2025年3月27日
電子情報通信学会 総合大会 企画セッション
「パターン認識・メディア理解(PRMU)技術の産業応用」
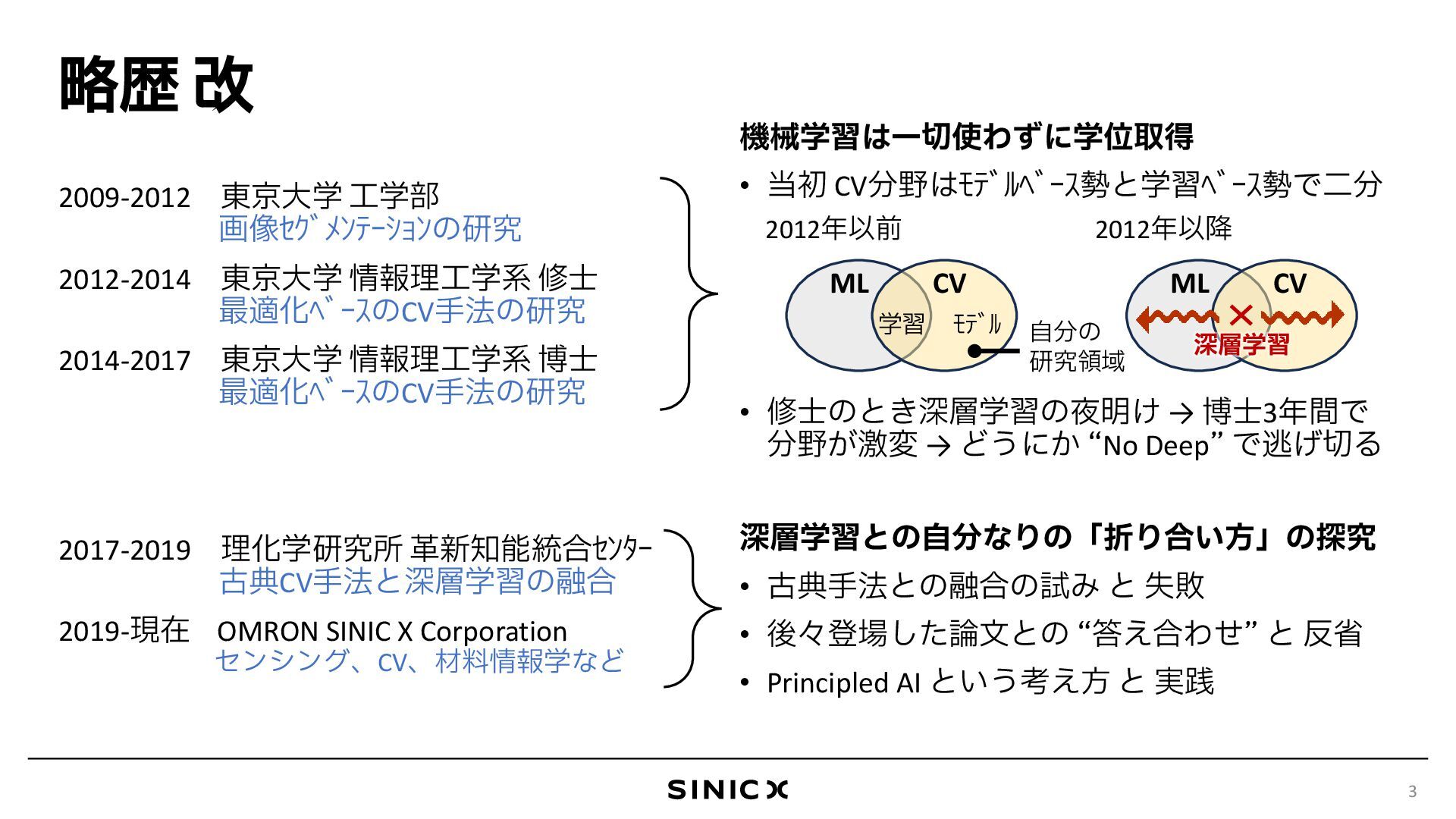
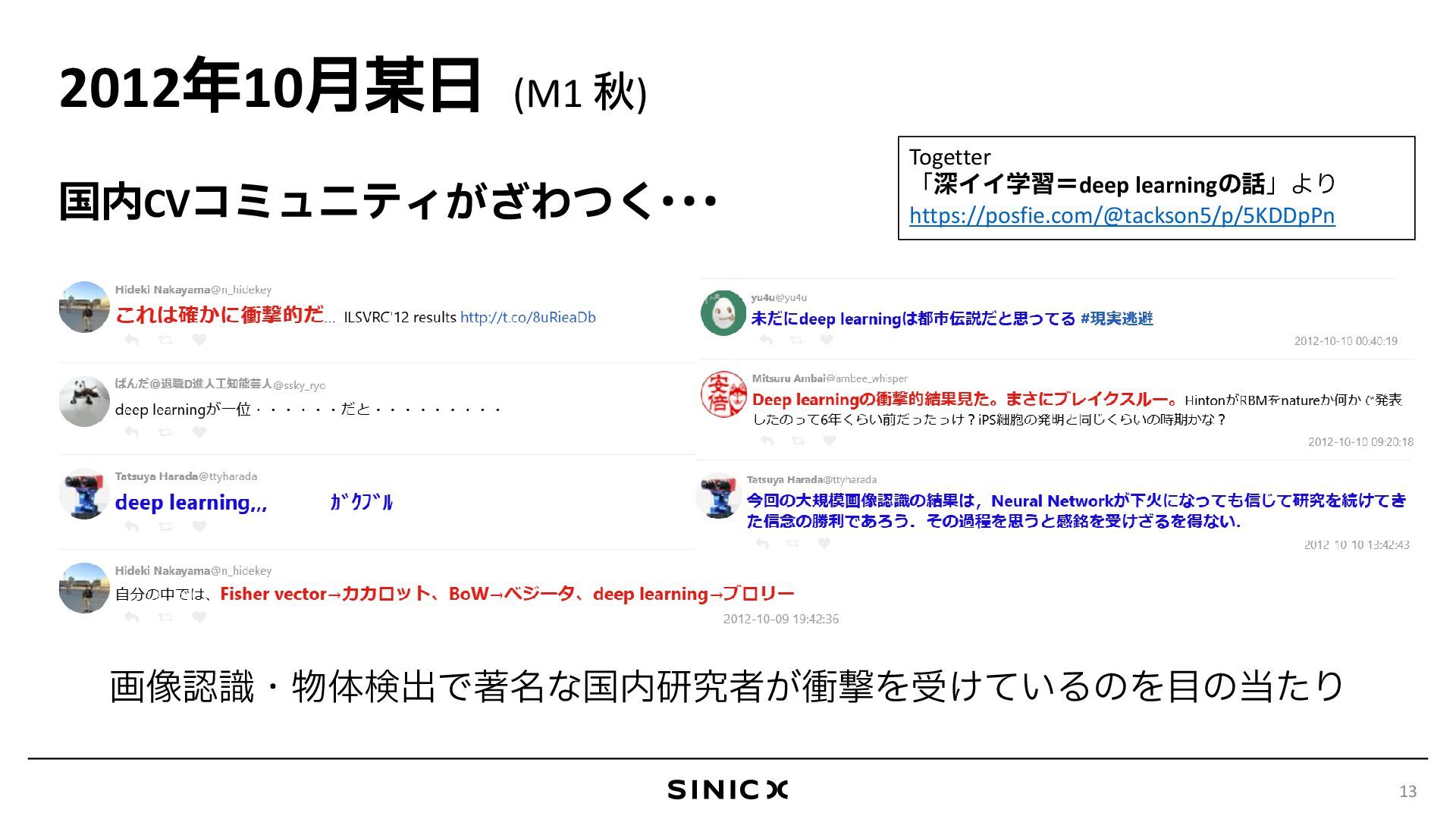
深層学習を用いたAI技術は、2012年に音声認識や画像認識で成功を収めて以来、目覚ましい進化を遂げています。私は、深層学習が台頭する以前の2011年頃からコンピュータビジョン分野で画像セグメンテーションや奥行推定などの課題に取り組み、特に2012年から2017年の深層学習の黎明期から過渡期にかけては、修士・博士課程の大学院生として、この技術が従来の手法を刷新していく様子を最前線で目の当たりにしました。