Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kaggle本輪読会_3章後半_20191211
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
syaorn_13
December 11, 2019
1k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kaggle本輪読会_3章後半_20191211
「Kaggleで勝つデータ分析の技術」の輪読会資料です。
https://gihyo.jp/book/2019/978-4-297-10843-4
syaorn_13
December 11, 2019
More Decks by syaorn_13
See All by syaorn_13
Kaggle M5 Forecasting - Accuracy 42nd place solution
syaorn_13
4
12k
Kaggle DSB2019 58th place solution
syaorn_13
2
540
APTOSコンペ振り返り_207th(銅メダル)
syaorn_13
0
870
Featured
See All Featured
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
30 Presentation Tips
portentint
PRO
1
350
HDC tutorial
michielstock
2
750
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
YesSQL, Process and Tooling at Scale
rocio
174
15k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Transcript
Kaggleで勝つデータ分析の技術 ジョブカレ輪読会 第3回 2019/12/11 藤本 海人
自己紹介 2 名前:藤本 海人 (Fujimoto Kaito) 所属:ブレインパッド (2019/10~) 職種:データサイエンティスト 趣味:Kaggle
(contributor) Twitter_ID:syaorn_13
今日の内容 3 3章(特徴量作成)の後半戦です 8. 他のテーブルと結合 9. 集約して統計量をとる 10. 時系列データの扱い 11.
次元削減・教師なし学習による特徴量 12. その他テクニック 13. 分析コンペにおける特徴量作成の例
前置き 4 気軽に指摘や質問してください • 理解が怪しい箇所がたくさんあります • 全員で知見を共有しあう場にしたいです
3.8 他のテーブルと結合
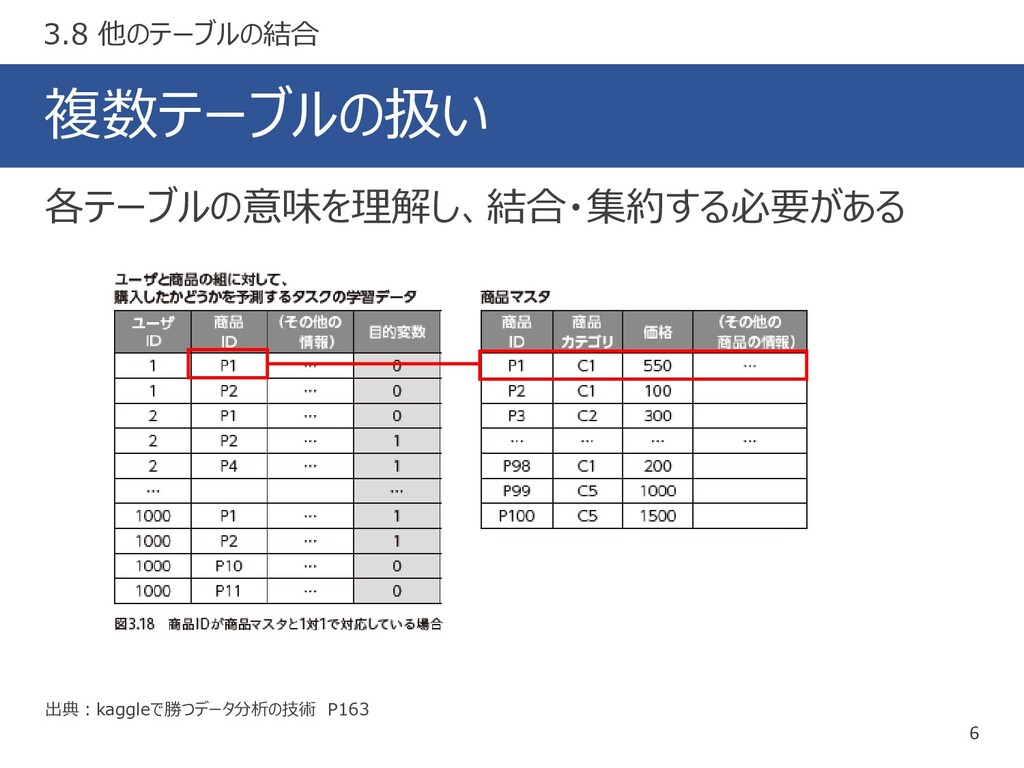
複数テーブルの扱い 6 出典:kaggleで勝つデータ分析の技術 P163 各テーブルの意味を理解し、結合・集約する必要がある 3.8 他のテーブルの結合
3.9 集約して統計量をとる
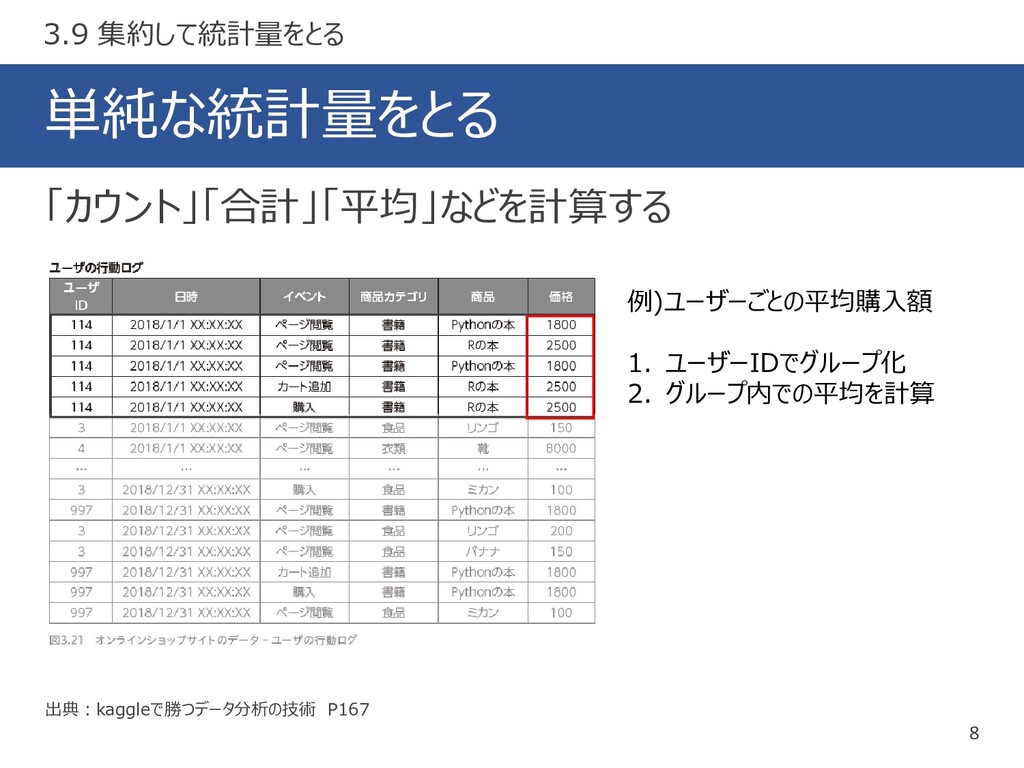
単純な統計量をとる 8 出典:kaggleで勝つデータ分析の技術 P167 「カウント」「合計」「平均」などを計算する 3.9 集約して統計量をとる 例)ユーザーごとの平均購入額 1. ユーザーIDでグループ化
2. グループ内での平均を計算
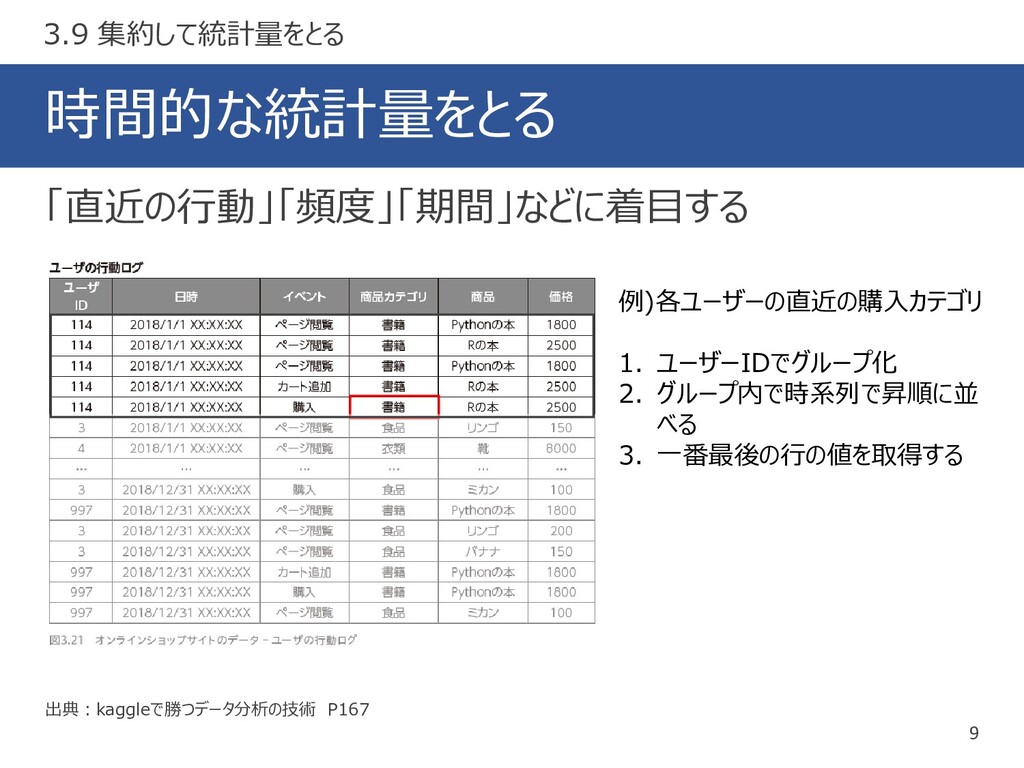
