S., and Andrew G. Barto. 2018. Reinforcement Learning, Second Edition: An Introduction. MIT Press. Snyder, Lawrence V., and Zuo-Jun Max Shen. 2019. Fundamentals of Supply Chain Theory. John Wiley & Sons. Puterman, Martin L. 1990. “Chapter 8 Markov Decision Processes.” In Handbooks in Operations Research and Management Science, 2:331-434. Elsevier. Kochenderfer, Mykel J., and Tim A. Wheeler. 2019. Algorithms for Optimization. MIT Press. Jin, Yaochu, Handing Wang, and Chaoli Sun. 2021. Data-Driven Evolutionary Optimization: Integrating Evolutionary Computation, Machine Learning and Data Science. Springer Nature. Webpages “UCL Course on RL.” 2019. David Silver. December 19, 2019. https://www.davidsilver.uk/teaching/. Snyder, Larry. n.d. RL for Inventory Optimization. Github. Accessed January 4, 2024. https://github.com/LarrySnyder/RLforInventory. Poupart, Pascal. n.d. “CS885 Spring 2020 - Reinforcement Learning.” Accessed January 4, 2024. https://cs.uwaterloo.ca/ ppoupart/teaching/cs885-spring20/schedule.html. 3 / 78
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
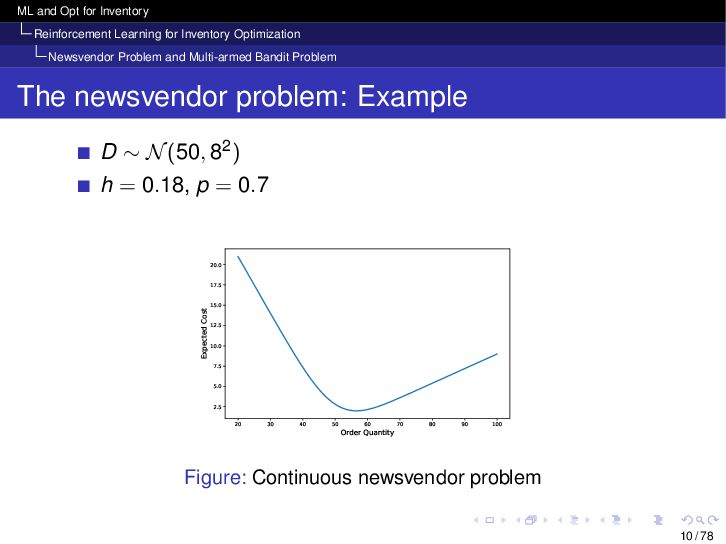{kind=link}
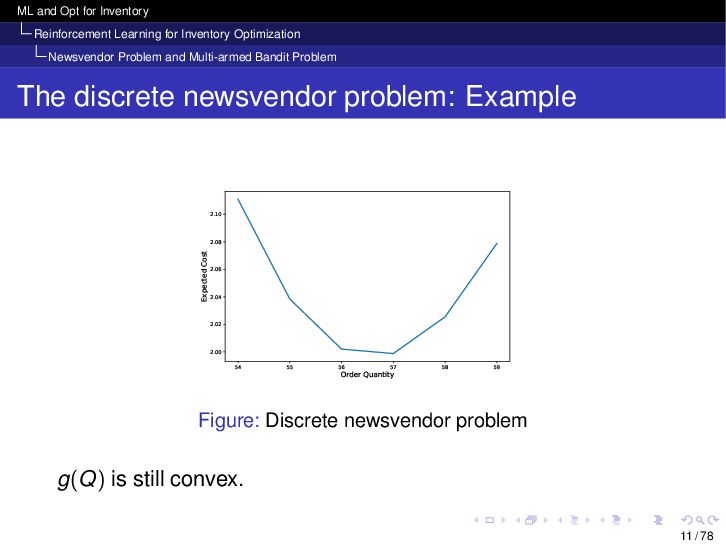{kind=link}
{kind=link}
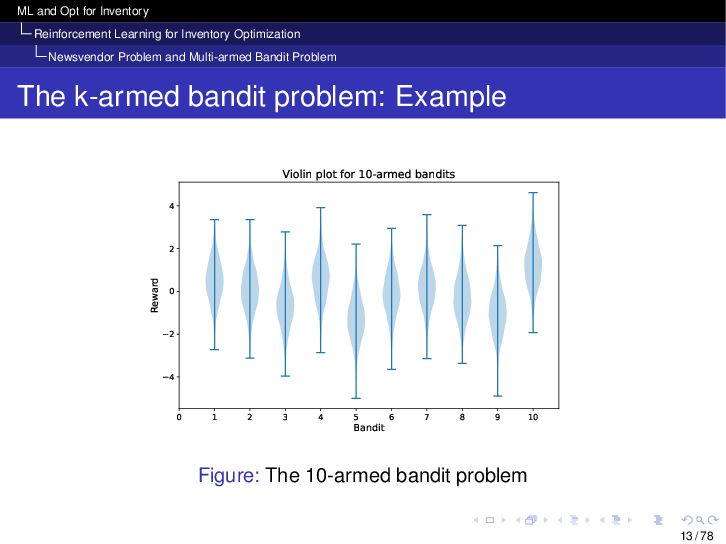{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
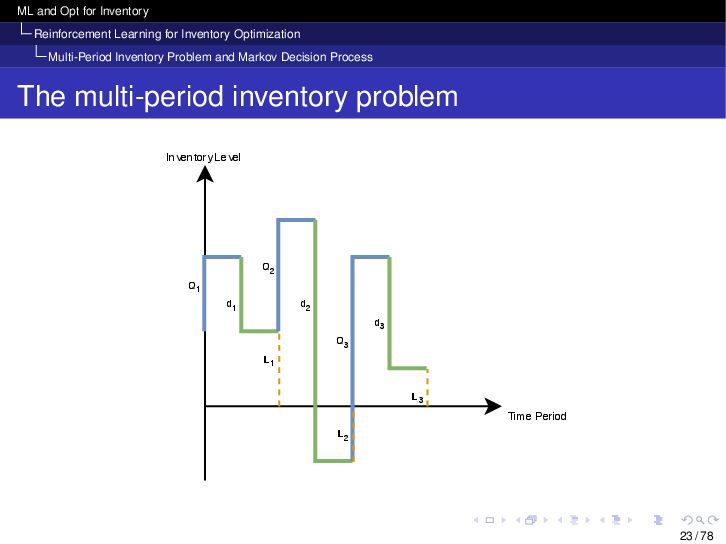{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
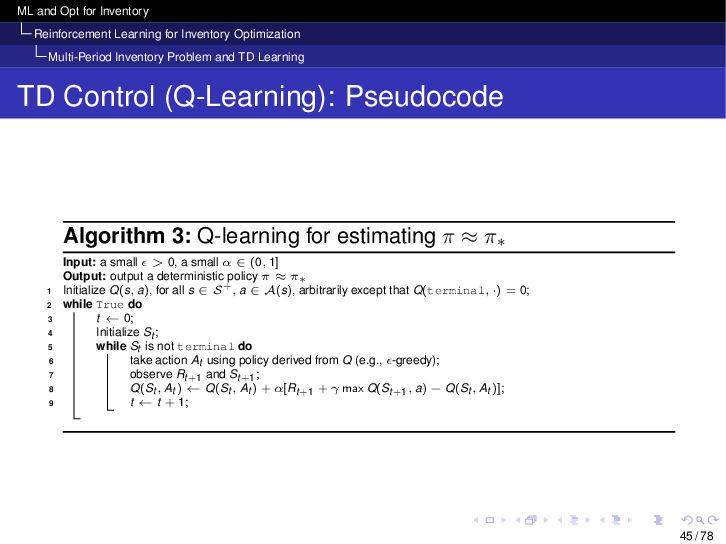{kind=link}