現在も自立制御や材料科学の分野を中心に、AI技術の研究に取り組んでいます。本講演では、こうした経験をもとに、AI技術の進展を振り返りつつ、私が近年追求する課題解決の方法論「Principled AI」を紹介します。Principled AIは、ニューラルネットワークをブラックボックス型ツールとして扱うのではなく、古典的アプローチで培われた知見を統合し、性能やデータ効率、信頼性を追求する設計思想です。Principled AIの材料科学分野への応用例として、ICLR 2024で発表したCrystalformerを取り上げ、物性予測やセンシングといった物理法則が支配する問題領域における深層学習の可能性を議論します。
{kind=link}
![今日 話したいこと 1 • Transformerを用いた3次元結晶構造解析の研究の紹介 [ICLR 24 & 25] の前に・・・](https://files.speakerdeck.com/presentations/203800c8299d4dd5842de5e63a9cb019/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![CVとの出会い 2011年3月 5 • 画像セグメンテーション(B4研究室配属時のD3の先輩のテーマ) “GraphCut” [Rother+, SIGGRAPH 04] 𝐸](https://files.speakerdeck.com/presentations/203800c8299d4dd5842de5e63a9cb019/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
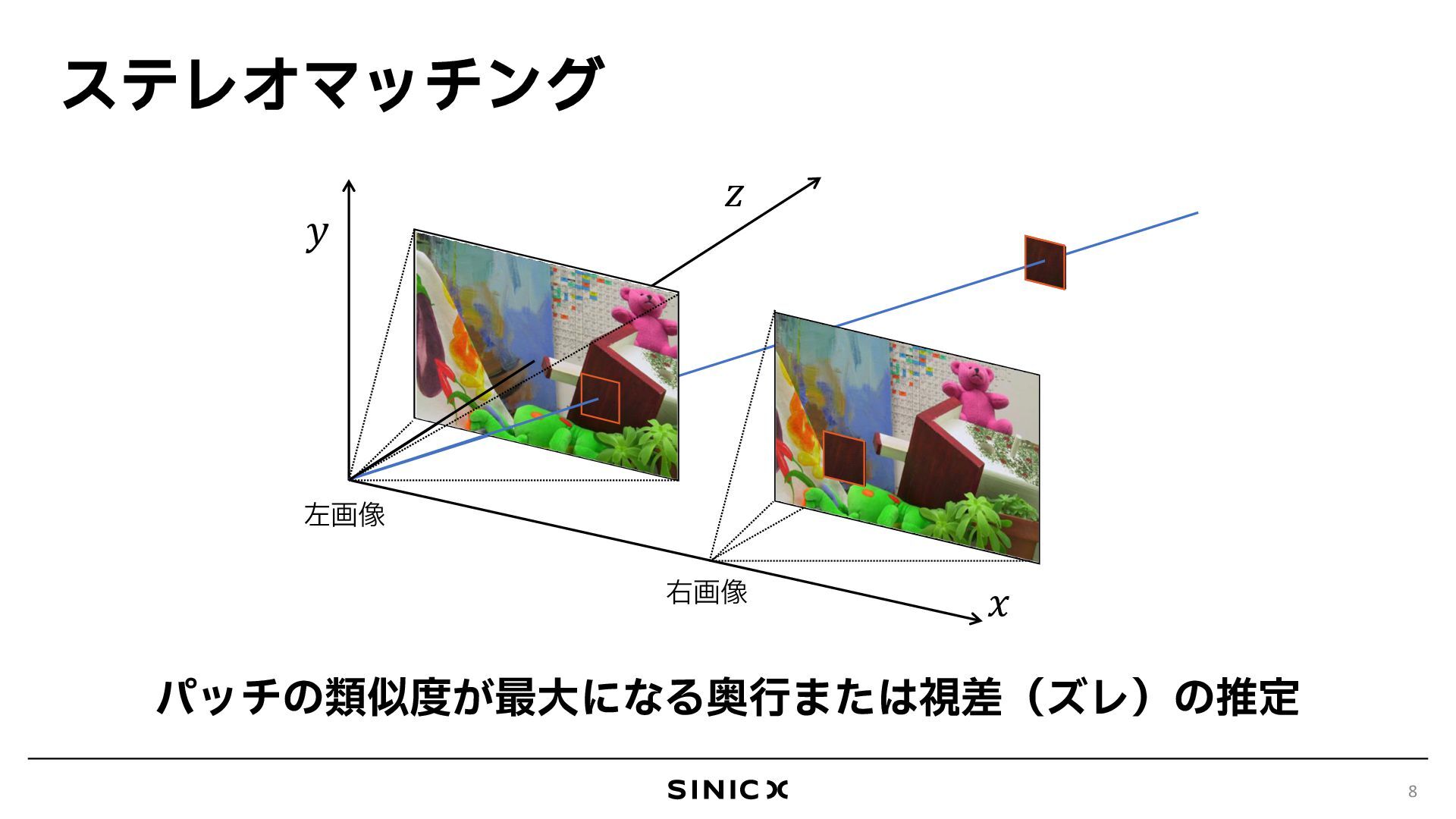
![傾きパッチによるステレオ [Bleyer+, BMVC 11] 9 𝑥 𝑦 𝑧 𝑝′ 左画像](https://files.speakerdeck.com/presentations/203800c8299d4dd5842de5e63a9cb019/slide_9.jpg){kind=link}