時間的な統計量をとる 9 出典:kaggleで勝つデータ分析の技術 P167 「直近の行動」「頻度」「期間」などに着目する 3.9 集約して統計量をとる 例)各ユーザーの直近の購入カテゴリ 1. ユーザーIDでグループ化
2. グループ内で時系列で昇順に並 べる 3. 一番最後の行の値を取得する
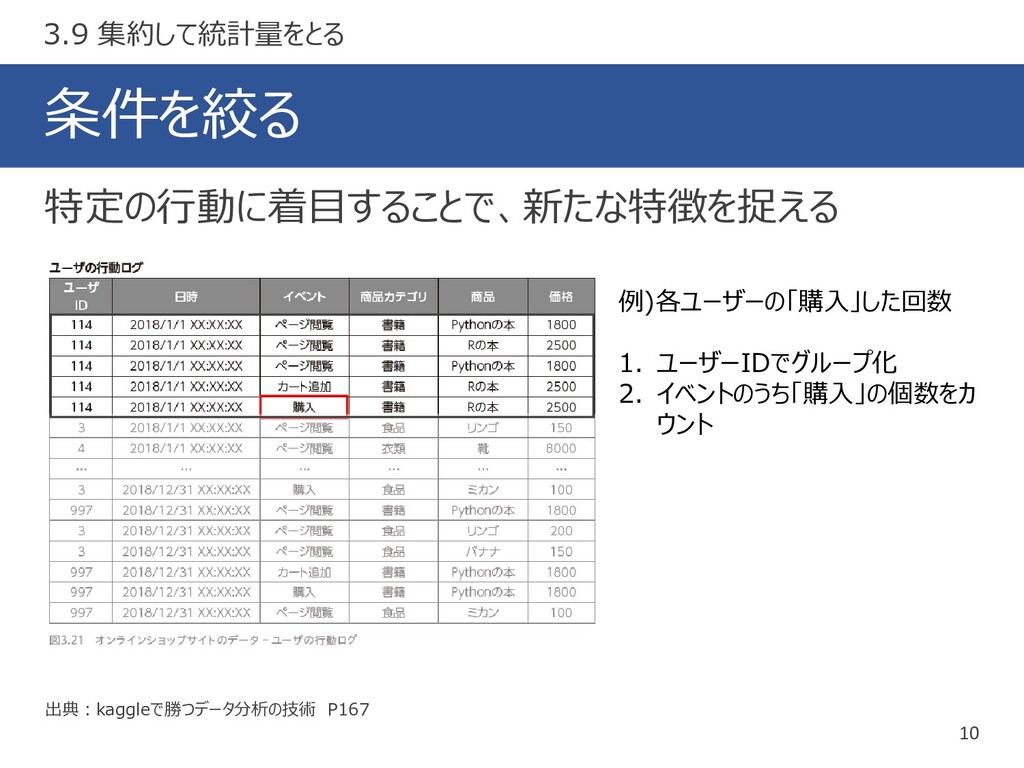
条件を絞る 10 出典:kaggleで勝つデータ分析の技術 P167 特定の行動に着目することで、新たな特徴を捉える 3.9 集約して統計量をとる 例)各ユーザーの「購入」した回数 1. ユーザーIDでグループ化
2. イベントのうち「購入」の個数をカ ウント
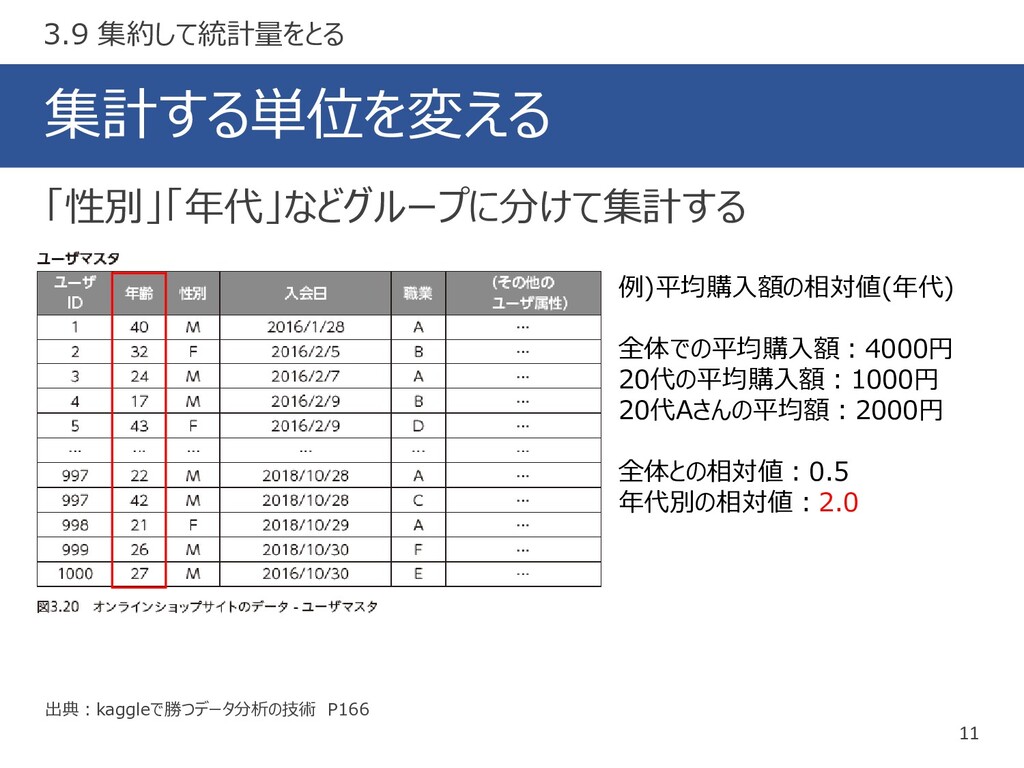
集計する単位を変える 11 出典:kaggleで勝つデータ分析の技術 P166 「性別」「年代」などグループに分けて集計する 3.9 集約して統計量をとる 例)平均購入額の相対値(年代) 全体での平均購入額:4000円 20代の平均購入額:1000円
20代Aさんの平均額:2000円 全体との相対値:0.5 年代別の相対値:2.0
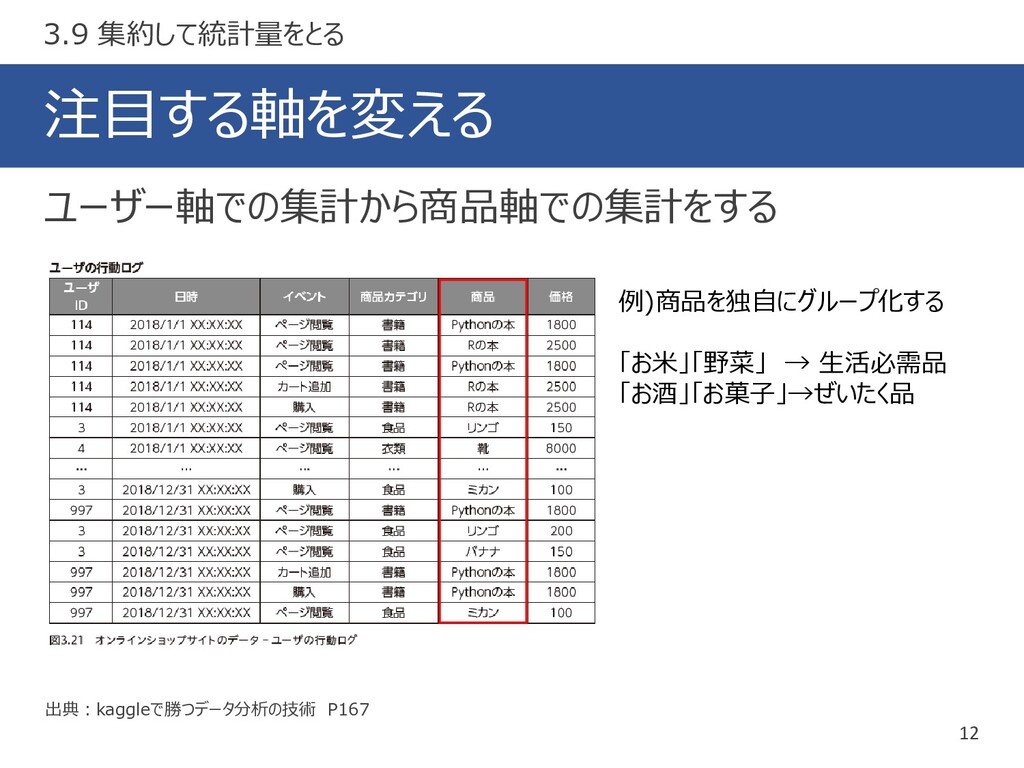
注目する軸を変える 12 ユーザー軸での集計から商品軸での集計をする 3.9 集約して統計量をとる 例)商品を独自にグループ化する 「お米」「野菜」 → 生活必需品 「お酒」「お菓子」→ぜいたく品
出典:kaggleで勝つデータ分析の技術 P167
3.10 時系列データの扱い
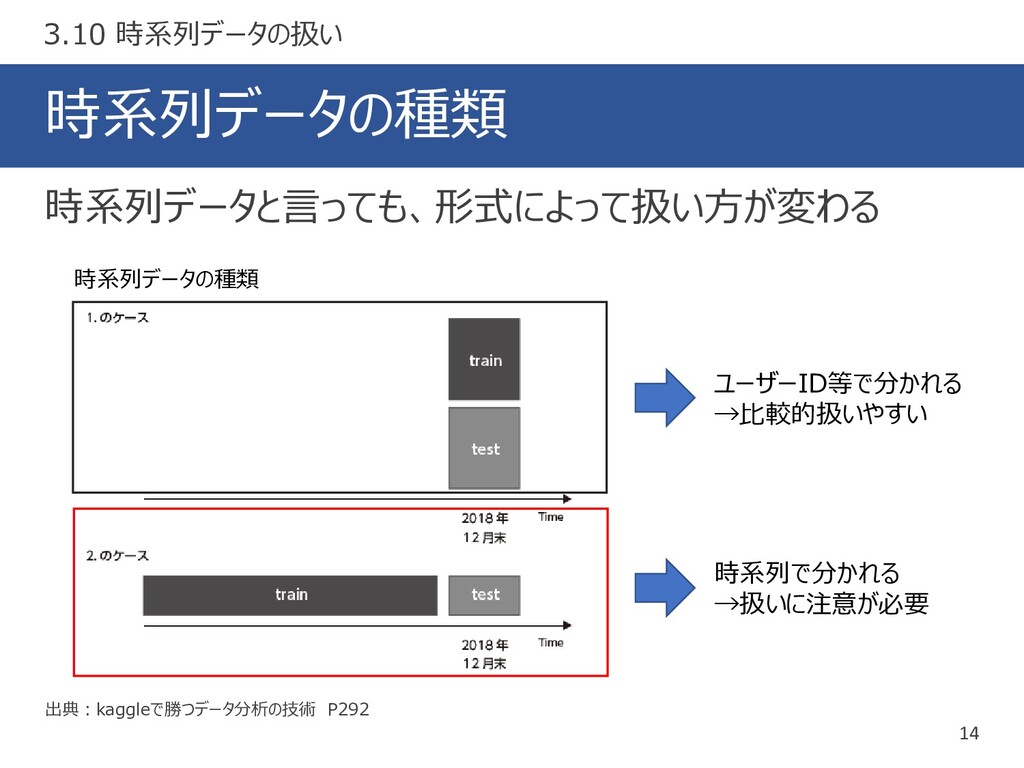
