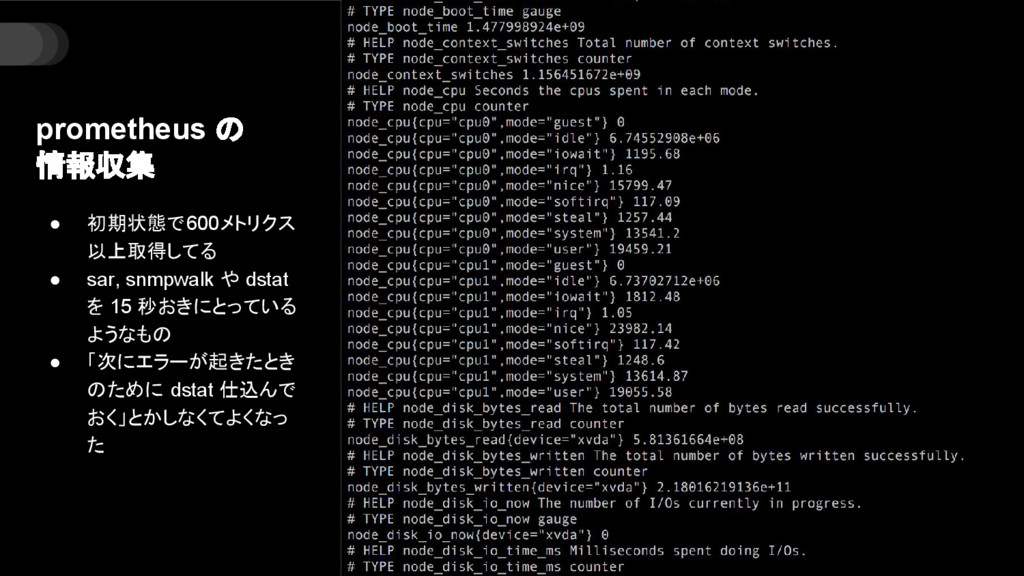
2017/01/19 『【freee×プレイド】Tech Meetup 〜インフラ監視編〜』の LT 発表資料です。 Prometheus を使っていく中で、監視に対する考え方が変化してきたので、それについてまとめてみました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}