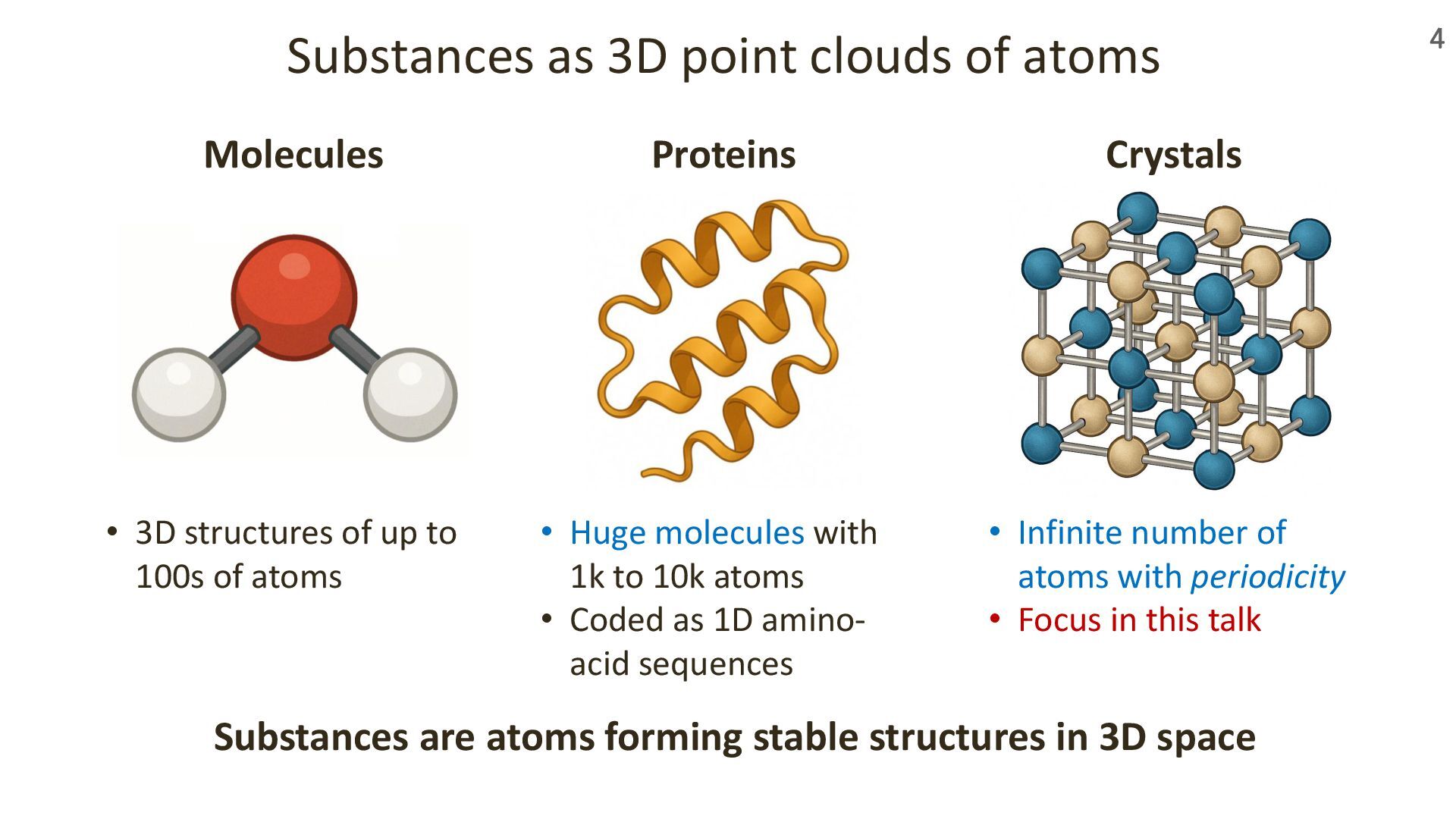
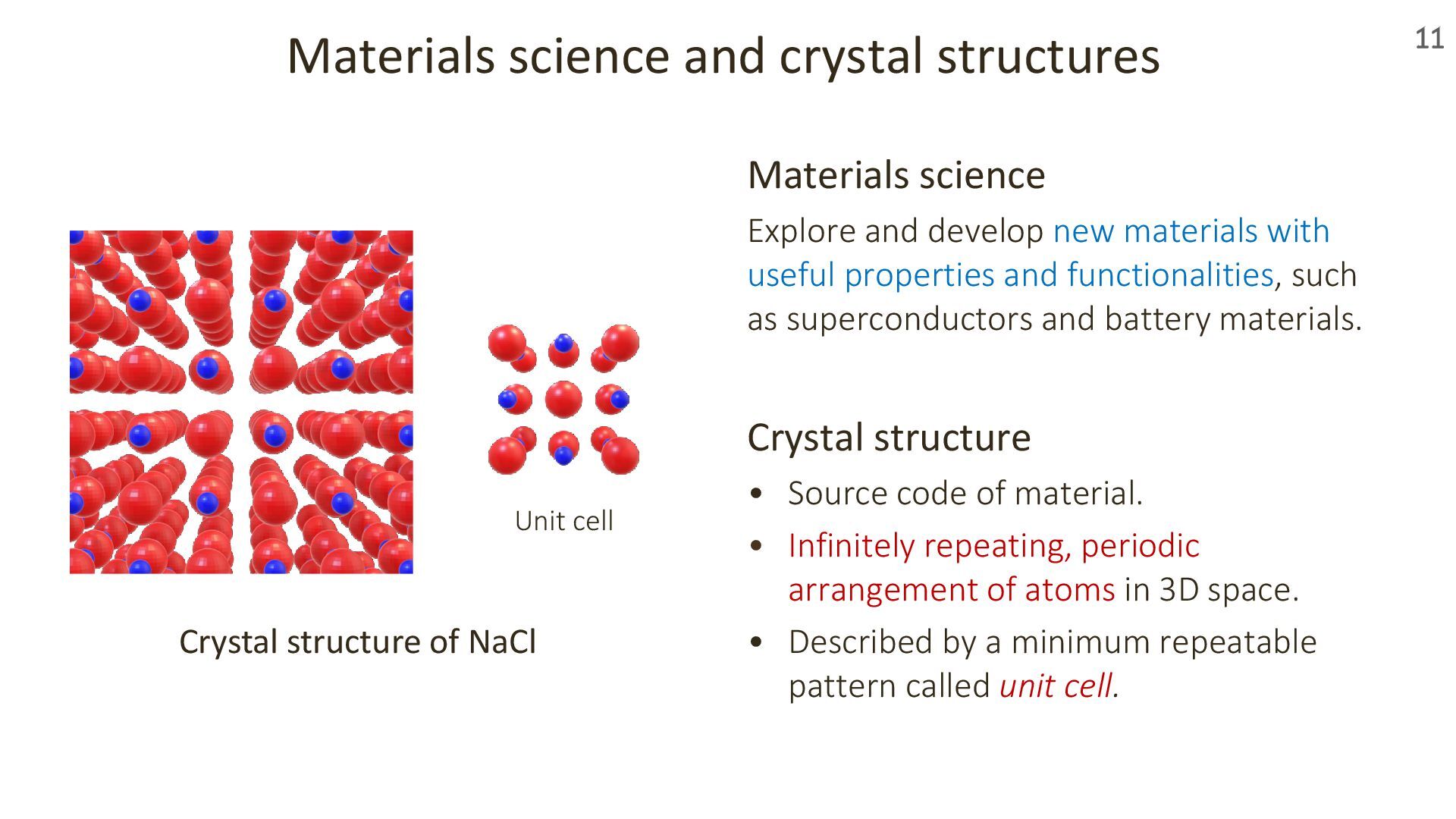
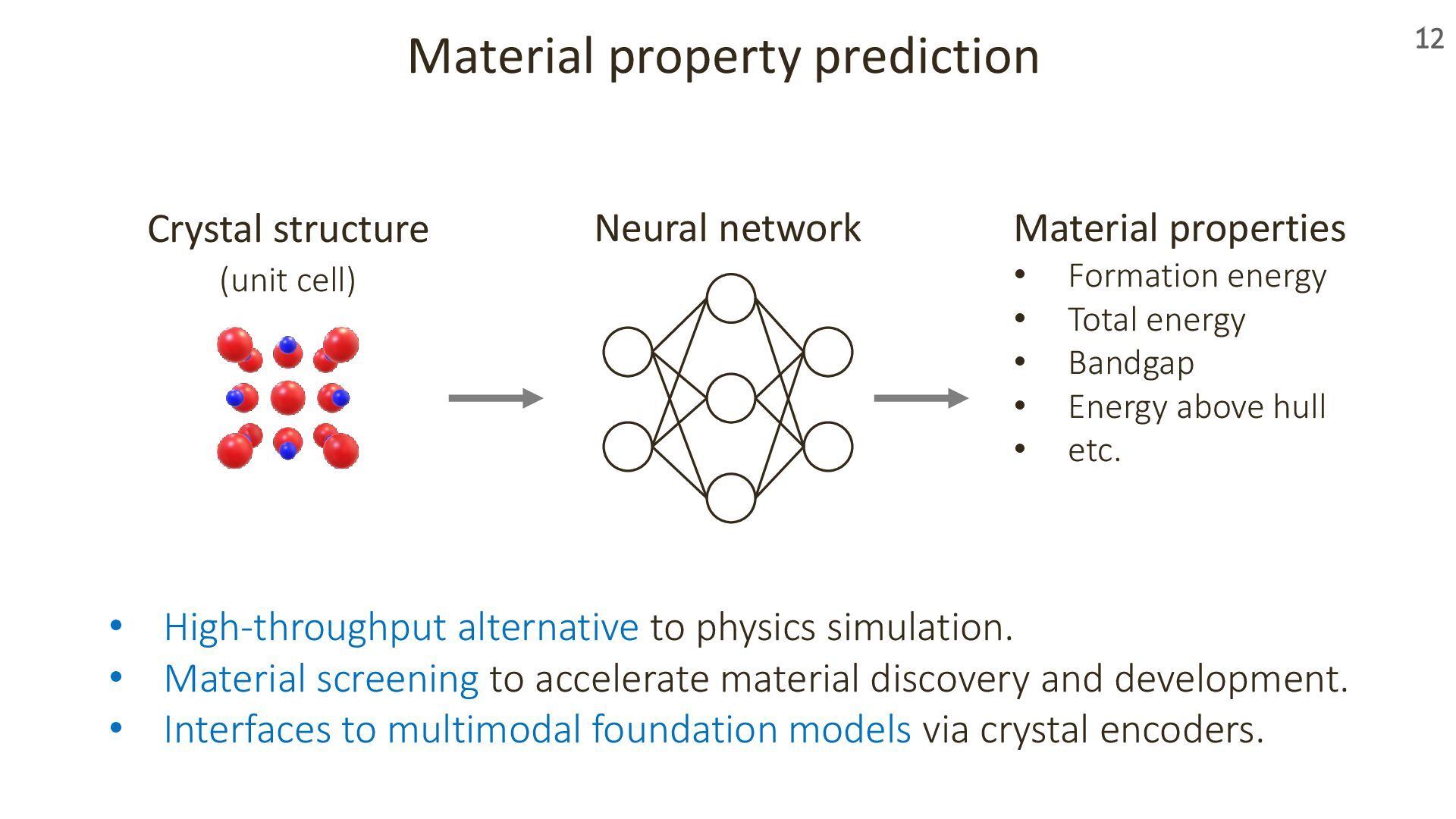
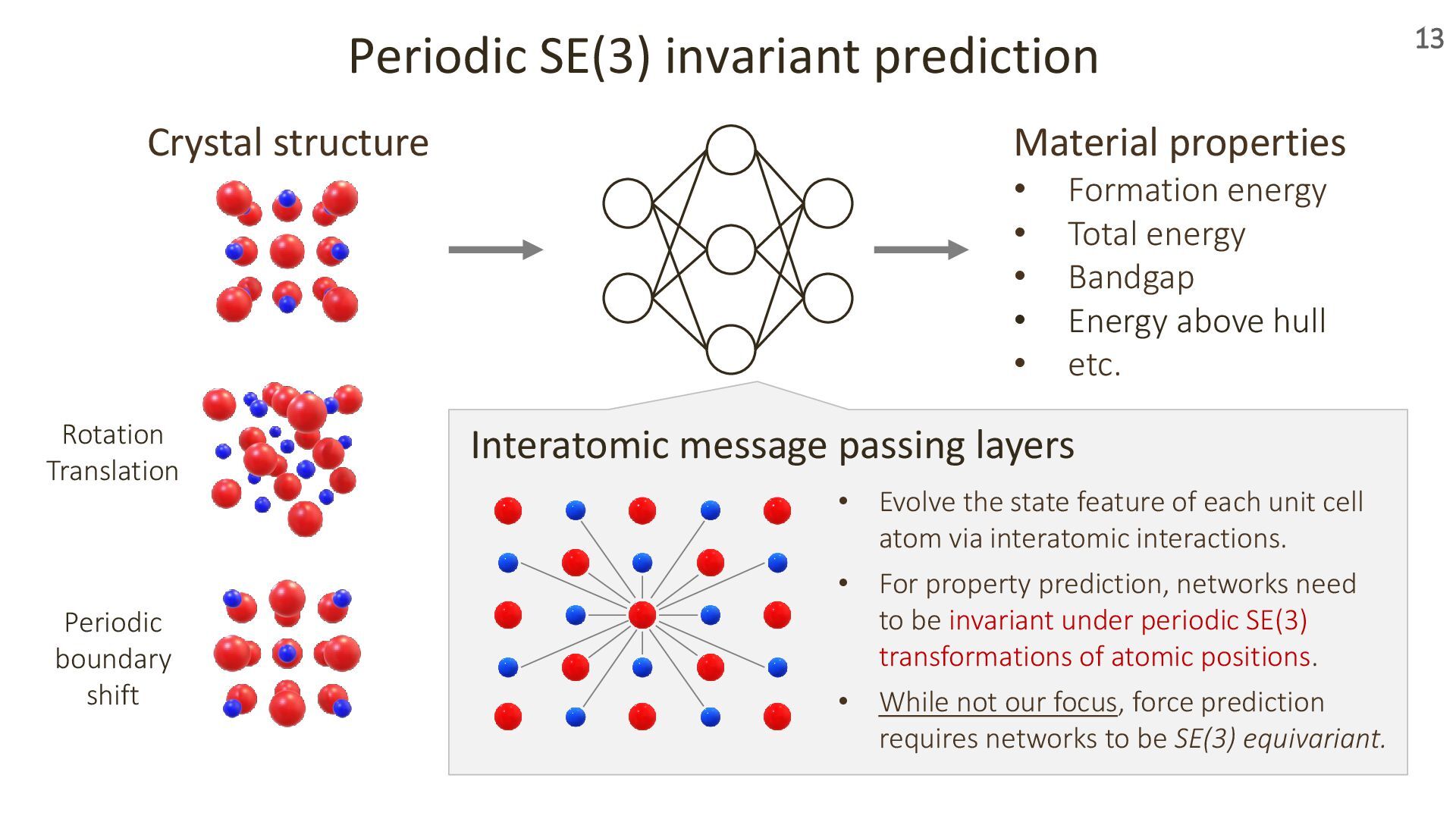
Materials are everywhere around us—serving as semiconductors in computers, souvenir magnets on refrigerators, and lithium-ion battery components in smartphones. At the atomic level, these materials are made of