時系列データの種類 14 出典:kaggleで勝つデータ分析の技術 P292 時系列データと言っても、形式によって扱い方が変わる 3.10 時系列データの扱い 時系列で分かれる →扱いに注意が必要 ユーザーID等で分かれる
→比較的扱いやすい 時系列データの種類
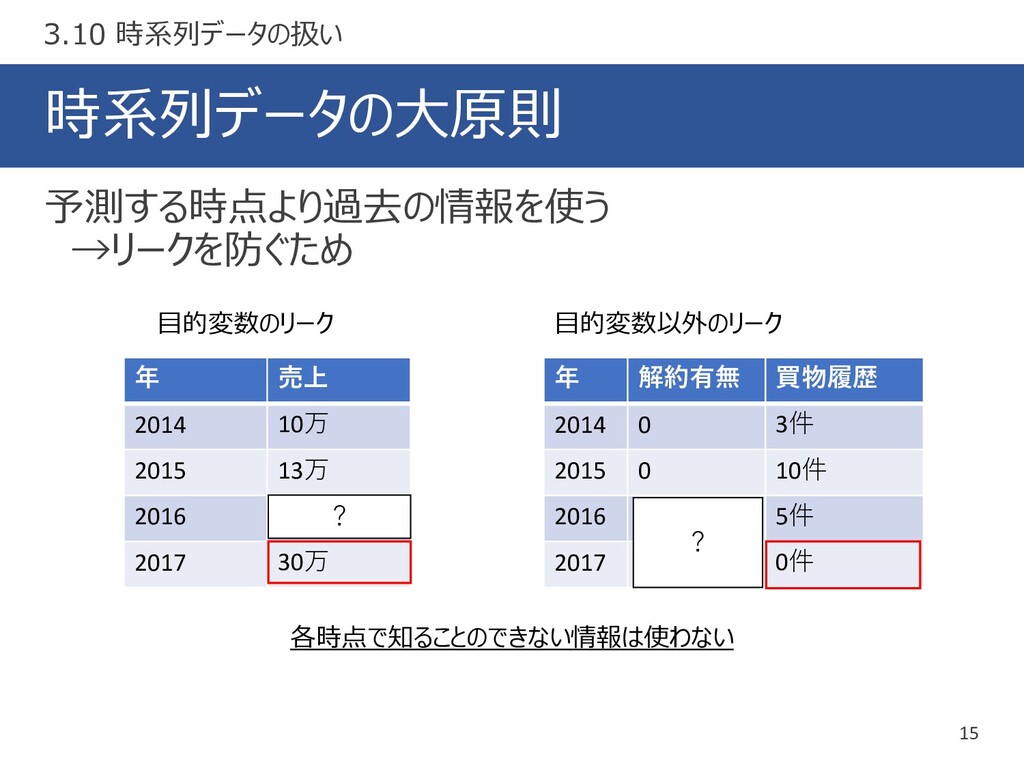
時系列データの大原則 15 予測する時点より過去の情報を使う →リークを防ぐため 3.10 時系列データの扱い 年 売上 2014 10万
2015 13万 2016 2017 30万 ? 目的変数のリーク 目的変数以外のリーク 年 解約有無 買物履歴 2014 0 3件 2015 0 10件 2016 5件 2017 0件 ? 各時点で知ることのできない情報は使わない
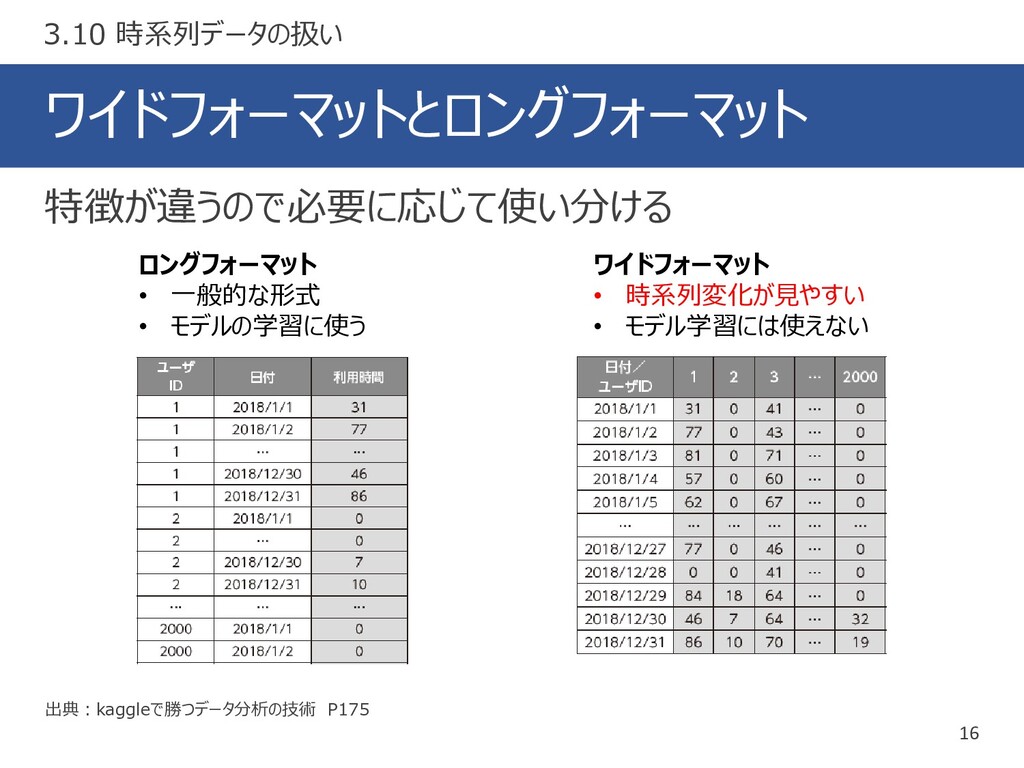
ワイドフォーマットとロングフォーマット 16 出典:kaggleで勝つデータ分析の技術 P175 特徴が違うので必要に応じて使い分ける 3.10 時系列データの扱い ロングフォーマット • 一般的な形式
• モデルの学習に使う ワイドフォーマット • 時系列変化が見やすい • モデル学習には使えない
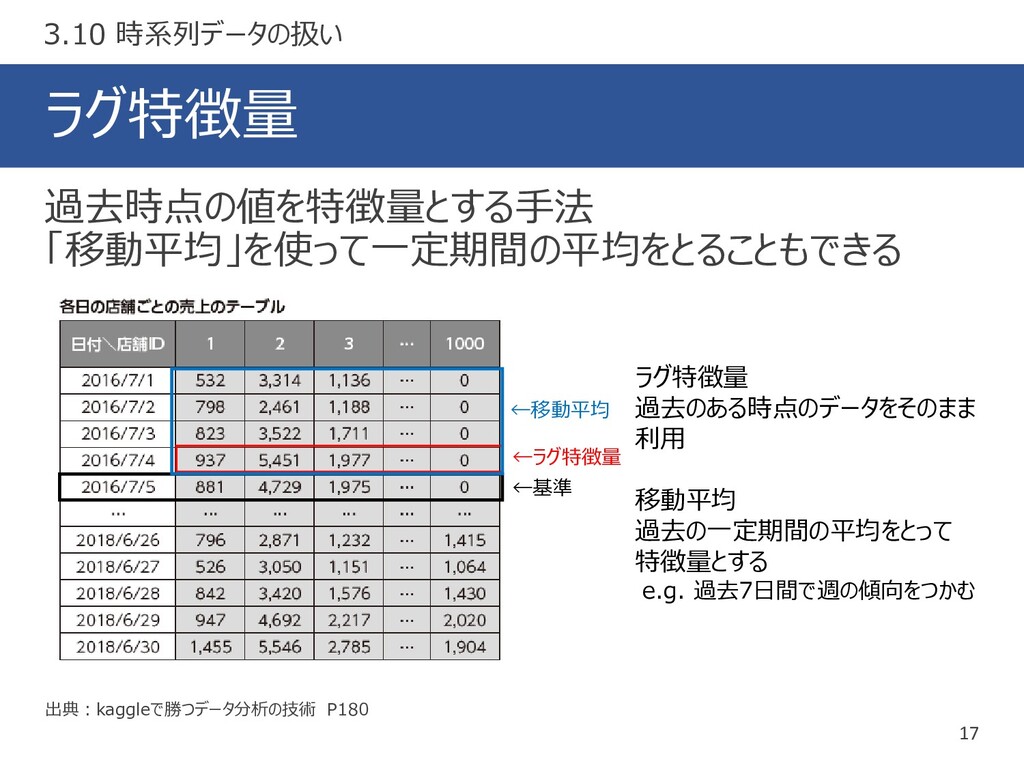
ラグ特徴量 17 出典:kaggleで勝つデータ分析の技術 P180 過去時点の値を特徴量とする手法 「移動平均」を使って一定期間の平均をとることもできる 3.10 時系列データの扱い ラグ特徴量 過去のある時点のデータをそのまま
利用 移動平均 過去の一定期間の平均をとって 特徴量とする e.g. 過去7日間で週の傾向をつかむ ←基準 ←ラグ特徴量 ←移動平均