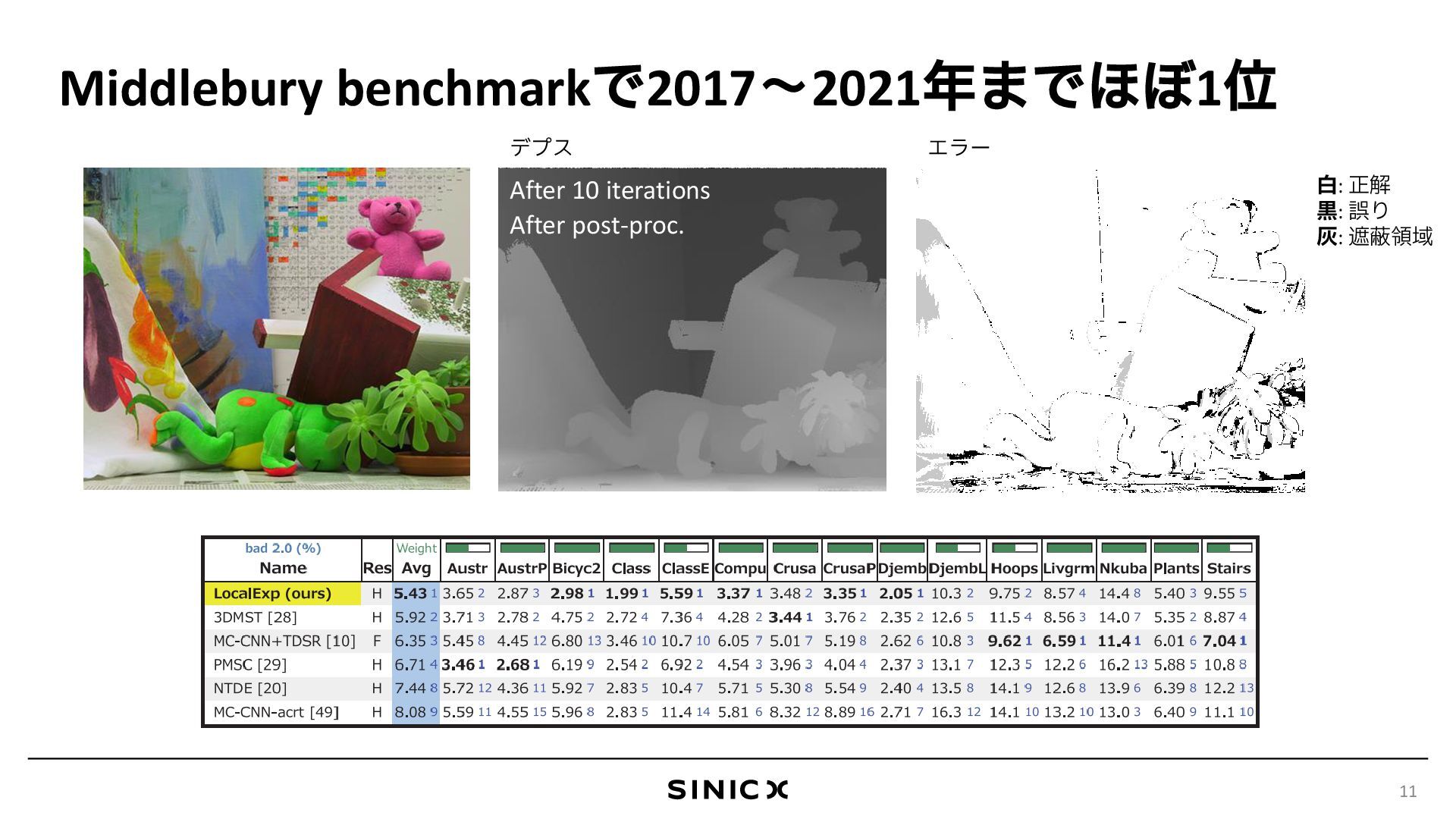
![提案した最適化手法 [Taniai+, CVPR 14 & TPAMI 18] Local α-expansion法 (提案手法)](https://files.speakerdeck.com/presentations/203800c8299d4dd5842de5e63a9cb019/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
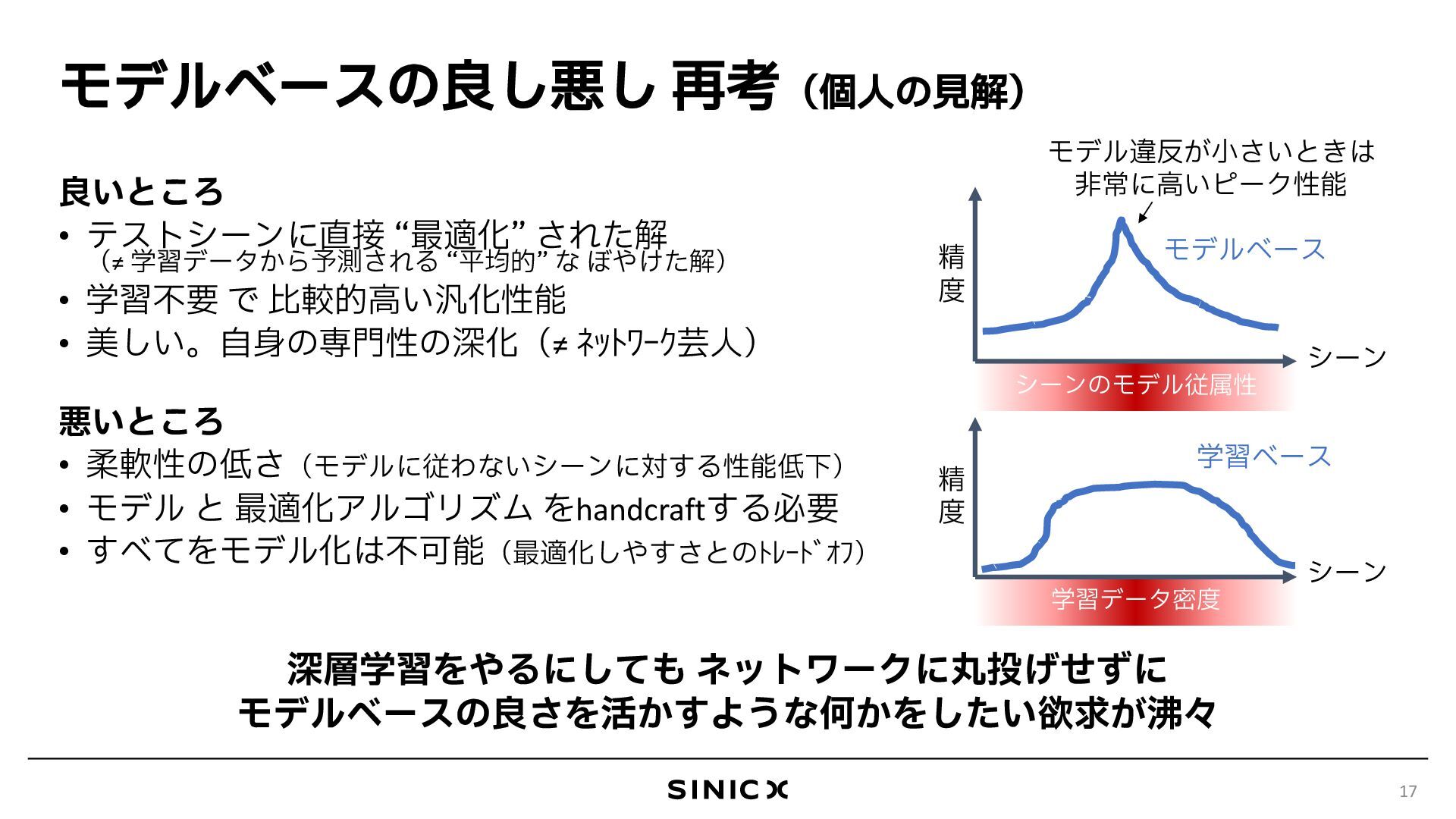{kind=link}