atoms arranged in three-dimensional space with a remarkable property: periodicity.
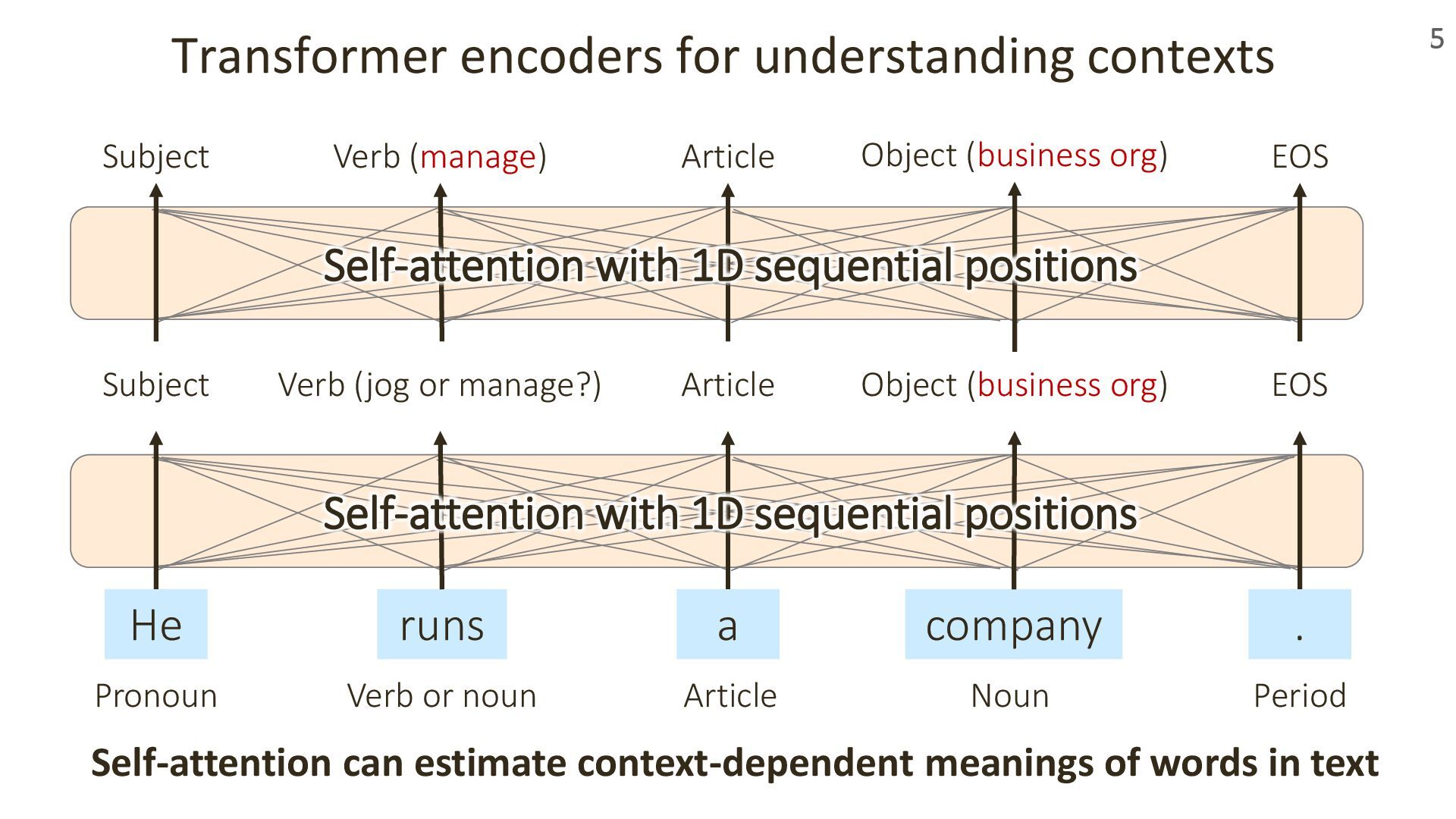
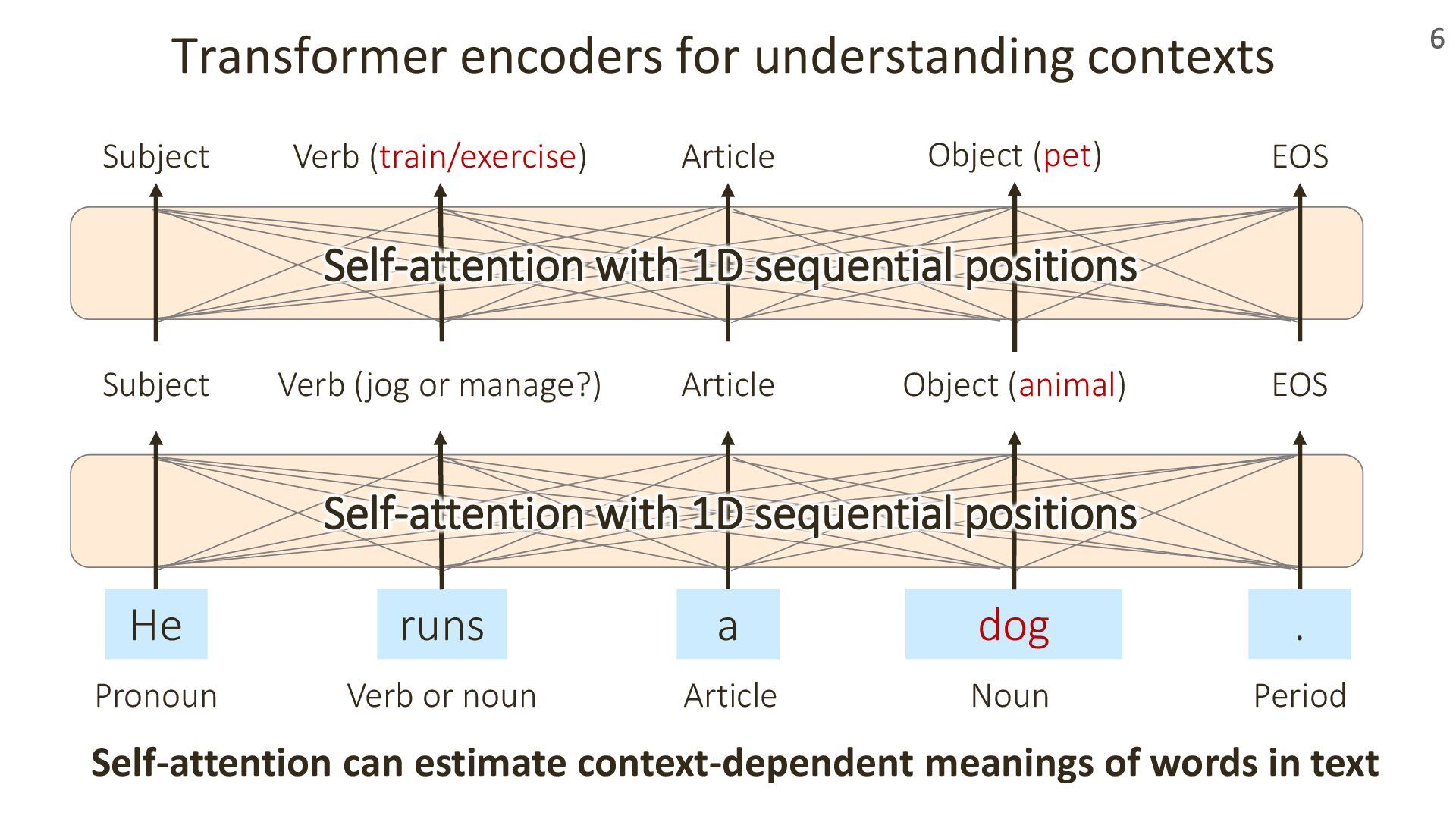
For decades, materials scientists have explored how such structures relate to material properties, using both experiments and simulations. Today, machine learning is bringing new perspectives to this challenge.