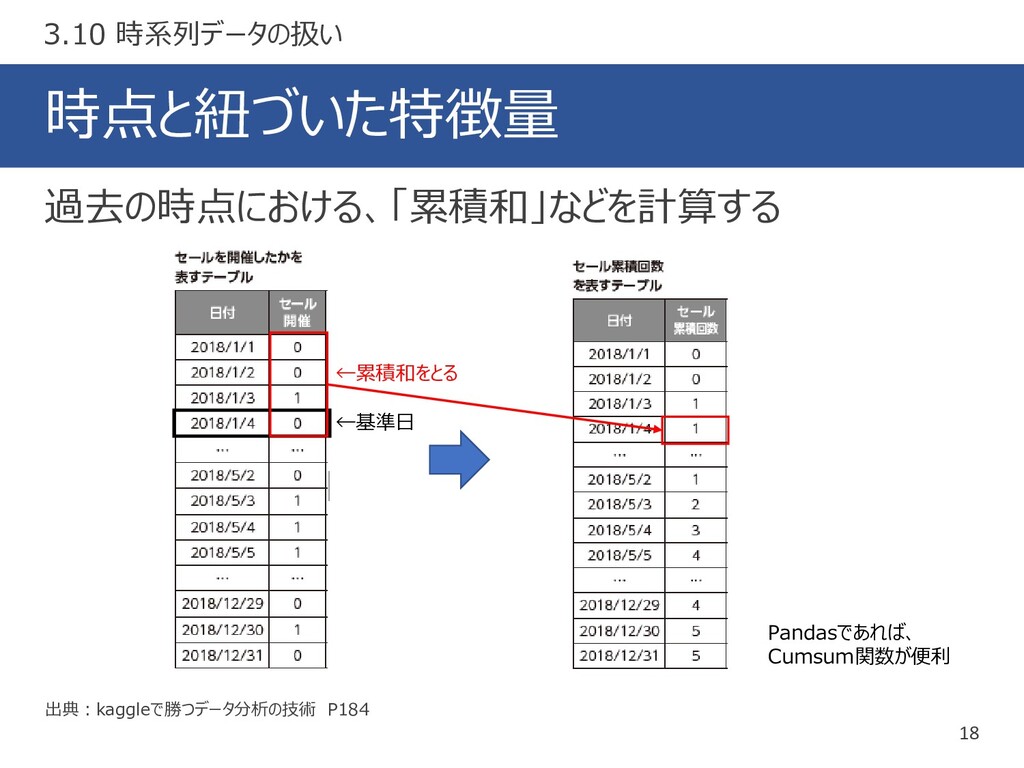
時点と紐づいた特徴量 18 出典:kaggleで勝つデータ分析の技術 P184 過去の時点における、「累積和」などを計算する 3.10 時系列データの扱い ←基準日 ←累積和をとる Pandasであれば、
Cumsum関数が便利
Testデータにおいて使える過去データを把握しておく →Testデータで使えない特徴量は意味がない Train Test 日付 12/1 12/2 12/3 12/4 12/5
12/6 12/7 売上 100 120 90 100 ? ? ? 特徴量を作成する時の注意点 19 3.10 時系列データの扱い 前日の売上が分からない ? 例) 前日の売上から翌日の売上を予測するモデルを作った場合 ?
3.11 次元削減・教師なし学習
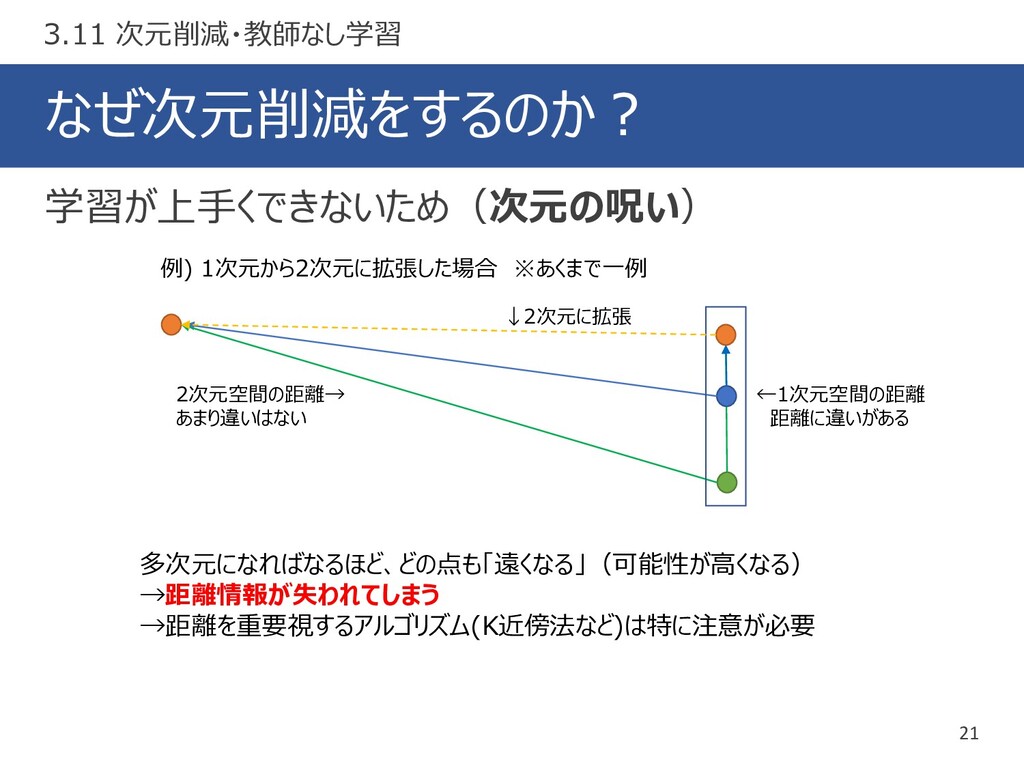
なぜ次元削減をするのか? 21 学習が上手くできないため(次元の呪い) 3.11 次元削減・教師なし学習 ←1次元空間の距離 距離に違いがある 2次元空間の距離→ あまり違いはない 多次元になればなるほど、どの点も「遠くなる」(可能性が高くなる)
→距離情報が失われてしまう →距離を重要視するアルゴリズム(K近傍法など)は特に注意が必要 ↓2次元に拡張 例) 1次元から2次元に拡張した場合 ※あくまで一例
なぜ次元削減をするのか? 22 次元の呪い以外に • 計算時間を減らす • (線形モデルにおいて)多重共線性のリスクを下げる • 過学習のリスクを下げる(ノイズを学習しづらくなる) という理由もある
3.11 次元削減・教師なし学習
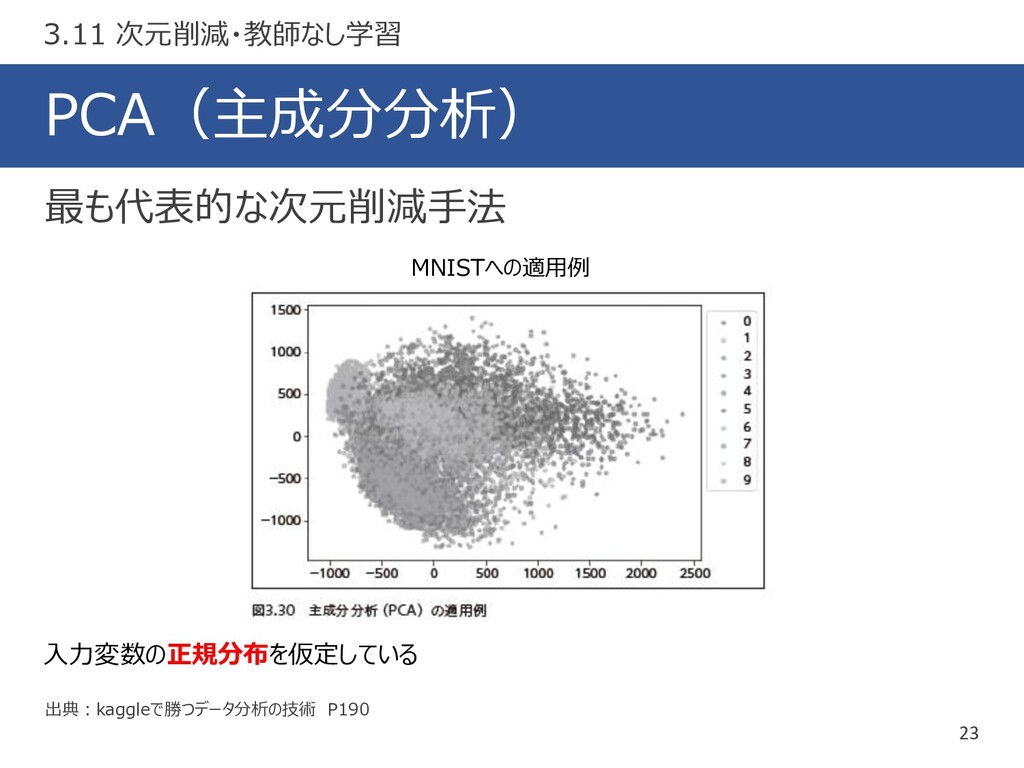