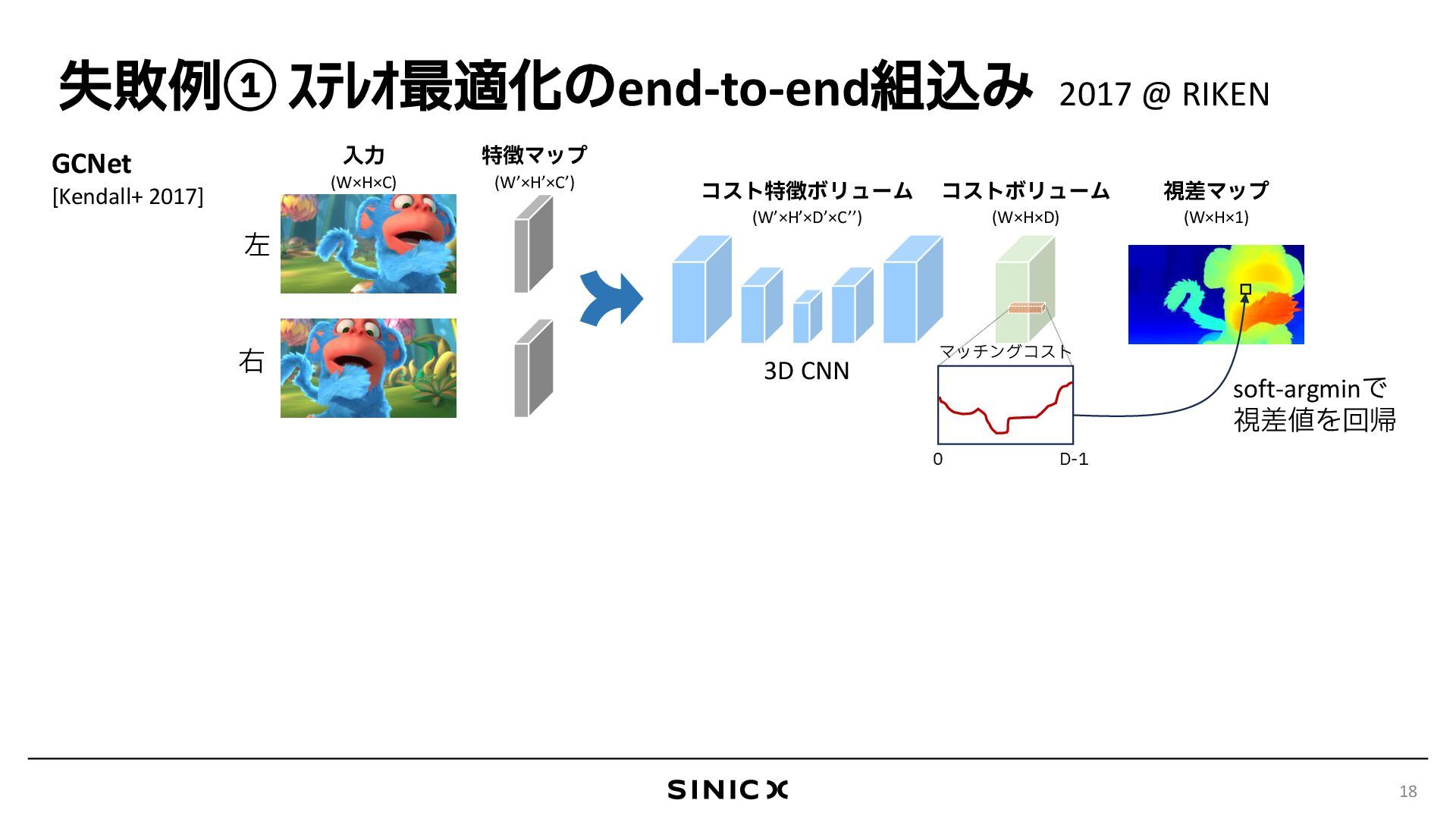{kind=link}
{kind=link}
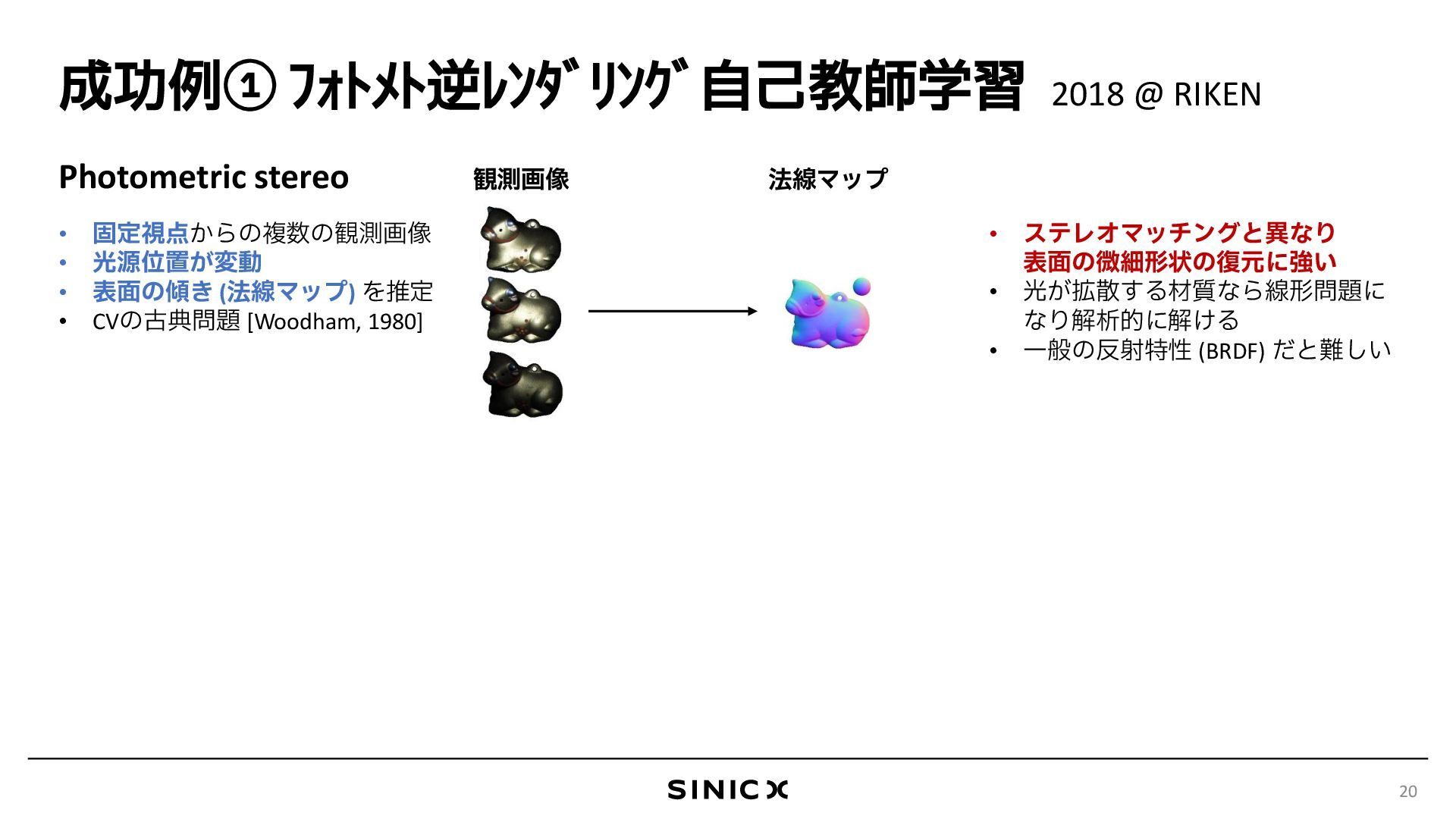{kind=link}
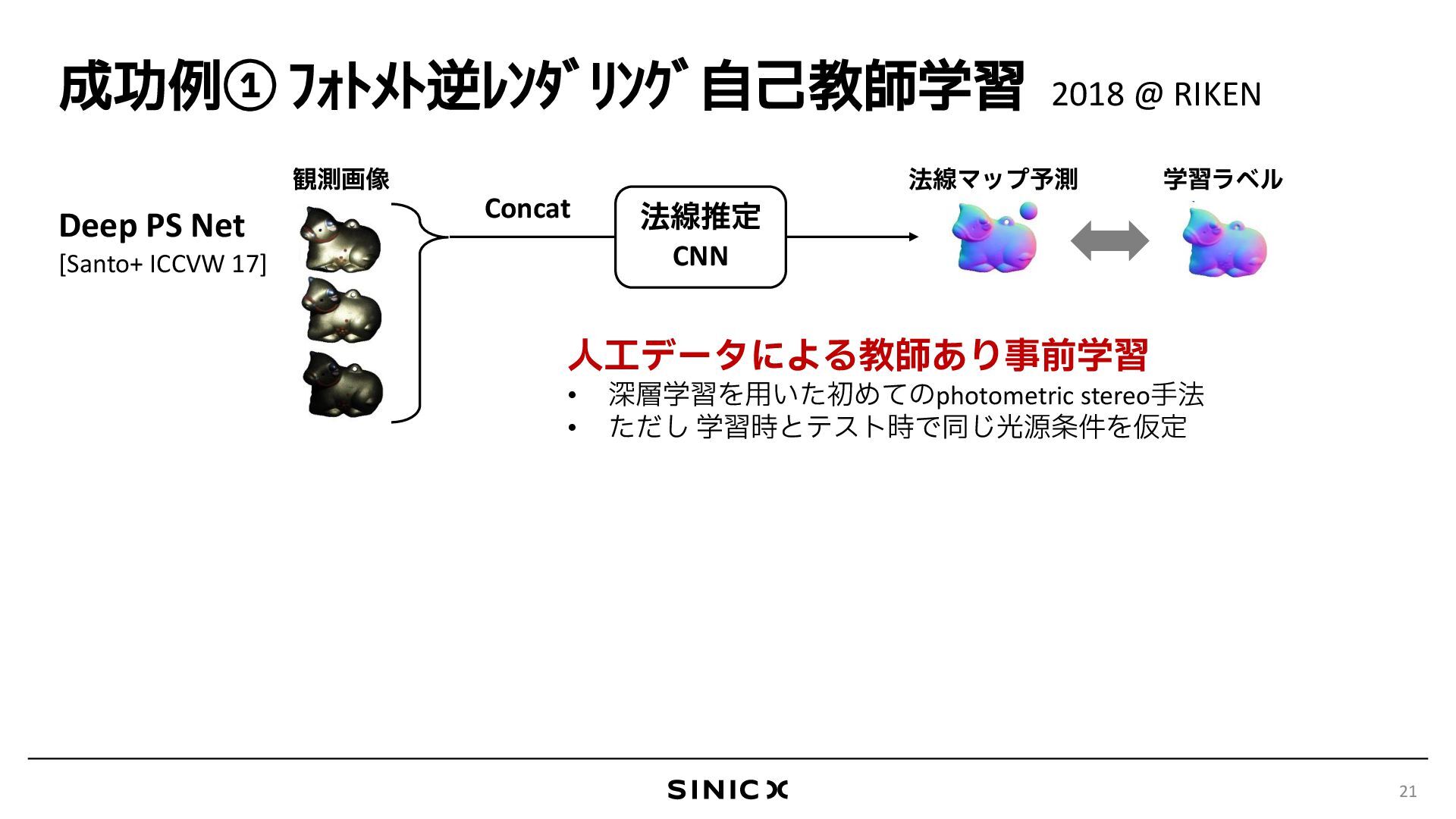{kind=link}
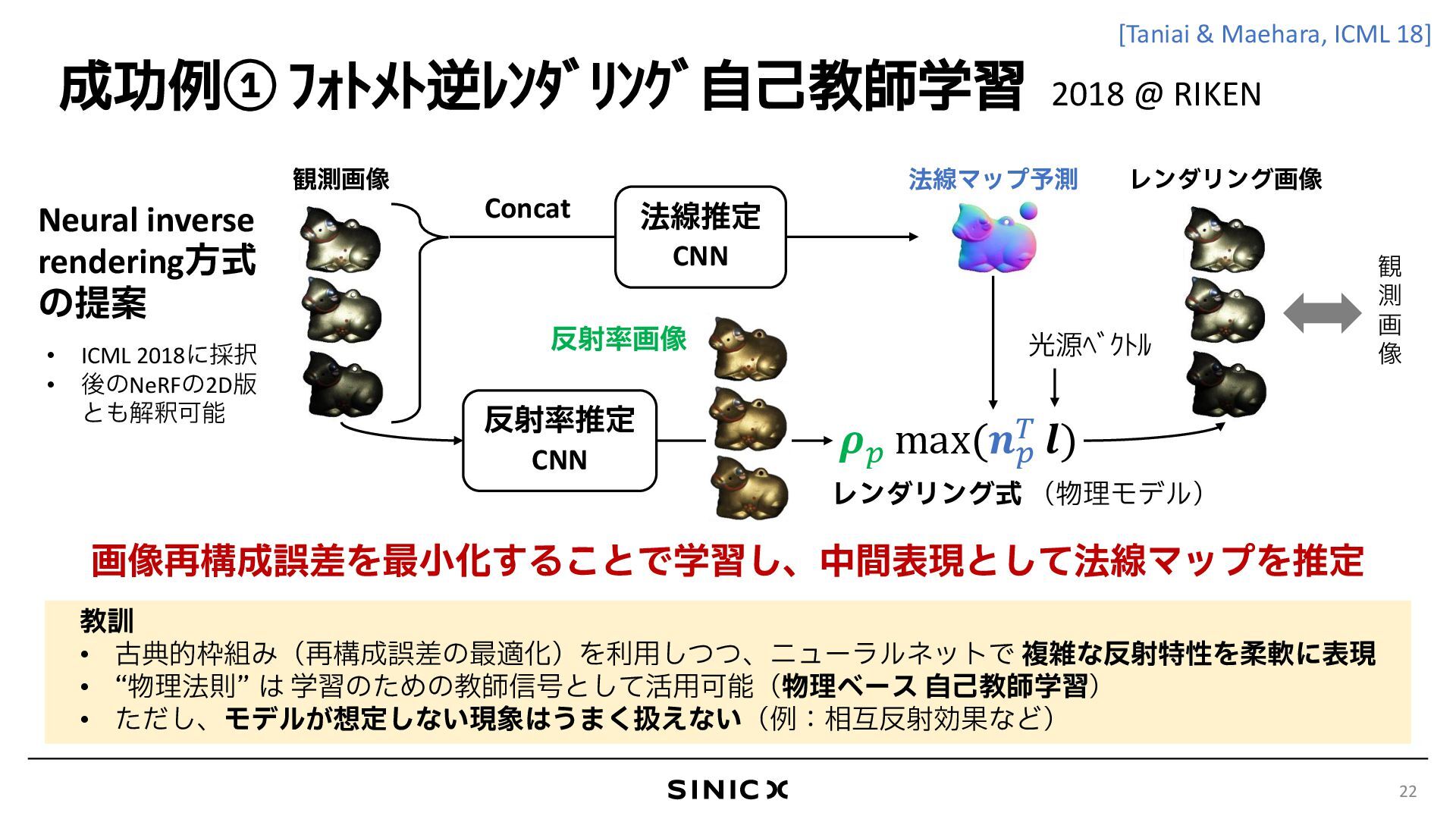{kind=link}
{kind=link}
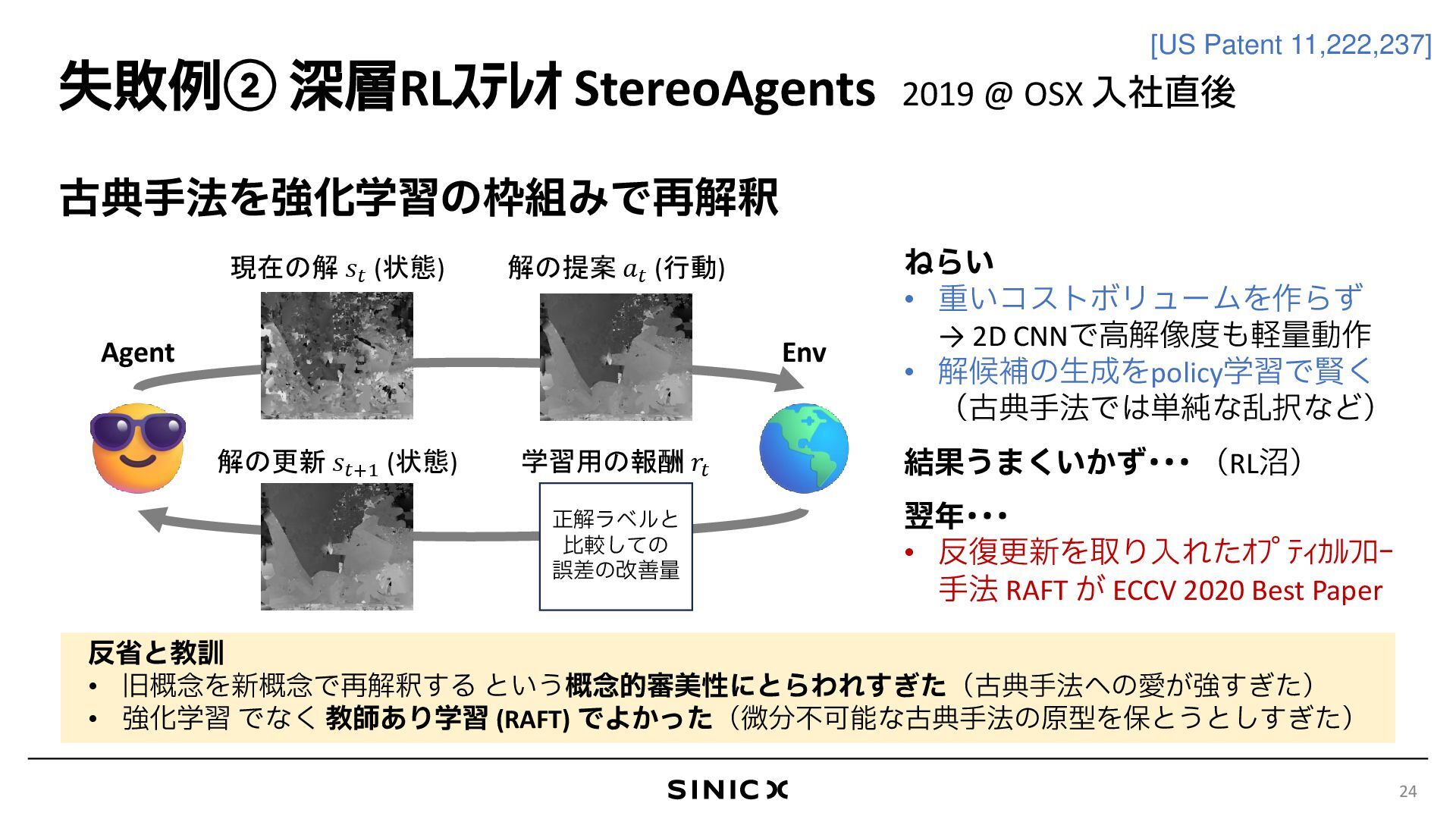{kind=link}