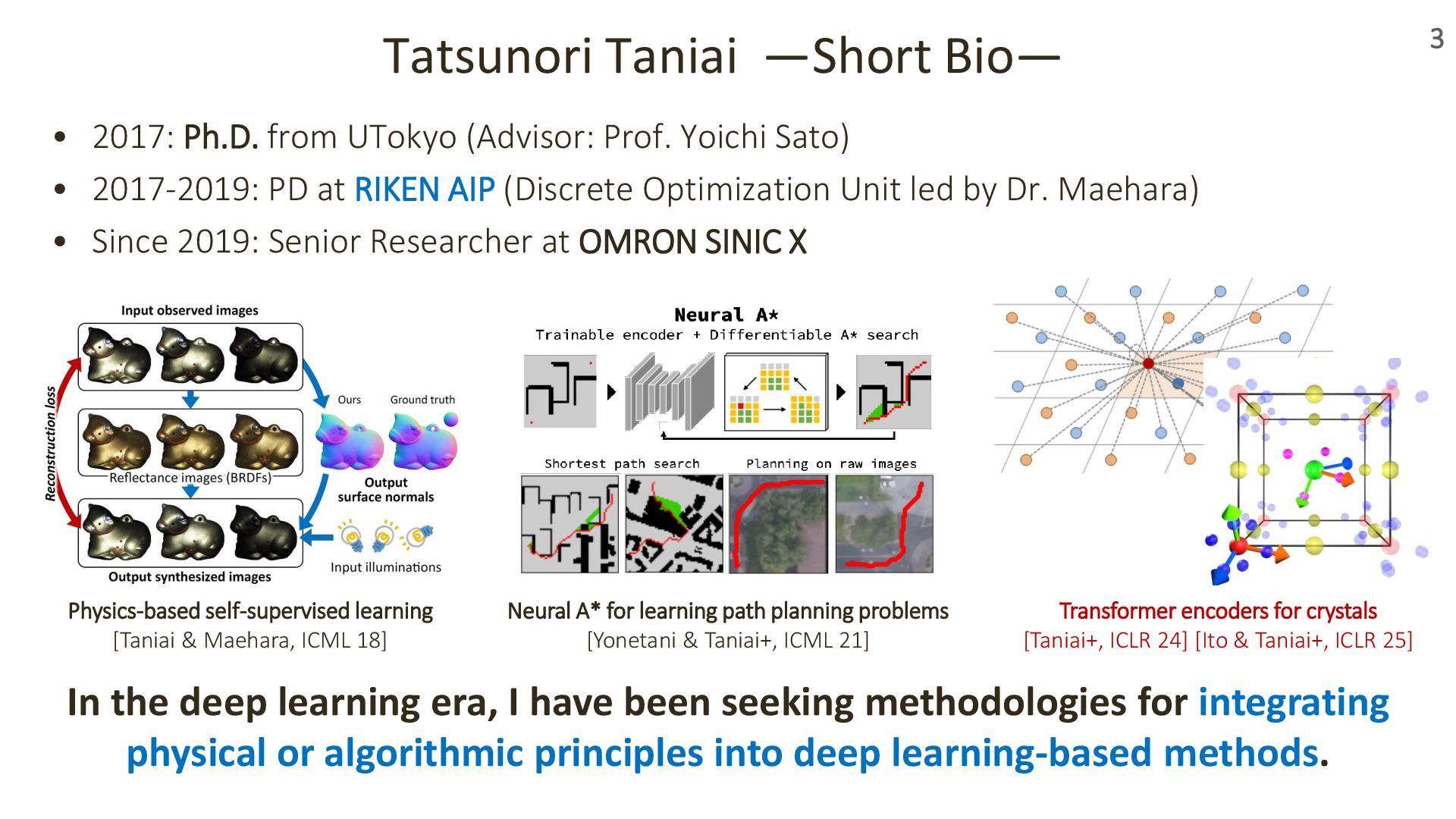
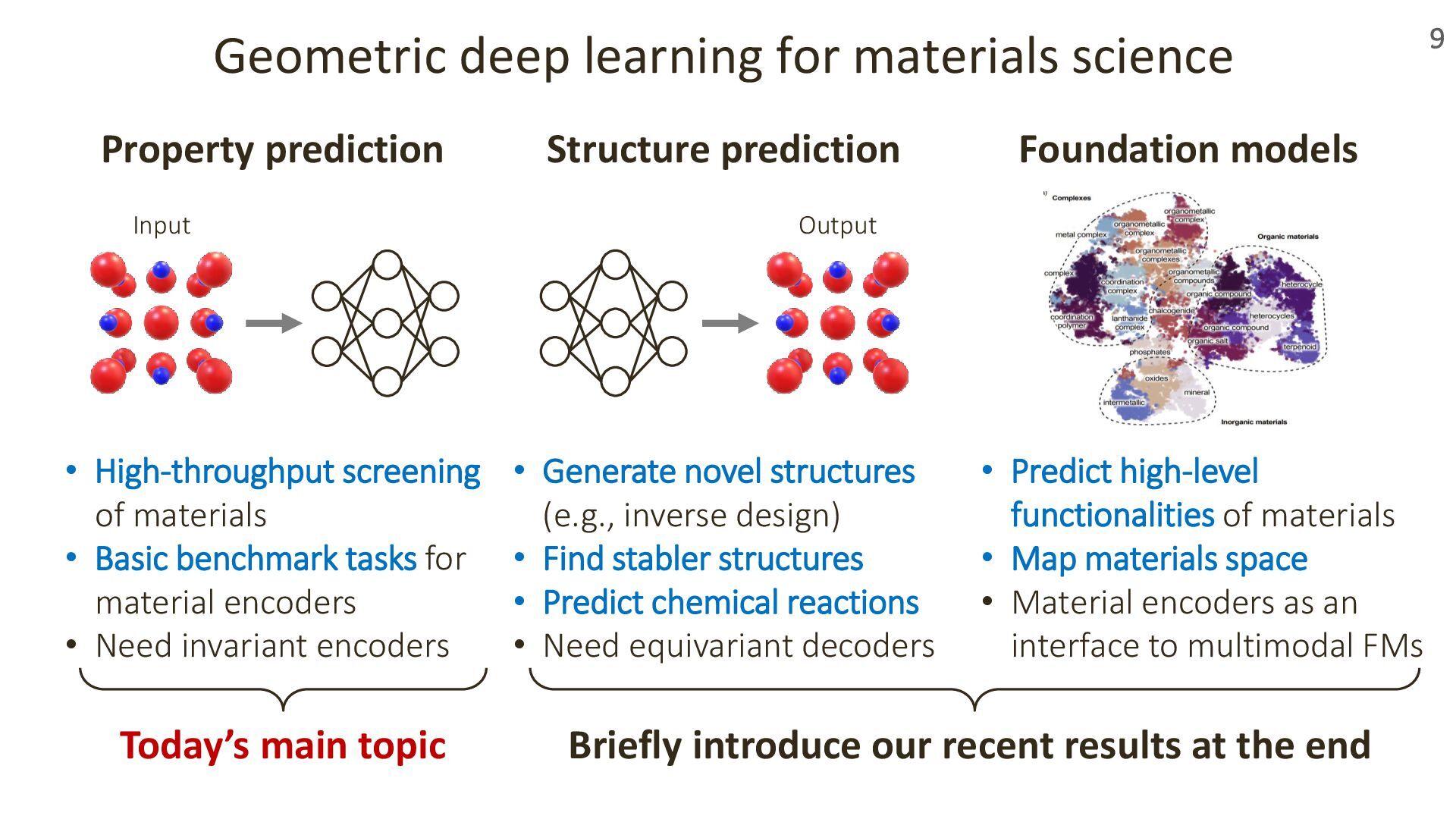
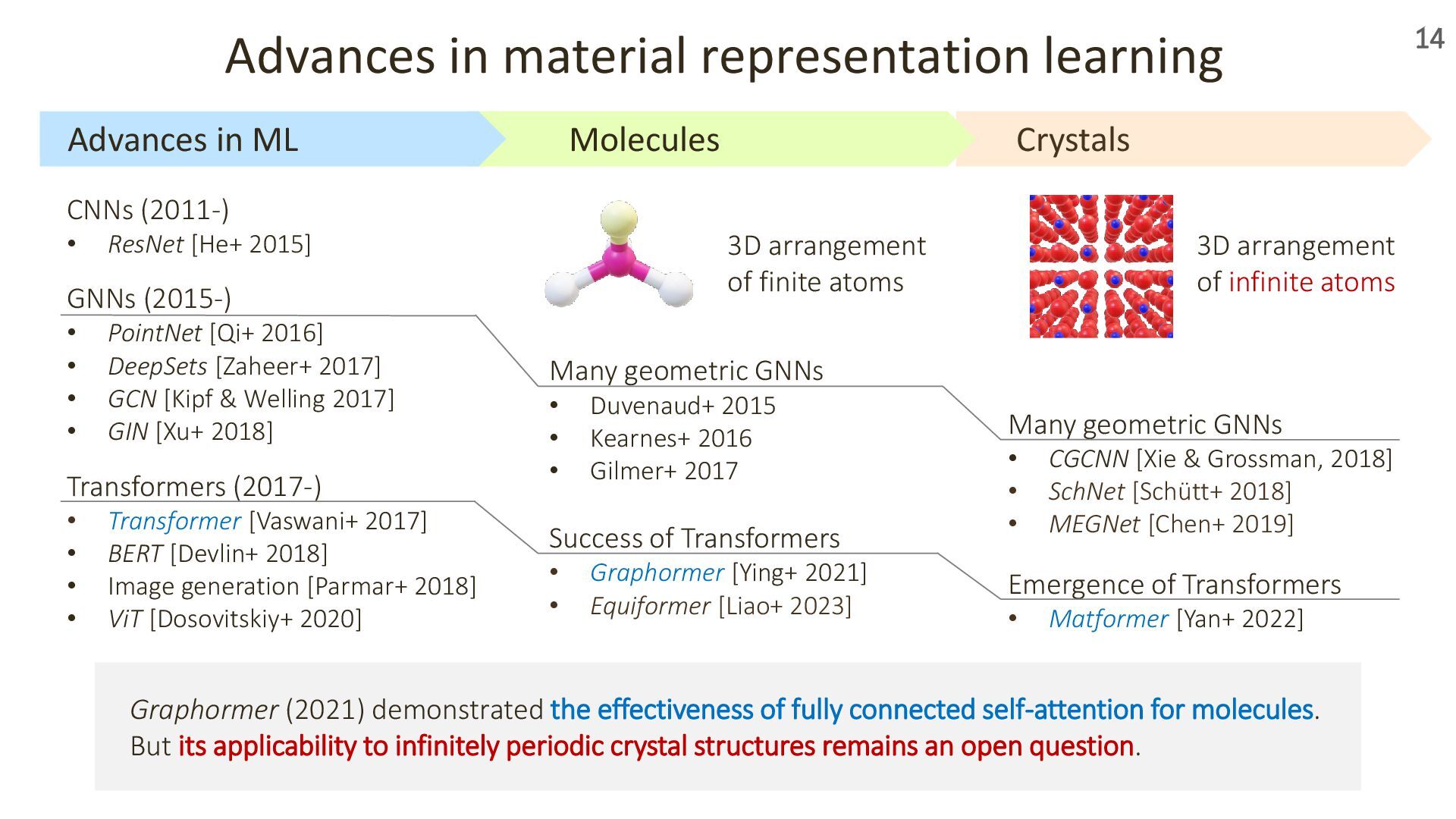
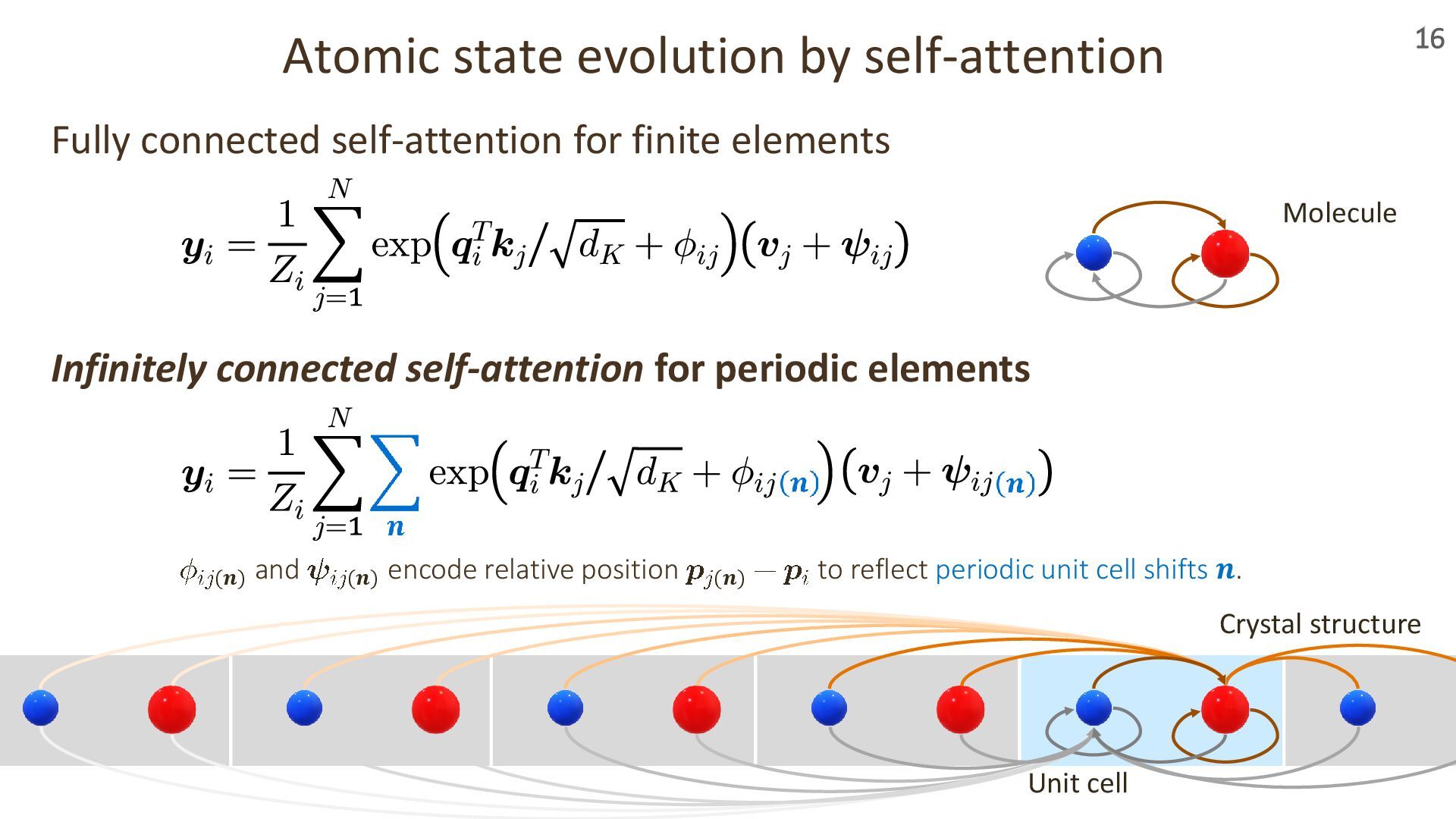
In this talk, I’ll introduce our recent work presented at ICLR 2024 and 2025 on