PCA(主成分分析) 23 出典:kaggleで勝つデータ分析の技術 P190 最も代表的な次元削減手法 3.11 次元削減・教師なし学習 入力変数の正規分布を仮定している MNISTへの適用例
NMF(非負値行列分解) 24 出典:https://abicky.net/2010/03/25/101719/ 非負データのみに使える次元削減手法 3.11 次元削減・教師なし学習 NMFはPCAより局所的な特徴を抽出できる(?) 顔画像をNMFとPCAで次元削減
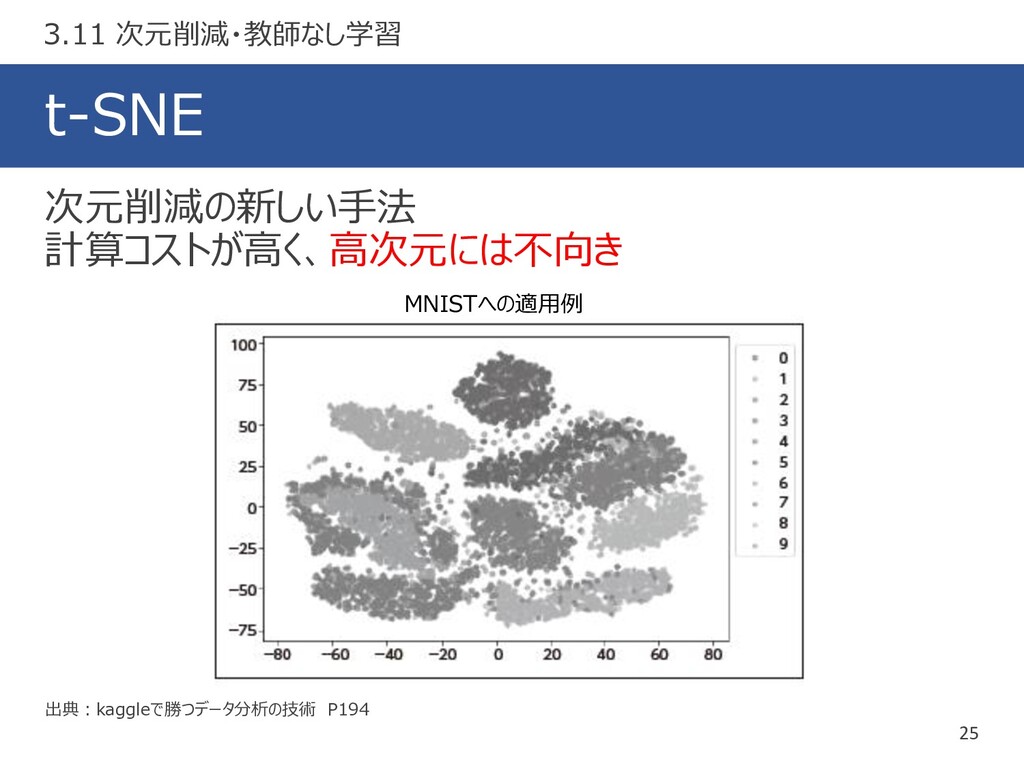
t-SNE 25 出典:kaggleで勝つデータ分析の技術 P194 次元削減の新しい手法 計算コストが高く、高次元には不向き 3.11 次元削減・教師なし学習 MNISTへの適用例
UMAP 26 出典:kaggleで勝つデータ分析の技術 P195 最近(2018年)登場した次元削減手法 t-SNEより計算量が少ない 3.11 次元削減・教師なし学習 MNISTへの適用例
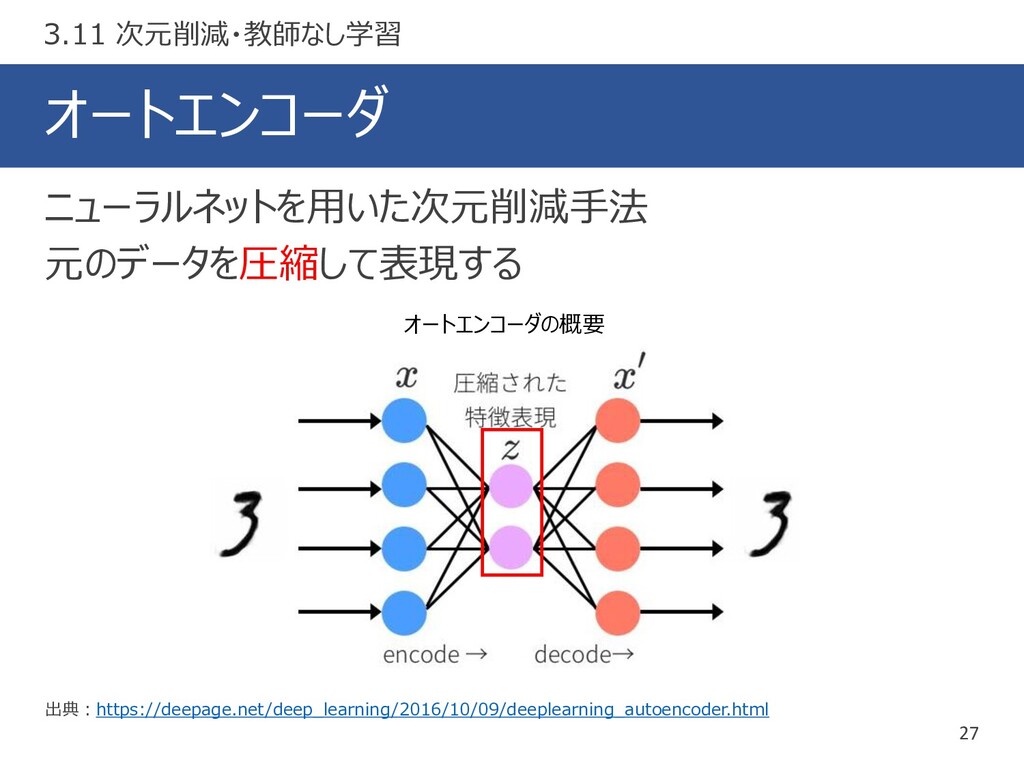
オートエンコーダ 27 出典:https://deepage.net/deep_learning/2016/10/09/deeplearning_autoencoder.html ニューラルネットを用いた次元削減手法 元のデータを圧縮して表現する 3.11 次元削減・教師なし学習 オートエンコーダの概要
クラスタリング 28 出典:http://tech.nitoyon.com/ja/blog/2009/04/09/kmeans-visualise/ クラスタリングした結果を特徴量とすることもできる 3.11 次元削減・教師なし学習 重心からの距離と特徴量とすること もできる