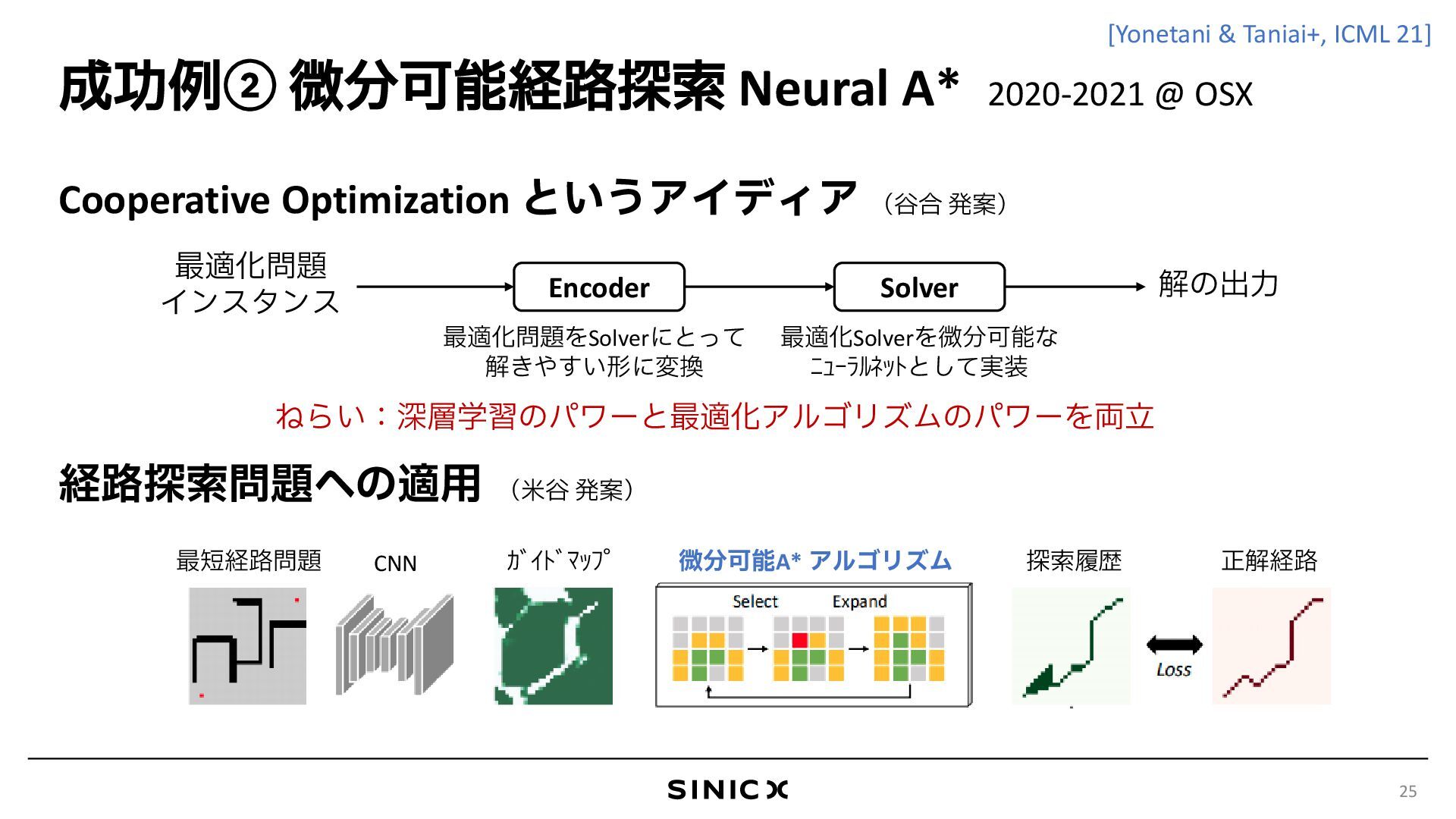{kind=link}
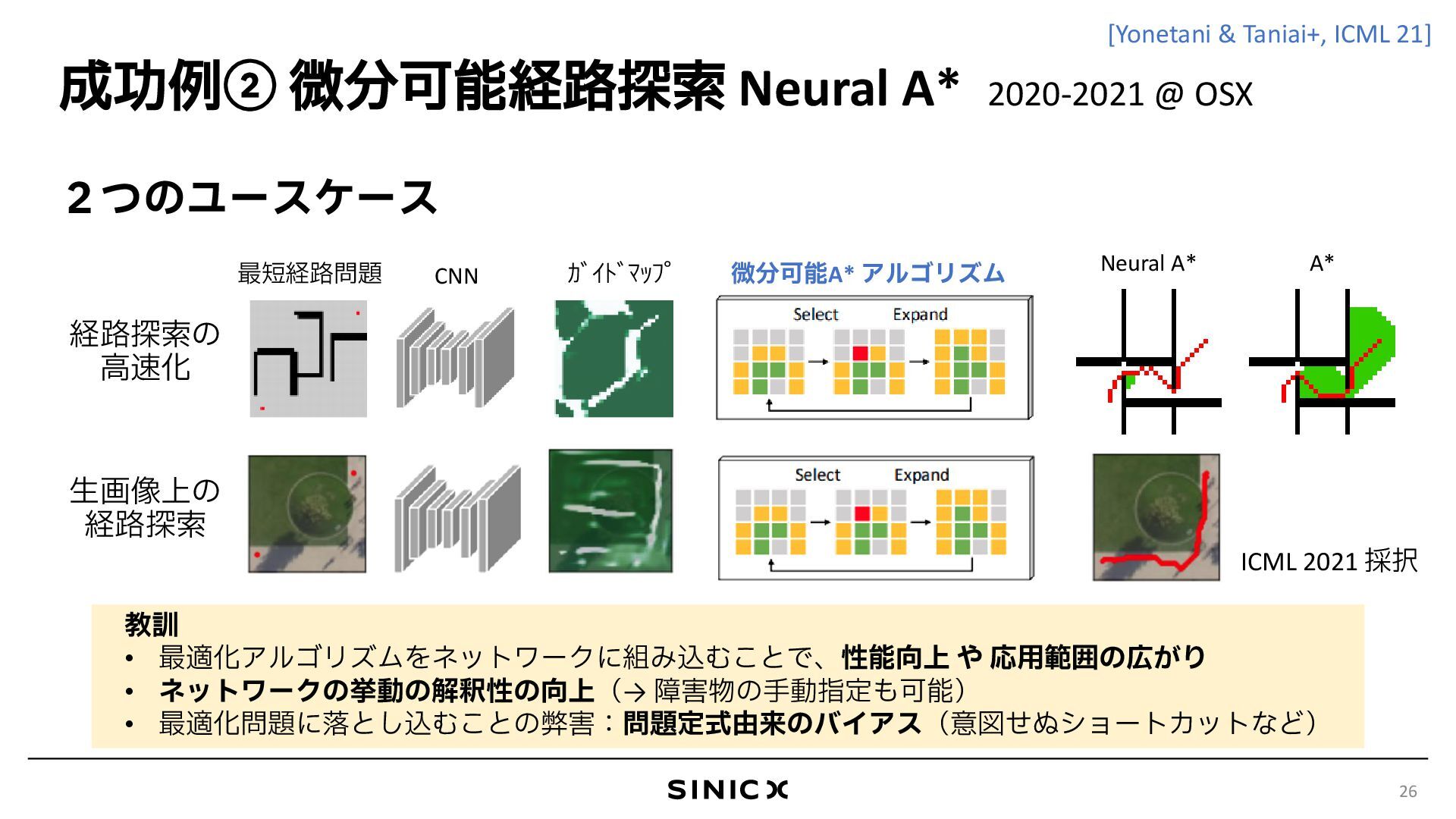{kind=link}
{kind=link}
{kind=link}
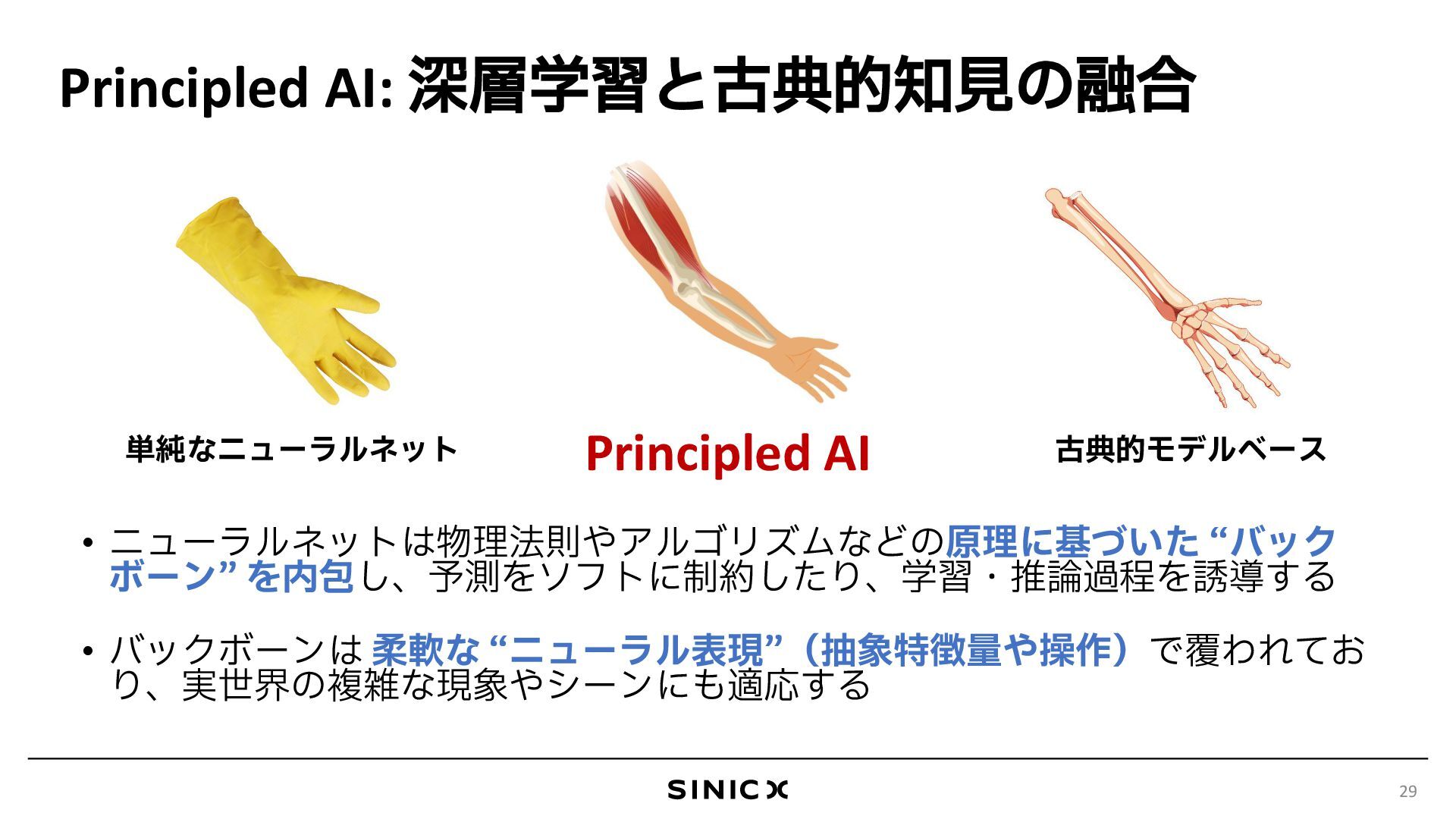{kind=link}
{kind=link}
{kind=link}
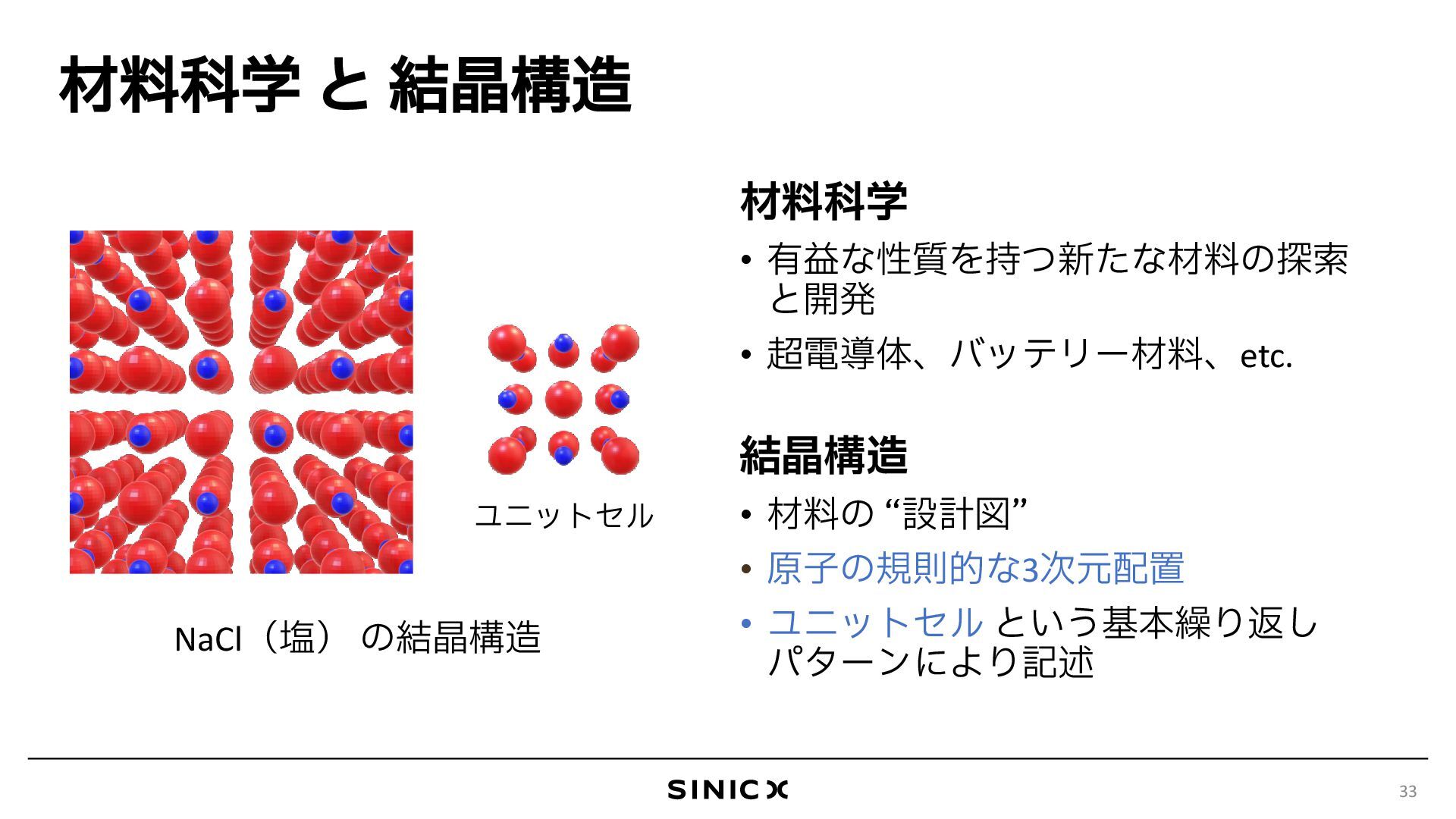{kind=link}
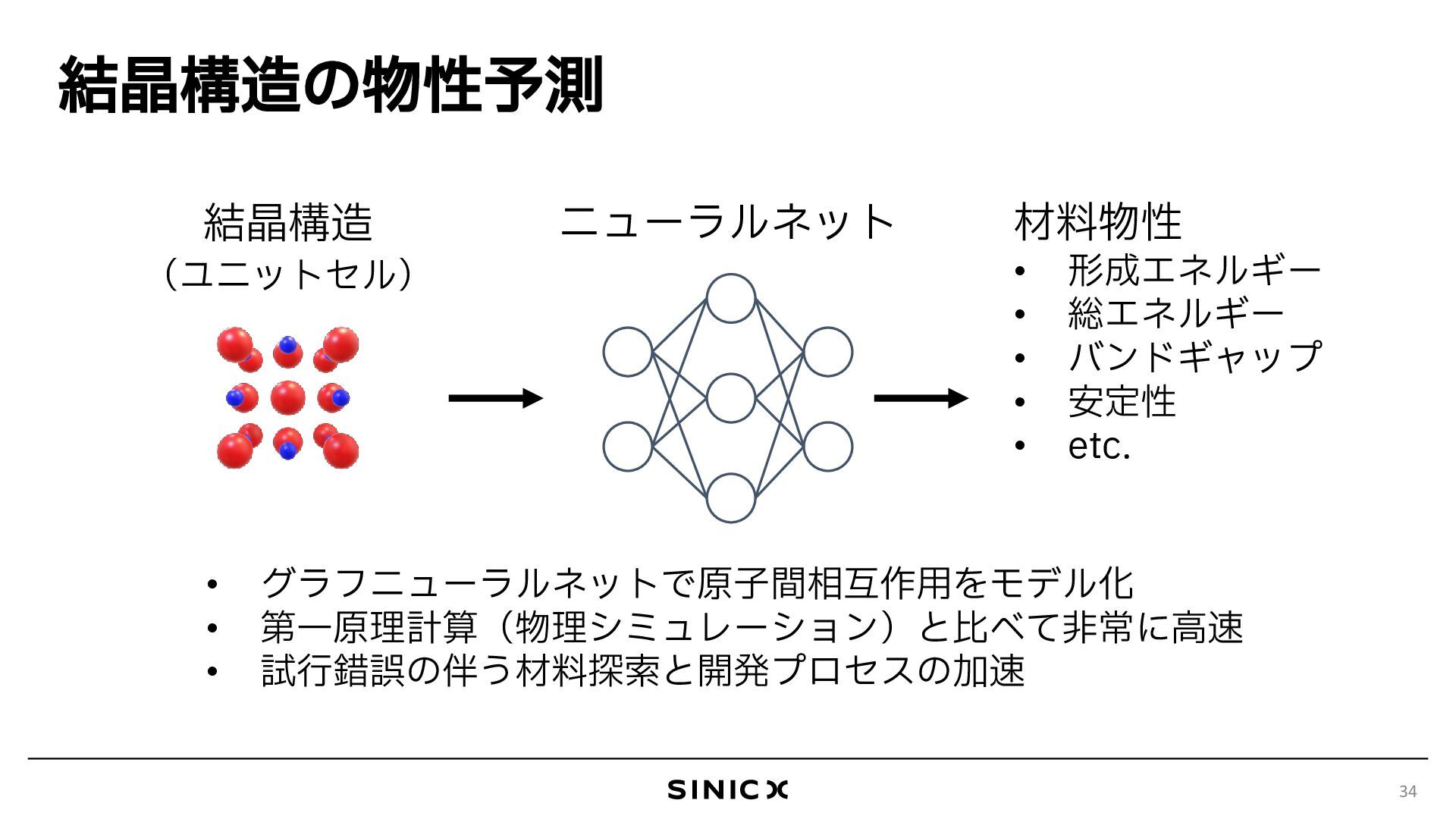{kind=link}
{kind=link}