transformer-based geometric encoders for crystal structures. These models aim to predict material properties by learning from the 3D periodic geometry of crystals. I’ll also touch on broader applications of these crystal encoders beyond property prediction, as explored in our group.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
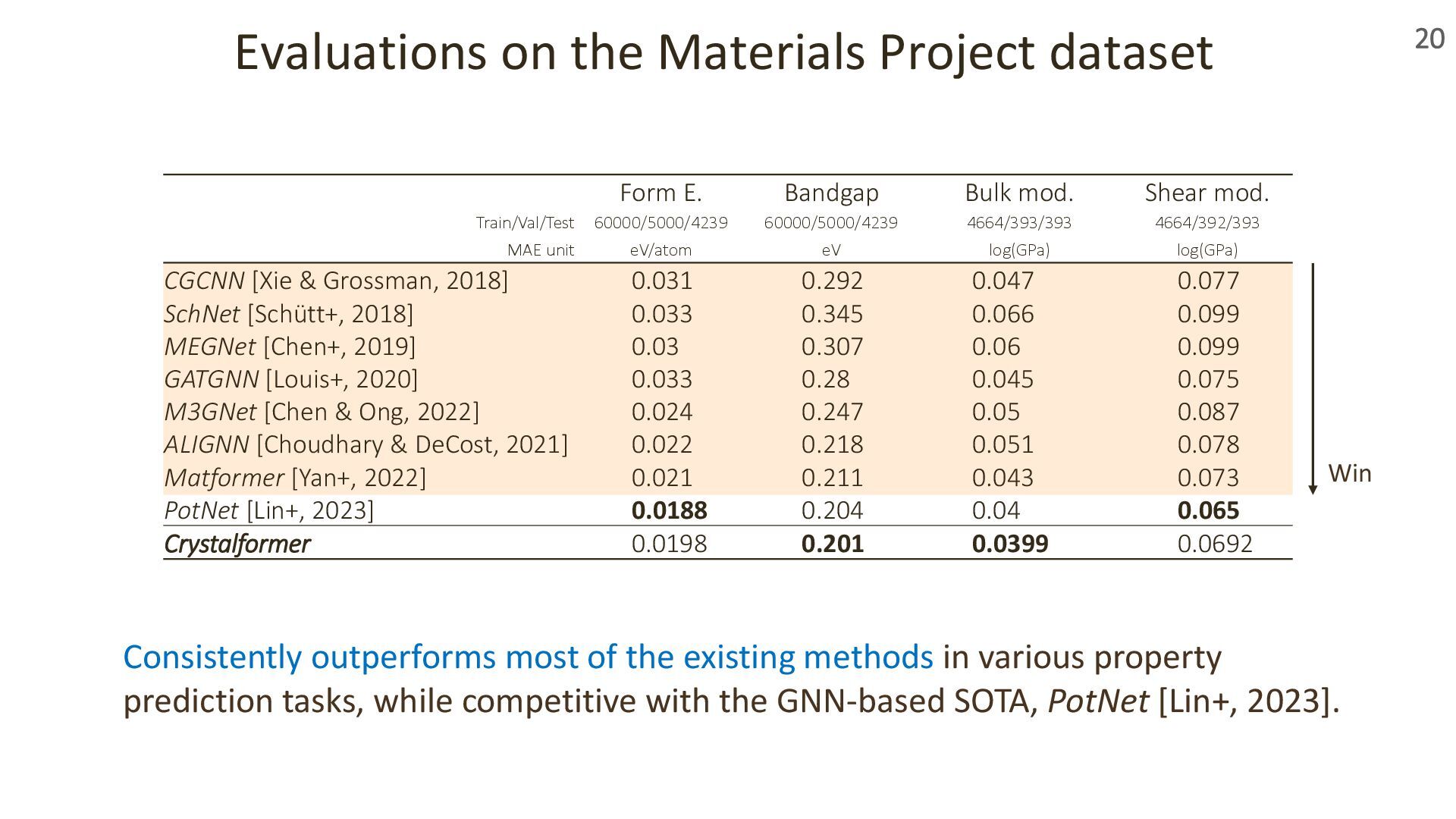{kind=link}
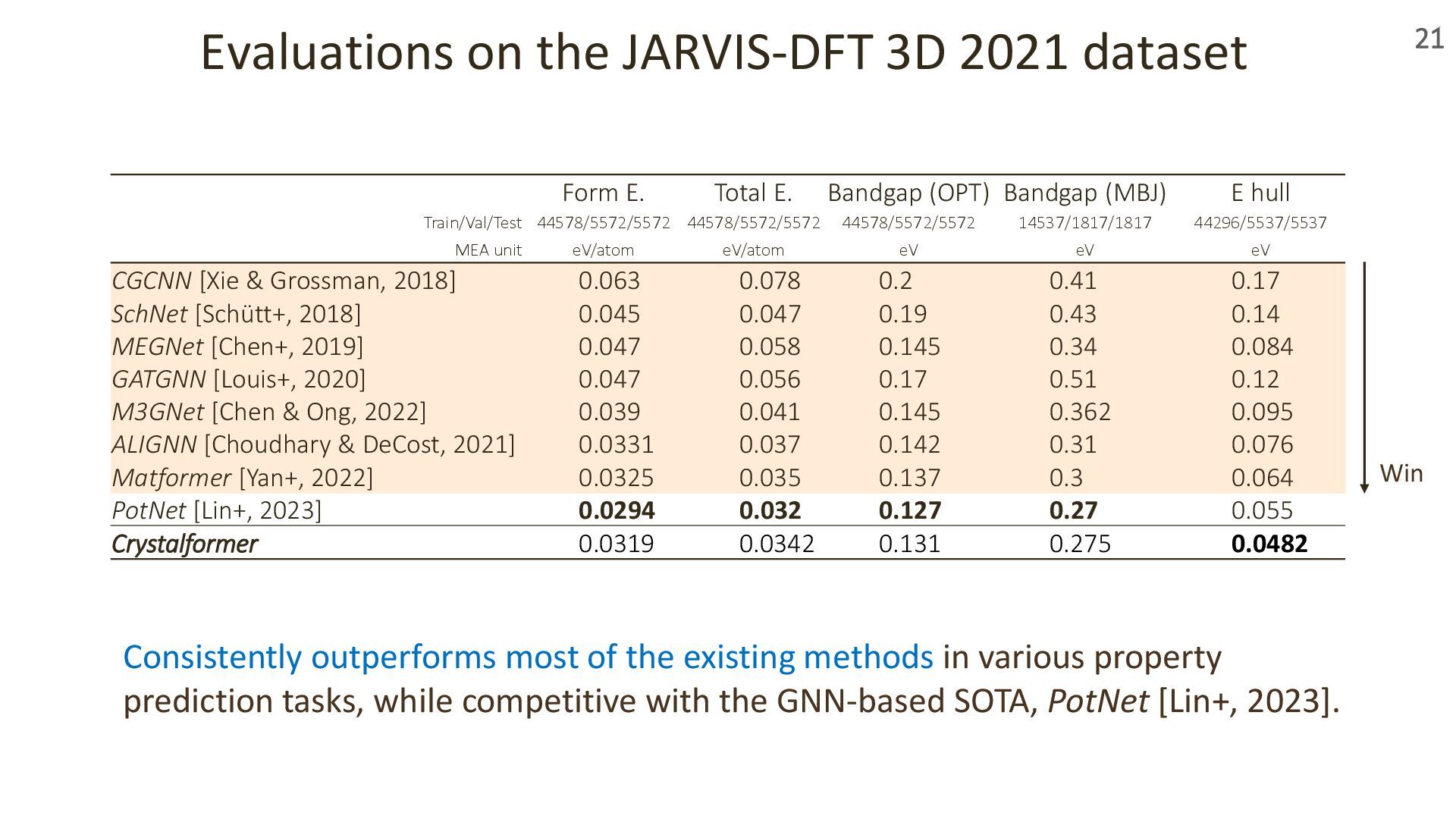{kind=link}
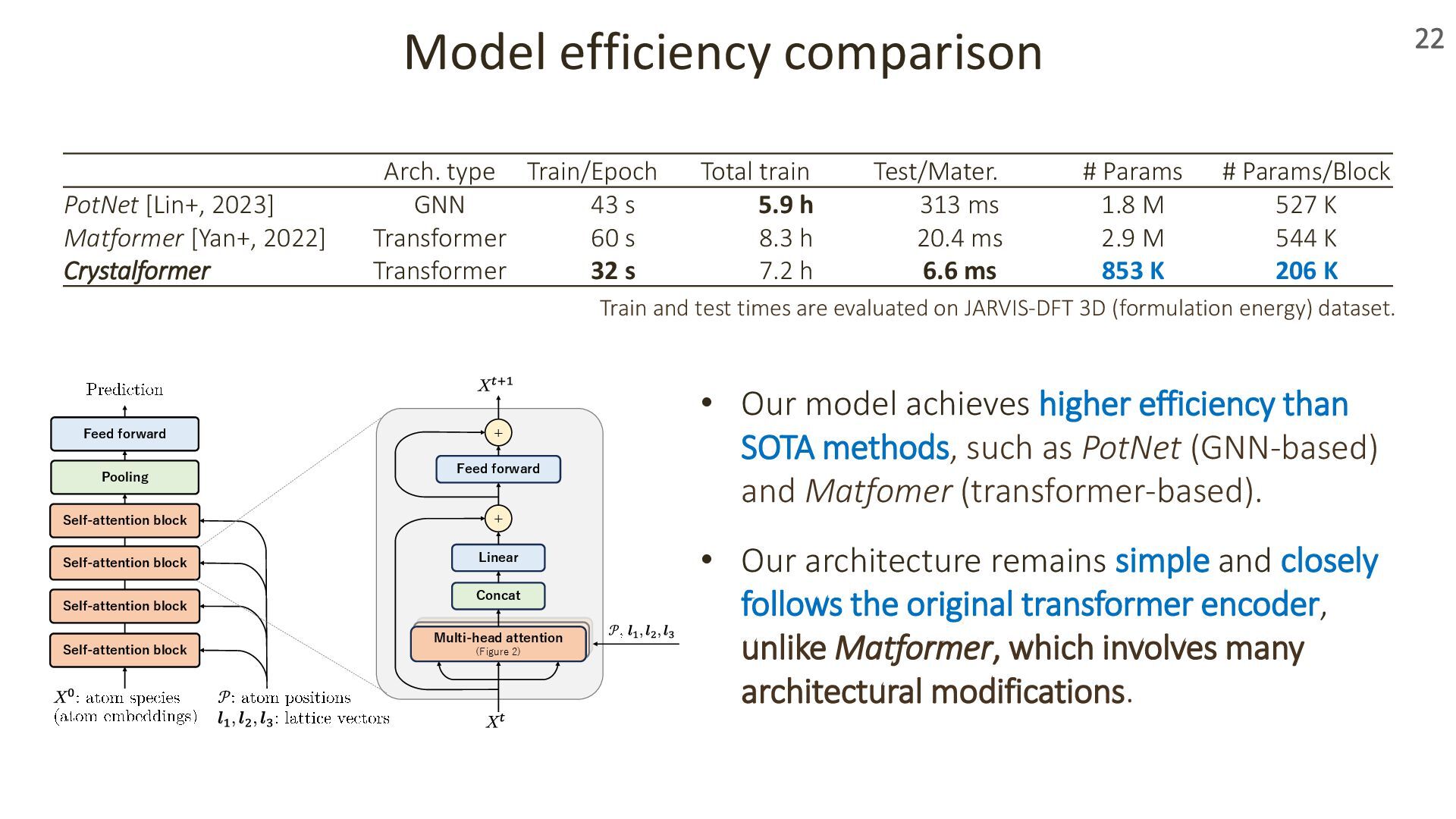{kind=link}