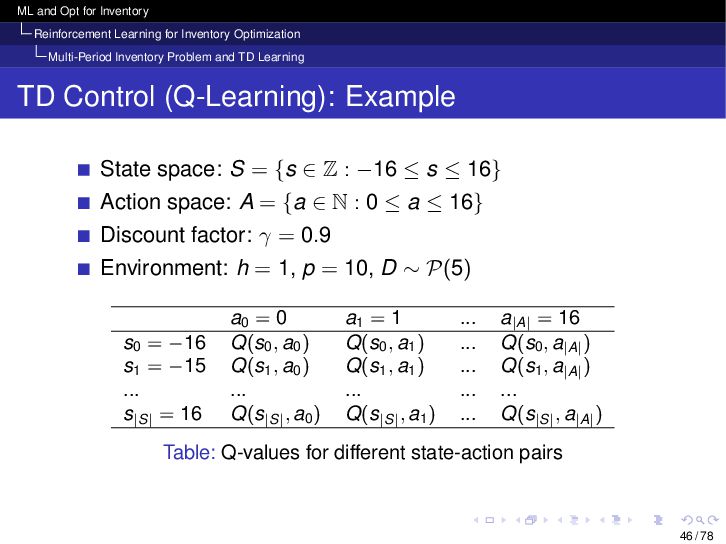{kind=link}
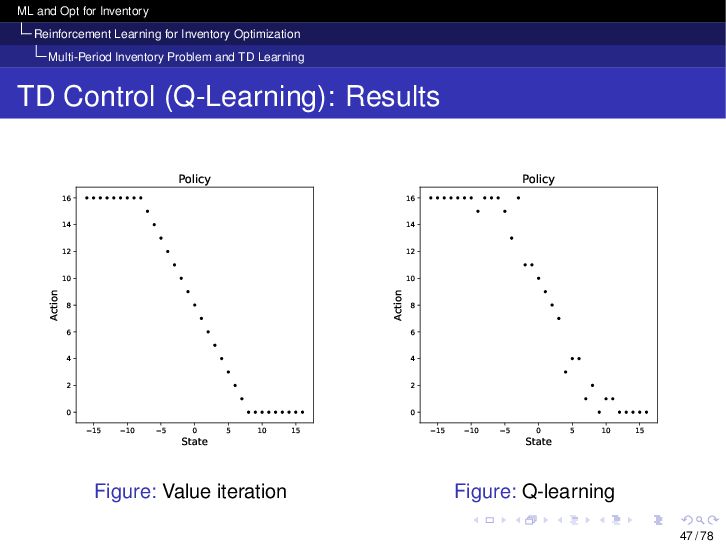{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
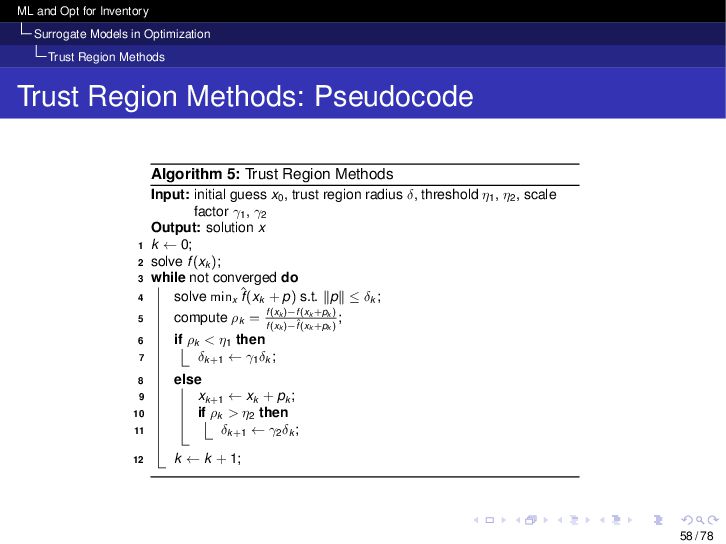{kind=link}
{kind=link}
{kind=link}
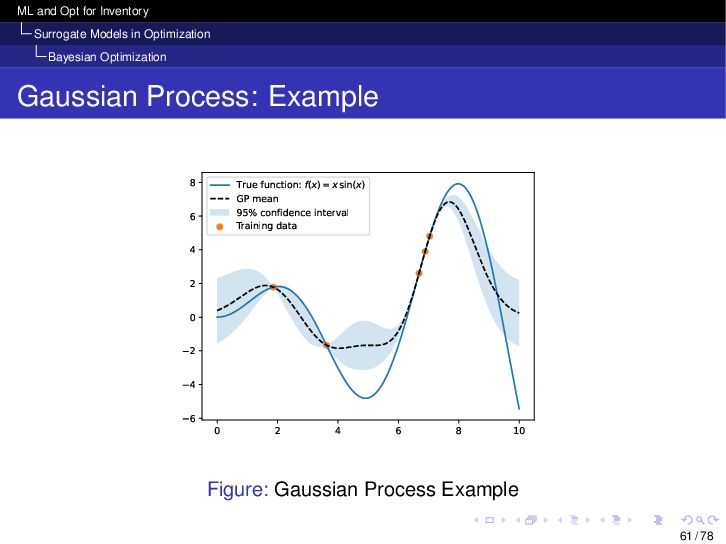{kind=link}
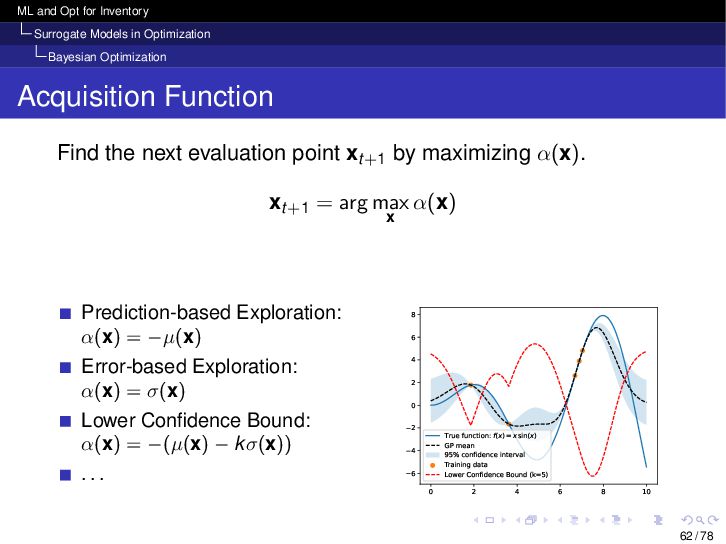{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
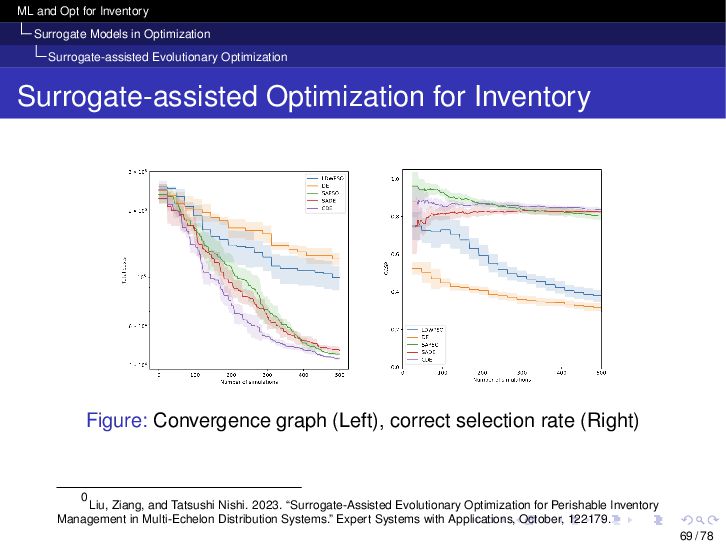{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}