{kind=link}
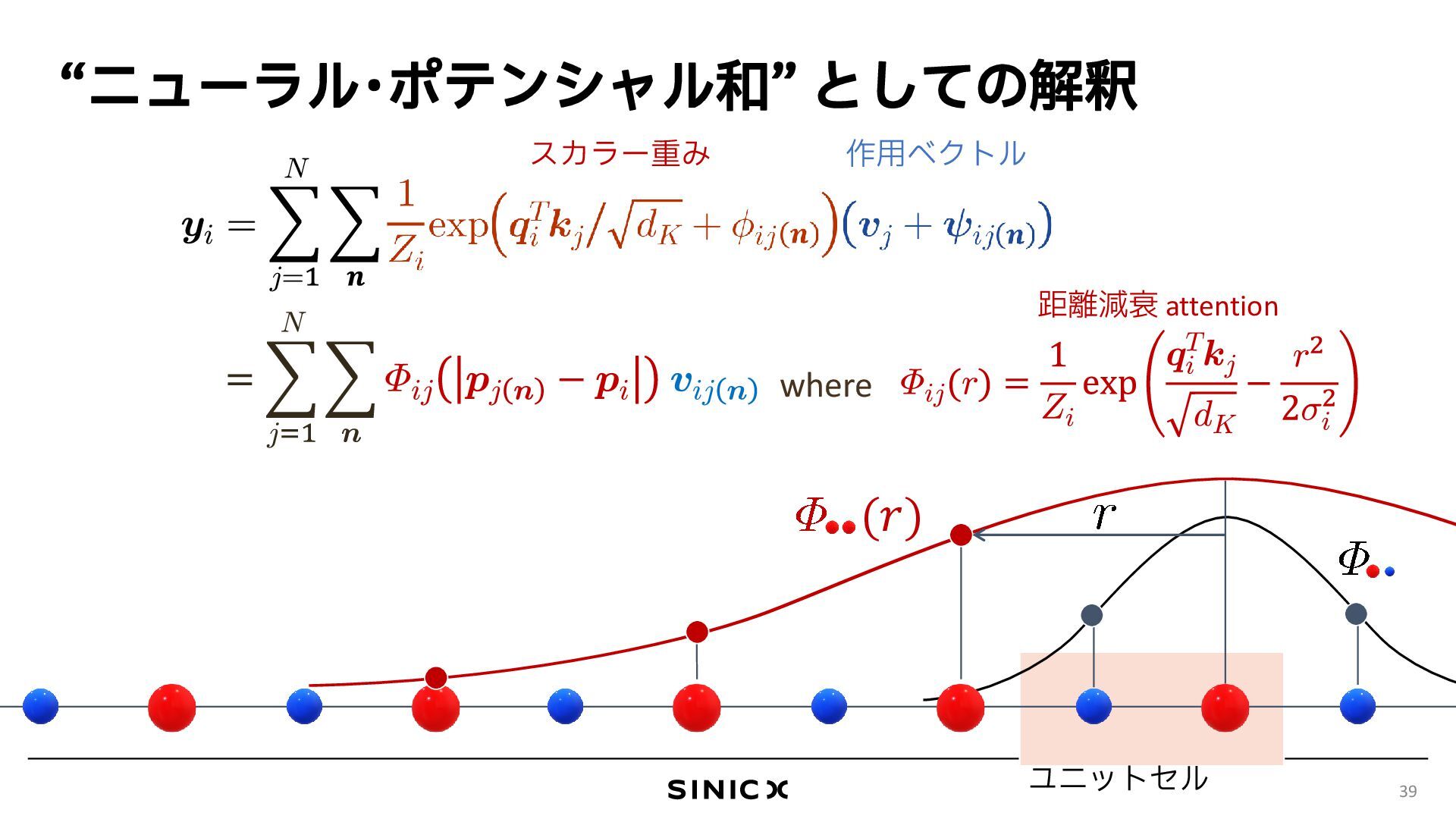{kind=link}
{kind=link}
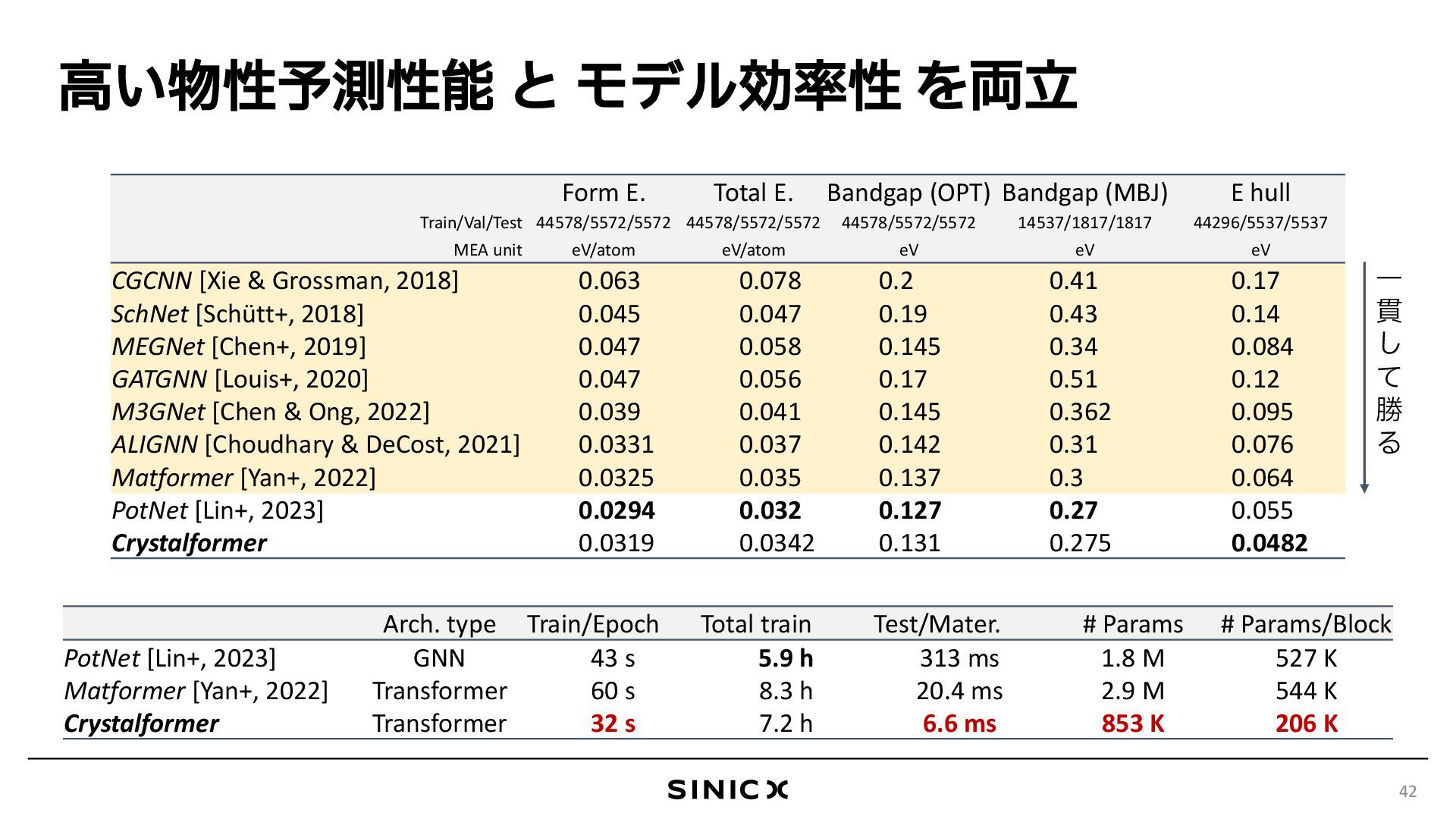{kind=link}
![CrystalFramer では さらに精度向上 [Ito & Taniai+, ICLR 25] Form E.](https://files.speakerdeck.com/presentations/203800c8299d4dd5842de5e63a9cb019/slide_39.jpg){kind=link}
{kind=link}
{kind=link}