{kind=link}
{kind=link}
{kind=link}
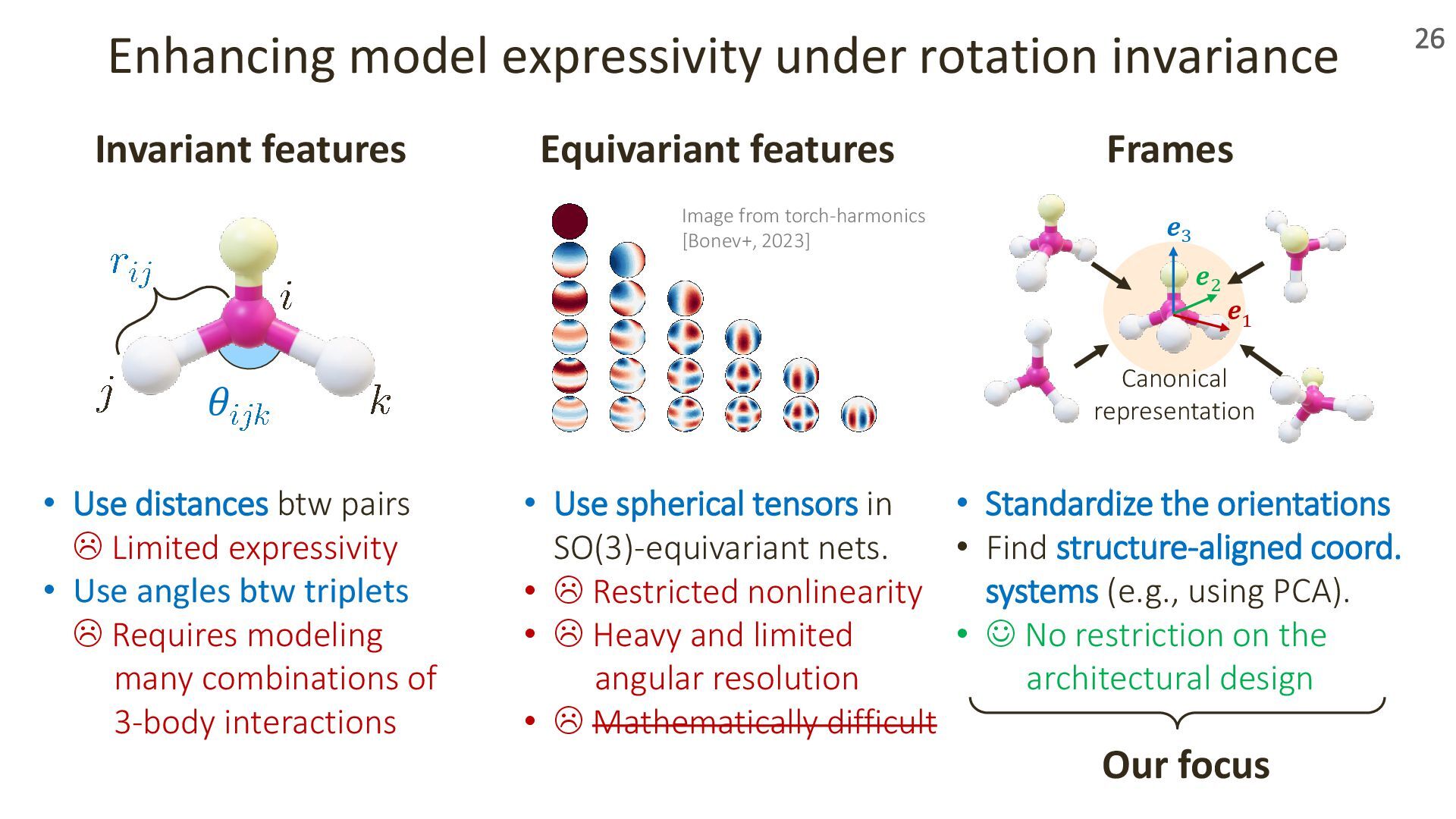{kind=link}
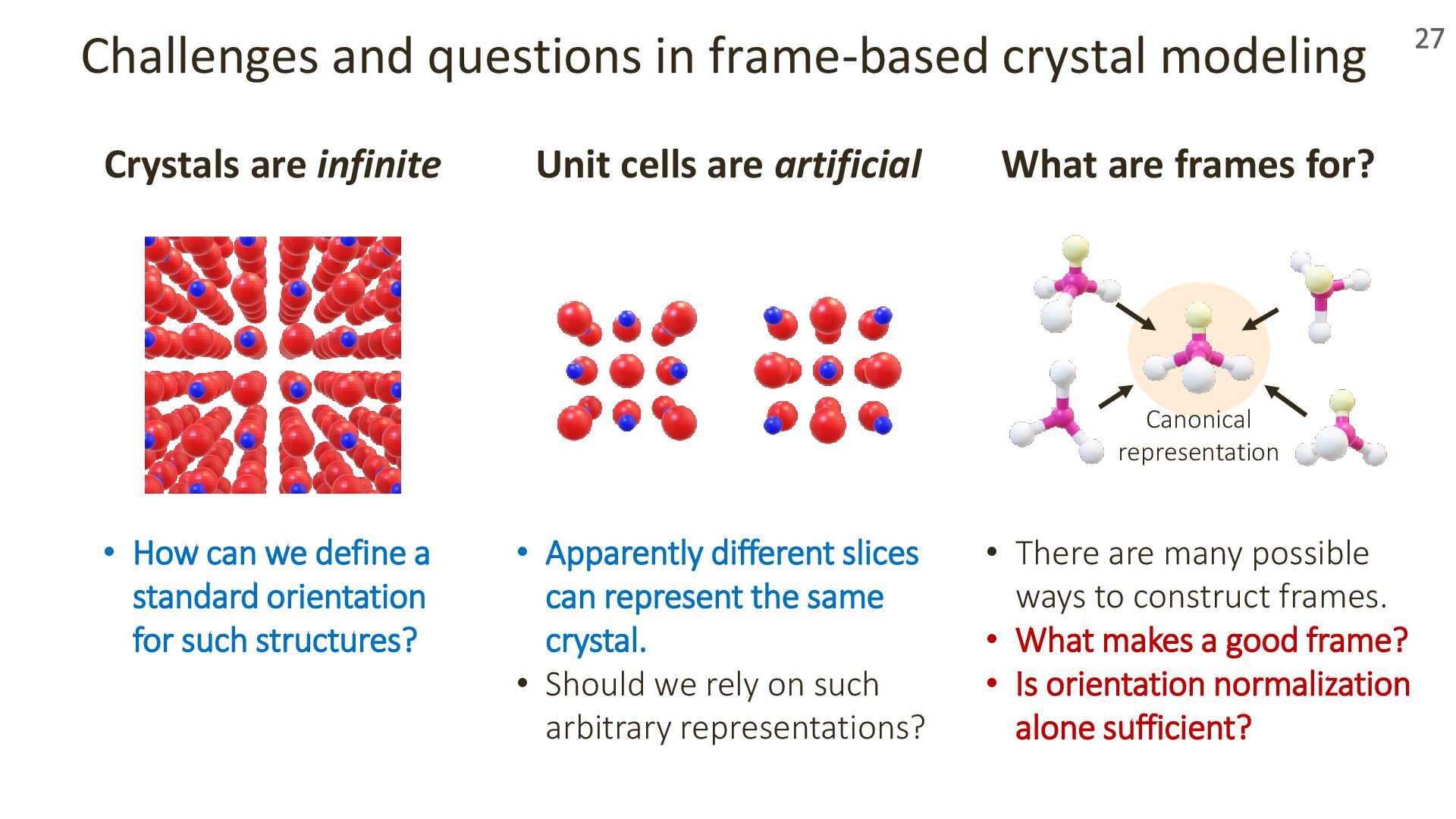{kind=link}
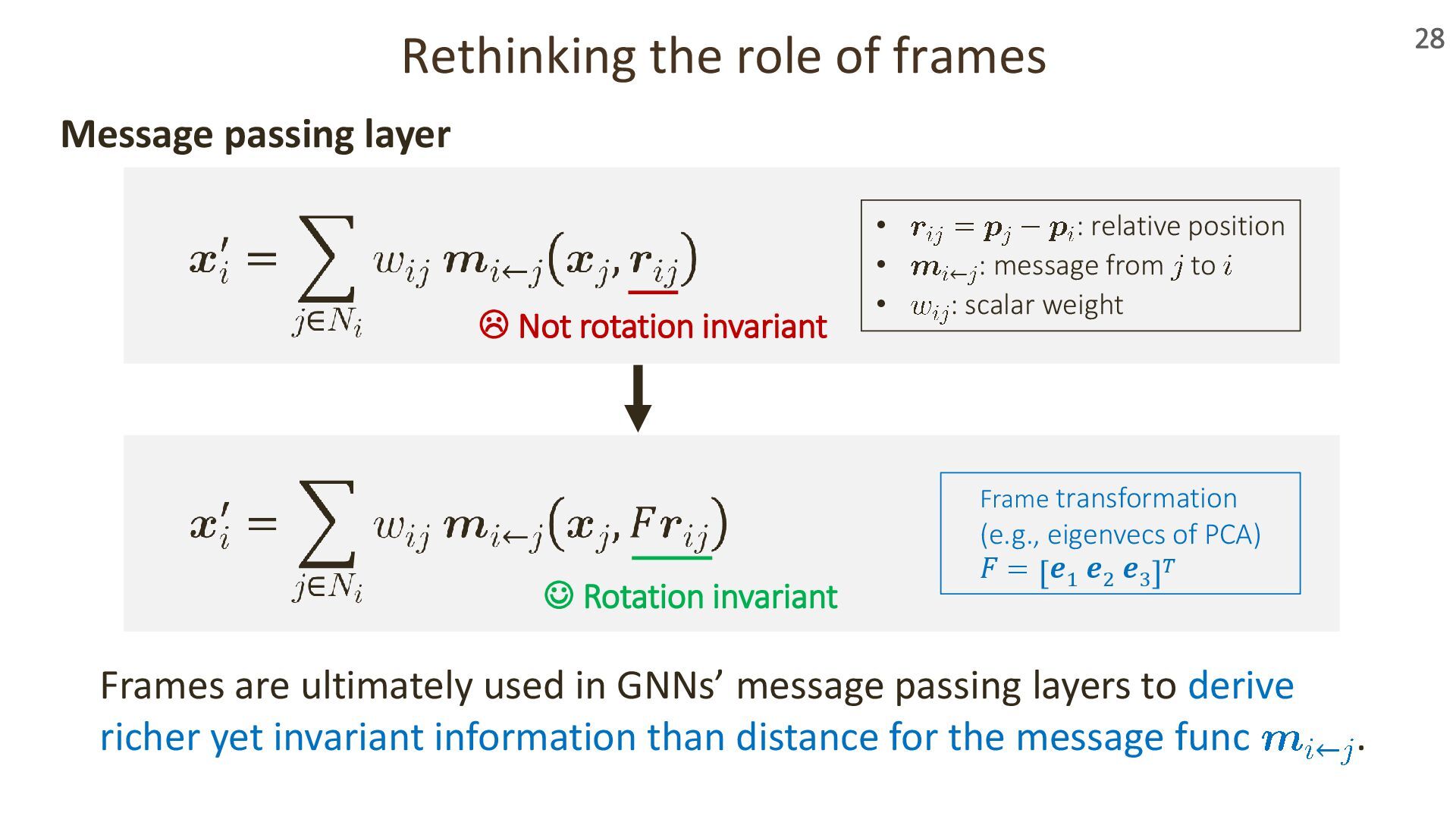{kind=link}
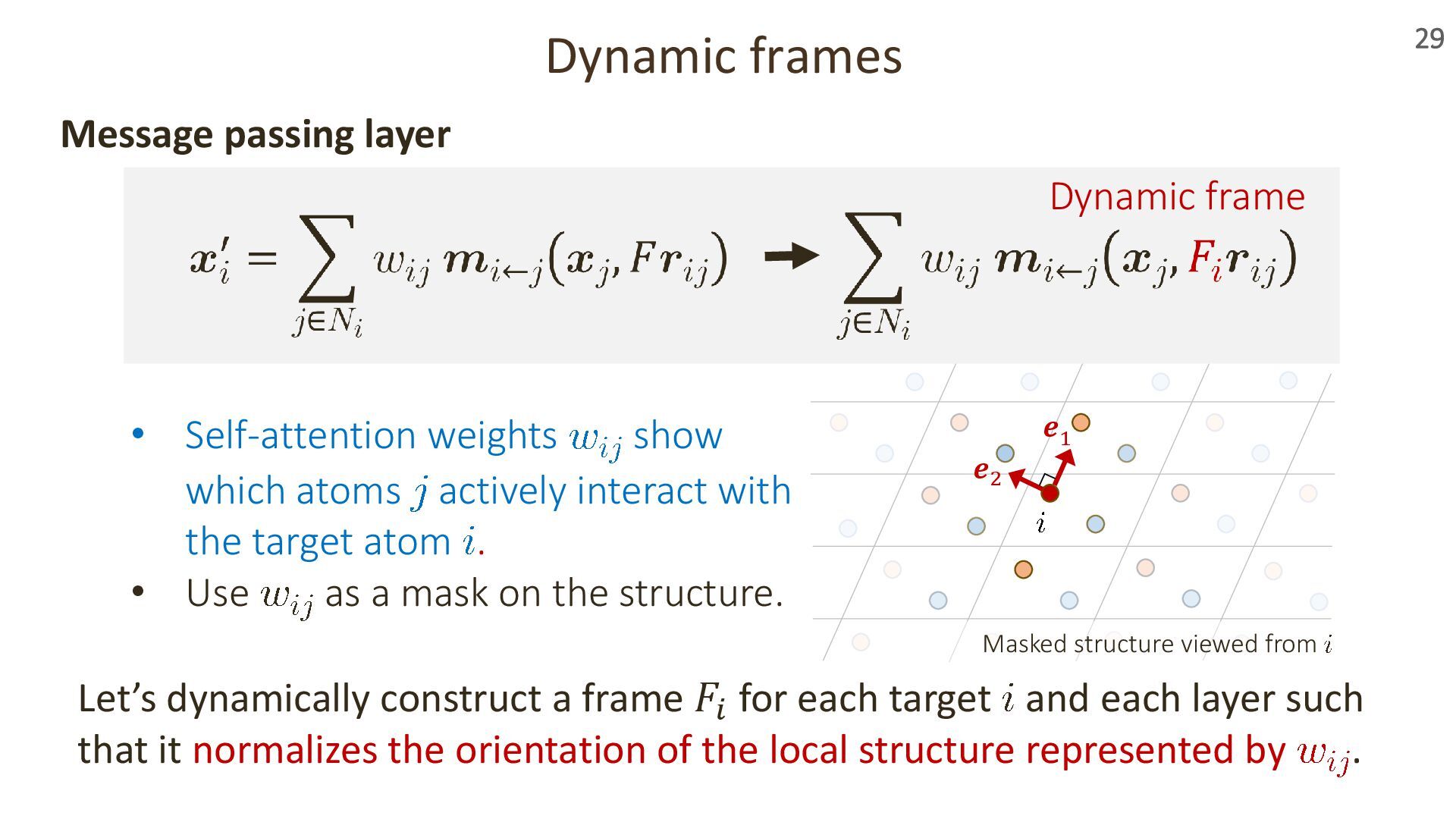{kind=link}