3.12 その他のテクニック
細かい内容が多いので、 個別の説明は割愛します
データに深く向き合う 31 出典:普通のデータサイエンティストと世界トップクラスのデータサイエンティストの違い https://newswitch.jp/p/19990 細かいテクニックを覚えるより、データを見て考えることが大事 3.12 その他のテクニック ・仮説 Colaの代替品として、 Fridge-Pack-Colaが購入されて
いるのではないか? 深くデータと向き合わないと 気付かない あるユーザーの購買履歴
マルチモーダル学習 32 出典:https://speakerdeck.com/upura/kaggle-petfinder-2nd-place-solution テーブル・画像・自然言語などのデータを統合して学習させる 自然言語:単語のカウント、文章の長さなど 画像 :画像サイズ、RGB、CNNの出力層付近の値など 3.12 その他のテクニック ・目的変数
ペットの引き取られるまでの速さ e.g. Kaggle PetFinder.my Adoption Prediction
3.12 分析コンペにおける 特徴量作成の例
数が多いので、 1つコンペを取り上げます
Kaggle: Instacart Market Basket Analysis 35 出典:https://www.kaggle.com/c/instacart-market-basket-analysis/overview 3.12 分析コンペにおける特徴量作成の例 •
予測すること 過去に購入した商品のうち、再注文する商品 • 使うデータ 過去の注文履歴
ユーザーベースの特徴量 36 • どのくらい頻繁に再注文を行うか • 注文間の間隔 • 注文する時間帯 • オーガニック、グルテンフリー、アジアのアイテムを過去に注文したか