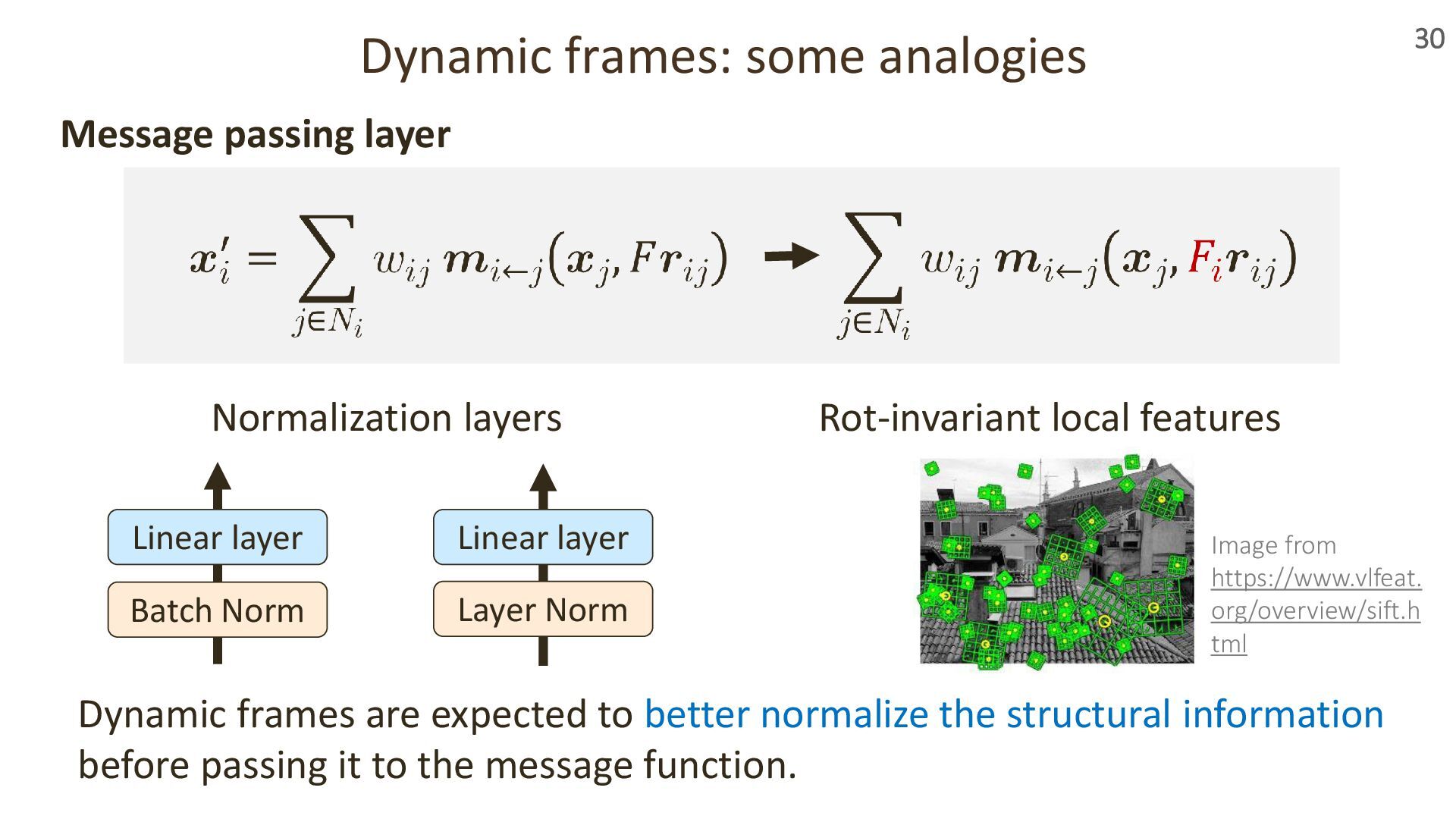{kind=link}
{kind=link}
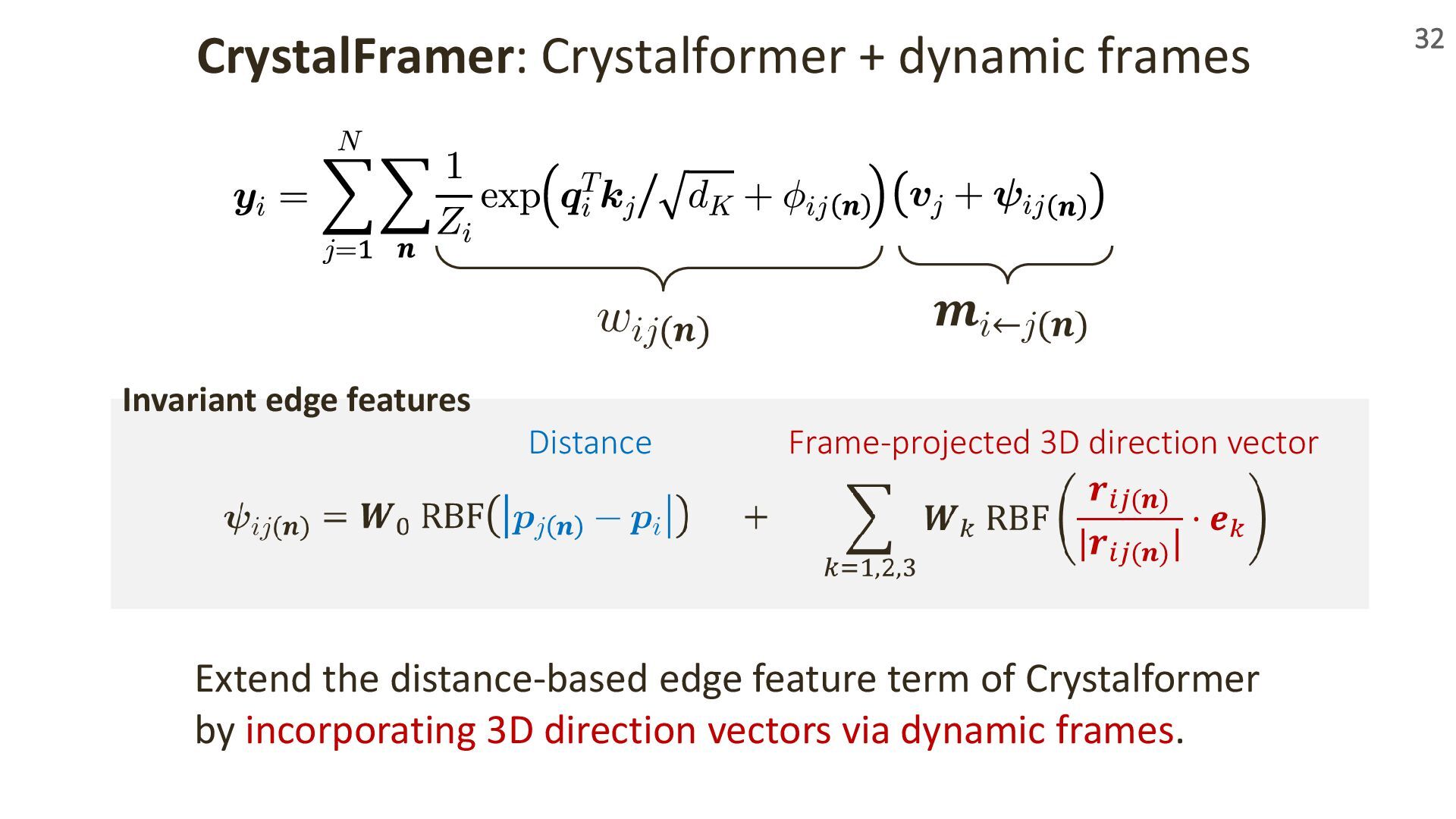{kind=link}
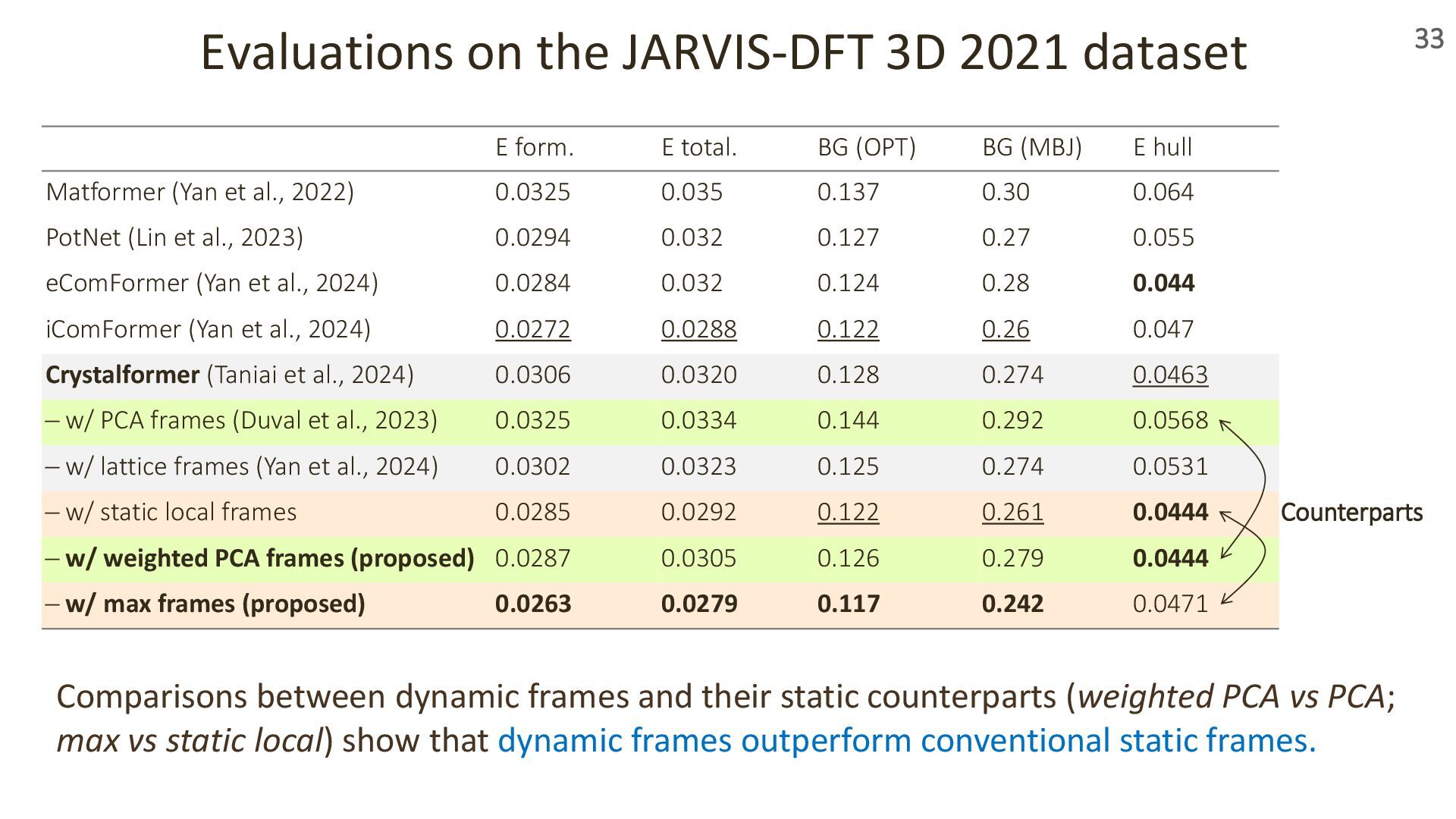{kind=link}
{kind=link}
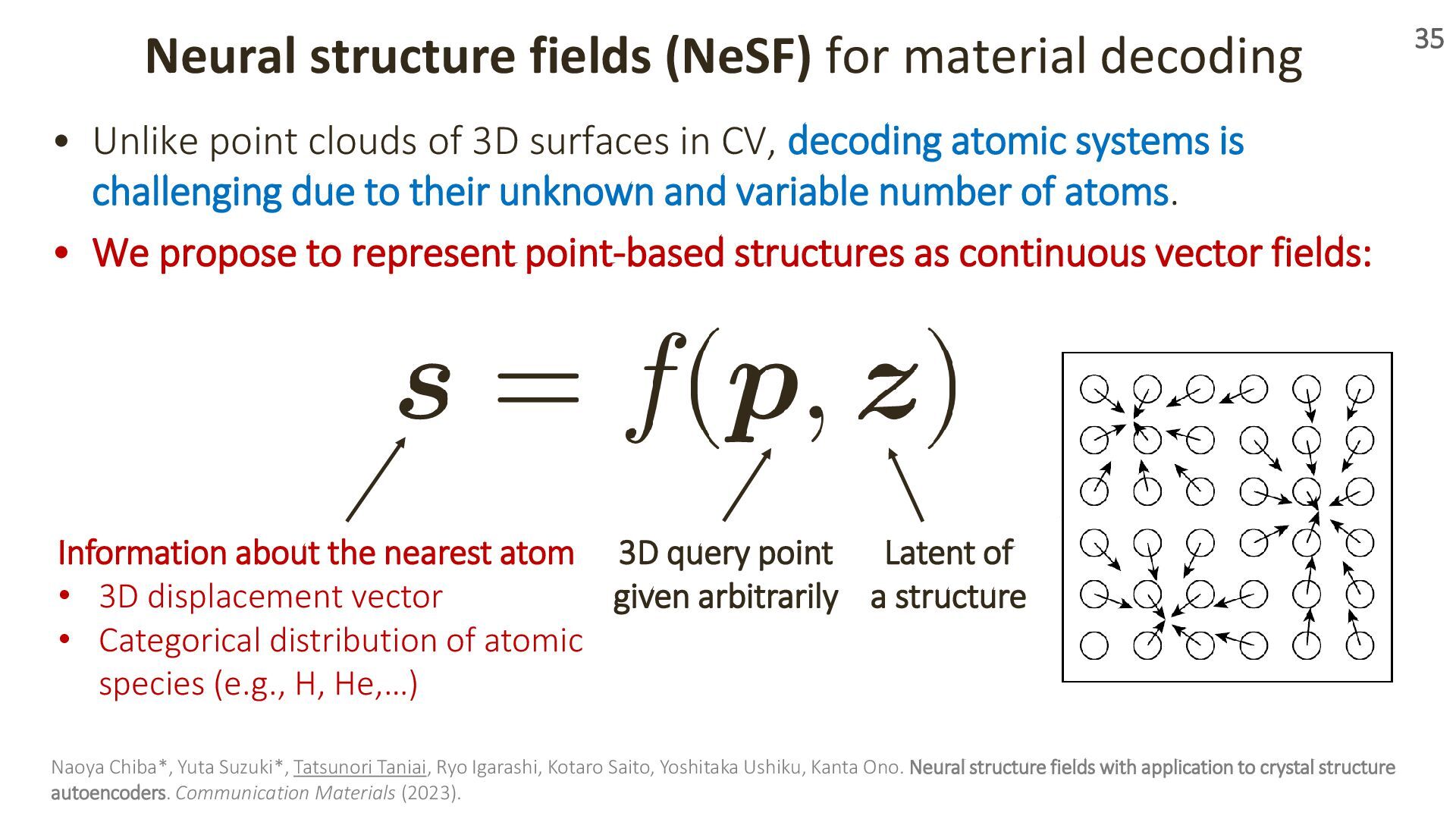{kind=link}
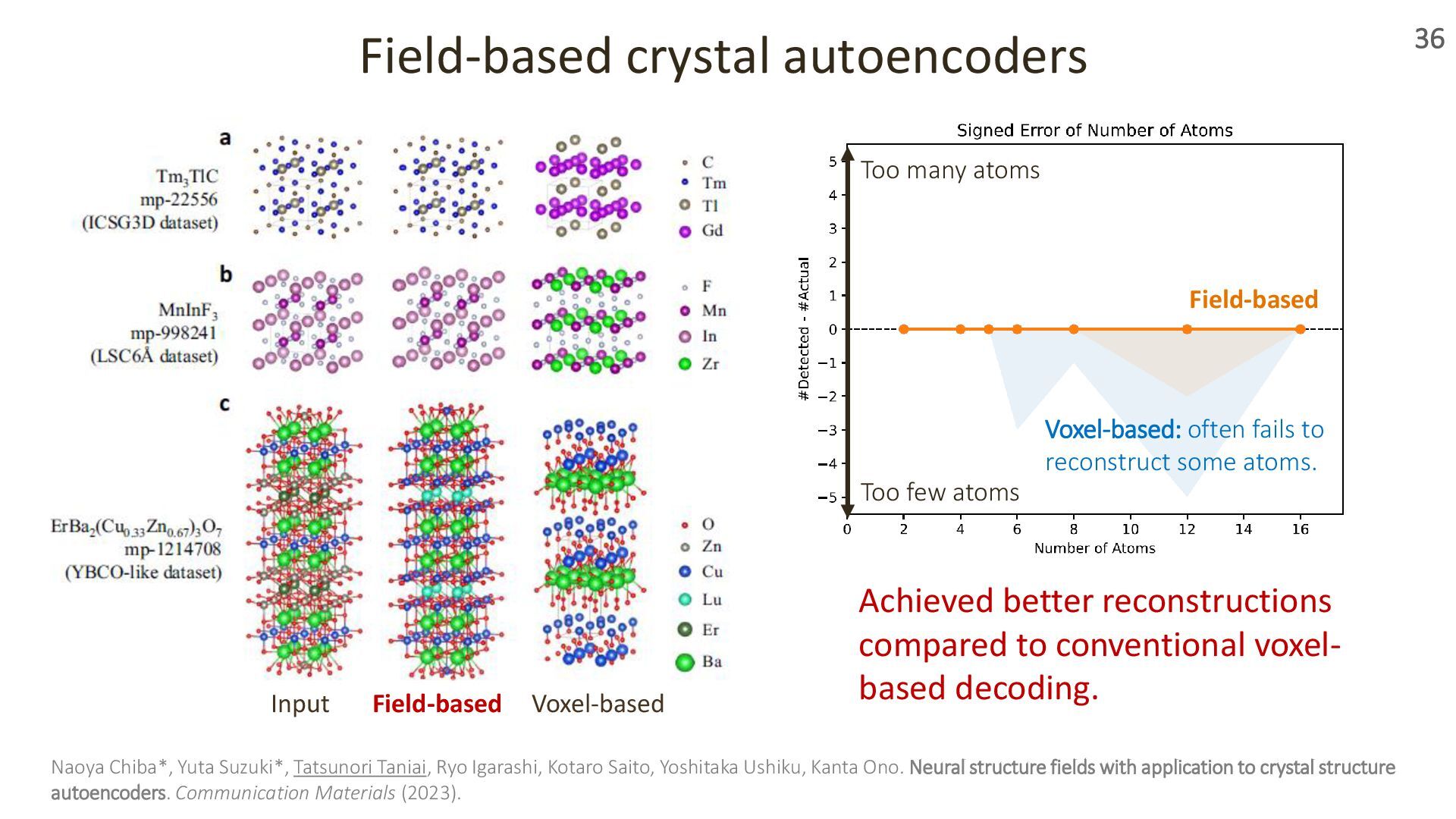{kind=link}
{kind=link}
{kind=link}
{kind=link}
![40 Summary of this talk Crystalformer [Taniai+, ICLR 2024] –](https://files.speakerdeck.com/presentations/f81c68fdb97c4dbe946d43c5e8521803/slide_39.jpg){kind=link}
{kind=link}