• 一度の注文の商品数についての特徴 • 初めて購入するアイテムを含む注文はどれだけあるか 3.12 分析コンペにおける特徴量作成の例 ユーザーの属性ごとにを特定する効果
アイテムベースの特徴量 37 • どの程度頻繁に購入されるか • カート内での位置 • どの程度「一度きり」として購入されるか • 同時に購入される商品の数についての統計量
• 注文をまたいだ共起についての統計量 例:前回バナナを買った場合、次にイチゴを買うかどうか) • 連続注文(途切れずに連続で注文されること)についての統計量 • N回の注文中に再注文される確率 • どの曜日に注文されるかの分布 • 最初の注文後に再注文されるかの確率 • 注文間の間隔の統計量 3.12 分析コンペにおける特徴量作成の例 「日常的に購入される商品」と 「お試しで購入されやすい商品」 の違いを捉える?
ユーザ×アイテムベースの特徴量 38 • ユーザがその商品を購入した回数 • ユーザがその商品を最後に購入してからの経過 • 連続注文 • カート内での位置
• 当日にそのユーザがすでにそのアイテムを注文したか • 同時に購入される商品についての統計量 • ある商品の代わりに購入される商品(=注文をまたいだ共起につ いて、購入しなかったことに注目したもの) 3.12 分析コンペにおける特徴量作成の例 リピートする商品ほど、先にカゴ に入れる?
日時の特徴量 39 • 曜日ごとの注文数、注文された商品数 • 時間ごとの注文数、注文された商品数 3.12 分析コンペにおける特徴量作成の例
以上 ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}